
Скальперский советник Ilan 3.0 Ai с машинным обучением

Введение
В мире алгоритмической торговли некоторые стратегии, подобно вечным звездам в постоянно меняющемся небосводе финансовых рынков, оставляют неизгладимый след в истории трейдинга. Среди них — Ilan, некогда легендарный советник-сеточник, покоривший умы и счета трейдеров 2010-х годов своей обманчивой простотой и потенциальной эффективностью в периоды низкой волатильности.
Однако, время не стоит на месте. В эпоху квантовых вычислений, нейронных сетей и машинного обучения стратегии вчерашнего дня требуют фундаментального переосмысления. Что если объединить классическую механику сеточного усреднения Ilan с передовыми алгоритмами искусственного интеллекта? Что если вместо жестко закодированных правил, позволить системе самостоятельно адаптироваться и постоянно улучшаться?
В этой статье мы бросаем вызов устоявшимся представлениям о торговых системах и предпринимаем амбициозную попытку возродить классический Ilan, вооружив его механизмами глубокого обучения с подкреплением (DQN) и динамической Q-таблицей. Мы не просто модифицируем существующий код — мы создаем принципиально новую интеллектуальную систему, способную учиться на собственном опыте, адаптироваться к рыночным изменениям и оптимизировать торговые решения в реальном времени.
Наше путешествие проведет вас через лабиринты алгоритмической торговли, где математическая строгость встречается с вычислительной элегантностью, а классические техники мартингейла обретают новую жизнь, благодаря инновационным подходам машинного обучения. Независимо от того, являетесь ли вы опытным алгоритмическим трейдером, разработчиком торговых систем, или просто энтузиастом финансовых технологий, эта статья предлагает уникальный взгляд на будущее автоматизированной торговли.
Пристегните ремни — мы отправляемся в увлекательное путешествие по созданию Ilan 3.0 AI, где традиции встречаются с инновациями, а прошлое эволюционирует в будущее.
Разбираем классический Ilan изнутри
Прежде чем погрузиться в мир искусственного интеллекта, необходимо понять, что делало Ilan настолько популярным советником в 2010-х годах. Ключевая идея его работы заключалась в концепции усреднения позиций. Когда цена двигалась против открытой позиции, советник не закрывал убыток, а добавлял новые ордера, улучшая среднюю цену входа.
Вот упрощенный фрагмент кода, иллюстрирующий эту логику:
// Упрощенная логика усреднения в оригинальном Ilan if(positionCount == 0) { // Открытие первой позиции по сигналу if(OpenSignal()) { OpenPosition(ORDER_TYPE_BUY, StartLot); } } else { // Вычисление уровня для усреднения double averagePrice = CalculateAveragePrice(); double gridLevel = averagePrice - GridSize * Point(); // Если цена достигла уровня сетки, добавляем позицию if(Bid <= gridLevel) { double newLot = StartLot * MathPow(LotMultiplier, positionCount); OpenPosition(ORDER_TYPE_BUY, newLot); } // Проверка на закрытие всех позиций по TP if(Bid >= averagePrice + TakeProfit * Point()) { CloseAllPositions(); } }
Магия Мартингейла: почему трейдеры влюблялись в Ilan
Популярность Ilan можно объяснить несколькими факторами. Прежде всего, его работа была интуитивно понятна даже начинающим трейдерам. В боковом рынке система показывала почти магические результаты — каждое колебание цены превращалось в источник прибыли. Усреднение позиций позволяло "спасать" сделки, которые изначально шли в убыток, создавая у трейдера ощущение непобедимости системы.
Другим привлекательным фактором была возможность настройки стратегии с помощью минимального набора параметров:
// Ключевые параметры советника Ilan input double StartLot = 0.01; // Начальный размер лота input double LotMultiplier = 1.5; // Множитель лота для каждой новой позиции input int GridSize = 30; // Шаг сетки в пунктах input int TakeProfit = 40; // Прибыль для закрытия всех позиций input int MaxPositions = 10; // Максимальное количество открываемых позиций
Такая простота настройки создавала иллюзию контроля — трейдер мог экспериментировать с различными комбинациями параметров, добиваясь впечатляющих результатов на исторических данных.
Попытки эволюции: что изменилось в Ilan 2.0
В Ilan 2.0 разработчики попытались решить некоторые из этих проблем. Были добавлены динамический расчет шага сетки на основе рыночной волатильности, работа с несколькими валютными парами и анализ их корреляции, дополнительные фильтры для открытия позиций и механизмы защиты от чрезмерных убытков.
// Динамический расчет шага сетки в Ilan 2.0 double CalculateGridStep(string symbol) { double atr = iATR(symbol, PERIOD_CURRENT, ATR_Period, 0); return atr * ATR_Multiplier; } // Защитный механизм для ограничения убытков bool EquityProtection() { double currentEquity = AccountInfoDouble(ACCOUNT_EQUITY); double maxAllowedDrawdown = AccountInfoDouble(ACCOUNT_BALANCE) * MaxDrawdownPercent / 100.0; if(AccountInfoDouble(ACCOUNT_BALANCE) - currentEquity > maxAllowedDrawdown) { CloseAllPositions(); return true; } return false; }
Эти улучшения действительно делали систему более устойчивой, но не решали фундаментальную проблему отсутствия адаптивности. Ilan 2.0 по-прежнему основывался на статических правилах и не мог учиться на своем опыте, или адаптироваться к изменяющимся рыночным условиям.
Почему трейдеры продолжали использовать Ilan
Несмотря на очевидные недостатки, многие трейдеры продолжали использовать Ilan и его модификации. Это объясняется целым рядом психологических факторов. Те, кто разорился, обычно молчали, в то время как успешные истории активно публиковались. Трейдеры замечали успешные периоды и игнорировали предупреждающие знаки. Казалось, что тонкая настройка параметров может решить все проблемы. К тому же, стратегия мартингейла активировала те же психологические триггеры, что и азартные игры.
Справедливости ради, стоит отметить, что в определенных рыночных условиях — особенно в периоды низкой волатильности и бокового движения — советник действительно мог показывать впечатляющие результаты в течение продолжительного времени. Проблема заключалась в том, что рыночные условия неизбежно менялись, а советник к этим изменениям не адаптировался.
Почему Ilan неизбежно ломался и сливал депозит
Настоящая проблема Ilan раскрывалась в долгосрочной перспективе. Стратегия, блестяще работающая в боковом рынке, оказывалась катастрофически уязвимой перед затяжными трендовыми движениями. Рассмотрим типичный сценарий краха.
Сначала открывается первая позиция на покупку. Затем рынок начинает устойчивое движение вниз. Советник добавляет позиции, увеличивая лоты по геометрической прогрессии. После нескольких уровней усреднения, размер позиции становится настолько большим, что даже небольшое дальнейшее движение приводит к маржин-коллу.
Математически эту проблему можно выразить так: при стратегии мартингейла с коэффициентом умножения лота 1.5 и начальным лотом 0.01, десятая последовательная позиция будет иметь размер около 0.57 лота — в 57 раз больше начальной. Общий размер всех открытых позиций составит около 1.1 лота, что для счета в $1000 при плече 1:100 означает использование практически всей доступной маржи.
// Расчет общего размера позиций при мартингейле double totalVolume = 0; double currentLot = StartLot; for(int i = 0; i < MaxPositions; i++) { totalVolume += currentLot; currentLot *= LotMultiplier; } // При StartLot = 0.01 и LotMultiplier = 1.5 после 10 позиций // totalVolume будет около 1.1 лота!
Ключевая проблема заключалась в отсутствии механизма определения, когда стратегию усреднения следует прекратить. Ilan был подобен азартному игроку, который не знает, когда остановиться, и продолжает ставить всё больше и больше, в надежде отыграться.
Почему Ilan нуждается в ИИ
Анализируя сильные и слабые стороны Ilan, становится очевидно, что его ключевая проблема — это неспособность учиться и адаптироваться. Советник следует одним и тем же правилам, независимо от того, насколько успешными или катастрофическими были его предыдущие действия.
Именно здесь на сцену выходит искусственный интеллект. Что если мы сохраним базовый механизм работы Ilan, но добавим ему способность анализировать результаты своих действий и корректировать стратегию? Что если вместо жестко закодированных правил, мы позволим системе самостоятельно находить оптимальные параметры и точки входа на основе накопленного опыта?
Именно эта идея лежит в основе нашего проекта по созданию Ilan 3.0 AI, где мы интегрируем проверенную временем стратегию усреднения с современными методами машинного обучения. В следующем разделе мы рассмотрим, как технология Q-обучения позволяет сделать эту концепцию реальностью.
Как Q-обучение улучшит советник Ilan
Переход от классической модели Ilan к интеллектуальной системе, способной обучаться, требует фундаментального изменения архитектуры советника. Сердцем Ilan 3.0 AI становится алгоритм Q-обучения — одна из важнейших технологий в области обучения с подкреплением.
Основы Q-обучения на своих действиях
Q-обучение названо так из-за "функции качества" (Quality function), которая определяет ценность действия в конкретном состоянии. В нашей реализации мы используем Q-таблицу — структуру данных, хранящую оценки для каждой пары "состояние-действие":
// Структура для Q-таблицы struct QEntry { string state; // Дискретизированное состояние рынка int action; // Действие (0-ничего, 1-покупка, 2-продажа) double value; // Q-значение }; // Глобальный массив для Q-таблицы QEntry QTable[]; int QTableSize = 0;Ключевая особенность Q-обучения — способность системы учиться на собственном опыте. После каждого действия алгоритм получает награду (прибыль) или штраф (убыток) и корректирует свою оценку ценности данного действия в конкретной рыночной ситуации:
// Обновление Q-значения по формуле Беллмана void UpdateQValue(string stateStr, int action, double reward, string nextStateStr, bool done) { double currentQ = GetQValue(stateStr, action); double nextMaxQ = 0; if(!done) { // Находим максимальное Q для следующего состояния nextMaxQ = GetMaxQValue(nextStateStr); } // Обновление Q-значения double newQ = currentQ + LearningRate * (reward + DiscountFactor * nextMaxQ - currentQ); // Сохранение обновленного значения SetQValue(stateStr, action, newQ); }
Эта формула, известная как уравнение Беллмана, является краеугольным камнем нашей системы. Параметр LearningRate определяет скорость обучения, а DiscountFactor — важность будущих наград относительно текущих.
Баланс между поиском новых решений и использованием опыта
Одна из ключевых проблем в обучении с подкреплением — необходимость балансировать между исследованием новых стратегий и эксплуатацией уже известных оптимальных решений. Для решения этой проблемы мы используем ε-жадную стратегию:
// Выбор действия с балансом между исследованием и использованием int SelectAction(string stateStr) { // С вероятностью epsilon выбираем случайное действие (исследование) if(MathRand() / (double)32767 < currentEpsilon) { return MathRand() % ActionCount; } // Иначе выбираем действие с максимальным Q-значением (использование) int bestAction = 0; double maxQ = GetQValue(stateStr, 0); for(int a = 1; a < ActionCount; a++) { double q = GetQValue(stateStr, a); if(q > maxQ) { maxQ = q; bestAction = a; } } return bestAction; }Параметр currentEpsilon определяет вероятность случайного выбора действия. Со временем его значение уменьшается, что позволяет системе переходить от активного исследования к преимущественному использованию накопленных знаний:
// Уменьшение epsilon для постепенного перехода от исследования к использованию if(currentEpsilon > MinExplorationRate) currentEpsilon *= ExplorationDecay;
Цифровой орган чувств: как алгоритм воспринимает рынок
Для эффективного обучения алгоритму необходимо "видеть" рынок — иметь формализованное представление текущей ситуации. В Ilan 3.0 AI мы используем комплексный вектор состояния, включающий технические индикаторы, метрики открытых позиций и другие рыночные данные:
// Получение текущего состояния рынка для Q-обучения void GetCurrentState(string symbol, double &state[]) { ArrayResize(state, StateDimension); // Технические индикаторы double rsi = iRSI(symbol, PERIOD_CURRENT, RSI_Period, PRICE_CLOSE, 0); double cci = iCCI(symbol, PERIOD_CURRENT, CCI_Period, PRICE_TYPICAL, 0); double macd = iMACD(symbol, PERIOD_CURRENT, 12, 26, 9, PRICE_CLOSE, MODE_MAIN, 0); // Нормализация индикаторов double normalized_rsi = rsi / 100.0; double normalized_cci = (cci + 500) / 1000.0; // Метрики позиций int positions = (symbol == "EURUSD") ? euroUsdPositions : audUsdPositions; double normalized_positions = (double)positions / MaxTrades; // Расчет разницы цен double point = SymbolInfoDouble(symbol, SYMBOL_POINT); double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double avgPrice = CalculateAveragePrice(symbol); double price_diff = (currentBid - avgPrice) / (100 * point); // Заполнение вектора состояния state[0] = normalized_rsi; state[1] = normalized_cci; state[2] = normalized_positions; state[3] = price_diff; state[4] = macd / (100 * point); state[5] = AccountInfoDouble(ACCOUNT_EQUITY) / AccountInfoDouble(ACCOUNT_BALANCE); }Для работы с Q-таблицей непрерывные значения состояния необходимо дискретизировать — преобразовать в строковое представление с конечным числом вариантов:
// Преобразование состояния в строку для Q-таблицы string StateToString(double &state[]) { string stateStr = ""; for(int i = 0; i < ArraySize(state); i++) { // Округление до 2 десятичных знаков для дискретизации double discretized = MathRound(state[i] * 100) / 100.0; stateStr += DoubleToString(discretized, 2); if(i < ArraySize(state) - 1) stateStr += ","; } return stateStr; }
Этот процесс дискретизации позволяет системе обобщать опыт, применяя его к схожим, но не идентичным рыночным ситуациям.
Система стимулов: кнут и пряник в мире ИИКорректное определение системы наград — пожалуй, самый критичный аспект в построении эффективной системы обучения с подкреплением. В Ilan 3.0 AI мы разработали многоуровневую систему стимулов, которая направляет развитие алгоритма в нужном направлении.
Экономика наград: как замотивировать алгоритм
При закрытии позиций с прибылью, система получает положительное вознаграждение, пропорциональное размеру прибыли:
// Награда при закрытии прибыльных позиций if(shouldClose) { if(ClosePositions(symbol, magic)) { if(isTraining) { double reward = profit; // Награда равна прибыли UpdateQValue(stateStr, action, reward, stateStr, true); // Статистика обучения episodeCount++; totalReward += reward; Print("Эпизод ", episodeCount, " завершен с наградой: ", reward, ". Средняя награда: ", totalReward / episodeCount); } } }При усреднении убыточных позиций, система получает небольшой штраф, что стимулирует ее искать оптимальные точки входа и избегать ситуаций, требующих усреднения:
// Штраф при усреднении позиций if(OpenPosition(symbol, ORDER_TYPE_BUY, CalculateLot(positionsCount, symbol), StopLoss, TakeProfit, magic)) { if(isTraining) { double reward = -1; // Небольшой штраф за усреднение UpdateQValue(stateStr, action, reward, stateStr, false); } }
Отсутствие немедленной награды при открытии первой позиции, заставляет систему ориентироваться на долгосрочный результат, а не на краткосрочные действия.
Тонкая балансировка системы
Эффективность системы Q-обучения сильно зависит от правильной настройки ее ключевых параметров. В Ilan 3.0 AI мы предоставляем возможность тонкой настройки всех аспектов обучения:
// Параметры обучения с подкреплением input double LearningRate = 0.01; // Скорость обучения input double DiscountFactor = 0.95; // Коэффициент дисконтирования input double ExplorationRate = 0.3; // Начальная вероятность исследования input double ExplorationDecay = 0.995; // Коэффициент уменьшения исследования input double MinExplorationRate = 0.01;// Минимальная вероятность исследования
LearningRate определяет скорость обновления Q-значений. Высокие значения приводят к быстрому обучению, но могут вызвать нестабильность. Низкие значения обеспечивают стабильное, но медленное обучение.
DiscountFactor определяет важность будущих наград. Значения ближе к 1 заставляют систему стремиться к долгосрочной максимизации прибыли, иногда жертвуя немедленными выгодами.
Параметры исследования контролируют баланс между поиском новых стратегий и эксплуатацией известных оптимальных решений. Со временем, вероятность исследования уменьшается, позволяя системе всё больше полагаться на накопленный опыт.
От теории к практике: реализация
Реализация Ilan 3.0 AI требует интеграции механизмов Q-обучения с традиционной логикой торгового советника. Ключевым компонентом является функция управления торговлей, которая использует Q-обучение для принятия решений:// Функция управления торговлей с использованием Q-обучения void ManagePairWithDQN(string symbol, int &positionsCount, CArrayDouble &trades, int magic, datetime &firstTradeTime) { // Получение текущих рыночных данных double currentBid = SymbolInfoDouble(symbol, SYMBOL_BID); double currentAsk = SymbolInfoDouble(symbol, SYMBOL_ASK); double point = SymbolInfoDouble(symbol, SYMBOL_POINT); // Формирование текущего состояния double state[]; GetCurrentState(symbol, state); string stateStr = StateToString(state); // Выбор действия с помощью Q-таблицы int action = SelectAction(stateStr); // Преобразование действия в торговую операцию bool shouldTrade = (action > 0); ENUM_ORDER_TYPE orderType = (action == 1) ? ORDER_TYPE_BUY : ORDER_TYPE_SELL; // Логика открытия и управления позициями if(shouldTrade) { // Логика открытия первой позиции или усреднения // ... } // Проверка необходимости закрытия позиций double profit = CalculatePositionsPnL(symbol, magic); if(profit > 0 && positionsCount > 0) { // Логика закрытия прибыльных позиций // ... } }
Сохранение опыта системы
Для сохранения накопленного опыта, между сессиями мы реализовали механизм сохранения и загрузки Q-таблицы:
// Сохранение Q-таблицы в файл bool SaveQTable(string filename) { int handle = FileOpen(filename, FILE_WRITE|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Ошибка при открытии файла для записи Q-таблицы: ", GetLastError()); return false; } // Запись размера таблицы FileWriteInteger(handle, QTableSize); // Запись значений for(int i = 0; i < QTableSize; i++) { FileWriteString(handle, QTable[i].state); FileWriteInteger(handle, QTable[i].action); FileWriteDouble(handle, QTable[i].value); } FileClose(handle); return true; } // Загрузка Q-таблицы из файла bool LoadQTable(string filename) { if(!FileIsExist(filename)) { Print("Файл Q-таблицы не существует: ", filename); return false; } int handle = FileOpen(filename, FILE_READ|FILE_BIN); if(handle == INVALID_HANDLE) { Print("Ошибка при открытии файла для чтения Q-таблицы: ", GetLastError()); return false; } // Чтение размера таблицы int size = FileReadInteger(handle); // Выделение памяти для таблицы if(size > ArraySize(QTable)) { ArrayResize(QTable, size); } // Чтение значений for(int i = 0; i < size; i++) { QTable[i].state = FileReadString(handle); QTable[i].action = FileReadInteger(handle); QTable[i].value = FileReadDouble(handle); QTableSize++; } FileClose(handle); return true; }
Рассмотрим тест данного советника. Тест получен на моделировании OHLC на 15-минутном графике, на парах AUDUSD и EURUSD за 2020-2025 годы (основной символ EURUSD, но советник также загружает AUDUSD).
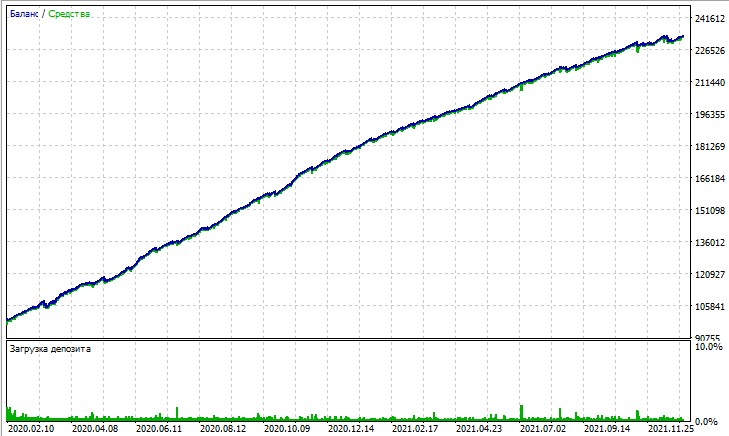
А вот тест на "Всех тиках" беспощадно подсвечивает крупные просадки, возникающие из-за Мартингейла. Несмотря на штрафы, иногда модель впадает в череду усредняющих сделок. Возможно, в будущих версиях мы уберем просадки при помощи DQN риск-менеджмента:
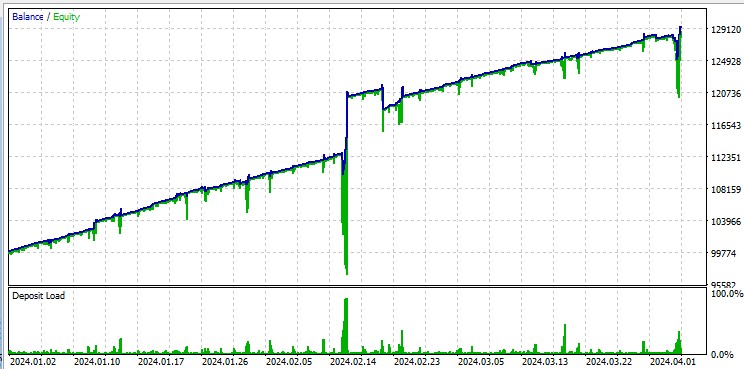
Отдельно стоит указать, что робот проторговывает огромные лоты, что полезно для получения ребейтов за оборот от брокера.
Пути улучшения алгоритма
Несмотря на значительные улучшения, Ilan 3.0 AI представляет собой лишь первый шаг в эволюции интеллектуальных торговых систем. Перспективные направления дальнейшего развития включают:
- Замену Q-таблицы полноценной нейронной сетью для лучшего обобщения опыта
- Внедрение алгоритмов глубокого обучения с подкреплением (DQN, DDPG, PPO)
- Использование техник мета-обучения для быстрой адаптации к новым рыночным условиям
- Интеграцию с системами анализа новостей и фундаментальных данных
Заключение
Создание Ilan 3.0 AI демонстрирует фундаментальное изменение в подходе к алгоритмической торговле. Мы переходим от статических систем, основанных на фиксированных правилах, к адаптивным алгоритмам, способным учиться и эволюционировать.
Интеграция классической стратегии Ilan с современными методами машинного обучения открывает новые горизонты в разработке торговых систем. Вместо бесконечной оптимизации параметров, мы создаем системы, способные самостоятельно находить оптимальные стратегии и адаптироваться к изменяющимся рыночным условиям.
Будущее алгоритмической торговли лежит в гибридных подходах, сочетающих проверенные временем торговые стратегии с инновационными методами искусственного интеллекта. Ilan 3.0 AI — это не просто улучшенная версия классического советника, а принципиально новый класс интеллектуальных торговых систем, способных учиться, адаптироваться и развиваться вместе с рынком.
Мы стоим на пороге новой эры в алгоритмическом трейдинге — эры систем, которые не просто исполняют заданные правила, а постоянно эволюционируют, находя оптимальные стратегии в постоянно меняющемся мире финансовых рынков.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
прочитал пока бегло - на первый взгляд статья -суппер!
надо смотреть и оптить на разных символах - какие лучше какие хуже поддаются илано -дрессировке!!!
Мартин многим Должен..
Интересно будет получить продвинутый продукт с перспективой развития.
Здравствуйте Евгений,
где находится код CalculateAveragePrice(symbol) ?
И еще, как мне предварительно рассчитать SL и TP по средней цене между 2 и более позициями?
Спасибо, Сабино.