
Нейросети в трейдинге: Гибридный торговый фреймворк с предиктивным кодированием (StockFormer)

Введение
Обучение с подкреплением (Reinforcement Learning, RL) все чаще используется для решения сложных задач в финансовой сфере, включая разработку торговых стратегий и управление инвестиционными портфелями. Модели обучаются анализировать исторические данные о движении цен на финансовые инструменты, объемы торговых операций и показатели технических индикаторов. Однако большинство существующих методов предполагают, что анализируемые данные полностью отображают все взаимозависимости между активами. На практике это не всегда так, а особенно актуально для шумных и высоковолатильных рыночных данных.
Традиционные методы часто не учитывают долгосрочные и краткосрочные прогнозы доходности активов, а также их взаимные корреляции. В то же время, успешные инвестиционные стратегии обычно базируются на глубоком анализе этих факторов. Для моделирования таких сложных зависимостей в работе "StockFormer: Learning Hybrid Trading Machines with Predictive Coding" была предложена гибридная торговая система StockFormer, которая сочетает возможности прогнозного моделирования (predictive coding) и гибкость RL-агентов. Прогнозное моделирование, широко применяемое в области обработки естественного языка и компьютерного зрения, позволяет извлекать информативные скрытые состояния из зашумленных исходных данных, что особенно важно в финансовых приложениях.
Фреймворк StockFormer объединяет три модифицированные ветви архитектуры Transformer, каждая из которых отвечает за изучение различных аспектов рыночной динамики:
- долгосрочные тенденции;
- краткосрочные тенденции;
- взаимозависимости между активами.
Все ветви оснащены механизмом "Diversified Multi-Head Attention" (DMH-Attn), который улучшает ванильный модуль Transformer путем использования многоголовых блоков FeedForward. Это позволяет выявлять разнообразные паттерны временных рядов в разных подпространствах, сохраняя критически важную информацию.
Для оптимизации торговых стратегий, три вида латентных состояний из разных ветвей адаптивно объединяются с помощью многоголовых механизмов внимания в единое подпространство состояний, которое затем используется RL-агентом.
Обучение политики авторы фреймворка предлагают осуществлять методами Actor-Critic. При этом обратное распространение градиентов ошибки от Критика направлено на улучшение модуля прогнозного кодирования, что обеспечивает тесную интеграцию между этапами обучения.
Эксперименты, проведенные авторами фреймворка на трех публичных наборах данных, показали, что StockFormer значительно превосходит существующие методы как в прогнозировании, так и в максимизации инвестиционной прибыли.
Алгоритм StockFormer
Фреймворк StockFormer решает задачи прогнозирования и принятия торговых решений на финансовых рынках с помощью подходов обучения с подкреплением (RL). Одна из главных проблем традиционных методов заключается в отсутствии эффективного механизма анализа динамичных зависимостей между активами и их будущими трендами. Это особенно важно на финансовых рынках, где изменения могут происходить быстро и непредсказуемо. Для решения этой задачи StockFormer использует два ключевых этапа: прогнозное кодирование и обучение торговой стратегии.
На первом этапе, StockFormer обучает модель с использованием подходов самоконтролируемого обучения эффективно извлекать скрытые закономерности из рыночных данных, даже при наличии шума. Это позволяет модели учитывать краткосрочные и долгосрочные тенденции, а также взаимозависимости между активами. Используя этот подход, модель извлекает важные скрытые состояния, которые затем применяются на следующем этапе для принятия торговых решений.
Разнообразие временных паттернов среди последовательностей нескольких активов на финансовых рынках значительно увеличивает сложность извлечения эффективных представлений из сырых данных. Для решения этой проблемы авторы фреймворка StockFormer модернизируют модуль многоголового внимания в ванильном Transformer, заменяя один блок FeedForward (FFN) на группу аналогичных блоков. Без изменения общего числа параметров такой механизм усиливает способность многоголового внимания к декомпозиции признаков, что облегчает моделирование разнообразных временных паттернов в разных подпространствах.
Этот модифицированный модуль получил название "Диверсифицированный многоголовый модуль внимания" (Diversified Multi-Head Attention — DMH-Attn). Для сущностей Query, Key и Value размерности dmodel процесс в модуле диверсифицированного многоголового внимания можно представить следующим образом: вначале разделяем выходные признаки Z многоголового внимания на h групп вдоль размерности канала, где h — это количество параллельных голов внимания, а затем, применяем отдельную FFN к каждой группе разделенных признаков в Z:
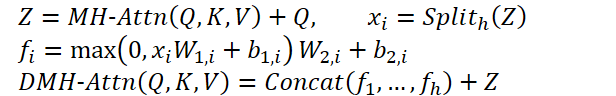
Где MH-Attn обозначает многоголовое внимание. А 𝑓𝑖 — это выходные признаки каждой головы FFN, которые содержат две линейные проекции с активацией ReLU между ними.
Каждая ветвь модели модернизированного Transformer в StockFormer делится на два модуля: энкодер и декодер. Оба модуля используются в процессе обучения прогнозного кодирования с разными целями, однако, только энкодер используется при оптимизации стратегии. В модели используется L слоев энкодера и M слоев декодера. Латентные представления, полученные на последнем слое энкодера XLenc, служат одним из входов для каждого слоя декодера. Процесс вычислений на l-м слое энкодера и m-м слое декодера можно записать следующим образом:
- слой энкодера:
![]()
- слой декодера:
![]()
Здесь Xl,enc и Xm,dec — это результаты работы слоев энкодера и декодера, соответственно. На входы для первого слоя энкодера и декодера подаются исходные данные с добавленными позиционными эмбедингами. А результаты последнего слоя декодера передаются в слой проекции, который генерирует финальный результат для задачи прогнозного кодирования.
Модуль извлечения взаимозависимостей предназначен для выявления динамических корреляций между временными рядами. На каждом временном шаге t модуль использует одни и те же исходные данные для энкодера и декодера. Для работы с данными фондового рынка в качестве статистик авторы фреймворка в своей работе использовали технические индикаторы, такие как MACD, RSI и SMA.
В процессе обучения исходные данные делятся на две части:
- Ковариационная матрица. Матрица ковариаций между последовательностями дневных цен закрытия всех активов за фиксированный период времени до момента t.
- Замаскированные статистики. В этой части случайно выбирается половина временных рядов, и их исходные статистики маскируются нулями. На фазе тестирования используются полные данные без маскировки.
Основная цель модуля извлечения взаимозависимостей — восстановить замаскированные статистики, основываясь на ковариационной матрице и оставшихся видимых статистиках. Этот метод прогнозного кодирования заставляет энкодер Transformer обучаться выявлять зависимости между анализируемыми временными рядами.
Модули краткосрочного и долгосрочного прогнозирования в StockFormer нацелены на прогнозирование коэффициентов доходности для каждого актива на различные временные горизонты.
Задача модуля краткосрочного прогнозирования заключается в прогнозировании коэффициента доходности актива на следующий день (H = 1). Для этого на вход энкодера подаются анализируемые статистики за T дней. Декодер получает такие же показатели только на анализируемый момент времени.
Модуль долгосрочного прогнозирования работает аналогичным образом, но с горизонтом планирования коэффициентов доходности актива на больший период. Что побуждает модель захватывать динамику рынка на более длительном временном горизонте.
Для обучения модулей краткосрочного и долгосрочного прогнозирования используется комбинированная функция потерь, включающая регрессионную ошибку и ошибку ранжирования акций. Первая минимизирует разницу между прогнозными и фактическими доходностями, а ошибка ранжирования гарантирует, что активы с более высокой доходностью имеют больший приоритет.
Таким образом, две ветви модели помогают StockFormer захватывать динамику рынка на разных временных горизонтах, что позволяет агенту RL принимать более точные и информированные торговые решения.
На втором этапе обучения StockFormer объединяет три типа латентных представлений srelat,t, slong,t, sshort,t в единое пространство состояний St с помощью каскада блоков многоголового внимания. Вначале осуществляется слияние краткосрочных и долгосрочных прогнозов. При этом представление долгосрочного прогноза выступает в качестве Query, так как оно менее подвержено краткосрочным шумам. Результаты этой работы сопоставляются с латентным состоянием взаимозависимостей активов, которое используются в качестве Key и Value следующего модуля внимания.
Затем модель обучается определять оптимальную стратегию торговли, используя подход Актер—Критик. Одним из ключевых преимуществ StockFormer является интеграция фаз предиктивного кодирования и оптимизации политики. Оценки Критика помогают улучшить качество извлечения латентных представлений, что позволяет модели глубже анализировать связи между активами и справляться с шумом в исходных данных.
Авторская визуализация фреймворка StockFormer представлена ниже.
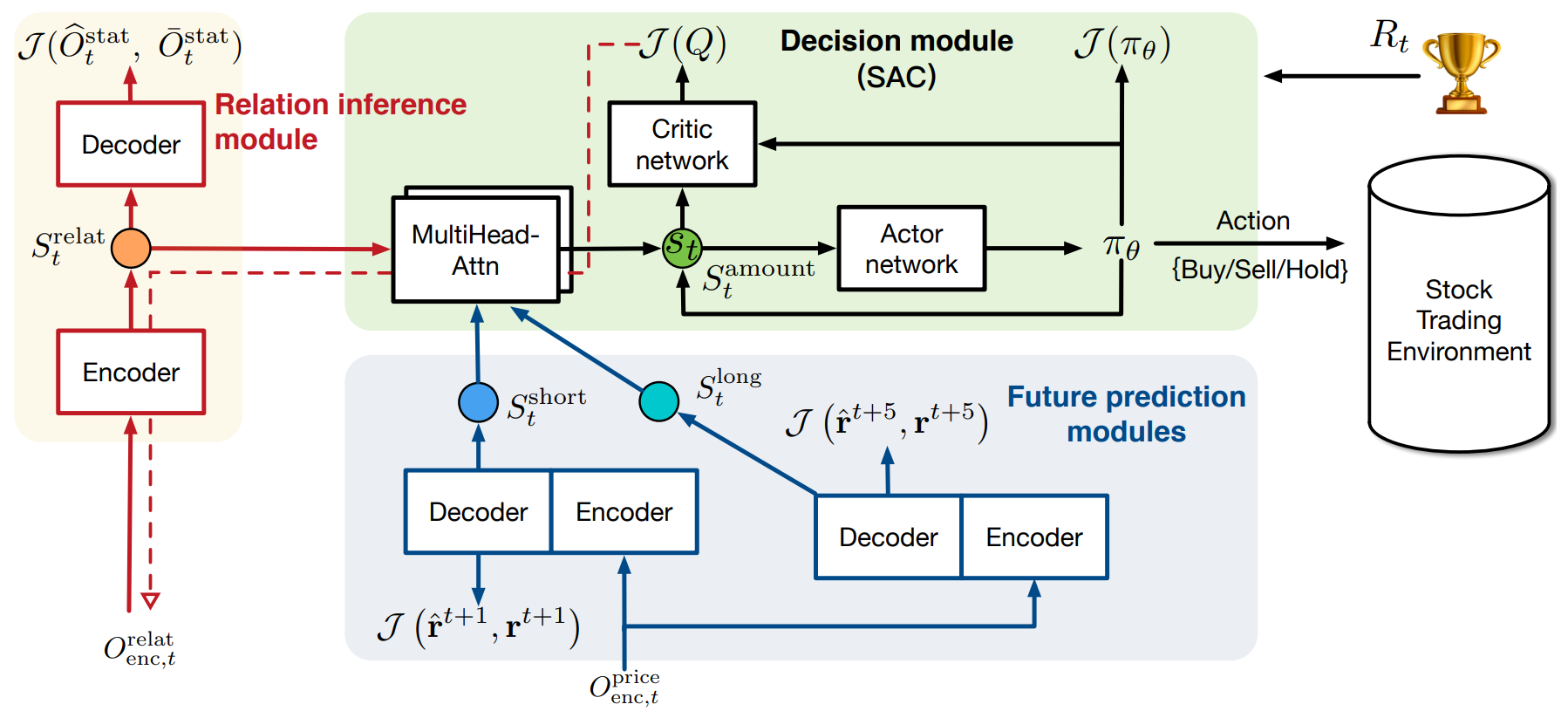
Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка StockFormer, мы переходим к реализации собственного видения предложенных подходов средствами MQL5. И как можно заметить в представленном теоретическом описании фреймворка, основным конструктивным изменением архитектуры используемых модулей внимания является внедрение блока многоголового FeedForward. Реализацией данного блока мы и займемся на первом этапе нашей работы.
В предложенной авторами фреймворка StockFormer реализации блока многоголового FeedForward, результаты работы блока многоголового Self-Attention по каждому элементу последовательности разбиваются на h равных групп, и к каждой группе применяется свой MLP c уникальными обучаемыми параметрами.
Обратите внимание, что здесь подход к формированию голов отличается от ранее используемого нами блока многоголового внимания. В Multy-Head Self-Attention мы на основании одного эмбединга элемента последовательности формировали несколько вариантов сущностей Query, Key и Value. В данном случае, авторы StockFormer предлагают сразу разбить вектор описания одного элемента последовательности на несколько равных групп элементов. После чего, к каждой группе применяется свой MLP. Такой подход, конечно, позволяет организовать несколько голов без увеличения обучаемых параметров. И на выходе мы получаем тензор той же размерности, без необходимости слоя проекции, как это организовано в MH Self-Attention. Однако, это не позволяет нам использовать существующие сверточные слои, как это было ранее. И нам необходимо найти какое-то альтернативное решение.
С одной стороны, мы могли бы подумать о вариантах транспонирования трехмерного тензора с целью "подогнать" решение под использование сверточного слоя с независимым анализом унитарных последовательностей. Но мы же понимаем, что таких слоев в StockFormer будет довольно много. Следовательно, транспонирование данных до и после блока FeedForward на каждом слое значительно увеличит время обучения и эксплуатации модели. Поэтому было принято решение о создании многоголового варианта сверточного слоя. Но перед началом работ по построению нового объекта на стороне основной программы, нам предстоит немного поработать с нашей OpenCL-программой.
Дополнение OpenCL-программы
И начнем мы работу с построения кернела прямого прохода нашего нового многоголового сверточного слоя FeedForwardMHConv. Надо сказать, что структуру параметров и часть алгоритма мы заимствовали у аналогичного кернела существующего сверточного слоя. А идентификатор головы свертки и их общее количество мы ввели в виде дополнительного измерения пространства задач.
__kernel void FeedForwardMHConv(__global float *matrix_w, __global float *matrix_i, __global float *matrix_o, const int inputs, const int step, const int window_in, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t h = get_global_id(1); const size_t v = get_global_id(2); const size_t total = get_global_size(0); const size_t heads = get_global_size(1);
В теле кернела мы осуществляем идентификацию текущего потока по всем измерениям пространства задач. А затем определим размерности каждой головы свертки на входе и выходе слоя и смещение в буферах глобальных данных до анализируемых элементов.
const int window_in_h = (window_in + heads - 1) / heads; const int window_out_h = (window_out + heads - 1) / heads; const int shift_out = window_out * i + window_out_h * h; const int shift_in = step * i + window_in_h * h; const int shift_var_in = v * inputs; const int shift_var_out = v * window_out * total; const int shift_var_w = v * window_out * (window_in_h + 1); const int shift_w_h = h * window_out_h * (window_in_h + 1);
После выполнения подготовительной работы мы переходим к построению операций алгоритма свертки исходных данных с обучаемым фильтром. В рамках одного потока мы будем выполнять операции свертки одной головы исходных данных с соответствующим фильтром. Для этого организуем систему вложенных циклов. Внешний цикл перебирает элементы в слое результатов анализируемого элемента по соответствующей голове свертки.
float sum = 0; float4 inp, weight; int stop = (window_in_h <= (inputs - shift_in) ? window_in_h : (inputs - shift_in)); //--- for(int out = 0; (out < window_out_h && (window_out_h * h + out) < window_out); out++) { int shift = (window_in_h + 1) * out + shift_w_h;
И в теле внешнего цикла мы сначала определяем смещение в буфере обучаемых параметров. А затем организовываем цикл перебора элементов окна исходных данных.
for(int k = 0; k <= stop; k += 4) { switch(stop - k) { case 0: inp = (float4)(1, 0, 0, 0); weight = (float4)(matrix_w[shift_var_w + shift + window_in_h], 0, 0, 0); break; case 1: inp = (float4)(matrix_i[shift_var_in + shift_in + k], 1, 0, 0); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + window_in_h], 0, 0); break; case 2: inp = (float4)(matrix_i[shift_var_in + shift_in + k], matrix_i[shift_var_in + shift_in + k + 1], 1, 0); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + k + 1], matrix_w[shift_var_w + shift + window_in_h], 0); break; case 3: inp = (float4)(matrix_i[shift_var_in + shift_in + k], matrix_i[shift_var_in + shift_in + k + 1], matrix_i[shift_var_in + shift_in + k + 2], 1); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + k + 1], matrix_w[shift_var_w + shift + k + 2], matrix_w[shift_var_w + shift + shift_w_h]); break; default: inp = (float4)(matrix_i[shift_var_in + shift_in + k], matrix_i[shift_var_in + shift_in + k + 1], matrix_i[shift_var_in + shift_in + k + 2], matrix_i[shift_var_in + shift_in + k + 3]); weight = (float4)(matrix_w[shift_var_w + shift + k], matrix_w[shift_var_w + shift + k + 1], matrix_w[shift_var_w + shift + k + 2], matrix_w[shift_var_w + shift + k + 3]); break; }
С целью оптимизации вычислительных процессов для операций свертки мы воспользуемся встроенным умножением векторных переменных, которые позволяют более эффективно использовать ресурсы процессора. Поэтому мы сначала переносим данные из внешних буферов в локальные векторные переменные, а затем осуществляем умножение векторов и переходим к следующей итерации вложенного цикла.
sum += IsNaNOrInf(dot(inp, weight), 0);
}
После выполнения всех итераций вложенного цикла, мы выполняем операции функции активации и сохраняем полученное значение в соответствующий элемент буфера результатов. И переходим к следующей итерации внешнего цикла.
sum = IsNaNOrInf(sum, 0); //--- matrix_o[shift_var_out + out + shift_out] = Activation(sum, activation);; } }
По завершению всех итераций системы циклов, в буфере результатов будут сохранены все необходимые значения, и мы завершаем работу кернела.
Далее мы переходим к построению алгоритмов обратного прохода. И здесь, надо сказать, мы уже не можем ввести идентификатор головы свертки в виде измерения пространства задач.
Напомню, что в процессе выполнения алгоритма распределения градиента ошибки мы собираем значения влияния каждого элемента исходных данных на результат. И в случае, когда шаг анализируемого окна свертки меньше его размера, один элемент исходных данных может оказывать влияние на элементы тензора результатов из разных голов свертки.
Поэтому в данном случае мы вводим количество голов внимания в виде дополнительного внешнего параметра кернела CalcHiddenGradientMHConv. А идентификатор конкретной головы свертки определяем в процессе сбора градиентов ошибки.
__kernel void CalcHiddenGradientMHConv(__global float *matrix_w, __global float *matrix_g, __global float *matrix_o, __global float *matrix_ig, const int outputs, const int step, const int window_in, const int window_out, const int activation, const int shift_out, const int heads ) { const size_t i = get_global_id(0); const size_t inputs = get_global_size(0); const size_t v = get_global_id(1);
В теле кернела мы идентифицируем текущий поток в двухмерном пространстве задач, которое указывает на элемент исходных данных и идентификатор унитарной последовательности. После чего определяем значения констант, среди которых смещения в буферах данных, а так же размерности окна и количество фильтров для одной головы свертки.
const int shift_var_in = v * inputs; const int shift_var_out = v * outputs; const int shift_var_w = v * window_out * (window_in + 1); const int window_in_h = (window_in + heads - 1) / heads; const int window_out_h = (window_out + heads - 1) / heads;
Тут же мы определяем диапазон окна результатов, на которые оказывает влияние анализируемый элемент исходных данных.
float sum = 0; float out = matrix_o[shift_var_in + i]; const int w_start = i % step; const int start = max((int)((i - window_in + step) / step), 0); int stop = (w_start + step - 1) / step; stop = min((int)((i + step - 1) / step + 1), stop) + start; if(stop > (outputs / window_out)) stop = outputs / window_out;
После проведения подготовительной работы, мы переходим к сбору градиентов ошибки от всех зависимых элементов тензора результатов. Для этого мы организуем систему циклов. Внешний цикл будет перебирать зависимые элементы в пределах ранее определенного окна.
for(int k = start; k < stop; k++) { int head = (k % window_out) / window_out_h;
В теле внешнего цикла мы сначала определяем голову свертки для отдельно взятого элемента тензора результатов, а затем организовываем вложенный цикл перебора фильтров.
for(int h = 0; h < window_out_h; h ++) { int shift_g = k * window_out + head * window_out_h + h; int shift_w = (stop - k - 1) * step + (i % step) / window_in_h + head * (window_in_h + 1) + h * (window_in_h + 1); if(shift_g >= outputs || shift_w >= (window_in_h + 1) * window_out) break; float grad = matrix_g[shift_out + shift_g + shift_var_out]; sum += grad * matrix_w[shift_w + shift_var_w]; } }
Именно в теле вложенного цикла мы собираем градиент ошибки по всем фильтрам одной головы свертки и переходим к следующей итерации системы циклов.
После успешного сбора градиентов ошибки со всех зависимых элементов мы корректируем собранное значение на производную функции активации и сохраняем полученный результат в соответствующем элементе буфера данных.
matrix_ig[shift_var_in + i] = Deactivation(sum, out, activation); }
На этом завершаются операции кернела распределения градиента ошибки. А с кернелом обновления параметров модели я предлагаю вам ознакомиться самостоятельно. Полный код OpenCL-программы вы найдете во вложении к статье. А мы переходим к следующему этапу нашей работы — построению объекта нейронного слоя многоголовой свертки на стороне основной программы.
Слой многоголовой свертки
Для реализации функционала свертки на стороне основной программы, мы создадим новый объект CNeuronMHConvOCL. И, как не сложно догадаться, в качестве родительского класса мы использовали существующий сверточный слой. Структура нового объекта представлена ниже.
class CNeuronMHConvOCL : public CNeuronConvOCL { protected: uint iHeads; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMHConvOCL(void) : iHeads(1) {}; ~CNeuronMHConvOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronMHConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; };
В представленной структуре объекта мы лишь объявляем одну внутреннюю переменную для хранения заданного количества голов свертки. Все остальные объекты и переменные, необходимые для организации процессов, мы унаследуем от родительского класса. Кроме того, мы переопределяем методы прямого и обратного проходов, которые являются "обертками" для вызова вышеописанных кернелов. Алгоритм постановки кернелов в очередь выполнения остается прежним. Поэтому мы не будем останавливаться на рассмотрении указанных методов. В рамках данной статьи я предлагаю разобраться лишь в методе инициализации нового объекта Init, который мы создали практически "с чистого листа".
В структуре параметров метода инициализации был добавлен лишь один элемент для передачи из вызывающей программы количества голов свертки.
bool CNeuronMHConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronProofOCL::Init(numOutputs, myIndex, open_cl, window, step, units_count * window_out * variables, ADAM, batch)) return false;
В теле метода мы сразу вызываем одноименный метод подвыборочного слоя, который в данном случае является прародительским объектом. А затем сохраняем значения внешних параметров в локальные переменные.
iWindowOut = window_out; iVariables = variables; iHeads = MathMax(MathMin(heads, window), 1);
Далее нам предстоит инициализировать случайными значениями тензор обучаемых параметров. Но прежде, определим размерность данного тензора. Она зависит от количества унитарных рядов в анализируемой мультимодальной последовательности, общего количества фильтров и размера анализируемого окна одной головы свертки.
const int window_h = int((iWindow + heads - 1) / heads); const int count = int((window_h + 1) * iWindowOut * iVariables);
Обратите внимание, что мы говорим об общем количестве фильтров всех голов свертки, но при этом используем анализируемое окно только одной головы. Не сложно догадаться, что количество обучаемых параметров для одной головы свертки равно произведению количества фильтров для одной головы на размер анализируемого ею окна исходных данных, плюс один элемент байесовского смещения (Fi * (Wi + 1)). Тогда, для получения общего количества параметров для одной унитарной последовательности, нам достаточно умножить полученное значение на количество голов свертки (Fi * (Wi + 1) * H). И здесь очевидно, что количество фильтров одной головы свертки, помноженное на количество голов, даст нам общее количество фильтров, заданное пользователем.
Следующим шагом мы проверяем актуальность указателя на объект буфера обучаемых параметров и, при необходимости, создаём новый объект.
if(!WeightsConv) { WeightsConv = new CBufferFloat(); if(!WeightsConv) return false; }
Резервируем нужное количество элементов в буфере и организовываем цикл заполнения буфера случайными значениями.
if(!WeightsConv.Reserve(count)) return false; float k = (float)(1 / sqrt(window_h + 1)); for(int i = 0; i < count; i++) { if(!WeightsConv.Add((GenerateWeight() * 2 * k - k) * WeightsMultiplier)) return false; } if(!WeightsConv.BufferCreate(OpenCL)) return false;
После успешного заполнения буфера случайными значениями, мы переносим его в память OpenCL-контекста. Тут же мы создаем буферы моментов, заполнив их нулевыми значениями.
if(!FirstMomentumConv) { FirstMomentumConv = new CBufferFloat(); if(!FirstMomentumConv) return false; } if(!FirstMomentumConv.BufferInit(count, 0.0)) return false; if(!FirstMomentumConv.BufferCreate(OpenCL)) return false; //--- if(!SecondMomentumConv) { SecondMomentumConv = new CBufferFloat(); if(!SecondMomentumConv) return false; } if(!SecondMomentumConv.BufferInit(count, 0.0)) return false; if(!SecondMomentumConv.BufferCreate(OpenCL)) return false; if(!!DeltaWeightsConv) delete DeltaWeightsConv; //--- return true; }
На этом мы завершаем рассмотрение методов объекта многоголового сверточного слоя CNeuronMHConvOCL. С полным кодом указанного класса и всех его методов вы можете ознакомиться во вложении.
Многоголовый блок FeedForward
Мы уже создали первый "кирпичик" на пути построения фреймворка StockFormer. И теперь воспользуемся им для создания блока многоголового FeedForward в рамках нового объекта CNeuronMHFeedForward, структура которого приведена ниже.
class CNeuronMHFeedForward : public CNeuronBaseOCL { protected: CNeuronMHConvOCL acConvolutions[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMHFeedForward(void) {}; ~CNeuronMHFeedForward(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronMHFeedForward; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; };
В структуре нового объекта мы объявляем массив из двух внутренних многоголовых сверточных слоев и переопределяем уже привычный набор виртуальных методов. Внутренние объекты объявляются статично, что позволяет оставить пустыми конструктор и деструктор класса. Инициализация всех объявленных и унаследованных объектов осуществляется в методе Init.
bool CNeuronMHFeedForward::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_out, uint units_count, uint variables, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * variables, optimization_type, batch)) return false;
В параметрах метода инициализации мы получаем константы, определяющие архитектуру создаваемого объекта. Часть из полученных параметров мы сразу передаем в одноименный метод родительского класса для инициализации унаследованных базовых интерфейсов.
Далее мы инициализируем первый сверточный слой, указав ему GELU в качестве функции активации.
if(!acConvolutions[0].Init(0, 0, OpenCL, window, window, window_out, units_count, variables, heads, optimization, iBatch)) return false; acConvolutions[0].SetActivationFunction(GELU);
Затем инициализируем второй сверточный слой уже без функции активации.
if(!acConvolutions[1].Init(0, 1, OpenCL, window_out, window_out, window, units_count, variables, heads, optimization, iBatch)) return false; acConvolutions[1].SetActivationFunction(None);
И обратите внимание, что при вызове метода инициализации второго сверточного слоя мы переставляем параметры количества фильтров и анализируемого окна исходных данных.
На выходе блока FeedForward используются остаточные связи с нормализацией данных, поэтому мы не переопределяем буфер интерфейса результатов нашего блока. Тем не менее, мы переопределим буфер градиентов ошибки, что позволит осуществить непосредственную передачу градиентов из интерфейсов в соответствующий буфер второго сверточного слоя.
if(!SetGradient(acConvolutions[1].getGradient(), true)) return false; SetActivationFunction(None); //--- return true; }
Мы так же отключаем функцию активации для нашего блока и завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
После завершения работы по инициализации нового объекта, мы переходим к построению алгоритма прямого прохода в рамках метода feedForward. И надо сказать, что в данном случае его реализация не вызывает трудностей. Мы лишь последовательно вызываем одноименные методы внутренних сверточных слоев.
bool CNeuronMHFeedForward::feedForward(CNeuronBaseOCL *NeuronOCL) { CObject *prev = NeuronOCL; for(uint i = 0; i < acConvolutions.Size(); i++) { if(!acConvolutions[i].FeedForward(prev)) return false; prev = GetPointer(acConvolutions[i]); }
А затем суммируем полученные значения с исходными данными с нормализацией результатов в рамках отдельных элементов анализируемой мультимодальной последовательности.
if(!SumAndNormilize(NeuronOCL.getOutput(), acConvolutions[acConvolutions.Size() - 1].getOutput(), Output, acConvolutions[0].GetWindow(), true, 0, 0, 0, 1)) return false; //--- return true; }
И завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Немного сложнее выглядит алгоритм метода распределения градиента ошибки calcInputGradients, что связано с необходимостью проведения градиентов по двум информационным потокам.
bool CNeuronMHFeedForward::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В параметрах метода мы получаем указатель на объект исходных данных, в буфер которого нам предстоит передать градиент ошибки в объеме влияния исходных данных на итоговый результат работы модели. И в теле метода мы сразу проверяем актуальность полученного указателя.
После успешного прохождения блока контролей, мы организовываем цикл обратного перебора внутренних сверточных слоев с последовательным вызовом их одноименных методов.
for(int i = (int)acConvolutions.Size() - 2; i >= 0; i--) { if(!acConvolutions[i].calcHiddenGradients(acConvolutions[i + 1].AsObject())) return false; }
За распределением градиента ошибки по магистрали внутренних объектов следует его передача на уровень исходных данных. Эта операция завершает операции основного потока информации.
if(!NeuronOCL.calcHiddenGradients(acConvolutions[0].AsObject())) return false;
Далее нам предстоит провести градиент ошибки по второму информационному потоку. И здесь алгоритм делится на две ветви операций, в зависимости от наличия функции активации исходных данных. При отсутствии функции активации достаточно просто суммировать накопленный градиент ошибки на уровне исходных данных с аналогичными значениями на выходе нашего блока.
if(NeuronOCL.Activation() == None) { if(!SumAndNormilize(NeuronOCL.getGradient(), Gradient, NeuronOCL.getGradient(), acConvolutions[0].GetWindow(), false, 0, 0, 0, 1)) return false; } else { if(!DeActivation(NeuronOCL.getOutput(), NeuronOCL.getPrevOutput(), Gradient, NeuronOCL.Activation()) || !SumAndNormilize(NeuronOCL.getGradient(), NeuronOCL.getPrevOutput(), NeuronOCL.getGradient(), acConvolutions[0].GetWindow(), false, 0, 0, 0, 1)) return false; } //--- return true; }
В противном случае нам необходимо сначала скорректировать градиент ошибки уровня результатов нашего блока на производную функции активации исходных данных. И только потом осуществить операцию суммирования данных их двух информационным потоком.
Теперь нам остается лишь вернуть логический результат выполнения вызывающей программе и завершить работу метода.
Метод корректировки обучаемых параметров блока в сторону снижения общей ошибки работы модели updateInputWeights я предлагаю оставить для самостоятельного изучения. Его алгоритм довольно прост: мы лишь последовательно вызываем одноименные методы внутренних объектов. Полный код объекта многоголового блока FeedForwardCNeuronMHFeedForward и всех его методов можно найти во вложении к статье.
Декодер диверсифицированного многоголового внимания
После создания блока многоголового FeedForward мы переходим к построению объектов энкодера и декодера диверсифицированного многоголового внимания. Для построения алгоритмов указанных модулей мы создадим новые объекты CNeuronDMHAttention и CNeuronCrossDMHAttention, соответственно. Структура построения объектов довольно схожа. Последний отличается наличием внутреннего блока кросс-внимания и работай с двумя источниками исходных данных. В рамках данной статьи я предлагаю остановиться на рассмотрении алгоритмов построения декодера, как более сложного объекта. После их рассмотрения, я думаю, Вам не составит труда понять алгоритмы энкодера.
В качестве родительского объекта в обоих случаях мы использовали CNeuronRMAT в рамках которого организован алгоритм последовательной модели.
class CNeuronCrossDMHAttention : public CNeuronRMAT { protected: //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronCrossDMHAttention(void) {}; ~CNeuronCrossDMHAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint window_cross, uint units_cross, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronCrossDMHAttention; } };
В структуре объекта декодера можно заметить лишь переопределение виртуальных методов. Структура внутренних объектов задается в методе инициализации Init, в параметрах которого мы получаем основные константы, определяющие архитектуру объекта.
bool CNeuronCrossDMHAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint window_cross, uint units_cross, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода мы сначала вызываем одноименный метод базового объекта полносвязного слоя для инициализации унаследованных интерфейсов.
А затем очищаем динамический массив хранения указателей на внутренние объекты модуля и создаем несколько локальных переменных для временного хранения данных.
cLayers.Clear(); cLayers.SetOpenCL(OpenCL); CNeuronRelativeSelfAttention *attention = NULL; CNeuronRelativeCrossAttention *cross = NULL; CNeuronMHFeedForward *conv = NULL; bool use_self = units_count > 0; int layer = 0;
На этом подготовительная работа завершена и организовываем цикл с числом итераций равным заданному количеству внутренних слоев декодера диверсифицированного многоголового внимания.
for(uint i = 0; i < layers; i++) { if(use_self) { attention = new CNeuronRelativeSelfAttention(); if(!attention || !attention.Init(0, layer, OpenCL, window, window_key, units_count, heads, optimization, iBatch) || !cLayers.Add(attention) ) { delete attention; return false; } layer++; }
В теле цикла мы сначала создаем блок относительного Self-Attention для анализа зависимостей в исходных данных основного потока. Однако обратите внимание, что блок Self-Attention создается только при длине последовательности исходных основного потока больше "1". В противном случае у нас нет данных для поиска зависимостей.
Далее мы добавляем модуль относительного кросс-внимания.
cross = new CNeuronRelativeCrossAttention(); if(!cross || !cross.Init(0, layer, OpenCL, window, window_key, units_count, heads, window_cross, units_cross, optimization, iBatch) || !cLayers.Add(cross) ) { delete cross; return false; } layer++;
И завершает каждый внутренний слой декодера многоголовый блок FeedForward. После чего мы переходим к следующей итерации цикла.
conv = new CNeuronMHFeedForward(); if(!conv || !conv.Init(0, layer, OpenCL, window, 2 * window, units_count, 1, heads, optimization, iBatch) || !cLayers.Add(conv) ) { delete conv; return false; } layer++; }
После завершения инициализации полного объема внутренних объектов мы осуществляем подмену указателей на объекты интерфейсов и завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
SetOutput(conv.getOutput(), true); SetGradient(conv.getGradient(), true); //--- return true; }
Алгоритм метода прямого прохода feedForward не содержит каких-либо сложных моментов и заключается в последовательном вызове одноименных методов внутренних объектов. Предлагаю оставить его для самостоятельного изучения. Однако, уделим немного времени рассмотрению алгоритма распределения градиента ошибки calcInputGradients.
bool CNeuronCrossDMHAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondInput || !SecondGradient) return false;
В параметрах метода мы получаем указатели на объекты исходных данных и их градиентов ошибки, в которые нам и предстоит записать результаты операций. Поэтому в теле метода мы сразу проверяем актуальность полученных указателей.
Далее стоит обратить внимание, что второй источник исходных данных, в рамках операций прямого прохода, в равной степени использовался модулями кросс-внимания всех внутренних слоев декодера. Соответственно, нам предстоит собрать градиент ошибки со всех информационных потоков, и, как обычно, в таком случае нам потребуется буфер внутреннего хранения данных, который мы не создали в рамках нового объекта. Поэтому воспользуемся одним из неиспользуемых буферов, унаследованных от родительского класса.
Вначале мы проверим размер унаследованного буфера и, при необходимости, скорректируем его.
if(PrevOutput.Total() != SecondGradient.Total()) { PrevOutput.BufferFree(); if(!PrevOutput.BufferInit(SecondGradient.Total(), 0) || !PrevOutput.BufferCreate(OpenCL)) return false; }
А затем заполним нулевыми значениями буфер градиентов ошибки для второго источника данных. Эта операция необходима для исключения суммирования градиентов текущего прохода с ранее накопленными.
if(!SecondGradient.Fill(0)) return false;
И создадим локальные переменные временного хранения данных.
CObject *next = cLayers[-1]; CNeuronBaseOCL *current = NULL;
На этом этап подготовительной работы завершен, и мы создаем цикл обратного перебора внутренних объектов.
for(int i = cLayers.Total() - 2; i >= 0; i--) { current = cLayers[i]; if(!current || !current.calcHiddenGradients(next, SecondInput, PrevOutput, SecondActivation)) return false; if(next.Type() == defNeuronCrossDMHAttention) if(!SumAndNormilize(SecondGradient, PrevOutput, SecondGradient, 1, false, 0, 0, 0, 1)) return false; next = current; }
В теле цикла мы последовательно вызываем одноименные методы внутренних объектов, и постоянно проверяем тип объекта, который осуществляет распределение градиента ошибки. В случае использования блока кросс-внимания, мы добавляем полученный градиент ошибки второго источника данных к ранее накопленным значениям.
После успешного выполнения всех итераций цикла, мы осуществляем передачу градиента ошибки на уровень исходных данных основной магистрали.
if(!NeuronOCL.calcHiddenGradients(next, SecondInput, PrevOutput, SecondActivation)) return false; if(next.Type() == defNeuronCrossDMHAttention) if(!SumAndNormilize(SecondGradient, PrevOutput, SecondGradient, 1, false, 0, 0, 0, 1)) return false; //--- return true; }
При этом проверяем тип объекта распределения градиента ошибки и, при необходимости, добавляем градиент второго информационного потока к ранее накопленным данным. После чего нам остается лишь завершить работу метода, вернув логический результат выполнения операций вызывающей программе.
На этом мы завершаем рассмотрение алгоритмов построения методов декодера диверсифицированного многоголового внимания. С полным кодом данного объекта и всех его методов Вы можете ознакомиться во вложении. Там же Вы найдете полный код всех объектов, представленных в данной статье.
Что ж, мы реализовали основную архитектурную единицу фреймворка StockFormer — диверсифицированный модуль многоголового внимания в виде энкодера и декодера архитектуры Transformer. Однако, авторы StockFormer предложили двухуровневый процесс обучения со сложным механизмом взаимодействия обучаемых моделей. Об этом мы поговорим в следующей статье.
Заключение
Мы познакомились с фреймворком StockFormer, авторы которого предложили инновационный подход к обучению торговых стратегий на финансовых рынках. StockFormer сочетает методы предиктивного кодирования и глубокого обучения с подкреплением. Его основное преимущество заключается в способности обучать гибкие политики, учитывающие динамические зависимости между несколькими активами, а также прогнозировать их поведение в краткосрочной и долгосрочной перспективах.
Трёхветвевое предиктивное кодирование обеспечивает извлечение латентных представлений, связанных с краткосрочными трендами, долгосрочной динамикой и взаимозависимостями между активами. А механизм каскадного многоголового внимания позволяет эффективно интегрировать разные типы представлений в единое пространство состояний.
В практической части статьи мы реализовали средствами MQL5 предложенную авторами метода модификацию ванильного алгоритма Transformer и внедрили её в модули энкодера и декодера диверсифицированного многоголового внимания. В следующей статье мы продолжим начатую работу и поговорим об архитектуре обучаемых моделей, а также о процессе их обучения.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study1.mq5 | Советник | Советник обучения предиктивного обучения |
| 4 | Study2.mq5 | Советник | Советник обучения политики |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования