
Schneller Handelsstrategie-Tester in Python mit Numba
Warum ein schneller Tester von Nurtzerstrategien wichtig ist
Bei der Entwicklung von Handelsalgorithmen, die auf maschinellem Lernen basieren, ist es wichtig, die Ergebnisse ihres Handels in der Vergangenheit korrekt und schnell zu bewerten. Wenn wir den seltenen Einsatz des Testers in großen Zeitintervallen und mit einer geringen Historientiefe berücksichtigen, dann ist der Tester in Python durchaus geeignet. Wenn die Aufgabe jedoch mehrere Tests und hochfrequente Strategien beinhaltet, kann eine interpretierte Sprache zu langsam sein.
Angenommen, wir sind mit der Ausführungsgeschwindigkeit einiger Skripte nicht zufrieden, wollen aber unsere vertraute Python-Entwicklungsumgebung nicht aufgeben. An dieser Stelle kommt Numba zur Hilfe, das es uns ermöglicht, nativen Python-Code in schnellen Maschinencode zu konvertieren und zu kompilieren. Die Ausführungsgeschwindigkeit eines solchen Codes wird vergleichbar mit der Ausführungsgeschwindigkeit von Code in Programmiersprachen wie C und FORTRAN.
Kurzbeschreibung der Numba-Bibliothek
Numba ist eine Bibliothek für die Programmiersprache Python, die dazu dient, die Ausführung von Code zu beschleunigen, indem Funktionen auf Bytecode-Ebene mithilfe der JIT-Kompilierung (Just-In-Time) in Maschinencode übersetzt werden. Diese Technologie kann die Rechenleistung erheblich verbessern, insbesondere bei wissenschaftlichen Anwendungen, die häufig Schleifen und komplexe mathematische Operationen verwenden. Die Bibliothek unterstützt die Arbeit mit NumPy-Arrays und ermöglicht auch eine effiziente Arbeit mit Parallelität und GPU-Computing.
Die gebräuchlichste Art, Numba zu verwenden, besteht darin, seine Sammlung von Dekoratoren auf Python-Funktionen anzuwenden, um Numba anzuweisen, sie zu kompilieren. Wenn eine mit Numba dekorierte Funktion aufgerufen wird, wird sie gerade rechtzeitig in Maschinencode kompiliert, sodass der gesamte oder ein Teil des Codes mit der Geschwindigkeit des nativen Maschinencodes ausgeführt werden kann.
Die folgenden Architekturen werden derzeit unterstützt:
-
OS: Windows (64 Bit), OSX, Linux (64 Bit).
-
Architektur: x86, x86_64, ppc64le, armv8l (aarch64), M1/Arm64.
-
GPUs: Nvidia CUDA.
-
CPython
-
NumPy 1.22 - 1.26
Es ist zu bedenken, dass das Pandas-Paket von der Numba-Bibliothek nicht unterstützt wird und die Arbeit mit Dataframes mit der gleichen Geschwindigkeit erfolgt.
Handhabung des Codes aus diesem Artikel
Damit alles auf Anhieb funktioniert, sollten Sie die folgenden vorbereitenden Schritte durchführen:
- Installieren Sie alle erforderlichen Pakete.
pip install numpy pyp install pandas pip install catboost pip install scikit-learn pip install scipy
- Laden Sie die EURGBP_H1.csv-Daten herunter und legen Sie sie im Ordner „Files“ ab.
- Laden Sie alle Python-Skripte herunter und legen Sie sie in einem Ordner ab.
- Bearbeiten Sie die erste Zeichenkette von Tester_ML.py, sodass er wie folgt aussieht: from tester_lib import test_model.
- Geben Sie den Pfad zur Datei im Skript Tester_ML.py an.
- p = pd.read_csv('C:/Program Files/MetaTrader 5/MQL5/Files/'EURGBP_H1'.csv', sep='\s+').
Wie nutzt man das Numba-Paket?
