
Нейросети в трейдинге: Актер—Режиссёр—Критик (Actor—Director—Critic)

Введение
Обучение с подкреплением (Reinforcement Learning — RL) остаётся одним из самых перспективных и активно развивающихся направлений в современном машинном обучении. Его уникальность заключается в способности Агента обучаться путем взаимодействия с окружающей средой, вырабатывая оптимальные стратегии поведения на основе накопленного опыта. Особенно эффективным оказался синтез с глубокими нейронными сетями — так называемое глубокое обучение с подкреплением (Deep Reinforcement Learning — Deep-RL), которое дало толчок к развитию автономных систем в робототехнике, игровых задачах, управлении производством, а также в области финансовых рынков.
Финансовая среда характеризуется высокой стохастичностью, непрерывными изменениями и высоким уровнем риска, что делает её идеальным полигоном для применения и тестирования методов Deep-RL. Здесь Агенту необходимо быстро адаптироваться к изменениям цен, объемов торгов, рыночной волатильности и принимать решения в условиях неопределённости. Однако, на практике внедрение RL в торговые стратегии, особенно в условиях высокочастотной торговли и портфельного управления, сталкивается с рядом трудностей. Одной из ключевых проблем остаётся низкая эффективность использования данных — то есть крайне высокая стоимость неинформативных действий и ошибочных стратегий.
В классических Model-Free RL алгоритмах, где модель окружающей среды не используется явно, Агент получает информацию исключительно из наблюдаемого опыта. Он действует методом проб и ошибок: совершает действия, получает вознаграждение, обновляет свои оценки. Однако, значительная часть таких взаимодействий оказываются малоинформативной. В условиях рынка это означает высокие торговые издержки, потери капитала и долгий путь к формированию устойчивой стратегии. Следовательно, актуальной задачей становится повышение эффективности использования данных и ускорение сходимости обучения.
Одной из наиболее устойчивых и широко используемых архитектур стал фреймворк Actor-Critic, который совмещает две модели:
- Актёр (Actor) — изучает стратегию (Policy),
- Критик (Critic) — оценивает действия через функцию ценности (Value Function).
В финансовых приложениях архитектура Actor-Critic используется для построения Агентов, способных прогнозировать краткосрочные прибыли и управлять рисками в долгосрочной перспективе. Например, в задаче ребалансировки портфеля Критик обучается прогнозировать ожидаемую доходность, а Актёр выбирает веса активов, позволяющие увеличить ценность портфеля. Однако даже такая продвинутая архитектура имеет ограничения: на ранних стадиях обучения оценка Критика может быть слишком грубой, а сигналы, поступающие Актёру, — ошибочными. Агент в этом случае может повторно исследовать заведомо невыгодные области пространства действий.
Для устранения этого недостатка в работе "Actor-Director-Critic: A Novel Deep Reinforcement Learning Framework" был предложен новый фреймворк — Actor—Director—Critic (ADC). В дополнение к Актёру и Критику в архитектуру вводится третий элемент — Режиссёр (Director). Его задача — выступать в роли классификатора, способного отличать качественные действия от некачественных ещё до того, как Критик обучится давать корректные оценки. В отличие от Критика, Режиссёр выполняет не оценочную, а классификационную функцию. Он определяет: стоит ли пытаться обучать политику на данном действии, или оно изначально низкого качества и может быть исключено из последующего рассмотрения.
Введение режиссёра дает следующие преимущества. Во-первых, на ранней фазе обучения крайне важна селективность — необходимо избегать повторения неэффективных действий. Во-вторых, в условиях высоких транзакционных издержек и волатильности, присущих финансовым рынкам, каждый неудачный шаг дорого обходится Агенту. В таких условиях Режиссёр выступает как механизм начального «направления» Актёра, позволяя фокусироваться на потенциально эффективных действиях. Такой подход уменьшает энтропию исследования и ускоряет формирование продуктивных стратегий.
Процесс обучения Режиссёра основан на построении двух эмпирических подмножеств данных: в одно включаются наборы данных (состояние, действие, награда) с высокой доходностью, в другое — с низкой. После обучения Режиссёр способен выполнять бинарную классификацию новых действий: отсеивать потенциально неэффективные, усиливая тем самым сигналы, поступающие от Критика. Влияние Режиссёра регулируется через коэффициент затухания: сначала он оказывает большое влияние на Актёра, но по мере роста точности Критика вес Режиссёра снижается. Этот механизм позволяет сохранить гибкость и устойчивость в процессе оптимизации.
В дополнение к структурным улучшениям архитектуры ADC, авторы фреймворка предлагают решение другой фундаментальной проблемы — переоценки действий (Overestimation Bias). В RL переоценка возникает из-за использования завышенных значений в качестве целевых — это приводит к переоцененному ожидаемому вознаграждению и дестабилизации обучения. Причинами переоценки служат:
- Смещение, связанное с выбором завышенного значения функции ценности (Maximization Bias);
- Ошибки бутстрэпинга, когда прогнозные оценки будущих вознаграждений используются для обновления текущего состояния.
Одним из наиболее известных подходов для борьбы с переоценкой стал алгоритм Twin Delayed Deep Deterministic Policy Gradient (TD3). Он использует две независимые Q-функции и выбирает минимум из них для обновления. Однако стабильность этого метода всё ещё ограничена: целевые модели обновляются с задержкой, и их оценки нестабильны.
Фреймворк ADC предлагает модификацию этой схемы: каждая Q-функция получает две целевые копии, которые обновляются в чередующемся порядке с разными интервалами. При расчёте целевого значения используется усреднённая оценка двух целевых моделей. Такой подход снижает дисперсию оценок, минимизирует переоценку и делает обучение более стабильным. Это особенно важно в задачах, где ошибка в Q-функции может привести к потере капитала, как в торговых приложениях.
Объединение архитектуры Actor-Director-Critic с усовершенствованной системой двойной оценки даёт в результате мощный, адаптивный и устойчивый фреймворк. Его применение в задачах алгоритмической торговли, управления активами и автоматического хеджирования, способно существенно повысить эффективность торговых стратегий, ускорить обучение Агентов и снизить риски за счёт интеллектуального отбора действий уже на ранних стадиях обучения.
Алгоритм ADC
Во множестве задач обучения с подкреплением архитектура Actor-Critic зарекомендовала себя как надёжный и эффективный инструмент. Её элегантность, понятность и способность обеспечивать высококачественные стратегии сделали эту модель основой для дальнейших разработок в области обучения с подкреплением. Однако, с ростом сложности анализируемых сред, особенно при наличии непрерывного пространства действий Агента и слабо выраженной обратной связи от окружающей среды, возникла потребность в более мощных и гибких архитектурных решениях. Ответом на эти вызовы стал инновационный фреймворк Actor-Director-Critic (ADC), в котором заложены принципы стратегического планирования, эвристического руководства и глубокой оценки полезности действий.
Данная архитектура опирается на три взаимосвязанных компонента: Актёра (Actor), Критика (Critic) и Режиссера (Director). Вместе они формируют скоординированную систему, в которой каждый элемент поддерживает и усиливает другие, создавая условия для более устойчивого и быстрого обучения Агента.
Критик выполняет роль аналитического центра системы. Его основная задача — оценивать полезность действий Агента в долгосрочной перспективе, аппроксимируя функцию ценности Q(s, a), которая отражает ожидаемое суммарное вознаграждение при использовании текущей политики. Он обучается путём минимизации ошибки между прогнозным и целевым значением:
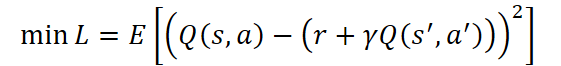
где:
- r — вознаграждение от окружающей среды за последнее действие Агента,
- γ ∈ [0,1) — коэффициент дисконтирования,
- s' и a' — следующее состояние и действие, соответственно.
