
Нейросети в трейдинге: Иерархический двухбашенный трансформер (Hidformer)

Введение
Особенно востребованными в финансовом прогнозировании стали нейросетевые модели, способные учитывать временную структуру данных и выявлять скрытые паттерны. Однако, традиционные нейросетевые подходы имеют ограничения, связанные с высокой вычислительной сложностью и недостаточной интерпретируемостью результатов. В связи с этим, в последние годы внимание исследователей привлекли архитектуры на основе механизмов внимания, обеспечивающие более точный анализ временных рядов и финансовых данных.
Наибольшую популярность получили модели на основе архитектуры Transformer и её модификаций. В работе "Hidformer: Transformer-Style Neural Network in Stock Price Forecasting" представлена одна из таких модификаций, получившая название Hidformer. Эта модель разработана специально для анализа временных рядов и ориентирована на повышение точности прогнозирования за счет оптимизированных механизмов внимания, эффективного выявления долгосрочных зависимостей и адаптации к спецификам финансовых данных. Основное преимущество Hidformer заключается в способности учитывать сложные временные зависимости, что особенно важно для анализа фондового рынка, где цены активов зависят от множества факторов.
Авторы фреймворка предложили улучшенную обработку временных зависимостей, снижение вычислительной сложности модели и повышение точности прогнозирования. Это делает Hidformer перспективным инструментом для финансового анализа и прогнозирования.
Алгоритм Hidformer
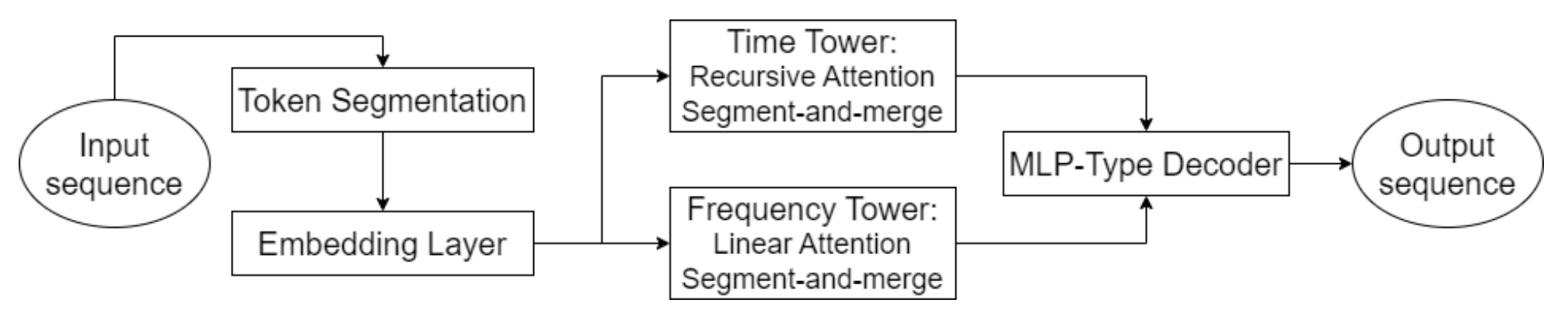
Одной из ключевых особенностей Hidformer является параллельная обработка данных двумя энкодерами. Первый анализирует временные характеристики, выявляя тренды и закономерности на временной шкале. А второй работает в частотной области, что позволяет идентифицировать более глубокие зависимости и устранить рыночный шум. Такой подход позволяет выделять скрытые закономерности в данных, что критично при прогнозировании цен на фондовом рынке, где сигналы могут быть замаскированы рыночным шумом. Исходные данные разделяются на подпоследовательности, которые затем объединяются на каждом этапе обработки, что улучшает выявление значимых паттернов.
Данная методика особенно полезна для анализа волатильных активов, таких как акции технологических компаний или криптовалюты, так как она помогает отделять фундаментальные тренды от краткосрочных колебаний. Вместо стандартного многоголового внимания, используемого в архитектуре Transformer, авторы Hidformer предложили использовать рекурсивный механизм внимания во временном энкодере и линейный механизм внимания для поиска зависимостей в частотном спектре. Это позволило сократить потребление вычислительных ресурсов и повысить стабильность прогнозирования, что делает модель эффективной при работе с большим объемом рыночных данных.
Декодер модели основан на многослойном перцептроне, что позволяет прогнозировать всю последовательность цен за один шаг. В результате исключаются ошибки, которые могли бы накапливаться при пошаговом прогнозировании. Данная архитектура особенно полезна для финансового прогнозирования, так как позволяет уменьшить вероятность накопления неточностей в долгосрочном прогнозе.
Авторская визуализация фреймворка Hidformer представлена ниже.
Реализация средствами MQL5
После небольшого ознакомления с теоретическими аспектами фреймворка Hidformer, мы переходим к реализации собственного видения предложенных подходов средствами MQL5. И начнем мы свою работу с реализации модифицированных алгоритмов внимания.
Прежде всего, давайте посмотрим на алгоритм предложенного рекурсивного внимания. Первоначально, алгоритм рекурсивного внимания был предложен для решения задач визуального диалога, он позволяет найти правильный контекст текущего вопроса в имеющейся истории предшествующего диалога. Очевидно, что рекурсивная обработка данных, взамен параллельного вычисления многоголового внимания, только усложнит нам задачу. С другой стороны, рекурсивный подход позволяет нам не обрабатывать всю историю, остановившись на ближайшем найденном сообщении с соответствующим контекстом.
Такие размышления приводят нас построению алгоритма многомасштабного внимания. Ранее мы уже обсуждали различные алгоритмы захвата локальных и глобальных особенностей путем изменения окна внимания. Но разные уровни внимания использовались в отдельных объектах. Сейчас же я предлагаю несколько изменить ранее построенный алгоритм многоголового внимания, предоставив каждой голове свое окно контекста. Более того, мы предлагаем определять окно контекста не вокруг анализируемого элемента, а от начала последовательности. Напомню, что в начале последовательности у нас хранятся наиболее новые данные. Такой подход позволит нам оценить анализируемую историю именно в контексте текущей рыночной ситуации.
Модификация внимания на стороне OpenCL
Для начала мы реализуем описанные выше изменения на стороне OpenCL-программы. Для этого мы создадим новый кернел MultiScaleRelativeAttentionOut, большую часть кода которого мы перенесем из донорского кернела MHRelativeAttentionOut. Список параметров кернела был перенесен без изменений.
__kernel void MultiScaleRelativeAttentionOut(__global const float * q, ///<[in] Matrix of Querys __global const float * k, ///<[in] Matrix of Keys __global const float * v, ///<[in] Matrix of Values __global const float * bk, ///<[in] Matrix of Positional Bias Keys __global const float * bv, ///<[in] Matrix of Positional Bias Values __global const float * gc, ///<[in] Global content bias vector __global const float * gp, ///<[in] Global positional bias vector __global float * score, ///<[out] Matrix of Scores __global float * out, ///<[out] Matrix of attention const int dimension ///< Dimension of Key ) { //--- init const uint q_id = get_global_id(0); const uint k_id = get_local_id(1); const uint h = get_global_id(2); const uint qunits = get_global_size(0); const uint kunits = get_local_size(1); const uint heads = get_global_size(2); const int shift_q = dimension * (q_id * heads + h); const int shift_kv = dimension * (heads * k_id + h); const int shift_gc = dimension * h; const int shift_s = kunits * (q_id * heads + h) + k_id; const int shift_pb = q_id * kunits + k_id; const uint ls = min((uint)get_local_size(1), (uint)LOCAL_ARRAY_SIZE); const uint window = fmax((kunits + h) / (h + 1), fmin(3, kunits)); float koef = sqrt((float)dimension);
В теле метода мы сначала проводим подготовительную работу. Здесь мы определяем все необходимые константы, включая окно контекста.
Стоит отметить, что мы не стали создавать отдельный буфер для передачи индивидуальных размеров контекста для каждой головы внимания. Вместо этого, мы просто разделили длину анализируемой последовательности на идентификатор головы внимания, увеличенный на "1", так как идентификаторы начинаются с "0". Таким образом, первая голова внимания анализируем всю последовательность, а далее осуществляется кратное уменьшение анализируемого контекста.
Далее нам предстоит определить коэффициенты влияния. И здесь каждый поток операций вычисляет один коэффициент для соответствующего элемента. Однако операции осуществляются только в пределах окна контекста. Остальные элементы автоматически получают нулевой коэффициент влияния.
__local float temp[LOCAL_ARRAY_SIZE]; //--- score float sc = 0; if(k_id < window) { for(int d = 0; d < dimension; d++) { float val_q = q[shift_q + d]; float val_k = k[shift_kv + d]; float val_bk = bk[shift_kv + d]; sc += val_q * val_k + val_q * val_bk + val_k * val_bk + gc[shift_q + d] * val_k + gp[shift_q + d] * val_bk; } sc = sc / koef; }
Для повышения стабильности определения коэффициентов, мы осуществим их смещения в зону действительности значений. С этой целью мы найдем максимальное значение среди вычисленных коэффициентов, исключая значения за пределами окна контекста.
//--- max value for(int cur_k = 0; cur_k < kunits; cur_k += ls) { if(k_id < window) if(k_id >= cur_k && k_id < (cur_k + ls)) { int shift_local = k_id % ls; temp[shift_local] = (cur_k == 0 ? sc : fmax(temp[shift_local], sc)); } barrier(CLK_LOCAL_MEM_FENCE); } uint count = min(ls, kunits); //--- do { count = (count + 1) / 2; if(k_id < (window + 1) / 2) if(k_id < ls) temp[k_id] = (k_id < count && (k_id + count) < kunits ? fmax(temp[k_id + count], temp[k_id]) : temp[k_id]); barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
И только затем определим экспоненциальное значение коэффициента за вычетом максимального значения.
if(k_id < window) sc = IsNaNOrInf(exp(fmax(sc - temp[0], -120)), 0); barrier(CLK_LOCAL_MEM_FENCE);
Однако, здесь следует особо обратить внимание на выполнение операций в пределах окна контекста. Приводя максимальное значение к "0", мы делаем максимальную экспоненту равную "1". При этом, все прочие коэффициенты получат значения в диапазоне от 0 до 1. Такой подход повышает стабильность работы функции SoftMax. Но мы же помним, что коэффициенты за пределами окна контекста автоматически получили нулевые значения. Вычисление их экспоненциального значения даст им максимальный коэффициент влияния, что крайне нежелательно. Поэтому нам важно оставить их с "0".
Далее мы суммируем полученные значения коэффициентов в рамках рабочей группы.
//--- sum of exp for(int cur_k = 0; cur_k < kunits; cur_k += ls) { if(k_id >= cur_k && k_id < (cur_k + ls)) { int shift_local = k_id % ls; temp[shift_local] = (cur_k == 0 ? 0 : temp[shift_local]) + sc; } barrier(CLK_LOCAL_MEM_FENCE); } //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k_id < count && k_id < (window + 1) / 2) temp[k_id] += ((k_id + count) < kunits ? temp[k_id + count] : 0); if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
И нормализуем каждый коэффициент, разделив его на полученную сумму.
//--- score float sum = IsNaNOrInf(temp[0], 1); if(sum <= 1.2e-7f) sum = 1; sc /= sum; score[shift_s] = sc; barrier(CLK_LOCAL_MEM_FENCE);
Нормализованные значения сохраняем в соответствующий буфер данных.
Теперь, после получения нормализованных коэффициентов влияния отдельных элементов последовательности, мы можем определить скорректированное значение текущего элемента. Для этого мы организуем цикл, в теле которого умножим Value на соответствующие коэффициенты влияния и суммируем полученные значения.
//--- out int shift_local = k_id % ls; for(int d = 0; d < dimension; d++) { float val_v = v[shift_kv + d]; float val_bv = bv[shift_kv + d]; float val = IsNaNOrInf(sc * (val_v + val_bv), 0); //--- sum of value for(int cur_v = 0; cur_v < kunits; cur_v += ls) { if(k_id >= cur_v && k_id < (cur_v + ls)) temp[shift_local] = (cur_v == 0 ? 0 : temp[shift_local]) + val; barrier(CLK_LOCAL_MEM_FENCE); } //--- count = min(ls, (uint)kunits); do { count = (count + 1) / 2; if(k_id < count && (k_id + count) < kunits) temp[k_id] += temp[k_id + count]; if(k_id + count < ls) temp[k_id + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1); //--- if(k_id == 0) out[shift_q + d] = IsNaNOrInf(temp[0], 0); barrier(CLK_LOCAL_MEM_FENCE); } }
Результаты операций сохраним в соответствующий буфер данных.
Использование сохраненных нулевых коэффициентов влияния позволяет нам использовать существующие средства для выполнения алгоритмов обратного прохода. Поэтому мы завершаем работу на стороне OpenCL-программы. С полным её кодом вы можете ознакомиться во вложении.
Создание объектов многомасштабного внимания
Далее нам предстоит создать на стороне основной программы объекты многомасштабного внимания. И здесь мы решили максимально использовать функционал наследования объектов. И просто создали объекты Self-Attention и Cross-Attention на базе существующих аналогичных методов, переопределив лишь метод вызова созданного выше кернела. Структура новых объектов представлена ниже.
class CNeuronMultiScaleRelativeSelfAttention : public CNeuronRelativeSelfAttention { protected: //--- virtual bool AttentionOut(void); public: CNeuronMultiScaleRelativeSelfAttention(void) {}; ~CNeuronMultiScaleRelativeSelfAttention(void) {}; //--- virtual int Type(void) override const { return defNeuronMultiScaleRelativeSelfAttention; } };
class CNeuronMultiScaleRelativeCrossAttention : public CNeuronRelativeCrossAttention { protected: virtual bool AttentionOut(void); public: CNeuronMultiScaleRelativeCrossAttention(void) {}; ~CNeuronMultiScaleRelativeCrossAttention(void) {}; //--- virtual int Type(void) override const { return defNeuronMultiScaleRelativeCrossAttention; } };
Для вызова кернела мы использовали классический алгоритм постановки его в очередь выполнения. Подобные методы мы уже рассматривали много раз. И я думаю, что для вас не составит труда самостоятельно с ним ознакомиться. Полный код указанных методов представлен во вложении.
Объект рекурсивного внимания
Реализованные выше объекты многомасштабного внимания позволяют нам проанализировать данные с разным окном контекста, но это не то рекурсивное внимание, которое предложили авторы фреймворка Hidformer. Мы выполнили лишь подготовительную работу.
Следующим этапом нашей работы мы построим объект рекурсивного внимания, который позволит нам анализировать текущие данные в контексте ранее наблюдаемой истории. Для этого мы воспользуемся некоторыми наработками в области построения модулей памяти. В частности мы будем сохранять контекст наблюдаемых состояний на заданную историческую глубину, который будет использоваться для оценки текущего состояния. Подобный алгоритм мы реализуем в рамках метода CNeuronRecursiveAttention, структура которого представлена ниже.
class CNeuronRecursiveAttention : public CNeuronMultiScaleRelativeCrossAttention { protected: CNeuronMultiScaleRelativeSelfAttention cSelfAttention; CNeuronTransposeOCL cTransposeSA; CNeuronConvOCL cConvolution; CNeuronEmbeddingOCL cHistory; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override { return false; } public: CNeuronRecursiveAttention(void) {}; ~CNeuronRecursiveAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint history_size, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRecursiveAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
В качестве родительского класса, в данном случае, мы воспользуемся реализованным выше объектом многомасштабного кросс-внимания.
В теле метода мы видим уже привычный набор переопределяемых виртуальных методов и ряд внутренних объектов, с назначением которых мы познакомимся в процессе построения алгоритмов прямого и обратного проходов.
Все внутренние объекты объявлены статичными, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализации всех унаследованных и объявленных объектов осуществляется в методе Init.
bool CNeuronRecursiveAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint history_size, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMultiScaleRelativeCrossAttention::Init(numOutputs, myIndex, open_cl, window, window_key, units_count, heads, window_key, history_size, optimization_type, batch)) return false;
В параметрах метода мы получаем ряд констант, позволяющих однозначно интерпретировать архитектуру создаваемого объекта. И тут следует обратить внимание, что, несмотря на наследование от класса кросс-внимания, наш объект работает с одним потоком исходных данных. Второй поток информации, необходимый для корректной работы методов родительского класса формируется внутри нашего объекта. И размер анализируемой последовательности второго информационного потока задается в виде глубины истории сохраняемого контекста history_size.
В теле метода мы, по уже сложившейся традиции, сразу вызываем одноименный метод родительского класса, передав ему необходимый набор параметров. Напомню, что в методе родительского класса уже реализованы необходимые точки контроля и инициализация всех унаследованных объектов, включая базовые интерфейсы.
Далее мы переходим к инициализации вновь объявленных внутренних объектов. И первым в нашем списке будет объект многомасштабного Self-Attention.
int index = 0; if(!cSelfAttention.Init(0, index, OpenCL, iWindow, iWindowKey, iUnits, iHeads, optimization, iBatch)) return false;
Использование данного объекта позволяет нам определить элементы исходных данных, оказывающих максимальное влияние на текущее состояние анализируемого финансового инструмента.
Затем нам необходимо добавить контекст текущего состояния окружающей в память нашего блока рекурсивного внимания. При этом мы бы хотели сохранить контекст отдельных унитарных последовательностей. Поэтому мы сначала транспонируем исходные данные.
index++; if(!cTransposeSA.Init(0, index, OpenCL, iUnits, iWindow, optimization, iBatch)) return false;
Потом извлекаем контекст унитарных последовательностей с использованием сверточного слоя.
index++; if(!cConvolution.Init(0, index, OpenCL, iUnits, iUnits, iWindowKey, 1, iWindow, optimization, iBatch)) return false;
Обратите внимание, что в параметрах сверточного слоя мы указываем один элемент анализируемой последовательности, а количество унитарных последовательностей передаем в параметр количества независимых переменных. Такой подход позволяет нам осуществлять полностью независимый анализ унитарных последовательностей, так как для выделения контекста каждой, используется индивидуальный набор обучаемых параметров. Это позволяет нам осуществлять более глубокий анализ исходной мультимодальной последовательности.
Далее мы используем слой генерации эмбедингов для фиксирования контекста анализируемого состояния окружающей среды и добавления его в стек памяти исторической последовательности.
index++; uint windows[] = { iWindowKey * iWindow }; if(!cHistory.Init(0, index, OpenCL, iUnitsKV, iWindowKey, windows)) return false; //--- return true; }
После успешного выполнения всех операций, мы возвращаем логический результат их работы вызывающей программе и завершаем работу метода.
Следующем нашим шагом будет реализация метода прямого прохода feedForward, алгоритм которого выглядит вполне линейно.
bool CNeuronRecursiveAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cSelfAttention.FeedForward(NeuronOCL)) return false;
В параметрах метода мы получаем указатель на объект исходных данных, содержащий мультимодальный временной ряд. Полученный указатель сразу предаем в модуль Self-Attention, для анализа зависимостей в текущем описании состояния окружающей среды. Результаты анализа мы транспонируем для удобства дальнейшей обработки.
if(!cTransposeSA.FeedForward(cSelfAttention.AsObject())) return false;
И извлекаем контекст унитарных последовательностей с помощью сверточного слоя.
if(!cConvolution.FeedForward(cTransposeSA.AsObject())) return false;
Подготовленные данные передаем в объект генерации эмбедингов, где осуществляется извлечение контекста анализируемого состояния и добавление его в стек памяти.
if(!cHistory.FeedForward(cConvolution.AsObject())) return false;
Теперь нам остается обогатить результаты проведенного ранее анализа в блоке Self-Attention контекстом наблюдаемой ранее исторической последовательности. Для этого мы воспользуемся одноименным методом родительского класса, передав ему необходимую информацию.
return CNeuronMultiScaleRelativeCrossAttention::feedForward(cSelfAttention.AsObject(),
cHistory.getOutput());
}
Здесь стоит обратить внимание, что для анализа текущего состояния в контексте наблюдаемых ранее состояний, мы используем созданный выше объект многомасштабного внимания. Такой подход позволяет нам придать больший вес данным из ближайшей истории, снижая их значимость с течением времени. Тем не менее у нас остается возможность извлечения ключевых точек и из "глубин памяти".
В завершении работы метода мы возвращаем логический результат выполнения операций вызывающей программе.
За видимой простотой метода прямого прохода легко упустить двойное использование результатов работы объекта многомасштабного Self-Attention. Однако, это обстоятельство накладывает отпечаток на алгоритм обратного прохода, который мы реализуем в методе calcInputGradients.
bool CNeuronRecursiveAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В параметрах метода обратного прохода мы получаем указатель на тот же объект исходных данных, только теперь нам предстоит передать в него градиент ошибки, соответствующий их влиянию на результат работы модели.
В теле метода мы сразу проверяем актуальность полученного указателя, ведь в противном случае, мы не сможем передать данные в несуществующий объект, и проведение дальнейших операций сразу теряет смысл. Поэтому, мы продолжаем работу метода только в случае успешного прохождения данной точки контроля.
Как вы знаете, информационные потоки прямого и обратного проходов полностью соответствуют, только имеют разнонаправленный характер. Метод прямого прохода мы завершили вызовом одноименного метода родительского класса. Соответственно, операции обратного прохода начинаются вызовом унаследованного метода. Он распределит полученный ранее градиент ошибки по двум информационным потокам в соответствии с их влиянием на итоговый результат.
if(!CNeuronMultiScaleRelativeCrossAttention::calcInputGradients(cSelfAttention.AsObject(), cHistory.getOutput(), cHistory.getGradient(), (ENUM_ACTIVATION)cHistory.Activation())) return false;
Вначале мы распределяем градиент ошибки вспомогательного информационного потока, который соответствует памяти нашего объекта. Здесь мы спускаем погрешность до уровня сверточного слоя извлечения контекста унитарных последовательностей.
if(!cConvolution.calcHiddenGradients(cHistory.AsObject())) return false;
И далее до слоя транспонирования результатов блока Self-Attention.
if(!cTransposeSA.calcHiddenGradients(cConvolution.AsObject())) return false;
Теперь нам предстоит передать градиент ошибки до уровня слоя многомасштабного Self-Attention. Но ранее мы ему уже передали градиент ошибки основного информационного потока, который нам необходимо сохранить. С этой целью мы воспользуемся подменой указателей на буферы данных. Сначала мы передадим в объект указатель на свободный буфер, предварительно сохранив имеющийся.
CBufferFloat *temp = cSelfAttention.getGradient(); if(!cSelfAttention.SetGradient(cTransposeSA.getPrevOutput(), false) || !cSelfAttention.calcHiddenGradients(cTransposeSA.AsObject()) || !SumAndNormilize(temp, cSelfAttention.getGradient(), temp, iWindow, false, 0, 0, 0, 1) || !cSelfAttention.SetGradient(temp, false)) return false;
А затем спустим градиент ошибки и суммируем значения двух информационных потоков. После чего, вернем указатели на буферы данных в исходное состояние.
Теперь нам остается лишь передать градиент ошибки на уровень исходных данных.
if(!NeuronOCL.calcHiddenGradients(cSelfAttention.AsObject())) return false; //--- return true; }
И в завершении метода, мы возвращаем логический результат выполнения операций вызывающей программе.
С полным кодом данного объекта и всех его методов вы можете самостоятельно ознакомиться во вложении.
Объект линейного внимания
Кроме реализованного объекта рекурсивного внимания, авторы фреймворка предложили использовать линейное внимание в башне анализа частотного спектра.
Линейное внимание (“Linear Attention”) является одним из способов оптимизации традиционного механизма внимания в трансформерах. В отличие от классического Self-Attention, использующего полносвязные матричные операции с квадратичной сложностью, линейное внимание снижает вычислительную сложность, что делает его эффективным для обработки длинных последовательностей.
В линейном внимании вводится разложение функций φ(Q) и φ(K), позволяющее представить внимание как:
![]()
Преимущества линейного внимания
- Линейная сложность: сокращение вычислительных затрат, что делает возможной обработку длинных последовательностей.
- Снижение потребления памяти: нет необходимости хранить полную матрицу коэффициентов зависимости Score, что уменьшает объем требуемой памяти.
- Эффективность в онлайновых задачах: линейное внимание подходит для потоковой обработки данных, так как обновление происходит инкрементально.
- Гибкость в выборе функций ядра: использование различных функций φ(x) может адаптировать внимание к специфике задачи.
Реализация линейного алгоритма внимания представлена в объекте CNeuronLinerAttention, структура которого представлена ниже.
class CNeuronLinerAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iWindowKey; uint iUnits; uint iVariables; //--- CNeuronConvOCL cQuery; CNeuronConvOCL cKey; CNeuronTransposeVRCOCL cKeyT; CNeuronBaseOCL cKeyValue; CNeuronBaseOCL cAttentionOut; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronLinerAttention(void) {}; ~CNeuronLinerAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronLinerAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Здесь мы видим базовый набор переопределяемых методов и несколько внутренних объектов, которые играют ключевую роль в выстраиваемом нами алгоритме. Более детально с их функционалом мы познакомимся в процессе реализации методов нового класса.
Все объявлены методы создаются статично, что позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех унаследованных и объявленных объектов осуществляется в Init. В параметрах данного метода мы получаем ряд параметров, позволяющих однозначно определить архитектуру создаваемого объекта.
bool CNeuronLinerAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
В теле метода мы сразу вызываем одноименный метод родительского класса. В данном случае это полносвязный слой.
Затем мы сохраним ключевые параметры архитектуры во внутренних переменных. И перейдем к инициализации внутренних объектов.
iWindow = window; iWindowKey = fmax(window_key, 1); iUnits = units_count; iVariables = variables;
Здесь мы сначала инициализируем сверточные слои генерации сущностей Query и Key. При формировании запросов мы используем сигмовидную функцию активации, которая укажет долю влияния на объект других элементов.
int index = 0; if(!cQuery.Init(0, index, OpenCL, iWindow, iWindow, iWindowKey, iUnits, iVariables, optimization, iBatch)) return false; cQuery.SetActivationFunction(SIGMOID); index++; if(!cKey.Init(0, index, OpenCL, iWindow, iWindow, iWindowKey, iUnits, iVariables, optimization, iBatch)) return false; cKey.SetActivationFunction(TANH);
А для ключей мы используем гиперболический тангенс в качестве функции активации, что позволит определить прямое и обратное влияние соответствующего элемента.
Тут же мы инициализируем объект транспонирования матрицы Key.
index++; if(!cKeyT.Init(0, index, OpenCL, iVariables, iUnits, iWindowKey, optimization, iBatch)) return false; cKeyT.SetActivationFunction(TANH);
И объект для записи произведения матриц Key и Value.
index++; if(!cKeyValue.Init(0, index, OpenCL, iWindow * iWindowKey, optimization, iBatch)) return false; cKeyValue.SetActivationFunction(None);
Обратите внимание, что мы не используем слой генерации сущности Value. Вместо неё, мы планируем напрямую использовать исходные данные.
Результаты внимания мы сохраним в специально созданный внутренний объект.
index++; if(!cAttentionOut.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cAttentionOut.SetActivationFunction(None);
А интерфейсы родительского класса будем использовать для создания остаточных связей. Поэтому мы воспользуемся подменой указателя на буфер градиентов ошибки, что позволит исключить излишние операции копирования данных.
if(!SetGradient(cAttentionOut.getGradient(), true)) return false; //--- return true; }
И перед завершением работы, мы вернем логический результат выполнения операций вызывающей программе.
После завершения работы по инициализации объекта, мы переходим к построению алгоритма прямого прохода в рамках метода feedForward.
bool CNeuronLinerAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cQuery.FeedForward(NeuronOCL)) return false; if(!cKey.FeedForward(NeuronOCL) || !cKeyT.FeedForward(cKey.AsObject())) return false;
В параметрах метода мы получаем указатель на объект многомерной последовательности исходных данных, которую сразу используем для формирования сущностей Query и Key.
Затем определим влияние каждого из объектов на анализируемую последовательность, путем умножения транспонированной матрицы Key на исходные данные.
if(!MatMul(cKeyT.getOutput(), NeuronOCL.getOutput(), cKeyValue.getOutput(), iWindowKey, iUnits, iWindow, iVariables)) return false;
Для получения результатов линейного внимания мы умножим тензор Query на результат предыдущей операции.
if(!MatMul(cQuery.getOutput(), cKeyValue.getOutput(), cAttentionOut.getOutput(), iUnits, iWindowKey, iWindow, iVariables)) return false;
Теперь нам остается добавить остаточные связи и нормализировать результаты операции.
if(!SumAndNormilize(NeuronOCL.getOutput(), cAttentionOut.getOutput(), Output, iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
Возвращаем логический результат выполнения операций вызывающей программе и завершаем работу метода.
Далее нам предстоит организовать распределение градиентов ошибки между всеми внутренними объектами и исходными данными, в соответствии с их влиянием на результат работы модели. Как обычно, данные операции мы осуществляем в методе calcInputGradients, в параметрах которого получаем указатель на объект исходных данных. Только на этот раз он используется для записи результатов работы.
bool CNeuronLinerAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
И в теле метода мы сразу проверяем актуальность полученного указателя. О критичности прохождения данной точки контроля мы уже говорили выше.
Благодаря подмене указателей на буфер данных, полученный от последующего нейронного слоя градиент ошибки автоматически попадает во внутренний объект результатов линейного внимания. И далее мы распределяем его по информационным потокам.
if(!MatMulGrad(cQuery.getOutput(), cQuery.getGradient(), cKeyValue.getOutput(), cKeyValue.getGradient(), cAttentionOut.getGradient(), iUnits, iWindowKey, iWindow, iVariables)) return false; if(!MatMulGrad(cKeyT.getOutput(), cKeyT.getGradient(), NeuronOCL.getOutput(), cAttentionOut.getPrevOutput(), cKeyValue.getGradient(), iWindowKey, iUnits, iWindow, iVariables)) return false;
Здесь обратить внимание, что на уровень исходных данных нам предстоит передать градиент ошибки по 4 информационным потокам:
- сущность Query;
- сущность Key;
- произведение Key*Value;
- остаточные связи.
В последней операции мы сохранили градиент ошибки от произведения Key*Value в свободном буфере. А градиент потока остаточных в полном объеме передается с уровня результатов текущего объекта. Следует так же сказать, что эти градиенты не скорректированы на производную функции активации объекта исходных данных. Однако, при распределении градиента ошибки через сверточные слои генерации сущностей осуществляется его корректировка на производную функции активации. С целью получения сопоставимых данных по всем информационным потокам, мы суммируем имеющиеся значения и корректируем на производную функции активации объекта исходных данных. Результаты сохраняем в свободном буфере данных.
if(!SumAndNormilize(Gradient, cAttentionOut.getPrevOutput(), cAttentionOut.getPrevOutput(), iWindow, false, 0, 0, 0, 1)) return false; //--- if(NeuronOCL.Activation() != None) if(!DeActivation(NeuronOCL.getOutput(), cAttentionOut.getPrevOutput(), cAttentionOut.getPrevOutput(), NeuronOCL.Activation())) return false;
Кроме того, мы корректируем градиенты ошибки по прочим информационным потокам на производные соответствующих функций активации.
if(cKeyT.Activation() != None) if(!DeActivation(cKeyT.getOutput(), cKeyT.getGradient(), cKeyT.getGradient(), cKeyT.Activation())) return false; if(cQuery.Activation() != None) if(!DeActivation(cQuery.getOutput(), cQuery.getGradient(), cQuery.getGradient(), cQuery.Activation())) return false;
Далее, мы распределяем градиент ошибки по информационному потоку сущности Key и суммируем с ранее накопленными данными.
if(!cKey.calcHiddenGradients(cKeyT.AsObject()) || !NeuronOCL.calcHiddenGradients(cKey.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cAttentionOut.getPrevOutput(), cAttentionOut.getPrevOutput(), iWindow, false, 0, 0, 0, 1)) return false;
Аналогичным образом проводим градиент ошибки и по информационному потоку сущности Query, после чего, суммарный градиент ошибки передаем на объект исходных данных.
if(!NeuronOCL.calcHiddenGradients(cQuery.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cAttentionOut.getPrevOutput(), NeuronOCL.getGradient(), iWindow, false, 0, 0, 0, 1)) return false; //--- return true; }
В завершении операций метода, мы возвращаем логический результат их выполнения вызывающей программе.
На этом мы завершаем рассмотрение алгоритмов построения методов объектов линейного внимания. С полным кодом данного класса и всех его методов вы можете самостоятельно познакомиться во вложении.
Мы хорошо потрудились и подошли к границам статьи. Но наша работа еще не завершена. Сделаем небольшой перерыв и продолжим работу в следующей статье, где доведем её до логического завершения.
Заключение
Мы познакомились с фреймворком Hidformer, который демонстрирует эффективность в прогнозировании временных рядов, включая финансовые данные. Его особенностью является использование двухбашенного энкодера с раздельным анализом исходных данных в виде временной последовательности и её частотных характеристик. Это наделяет Hidformer высокой гибкостью и адаптивностью к различным рыночным условиям.
В практической части статьи были реализованы некоторые компоненты, предложенные авторами фреймворка Hidformer. Но наша работа ещё не завершена, и мы продолжим её в ближайшее время.
Ссылки
- Hidformer: Transformer-Style Neural Network in Stock Price Forecasting
- Hidformer: Hierarchical dual-tower transformer using multi-scale mergence for long-term time series forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Эволюционный торговый алгоритм обучения с подкреплением и вымиранием убыточных особей (ETARE)
Эволюционный торговый алгоритм обучения с подкреплением и вымиранием убыточных особей (ETARE)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Нейросети в трейдинге: Иерархический двухбашенный трансформер (Hidformer):
Автор: Dmitriy Gizlyk
Hello Dmitriy,
According to the OnTesterDeinit() the code should in the Tester mode (ie. in the StrategyTester) save down NN files.
This doesnt happen. Also this OnTesterDeinit() doesnt get called it seems. Since i dont see any of the print statements.
Is this due to an update of MQL5? Or why does your code not save files anymore?
Hello Dmitriy,
According to the OnTesterDeinit() the code should in the Tester mode (ie. in the StrategyTester) save down NN files.
This doesnt happen. Also this OnTesterDeinit() doesnt get called it seems. Since i dont see any of the print statements.
Is this due to an update of MQL5? Or why does your code not save files anymore?
Dear Andreas,
OnTesterDeinit runs only in optimization mode. Please refer to the documentation at https://www.mql5.com/en/docs/event_handlers/ontesterdeinit.
We do not save models in the tester because this EA does not study them. It is necessary to check the effectiveness of previously studied model.
Best regards,
Dmitriy.