Im Allgemeinen läuft die Verwendung des Numba-Pakets darauf hinaus, es zu installieren
pip install numba conda install numba
und die Anwendung des Dekorators vor der Funktion, die wir beschleunigen wollen, zum Beispiel:
@jit(nopython=True) def process_data(*args): ...
Der Dekorateur wird auf zwei verschiedene Arten aufgerufen.
- Nopython-Modus
- Objektmodus
Die erste Möglichkeit besteht darin, die dekorierte Funktion so zu kompilieren, dass sie vollständig ohne Beteiligung des Python-Interpreters ausgeführt wird. Dies ist die schnellste Methode und wird für die Verwendung empfohlen. Numba hat jedoch Einschränkungen, da es nur die in Python eingebauten Operationen und Numpy-Array-Operationen kompilieren kann. Wenn eine Funktion Objekte aus anderen Bibliotheken, wie z. B. Pandas, enthält, kann Numba sie nicht kompilieren und der Code wird vom Interpreter ausgeführt.
Numba kann den Objektmodus verwenden, um Einschränkungen bei der Verwendung von Bibliotheken Dritter zu umgehen. In diesem Modus kompiliert Numba die Funktion unter der Annahme, dass alles ein Python-Objekt ist, und führt den Code im Wesentlichen im Interpreter aus.
@jit(forceobj=true, looplift=True) kann die Leistung im Vergleich zum reinen Objektmodus verbessern, da Numba versucht, Schleifen in Funktionen zu kompilieren, die im Maschinencode ausgeführt werden, und den Rest des Codes im Interpreter ausführt. Um die beste Leistung zu erzielen, sollten Sie den Objektmodus ganz vermeiden!
Das Paket unterstützt auch parallele Berechnungen, wenn dies möglich ist (Parallel=True). Bitte beachten Sie, dass beim ersten Aufruf einer Funktion diese in Maschinencode kompiliert wird, was einige Zeit in Anspruch nimmt. Dieser Code wird dann zwischengespeichert, sodass nachfolgende Aufrufe schneller erfolgen.
Beispiel für die Beschleunigung der Funktion von deal markup
Bevor wir mit der Beschleunigung des Testers beginnen, sollten wir etwas Einfacheres ausprobieren. Ein hervorragender Kandidat für diese Rolle ist die Funktion von deal markup. Diese Funktion nimmt einen Datenrahmen mit Kursen und kennzeichnet die Abschlüsse als Kauf und Verkauf (0 und 1). Solche Funktionen werden häufig verwendet, um Daten vorab zu kennzeichnen, damit später ein Klassifikator trainiert werden kann.
def get_labels(dataset, min = 1, max = 15) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'].iloc[i] future_pr = dataset['close'].iloc[i + rand] if (future_pr + hyper_params['markup']) < curr_pr: labels.append(1.0) elif (future_pr - hyper_params['markup']) > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
Wir verwenden als Daten die minütlichen Schlusskurse des EURGBP für 15 Jahre:
>>> pr = get_prices() >>> pr close time 2010-01-04 00:00:00 0.88810 2010-01-04 00:01:00 0.88799 2010-01-04 00:02:00 0.88786 2010-01-04 00:03:00 0.88792 2010-01-04 00:04:00 0.88802 ... ... 2024-10-09 19:03:00 0.83723 2024-10-09 19:04:00 0.83720 2024-10-09 19:05:00 0.83704 2024-10-09 19:06:00 0.83702 2024-10-09 19:07:00 0.83703 [5480021 rows x 1 columns]
Der Datensatz enthält mehr als fünf Millionen Beobachtungen, was für Tests völlig ausreichend ist.
Lassen Sie uns nun die Ausführungsgeschwindigkeit dieser Funktion für unsere Daten messen:
# get labels test start_time = time.time() pr = get_labels(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Die Ausführungszeit betrug 74,1843 Sekunden.
Versuchen wir nun, diese Funktion mit Hilfe des Numba-Pakets zu beschleunigen. Wir können sehen, dass die ursprüngliche Funktion auch das Pandas-Paket verwendet, und wir wissen, dass diese beiden Pakete nicht kompatibel sind. Verschieben wir alles, was mit Pandas zu tun hat, in eine separate Funktion und beschleunigen wir den Rest des Codes.
@jit(nopython=True) def get_labels_numba(close_prices, min_val, max_val, markup): labels = np.empty(len(close_prices) - max_val, dtype=np.float64) for i in range(len(close_prices) - max_val): rand = np.random.randint(min_val, max_val + 1) curr_pr = close_prices[i] future_pr = close_prices[i + rand] if (future_pr + markup) < curr_pr: labels[i] = 1.0 elif (future_pr - markup) > curr_pr: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_fast(dataset, min_val=1, max_val=15): close_prices = dataset['close'].values markup = hyper_params['markup'] labels = get_labels_numba(close_prices, min_val, max_val, markup) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) return dataset
Der ersten Funktion ist ein Aufruf des Dekorators @jit vorangestellt. Dies bedeutet, dass diese Funktion in Bytecode kompiliert wird. Außerdem werden wir darin Pandas los und verwenden nur Listen, Schleifen und Numpy.
Die zweite Funktion ist die vorbereitende Arbeit. Sie konvertiert den Pandas-Datenrahmen in ein Numpy-Array und übergibt es dann an die erste Funktion. Danach wird das Ergebnis genommen und der Pandas-Datenrahmen wieder zurückgegeben. Auf diese Weise wird die Hauptberechnung von markup beschleunigt.
Nun wollen wir die Geschwindigkeit messen. Die Berechnungszeit wurde auf 12 Sekunden reduziert! Bei dieser Funktion konnten wir eine mehr als 5-fache Beschleunigung erzielen. Natürlich ist dies kein völlig sauberer Test, da die Pandas-Bibliothek immer noch für Zwischenberechnungen verwendet wird, aber es wurde eine erhebliche Beschleunigung bei der Berechnung der Kennzeichnungen erreicht.
Beschleunigung des Strategieprüfers für Aufgaben des maschinellen Lernens
Ich habe den Strategietester in eine separate Bibliothek verschoben, die Sie im Anhang unten finden können. Es enthält die Funktionen „tester“ und „slow_tester“ zum Vergleich.
Der Leser könnte einwenden, dass die meisten Geschwindigkeitssteigerungen in Python aus der Vektorisierung stammen. Das ist richtig, aber manchmal müssen wir trotzdem Schleifen verwenden. So verfügt der Tester beispielsweise über eine recht komplexe Schleife, um die gesamte Historie zu durchlaufen und den Gesamtgewinn unter Berücksichtigung von Stop-Loss und Take-Profit zu kumulieren. Dies durch Vektorisierung zu realisieren, scheint keine einfache Aufgabe zu sein.Der Hauptteil der Testschleife (der Teil, der am längsten für die Ausführung benötigt) ist unten zu Referenzzwecken dargestellt.
for i in range(dataset.shape[0]): line_f = len(report) if i <= forw else line_f line_b = len(report) if i <= backw else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue
Messen wir die Testgeschwindigkeit mit den Daten, die wir zuvor erhalten haben. Schauen wir uns zunächst die Geschwindigkeit des langsamen Tests an:
# native python tester test start_time = time.time() tester_slow(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['markup'], hyper_params['forward'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 6.8639 seconds Es sieht nicht sehr langsam aus, man könnte sogar sagen, dass der Interpreter den Code recht schnell ausführt.
Lassen Sie uns die Testfunktion wieder in zwei Funktionen aufteilen. Eine davon dient als Hilfsrechner, die zweite führt die Hauptberechnungen durch.
Die Funktion „process data“ implementiert die Hauptschleife des Testers, die beschleunigt werden sollte, da Schleifen in Python langsam sind. Gleichzeitig bereitet die Funktion „Tester“ selbst zunächst die Daten für die Funktion „Daten verarbeiten“ vor, nimmt dann das Ergebnis entgegen und zeichnet das Diagramm.
