
Klassische Strategien neu interpretieren (Teil 13): Unsere Kreuz-Strategie in neue Dimensionen führen (Teil 2)

In unserer letzten Diskussion über gleitende Durchschnitte haben wir untersucht, wie sich die mit gleitenden Durchschnitten verbundene Verzögerung minimieren lässt. Gleitende Durchschnitte sind dafür bekannt, dass sie verzögerte Signale erzeugen. Wir haben dargelegt, dass wir durch die Festlegung der Periodenlängen beider gleitender Durchschnitte auf einen gemeinsamen Wert – beispielsweise eine Periodenlänge von drei, wie in unserer vorherigen Erörterung verwendet – wesentlich reaktionsschnellere Handelssignale erhalten können. Diese Verbesserung ergibt sich aus der separaten Anwendung von gleitenden Durchschnittsindikatoren auf die Eröffnungs- und Schlusskurse, obwohl diese denselben Zeitraum betreffen. Durch die Platzierung auf unterschiedlichen Preisniveaus können wir weiterhin sicher sein, dass es zu Überschneidungen zwischen den gleitenden Durchschnitten bei Eröffnung und Schlusskurs kommt. Gleichzeitig reduziert dieser Ansatz die Verzögerung im System, indem kurze Periodenlängen verwendet werden, die in der Regel kleiner als fünf sind.
Wir haben gezeigt, dass diese Strategie gegenüber dem klassischen Ansatz des Kreuzens der gleitenden Durchschnitte Vorteile bietet. In unserer ersten Diskussion haben wir diese neue vorgeschlagene Kreuzungs-Strategie mit ihrem klassischen Gegenstück verglichen. In diesem Artikel werden wir unsere Strategie des Kreuzens der gleitenden Durchschnitte weiterentwickeln und versuchen, die inhärente Verzögerung weiter zu reduzieren, indem wir untersuchen, ob es möglich ist, die Kreuzungen vorherzusagen, bevor sie eintreten. Dies würde es uns ermöglichen, proaktiv zu handeln und schneller auf Handelsmöglichkeiten zu reagieren. Im Gegensatz zu typischen Marktteilnehmern, die auf eine Bestätigung warten und erst reagieren, wenn das Kreuzen offensichtlich ist, wollen wir statistische Modelle entwickeln, Kreuzungen im Voraus erkennen können, damit wir unsere Konten entsprechend positionieren können, bevor sich die Bewegungen entfalten.
Obwohl es schwierig sein kann, Handelssignale inmitten des Rauschens des Marktes zu erkennen, können mehrere datenwissenschaftliche Prinzipien dazu beitragen, unsere Strategie zu stärken. Beispielsweise verweisen wir auf eine Präsentation des Teams des NASA Jet Propulsion Laboratory am California Institute of Technology (Caltech), die wertvolle Einblicke bietet. Der Link zur Präsentation ist hier verfügbar. Diese Präsentation konzentrierte sich auf Big Data und stellte ein für unsere Diskussion relevantes Grundprinzip vor. Interessierte Leser werden gebeten, sich die Folien selbst anzusehen. Kurz gesagt besagt dieses Prinzip, dass bestimmte schwierige Probleme in der Datenwissenschaft leichter zu lösen sind, wenn sie in höherdimensionale Räume projiziert werden. Zur Erleichterung für den Leser haben wir einen Auszug aus der Originalpräsentation, der für unsere Diskussion relevant ist, in Abbildung 1 unten aufgenommen.
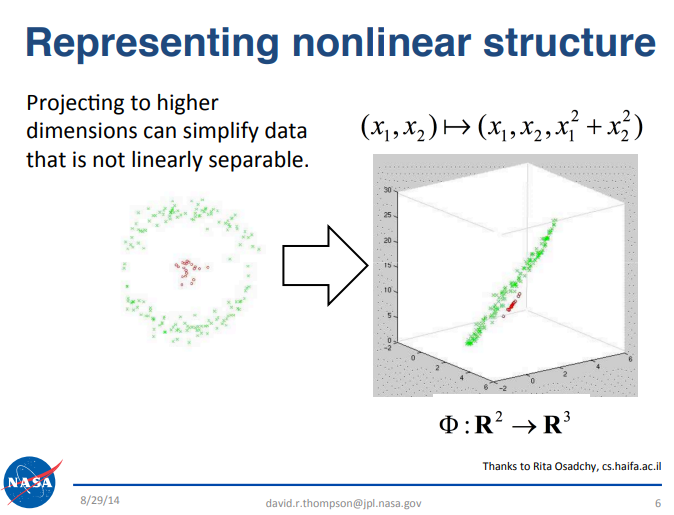
Abbildung 1: Die obige Folie war ursprünglich Teil der öffentlich zugänglichen Präsentation „Big Data Analytics“, die vom NASA JPL-Team an der Caltech University im September 2014 gehalten wurde.
Betrachten wir beispielsweise einen Datensatz mit drei Merkmalen, bei dem das Ziel darin besteht, steigende und fallende Markttage zu klassifizieren. In diesem niedrigen dreidimensionalen Raum kann es schwierig sein, eine hohe Klassifizierungsgenauigkeit zu erreichen. Durch die Projektion des Datensatzes in höhere Dimensionen kann sich die Leistung jedoch verbessern, da einige Probleme in höherdimensionalen Merkmalsräumen besser trennbar werden. Obwohl maschinelles Lernen nicht in allen Fällen Erfolg garantiert, führt dieser Ansatz oft zu besseren Ergebnissen und ist oft einen Versuch wert.
Dieses Prinzip steht im Gegensatz zu unseren früheren Ausführungen in unserer Artikelserie, beispielsweise „Selbstoptimierende Expert Advisors in MQL5“, in der wir die Vorteile von Techniken zur Dimensionsreduktion wie UMAP untersucht haben, um Datensätze von 30 Merkmalen auf vier zu reduzieren. In der Regel konzentrieren wir uns darauf, die Dimensionen zu reduzieren, um Modelle zu vereinfachen und die Generalisierung zu verbessern. Heute werden wir jedoch den umgekehrten Ansatz verfolgen und die Dimensionalität unseres Datensatzes bewusst erhöhen, da dies einen praktischen Nutzen haben kann, den wir demonstrieren werden.
In diesem Artikel werden wir eine manuell entwickelte Methode zur Generierung vieler neuer Merkmals-Spalten ableiten. In zukünftigen Diskussionen werden wir mit flexibleren algorithmischen Techniken zur Merkmalsgenerierung arbeiten.
Erste Schritte in MQL5
Zunächst erstellen wir ein Skript, um alle erforderlichen Daten aus unserem MetaTrader 5-Terminal abzurufen. Wir beginnen damit, bestimmte für unsere Diskussion relevante Konstanten festzulegen. Beispielsweise wird der Zeitraum für alle gleitenden Durchschnitte auf einen festen Wert festgelegt, und wir werden in dieser Diskussion durchgehend einfache gleitende Durchschnitte verwenden.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 2 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define HORIZON 5 //--- Forecast horizon
Darüber hinaus werden wir globale Variablen wie Handler und Puffer für die gleitenden Durchschnittsindikatoren definieren.
//--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; //--- File name string file_name = Symbol() + " Market Data As Series Moving Average.csv"; //--- Amount of data requested input int size = 3000;
Als Nächstes definieren wir den Hauptteil unseres Skripts. Wenn das Skript ausgeführt wird, initialisieren wir unsere Handler für gleitende Durchschnitte und kopieren dann die Werte aus diesen Handlern in die zugehörigen Puffer. Bei der Vorbereitung des Schreibvorgangs der Daten in eine Datei ist zu beachten, dass zahlreiche Spalten ausgefüllt werden müssen. Die ersten acht Spalten sind Standard: Eröffnungskurs, Höchstkurs, Tiefstkurs, Schlusskurs und die entsprechenden gleitenden Durchschnitte. Darüber hinaus fügen wir Spalten hinzu, die das Wachstum innerhalb jedes Preis-Feeds darstellen.
Darüber hinaus gibt es Spalten, die der Berechnung der relativen Veränderungen zwischen verschiedenen Preisniveaus dienen. Beispielsweise berechnen wir nicht nur die Veränderung des Eröffnungskurses im Vergleich zu seinem historischen Wert, sondern auch die Veränderung des Eröffnungskurses im Verhältnis zum Schlusskurs, die Veränderung des Eröffnungskurses im Verhältnis zum Tiefstkurs und so weiter. Die gleichen Berechnungen werden für die gleitenden Durchschnitte wiederholt. Insgesamt erzeugt dieser Prozess 40 Spalten in unserem Datensatz. Schließlich speichern wir die tatsächlichen Werte, die wir schreiben möchten, und schließen dann den Datei-Handler.
//+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close", //--- MA OHLC "True MA C", "True MA O", "True MA H", "True MA L", //--- Growth in OHLC "Diff Open", "Diff High", "Diff Low", "Diff Close", //--- Growth in MA OHLC "Diff MA Close 2", "Diff MA Open 2", "Diff MA High 2", "Diff MA Low 2", //--- Grwoth between channels "O - C", "Delta O - C", "O - L", "Delta O - L", "O - H", "Delta O - H", "H - L", "Delta H - L", "C - H", "Delta C - H", "C - L", "Delta C - L", //--- Grwoth between MA channels "MA O - C", "MA Delta O - C", "MA O - L", "MA Delta O - L", "MA O - H", "MA Delta O - H", "MA H - L", "MA Delta H - L", "MA C - H", "MA Delta C - H", "MA C - L", "MA Delta C - L" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_reading[i], ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,i) - iOpen(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,(i + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,(i + HORIZON)), //--- Growth in MA OHLC ma_reading[i] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_o_reading[(i + HORIZON)], ma_h_reading[i] - ma_h_reading[(i + HORIZON)], ma_l_reading[i] - ma_l_reading[(i + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,i) - iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iHigh(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,i + HORIZON), iClose(_Symbol,PERIOD_CURRENT,i) - iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,i + HORIZON), //--- Growth between moving average channels ma_o_reading[i] - ma_reading[i], ma_o_reading[(i + HORIZON)] - ma_reading[(i + HORIZON)], ma_o_reading[i] - ma_l_reading[i], ma_o_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_o_reading[i] - ma_h_reading[i], ma_o_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_h_reading[i] - ma_l_reading[i], ma_h_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)], ma_reading[i] - ma_h_reading[i], ma_reading[(i + HORIZON)] - ma_h_reading[(i + HORIZON)], ma_reading[i] - ma_l_reading[i], ma_reading[(i + HORIZON)] - ma_l_reading[(i + HORIZON)] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Analyse unserer Daten in Python
Nachdem Sie nun Ihr Skript auf dem Terminal bereitgestellt und die erforderlichen Daten extrahiert haben, können wir mit der Analyse und Verarbeitung der Daten beginnen. Zunächst laden wir die Standardbibliotheken für die numerische Analyse.
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Als Nächstes lesen wir die Datensätze ein. Wie Sie feststellen werden, ist der Datensatz sehr breit, sodass einige Spalten nicht vollständig angezeigt werden können.
data = pd.read_csv("C:\\Users\\Westwood\\AppData\\Roaming\\MetaQuotes\\Terminal\\D0E8209F77C8CF37AD8BF550E51FF075\\MQL5\\Files\\EURUSD Market Data As Series Moving Average.csv")
data 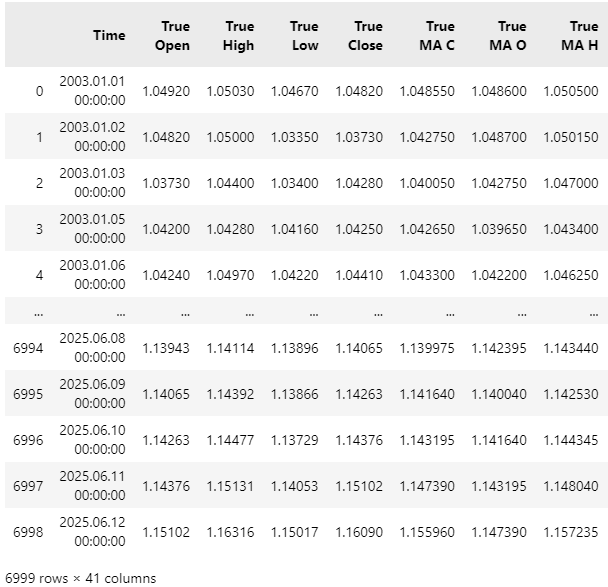
Abbildung 2: Visualisierung der Daten, die wir von unserem MetaTrader 5-Terminal abgerufen haben.
Anschließend definieren wir unsere Zielvariable. Denken Sie daran, dass in diesem Beispiel das Ziel das Kreuzen zwischen gleitenden Durchschnitten ist. Eine einfache Methode, um dieses Kreuzen zu verfolgen, besteht darin, den Mittelpunkt zwischen den beiden gleitenden Durchschnitten zu beobachten. Indem wir beobachten, ob der Mittelpunkt gestiegen oder gefallen ist, erfassen wir effektiv dieselben Informationen für unsere statistischen Modelle.
HORIZON = 10 #Classical Target data['Target'] = 0 #High Low Mid Point Target data['Target 2'] = 0 #Open Close Mid Point Target data['Target 3'] = 0 data.loc[data['True Close'].shift(-HORIZON) > data['True Close'],'Target'] = 1 #The Mid Point Between The High And The Low Moving Average data.loc[((data['True MA H'].shift(-HORIZON) + data['True MA L'].shift(-HORIZON)) / 2) > ((data['True MA H'] + data['True MA L']) / 2),'Target 2'] = 1 #The Open And Close Mid Point data.loc[((data['True MA O'].shift(-HORIZON) + data['True MA C'].shift(-HORIZON)) / 2) > ((data['True MA O'] + data['True MA C']) / 2),'Target 3'] = 1 data = data.iloc[:-HORIZON,:]
Bevor wir fortfahren, möchte ich kurz demonstrieren, welchen Wert die Projektion von Datensätzen in höhere Dimensionen hat. Dies dient als einfacher Beweis für Leser, die mit diesem Prinzip möglicherweise nicht vertraut sind, und stellt sicher, dass wir alle auf dem gleichen Stand sind. Wir beginnen damit, eine Kopie des ursprünglichen Datensatzes zu erstellen, die nur die vier Standardspalten enthält: Eröffnungskurs, Höchstkurs, Tiefstkurs und Schlusskurs. Anschließend berechnen wir unsere Zielvariable anhand dieses reduzierten Datensatzes neu.
#Copy the dataset X = data.iloc[:,:5].copy() X['Target'] = data['True Close'].shift(-HORIZON) - data['True Close'] X.dropna(inplace=True)
Als Nächstes definieren wir eine Funktion, die einen Datensatz entgegennimmt und eine beliebige Anzahl von Spalten hinzufügt, die mit Nullen gefüllt sind. Wenn wir diese Funktion beispielsweise mit unserer Datensatzkopie aufrufen und fünf Spalten angeben, gibt sie den Datensatz mit fünf zusätzlichen Spalten zurück, die jeweils mit Nullen gefüllt sind.
def fill_zeros(f_data,f_n): #Copy the original data res = f_data.copy() #We want to keep the target at the end t = 'Target' v = res.pop('Target') #Add columns of zeros for i in np.arange(f_n): name = str(i) + ' Col' res[name] = 0 #Place the target back res[t]= v #Return the new dataframe return(res)
Anschließend führen wir einen einfachen Test durch, indem wir unser Modell mit einer zunehmenden Anzahl von mit Nullen gefüllten Spalten kreuzvalidieren und die Auswirkungen auf den Kreuzvalidierungsfehler beobachten. Beachten Sie, dass die resultierende Kurve nicht glatt ist, was auf eine Variabilität des Fehlers bei zunehmender Dimensionierung hinweist.
Es ist jedoch klar, dass die Kurve neue Tiefststände erreicht, die sie zuvor im Diagramm nicht erreichen konnte. Zu Beginn beobachten wir den Fehlergrad unseres Modells, wenn keine zusätzlichen mit Nullen gefüllten Spalten vorhanden sind. Mit zunehmender Anzahl von Nullspalten steigt der Fehler in der Regel sprunghaft an und fällt dann auf neue, bisher nicht erreichte Tiefstwerte. Diese Beobachtung sollte den Leser dazu veranlassen, sich zu fragen, warum sich die Leistung des Modells verbessert, obwohl keine zusätzlichen Informationen bereitgestellt werden. Denken Sie daran, dass die Nullspalten keine für das Modell nützlichen Daten enthalten.
#Load our libraries from sklearn.neural_network import MLPRegressor from sklearn.model_selection import cross_val_score,TimeSeriesSplit tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) EPOCHS = 50 #Observe what happens to our error levels as we increase the number of columns in the dataset res = [] for i in np.arange(EPOCHS): #Fetch new data with addtional columns of zeros new_data = fill_zeros(X,(1+i)) #Record the new error res.append(np.mean(np.abs(cross_val_score(MLPRegressor(hidden_layer_sizes=(new_data.iloc[:,1:-1].shape[1],2,50,100),random_state=0,shuffle=False),X.iloc[:,1:-1],X.iloc[:,-1],cv=tscv,n_jobs=-1)))) plt.plot(res,color='black') plt.grid() plt.ylabel('RMSE Error') plt.xlabel('Additional Columns of Zero') plt.title('Our Error Levels Can Fall Without Any New Information')
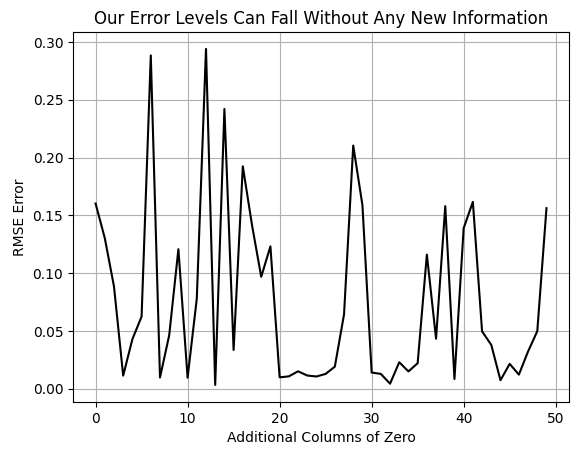
Abbildung 3: Die Fehlerquoten unseres Modells sinken, obwohl wir keine zusätzlichen Informationen bereitstellen.
Es gibt mehrere plausible Erklärungen für dieses Phänomen. Für die Zwecke dieser Diskussion werden wir den Standpunkt vertreten, dass eine zunehmende Dimensionalität einen intrinsischen Wert hat. Wir interpretieren dies als Beweis für den Nutzen der Projektion von Daten in höherdimensionale Räume. Obwohl es durchaus andere plausible Erklärungen gibt, dient diese Beobachtung für unsere Zwecke als Motivation für die 32 handgefertigten Merkmals-Spalten, die wir für unseren Datensatz erstellt haben. Wir glauben, dass wir durch die Erhöhung der Anzahl zusätzlicher Spalten erneut neue Tiefstwerte bei den Fehlern erreichen können. Dieses Mal wollen wir jedoch keine Nullen hinzufügen, sondern sinnvolle Informationen.
Nachdem wir unsere Motivation festgelegt haben, fahren wir nun fort, unsere Eingabe- und Ausgabespalten zu identifizieren. Zunächst sammeln wir alle Eingabespalten und speichern sie in einer Variablen namens X.
X = data.iloc[:,1:-4].columns
Als Nächstes listen wir unsere Zielvariablen auf.
y2 = data['Target 2']
Wir müssen auch eine Funktion definieren, die eine neue Instanz unseres statistischen Modells zurückgibt.
return(RandomForestClassifier(random_state=0,n_estimators=500,max_depth=3,min_samples_leaf=20))
Anschließend schließen wir alle Daten aus, die sich mit dem Backtest-Zeitraum überschneiden, da wir das Modell nicht an alle verfügbaren Daten überanpassen möchten. Es ist wichtig, einige Daten ausschließlich für Testzwecke zu reservieren. Anschließend standardisieren und skalieren wir unseren Datensatz, indem wir die Spaltenmittelwerte subtrahieren und durch die Spaltenstandardabweichungen für jede der 40 Spalten dividieren. Dieser Prozess liefert einen skalierten Datensatz.
data = data.iloc[:-(365*2),:] Z = pd.DataFrame(columns=['Z1','Z2']) Z['Z1'] = data.loc[:,X].mean() Z['Z2'] = data.loc[:,X].std() data.loc[:,X] = (data.loc[:,X] - data.loc[:,X].mean()) / data.loc[:,X].std()
Schließlich passen wir unser Modell an alle Trainingsdaten an, bevor wir es im ONNX-Format exportieren, damit es in MQL5 verwendet werden kann.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.ensemble import GradientBoostingRegressor model = GradientBoostingRegressor(random_state=0,max_depth=3) model.fit(data.loc[:,X],data.loc[:,'Target 2']) initial_types = [("FLOAT INPUT",FloatTensorType([1,len(X)]))] model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) onnx.save(model_proto,"EURUSD GBR PRICE D1.onnx")
Alles zusammenbringen
Wir sind nun bereit, mit der Zusammenstellung unseres Expert Advisors zu beginnen. Unsere erste Aufgabe besteht darin, globale Konstanten zu definieren, die nicht geändert werden sollen. Beachten Sie, dass viele dieser Definitionen mit denen übereinstimmen, die zuvor in unserem Skript zum Abrufen von Daten festgelegt wurden. Insbesondere bleiben die Periodenlänge und der Typ des gleitenden Durchschnitts jeweils auf denselben Werten fixiert. Darüber hinaus haben wir die Dauer für das Halten jeder Position sowie den Zeitrahmen, in dem wir handeln werden, festgelegt.
//+------------------------------------------------------------------+ //| System constants | //+------------------------------------------------------------------+ //--- Define our moving average indicator #define MA_PERIOD 2 //Moving Average Period #define MA_TYPE MODE_SMA //Type of moving average we have #define HORIZON 10 //Forecast horizon #define TF PERIOD_D1
Als Nächstes deklarieren wir wichtige globale Variablen. Beispielsweise müssen die Z1- und Z2-Werte, die zur Standardisierung und Skalierung unseres Datensatzes verwendet werden, innerhalb des Expert Advisors beibehalten werden. Wir benötigen außerdem globale Variablen für die Handler des gleitenden Durchschnitts und die entsprechenden Puffer.
//+------------------------------------------------------------------+ //| Global definitions | //+------------------------------------------------------------------+ float Z1[] = { 1.23933432e+00, 1.24403263e+00, 1.23474846e+00, 1.23936216e+00, 1.23935910e+00, 1.23933128e+00, 1.24402971e+00, 1.23474522e+00, 3.83991053e-05, 3.60920275e-05, 3.66240614e-05, 3.55759706e-05, 3.68749001e-05, 3.98194600e-05, 3.78958300e-05, 3.79070139e-05, -2.78415082e-05, -3.06646429e-05, 4.58586036e-03, 4.58408532e-03, -4.69831123e-03, -4.70061831e-03, 9.28417159e-03, 9.28470363e-03, -4.67046972e-03, -4.66995367e-03, 4.61370187e-03, 4.61474996e-03, -2.78151462e-05, -3.07597060e-05, 4.58606247e-03, 4.58415002e-03, -4.69842067e-03, -4.70034430e-03, 9.28448314e-03, 9.28449433e-03, -4.67060553e-03, -4.66958460e-03, 4.61387762e-03, 4.61490973e-03 }; float Z2[]= { 0.12576155, 0.12640182, 0.125071, 0.12572605, 0.12568469, 0.125719, 0.12636385, 0.12503521, 0.0150256, 0.01494947, 0.01478075, 0.01493629, 0.0141562, 0.01423137, 0.01419596, 0.01404453, 0.00669432, 0.0066951, 0.00482275, 0.004823, 0.00493041, 0.00493002, 0.0063063, 0.00630607, 0.0048614, 0.0048616, 0.00471017, 0.0047104, 0.00471147, 0.00471252, 0.00361188, 0.00361259, 0.00371563, 0.00371488, 0.00513505, 0.00513498, 0.0037117, 0.0037125, 0.00353196, 0.00353191 }; //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[]; int fetch = HORIZON * 2; int timer = 0; int state = 0;
Darüber hinaus laden wir unser ONNX-Modell als Ressource in den Expert Advisor.
//+------------------------------------------------------------------+ //| Resources | //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| DISCLAIMER | //| This ONNX model was trained from 1 January 2003 until 29 January | //| 2023. For reliable results, ensure that all back tests are done | //| beyond the model's training period. | //+------------------------------------------------------------------+ #resource "\\Files\\MA Approximation\\EURUSD GBR MA D1.onnx" as const uchar onnx_proto[];
Wir werden auch die erforderlichen Bibliotheken und Abhängigkeiten laden. Beispielsweise gibt es eine spezielle MQL5-Bibliothek für die Verwaltung von Handelsgeschäften sowie eine im Laufe der Zeit entwickelte nutzerdefinierte Bibliothek für die Verarbeitung von ONNX-Modellen und den Abruf von Handelsinformationen.
//+------------------------------------------------------------------+ //| Dependencies | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\ONNX\ONNXFloat.mqh> #include <VolatilityDoctor\Time\Time.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; ONNXFloat *onnx_handler; Time *time_handler; TradeInfo *trade_handler;
Während der Initialisierungssequenz des Expert Advisors laden wir alle diese Bibliotheken und technischen Indikatoren.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- onnx_handler = new ONNXFloat(onnx_proto); time_handler = new Time(Symbol(),TF); trade_handler = new TradeInfo(Symbol(),TF); Print("Onnx Handler Pointer: ",onnx_handler); onnx_handler.DefineOnnxInputShape(0,1,40); onnx_handler.DefineOnnxOutputShape(0,1,1); //---Setup our technical indicators ma_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,TF,MA_PERIOD,0,MA_TYPE,PRICE_LOW); //--- return(INIT_SUCCEEDED); }
Um eine sichere Speicherverwaltung zu gewährleisten, werden wir alle dynamisch erstellten Objekte löschen und technische Indikatoren freigeben, die nicht mehr verwendet werden.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- IndicatorRelease(ma_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_h_handle); IndicatorRelease(ma_l_handle); delete time_handler; delete trade_handler; delete onnx_handler; }
Sobald neue Preisaktualisierungen eingehen, überprüfen wir, ob sich eine neue Kerze gebildet hat. Wenn ja, werden wir unsere technischen Indikatoren aktualisieren, bevor wir nach Handelssignalen suchen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(time_handler.NewCandle()) { update(); check_signal(); } }
Die Methode zur Aktualisierung der technischen Indikatoren ist wie folgt: Zunächst kopieren wir alle Indikatorwerte in die zugehörigen Puffer. Dadurch wird der Eingabevektor für unser ONNX-Modell vorbereitet. Das Modell akzeptiert denselben Satz von 40 Eingaben, der auch in der vorherigen Aufgabe verwendet wurde. Bevor wir diese Eingaben an das Modell weitergeben, standardisieren und skalieren wir sie. Das Modell generiert dann eine Vorhersage.
//+------------------------------------------------------------------+ //| Update our technical data | //+------------------------------------------------------------------+ void update(void) { //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); vectorf model_input_vector = { //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0), iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0), //--- MA OHLC ma_reading[0], ma_o_reading[0], ma_h_reading[0], ma_l_reading[0], //--- Growth in OHLC iOpen(_Symbol,PERIOD_CURRENT,0) - iOpen(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iHigh(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iLow(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), iClose(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,(0 + HORIZON)), //--- Growth in MA OHLC ma_reading[0] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_o_reading[(0 + HORIZON)], ma_h_reading[0] - ma_h_reading[(0 + HORIZON)], ma_l_reading[0] - ma_l_reading[(0 + HORIZON)], //--- Growth between channels iOpen(_Symbol,PERIOD_CURRENT,0) - iClose(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iOpen(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iOpen(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iHigh(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iHigh(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iHigh(_Symbol,PERIOD_CURRENT,0 + HORIZON), iClose(_Symbol,PERIOD_CURRENT,0) - iLow(_Symbol,PERIOD_CURRENT,0), iClose(_Symbol,PERIOD_CURRENT,0 + HORIZON) - iLow(_Symbol,PERIOD_CURRENT,0 + HORIZON), //--- Growth between moving average channels ma_o_reading[0] - ma_reading[0], ma_o_reading[(0 + HORIZON)] - ma_reading[(0 + HORIZON)], ma_o_reading[0] - ma_l_reading[0], ma_o_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_o_reading[0] - ma_h_reading[0], ma_o_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_h_reading[0] - ma_l_reading[0], ma_h_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)], ma_reading[0] - ma_h_reading[0], ma_reading[(0 + HORIZON)] - ma_h_reading[(0 + HORIZON)], ma_reading[0] - ma_l_reading[0], ma_reading[(0 + HORIZON)] - ma_l_reading[(0 + HORIZON)] }; for(int i =0;i<40;i++) { model_input_vector[i] = ((model_input_vector[i] - Z1[i]) / Z2[i]); } onnx_handler.Predict(model_input_vector); }
Unsere Signalprüfungsfunktion funktioniert wie erwartet. Wir beginnen damit, den Timer zurückzusetzen, wenn derzeit keine Positionen offen sind, wodurch der Systemstatus zurückgesetzt wird. Wenn das ONNX-Modell eine steigende Preisentwicklung prognostiziert, werden wir eine Kaufposition eingehen; wenn es eine fallende Preisentwicklung prognostiziert, werden wir eine Verkaufsposition eingehen. Beachten Sie, dass Aufwärts- oder Abwärtssignale den vom Modell ausgegebenen Klassenwahrscheinlichkeiten entsprechen: Wahrscheinlichkeiten größer als 0,5 deuten auf ein zu erwartetes Ansteigen hin, während Wahrscheinlichkeiten kleiner als 0,5 auf ein zu erwarteten Abstieg hin.
Zusätzlich zum Signal des ONNX-Modells suchen wir nach einer Bestätigung durch unser gleitendes Durchschnitts-Kreuzungs-Muster. Wenn eine Position bereits offen ist, verfolgen wir den Timer, und sobald er sich der vordefinierten Positionslaufzeit nähert, schließen wir alle offenen Positionen und starten den Zyklus neu.
//+------------------------------------------------------------------+ //| Check if we have oppurtunities to trade | //+------------------------------------------------------------------+ void check_signal(void) { if(PositionsTotal() == 0) { timer = 0; state = 0; if(onnx_handler.GetPrediction() > 0.5 { state =1; Trade.Buy(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetAsk(),0,0,""); } else if(onnx_handler.GetPrediction() < 0.5 && ma_reading[0] < ma_o_reading[0]) { state =-1; Trade.Sell(trade_handler.MinVolume(),trade_handler.GetSymbol(),trade_handler.GetBid(),0,0,""); } } else { timer++; if(timer >= HORIZON) Trade.PositionClose(Symbol()); } }
Denken Sie daran, alle Systemdefinitionen immer zu löschen.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE #undef TF
Wir sind nun bereit, unser System anhand von Daten zu testen, die wir während des Trainings vor ihm verborgen haben. Wir wählen alle Daten aus, die außerhalb unseres Trainingszeitraums liegen. Denken Sie daran, dass unser Trainingszeitraum am 29. Januar 2023 endete.
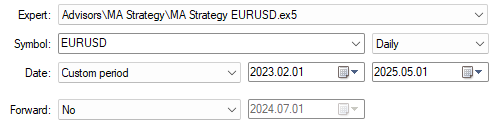
Abbildung 4: Unsere Backtest-Tage liegen immer außerhalb des Trainingszeitraums, den wir dem Modell gezeigt haben.
Wählen Sie unbedingt „Zufällige Verzögerung“, um die Unvorhersehbarkeit realer Handelssitzungen realistisch zu simulieren.
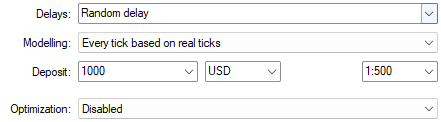
Abbildung 5: Wählen Sie „Zufällige Verzögerung“ für die robustesten verfügbaren Backtest-Einstellungen.
Unsere Strategie führte zu der in Abbildung 6 dargestellten Kapitalkurve. Wir freuen uns, dass wir auch bei der Überprüfung unseres Modells mit Daten, die es zuvor noch nicht gesehen hat, einen positiven Aufwärtstrend aufrechterhalten konnten. Es ist möglich, dass unser Modell durch das Training mit einem hochauflösenden Bild des Marktes unter Verwendung der von uns generierten 40 Spalten besser auf Bedingungen verallgemeinern kann, für die es nicht trainiert wurde.
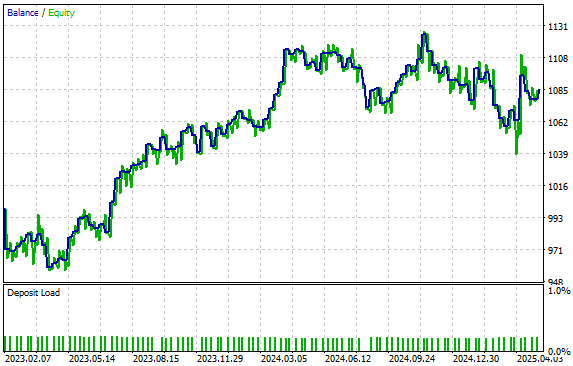
Abbildung 6: Visualisierung der durch unser statistisches Modell erzeugten Kapitalkurve.
Schließlich können wir jederzeit eine detaillierte Zusammenfassung der Performance unserer Strategie einsehen. Wir können beobachten, dass 52,9 % der von unserer Strategie getätigten Trades profitabel waren und dass unser durchschnittlicher Gewinn im Allgemeinen größer sein dürfte als unser durchschnittlicher Verlust. Dies sind ermutigende Statistiken, die zeigen, dass es sich lohnt, sich Zeit zu nehmen, um detaillierte Merkmale in Ihre Datensätze einzubauen. Auch wenn dies ein mühsamer Prozess sein kann, lohnt sich der zusätzliche Aufwand immer, wenn er sich auszahlt.
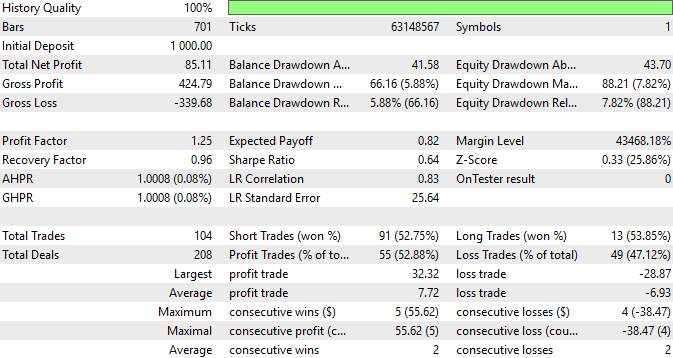
Abbildung 7: Eine ausführliche Zusammenfassung der von unserer Handelsanwendung erzielten Leistung.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass dieser Artikel dem Leser zahlreiche praktische Einblicke vermittelt hat, wie etablierte Strategien neu gedacht und mit neuen Fähigkeiten angereichert werden können.
Durch die Nutzung bekannter Prinzipien der Datenwissenschaft, wie beispielsweise der Fähigkeit von Modellen, in höherdimensionalen Räumen manchmal bessere Leistungen zu erbringen, konnten wir die Verzögerung in unseren gleitenden Durchschnitt-Kreuzungs-Strategien konsequent verringern. Dies wurde durch die manuelle Erstellung unserer eigenen umfangreichen Datensätze erreicht, wodurch unser Modell ein hochauflösendes Verständnis des Marktes erlangen konnte. Obwohl diese datenwissenschaftlichen Prinzipien gut erforscht sind, ist es entscheidend, die Erwartungen zu steuern.
Für den Leser ist es wichtig zu beachten, dass die Erweiterung von Datensätzen in höhere Dimensionen nicht immer eine bessere Leistung garantiert. Vielmehr sollten Leser verstehen, dass es immer von Vorteil ist, zu untersuchen, ob die Projektion von Datensätzen in höhere Dimensionen zu Verbesserungen führen kann. Dieser Ansatz bietet keine Garantien, aber es lohnt sich immer, ihn zu prüfen. Der Leser hat auch gelernt, dass die mit technischen Indikatoren verbundene Verzögerung durch kritisches Denken und Kreativität in Frage gestellt und wirksam angegangen werden kann. Das Potenzial des MetaTrader 5-Terminals scheint enorm zu sein.
| Dateiname | Beschreibung der Datei |
|---|---|
| EURUSD GBR MA D1.onnx | Das ONNX-Modell, das wir gemeinsam unter Verwendung unseres hochdimensionalen Spaltendatensatzes erstellt haben. |
| Proof of Case Article.ipynb | Das Jupyter Notebook, das wir gemeinsam geschrieben haben, um die Vorteile der Projektion von Daten in höhere Dimensionen zu demonstrieren. |
| MA Strategy EURUSD.ex5 | Eine kompilierte Version der Handelsanwendung, die wir entwickelt haben, um unseren handgefertigten Datensatz zu nutzen. |
| Fetch Data MA.mq5 | Das MQL5-Skript, das wir geschrieben haben, um unseren hochdimensionalen Datensatz abzurufen und in CSV zu schreiben. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/18525
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.