
El análisis volumétrico de redes neuronales como clave de las tendencias futuras

En una época en la que todo en el trading está cada vez más automatizado, nos conviene recordar a los antiguos tráders, muchos de los cuales nos enseñan que el volumen es la raíz de todo. De hecho, resultaría muy útil e interesante introducir tanto el análisis técnico como el análisis volumétrico como características en el aprendizaje automático. De interpretarse correctamente, quizá nos ofrezcan un resultados. En este artículo, evaluaremos un enfoque que analiza el volumen comercial y las características basadas en el volumen utilizando la arquitectura LSTM.
Nuestro sistema analizará las anomalías en los volúmenes y pronosticará los movimientos futuros de los precios. Las características clave del sistema son la detección de volúmenes anómalos, la clusterización de volúmenes y el entrenamiento del modelo directamente a través de Python + MetaTrader 5.
También realizaremos backtesting complejo con la visualización posterior de los resultados. El modelo demuestra una especial eficacia en el marco temporal horario de la bolsa rusa, lo cual confirman los resultados de las pruebas realizadas con datos históricos de las acciones de Sberbank durante el último año. En este artículo analizaremos con detalle la arquitectura del sistema, sus principios de funcionamiento y los resultados prácticos de su aplicación.
Análisis sintáctico del código: de los datos a las predicciones
Hoy vamos a profundizar en la materia e intentaremos crear un sistema que entienda realmente lo que ocurre con los volúmenes en este momento. Empezaremos por algo sencillo: la obtención y el procesamiento de datos. Por un lado, no es nada complicado: descargamos los datos y trabajamos con ellos..... Pero el diablo, como siempre, está en los detalles.
La fuente de datos: profundizamos en la materia
Entonces, aquí tenemos nuestra función de carga de datos:
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"MT5 data request: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
Parece de lo más sencilla. Utilizamos deliberadamente copy_rates_range en lugar de copy_rates_from, más sencillo. Necesitamos esto para no perder periodos cero al tratar con instrumentos ilíquidos.
Luego empezamos a trabajar con signos e indicadores.
Preprocesamiento: el arte de preparar los datos
No vamos a atormentarnos demasiado con la elección de las características: nos centraremos en algunas de las más evidentes.
def preprocess_data(self, df): # Basic volume indicators df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # ML indicators df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
La selección de las características resulta semejante a la afinación del sonido de una orquesta. Cada característica tiene su propio papel y un sonido específico en la sinfonía de los datos. Vamos a analizar nuestro conjunto básico.
El primero es el más sencillo: tomaremos una media móvil de volumen. La media de volumen con un periodo de 5 capta las fluctuaciones más pequeñas, mientras que la de 20 puntos reacciona a tendencias de volumen mucho más potentes.
También resulta interesante la característica en forma de relación entre el volumen y su media. Cuando se produce un salto brusco en el futuro, es muy habitual que ocurra un fuerte impulso de los precios.
También observaremos el impulso del precio y el impulso del volumen en las últimas 24 barras.
Existe una característica aún más interesante denominada volatilidad del volumen. Esto es lo que yo llamaría un indicador de los nervios del mercado. El aumento de la volatilidad del volumen, puede indicar potentes inyecciones en el mercado por parte de tráders sólidos.
Nuestro modelo también considera la correlación precio-volumen. Al final, nos aseguraremos de observar todas estas señales en directo visualizando nuestros indicadores recién creados.
Cuellos de botella en el rendimiento
Para no sobrecargar el sistema, podemos aplicar el procesamiento por lotes de datos y la computación paralela, es decir, dividiremos los datos en trozos pequeños y los procesaremos paralelamente.
Esta sencilla técnica acelerará varias veces el procesamiento de datos, y también nos ayudará a evitar problemas de fugas de memoria en grandes cantidades de datos.
En la siguiente parte del artículo le contaré la parte más interesante: cómo detecta el sistema los volúmenes anormales y qué ocurre a continuación.
En busca de "cisnes negros": cómo reconocer volúmenes anómalos
Obviamente, todos hemos oído hablar de lo que son los volúmenes anormales y de cómo verlos en un gráfico. Tal vez, cualquier tráder con experiencia sea capaz de discernirlos. Pero he aquí el problema: ¿cómo introducir esto en el código? ¿Cómo podemos formalizar la lógica para encontrar dichos volúmenes?