@jit(nopython=True) def process_data(close, labels, metalabels, stop, take, markup, forward, backward): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b def tester(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value plot: false/true ''' dataset, stop, take, forward, backward, markup, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data(close, labels, metalabels, stop, take, markup, forw, backw) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.plot(chart) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Nun wollen wir den Numba-beschleunigten Strategietester testen:
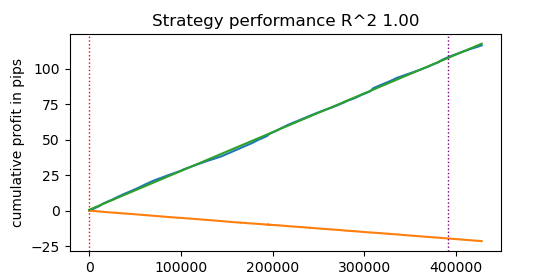
start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 0.1470 seconds Die beobachtete Geschwindigkeitssteigerung beträgt fast das 50-fache! Mehr als 400.000 Geschäfte wurden abgeschlossen.
Stellen Sie sich vor, Sie würden 1 Stunde pro Tag damit verbringen, Ihre Algorithmen zu testen, und mit dem Schnelltester bräuchten Sie dafür nur eine Minute.
Testen von Strategien anhand von Tickdaten
Erschweren wir uns die Aufgabe und laden wir den Tickverlauf der letzten 3 Jahre vom Terminal in eine .csv-Datei herunter.
Um die Datei korrekt zu lesen, muss die Funktion zum Laden von Zitaten leicht geändert werden. Anstelle von Close werden wir Bid-Preise verwenden. Wir müssen auch Preise mit denselben Indizes entfernen.
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+') pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<BID>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') # Remove duplicate string by 'time' index pFixed = pFixed[~pFixed.index.duplicated(keep='first')] return pFixed.dropna()
Das Ergebnis waren fast 62 Millionen Beobachtungen. Das Testprogramm akzeptiert Preise mit dem Spaltennamen „close“, also wird Bid in Close umbenannt.
>>> pr close time 2022-01-03 00:05:01.753 0.84000 2022-01-03 00:05:04.032 0.83892 2022-01-03 00:05:05.849 0.83918 2022-01-03 00:05:07.280 0.83977 2022-01-03 00:05:07.984 0.83939 ... ... 2024-11-08 23:58:53.491 0.82982 2024-11-08 23:58:53.734 0.82983 2024-11-08 23:58:55.474 0.82982 2024-11-08 23:58:57.040 0.82984 2024-11-08 23:58:57.337 0.82982 [61896607 rows x 1 columns]
Führen wir ein kurzes Markup aus und messen wir die Ausführungszeit.
# get labels test start_time = time.time() pr = get_labels_fast(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Die Zeit von markup betrug 9,5 Sekunden.
Führen wir nun den Schnelltest durch.
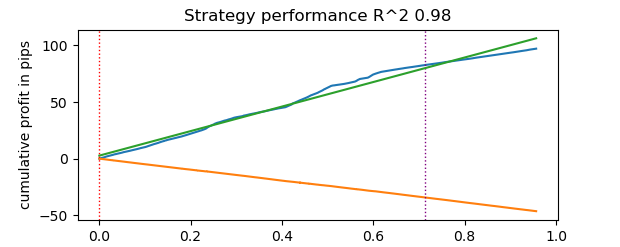
# numba tester test start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Die Testzeit betrug 0,16 Sekunden. Der langsame Tester benötigte dafür 5,5 Sekunden.
Der schnelle Tester mit Numba erledigte die Aufgabe 35 Mal schneller als der Tester mit reinem Python. Aus der Sicht des Beobachters erfolgt die Prüfung im Falle des schnellen Testers sofort, während die Verwendung des langsamen Testers eine gewisse Wartezeit erfordert. Dennoch muss man dem langsamen Tester ein Lob aussprechen, der ebenfalls gute Arbeit leistet und für das Testen von Strategien auch auf Tick-Daten gut geeignet ist.
Insgesamt waren es 1e6 oder eine Million Geschäfte.
Informationen zur Verwendung des Schnelltesters für Aufgaben des maschinellen Lernens
Wenn Sie die vorgeschlagene Testversion tatsächlich verwenden wollen, könnten die folgenden Informationen für Sie nützlich sein.
Fügen wir unserem Datensatz Merkmale hinzu, damit wir den Klassifikator trainieren können.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC-pFixedC.rolling(i).mean() count += 1 return pFixed.dropna()
Dabei handelt es sich um einfache Indikatoren, die auf der Differenz zwischen den Preisen und den gleitenden Durchschnitten basieren.
Als Nächstes erstellen wir ein Wörterbuch mit Modell-Hyperparametern, die für das Training und die Tests verwendet werden sollen. Wir werden sie bei der Erstellung eines neuen Datensatzes anwenden.
hyper_params = {
'symbol': 'EURGBP_H1',
'markup': 0.00010,
'stop_loss': 0.01000,
'take_profit': 0.01000,
'backward': datetime(2010, 1, 1),
'forward': datetime(2023, 1, 1),
'periods': [i for i in range(50, 300, 50)],
}
# catboost learning
dataset = get_labels_fast(get_features(get_prices()))
dataset['meta_labels'] = 1.0
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy()
Dabei ist zu beachten, dass der Tester nicht nur die Werte von „labels“ akzeptiert, sondern auch die von „meta_labels“. Wir brauchen sie vielleicht, wenn wir Filter für unser auf maschinellem Lernen basierendes Handelssystem verwenden wollen. Bei einem Wert von 1 ist der Handel erlaubt, bei einem Wert von 0 ist er untersagt. Da wir in diesem Demo-Beispiel keine Filter verwenden werden, erstellen wir einfach eine zusätzliche Spalte und füllen sie mit Einsen, die den Handel zu jeder Zeit ermöglichen.
dataset['meta_labels'] = 1.0
Jetzt können wir das Modell CatBoost auf dem generierten Datensatz trainieren, nachdem wir zuvor die Daten für die Vorwärts- und Rückwärtstests aus dem Verlauf entfernt haben, damit nicht mit ihnen trainiert wird.
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) model = CatBoostClassifier(iterations=500, thread_count=8, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False)
Nach dem Training testen wir das Modell mit dem gesamten Datensatz, einschließlich der Testdaten. Die Funktion test_model befindet sich in der Datei tester_lib.py zusammen mit den Funktionen des schnellen und langsamen Testers selbst. Es ist ein Wrapper für den schnellen Tester und hat die Aufgabe, die Vorhersagewerte eines trainierten maschinellen Lernmodells zu ermitteln (in unserem Fall ist es CatBoost, aber es kann auch ein anderes sein).
def test_model(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, plt = False): ext_dataset = dataset.copy() X = ext_dataset[dataset.columns[1:-2]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] # ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) # ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(ext_dataset, stop, take, forward, backward, markup, plt)
Der obige Code enthält auskommentierte Zeichenketten, die es ermöglichen, Meta-Kennzeichen zu erhalten, die angeben, ob gehandelt werden soll oder nicht. Mit anderen Worten: Das zweite maschinelle Lernmodell kann für diese Zwecke verwendet werden. Wir verwenden sie in diesem Artikel nicht.
Beginnen wir direkt mit den Tests.
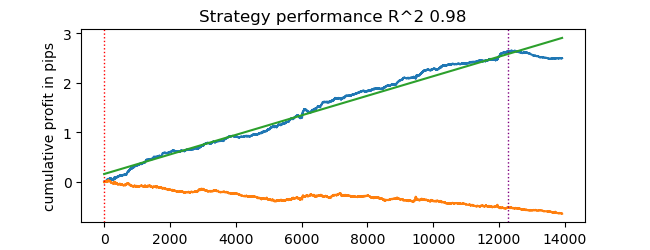
# test catboost model test_model(dataset, [model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True)
Und wir erhalten das Ergebnis. Das Modell wurde überangepasst, wie man an den Testdaten rechts von der vertikalen Linie sehen kann. Aber das spielt für uns keine Rolle, denn wir testen ja den Tester.
Da der Tester die Möglichkeit der Verwendung von Stop-Loss und Take-Profit impliziert und Sie diese vielleicht optimieren wollen, sollten wir die Optimierung nutzen, denn unser Tester ist jetzt sehr schnell!
Optimierung der Parameter von Handelssystemen durch maschinelles Lernen
Betrachten wir nun die Möglichkeit der Optimierung von Stop-Loss und Take-Profit. In der Tat ist es möglich, andere Parameter des Handelssystems zu optimieren, wie z.B. die Meta-Kennzeichnungen, aber das würde den Rahmen dieses Artikels sprengen und kann im nächsten Artikel behandelt werden.
Wir führen zwei Arten der Optimierung durch:
- Suche über Parameterraster
- Optimierung mit der Methode L-BFGS-B
Schauen wir uns zunächst kurz den Code für jede Methode an. Die Methode GRID_SEARCH wird unten angezeigt.
Sie nimmt als Argumente:
- Testdaten
- trainiertes Modell
- das Wörterbuch mit den Hyperparametern des oben beschriebenen Algorithmus
- Testobjekt
# stop loss / take profit grid search def optimize_params_GRID_SEARCH(pr, model, hyper_params, test_model_func): best_r2 = -np.inf best_stop_loss = None best_take_profit = None # Ranges for stop_loss and take_profit stop_loss_range = np.arange(0.00100, 0.02001, 0.00100) take_profit_range = np.arange(0.00100, 0.02001, 0.00100) total_iterations = len(stop_loss_range) * len(take_profit_range) start_time = time.time() for stop_loss in stop_loss_range: for take_profit in take_profit_range: # Create a copy of hyper_params current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = stop_loss current_hyper_params['take_profit'] = take_profit r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) if r2 > best_r2: best_r2 = r2 best_stop_loss = stop_loss best_take_profit = take_profit end_time = time.time() total_time = end_time - start_time average_time_per_iteration = total_time / total_iterations print(f"Total iterations: {total_iterations}") print(f"Average time per iteration: {average_time_per_iteration:.6f} seconds") print(f"Total time: {total_time:.6f} seconds") return best_stop_loss, best_take_profit, best_r2
Schauen wir uns nun den Code der Methode L-BFGS_B an. Nähere Informationen dazu finden Sie hier.
Die Funktionsargumente bleiben dieselben. Es wird jedoch eine Fitnessfunktion erstellt, über die der Strategietester aufgerufen wird. Die Grenzen der Optimierungsparameter und die Anzahl der Initialisierungen (Zufallspunkte des Parametersatzes) für den L-BFGS_B-Algorithmus werden festgelegt. Zufällige Initialisierungen sind notwendig, um zu verhindern, dass der Optimierungsalgorithmus in lokalen Minima stecken bleibt. Danach wird die Minimieren-Funktion aufgerufen, der die Parameter des Optimierers selbst übergeben werden.
def optimize_params_L_BFGS_B(pr, model, hyper_params, test_model_func): def objective(x): current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = x[0] current_hyper_params['take_profit'] = x[1] r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) return -r2 bounds = ((0.001, 0.02), (0.001, 0.02)) # Let's try some random starting points n_attempts = 50 best_result = None best_fun = float('inf') start_time = time.time() for _ in range(n_attempts): # Random starting point x0 = np.random.uniform(0.001, 0.02, 2) result = minimize( objective, x0, method='L-BFGS-B', bounds=bounds, options={'ftol': 1e-5, 'disp': False, 'maxiter': 100} # Increase accuracy and number of iterations ) if result.fun < best_fun: best_fun = result.fun best_result = result # Get the end time and calculate the total time end_time = time.time() total_time = end_time - start_time print(f"Total time: {total_time:.6f} seconds") return best_result.x[0], best_result.x[1], -best_result.fun
Jetzt können wir beide Optimierungsalgorithmen ausführen und die Ausführungszeit und die Genauigkeit betrachten.
# using
best_stop_loss, best_take_profit, best_r2 = optimize_params_GRID_SEARCH(dataset, model, hyper_params, test_model)
best_stop_loss, best_take_profit, best_r2 = optimize_params_L_BFGS_B(dataset, model, hyper_params, test_model)
Algorithmus für die Gittersuche:
Total iterations: 400 Average time per iteration: 0.031341 seconds Total time: 12.536394 seconds Best parameters: stop_loss=0.004, take_profit=0.002, R^2=0.9742298702323458
Der Algorithmus L-BFGS-B:
Total time: 4.733158 seconds Best parameters: stop_loss=0.0030492548809269732, take_profit=0.0016816794762543421, R^2=0.9733045271274298
Mit meinen Standardeinstellungen war L-BFGS-B mehr als doppelt so schnell und zeigte Ergebnisse, die mit denen des Gittersuchalgorithmus vergleichbar waren.
Man kann also beide Algorithmen verwenden und je nach Anzahl und Bereich der zu optimierenden Parameter den besten auswählen.
Schlussfolgerung
Dieser Artikel zeigt die Möglichkeit auf, den Strategietester zu beschleunigen, der zum schnellen Testen von auf maschinellem Lernen basierenden Strategien verwendet werden kann. Numba liefert nachweislich den 50-fachen Geschwindigkeitsschub. Das Testen wird schnell und ermöglicht mehrere Tests und sogar eine Parameteroptimierung.
Anhänge:
- tester_lib.py - Tester-Bibliothek
- test tester.py - Skript zum Vergleich von langsamen (Python) und schnellen (Numba) Testern
- tester ticks.py - Skript zum Vergleich von Testern anhand von Tickdaten
- tester ML.py - Skript für das Training des Klassifikators und die Optimierung der Hyperparameter
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/14895
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Nun, die Standardabweichung in einem gleitenden Fenster mit festem Wert wird eine nicht normalisierte Schwankungsbreite haben, die von der Volatilität abhängt. Soweit ich weiß, wird zu diesem Zweck in der Regel der z-Score verwendet, da er ein normalisierter Wert ist. Das ist das Ende der Überlegungen )
Verstanden, ich nehme Min/Max über die gesamte verfügbare Historie und setze sie als Grenzen, dann unterteile ich sie bei jeder Iteration des Optimierers in zufällige Bereiche. Sie können auch zscore tun. Ich dachte, eine solche Normalisierung könnte besser für den Optimierer sein (loswerden von kleinen Werten mit einer großen Anzahl von Nullen nach dem Komma), aber ich glaube nicht, dass es sein sollte.
Hallo Maxime, ich glaube, du bist die klügste Person im Forum, ich hoffe, dass ich im zweiten Artikel eine detaillierte Beschreibung sehen werde. danke
Danke für das schmeichelhafte Feedback, ich werde versuchen, etwas Interessantes für Sie zu schreiben.
Ich habe etwas Zeit und bin fast fertig mit dem Modelltraining und der Optimierung der Hyperparameter in einer Flasche.
Es wird möglich sein, viele Modelle auf einmal zu trainieren, sie dann zu optimieren, dann das beste Modell mit den besten Optimierungsparametern auszuwählen, zum Beispiel:
Und das Ergebnis ausgeben.
Dann kann das Modell mit optimalen Hyperparametern in das Terminal exportiert werden. Oder man verwendet den Terminal-Optimierer selbst.
Ich werde den Artikel später beginnen, ich habe es nicht vergessen.