
Neuronale Netze im Handel: Speichererweitertes kontextbezogenes Lernen für Kryptowährungsmärkte (letzter Teil)

Einführung
Im vorherigen Artikel haben wir das MacroHFT-Framework vorgestellt, das für den Hochfrequenzhandel mit Kryptowährungen (HFT) entwickelt wurde. Dieser Rahmen stellt einen modernen Ansatz dar, der kontextabhängige Reinforcement-Learning-Methoden mit Speichernutzung kombiniert und so eine effiziente Anpassung an dynamische Marktbedingungen bei gleichzeitiger Risikominimierung ermöglicht.
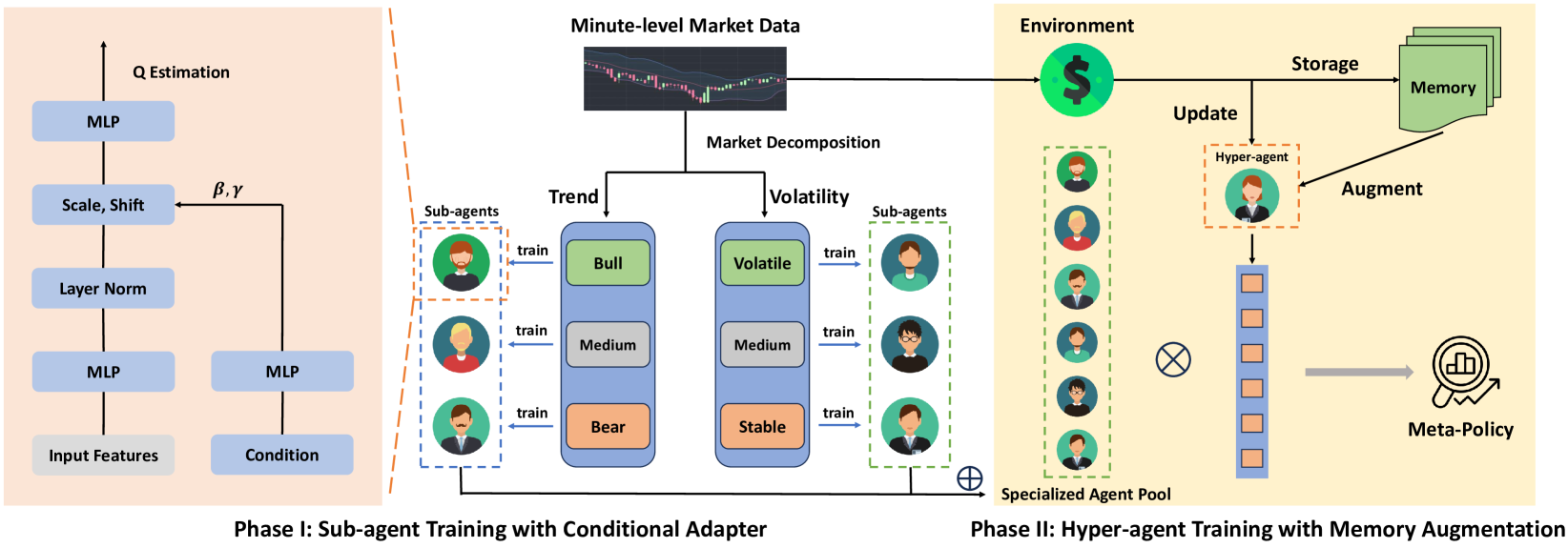
Das Funktionsprinzip von MacroHFT basiert auf zwei Stufen des Trainings seiner einzelnen Komponenten. In der ersten Stufe werden die Marktzustände nach Trendrichtung und Volatilitätsniveau klassifiziert. Dieser Prozess ermöglicht die Identifizierung der wichtigsten Marktzustände, die dann zum Training spezialisierter Unteragenten verwendet werden. Jeder Unteragent ist für den Betrieb in bestimmten Szenarien optimiert. In der zweiten Phase wird ein mit einem Speichermodul (memory) ausgestatteter Hyper-Agent ausgebildet, der die Arbeit der Unter-Agenten koordiniert. Dieses Modul berücksichtigt historische Daten und ermöglicht präzisere Entscheidungen auf der Grundlage früherer Erfahrungen.
Die Architektur von MacroHFT umfasst mehrere Schlüsselkomponenten. Das erste ist das Datenvorverarbeitungsmodul, das die Filterung und Normalisierung der eingehenden Marktinformationen vornimmt. Dadurch wird das Rauschen beseitigt und die Datenqualität verbessert, was für die anschließende Analyse von entscheidender Bedeutung ist.
Unteragenten sind Deep-Learning-Modelle, die auf bestimmte Marktszenarien trainiert wurden. Sie nutzen Methoden des Verstärkungslernens, um sich an komplexe und schnell wechselnde Bedingungen anzupassen. Die letzte Komponente ist der speichergestützte Hyper-Agent. Es integriert die Ergebnisse der Unteragenten und analysiert sowohl historische Ereignisse als auch den aktuellen Marktzustand. Dies ermöglicht eine hohe Vorhersagegenauigkeit und Widerstandsfähigkeit gegenüber Marktspitzen.
Durch die Integration all dieser Komponenten kann MacroHFT nicht nur unter sehr volatilen Marktbedingungen effektiv arbeiten, sondern auch die Rentabilitätskennzahlen deutlich verbessern.
Die Originalvisualisierung des MacroHFT-Rahmens ist unten zu sehen.
Im praktischen Teil des vorangegangenen Artikels haben wir ein Hyper-Agenten-Objekt erstellt und seinen Interaktionsalgorithmus mit Unter-Agenten implementiert. Heute werden wir diese Arbeit fortsetzen und uns dabei auf neue Aspekte der MacroHFT-Architektur konzentrieren.
Modul Risikomanagement
Im vorigen Artikel haben wir den Betrieb des Hyperagenten als das Objekt CNeuronMacroHFTHyperAgent organisiert und Algorithmen für seine Interaktion mit Sub-Agenten entwickelt. Außerdem haben wir beschlossen, bereits erstellte Analysten-Agenten mit komplexeren Architekturen als Unteragenten zu verwenden. Auf den ersten Blick scheint dies für die Umsetzung des MacroHFT-Rahmens ausreichend zu sein. Die derzeitige Implementierung hat jedoch gewisse Einschränkungen: Sowohl die Subagenten als auch der Hyperagent analysieren nur den Zustand der Umgebung. Dies ermöglicht zwar die Vorhersage künftiger Kursbewegungen, die Bestimmung der Handelsrichtung und die Festlegung von Stop-Loss- und Take-Profit-Niveaus, aber es geht nicht auf die Handelsgröße ein, die ein entscheidendes Element der Gesamtstrategie ist.
Die Verwendung einer festen Handelsgröße oder die Berechnung des Volumens auf der Grundlage eines festen Risikoniveaus im Verhältnis zu einem prognostizierten Stop-Loss und Kontostand ist möglich. Allerdings ist jede Prognose mit einem individuellen Konfidenzniveau verbunden. Es ist logisch anzunehmen, dass dieses Vertrauensniveau eine zentrale Rolle bei der Bestimmung des Handelsvolumens spielen sollte. Ein hohes Vertrauen in eine Vorhersage erlaubt größere Handelsgeschäfte und maximiert die Gesamtrentabilität, während ein geringes Vertrauen einen konservativeren Ansatz nahelegt.
In Anbetracht dieser Faktoren beschloss ich, die Umsetzung um ein Risikomanagementmodul zu erweitern. Dieses Modul wird in die bestehende Architektur integriert, um einen flexiblen, anpassungsfähigen Ansatz für das Losgrößenbestimmung des Handelsgeschäfts zu bieten. Die Einführung des Risikomanagements wird die Widerstandsfähigkeit des Modells gegenüber instabilen Marktbedingungen verbessern, was besonders im Hochfrequenzhandel wichtig ist.
Es ist wichtig zu beachten, dass in diesem Fall der Risikomanagement-Algorithmus teilweise von der direkten Umweltanalyse „abgekoppelt“ ist. Stattdessen liegt der Schwerpunkt auf der Bewertung der Auswirkungen der Handlungen des Vertreters auf die finanziellen Ergebnisse. Die Idee ist, jeden Handel mit Veränderungen in der Bilanz zu korrelieren und Muster zu erkennen, die auf die Wirksamkeit der Politik hinweisen. Eine wachsende Zahl gewinnbringender Handelsgeschäfte in Verbindung mit einem stetig wachsenden Saldo zeigt den Erfolg der derzeitigen Politik und rechtfertigt ein höheres Risiko pro Handelsgeschäft. Umgekehrt signalisiert eine Zunahme von Verlustgeschäften die Notwendigkeit einer konservativeren Strategie zur Risikominderung. Dieser Ansatz verbessert nicht nur die Anpassung an sich ändernde Marktbedingungen, sondern erhöht auch die Effizienz des Kapitalmanagements insgesamt. Um die Qualität der Analyse zu verbessern, werden außerdem mehrere Projektionen des Kontostandes erstellt, die jeweils unterschiedliche Aspekte des aktuellen und historischen Zustands darstellen. Dies ermöglicht eine genauere Bewertung der Leistung der Strategie und eine rechtzeitige Anpassung an die Marktdynamik.
Der Risikomanagement-Algorithmus ist in dem Objekt CNeuronMacroHFTvsRiskManager implementiert, dessen Struktur unten dargestellt ist.
class CNeuronMacroHFTvsRiskManager : public CResidualConv { protected: CNeuronBaseOCL caAccountProjection[2]; CNeuronMemoryDistil cMemoryAccount; CNeuronMemoryDistil cMemoryAction; CNeuronRelativeCrossAttention cCrossAttention; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronMacroHFTvsRiskManager(void) {}; ~CNeuronMacroHFTvsRiskManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMacroHFTvsRiskManager; } //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Die vorgestellte Struktur enthält eine Reihe von Standardmethoden, die überschrieben werden können, sowie mehrere interne Objekte, die eine Schlüsselrolle bei der Umsetzung des oben beschriebenen Risikomanagementmechanismus spielen. Die Funktionalität dieser internen Objekte wird bei der Beschreibung der Klassenmethoden im Detail erörtert, um ein tieferes Verständnis ihrer Verwendungslogik zu ermöglichen.
Alle internen Objekte in unserer Risikomanagementklasse sind als statisch deklariert, was die Objektstruktur vereinfacht. Dadurch können der Konstruktor und der Destruktor leer bleiben, da keine zusätzlichen Operationen zur Initialisierung oder Speicherbereinigung erforderlich sind. Die Initialisierung aller geerbten und deklarierten Objekte erfolgt in der Methode Init, die für die Einrichtung der Klassenarchitektur bei der Erstellung verantwortlich ist.
Die Klassenparameter enthalten Konstanten, die eine eindeutige Interpretation der Architektur des Objekts ermöglichen.
bool CNeuronMacroHFTvsRiskManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (nactions + 2) / 3, optimization_type, batch)) return false;
Innerhalb des Methodenkörpers wird sofort die gleichnamige Methode der Elternklasse aufgerufen. In diesem Fall handelt es sich um einen Faltungsblock mit Rückkopplung. Es ist wichtig zu beachten, dass die erwartete Ausgabe dieses Moduls ein Tensor ist, der eine Handelsentscheidungsmatrix darstellt. Jede Zeile beschreibt einen separaten Handel und enthält einen Vektor von Handelsparametern: Volumen, Stop Loss und Take Profit. Um die Handelsanalyse korrekt zu organisieren, werden Kauf- und Verkaufsgeschäfte als separate Zeilen behandelt, was eine unabhängige Analyse von jedem Handelsgeschäft ermöglicht.
Bei der Organisation von Faltungsoperationen werden die Kernelgröße und die Schrittweite auf 3 gesetzt, was der Anzahl der Parameter in der Handelsbeschreibung entspricht.
Als Nächstes wollen wir uns den Initialisierungsprozess der internen Objekte ansehen. Es ist wichtig zu beachten, dass das Risikomanagementmodul auf zwei wichtige Datenquellen angewiesen ist: Aktionen des Agenten und ein Vektor, der den analysierten Kontostatus beschreibt. Der Hauptdatenstrom, der die Aktionen des Agenten darstellt, wird als Objekt der neuronalen Schicht bereitgestellt. Der sekundäre Datenstrom, der die Beschreibung des Kontostands enthält, wird durch einen Datenpuffer geleitet.
Damit alle internen Komponenten ordnungsgemäß funktionieren, müssen beide Datenströme als neuronale Schichtobjekte dargestellt werden. Der erste Schritt ist daher die Initialisierung einer vollständig verknüpften neuronalen Schicht, in die Daten aus dem zweiten Datenstrom übertragen werden.
int index = 0; if(!caAccountProjection[0].Init(0, index, OpenCL, account_decr, optimization, iBatch)) return false;
In der nächsten Stufe wird eine vollständig verknüpfte Schicht hinzugefügt, die Projektionen der Beschreibung des Kontostandes bilden soll. Diese trainierbare Schicht erzeugt einen Tensor, der mehrere Projektionen des analysierten Kontostandes in Unterräume bestimmter Dimensionalität enthält. Die Anzahl der Projektionen und die Dimensionalität der Teilräume werden als Verfahrensparameter angegeben, was eine flexible Konfiguration der Ebenen für verschiedene Aufgaben ermöglicht.
index++; if(!caAccountProjection[1].Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false;
Die vom Risikomanagementmodul empfangenen Rohdaten liefern nur eine statische Beschreibung des analysierten Zustands. Um jedoch die Wirksamkeit der Politik des Agenten genau zu bewerten, müssen dynamische Veränderungen berücksichtigt werden. Speichermodule werden auf beide Informationsströme angewandt, um die zeitliche Abfolge der Daten zu erfassen. Eine wichtige Entscheidung ist, ob der ursprüngliche Kontostandsvektor oder seine Projektionen gespeichert werden sollen. Der ursprüngliche Vektor ist kleiner und ressourceneffizienter, während die nach der Speicherverarbeitung erstellten Projektionen durch die Einbeziehung der Kontostanddynamik in die statischen Daten reichere Informationen liefern.
index++; if(!cMemoryAccount.Init(caAccountProjection[1].Neurons(), index, OpenCL, account_decr, window_key, 1, heads, stack_size, optimization, iBatch)) return false;
Das Speichermodul für Agentengeschäfte arbeitet auf der Ebene der einzelnen Handelsgeschäfte.
index++; if(!cMemoryAction.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Für eine effektivere politische Analyse wird ein Modul für die Querschnittsbetrachtung eingesetzt. Dieses Modul korreliert die jüngsten Aktionen des Agenten mit der Dynamik des Kontostandes und identifiziert die Beziehung zwischen Entscheidungen und den daraus resultierenden finanziellen Ergebnissen.
index++; if(!cCrossAttention.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
Zu diesem Zeitpunkt ist die Initialisierung der internen Objekte abgeschlossen. Die gesamte Methode ist auch hier abgeschlossen. Wir müssen nur das logische Ergebnis der Operationen an das aufrufende Programm zurückgeben.
Nach der Initialisierung des Risikomanagement-Objekts wird der Vorwärtsdurchlauf-Algorithmus in der Methode feedForward erstellt.
bool CNeuronMacroHFTvsRiskManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(caAccountProjection[0].getOutput() != SecondInput) { if(!caAccountProjection[0].SetOutput(SecondInput, true)) return false; }
Die Methode empfängt Zeiger auf zwei Rohdatenobjekte. Einer ist als Datenpuffer vorgesehen, dessen Inhalt in ein internes Objekt der neuronalen Schicht übertragen werden muss. Anstatt alle Daten zu kopieren, verwende ich einen effizienteren Ansatz: Der Pufferzeiger des internen Objekts wird durch den Zeiger auf den Eingangsdatenpuffer ersetzt. Dadurch wird die Verarbeitung erheblich beschleunigt.
Anschließend werden beide Informationsströme mit zusätzlichen Daten über die akkumulierte Dynamik angereichert. Die Daten werden durch spezialisierte Speichermodule geleitet, die frühere Zustände und Änderungen erfassen, sodass zeitliche Abhängigkeiten erhalten bleiben und der Kontext für eine genauere Verarbeitung erhalten bleibt.
if(!cMemoryAccount.FeedForward(caAccountProjection[0].AsObject())) return false; if(!cMemoryAction.FeedForward(NeuronOCL)) return false;
Auf der Grundlage dieser angereicherten Daten werden Projektionen des Kontostandsvektors erstellt. Diese Projektionen bieten eine umfassende Grundlage für die Analyse der Kontodynamik und die Bewertung der Auswirkungen früherer Maßnahmen auf den aktuellen Stand.
if(!caAccountProjection[1].FeedForward(cMemoryAccount.AsObject())) return false;
Sobald die erste Phase der Datenverarbeitung abgeschlossen ist, werden die Auswirkungen der Politik des Agenten auf die finanziellen Ergebnisse mit Hilfe des Kreuzaufmerksamkeits-Blocks analysiert. Durch die Korrelation zwischen den Handlungen der Agenten und den finanziellen Veränderungen wird der Zusammenhang zwischen Entscheidungen und Ergebnissen deutlich.
if(!cCrossAttention.FeedForward(cMemoryAction.AsObject(), caAccountProjection[1].getOutput())) return false;
Den letzten „Schliff“ für die Handelsentscheidung geben die übergeordneten Klassenmechanismen, die die endgültige Informationsverarbeitung vornehmen.
return CResidualConv::feedForward(cCrossAttention.AsObject());
}
Das logische Ergebnis dieser Operationen wird an das aufrufende Programm zurückgegeben, und die Methode ist beendet.
Die Backpropagation-Methoden verwenden lineare Algorithmen und bedürfen im Selbststudium wahrscheinlich keiner weiteren Erklärung. Damit ist die Überprüfung des Risikomanagementobjekts abgeschlossen. Der vollständige Code der Klasse und alle ihre Methoden sind im Anhang enthalten.
Modell der Architektur
Wir setzen unsere Arbeit an der Implementierung der Ansätze des MacroHFT-Rahmens mit MQL5 fort. In der nächsten Phase wird die Architektur des trainierbaren Modells erstellt. In diesem Fall wird ein einzelnes Akteursmodell trainiert, dessen Architektur in der Methode CreateDescriptions definiert ist.
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
Die Methode empfängt einen Zeiger auf ein dynamisches Array-Objekt zur Aufzeichnung der Architektur des zu erstellenden Modells. Und im Hauptteil der Methode prüfen wir sofort die Relevanz des empfangenen Zeigers. Falls erforderlich, erstellen wir eine neue Instanz des dynamischen Array-Objekts.
Als Nächstes erstellen wir die Beschreibung einer vollständig verknüpften Schicht, die in diesem Fall dazu dient, die rohen Eingabedaten zu empfangen, und die groß genug sein muss, um den Tensor aufzunehmen, der den analysierten Umweltzustand beschreibt.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Es ist wichtig, daran zu erinnern, dass die rohen Eingangsdaten direkt vom Terminal bezogen werden. Der Vorverarbeitungsblock für diese Daten ist als Batch-Normalisierungsschicht organisiert.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Nach der Normalisierung wird die Beschreibung des Umgebungszustands an die Schicht übergeben, die wir im Rahmen von MacroHFT erstellt haben.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFT; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Beachten Sie, dass MacroHFT für den 1-Minuten-Zeitrahmen ausgelegt ist. Dementsprechend wurde der Speicherstapel der Umweltzustände auf 120 Elemente erhöht, was einer 2-Stunden-Sequenz entspricht. Dies ermöglicht eine umfassendere Berücksichtigung der Marktdynamik und damit eine genauere Prognose und Entscheidungsfindung im Rahmen der Handelsstrategie.
Wie bereits erwähnt, konzentriert sich dieses Modul ausschließlich auf die Analyse des Umweltzustands und bietet keine Möglichkeiten zur Risikobewertung. Der nächste Schritt ist daher die Hinzufügung eines Risikomanagementmoduls.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions,AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
In diesem Fall reduzieren wir den Speicherstapel auf 15 Elemente, was die Menge der zu verarbeitenden Daten verringert und die Konzentration auf kurzfristige Dynamiken ermöglicht. Dies gewährleistet eine schnellere Reaktion auf Marktveränderungen.
Die Ausgabe des Risikomanagementmoduls sind normalisierte Werte. Um sie in den vom Agenten benötigten Aktionsraum zu übertragen, verwenden wir eine Faltungsschicht mit einer geeigneten Aktivierungsfunktion.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Nach Abschluss der Methode wird das logische Ergebnis der Operationen an das aufrufende Programm zurückgegeben.
Beachten Sie, dass wir in dieser Implementierung keinen stochastischen Kopf für den Agenten verwenden. Meiner Ansicht nach würde ihre Verwendung im Hochfrequenzhandel nur unnötiges Rauschen verursachen. Bei HFT-Strategien ist es entscheidend, Zufallsfaktoren zu minimieren, um schnelle und fundierte Reaktionen auf Marktveränderungen zu gewährleisten.
Training des Modells
In diesem Stadium haben wir die Umsetzung unserer Interpretation der von den Autoren des MacroHFT-Rahmens vorgeschlagenen Ansätze mit MQL5 abgeschlossen. Die Architektur des trainierbaren Modells wurde definiert. Nun ist es an der Zeit, das Modell zu trainieren. Zunächst müssen wir jedoch einen Trainingsdatensatz sammeln. Zuvor wurden die Modelle mit stündlichen Daten trainiert. In diesem Fall benötigen wir Informationen aus dem 1-Minuten-Zeitfenster.
Es ist zu beachten, dass die Verringerung des Zeitrahmens das Datenvolumen erhöht. Es liegt auf der Hand, dass das gleiche historische Intervall 60 Mal mehr Balken ergibt. Dies führt zu einer proportionalen Vergrößerung des Trainingsdatensatzes, wenn alle anderen Parameter gleich bleiben. Es müssen daher Maßnahmen ergriffen werden, um sie zu verringern. Es gibt zwei Ansätze: Verkürzung des Trainingszeitraums oder Reduzierung der Anzahl der im Trainingsdatensatz gespeicherten Durchgänge.
Wir haben beschlossen, einen einjährigen Trainingszeitraum beizubehalten, der meiner Meinung nach das Mindestintervall ist, das zumindest einen gewissen Einblick in die Saisonalität ermöglicht. Die Dauer eines jeden Durchgangs war jedoch auf einen Monat begrenzt. Für jeden Monat wurden zwei Durchgänge von Zufallspolicen gespeichert, was insgesamt 24 Durchgänge ergibt. Obwohl dies für ein vollständiges Training nicht ausreicht, ergibt dieses Format bereits eine Trainingsdatendatei von über 3 GB.
Diese Beschränkungen für die Erfassung des Trainingsdatensatzes waren recht streng. Es ist anzumerken, dass niemand von einer zufälligen Agentenpolitik profitable Ergebnisse erwartet. Es überrascht nicht, dass wir bei allen Durchgängen schnell die gesamte Kaution verloren haben. Um zu verhindern, dass die Tests aufgrund von Nachschussforderungen abgebrochen werden, haben wir eine Mindestkontogrenze für die Generierung von Handelsentscheidungen festgelegt. Auf diese Weise konnten wir alle Umweltzustände im Datensatz für den analysierten Zeitraum beibehalten, wenn auch ohne Belohnungen für den Handel.
Es ist auch erwähnenswert, dass die MacroHFT-Autoren ihre eigene Liste von technischen Indikatoren beim Training ihres Kryptowährungshandelsmodells verwendet haben. Diese Liste ist im Anhang des Originalartikels zu finden.
Wir haben uns dafür entschieden, die zuvor verwendete Liste der analysierten Indikatoren beizubehalten. Dies ermöglicht einen direkten Vergleich der Wirksamkeit der implementierten Lösung mit zuvor erstellten und trainierten Modellen. Die Verwendung der gleichen Indikatoren gewährleistet eine objektive Bewertung, bei der die Ergebnisse direkt miteinander verglichen werden, um die Stärken und Schwächen des neuen Modells zu ermitteln.
Die Datenerfassung für den Trainingsdatensatz erfolgt durch den Expert Advisor „...\MacroHFT\Research.mq5“. In diesem Artikel werden wir uns auf die Methode OnTick konzentrieren, in der der Kernalgorithmus für den Erhalt von Terminaldaten und die Ausführung von Handelsgeschäften implementiert ist.
void OnTick() { //--- if(!IsNewBar()) return;
Innerhalb des Methodenkörpers wird zunächst geprüft, ob ein neuer Balken eröffnet wurde. Erst dann werden weitere Operationen durchgeführt. Zunächst aktualisieren wir die Daten der analysierten technischen Indikatoren und laden die Daten der historischen Kursbewegungen.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Als Nächstes organisieren wir eine Schleife, die den Puffer bildet, der den Umgebungszustand auf der Grundlage der vom Terminal empfangenen Daten beschreibt.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Es ist anzumerken, dass die Werte der Oszillatoren ein vergleichbares Aussehen haben und die Verteilung über die Zeit stabil bleibt. Um dies zu erreichen, werden nur die Abweichungen zwischen den Indikatoren für die Preisbewegung analysiert, wodurch die Stabilität der Verteilung gewahrt bleibt und übermäßige Schwankungen, die die Analyseergebnisse verfälschen könnten, vermieden werden.
Der nächste Schritt ist die Erstellung des Vektors zur Beschreibung des Kontostandes unter Berücksichtigung der offenen Positionen und der erzielten finanziellen Ergebnisse. Zunächst sammeln wir Informationen über offene Stellen.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Anschließend erzeugen wir die Harmonische des Zeitstempels.
bTime.Clear(); double time = (double)Rates[0].time; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Erst nach Abschluss der vorbereitenden Arbeiten konsolidieren wir alle Finanzergebnisse in einem einzigen Datenpuffer.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); bAccount.AddArray(GetPointer(bTime)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
Wenn alle erforderlichen Rohdaten vorbereitet sind, prüfen wir den Kontostand. Wenn er ausreicht, führt das Modell einen Vorwärtsdurchlauf durch.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); //--- vector<float> temp; if(sState.account[0] > 50) { if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- for(int i = 0; i < NActions; i++) { float random = float(rand() / 32767.0 * 5 * min_lot - min_lot); temp[i] += random; } } else temp = vector<float>::Zeros(NActions);
Um die Umwelterkundung zu verbessern, wird der generierten Handelsentscheidung ein geringes Maß an Rauschen hinzugefügt. Während sie bei der zufälligen Ausführung von Richtlinien in der Anfangsphase scheinbar unnötig ist, erweist sie sich bei der Aktualisierung des Trainingsdatensatzes unter Verwendung einer bereits trainierten Richtlinie als nützlich.
Erreicht der Kontostand die untere Grenze, wird der Vektor für die Handelsentscheidung mit Nullen gefüllt, was bedeutet, dass keine Handelsgeschäfte getätigt werden.
Als Nächstes arbeiten wir mit dem erhaltenen Vektor für Handelsentscheidungen. Zunächst werden die Volumina der entgegengesetzten Handelsgeschäfte ausgeschlossen.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Anschließend überprüfen wir die Parameter der Kaufposition. Wenn in der Handelsentscheidung keine Kaufposition angegeben ist, prüfen wir, ob zuvor eröffnete Kaufpositionen vorhanden sind, und schließen diese.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Wenn es notwendig ist, eine Kaufposition zu eröffnen oder zu halten, bringen wir zunächst die Handelsparameter in das gewünschte Format und passen die Handelsniveaus der bereits offenen Positionen an.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
Wir passen dann das Volumen der offenen Positionen durch Aufstockung oder teilweise Schließung an.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Die Parameter von Verkaufspositionen werden auf ähnliche Weise gehandhabt.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Nach der Ausführung der Handelsgeschäfte wird ein Belohnungs-Vektor erstellt.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0;
Alle gesammelten Daten werden dann in den Datenspeicher für den Trainingsdatensatz übertragen, und wir warten auf das Ereignis, dass sich ein neuer Balken öffnet.
for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Wenn dem Trainingsdatenpuffer keine neuen Daten hinzugefügt werden können, wird das Programm initialisiert und beendet. Dies kann entweder aufgrund eines Fehlers geschehen oder wenn der Puffer vollständig gefüllt ist.
Der vollständige Code für diesen Expert Advisor ist in der Anlage enthalten.
Die eigentliche Sammlung des Trainingsdatensatzes erfolgt im MetaTrader 5 Strategy Tester durch langsame Optimierung.

Es liegt auf der Hand, dass ein Trainingsdatensatz, der mit einer begrenzten Anzahl von Durchläufen erfasst wurde, einen besonderen Ansatz für das Modelltraining erfordert. Vor allem, wenn man bedenkt, dass ein erheblicher Teil der Daten nur aus Informationen über den Zustand der Umgebung besteht, was das Lernpotenzial einschränkt. Unter solchen Bedingungen erscheint es optimal, das Modell auf der Grundlage „nahezu idealer“ Handelsentscheidungen zu trainieren. Diese Methode, die wir beim Training mehrerer neuerer Modelle verwendet haben, ermöglicht es, die Daten trotz ihres begrenzten Umfangs so effizient wie möglich zu nutzen.
Es ist auch erwähnenswert, dass das Modelltrainingsprogramm ausschließlich mit dem Trainingsdatensatz arbeitet und nicht von dem für die Datenerhebung verwendeten Zeitrahmen oder Finanzinstrument abhängt. Dies bietet einen erheblichen Vorteil, da das zuvor entwickelte Trainingsprogramm ohne Änderung des Algorithmus wiederverwendet werden kann. So können vorhandene Ressourcen und Methoden effizient genutzt werden, was Zeit und Aufwand spart, ohne die Qualität der Modellschulung zu beeinträchtigen.
Test
Wir haben umfangreiche Arbeiten durchgeführt, um unsere Interpretation der von den Autoren des MacroHFT-Rahmens vorgeschlagenen Ansätze mit MQL5 umzusetzen. Der nächste Schritt ist die Bewertung der Wirksamkeit der implementierten Methoden anhand realer historischer Daten.
Es sei darauf hingewiesen, dass die hier vorgestellte Umsetzung erheblich vom Original abweicht, auch was die Wahl der technischen Indikatoren betrifft. Dies wird sich unweigerlich auf die Ergebnisse auswirken, sodass alle Schlussfolgerungen vorläufig und spezifisch für diese Änderungen sind.
Für das Modelltraining wurden EURUSD-Daten aus dem Jahr 2024 im 1-Minuten-Zeitrahmen (M1) verwendet. Die analysierten Indikatorparameter wurden unverändert gelassen, um sich auf die Bewertung der Algorithmen und Ansätze selbst zu konzentrieren, ohne störende Auswirkungen von Indikatoreinstellungen. Das Verfahren für die Sammlung des Trainingsdatensatzes und das Training des Modells wurde oben beschrieben.
Das trainierte Modell wurde mit historischen Daten vom Januar 2025 getestet. Die Testergebnisse sind wie folgt:


Es ist anzumerken, dass das Modell während des zweiwöchigen Testzeitraums nur acht Handelsgeschäfte ausgeführt hat, was für einen Expert Advisor für den Hochfrequenzhandel zweifellos wenig ist. Auf der anderen Seite ist die Effizienz der ausgeführten Handelsgeschäfte bemerkenswert – nur ein einziges Handelsgeschäft war unrentabel. Daraus ergibt sich ein Gewinnfaktor von 2,47.

Bei genauer Betrachtung der Historie der getätigten Transaktionen lässt sich ein steigender Aufwärtstrend feststellen.
Schlussfolgerung
Wir haben das MacroHFT-Framework untersucht, das ein innovatives und vielversprechendes Tool für den Hochfrequenzhandel auf den Kryptowährungsmärkten ist. Ein wesentliches Merkmal dieses Rahmens ist seine Fähigkeit, sowohl makroökonomische Zusammenhänge als auch die Dynamik lokaler Märkte zu berücksichtigen. Diese Kombination ermöglicht eine wirksame Anpassung an sich rasch ändernde Finanzbedingungen und fundiertere Handelsentscheidungen.
Im praktischen Teil unserer Arbeit haben wir unsere Interpretation der vorgeschlagenen Ansätze mit MQL5 implementiert, wobei wir einige Anpassungen an der Funktionsweise des Frameworks vorgenommen haben. Wir haben das Modell anhand echter historischer Daten trainiert und es an Daten außerhalb des Trainingssatzes getestet. Die Zahl der getätigten Handelsgeschäfte war zwar enttäuschend und spiegelt nicht den typischen Hochfrequenzhandel wider. Dies kann auf die suboptimale Auswahl der technischen Indikatoren oder den begrenzten Trainingsdatensatz zurückzuführen sein. Die Überprüfung dieser Annahmen erfordert weitere Untersuchungen. Die Testergebnisse zeigten jedoch, dass das Modell in der Lage ist, wirklich stabile Muster zu erkennen, was zu einem hohen Anteil an profitablen Handelsgeschäften im Testdatensatz führte.
Referenzen
- MacroHFT: Memory Augmented Context-aware Reinforcement Learning On High Frequency Trading
- Andere Artikel dieser Serie
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor zum Sammeln von Beispielen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Probenahme mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor mit dem Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Modellprüfung Expert Advisor |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/16993
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.


- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.