A la caza de anomalías
Tras varios experimentos, mi investigación en este campo se decantó por el método del Isolation Forest. ¿Por qué precisamente este método?, se preguntará el lector. Bueno, los métodos clásicos como la puntuación z o la estimación del percentil pueden pasar por alto una anomalía local, pequeña, pero lo que importa no son los valores absolutos o porcentuales, sino los volúmenes que sobresalen... y esos se encuentran fuera del contexto general.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
Una solución aún mejor sería ajustar todos los parámetros del modelo a algoritmos como el BGA. Hemos fijado el valor en el 0,05 recomendado en los manuales, que se corresponde con un 5% de anomalías. Pero el mercado real es mucho más ruidoso de lo que cabría imaginar. Así que hemos elevado el listón un poco, y seguirá resultando útil ver las anomalías de primera mano, agrupadas con los movimientos de los precios (volveremos sobre este tema más adelante),
Clusterización: búsqueda de patrones
Las anomalías por sí solas no bastan para realizar una buena previsión. Necesitamos además la clusterización de volúmenes. Nos centraremos en esta variante de clusterización:
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
Las características seleccionadas para la clusterización son bastante sencillas. Creo que sería extraño agrupar solo los volúmenes reales en sí, de lo contrario ¿para qué creamos nuestros signos e indicadores? La otra cuestión es que el número de señales, así como los indicadores de volumen, podrían mejorarse significativamente.
Hemos elegido tres grupos porque convencionalmente dividiría todos los volúmenes en volúmenes de "fondo o acumulación", volúmenes de "trazo y movimiento" y volúmenes de "movimiento extremo".
Hallazgos inesperados
El trabajo con los datos ha aportado varias regularidades y secuencias, por ejemplo, que después de los volúmenes anormales, comienza el tercer grupo de volúmenes, luego el volumen activo, y después hay un movimiento de las cotizaciones en una u otra dirección.
Esto se da de forma especialmente pronunciada en las primeras horas tras la apertura de la sesión bursátil. Resultaría útil disponer de un mapa de calor de los clústeres y sus movimientos de precios asociados.
Red neuronal: cómo enseñar a una máquina a leer el mercado
Como llevo mucho tiempo utilizando redes neuronales, sería algo lógico aplicar también una red neuronal a nuestro análisis volumétrico. Hasta ahora no había probado la arquitectura LSTM, pero por fin me he decidido a hacerlo tras observar casos de esta arquitectura en otras esferas.
Veamos esto más de cerca.
Arquitectura: menos es mejor
Más sencillo es mejor. Así, he llegado a una arquitectura notablemente simple:
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
A primera vista, toda la arquitectura parece muy primitiva, solo dos capas LTSM y una capa lineal. Pero todo el poder reside en la sencillez. Porque, por desgracia, si construimos una red más desplegada, con un aprendizaje más profundo, sufriremos el sobreentrenamiento. Originalmente construí una red mucho más compleja, con tres capas LSTM, capas adicionales completamente conectadas y un complejo esquema de dropout. Los resultados fueron impresionantes... En los datos de prueba. Pero en cuanto la red se enfrentó al mercado real durante un periodo prolongado, todo se vino abajo. Es decir, se observaba sobreentrenamiento.
La batalla contra el sobreentrenamiento
El mayor problema de las redes neuronales modernas es el sobreentrenamiento. Las redes neuronales está perfectamente entrenadas para encontrar relaciones en las secciones de prueba de los datos, pero se pierden por completo en condiciones de mercado reales. He aquí cómo estoy intentando resolver este problema específicamente en la arquitectura presentada:
- Una sola capa no hace frente a la complejidad de las relaciones entre volumen y precio
- Las tres capas pueden encontrar interconexiones justo donde no las hay.
El tamaño de la capa oculta se selecciona de forma estándar: 64 neuronas. Podría ser mejor utilizar un mayor número de neuronas. En el futuro, cuando presentemos una solución funcional para combatir el sobreentrenamiento, podremos utilizar una arquitectura más compleja con más neuronas.
Datos de entrada: el arte de la selección de características
Vamos a considerar las peculiaridades de entrada para el entrenamiento:
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
Podemos experimentar mucho con un conjunto de características. Podemos añadir indicadores técnicos, derivados de precio, derivados de volumen, derivados de precio y volumen, los que queramos. Pero recuerde que un mayor número de características no siempre mejorará la calidad de la predicción. Y todos los signos aparentemente más lógicos pueden resultar ser simple ruido en los datos.
Aquí resulta interesante la conjunción de 'volume_cluster' y 'is_anomaly'. Individualmente las características son modestas, pero en sinergia son muy interesantes. Cuando aparecen volúmenes anómalos en determinados clústeres, se produce un efecto inusual en las previsiones.
Un descubrimiento inesperado
El sistema ha demostrado ser el más eficaz en aquellos periodos en los que el movimiento de los precios es potente y brillante. También rinde bien en momentos que la mayoría de los tráders calificarían de ilegibles, es decir, en mercados laterales y consolidaciones. Es en estos momentos cuando el sistema de análisis de anomalías y clústeres de volumen ve lo que está fuera del alcance de nuestra vista.
En la siguiente parte del artículo veremos cómo se ha mostrado este sistema en transacciones reales y compartiremos ejemplos concretos de señales.
De la previsión al trading: convertimos las señales en beneficio
Cualquier tráder algorítmico es consciente de ello: no basta con un modelo predictivo, hay que separarlo en una estrategia comercial que funcione. Pero, ¿cómo ponemos en práctica nuestro modelo? Vamos a considerar este punto. En la siguiente parte del artículo veremos no solo la teoría a secas, sino también la práctica real, con el comercio de prueba real, el fortalecimiento del algoritmo y la mejora de la lucha contra el sobreentrenamiento; pero por ahora, vamos a saltar la parte teórica habitual de nuestra investigación.
Anatomía de una señal comercial
En el proceso de desarrollo de una estrategia comercial, uno de los puntos clave es la generación de señales comerciales. En mi estrategia, las señales se generan a partir de predicciones del modelo que reflejan la rentabilidad esperada para el siguiente periodo.
def backtest_prediction_strategy(self, df, lookback=24): # Generating signals based on predictions df['signal'] = 0 signal_threshold = 0.001 # Threshold 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
Selección del umbral de señal
Por un lado, podemos poner el umbral justo por encima de 0. En este caso generaremos muchas señales, pero mostrarán mucho ruido debido al spread, las comisiones y el ruido del mercado. Este enfoque puede dar lugar a un gran número de señales falsas, lo que influirá negativamente en la eficacia de la estrategia.
Por consiguiente, la decisión de elevar el umbral de la rentabilidad prevista al 0,1%-0,2% parece lo más sensato. Esto permite eliminar la mayor parte del ruido y reducir el impacto de las comisiones, ya que las señales solo se generarán cuando se produzcan cambios significativos en los precios previstos.
signal_threshold = 0.001 # Threshold 0.1%
Aplicación de señales considerando el desplazamiento
Una vez generadas las señales, se aplicarán a los precios con un desplazamiento hacia delante de 24 periodos. Esto permitirá considerar el desfase entre la decisión comercial y su realización.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Un desplazamiento de 24 periodos significará que la señal generada en el momento t , se aplicará al precio en el momento t + 24 . Esto resulta importante porque, en realidad, las decisiones comerciales no pueden tomarse instantáneamente. Este enfoque permitirá una evaluación más realista de la eficacia de la estrategia comercial.
Cálculo de la rentabilidad de la estrategia
La rentabilidad de la estrategia se calcula como el producto de la señal desplazada y la variación del precio:
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Si la señal es igual a 1 , la rentabilidad de la estrategia será igual al cambio de precio ( price_change ). Si la señal es igual a -1 , la rentabilidad de la estrategia será igual a un cambio de precio negativo ( -price_change ). Si la señal es igual a 0 , la rentabilidad de la estrategia será igual a cero.
Así, el desplazamiento de las señales durante 24 periodos permitirá considerar el desfase entre la toma de una decisión comercial y su aplicación, lo cual hará más realista la evaluación de la eficacia de la estrategia.
El dorado término medio
Tras semanas de pruebas, nos hemos decidido por un umbral del 0,1%. Y he aquí por qué:
- En este umbral, el sistema genera señales con bastante frecuencia
- Alrededor del 52-63% de las transacciones resultan rentables
- El beneficio medio por transacción es de aproximadamente 2,5 veces la comisión.
El hallazgo más inusual es que la mayoría de las señales falsas también pueden centrarse en clústeres temporales. Si quiere, puede considerar un filtro de tiempo como este, y lo veremos más adelante en la siguiente parte del artículo.
def apply_time_filter(self, df): # We trade only during active hours trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
Gestión de riesgos
Una historia aparte sería la lógica de colocación de posiciones y la lógica de gestión de transacciones abiertas (soporte de las transacciones en el proceso comercial). Por un lado, la solución más obvia en este caso sería utilizar stops loss y take profits fijos, pero el mercado resulta demasiado impredecible y dinámico para que los límites de pérdidas y beneficios puedan describirse con la lógica formal habitual.
La solución que tenemos es bastante trivial: usar la volatilidad prevista para fijar los stops de forma dinámica:
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
Este planteamiento también deberá someterse a más pruebas. Todavía es posible aplicar el modelo de análisis de riesgos VaR para elegir stops loss y take profits según este sistema antiguo pero sin duda eficaz.
Hallazgos inesperados
Lo interesante es que una serie de señales consecutivas puede anunciar movimientos muy fuertes. Los problemas también surgen cuando la volatilidad media del mercado se dispara sustancialmente, entonces nuestro umbral ya no es suficiente para negociar con eficacia: y si se fija, los periodos de reducción en el gráfico están precisamente relacionados con la alta volatilidad... ¡Pero esto no es un problema para nosotros! En la siguiente parte de este artículo, resolveremos y solventaremos este problema.
Visualización y registro: cómo no ahogarse en datos
También resulta esencial no olvidar del sistema de registro. En general, todo lo que tenga que ver con impresiones, registros, salidas y comentarios del programa resulta vital durante la fase de depuración. De este modo, podremos encontrar el origen de los problemas en el código de forma muy rápida y eficaz.
Sistema de registro: los detalles marcan la diferencia
El núcleo del sistema de registro es de un formato sencillo pero eficaz:
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG) Pensará, ¿cuál es el problema? Llegué a este formato después de varios casos frustrantes en los que no podía entender por qué el sistema abría una posición en un momento determinado.
Ahora cada acción del sistema deja un rastro perfectamente claro en los registros. También tengo especial cuidado en registrar los momentos asociados a los volúmenes anormales:
self.logger.info(f"Abnormal volume detected: {volume:.2f}") self.logger.debug(f"Context: cluster {cluster}, volatility {volatility:.4f}")
También necesitamos implementar la visualización. La experiencia del trading manual ha dejado en mí el vivo hábito de observarlo todo visualmente, cuando miramos los datos de la misma manera que miramos el gráfico más ordinario. Aquí está nuestro código visual:
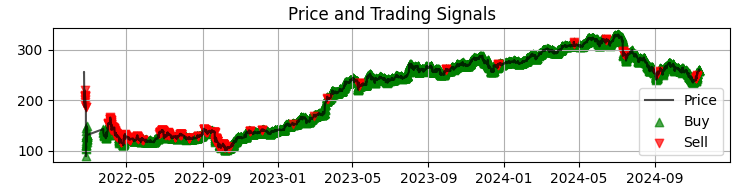
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # Price and signal chart plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Price', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Buy')
El primer gráfico que tenemos es el gráfico de precios más habitual de Sber con las señales recibidas del modelo. También complementamos las señales destacando las velas que tienen volúmenes anormales. Esto nos ayudará a comprender los momentos en que el sistema lee el mercado perfectamente, como un libro abierto.
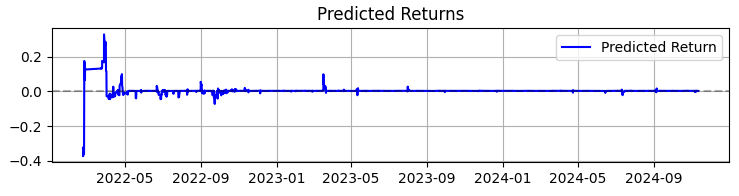
El segundo gráfico es la rentabilidad prevista. Y aquí podemos ver con claridad que una serie muy potente de predicciones a menudo comienza antes de los movimientos potentes de las cotizaciones del activo seleccionado. Así que esto nos sugiere la idea de considerar la creación de un sistema solo en esta observación particular. Resulta obvio que entonces el número de transacciones disminuirá, pero usted y yo no buscamos cantidad, sino calidad, ¿verdad?
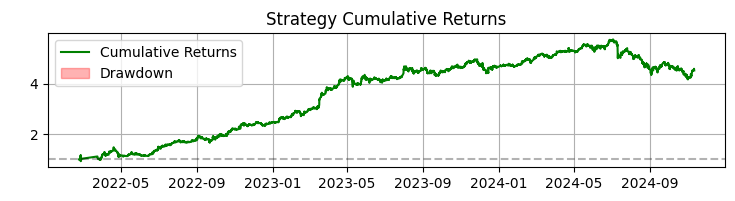
El tercer gráfico muestra la rentabilidad acumulada con las reducciones resaltadas.
De la teoría a la práctica: resultados y perspectivas
Vamos a resumir el trabajo sobre este sistema, no solo con cifras áridas, sino con descubrimientos que pueden ayudar a cualquier persona interesada en el análisis volumétrico en el trading.
El primero es que el mercado nos habla realmente a través del volumen de las transacciones. Pero este lenguaje es mucho más complejo de lo que imaginamos. En mi opinión personal, los métodos clásicos como el VSA están quedando rápidamente obsoletos, pues son incapaces de seguir el ritmo de desarrollo igualmente rápido del mercado. Los patrones se vuelven más complejos, y toda la esencia de la realidad reside en que los volúmenes forman patrones muy complejos que son difíciles de ver a simple vista.
En general, como resultado de mis casi tres años de trabajo con el aprendizaje automático, solo puedo resumir brevemente que el mercado resulta cada vez más complejo con cada año, y los algoritmos que se ejecutan en él, en parte por su OrderFlow formando tendencias y acumulaciones, también son cada vez más complejos. Lo que nos espera es la batalla de las redes neuronales, la batalla de las máquinas por el mercado, es decir, qué máquina será más eficiente.
Resumiendo el trabajo sobre el sistema, me gustaría compartir no solo los números, sino también los principales descubrimientos que pueden ser útiles para todos los que trabajan con análisis volumétrico.
En 365 días con acciones SBER, el sistema ha mostrado unos resultados impresionantes:
- Rentabilidad total: 365,0% anual (sin apalancamiento)
- Porcentaje de transacciones rentables: 50,73%
Pero lo más importante no son esas cifras. Es mucho más importante que el sistema ha demostrado ser resistente a las diversas condiciones del mercado. Funciona igual de bien tanto en una tendencia como en una tendencia lateral, aunque la naturaleza de las señales varíe significativamente.
Especialmente interesante ha resultado el comportamiento del sistema durante los periodos de alta volatilidad. Es cuando la mayoría de los tráders prefieren mantenerse al margen del mercado cuando la red neuronal encuentra los patrones más claros en el flujo de volumen. Tal vez sea que en esos momentos los jugadores institucionales dejan "huellas" más evidentes de sus acciones.
Lo que me ha enseñado este proyecto- El aprendizaje automático en el trading no supone la panacea. El éxito solo se logra con un profundo conocimiento del mercado y una cuidadosa ingeniería en el uso de características.
- La sencillez es la clave de la sostenibilidad. Cada vez que intentaba complicar el modelo añadiendo nuevas capas o características, el sistema se volvía más y más frágil.
- Los volúmenes deben analizarse dentro de su contexto. Por sí solos, los volúmenes o grupos anómalos no nos revelan gran cosa. La magia comienza cuando observamos sus interacciones con otros factores.
¿Qué es lo próximo?
El sistema sigue evolucionando. Ahora mismo estoy trabajando en algunas mejoras:
- El ajuste adaptativo de los parámetros en función de la fase del mercado
- La integración de órdenes de flujo para un análisis más preciso
- La expansión a otros instrumentos del mercado ruso
Encontrará el código fuente del sistema en los archivos adjuntos. Le agradeceríamos cualquier sugerencia de mejora. Resulta especialmente interesante escuchar las experiencias de quienes intentan adaptar el sistema a otras herramientas.
Conclusión
Para terminar, me gustaría señalar que el hallazgo más valioso de los últimos meses para mí ha sido la adaptación de enfoques clásicos, como el análisis volumétrico que hemos comentado hoy, a nuevas tecnologías como el aprendizaje automático, las redes neuronales y el big data.
La experiencia de las generaciones pasadas se mantiene muy viva. Nuestra tarea consiste simplemente en digerir esta experiencia, exprimirla y mejorarla desde el punto de vista de nuestra generación de tráders, utilizando las últimas tecnologías. Y, por supuesto, no podemos quedarnos atrás con respecto a la modernidad: tenemos por delante el aprendizaje automático cuántico, los algoritmos cuánticos para la previsión de precios y volúmenes, y las características multivariantes para el aprendizaje automático. Ya he intentado analizar el mercado en el superordenador cuántico de 20 cúbits de IBM. Los resultados son interesantes, en futuros artículos sin duda hablaremos de ellos.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16062
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.


 Integración de Smart Money Concepts (SMC), Order Blocks (OB) y Fibonacci para entradas óptimas
Integración de Smart Money Concepts (SMC), Order Blocks (OB) y Fibonacci para entradas óptimas
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso