
Причинно-следственный вывод в задачах классификации временных рядов
Содержание статьи:
- Введение
- Экскурс в историю причинно-следственного вывода
- Основы причинно-следственного вывода в машинном обучении
- Evidence Ladder в причинно-следственном выводе
- Нотация в причинно-следственном выводе
- Предвзятость или смещение (bias)
- Рандомизированные эксперименты
- Матчинг
- Неопределенность
- Мета-лернеры
- Пример построения торговой системы
В предыдущей статье мы подробно рассмотрели обучение через мета-лернер и кросс-валидацию, и сохранение моделей в формат ONNX. Также вы узнали, что модели машинного обучения не способны “из коробки” искать закономерности в разрозненных и противоречивых данных. В этом случае очень важно, что именно подается на вход и выход нейросети или любого другого алгоритма машинного обучения.
С другой стороны, мы не всегда можем подготовить необходимые данные для обучения, структура которых уже содержит причинно-следственные связи. Как правило, это набор индикаторов и примеры в каких случаях нужно покупать, а в каких продавать. Часто используется знак приращений, зигзаг, либо положение скользящих средних относительно друг друга, для задания направления будущей сделки. Все эти виды разметок не являются экспертными и, как правило, не содержат истинных причинно-следственных связей.
Разметка данных в мире машинного обучения является, пожалуй, самым дорогим и затратным по времени и ресурсам процессом, который требует привлечения специалистов в исследуемой области, так называемых аннотаторов. Даже такие мощные языковые нейронные сети как GPT и их аналоги, обучающиеся на больших объемах данных, способны классифицировать только языковые паттерны, которые формируют смысловой контекст, но не отвечают на вопрос: является ли какое-то конкретное утверждение истинным или ложным на самом деле. Группы аннотаторов работают с этими моделями, корректируя их ответы таким образом, чтобы они стали полезными для конечного пользователя.
В этом случае у трейдера возникает резонный вопрос: если я знаю как разметить данные, тогда зачем мне нужна нейросеть? Ведь я могу просто написать логику на основе своих знаний и эффективно ее использовать. И он окажется прав и неправ одновременно. Неправ он будет в том, что нейросеть прекрасно справляется с задачей предсказания, поэтому достаточно обучить ее на хорошо размеченных данных и затем получать предсказания на новых, не утруждая себя написанием логики торговой стратегии. Более того, встроенный функционал позволяет оценить надежность предсказаний на новых данных. А прав он, разумеется, в том, что не зная, что подать на вход нейросети или подавая на выход некорректно размеченные данные, по умолчанию она не сможет создать для него прибыльную торговую стратегию.
Понимание вышеизложенных проблем машинного обучения пришло к трейдерам не сразу. Ведь изначально даже создатели первых простых алгоритмов машинного обучения свято верили, что математический аналог нейрона копирует работу нейронов головного мозга, а значит достаточно большая нейросеть сможет полностью выполнять функции работы мозга и научиться анализировать информацию самостоятельно. Позже пришло понимание, что в мозге существует большое количество узкоспециализированных отделов, каждый из которых обрабатывает определенную информацию и передает ее в другие отделы. Так возникли многослойные архитектуры нейронных сетей, благодаря которым исследователи еще больше приблизились к разгадке тайн работы мозга. Такие архитектуры научились прекрасно обрабатывать специфическую информацию, например визуальную, текстовую, звуковую или табличные данные.
Как выяснилось позже, такие нейросети тоже не обладают способностью к самостоятельным умозаключениям относительно истинных закономерностей, обучаясь с учителем. И склонны к переобучению и субъективизму.
Следующим шагом на пути познания устройства и функционирования мозга явилось открытие того факта, что естественные нейросети работают по принципу обучения с подкреплением, а не только по принципу обучения на готовых образцах. Это такое обучение, при котором сложная система получает вознаграждение за субьективно правильные решения и штрафуется за неправильные. После многократного получения таких вознаграждений, в зависимости от поставленной задачи, накапливается опыт и происходит обучение субъективно правильным вариантам ответов. Мозг или нейросеть начинает реже ошибаться в тех или иных случаях, если уже встречали их до этого.
Знание этого привело к появлению обучения с подкреплением, когда исследователь сам задает функцию вознаграждения (некий аналог фитнес функции в алгоритмах оптимизации), поощряя или наказывая нейросеть за правильные или неправильные ответы. Теперь алгоритм машинного обучения уже не обучается на готовых, хорошо размеченных данных, а действует методом проб и ошибок, стараясь максимизировать функцию вознаграждения. На текущий момент существует большое количество алгоритмов обучения с подкреплением для разных задач, и эта область довольно активно развивается.
И это казалось прорывом до тех пор, пока не стало применяться в том числе для задач классификации финансовых временных рядов. Стало понятно, что такое обучение очень сложно контролировать, поскольку теперь все упирается в задание правильной функции вознаграждения и выбор правильной архитектуры сети. Все та же банальная проблема: если вы не знаете истинную целевую функцию, которая описывает реальные причинно-следственные связи между состояниями системы и ее ответами, то вряд ли найдете ее путем многочисленных переборов как самой целевой функции, так и разных алгоритмов обучения с подкреплением. Разве только вам не повезет.
Примерно такая же история произошла с генеративными моделями, которые обучаются условно без учителя. Построенные по принципу кодировщика - декодировщика или генератора - дискриминатора, они учатся сжимать информацию, выделяя важные признаки, либо отличать реальные образцы от фиктивных (в случае состязательных нейросетей), а затем генерировать правдоподобные примеры, например изображения. Если с изображениями все более-менее понятно и они являются своего рода правдоподобным “бредом” нейронной сети, то с генерированием точных непротиворечивых ответов все намного сложнее. Элемент случайности, заложенный в генерацию того или иного ответа, не позволяет делать однозначные выводы о причинно-следственных связях, что не подходит для такого рискованного занятия как трейдинг, где случайное поведение алгоритма равносильно получению убытков.
Автор статьи попробовал все эти алгоритмы для задач классификации временных рядов, в частности валютных пар “Форекс” и не слишком удовлетворился результатами.
В последнее время все чаще можно встретить публикации на тему так называемого “надежного” или “внушающего доверия” машинного обучения. В целом, набор подходов еще не до конца сформирован и варьируется от области к области. Важно понимать, что там затрагивается проблема причинно-следственного вывода посредством алгоритмов машинного обучения. Исследователи научились понимать и доверять машинному обучению уже настолько, что готовы возложить на него задачу поиска причинно-следственных связей в данных, что, конечно, выводит машинное обучение на совершенно новый уровень развития. Причинно-следственный вывод широко применяется в таких областях как медицина, эконометрика и маркетниг.
Эта статья как раз является описанием попытки осмысления некоторых техник causal inference применительно к алготорговле.
Экскурс в историю причинно-следственного вывода
Причинность имеет долгую историю и рассматривалась в большинстве, если не во всех известных нам развитых культурах.
Аристотель - один из самых плодовитых философов Древней Греции - утверждал, что понимание причинно-следственной структуры процесса является необходимым компонентом знания об этом процессе. Более того, он утверждал, что способность отвечать на вопросы типа "почему" — это суть научного объяснения. Аристотель выделяет четыре типа причин (материальные, формальные, эффективные и конечные), и эта идея, которая может отражать некоторые интересные аспекты реальности, хотя для современного человека она может звучать контринтуитивно.
David Hume, знаменитый шотландский философ XVIII века, предложил более унифицированную схему для причинно-следственных связей. Хьюм начал с утверждения, что мы никогда не наблюдаем причинно-следственных отношений в мире. Единственное, что мы наблюдаем — это то, что некоторые события связаны между собой: "Мы обнаруживаем лишь, что одно из них действительно следует за другим. Импульс одного бильярдного шара сопровождается движением второго. Таково целое, которое представляется внешним органам чувств. Разум не испытывает никаких чувств или внутренних впечатлений от этой последовательности объектов: следовательно, в каждом конкретном явлении нет ничего, что могло бы навести на мысль о силе или необходимой связи".
Одна из интерпретаций теории причинности Хьюма заключается в следующем:
- Мы наблюдаем только, как движение или появление объекта А предшествует движению или появлению объекта B.
- Если мы наблюдаем такую последовательность достаточное количество раз, у нас возникает чувство ожидания.
- Это чувство ожидания - суть нашей концепции причинности (дело не в мире; речь идет о чувстве, которое мы развиваем)
Эта теория очень интересна, по крайней мере, с двух точек зрения. Во-первых, элементы этой теории имеют большое сходство с идеей в психологии под названием обусловливание. Обусловленность — это форма обучения. Существует множество типов обусловливания, но все они все они опираются на общую основу - ассоциацию (отсюда и название этого типа обучения - ассоциативное обучение). При любом типе обусловливания мы берем какое-то событие или объект (обычно называемый стимул) и связываем его с определенным поведением или реакцией. Ассоциативное обучение работает у разных видов животных. Его можно обнаружить у людей, обезьян, собак и кошек, а также у гораздо более простых организмов, таких как улитки.
Во-вторых, большинство классических алгоритмов машинного обучения также работают на основе ассоциаций. Когда мы обучаем нейронную сеть c учителем, мы пытаемся найти функцию, которая сопоставляет входные данные с выходными. Чтобы сделать это эффективно, нам нужно выяснить, какие элементы входных данных полезны для предсказания выходных. И в большинстве случаев для этой цели достаточно ассоциации.
Дополнительные сведения о возможностях исследования нами причинно-следственных связей приходят из детской психологии.
Элисон Гопник - американский детский психолог, изучающая, как у младенцев формируются модели мира. Она также сотрудничает с учеными-компьютерщиками, помогая им понять, как человеческие младенцы строят здравые понятия о внешнем мире. Дети - в еще большей степени, чем взрослые, - используют ассоциативное обучение, но они также являются ненасытными экспериментаторами. Вы когда-нибудь видели, как родители пытаются убедить своего ребенка перестать разбрасывать игрушки? Некоторые родители склонны интерпретировать такое поведение как грубое, разрушительное или агрессивное, но у малышей часто бывают другие мотивы. Они проводят систематические эксперименты, которые позволяют им изучать законы физики и правила социального взаимодействия (Gopnik, 2009). Младенцы в возрасте 11 месяцев предпочитают проводить эксперименты с объектами, которые проявляют непредсказуемые свойства, чем с объектами, которые ведут себя предсказуемо (Stahl & Feigenson, 2015). Это предпочтение позволяет им эффективно строить модели мира.
Что мы можем узнать от младенцев, так это то, что мы не ограничиваемся наблюдением за миром, как предполагал Юм. Мы можем также взаимодействовать с ним. В контексте причинно-следственных выводов эти взаимодействия называются вмешательствами. Вмешательства лежат в основе того, что многие считают Святым Граалем научного метода: рандомизированное контролируемое исследование, или сокращенно РКИ.
Но как же отличить ассоциацию от реальной причинно-следственной связи? Давайте попробуем разобраться.
Основы причинно-следственного вывода в машинном обучении
Основной задачей причинно-следственного вывода в машинном обучении является определение того, можем ли мы принимать решения на основе обученного алгоритма машинного обучения. Здесь нас не всегда интересует точность и частота предсказаний, хотя это тоже важно, а нас больше интересует их стабильность и наш уровень доверия к ним.
Главный тезис причинно-следственного вывода гласит: “Корреляция не подразумевает причинно-следственную связь”. Это означает, что корреляция не доказывает влияние одного события на другое, а лишь определяет линейную связь этих двух или более событий.
Стало быть, причинно-следственная связь определяется через влияние одной переменной на другую. Влияющую переменную часто называют инструментальной в случае стороннего вмешательства, или просто одним из ковариатов (признаков в машинном обучении). Либо через какое-то действие на другое действие. В общем, действительно ли после события А всегда следует событие Б. Либо действительно ли событие А вызывает событие Б. Поэтому это еще называют A/B тестированием. Это именно то, с чем мы будем иметь дело в дальнейшем, но с использованием алгоритмов машинного обучения.
Существует некоторое количество подходов, позволяющих приблизиться к выводу причинно-следственной связи как с помощью рандомизированных экспериментов, так и с использованием инструментальных переменных и машинного обучения. Перечислять все способы здесь не имеет смысла, поскольку этому посвящены отдельные сборники. Нас интересует то, как мы можем применить это к задаче классификации временных рядов.
Важно отметить, что практически все эти способы основаны на причинно-следственной модели Неймана-Рубина, или модели потенциальных результатов (исходов). Это статистический подход, помогающий определить, действительно ли одно событие является следствием другого.
Например, обученный классификатор показывает прибыль на тренировочной и валидационной подвыборках, тогда как на тестовой подвыборке его сигналы приводят к убыткам. Чтобы измерить причинно-следственный эффект на новых данных с использованием этого классификатора, нам нужно сравнить результаты на новых данных в том случае, если он действительно был обучен и в том случае, если он обучен не был. Поскольку невозможно увидеть результаты не обученного классификатора, потому что он не формирует никаких сигналов на покупку и продажу, то этот потенциальный результат неизвестен. Мы имеем только фактический результат после его обучения, а неизвестный результат без обучения является контрфактическим. То есть, нам нужно выяснить, приводит ли обучение классификатора к увеличению прибыли или к получению прибыли на новых данных по сравнению с, допустим, случайным открытием сделок. То есть, дает ли обучение классификатора вообще хоть какой-то положительный эффект.
Эта дилемма - «фундаментальная проблема причинного-следственного вывода», когда мы не знаем, какой в действительности результат был бы в случае отсутствия обучения классификатора, а знаем только фактический результат после его обучения.
Из-за фундаментальной проблемы причинно-следственного вывода причинные эффекты на уровне единицы (одного обучающего примера) не могут быть непосредственно наблюдаемы. Мы не можем с уверенностью сказать, улучшились ли наши предсказания, потому что нам не с чем сравнивать. Однако рандомизированные эксперименты позволяют оценить причинно-следственные эффекты на популяционном уровне. В ходе рандомизированного эксперимента классификаторы случайным образом обучаются на разных подвыборках. Из-за этого случайного распределения обучающих примеров результаты предсказаний классификаторов (в среднем) эквивалентны, и разницу в предсказаниях классификаторов для конкретных примеров можно отнести к случаю, когда примеры из тестовой выборки попали или не попали в обучающие примеры. Затем можно получить оценку среднего причинно-следственного эффекта (также называемого средним эффектом лечения) путем вычисления разницы средних результатов между леченными (с обученным классификатором на этих данных) и контрольными (с не обученным классификатором на этих данных) образцами.
Либо представьте, что существует мультивселенная и в каждой из подвселенных живет один и тот же человек, который принимает разные решения, которые приводят к разным результатам (исходам). Каждый человек знает только свой вариант будущего и не знает вариантов будущего других себя в других вселенных.
В примере с мультивселенными мы предполагаем, что все люди имеют своих двойников в других вселенных. Все люди, в среднем, похожи. Это означает, что мы можем сравнить причины принимаемых ими решений с результатами этих решений. Таким образом, основываясь на этих знаниях, можно будет сделать причинно-следственный вывод о том, что бы произошло с конкретным человеком в другой вселенной, поступи он тем или иным образом, которым еще ни разу там не поступал. Если, конечно, эти вселенные похожи.
Доказательная лестница (Evidence Ladder) в причинно-следственном выводе
Существует некоторая систематизация методов причинно-следственного вывода, которая представляет собой иерархию методов по их доказательной способности. Это поможет выяснить, какой доказательной силой будет обладать выбранный нами метод. Здесь я приведу свой вольный перевод статьи, оригинал которой вы можете прочесть выше по ссылке.

- На верхней ступени лестницы расположены естественные эксперименты.
Такие, которым вас наверняка учили в средней или даже начальной школе. Чтобы объяснить, как должен проводиться научный эксперимент, учитель биологии заставил нас взять семена из коробки, разделить их на две группы и посадить в две банки. Учитель настоял на том, чтобы условия в двух банках были полностью идентичными: одинаковое количество семян, одинаковое увлажнение почвы и т. д. Задача состояла в том, чтобы измерить влияние света на рост растений, поэтому мы поставили одну банку у окна, а другую закрыли в шкафу. Через две недели на всех банках, стоящих у окна, появились маленькие бутоны, а на тех, что мы оставили в шкафу, они почти не выросли. Учитель объяснил, что единственным различием между двумя банками было воздействие света, и мы могли сделать вывод, что недостаток света привел к тому, что растения не растут.
В принципе, это самый строгий метод, который вы можете использовать, когда хотите узнать причину. Плохая новость заключается в том, что эта методология применима только в том случае, если у вас есть определенный уровень контроля как над лечебной группой (той, которая получает свет), так и над контрольной (той, которая находится в шкафу). Достаточный контроль, по крайней мере, чтобы все условия были строго идентичны, кроме одного параметра, с которым вы экспериментируете (свет в данном случае). Очевидно, что это не применимо ни в социальных науках, ни в науке о данных.
Тогда почему автор включил его в эту статью? Ну, в основном потому, что это эталонный метод. Все методы вывода причинно-следственных связей — это в некотором роде хаки, призванные воспроизвести эту простую методологию в условиях, в которых вы не смогли бы сделать выводы, если бы строго следовали правилам, объясненным вашим учителем в средней школе.
- Статистические эксперименты (А/Б тесты)
Вероятно, самый известный метод причинно-следственных связей: A/B-тесты, они же рандомизированные контролируемые эксперименты. Идея статистических экспериментов заключается в том, чтобы полагаться на случайность и размер выборки, чтобы смягчить невозможность поместить лечебную и контрольную группы в абсолютно одинаковые условия. Фундаментальные статистические теоремы, такие как закон больших чисел, центральная предельная теорема или байесовский вывод, дают гарантии того, что это сработает, и способ вывести оценки и их точность из собранных данных.
- Квазиэксперименты
Квазиэксперимент — это ситуация, когда ваша группа лечения и контрольная группа разделены естественным процессом, который не является действительно случайным, но может считаться достаточно близким для вычисления оценок. На практике это означает, что у вас будут разные методы, которые будут соответствовать разным предположениям о том, насколько "близко" вы находитесь к ситуации A/B-теста. Среди известных примеров естественных экспериментов: использование призывной лотереи во время войны во Вьетнаме для оценки влияния принадлежности к ветеранам на ваш заработок или границы между Нью-Джерси и Пенсильванией для изучения влияния минимальной заработной платы на экономику.
- Контрфактические методы
Тут мы отказываемся от идеи тритмент и контрольной групп (на самом деле, не совсем), и, по сути, моделируем временной ряд Y по историческим данным без участия Х в будущее, где Х уже вступает в игру. Таким образом, в период проведения эксперимента мы сможем сравнить фактические данные Y (где Х участвовал) с модельными (прогноз Y без участия Х) и предположить размер эффекта, скорректировав его на точность модели для Y. Однако, чтобы это предположение оказалось близким к правде, нам нужно сделать наибольшее количество тестов на устойчивость метода. Результирующий эффект будет критически зависеть не только от качества модели, но и в целом от корректности применения выбранного метода.
Строя модель классификации временного ряда, мы можем воспользоваться только контрфактическими методами. То есть нам нужно самим придумать инструментальную переменную или тритмент, применить его к нашим наблюдениям, а затем провести соответствующие тесты на устойчивость этого метода, чем мы в дальнейшем и займемся. Очевидно, что это самый сложный подход, который обладает наименьшей доказательной силой по версии Evidence Ladder.
Нотация в причинно-следственном выводе
Мы договорились, что под “лечением” T понимается некоторое воздействие на объект, будь то пациент клиники, человек под воздействием рекламной кампании или же некоторый сэмпл из обучающей выборки; тогда существует два варианта. Либо исследуемый объект получил лечение, либо нет.

Также мы уже знаем, что каждый объект (юнит) не может быть одновременно подвергнут и не подвергнут лечению. То есть может быть что-то одно из двух.
Таким образом,
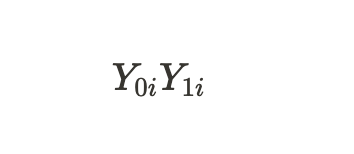
обозначают потенциальные исходы для юнита без лечения и для юнита с лечением. Можно посчитать индивидуальный лечебный эффект через разницу этих потенциальных исходов:
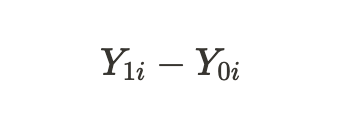
В связи с фундаментальной проблемой причинно-следственного вывода, которая была указана выше, мы не можем получить индивидуальный эффект лечения, поскольку известен только один из исходов, но мы можем посчитать средний лечебный эффект по всем аналогичным объектам, часть из которых получила лечение, а часть нет:
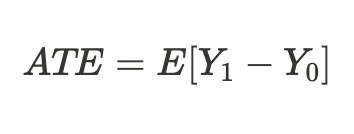
Либо можно получить средний лечебный эффект только для юнитов, которые подверглись лечению:
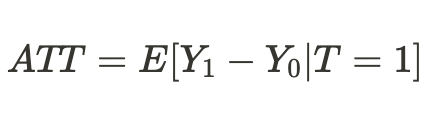
Предвзятость или смещение (bias)
Предвзятость — это то, что отличает корреляцию (ассоциативную связь) от каузальной (причинно-следственной). Что, если в другой вселенной наши двойники попали в совершенно другие условия существования, и результаты принимаемых ими решений уже не будут соответствовать тем, к которым мы привыкли в этой вселенной. Тогда выводы о возможных исходах окажутся ошибочными, а предположения будут лишь ассоциативными, но не причинно-следственными связями.
Это справедливо и для обученных классификаторов, когда они перестают приносить прибыль на новых данных, которые раньше не видели. Либо просто перестают корректно предсказывать.
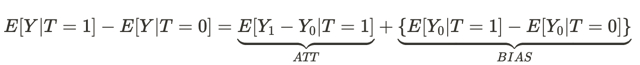
Это уравнение отвечает на вопрос, почему ассоциативная связь не является причинно-следственной связью. Предвзятость здесь — это насколько условия жизни людей в разных вселенных отличаются до того, как они произвели какое-то действие в обеих вселенных. Это происходит из-за того, что существует множество других переменных, которые влияют на результат принимаемого ими решения. Как итоговый результат, популяции людей в одной вселенной и в другой вселенной отличаются не только тем, что принимаются разные решения, но и другими условиями существования.
Отсюда получается, что если условия существования нас в разных вселенных оказались сопоставимыми, то наш вывод относительно результатов наших действий (в среднем) в другой вселенной окажется причинно-следственным:
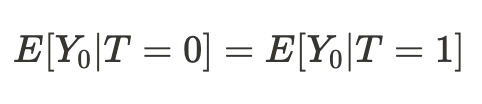
Соответсвенно, разница средних теперь становится средним причинно-следственным эффектом:
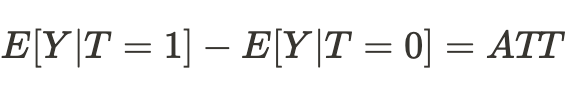
Мы можем сделать простой вывод, что для оценки причинно-следственного эффекта, выборка из одной вселенной должна быть сопоставима с выборкой из другой вселенной. Если это так, то мы сможем определить истинную взаимосвязь и с большой долей вероятности сможем предсказать результат действия нас самих же, но в другой вселенной.
Иными словами, ассоциативная связь становится причинно-следственной, когда bias или предвзятость равен или равна нулю.
Переводя вышесказанное в термины машинного обучения, обычно мы имеем дело с тренировочными и валидационными данными, а также тестовыми. Модель машинного обучения обучается на тренировочных данных, с частичным участием данных валидационных. Если подвыборки сопоставимы, то мы будем иметь примерно одинаковые ошибки предсказания на тренировочных и валидационных данных. Если же подвыборки отличаются на условный bias, то ошибка предсказания на валидационных данных окажется больше. Не говоря уже о тестовой подвыборке, распределение данных которой может быть и вовсе не похоже на распределения первых двух.
Но как же мы, в таком случае, можем сделать причинно-следственный вывод, если распределения подвыборок отличаются? Частично ответ был уже дан в предыдущем разделе: мы можем сделать причинно-следственный вывод в ходе рандомизированного эксперимента.
Рандомизированные эксперименты
Как уже стало ясно, рандомизация позволяет случайным образом разделить данные на группы, над одной из которых было проведено “лечение” (в нашем случае - обучение модели), а над другой нет. Более того, нам следует сделать это несколько раз и обучить много моделей. Это необходимо для того, чтобы исключить предвзятость (bias) из наших оценок. Рандомизация и обучение нескольких классификаторов убирает зависимость потенциальных исходов от одной конкретной модели машинного обучения.
Сначала это может немного вас запутать, ведь разве отсутствие зависимости исходов (предсказаний) от конкретной модели не делает обучение этой модели бесполезным? С точки зрения предсказаний данной конкретной модели да, но мы ведь имеем дело с потенциальными исходами (предсказаниями).
Потенциальный исход — это то, каким бы был исход в случае обучения модели, или в случае отсутствия ее обучения. В рандомизированных экспериментах мы не хотим, чтобы исход (прогноз) не зависел от обучения, поскольку обучение модели напрямую влияет на исход.
Но мы хотим, чтобы потенциальные исходы были бы независимыми от обучения какого-то конкретного классификатора, который является предвзятым!
Говоря таким образом, мы подразумеваем, что хотим, чтобы потенциальные исходы были бы теми же самыми для контрольной и тестовой групп. Наши обучающие и тестовые данные должны быть сопоставимыми, потому что мы хотим исключить предвзятость из оценок. Но каждый отдельный классификатор придает разные веса разным обучающим примерам, даже если они перемешаны, что делает неодинаковой величину тритмента для каждого наблюдения. Это затрудняет причинно-следственный вывод.
Рандомизация обучающих примеров позволяет нам оценить эффект от тритмента (обучения), путем получения разницы ошибок модели на тестовой и обучающей выборках. Но, в случае классификации, следует учесть особенности алгоритмов машинного обучения. В этом случае, оценка эффекта все равно является смещенной, поскольку каждый отдельный классификатор обучается на половине или более исходных примеров, давая каждому примеру разные веса (тритмент). Используя несколько классификаторов (их ансамбль), мы минимизируем смещение путем усреднения оценок классификаторов, делая тритмент более равнозначным для каждого юнита. Это ставит все обучающие примеры в одинаковые условия, дает им одинаковую ценность.
В этом разделе мы узнали, что рандомизированные эксперименты помогают убрать смещение в данных для более достоверного причинно-следственного вывода. А ансамбли моделей помогают дать равнозначные оценки эффекта от обучения.
Матчинг
Рандомизированные эксперименты позволяют оценить средний эффект от обучения ансамбля моделей. Мы же заинтересованы в том, чтобы получить индивидуальные эффекты для каждого обучающего примера. Это нужно для того, чтобы понять, в каких ситуациях торговая стратегия в среднем приносит прибыль, а какие ситуации следует скорректировать или исключить из торговли. Иными словами, мы хотим получить условные оценки эффектов от обучения, в зависимости от индивидуальных характеристик каждого объекта.
Матчинг — способ сравнить индивидуальные сэмплы из всей выборки, чтобы убедиться, что они похожи по всем другим характеристикам кроме того, попали они в обучающую выборку или нет. Это позволяет вывести индивидуальные оценки для каждого обучающего примера.
Существует точный и неточный (приблизительный) матчинг.
В приблизительном матчинге, например, можно сравнить все юниты по критерию близости вроде Эвклидового расстояния, а также расстояний Минковского и Макаланобиса. Но поскольку мы имеем дело с временными рядами, то у нас есть опция сравнивать юниты позиционно, по времени. Если мы обучаем ансамбль моделей, то предсказания каждой модели в каждый конкретный момент времени уже ассоциированы с набором признаков, присутствующих в этой точке на временной шкале. Нам останется только сравнить предсказания всех моделей для конкретной временной точки. И это хорошо, потому что вычислительная сложность такого сравнения минимальна, по сравнению с другими способами, что позволит проводить больше экспериментов. К тому же это будет являться точным матчингом.
Неопределенность
В алготорговле нам недостаточно определить средний и индивидуальный лечебный эффекты, потому что мы хотим построить финальную модель-классификатор. Нам нужно применить инструментарий причинно-следственного вывода, чтобы оценить неопределенность в датасете и разделить юниты на поддающихся условному лечению (обучению классификатора) и неподдающихся лечению. То есть на тех, которые, в подавляющем большинстве случаев, классифицируются правильно и неправильно. В зависимости от степени неопределенности, которая рассчитывается как сумма разниц между потенциальными исходами для всех моделей ансамбля.
Раз мы оцениваем неопределенность данных с точки зрения классификатора, ордера на покупку и продажу следует оценивать отдельно, потому что их совместное распределение будет вносить путаницу в финальную оценку.
Мета лернеры
Мета-лернеры в причинно-следственном выводе — это модели машинного обучения, которые помогают оценивать причинно-следственные эффекты.
Мы уже познакомились с такими понятиями, как ATE и ATT, которые дают нам информацию о среднем причинном эффекте в популяции. Однако важно помнить, что люди и другие сложные организмы (например, животные, социальные группы, компании или страны) могут по-разному реагировать на одно и то же лечение (тритмент). Когда мы имеем дело с подобной ситуацией, ATE может скрыть от нас важную информацию.
Одним из решений этой проблемы является расчет CATE (conditional average treatment effect), также известный как HTE. При расчете CATE, мы смотрим не только на лечение, но и на набор переменных, определяющих индивидуальные характеристики каждой единицы, которые могут изменить то, как лечение влияет на результат.
CATE, в случае бинарного тритмента, может быть определен как:
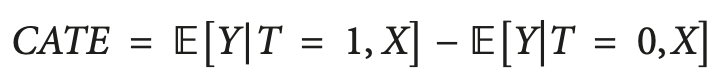
Где X — это признаки, описывающие каждый индивидуальный объект (юнит). Таким образом, мы осуществляем переход от гомогенного тритмент эффекта к гетерогенному.
Идея о том, что люди или другие юниты могут по-разному реагировать на один и тот же тритмент, часто представляется в виде матрицы, иногда называемой uplift-матрицей, которую вы можете увидеть на рисунке.
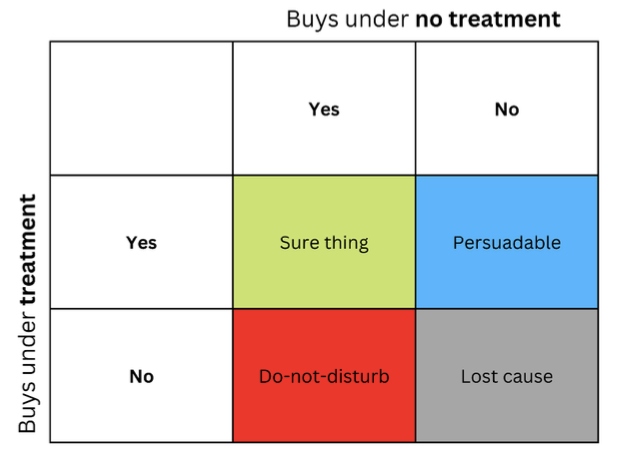
Строки представляют собой реакцию на контент, когда обращение (например, реклама) представлено получателю. Столбцы представляют реакции, когда лечение не применяется.
Четыре цветные ячейки отражают динамику эффекта лечения. Уверенные покупатели (зеленый цвет) покупают независимо от лечения. Не беспокоиться (красные) могут покупать без лечения, но не будут покупать если их лечить. Потерявшие интерес (серые) не будут покупать независимо от статуса лечения, а Persuadable (синие) не купят без лечения, но могут купить, если к ним обратиться.
Если вы маркетолог с ограниченным бюджетом, вы хотите сосредоточиться на маркетинге для синей группы (Persuadable) и по возможности избегать маркетинга для красной группы (Не беспокоить).
Маркетинг в группах Sure thing и Lost cause не нанесет вам прямого ущерба, но и не даст никакой пользы.
Аналогично, если вы врач, вы хотите выписать лекарство людям, которым оно может быть полезно, и избегаете назначать его тем, кому оно может навредить. Во многих сценариях реального мира переменная результата может быть вероятностной (например, вероятность покупки) или непрерывной (например, сумма расходов). В таких случаях мы не можем определить дискретные группы и сосредоточиваемся на поиске единиц с наибольшим ожидаемым увеличением переменной результата между условиями без лечения и с лечением. Эта разница между исходом при лечении по сравнению с отсутствием лечения иногда называют подъемом (uplift).
Переводя это на язык классификации временных рядов, нам нужно определить, какие примеры из обучающей выборки лучше всего реагируют на тритмент (обучение классификатора) и вынести их в отдельную группу.
Один из простых способов оценить гетерогенный тритмент эффект — это построить суррогатную модель, которая предсказывает переменную лечения на основе используемых вами предикторов, формально представленную следующим образом:
T ~ X
Производительность такой модели должна быть по сути случайной. Если она неслучайна, это будет означать, что тритмент зависит от признаков, а значит существует какая-то пропущенная переменная, которую мы не учли, и она влияет на наши причинно-следственные выводы, внося путаницу. Зачастую это происходит из-за неправильного дизайна рандомизированного контролируемого эксперимента, когда тритмент, в действительности, назначается не случайным образом.
S-Learner
S-Learner — это название простого подхода к моделированию CATE. S-Learner относится к категории так называемых мета-лернеров. Отметим, что причинные мета-лернеры не имеют прямого отношения к концепции метаобучения, используемого в традиционном машинном обучении. Они берут одну или более традиционных моделей машинного обучения, называемых базовыми, и используют их для вычисления причинно-следственного эффекта. В целом, вы можете использовать любую модель машинного обучения достаточной сложности (древовидную, нейросетевую и другие) в качестве базового лернера, если она совместима с вашими данными.
S-Learner — это простейшая метамодель, который использует только один базовый лернер (отсюда и его название: S(ingle)-Learner). Идея S-Learner удивительно проста: обучить одну модель на полном тренировочном наборе данных, включая переменную лечения в качестве признака, предсказать оба потенциальных исхода и вычесть результаты, чтобы получить CATE.
После обучения пошаговая процедура прогнозирования для S-Learner выглядит следующим образом:
- Выберите интересующее наблюдение.
- Установите значение тритмента для этого наблюдения равным 1 (или True).
- Предскажите результат с помощью обученной модели.
- Снова возьмите то же наблюдение.
- На этот раз установите значение тритмента равным 0 (или False).
- Сформируйте предсказание.
- Вычтите значение предсказания без лечения из значения предсказания с лечением.
T-Learner
Основная мотивация T-Learner заключается в том, чтобы преодолеть главное ограничение S-Learner. Если S-Learner может научиться игнорировать тритмент, то почему бы не сделать так, чтобы игнорировать тритмент было невозможно?
Именно этим и является T-Learner. Вместо того чтобы подгонять одну модель под все наблюдения (леченные и без лечения), мы теперь подгоняем две модели - одну только для единиц, прошедших лечение, а другую только для нелеченых единиц.
В некотором смысле это эквивалентно тому, чтобы заставить первое разбиение в модели, основанной на дереве, быть разбиением по переменной лечения.
Процесс обучения T-Learner выглядит следующим образом:
- Разделите данные по переменной лечения на два подмножества.
- Обучите две модели - по одной на каждом подмножестве.
- Для каждого наблюдения предскажите результаты с помощью обеих моделей.
- Вычтите результаты модели без лечения из результатов модели с лечением.
Обратите внимание, что теперь нет шанса, что лечение будет проигнорировано, поскольку мы закодировали разделение лечения как две отдельные модели.
T-Learner фокусируется на улучшении только одного аспекта, в котором S-Learner может (но не обязан) потерпеть неудачу. За это улучшение приходится платить. Подгонка двух алгоритмов к двум разным подмножествам данных означает, что каждый алгоритм обучается на меньшем количестве данных, что может ухудшить качество подгонки.
Это также делает T-Learner менее эффективным с точки зрения использования данных (вам нужно в два раза больше данных, чтобы обучить каждого базового обучаемого T-Learner для получения представления, сравнимого по качеству с S-Learner). Это обычно приводит к большей дисперсии в оценке T-Learner по сравнению с S-Learner. В частности, дисперсия может стать очень большой в случаях, когда в одной группе лечения гораздо меньше наблюдений чем у другой.
Подводя итог, можно сказать, что T-Learner может быть полезен, когда вы ожидаете, что эффект лечения может быть небольшим, а S-Learner может не распознать его. Следует помнить, что этот металернер обычно более требователен к данным, чем S-Learner, но разница уменьшается по мере увеличения общего размера набора данных.
X-Learner
X-Learner - металернер, созданный для более эффективного использования информации имеющуюся в данных.
X-Learner стремится оценить CATE напрямую и, делая это, использует информацию, которую S-Learner и T-Learner ранее отбросили. Что это за информация? S-Learner и T-Learner изучали так называемую функцию отклика или то, как юниты реагируют на на лечение (другими словами, функция отклика — это отображение признаков X и лечения T на результат y). В то же время ни одна из моделей не использовала реальный результат для моделирования CATE.
- Первый шаг прост, к тому же вы его уже знаете. Именно так мы поступили с T-Learner. Мы разделили наши данные по переменной лечения таким образом, чтобы получить два отдельных подмножества: первое содержащее только единицы, прошедшие лечение, и второе, содержащее только единицы, не прошедшие лечение. Далее мы обучаем две модели: по одной на каждом подмножестве.
- Мы вводим дополнительную модель, называемую "propensity score model", в простейшем случае это логистическая регрессия, и обучаем предсказывать тритмент для признаков X.
- Далее мы вычисляем тритмент эффект и обучаем две модели на признаках и значениях CATE.
- Результаты применения двух моделей складываем с весом, полученным из propensity score модели.
Благодаря возможности взвешивания двух субмоделей, X-Learner может быть действительно эффективным, когда набор данных сильно несбалансирован.
С другой стороны, если ваш набор данных очень мал, X-Learner может оказаться не самым лучшим выбором, поскольку при подгонке каждая дополнительная модель сопровождается дополнительным шумом, и у нас может быть недостаточно данных, чтобы использовать эту модель. В этом случае лучше подойдет S-Learner.
Существуют более продвинутые металернеры, рассматривать которые в данной короткой статье нет большого смысла, поскольку они не будут использоваться. Для справки, это Debiased/orthogonal machine learning и R-learner, с которыми вы можете познакомиться самостоятельно.
Вывод по существующим мета-лерненрам
Предложенные алгоритмы, несмотря на довольно обширную теоретическую часть, являются лишь оценщиками CATE эффекта. В литературе по причинно-следственному выводу почти не затрагивается полный цикл обнаружения и оценки тритмент эффекта, если это не какие-то совсем очевидные случаи, а также довольно слабо обстоит дело с внедрением полученных моделей в бизнес процессы. Заявляется, что исследователь сам должен формулировать эксперименты и затем использовать эти оценщики. Я решил пойти несколько дальше и инкорпорировал элементы этих оценщиков в процесс создания торговой системы, который происходит автоматически. На вход и выход алгоритма, как и прежде, подаются признаки и метки, затем алгоритм пытается выявить причинно-следственные связи на части данных, на которой это возможно, а остальную часть исключить из логики принятия торговых решений.
Реализация функции мета-лернеров для построения торгового алгоритма
Вооружившись необходимым минимумом знаний, я предлагаю рассмотреть мой авторский алгоритм. Было проведено много экспериментов с разными мета-лернерами и способами их применения для анализа причинно-следственных эффектов. На данный момент, предложенный алгоритм - один из лучших в арсенале, хотя есть способы как его можно модернизировать.
Поскольку мы определили, что для оценки потенциальных исходов нецелесообразно использовать один классификатор, являющийся предвзятым, то первым аргументом функции является некоторое задаваемое количество классификаторов. Я использовал алгоритм CatBoost. Далее идут гиперпараметры лернеров, такие как количество итераций и глубина дерева, а также bad_samples_fraction - параметр, известный по самой первой статье, посвященной металернерам. Это процент плохо классифицирующихся примеров, которые следует исключить из финальной обучающей выборки и стараться не торговать в эти моменты.
BAD_BUY и BAD_SELL — это коллекции индексов плохих примеров, которые пополняются на каждой итерации.
На каждой новой итерации, количество которых равно заданному количеству лернеров, датасет разделяется на тренировочную и валидационную подвыборки случайным образом в заданной пропорции (здесь 50/50). Для того, чтобы каждый отдельный алгоритм не переобучался. Случайное разбиение позволяет каждому классификатору обучаться и валидироваться на уникальных подвыборках, тогда как для получения оценок используется весь датасет. Это нивелирует предвзятость (bias) в оценках, позволяя более точно оценить какие примеры на самом деле плохо подвержены тритменту (обучению классификатора).
После каждого обучения реальные метки классов сравниваются с предсказанными. И затем неправильно предсказанные метки пополняют коллекции плохих примеров. Мы надеемся, что при увеличении количества классификаторов, оценки реально плохих семплов становятся менее смещенными.
После того, как коллекции плохих примеров сформированы, мы считаем среднее количество плохих семплов по всем индексам. После этого выбираем те индексы, количество плохих примеров в которых превышает среднее на некоторую величину. Это позволяет нам варьировать количество плохих примеров, попавших в обучение финальной модели, поскольку при большом количестве переобучений есть вероятность того, что каждый индекс попадет в плохие примеры хотя бы один раз; в этом случае получится, что из финальной обучающей выборки будут исключены вообще все примеры, тогда этот алгоритм работать не будет.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels(get_prices()) data = dataset[(dataset.index < FORWARD) & (dataset.index > BACKWARD)].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_BUY = pd.DatetimeIndex([]) BAD_SELL = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index) to_mark_b = BAD_BUY.value_counts() to_mark_s = BAD_SELL.value_counts() marked_idx_b = to_mark_b[to_mark_b > to_mark_b.mean() * bad_samples_fraction].index marked_idx_s = to_mark_s[to_mark_s > to_mark_s.mean() * bad_samples_fraction].index data.loc[data.index.isin(marked_idx_b), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_s), 'meta_labels'] = 0.0 return data[data.columns[1:]]
Остальные функции не изменены и расписаны в предыдущей статье, откуда их можно скачать, а функцию мета лернера заменить на предложенную. В оставшейся части этой статьи мы сконцентрируемся на экспериментах и попробуем сделать финальные выводы.
Тестирование алгоритма причинно-следственного вывода
Предположим, что мы используем генетическую оптимизацию параметров ТС по некоторому критерию (так называемой фитнес функции). И нас интересует не только лучший результат оптимизации, но и то, чтобы результаты всех проходов, в среднем, были хорошими. Если ТС плохая сама по себе или разброс параметров слишком велик, то получится большое количество проходов оптимизации с неудовлетворительными результатами, которые негативно повлияют на среднюю оценку. Этого хотелось бы избежать, поэтому обучим наш алгоритм много раз, потом усредним результаты и сравним лучший результат со средним.
Для этого я написал модификацию кастомного тестера, который тестирует сразу все обученные модели из списка:
def test_all_models(result: list): pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] pr_tst['labels'] = 0.5 pr_tst['meta_labels'] = 0.5 for i in range(len(result)): pr_tst['labels'] += result[i][1].predict_proba(X)[:,1] pr_tst['meta_labels'] += result[i][2].predict_proba(X)[:,1] pr_tst['labels'] = pr_tst['labels'] / (len(result)+1) pr_tst['meta_labels'] = pr_tst['meta_labels'] / (len(result)+1) pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(pr_tst, plot=plt)
Теперь сделаем причинный вывод 25 раз (обучим 25 независимых моделей, которые весьма рандомизированы в плане случайного разбиения на подвыборки):
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(15, 25, 2, 0.3)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) Протестируем сначала лучшую модель по версии R^2:
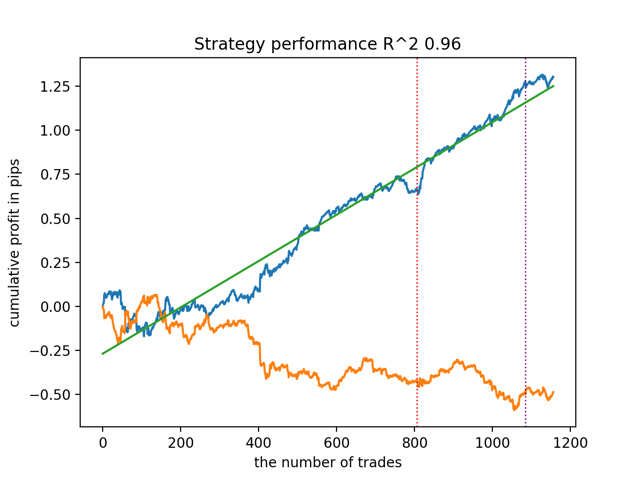
А затем все модели сразу:
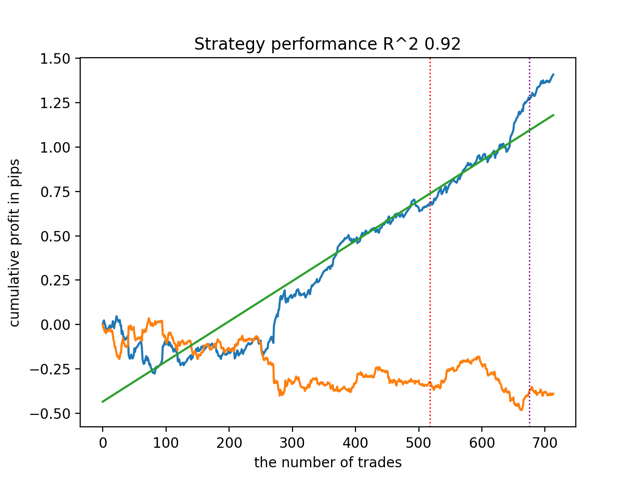
Средний результат не сильно отличается от лучшего. Это значит, что в ходе контролируемого рандомизированного эксперимента получается приблизиться к истинным причинно-следственным взаимосвязям.
Давайте обучим и протестируем алгоритм с другими входными параметрами мета лернеров.
options = []
for i in range(25):
print('Learn ' + str(i) + ' model')
options.append(learn_final_models(meta_learners(5, 10, 1, 0.4)))
options.sort(key=lambda x: x[0])
test_model(options[-1][1:], plt=True)
test_all_models(options) И получим результаты:
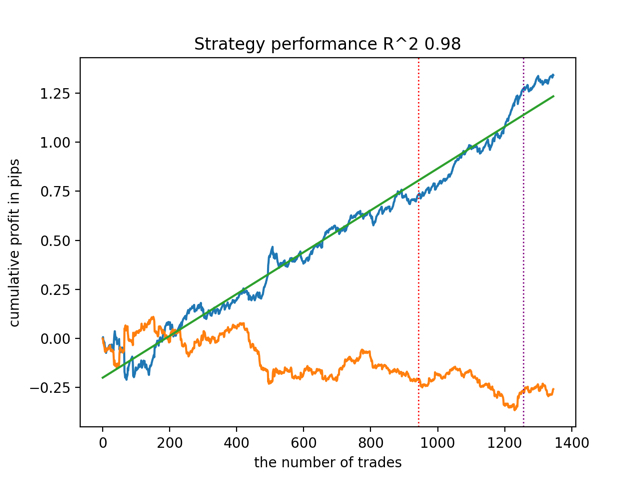
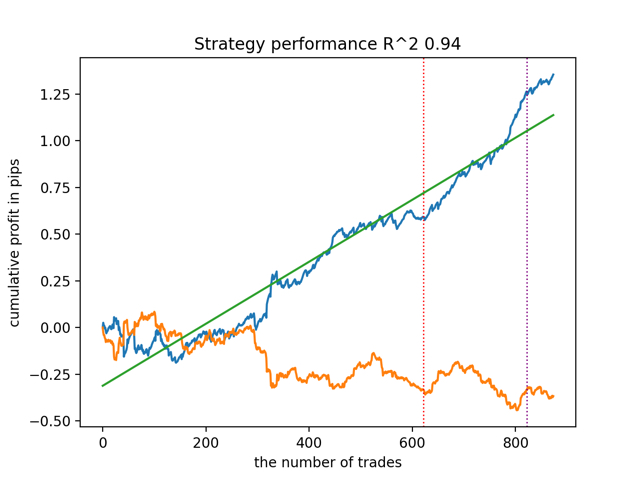
Было также замечено, что глубина истории обучения (выделена вертикальными линиями на графиках) влияет на качество результатов, так же как количество признаков и прочие гиперпараметры моделей (что в общем-то неудивительно), в то время как разброс по качеству моделей остается небольшим. Считаю, что полученная стабильность — это важное свойство или особенность предложенного алгоритма, которая позволяет иметь дополнительную уверенность в качестве получаемых ТС.
Выводы
Благодаря этой статье вы познакомились с основными понятиями причинно-следственного вывода. Это достаточно обширная и сложная тема, чтобы расписать все ее аспекты в рамках одной статьи. Причинно-следственный вывод и причинно-следственное мышление берут свои корни в философии и психологии, это важная часть нашего способа мыслить эту реальность. Поэтому многое из написанного хорошо воспринимается на интуитивном уровне. Тем не менее, будучи в некоторой степени агностиком, я постарался привести практический наглядный пример, чтобы продемонстрировать возможности так называемого причинно-следственного вывода в задачах классификации временных рядов. Вы можете использовать этот алгоритм для проведения различных экспериментов, достаточно заменить пару функций в коде, который представлен в предыдущей статье. На этом эксперименты не заканчиваются, возможно, появится новая интересная информация, которой впоследствии поделюсь с вами.
Полезная литература:
- книга Aleksander Molak "Causal inference and discovery in Python"
- онлайн книга Matheus Facure "Causal inference for the Brave and True"
- книга Miguel A. Hernan, James M. Robins "Causal inference: What If"
- статья Gabriel Okasa "Meta-learners for estimation of causal effects: finite sample cross-fit performance"
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
да я то понял, в тексте статьи этого нет, только абревиатура без расшифровки.)
Ну там сверху над уравнением написано, что для леченных. В целом фокус смещен в другую сторону немного, поэтому не стал расписывать ) А конкретно - как адаптировать эту науку со странными медицинскими определениями к анализу ВР
сложно адаптировать. ряды - пациенты сложно. Частями только, но вот разница свойств достаточно велика, что бы смысловые переносы без объяснений делать)))
К тому как и раньше писал, что это не явная понятая связь, а найденная через эксперименты, и не понятая. Я бы добавил для честности квази причинноследственный вывод.сложно адаптировать. ряды - пациенты сложно. Частями только, но вот разница свойств достаточно велика, что бы смысловые переносы без объяснений делать)))
К тому как и раньше писал, что это не явная понятая связь, а найденная через эксперименты, и не понятая. Я бы добавил для честности квази причинноследственный вывод.Почему-то файл к статье не прицепился, наверное не та версия черновика опубликовалась.
Исходник прикрепил.
Почему-то файл к статье не прицепился, наверное не та версия черновика опубликовалась.
Исходник прикрепил.
Отавлилась 30 января. Добавил