
Быстрый тестер торговых стратегий на Python с использованием Numba
Почему быстрый собственный тестер стратегий важен
При разработке торговых алгоритмов на основе машинного обучения, важно правильно и быстро оценивать результаты их торговли на истории. Если брать в расчет редкое использование тестера на крупных временных интервалах и с небольшой глубиной истории, то тестер на языке Python вполне подходит. Если же стоит задача многократного тестирования, в том числе высокочастотных стратегий, то интерпретируемый язык может оказаться слишком медленным.
Предположим, что мы не удовлетворены скоростью выполнения некоторых скриптов, но не хотим отказываться от привычной среды разработки Python. Здесь на помощь приходит Numba, которая позволяет транслировать и компилировать нативный Python код в быстрый машинный код на лету, скорость выполнения которого становится сравнима со скоростью выполнения кода таких языков программирования как C и FORTRAN.
Краткое описание библиотеки Numba
Numba — это библиотека для языка программирования Python, предназначенная для ускорения выполнения кода за счет компиляции функций на уровне байт-кода в машинный код с использованием JIT-компиляции (Just-In-Time). Эта технология позволяет значительно повысить производительность вычислений, особенно в научных приложениях, где часто используются циклы и сложные математические операции. Библиотека поддерживает работу с массивами NumPy, а также позволяет эффективно работать с параллелизмом и GPU-вычислениями.
Наиболее распространенный способ использования Numba заключается в применении его коллекции декораторов к Python функциям, чтобы указать Numba на необходимость их компиляции. Когда вызывается функция, декорированная с помощью Numba, она компилируется в машинный код «точно вовремя», благодаря чему весь код или его часть могут выполняться со скоростью нативного машинного кода.
На данный момент поддерживаются следующие архитектуры:
-
OS: Windows (64 bit), OSX, Linux (64 bit).
-
Architecture: x86, x86_64, ppc64le, armv8l (aarch64), M1/Arm64.
-
GPUs: Nvidia CUDA.
-
CPython
-
NumPy 1.22 - 1.26
Стоит учесть, что пакет Pandas не поддерживается библиотекой Numba, и работа с датафреймами будет выполняться с той же скоростью.
Работа с кодами из статьи
Для того чтобы все заработало сходу, сделайте предварительные действия:
- установите все необходимые пакеты;
pip install numpy pyp install pandas pip install catboost pip install scikit-learn pip install scipy
- скачайте данные EURGBP_H1.csv и положите их в папку Files;
- скачайте все скрипты пайтон и положите их в одну папку;
- подкорректируйте первую строчку скрипта Tester_ML.py, что бы было так : from tester_lib import test_model;
- пропишите путь к файлу в скрипте Tester_ML.py;
- p = pd.read_csv('C:/Program Files/MetaTrader 5/MQL5/Files/'EURGBP_H1'.csv', sep='\s+').
Как использовать пакет Numba?
В общем случае использование пакета Numba сводится к его установке
pip install numba conda install numba
и применению декоратора перед функцией, которую мы хотим ускорить, например:
@jit(nopython=True) def process_data(*args): ...
Вызов декоратора осуществляется двумя разными способами.
- nopython mode
- object mode
Первый способ заключается в компиляции декорированной функции таким образом, чтобы она работала полностью без участия интерпретатора Python. Это самый быстрый способ и рекомендован к использованию. Однако Numba имеет ограничения, например, она способна компилировать только встроенные операции Python и операции над массивами Numpy. Если функция содержит объекты других библиотек, например Pandas, то Numba не сможет ее скомпилировать, и код будет выполняться интерпретатором.
Чтобы обойти ограничения на использование сторонних библиотек, Numba может использовать object mode. В этом режиме Numba скомпилирует функцию, предполагая, что все является объектом Python, и по сути запустит код в интерпретаторе. Указание
@jit(forceobj=true, looplift=True) может повысить производительность по сравнению с чистым объектным режимом, поскольку Numba попытается скомпилировать циклы в функции, которые выполняются в машинном коде, и запустит оставшуюся часть кода в интерпретаторе. Для лучшей производительности избегайте использования объектного режима в целом!
Данный пакет также поддерживает параллельные вычисления, когда это возможно (Parallel=True). Обратите внимание на то, что при первом вызове функции происходит компиляция в машинный код, которая занимает определенное время. Затем этот код будет кэширован и последующие вызовы станут быстрее.
Пример ускорения функции разметки сделок
Прежде чем приступать к ускорению тестера, давайте попробуем ускорить что-нибудь более простое. Отличным кандидатом на эту роль выступает функция разметки сделок. Эта функция принимает датафрейм с ценами и размечает сделки на покупку и продажу (0 и 1). Подобные функции часто используются для предварительной разметки данных, чтобы после этого можно было обучить классификатор.
def get_labels(dataset, min = 1, max = 15) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'].iloc[i] future_pr = dataset['close'].iloc[i + rand] if (future_pr + hyper_params['markup']) < curr_pr: labels.append(1.0) elif (future_pr - hyper_params['markup']) > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
В качестве данных используем минутные цены закрытия валютной пары EURGBP за 15 лет:
>>> pr = get_prices() >>> pr close time 2010-01-04 00:00:00 0.88810 2010-01-04 00:01:00 0.88799 2010-01-04 00:02:00 0.88786 2010-01-04 00:03:00 0.88792 2010-01-04 00:04:00 0.88802 ... ... 2024-10-09 19:03:00 0.83723 2024-10-09 19:04:00 0.83720 2024-10-09 19:05:00 0.83704 2024-10-09 19:06:00 0.83702 2024-10-09 19:07:00 0.83703 [5480021 rows x 1 columns]
Датасет содержит более пяти миллионов наблюдений, этого вполне достаточно для тестирования.
Теперь давайте замерим скорость выполнения этой функции на на наших данных:
# get labels test start_time = time.time() pr = get_labels(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Время выполнения составило 74.1843 секунд.
Теперь попробуем ускорить эту функцию при помощи пакета Numba. Видно, что в исходной функции используется также пакет Pandas, а мы знаем, что эти два пакета несовместимы. Давайте вынесем все, что относится к Pandas в отдельную функцию, а остальной код ускорим.
@jit(nopython=True) def get_labels_numba(close_prices, min_val, max_val, markup): labels = np.empty(len(close_prices) - max_val, dtype=np.float64) for i in range(len(close_prices) - max_val): rand = np.random.randint(min_val, max_val + 1) curr_pr = close_prices[i] future_pr = close_prices[i + rand] if (future_pr + markup) < curr_pr: labels[i] = 1.0 elif (future_pr - markup) > curr_pr: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_fast(dataset, min_val=1, max_val=15): close_prices = dataset['close'].values markup = hyper_params['markup'] labels = get_labels_numba(close_prices, min_val, max_val, markup) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) return dataset
Перед первой функцией стоит вызов декоратора @jit. Это значит, что эта функция будет скомпилирована в байт код. Также мы избавились от Pandas внутри нее и используем только списки, циклы и Numpy.
Вторая функция делает подготовительную работу. Она конвертирует Pandas датафрейм в массив Numpy и затем передает его в первую функцию. После этого забирает результат и опять возвращает Pandas датафрейм. Таким образом, основной расчет разметки будет ускорен.
Теперь замерим скорость. Время расчетов уменьшилось до 12 секунд! Для этой функции мы получили ускорение более чем в 5 раз. Конечно это не совсем чистый тест, поскольку библиотека Pandas все равно используется для промежуточных вычислений, тем не менее значительное ускорение было достигнуто в части расчета меток.
Ускорение тестера стратегий для задач машинного обучения
Тестер стратегий я вынес в отдельную библиотеку, которую можно найти в аттаче к статье. Там имеются две функции "tester" и "slow_tester" для сравнения.
У читателя может возникнуть возражение, что большая часть ускорений на Python происходит за счет векторизации. Это действительно так, но иногда все же приходится использовать циклы. Например, в тестере реализован достаточно сложный цикл для прохода по всей истории и накопления суммарной прибыли с учетом стоп-лосс и тейк-профит. Реализовать это посредством векторизации не выглядит простой задачей.Тело цикла тестера (то, что выполняется дольше всего) представлено ниже для ознакомительных целей.
for i in range(dataset.shape[0]): line_f = len(report) if i <= forw else line_f line_b = len(report) if i <= backw else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue
Давайте замерим скорость тестирования на данных, которые получили до этого. Сначала посмотрим на скорость медленного тестера:
# native python tester test start_time = time.time() tester_slow(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['markup'], hyper_params['forward'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 6.8639 seconds Выглядит не очень медленно, можно было бы даже сказать, что интерпретатор исполняет код достаточно быстро.
Разобьем функцию тестера опять на две функции. Одна будет вспомогательной, а вторая будет выполнять основные расчеты.
В функции process data реализован основной цикл тестера, который следует ускорить, поскольку циклы на Python работают медленно. В то же время непосредственно функция tester сначала подготавливает данные для функции process data, затем принимает результат и выполняет отрисовку графика.
@jit(nopython=True) def process_data(close, labels, metalabels, stop, take, markup, forward, backward): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b def tester(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value plot: false/true ''' dataset, stop, take, forward, backward, markup, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data(close, labels, metalabels, stop, take, markup, forw, backw) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.plot(chart) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Теперь протестируем ускоренный посредством Numba тестер стратегий:
start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 0.1470 seconds Прирост скорости почти в 50 раз! При этом было совершено более 400 000 сделок.
Представьте, что если на тестирование своих алгоритмов вы тратили 1 час времени в день, то с быстрым тестером у вас ушла бы всего одна минута.
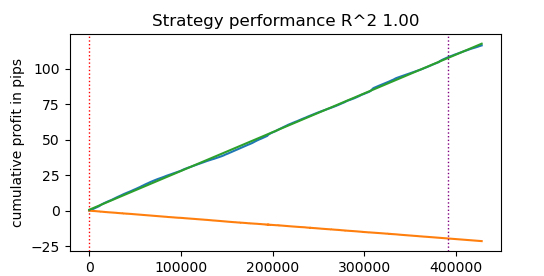
Тестирование стратегий на тиковых данных
Давайте усложним задачу и выгрузим из терминала тиковую историю за последние 3 года в .csv файл.
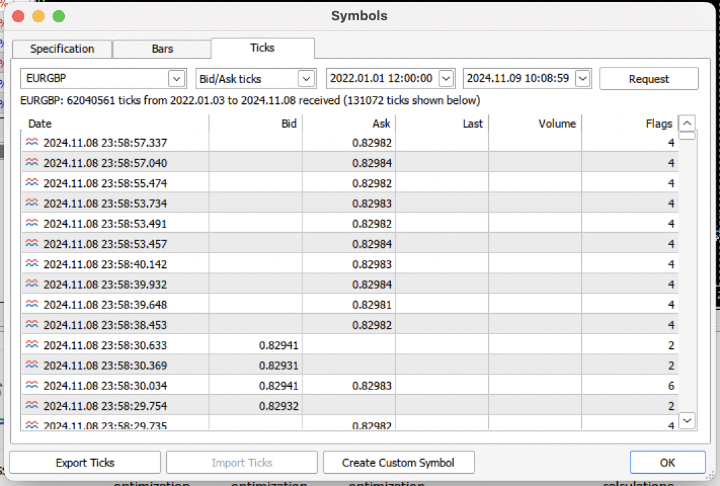
Для правильного чтения файла следует немного модифицировать функцию загрузки котировок. Вместо цен Close будем использовать цены Bid. Еще нужно удалить цены с одинаковыми индексами.
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+') pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<BID>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') # Удаление повторяющихся строк по индексу 'time' pFixed = pFixed[~pFixed.index.duplicated(keep='first')] return pFixed.dropna()
Получилось почти 62 миллиона наблюдений. Стоит отметить, что тестер принимает цены по имени колонки "close", поэтому Bid переименованы в Close.
>>> pr close time 2022-01-03 00:05:01.753 0.84000 2022-01-03 00:05:04.032 0.83892 2022-01-03 00:05:05.849 0.83918 2022-01-03 00:05:07.280 0.83977 2022-01-03 00:05:07.984 0.83939 ... ... 2024-11-08 23:58:53.491 0.82982 2024-11-08 23:58:53.734 0.82983 2024-11-08 23:58:55.474 0.82982 2024-11-08 23:58:57.040 0.82984 2024-11-08 23:58:57.337 0.82982 [61896607 rows x 1 columns]
Запустим быструю разметку и замерим время выполнения.
# get labels test start_time = time.time() pr = get_labels_fast(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Время разметки составило 9.5 секунд.
Теперь запустим быстрый тестер.
# numba tester test start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Время тестирования заняло 0.16 секунд. Тогда как медленный тестер потратил на это 5.5 секунд.
Быстрый тестер на Numba справился в 35 быстрее, чем тестер на чистом Python. Фактически, с точки зрения наблюдателя, тестирование происходит мгновенно в случае быстрого тестера, тогда как в случае медленного — существует момент ожидания. Все же стоит отдать должное медленному тестеру, который тоже неплохо справляется и вполне пригоден для тестирования стратегий даже на тиковых данных.
Всего получилось 1e6 или миллион сделок.
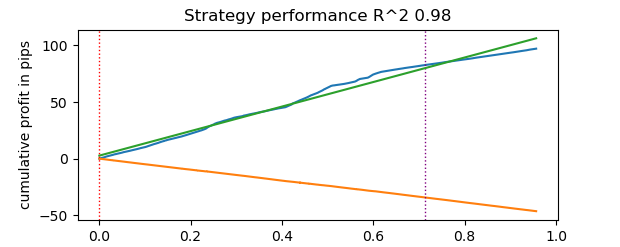
Информация по использованию быстрого тестера для задач машинного обучения
Если вы действительно собираетесь использовать предложенный тестер, то следующая информация может оказаться для вас полезной.
Давайте добавим признаки в наш датасет, чтобы была возможность обучать классификатор.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC-pFixedC.rolling(i).mean() count += 1 return pFixed.dropna()
Это простые признаки, основанные на разнице цен и скользящих средних.
Затем создадим словарь гиперпараметров модели, которые будут использоваться при обучении и тестировании. И используем их для генерации нового датасета.
hyper_params = {
'symbol': 'EURGBP_H1',
'markup': 0.00010,
'stop_loss': 0.01000,
'take_profit': 0.01000,
'backward': datetime(2010, 1, 1),
'forward': datetime(2023, 1, 1),
'periods': [i for i in range(50, 300, 50)],
}
# catboost learning
dataset = get_labels_fast(get_features(get_prices()))
dataset['meta_labels'] = 1.0
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() Здесь следует обратить внимание на то, что тестер принимает не только значения меток "labels", но и значения меток "meta_labels". Для чего же они нужны? Они нужны для того, если вы захотите использовать фильтры для своей торговой системы, основанной на машинном обучении. Тогда значение 1 будет разрешать торговлю, а значение 0 будет ее запрещать. Поскольку в данном демонстрационном примере мы не будем использовать фильтры, то просто создадим дополнительный столбец и заполним его единицами, всегда разрешая торговлю.
dataset['meta_labels'] = 1.0
Теперь мы можем обучить модель CatBoost на сформированном датасете, предварительно удалив из истории тестовые данные forward и backward, чтобы она на них не обучалась.
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) model = CatBoostClassifier(iterations=500, thread_count=8, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False)
После обучения протестируем модель на всем датасете, включая тестовые данные. Функция test_model расположена в файле tester_lib.py вместе с функциями непосредственно быстрого и медленного тестера. Она является оберткой для быстрого тестера и выполняет задачу получения предсказанных значений обученной модели машинного обучения (в нашем случае это CatBoost, но может быть любая другая).
def test_model(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, plt = False): ext_dataset = dataset.copy() X = ext_dataset[dataset.columns[1:-2]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] # ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) # ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(ext_dataset, stop, take, forward, backward, markup, plt)
В коде выше закомментированы строки, которые позволяют получать мета метки, отвечающие за указание на торговать/не торговать. То есть может использоваться вторая модель машинного обучения для этих целей. В данной статье не используется.
Запустим непосредственно тестирование.
# test catboost model test_model(dataset, [model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True)
И получим результат. Модель переобучена, это видно на тестовых данных справа от вертикальной черты. Но для нас это не важно, потому что мы тестируем тестер.
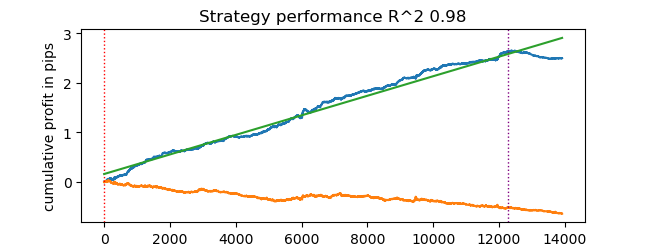
Поскольку тестер подразумевает возможность использования стоп-лосс и тейк-профит, и вы можете захотеть их оптимизировать, то давайте использовать оптимизацию, ведь наш тестер теперь очень быстрый!
Оптимизация параметров торговой системы на машинном обучении
Теперь давайте рассмотрим возможность оптимизации стоп-лосс и тейк-профит. На самом деле можно оптимизировать и другие параметры торговой системы, например мета-метки, но это выходит за рамки данной статьи и может быть рассмотрено в следующей.
Мы реализуем два вида оптимизации:
- Поиск по сетке параметров
- Оптимизация методом L-BFGS-B
Давайте сначала кратко пробежимся по коду каждого метода. Ниже представлен метод GRID_SEARCH.
В качестве аргументов он принимает:
- датасет для тестирования
- обученную модель
- словарь, содержащий гиперпараметры алгоритма, описанный выше
- объект тестера
# stop loss / take profit grid search def optimize_params_GRID_SEARCH(pr, model, hyper_params, test_model_func): best_r2 = -np.inf best_stop_loss = None best_take_profit = None # Диапазоны для stop_loss и take_profit stop_loss_range = np.arange(0.00100, 0.02001, 0.00100) take_profit_range = np.arange(0.00100, 0.02001, 0.00100) total_iterations = len(stop_loss_range) * len(take_profit_range) start_time = time.time() for stop_loss in stop_loss_range: for take_profit in take_profit_range: # Создаем копию hyper_params current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = stop_loss current_hyper_params['take_profit'] = take_profit r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) if r2 > best_r2: best_r2 = r2 best_stop_loss = stop_loss best_take_profit = take_profit end_time = time.time() total_time = end_time - start_time average_time_per_iteration = total_time / total_iterations print(f"Total iterations: {total_iterations}") print(f"Average time per iteration: {average_time_per_iteration:.6f} seconds") print(f"Total time: {total_time:.6f} seconds") return best_stop_loss, best_take_profit, best_r2
Теперь давайте рассмотрим код метода L-BFGS_B. Для более детального ознакомления с ним можете перейти по ссылке.
Аргументы для функции остались прежними. Но в ней создается фитнес-функция, через которую вызывается тестер стратегий. Задаются границы параметров оптимизации и количество начальных инициализаций (случайных точек множества параметров) для алгоритма L-BFGS_B. Случайные инициализации нужны для того чтобы алгоритм оптимизации не застревал в локальных минимумах. После этого вызывается функция minimize, которой передаются параметры самого оптимизатора.
def optimize_params_L_BFGS_B(pr, model, hyper_params, test_model_func): def objective(x): current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = x[0] current_hyper_params['take_profit'] = x[1] r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) return -r2 bounds = ((0.001, 0.02), (0.001, 0.02)) # Попробуем несколько случайных начальных точек n_attempts = 50 best_result = None best_fun = float('inf') start_time = time.time() for _ in range(n_attempts): # Случайная начальная точка x0 = np.random.uniform(0.001, 0.02, 2) result = minimize( objective, x0, method='L-BFGS-B', bounds=bounds, options={'ftol': 1e-5, 'disp': False, 'maxiter': 100} # Увеличиваем точность и число итераций ) if result.fun < best_fun: best_fun = result.fun best_result = result # Получаем время окончания и вычисляем общее время end_time = time.time() total_time = end_time - start_time print(f"Total time: {total_time:.6f} seconds") return best_result.x[0], best_result.x[1], -best_result.fun
Теперь можно запустить оба алгоритма оптимизации и посмотреть на время выполнения и точность.
# using
best_stop_loss, best_take_profit, best_r2 = optimize_params_GRID_SEARCH(dataset, model, hyper_params, test_model)
best_stop_loss, best_take_profit, best_r2 = optimize_params_L_BFGS_B(dataset, model, hyper_params, test_model) Алгоритм Grid search:
Total iterations: 400 Average time per iteration: 0.031341 seconds Total time: 12.536394 seconds Лучшие параметры: stop_loss=0.004, take_profit=0.002, R^2=0.9742298702323458
Алгоритм L-BFGS-B:
Total time: 4.733158 seconds Лучшие параметры: stop_loss=0.0030492548809269732, take_profit=0.0016816794762543421, R^2=0.9733045271274298
При моих стандартных настройках L-BFGS-B справился более чем в 2 раза быстрее, показав результат сопоставимый с алгоритмом поиска по сетке.
Таким образом, можно использовать оба этих алгоритма и выбирать лучший, в зависимости от количества и диапазона оптимизируемых параметров.
Заключение
В данной статье продемонстрирована возможность ускорения тестера стратегий, с помощью которого можно быстро тестировать стратегии, основанные на машинном обучении. Показано, что Numba дает прирост скорости в 50 раз. Тестирование становится быстрым, это позволяет делать множественные тесты и даже оптимизацию параметров.
К статье прикреплены:
- tester_lib.py - библиотека тестера
- test tester.py - скрипт для сравнения медленного (Python) и быстрого (Numba) тестеров
- tester ticks.py - скрипт для сравнения тестеров на тиковых данных
- tester ML.py - скрипт для обучения классификатора и оптимизации гиперпараметров
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Ну, стандартное отклонение в скользящем окне фиксированной величины будет иметь ненормированный диапазон изменений в зависимости от волатильности. Насколько я знаю, обычно для этого используют z-score, т.к. это нормированная величина. На этом мысль закончена )
Понял, я беру min/max по всей доступной истории и устанавливаю в качестве границ, потом разбиваю на случайные диапазоны на каждой итерации оптимизатора. Можно и зскор. Я думал для оптимизатора может быть лучше такое нормирование (избавление от маленьких значений с большим кол-вом нулей после запятой), но вроде не должно.
Привет maxim, я думаю ты самый умный человек на форуме, надеюсь увидеть подробное описание во второй статье. благодарный
Спасибо за лестный отзыв, я постараюсь написать что-нибудь интересное для вас.
Появилось время и почти доделал обучение моделей + оптимизацию гиперпараметров в одном флаконе.
Можно будет обучать сразу множество моделей, затем их оптимизировать, затем выбирать лучшую модель с лучшими параметрами оптимизации, например:
И выводить результат.
Затем модель можно будет экспортировать в терминал с уже оптимальными гиперпараметрами. Либо использовать оптимизатор самого терминала.
Позже начну статью, не забыл.