Тем не менее, полагаться исключительно на оценки Критика, особенно на ранних этапах обучения, может быть рискованно, поскольку его прогнозы ещё нестабильны. С целью компенсировать эту неопределённость и направить Агента в сторону разумных решений, в архитектуру добавляется Режиссер — компонент, выполняющий функции наставника. Он выступает в роли бинарного классификатора, отличающего потенциально хорошие действия от нежелательных. Обучение Режиссера происходит на заранее размеченных выборках положительных ah и отрицательных al действий по следующей целевой функции:
![]()
где функция D(s, a) оценивает вероятность того, что действие a в состоянии s является целесообразным. Таким образом Режиссер фильтрует действия и направляет обучение Актёра, особенно на начальной стадии, когда оценки Критика могут быть ненадёжными.
Актёр, в свою очередь, представляет собой реализацию политики поведения Агента. Это параметрическая функция μθ(s), возвращающая оптимальное (в рамках текущей политики поведения) действие a, после анализа текущего состояния s. В фреймворке ADC Актёр обучается не только на основе прогнозов Критика, но также получает указания от Режиссера. Это обеспечивает ему более уверенное движение в сторону оптимальных стратегий. Целевая функция Актёра объединяет два источника информации:
![]()
Тем самым Актёр стремится выбирать действия, которые одновременно одобряются Режиссером и обладают высокой ожидаемой ценностью по версии Критика.
С целью повышения устойчивости обучения и борьбы с переоценкой, авторы фреймворка ADC предлагают воспользоваться усовершенствованной системой двойной оценки: два независимых Критика получают по две целевых копии с замороженными параметрами для каждого. При обучении Критика, берётся среднее значение результатов оценки последующего состояния и действия соответствующими целевыми моделями, что способствует стабилизации процесса. А при обучении Актёра, используется минимальное значение среди оценок двух Критиков, что предотвращает переоценку действия и способствует формированию более консервативной, но надёжной стратегии.
Целевые модели Критиков обновляются поочерёдно, путём копирования параметров соответствующих обучаемых моделей через заданный промежуток времени. Это позволяет обеспечить стабильность при долгосрочном обучении и предотвратить резкие скачки в значениях целевых функций.
Стоит обратить внимание и на тот факт, что оптимизация параметров обучаемых моделей Критика проводится на всех итерациях процесса обучения. Однако, корректировка политики Актера осуществляется с задержкой, что дает дополнительную стабильность процессу обучения. Период задержки позволяет Критику точнее оценить актуальную политику поведения и указать более взвешенное направление её корректировки.
Дополнительно, для повышения разнообразия и устойчивости в поведении Агента применяются методы стохастического сглаживания, включающие:
- добавление гауссовского шума к действиям Агента:
![]()
- добавление ограниченного шума к целевым действиям:
![]()
Финальная функция оптимизации параметров Актёра интегрирует оба сигнала — от Критика и Режиссера:
![]()
Фреймворк Actor-Director-Critic открывает новые горизонты для создания интеллектуальных Агентов, способных не только извлекать знания из опыта, но и воспринимать наставничество, аналогичное человеческому обучению.
Авторская визуализация фреймворка Actor-Director-Critic представлена ниже.

Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка Actor-Director-Critic, мы переходим к практической части нашей статьи, в которой рассмотрим собственное видение реализации предложенных авторами фреймворка подходов средствами MQL5.
Как вы могли заметить, рассматриваемый фреймворк не предполагает создания каких-либо новых модулей в виде отдельных объектов. И это обстоятельство значительно выделяет данную работу из ряда предыдущих. Сегодня мы больше внимания уделим созданию архитектуры обучаемых моделей из ранее созданных модулей и построению процесса обучения с учетом предложенных подходов.
Архитектура обучаемых моделей
Начиная работу по построению архитектуры обучаемых моделей, стоит отметить, что предложенные авторами фреймворка ADC применимы к довольно широкому спектру архитектурных решений. В авторской работе приведены результаты экспериментов с расширением фреймворка TD3. Мы же, в своей работе, пойдем дальше и попробуем применить предложенные решения к более сложному архитектурному решению HiSSD, которое было рассмотрено в предыдущей работе. При этом, мы не ограничились добавлением двух новых моделей: Критика и Режиссера, но и внесли некоторые правки в ране созданные.
Как и ранее, архитектура всех обучаемых моделей представлена в методе CreateDescriptions. В параметрах данного метода добавляем 2 динамических массива для записи архитектуры добавляемых моделей.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В теле метода сразу проверяем полученные указатели и, при необходимости, создаем новые экземпляры объектов динамических массивов, что позволит нам исключить критические ошибки при последующем обращении к указанным массивам.
Первой, как и ранее, мы представим архитектуру планировщика высокого уровня, который отчасти выполняет роль энкодера состояния окружающей среды.
Напомню, что данная модель получает на вход тензор описания состояния окружающей среды. Генерирует матрицу общих навыков в латентном состоянии модели. И прогнозирует описание последующих состояний окружающей среды на заданный горизонт планирования. Для построения прогнозных состояний используется только информация об общих навыках. Таким образом, мы стимулируем модель к созданию наиболее информативного тензора общих навыков.
В качестве первого слоя мы по-прежнему используем полносвязный слой, размер которого достаточен для записи полного тензора описания состояния окружающей среды.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь надо напомнить, что на вход модели подаются "сырые" не обработанные исходные данные, получаемые непосредственно от терминала MetaTrader 5. Это могут быть как последовательности ценовых котировок, так и данные технических индикаторов — от простых скользящих средних до комплексных осцилляторов.
Анализируемые данные, несмотря на свою ценность, обладают крайне различной природой. Их диапазоны, статистические распределения и шумовые характеристики могут значительно отличаться. Без надлежащей предварительной обработки, такая гетерогенность приводит к резкому снижению эффективности обучения моделей. Поэтому следующим шагом становится приведение их в сопоставимый вид. Обычно для этого мы используем слой пакетной нормализации, который позволяет устранить дисбаланс в распределении значений.
Но не сегодня. С целью повышения устойчивости модели и её способности к генерализации, предлагаем усовершенствовать этот этап путём добавления управляемого шума к нормализованным данным. Таким образом, формируется своего рода механизм регуляризации, препятствующий переобучению и повышающий адаптивность модели в условиях реальной рыночной турбулентности.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И лишь затем используем универсальный объект генерации навыков, задачей которого является создание тензора информативных общих навыков для каждого агента. Этот тензор представляет собой концентрированную форму ключевых признаков, способных охарактеризовать поведение и цели агента в текущем контексте рынка. В условиях высокой волатильности и непредсказуемости финансовых инструментов, такая абстракция позволяет усилить устойчивость стратегии, снижая чувствительность к краткосрочным шумам и выбросам.
Важно понимать, что тензор навыков в последующем будет использоваться как часть исходных данных при формировании политики поведения Агента. Его наличие значительно повышает селективную способность модели — позволяет точнее отделять потенциально выгодные действия от бесперспективных. Таким образом, мы переосмысливаем анализируемые данные в терминах задач и компетенций. Речь уже идёт не о классическом «state → action», а об интерпретируемом переходе: «контекст → навык → действие».
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSkillsEncoder; descr.count = HistoryBars; { int temp[] = {BarDescr, NSkills, 4}; // Variables, Common Skills, Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; int prev_out = descr.windows[1]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
С целью повышения эффективности действий агентов с учётом динамики изменения тензора общих навыков, далее добавляем рекуррентный LSTM-блок. Этот элемент архитектуры играет ключевую роль в осмыслении временной структуры наблюдаемых рыночных данных. Финансовые рынки, как известно, обладают сильной зависимостью от прошлых состояний, и значительная часть рыночной логики скрыта именно во временных закономерностях.
Именно здесь LSTM (Long Short-Term Memory) проявляет себя как незаменимый инструмент. Его внутренняя память позволяет сохранять и актуализировать информацию о ключевых рыночных переходах и внутренних закономерностях, не теряя контекст при длительных временных зависимостях. Таким образом модель учится не только распознавать текущие рыночные условия, но и прогнозировать потенциальные развороты или продолжения движения, опираясь на сложную структуру прошлых наблюдений.
Подключение LSTM-блока после слоя генерации навыков — это сознательное архитектурное решение. Сначала модель извлекает абстрактное представление о текущем состоянии и целях агента в виде тензора навыков, а затем, LSTM-блок отслеживает эволюцию этих навыков во времени. Это позволяет агенту воспринимать не только «статичный снимок» рынка, но и наблюдать за тем, как меняется его стратегический профиль во времени — например, как изменяется доминирующий тренд, как формируются уровни поддержки/сопротивления, и как ведёт себя волатильность.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = prev_out; // Common Skkills descr.layers = prev_count; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Затем мы последовательно подключаем два сверточных слоя, каждый из которых играет свою специфическую роль в обработке многомерных временных рядов, поступающих от предыдущих уровней обработки. Эти сверточные слои выполняют функцию своеобразного MLP с независимыми головами прогнозирования, предназначенными для автономного анализа и предсказания продолжения унитарных компонент сложной рыночной последовательности на заданный горизонт планирования.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = 4*NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out=descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Прогнозные значения унитарных последовательностей транспонируем в представление многомерного временного ряда.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
И что немаловажно, после всей этой каскадной обработки и преобразования признаков, мы возвращаем полученные прогнозные значения к масштабу и распределению исходных данных с помощью обратной нормализации. Этот шаг необходим для того, чтобы результаты работы модели находились в понятных и интерпретируемых для торговой среды рамках.
Применение обратной нормализации позволяет сохранить связь между "модельным миром" и реальным рыночным пространством, где каждое значение имеет точный количественный смысл.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count*prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Хочу напомнить, что латентное представление, полученное на выходе блока формирования тензора общих навыков, не является конечным продуктом обработки. Оно представляет собой ценную промежуточную абстракцию, которая будет в дальнейшем многократно использоваться в различных компонентах реализуемого фреймворка Actor-Director-Critic. Именно по этой причине мы сохраняем описание рекуррентного LSTM-блока в локальной переменной, обеспечивая тем самым его доступность для последующих операций.
//--- Latent CLayerDescription *latent = encoder.At(LatentLayer); if(!latent) return false;
Следующим этапом опишем архитектуру низкоуровневого Контроллера. Данный модуль анализирует то же состояние окружающей среды и формирует тензор специфических навыков. Поэтому мы можем просто скопировать из архитектуры предыдущей модели описание первых двух слоев: исходных данных и их нормализации.
//--- Task task.Clear(); //--- Input layer if(!task.Add(encoder.At(0))) { return false; } //--- layer 1 if(!task.Add(encoder.At(1))) { return false; }
Далее используется объект низкоуровневого Контроллера, одной из задач которого является формирование тензора специфических навыков. В отличие от ранее построенного модуля генерации обобщённых навыков с учётом стратегического контекста, Контроллер работает на тактическом уровне, анализируя текущее состояние окружающей среды.
Контроллер не просто реагирует на ситуацию, он активно интерпретирует сложную рыночную среду, извлекая из неё то, что можно назвать краткосрочной «интуицией» агента. На основе этого анализа формируется тензор специфических навыков, отражающий мгновенные предпочтения и действия, которые агент должен предпринять в конкретной ситуации.
Затем происходит объединение трёх информационных потоков:
- Латентного представления общих (высокоуровневых) навыков.
- Тензора специфических (низкоуровневых) навыков.
- Нормализованного описания текущего состояния окружающей среды.
Объединённый тензор служит основой для генерации матрицы действий агентов. Эта структура обеспечивает мощную адаптивность модели: стратегические цели согласуются с тактическими реалиями. Поведенческие паттерны агентов становятся более гибкими, но при этом подчинёнными общей логике торговой политики.
Важно подчеркнуть, что Контроллер — это не просто механизм прогнозирования действия, а семантический связующий элемент между миром высокоуровневых намерений и конкретным рыночным контекстом. Он позволяет агенту адаптироваться к постоянно меняющимся рыночным условиям, сохраняя при этом стратегическую направленность своего поведения.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiSSDLowLevelControler; descr.count = HistoryBars; { int temp[] = {latent.layers, // Variables NSkills, // Task Skills latent.count, // Common Skills NActions, // Action Space 4}; // Heads if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window = 8; descr.step = 1; descr.window_out = 32; prev_count = descr.windows[0]; prev_out = descr.windows[3]; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
Далее переходим к описанию архитектуры модели высокоуровневого Актера, которая отвечает за формирование окончательного торгового решения. В её задачу входит интерпретация матрицы действий, предложенной Контроллером на предыдущем этапе. Иными словами, Актер выступает в роли последней инстанции, которая определяет, какое конкретное поведение будет реализовано в текущем рыночном контексте на основе множества альтернативных тактических сценариев.
Архитектура Актера была полностью заимствована из нашей предыдущей работы. Мы приняли принципиальное решение не добавлять шум к действиям, сгенерированным на основе матрицы возможных альтернатив. В отличие от многих задач в обучении с подкреплением, где добавление шума может способствовать исследованию и вариативности, в условиях финансового рынка даже минимальное искажение финального действия может обернуться катастрофическими последствиями. Изменение в доли объёма позиции, незначительное смещение торговых уровней, а тем более неверно интерпретированная динамика рынка — всё это может привести к существенным убыткам и, как следствие, снижению доверия к системе.
В модель прогнозирования вероятностей направления предстоящего движения мы внесли лишь точечные правки, связанные с переносом латентного состояния Энкодера описания состояния окружающей среды с модуля генерации общих навыков на рекуррентный блок. Это небольшое, но важное изменение направлено на улучшение способности модели учитывать временные зависимости и адаптироваться к изменяющимся условиям рынка в динамике.
Так как в рамках данного раздела статьи мы стремимся сохранить компактность изложения, то полное и подробное описание архитектур указанных моделей решили не приводить. Однако все заинтересованные читатели могут ознакомиться с полным описанием и деталями реализации во вложении к статье.
Практически все описанные выше модели формируют иерархическую структуру Актёра в рамках фреймворка Actor–Director–Critic. Следующим важным компонентом реализуемого фреймворка становится Режиссёр (Director) — специализированная модель, основная задача которой заключается в контекстной классификации действий Актёра на прибыльные и убыточные.
Роль Режиссёра трудно переоценить: он действует как фильтр стратегического качества, отсекающий потенциально убыточные решения ещё до того, как они будут реализованы и приведут к финансовым потерям. В условиях высоковолатильных финансовых рынков, где каждая ошибка может стоить дорого, такой механизм ранней оценки приобретает особую значимость.
Особенность предлагаемого подхода заключается в том, что Режиссёр не просто классифицирует действия, но и генерирует дополнительную обучающую обратную связь. Это ускоряет адаптацию стратегии Актёра, поскольку позволяет ему учитывать сигналы Режиссёра без необходимости многократного накопления негативного опыта. Такой механизм особенно эффективен в условиях, когда цена ошибки высока, а время на обучение ограничено.
В традиционных реализациях на вход Режиссёра подаётся тензор описания состояния окружающей среды, напрямую отражающий наблюдения Агента. Однако, в нашей реализации, Режиссёр получает на вход матрицу общих навыков — информативное латентное представление, сформированное в модуле генерации навыков на выходе LSTM-блока, предварительно обученного извлекать поведенческие паттерны из многомерных временных рядов. Это представление уже учитывает динамику изменений среды, отфильтровано от нерелевантных сигналов и концентрирует в себе наиболее значимые аспекты текущего контекста. Благодаря этому, Режиссёр работает в сжатом, устойчивом пространстве признаков, что существенно повышает точность классификации, улучшает стабильность решений и позволяет адаптироваться к условиям реального рынка в режиме реального времени.
По основному информационному потоку на вход Режиссера подается тензор действий Агента, который мы сразу нормализуем.
//--- Director director.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = NActions; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
Непосредственный анализ предложенных Актёром действий в контексте текущей рыночной ситуации, отражённой в матрице общих навыков, осуществляется в модуле кросс-внимания. Именно здесь происходит смысловое сопоставление между тем, что намерен сделать агент, и что в текущий момент действительно релевантно и оправдано с точки зрения рыночной динамики.
Механизм кросс-внимания позволяет Режиссёру выделить взаимосвязи между отдельными компонентами тензора действий и признаками из матрицы общих навыков. Это особенно важно в условиях высокой волатильности рынков, где простые линейные зависимости уже не работают. Кросс-внимание, по сути, позволяет модели сосредотачиваться на тех аспектах поведения Агента, которые оказываются наиболее критичными в конкретной ситуации.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {3, // Inputs window latent.count // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {NActions/3, // Inputs units latent.layers // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
На выходе модуля кросс-внимания формируется семантически насыщенное представление действия Актера, уже адаптированное к текущему рыночному контексту. Это представление отражает не просто намерение Агента, а его уместность в текущей ситуации, с учётом всей совокупности выявленных паттернов и взаимосвязей между действиями и общими навыками.
Именно это обогащённое контекстом представление становится основой для финального этапа обработки — классификации действия по признаку потенциальной прибыльности.
Процедура классификации реализуется с помощью последовательности из трёх полносвязных нейронных слоёв, каждый из которых снабжён собственной функцией активации, позволяющей внести необходимую нелинейность в обрабатываемые данные. Такой каскад даёт возможность модели гибко аппроксимировать сложные границы принятия решений, формируя более точное разделение между прибыльными и убыточными действиями.
В последнем слое используется сигмовидная функция активации, позволяющая интерпретировать выход модели как вероятностную оценку принадлежности действия к одному из двух классов. Таким образом, модель не просто выносит бинарное решение, но предоставляет оценку уверенности в правильности своей классификации.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 1; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!director.Add(descr)) { delete descr; return false; }
Следует отметить, что модель Критика в рамках данной реализации получила аналогичную архитектуру. Так же, как и в случае с Режиссёром, используется модуль кросс-внимания, который позволяет соотнести действия, предложенные Актёром, с текущим контекстом окружающей среды, представленным через матрицу общих навыков. Это обеспечивает более точную оценку последствий выбранного действия, учитывая сложные зависимости между поведением агента и скрытой динамикой рынка.
Однако, в финальной части архитектуры Критика существует принципиальное отличие. В отличие от Режиссёра, где используется сигмоида для вероятностной интерпретации результата, выходной слой Критика не содержит функции активации. Это обусловлено характером целевой величины — ожидаемого значения накопленного вознаграждения, которое может находиться в широком и, практически неограниченном, диапазоне.
Иными словами, выход Критика — это скалярная оценка полезности предложенного действия в текущем контексте, выраженная в условных единицах ожидаемого дохода. Применение ограничивающей функции активации исказило бы смысл этой величины, обрезая потенциально важные отклонения. Именно поэтому, итоговое значение подаётся напрямую, позволяя модели свободно варьировать оценки в соответствии с обученными представлениями об окружающей среде.
Но это лишь точечная корректировка архитектуры модели. Поэтому мы опустим детальное рассмотрение архитектуры Критика в рамках данной статьи. Полное описание архитектурного решения описанных моделей представлено во вложении и доступно для самостоятельного изучения.
К сожалению, за детальным рассмотрением используемых архитектурных решений мы практически исчерпали объем статьи. Сделаем небольшую паузу, и в следующей статье поговорим о процессе обучения моделей, и оценим эффективность реализованного решения на реальных исторических данных.
Заключение
В данной работе мы познакомились с новым фреймворком Actor-Director-Critic, предназначенным для решения задач с использованием методов глубокого обучения и нейронных сетей. Одним из ключевых аспектов данного фреймворка является введение модели Режиссёра*, который классифицирует действия Актёра в контексте текущего состояния окружающей среды, позволяет существенно повысить эффективность и стабильность процесса обучения.
В практической части статьи мы подробно рассмотрели архитектурные решения обучаемых моделей, которые лежат в основе фреймворка Actor-Director-Critic. Мы детально описали принципы использования различных модулей и представили важные моменты, которые лежат в основе каждой компоненты системы.
В следующей статье мы подробно рассмотрим процесс построения программ для обучения представленных моделей, а также проведем оценку их эффективности на реальных исторических данных.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 4 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования