
Объемный нейросетевой анализ как ключ к будущим трендам

В эпоху, когда вся торговля становится все более и более автоматизированной, нам полезно вспомнить старых трейдеров, многие из которых учат: объем всему голова. И действительно, технический анализ и объемный анализ было бы полезно и очень интересно подавать в качестве признаков в машинное обучение. Возможно, при правильной интерпретации это даст нам результат. В статье мы дадим оценку подходу к анализу объема торгов и признаков на основе объема, при помощи архитектуры LSTM.
Наша система будет анализировать аномалии в объемах и прогнозировать будущие движения цен. Ключевыми особенностями системы я бы назвал детектирование аномального объема, кластеризацию объема, и обучение модели прямо через связку Python + MetaTrader 5.
Проведем мы и комплексный бэктестинг с визуализацией результатов. Модель демонстрирует особую эффективность на часовом таймфрейме российского рынка акций, что подтверждается результатами тестирования на исторических данных акций Сбербанка за последний год. В статье я подробно рассмотрю архитектуру системы, принципы её работы и практические результаты применения.
Разбор кода: от данных к прогнозам
Давайте копнем глубоко, и попробуем создать систему, которая реально будет понимать, что сейчас происходит с объемами. Начнем с простого — как будем получать данные и обрабатывать их. С одной стороны, ничего сложного — скачал данные и работай…. Но дьявол, как всегда, кроется в деталях.
Источник данных: копаем глубже
Итак, наша функция загрузки данных.
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"Запрос данных MT5: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
Казалось бы, самая простая. Я намеренно использую copy_rates_range вместо более легкого copy_rates_from. Это нужно нам, чтобы не потерять нулевые периоды, при работе с неликвидными инструментами.
Дальше — больше, начинаем работать с признаками и индикаторами.
Препроцессинг: искусство подготовки данных
Не будем долго мучаться с выбором признаков, а остановимся на нескольких наиболее очевидных.
def preprocess_data(self, df): # Базовые индикаторы объема df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # Индикаторы для ML df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
Когда мы работаем с выбором признаков, мы словно настраиваем орекстр. Каждый признак несет свою роль и свой специфический звук в симфонии данных. Рассмотрим наш базовый набор.
Первое — самое простое: мы берем скользящую среднюю объема. Средняя от объема с периодом 5 улавливает малейшие колебания, ну а двадцаточка — реагирует на уже куда более мощные тренды объема.
Также интересен признак в виде отношения объема к своей средней. При резком скачке в будущем очень часто случается мощный импульс цены.
Также мы смотрим на моментум цены и моментум объема за последние 24 бара.
Есть еще более интересный признак, под названием волатильность объема. Эту штуку я бы назвал индикатором рыночных нервов. Когда волатильность объема растет, это может говорить об мощных вливаниях в рынок со стороны серьезных игроков.
Корреляция цены и объема так же рассматривается нашей моделью. В конце мы обязательно посмотрим на все эти признаки вживую, визуализировав наши свежеиспеченные индикаторы.
Бутылочное горлышко производительности
Чтобы не нагружать систему, мы можем внедрить батчинг данных и параллельные вычисления. То есть, мы делим данные на маленькие кусочки, и парралельно их обрабатываем.
Данная простейшая техника ускоряет обработку данных в несколько раз, а так же поможет избежать проблем с утечками памяти на больших объемах данных.
В следующей части статьи я расскажу о самом интересном — как система обнаруживает аномальные объемы и что происходит дальше.
В поисках "чёрных лебедей": как распознать аномальные объёмы
Все мы, разумеется, слышали о том, что такое аномальные объемы, и как их увидеть на графике. Пожалуй, любой трейдер с опытом способен их разглядеть. Но вот беда: а как зашить это в код? Как формализовать логику поиска таких объемов?
Охота на аномалии
После ряда экспериментов мои изыскания в этой области остановились на методе Isolation Forest. Почему этот метод, спросите вы? Ну, классические методы вроде z-оценки, или оценки процентилей, могут пропустить локальную аномалию, небольшую, а ведь важны не абсолютные или процентные величины, а именно те объемы, которые выделяются на фоне остальных — и выходят из общего контекста.
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
С параметром, конечно, еще лучше поиграться, а еще лучшим решением был бы подбор всех настроек модели по алгоритмам вроде BGA. Я ставил значение в рекомендуемые в учебниках 0.05, что соответствует 5% аномалий. Но реальный рынок намного более зашумлен, чем это можно представить. Поэтому планка была немного поднята вверх, и еще будет полезно увидеть аномалии воочию, в группировке с движениями цен (к этой теме еще вернемся ниже),
Кластеризация: поиск паттернов
Самих по себе аномалий недостаточно для хорошего прогнозирования. Нужна еще кластеризация объемов. Мы остановимся на этом варианте кластеризации:
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
Признаки для кластеризации выбраны довольно простые. Считаю, что подвергать кластеризации только сами реальные объемы было бы странно, иначе зачем мы создавали наши признаки и индикаторы. Другой вопрос — что число признаков, как и индикаторов объема, можно было бы вполне улучшить.
Три кластера выбраны из-за того, что я бы условно разделил все объемы на объемы «фона или накопления», объемы «хода и движения» и объемы «экстремального движения».
Неожиданные находки
Работа с данными принесла несколько закономерностей и найденных последовательностей, к примеру, что после аномальных объемов, начинается третий кластер объемов, затем активный объем, и уже после этого идет движение котировок в ту или иную сторону.
Особенно ярко это проявляется в первые часы после открытия сессии на бирже. Тут полезно было бы составить тепловую карту из кластеров и сопутствующих им движений цен.
Нейронная сеть: как научить машину читать рынок
Поскольку я давно использую нейросети, вполне логичным выводом было бы применить нейросеть и для нашего анализа объемов. До сих пор я не пробовал архитектуру LSTM, но сейчас наконец решился, наблюдая кейсы данной архитектуры в других областях.
Рассмотрим же ее подробнее.
Архитектура: меньше — значит лучше
Проще — лучше. Я пришел к удивительно простой архитектуре:
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
На первый взгляд, вся архитектура выглядит очень примитивно, лишь два слоя LTSM и один линейный слой. Но вся сила в простоте. Потому что увы, если мы строим сеть более развернутую, с более глубоким обучением — получим overfittig. Изначально я построил гораздо более сложную сеть — с тремя LSTM-слоями, дополнительными полносвязными слоями, сложной схемой dropout. Результаты были впечатляющими... На тестовых данных. Но как только сеть столкнулась с реальным рынком, продолжительным реальным рынком, всё рассыпалось. То есть, мы наблюдали переобучение.
Битва с переобучением
Самой большой проблемой современных нейросетей является переобучение. Нейросеть прекрасно обучается находить взаимосвязи в тестовых участках данных, но абсолютно теряется в реальных рыночных условиях. Вот как я пытаюсь решить эту проблему конкретно в представленной архитектуре:
- Один слой не справляется со сложностью взаимосвязей между объемами и ценой
- Три слоя могут находить взаимосвязи уже как раз там, где их на самом деле нет
Размер скрытого слоя выбран стандартным образом — 64 нейрона. Возможно, лучшим будет использовать большее число нейронов. В будущем, когда я представлю рабочее решение по борьбе с переобучением, мы сможем использовать более сложную архитектуру с большим числом нейронов.
Входные данные: искусство отбора признаков
Рассмотрим входные фичи для обучения:
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
С набором признаков можно очень сильно экспериментировать. Можно добавлять технические индикаторы, производные цен, объемов, производные цен и объемов, кто на что горазд. Но помните о том, что большее число признаков не всегда улучшит качество прогнозирования. А каждый, казалось бы, самый логичный признак — может на самом деле оказаться лишь простым шумом в данных.
Интересно тут смотрится связка 'volume_cluster' и 'is_anomaly'. Отдельно признаки скромны, но в синергии они очень интересны. Когда аномальные объемы появляются в определенных кластерах, это дает необычный эффект при прогнозировании.
Неожиданное открытие
Система оказалась наиболее эффективна в те периоды, когда движение цен идет мощно, ярко. Неплохо она также себя показывает в моменты, которые большая часть трейдеров назовет нечитаемыми, — то есть, на боковых рынках и на консолидациях. Именно в эти моменты система анализа аномалий и кластеров объемов видит то, что недоступно нашему зрению.
В следующей части статьи я расскажу о том, как эта система показала себя на реальных торгах, и поделюсь конкретными примерами сигналов.
От прогнозов к торговле: превращаем сигналы в прибыль
Любой алготрейдер в курсе: просто прогнозной модели мало, нужно ее выделять в рабочую торговую стратегию. Но как же применять нашу модель на практике? Давайте разберемся с этим моментом. В следующей части статьи вас ожидает уже не просто сухая теория, а реальная практика, с реальной тестовой торговлей, усиление алгоритма, улучшение борьбы с переобучением, а пока что — обойдемся обычной теоретической частью нашего исследования.
Анатомия торгового сигнала
В процессе разработки торговой стратегии, одним из ключевых моментов является генерация торговых сигналов. В моей стратегии сигналы генерируются на основе предсказаний модели, которые отражают ожидаемую доходность на следующий период.
def backtest_prediction_strategy(self, df, lookback=24): # Генерация сигналов на основе предсказаний df['signal'] = 0 signal_threshold = 0.001 # Порог 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
Выбор порога сигнала
С одной стороны, можно поставить порог просто выше 0. В этом случае мы будем генерировать множество сигналов, но они будут зашумлены из-за спреда, комиссий и рыночного шума. Такой подход может привести к большому количеству ложных сигналов, что негативно скажется на эффективности стратегии.
Поэтому разумнее всего выглядит решение поднять порог предсказанной доходности до 0.1%-0.2%. Это позволяет отсечь большую часть шума и снизить влияние комиссий, так как сигналы будут генерироваться только при значительных предсказанных изменениях цены.
signal_threshold = 0.001 # Порог 0.1%
Применение сигналов с учетом сдвига
После генерации сигналов, они применяются к ценам с учетом сдвига на 24 периода вперед. Это позволяет учесть лаг между принятием торгового решения и его реализацией.
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Сдвиг на 24 периода означает, что сигнал, сгенерированный в момент времени t , будет применяться к цене в момент времени t + 24 . Это важно, так как в реальности торговые решения не могут быть реализованы мгновенно. Такой подход позволяет более реалистично оценить эффективность торговой стратегии.
Расчет доходности стратегии
Доходность стратегии рассчитывается как произведение сдвинутого сигнала и изменения цены:
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
Если сигнал равен 1 , доходность стратегии будет равна изменению цены ( price_change ). Если сигнал равен -1 , доходность стратегии будет равна отрицательному изменению цены ( -price_change ). Если сигнал равен 0 , доходность стратегии будет равна нулю.
Таким образом, сдвиг сигналов на 24 периода позволяет учесть лаг между принятием торгового решения и его реализацией, что делает оценку эффективности стратегии более реалистичной.
Золотая середина
После недель тестирования я остановился на пороге в 0.1%. И вот почему:
- При таком пороге система генерирует сигналы достаточно часто
- Около 52-63% сделок оказываются прибыльными
- Средняя прибыль на сделку примерно в 2.5 раза превышает комиссию
Самое необычное открытие в том, что большая часть ложных сигналов может сосредотачиваться также по временным кластерам. Если хотите, можете рассмотреть такой вот временной фильтр, а мы его рассмотрим позднее, в следующей части статьи.
def apply_time_filter(self, df): # Торгуем только в активные часы trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
Управление рисками
Отдельной историей станет логика набора позиции и логика управления открытыми сделками (сопровождение сделок в процессе торговли). С одной стороны, самое очевидное решение здесь — использование фиксированных стопов и тейков, но ведь рынок слишком непредсказуем и динамичен, чтобы лимиты потерь и прибылей можно было описать обычной формальной логикой.
Решение у нас довольно банально — использовать предсказанную волатильность для динамической установки стопов:
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
Этот подход нужно также тестировать дополнительно. Возможно еще применять модель анализа рисков VaR, чтобы подбирать стопы и тейки по этой старой, но уверенно эффективной системе.
Неожиданные находки
Интересные находки в том, что серии из последовательных сигналов могут предвещать очень сильные движения. Также проблемы возникают тогда, когда волатильность рынка в среднем взлетает очень сильно, тогда нашего порога уже перестает хватать для эффективной торговли: и если вы заметите, то периоды просадок на графике как раз связаны с высокой волатильностью… Но для нас это не беда! В следующей части статьи мы решим и купируем эту проблему.
Визуализация и логирование: как не утонуть в данных
Еще нам очень важно не забыть о системе логирования. В целом, все что связано с принтами, логами, выводами и комментариями программы, является жизненно важным на этапе отладки. Так вы сможете находить источник проблем в коде очень быстро и эффективно.
Система логирования: детали решают всё
В основе системы логирования лежит простой, но эффективный формат:
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG) Казалось бы, что тут сложного? Я пришел к этому формату после нескольких болезненных случаев, когда не мог понять, почему система открыла позицию в конкретный момент.
Теперь каждое действие системы оставляет четкий след в логах. Особенно тщательно также я логирую моменты, связанные с аномальными объемами:
self.logger.info(f"Обнаружен аномальный объем: {volume:.2f}") self.logger.debug(f"Контекст: кластер {cluster}, волатильность {volatility:.4f}")
Нам нужна также и визуализация. Опыт ручного трейдинга оставил яркую привычку — наблюдать все визуально, когда ты смотришь на данные точно также, как ты смотришь на самый обычный график. Вот наш код визуала:
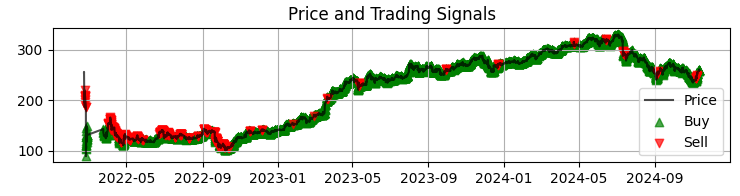
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # График цены и сигналов plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Цена', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Покупка')
Первый график у нас — это самый обычный график цен Сбера с полученными сигналами модели. Также мы дополняем сигналы подсветкой тех свечей, где есть аномальные объемы. Это помогает нам понимать моменты, когда система отлично читает рынок, словно открытую книгу.
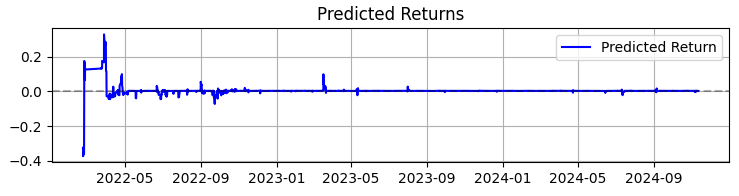
Второй график — предсказанная доходность. И тут уже явно видно, что перед мощными движениями котировок выбранного нами актива часто начинается очень мощная серия предсказаний. Так что это наводит на идею рассмотреть создание системы только на этом конкретном наблюдении. Разумеется, тогда число сделок упадет, но мы с вами ведь гонимся не за количеством, а за качеством?
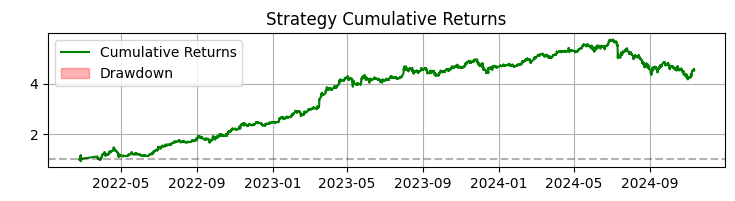
Третий график — кумулятивная доходность с подсветкой просадок.
От теории к практике: результаты и перспективы
Подведем итоги работы над данной системой — не просто сухими цифрами, а открытиями, которые могут помочь всем, кого интересует объемный анализ в трейдинге.
Первое — рынок реально говорит с нами через торговый оборот и объем. Но этот язык намного сложнее, чем вы можете себе представить. По моему личному мнению, классические методы вроде VSA уже стремительно устаревают, не поспевая за столь же стремительным развитием рынка. Паттерны усложняются, и вся соль реальности в том, что объемы формируют очень сложные паттерны, которые с трудом видны невооруженному глазу.
В целом, в результате моей почти трехлетней работы с машинным обучением, я могу резюмировать кратко лишь то, что рынок с каждым годом становится все сложнее, и алгоритмы, работающие на нем, отчасти своим OrderFlow формирующие тренды и накопления, становятся тоже все сложнее. Впереди нас ждет битва нейросетей — битва машин за рынок, чья машина окажется эффективнее.
Подводя итоги работы над системой, хочу поделиться не только цифрами, но и главными открытиями, которые могут быть полезны всем, кто работает с анализом объёмов.
За 365 дней на акциях SBER система показала впечатляющие результаты:
- Общая доходность: 365.0% годовых (без плеча)
- Доля прибыльных сделок: 50,73%
Но эти цифры — не самое главное. Гораздо важнее то, что система оказалась устойчивой к различным рыночным условиям. Она одинаково хорошо работает и в тренде, и в боковике, хотя характер сигналов заметно меняется.
Особенно интересным оказалось поведение системы в периоды высокой волатильности. Именно тогда, когда большинство трейдеров предпочитает оставаться вне рынка, нейронная сеть находит самые чёткие паттерны в потоке объёмов. Возможно, дело в том, что в такие моменты институциональные игроки оставляют более явные "следы" своих действий.
Чему научил меня этот проект- Машинное обучение в трейдинге — это не магическая таблетка. Успех приходит только при глубоком понимании рынка и тщательной инженерии признаков.
- Простота — ключ к устойчивости. Каждый раз, когда я пытался усложнить модель, добавляя новые слои или признаки, система становилась все более хрупкой.
- Объёмы нужно анализировать в контексте. Сами по себе аномальные объёмы или кластеры мало о чём говорят. Магия начинается, когда мы смотрим на их взаимодействие с другими факторами.
Что дальше
Система продолжает развиваться. Сейчас я работаю над несколькими улучшениями:
- Адаптивная настройка параметров в зависимости от рыночной фазы
- Интеграция потоковых ордеров для более точного анализа
- Расширение на другие инструменты российского рынка
Исходный код системы доступен во вложениях. Буду рад предложениям по улучшению. Особенно интересно услышать опыт тех, кто попробует адаптировать систему под другие инструменты.
Заключение
В заключение хочется отметить то, что самой ценной находкой последних месяцев для меня стала адаптация классических подходов, вроде рассмотренного сегодня нами объемного анализа, к новым технологиям вроде машинного обучения, нейросетей, больших данных.
Опыт прошлых поколений — черт возьми, жив. Просто наша с вами задача состоит в том, чтобы данный опыт переварить, сделать его выжимку, и улучшить уже с позиции нашего поколения трейдинга, с применением новейших технологий. Ну и конечно, нельзя отставать от современности: впереди у нас квантовое машинное обучение, квантовые алгоритмы прогнозирования цен и объемов, многомерные признаки для машинного обучения. Я уже пробовал анализировать рынок на 20-кубитном квантовом суперкомпьютере IBM. Результаты интересны, о них обязательно расскажу в будущих статьях.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования