
Нейросети — это просто (Часть 49): Мягкий Актор-Критик (Soft Actor-Critic)

Введение
Мы продолжаем наше знакомство с алгоритмами решения задач методом обучения с подкреплением в непрерывном пространстве действий. В предыдущих статьях мы уже познакомились с алгоритмами Deep Deterministic Policy Gradient (DDPG) и Twin Delayed Deep Deterministic policy gradient (TD3). В этой статье я предлагаю Вам познакомиться с ещё одним алгоритмом — Soft Аctor-Critic (SAC). Данный алгоритм впервые был представлен в статье "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor" (январь 2018 г). Метод был представлен практически одновременно с TD3 и имеет некоторые схожие моменты, но есть и отличия в алгоритмах. Основной целью SAC является максимизация ожидаемой награды с учетом максимальной энтропии политики, что позволяет находить разнообразные оптимальные решения в стохастических средах.
1. Алгоритм Soft Actor-Critic
Начиная рассмотрение алгоритма SAC, наверное, сразу надо обратить внимание, что он не является прямым наследником метода TD3 (как и наоборот). Но у них есть некоторое сходство. Они оба:
- являются алгоритмами off-policy
- эксплуатируют подходы DDPG
- используют 2 Критика.
Нo в отличии от двух ранее рассмотренных методов, SAC использует стохастическую политику Актера. Что позволяет алгоритму исследовать различные стратегии и находить оптимальные решения с учетом максимального разнообразия действий актера.
Говоря о стохастичности окружающей среды, мы понимаем, что в состоянии S при совершении действия A мы получаем награду R в диапазоне [Rmin, Rmax] с некой вероятностью Psa.
Soft Actor-Critic использует Актера со стохастической политикой. Это означает, что Актер в состоянии S может выбрать некое действие A' из всего пространства действий с некой вероятностью Pa'. Иными словами, политика Актера в каждом конкретном состоянии позволяет выбрать не одно конкретное оптимальное действие, а любое из возможных действий (но с определенной долей вероятности). И в процессе обучения Актер учит это вероятностное распределения получения максимального вознаграждения.
Это свойство стохастической политики Актера позволяет исследовать различные стратегии и обнаруживать оптимальные решения, которые могут быть скрыты при использовании детерминированной политики. Кроме того, стохастическая политика Актера учитывает неопределенность в окружающей среде. При наличии шума или случайных факторов такая политика может быть более устойчивой и адаптивной, поскольку позволяет генерировать разнообразные действия для эффективного взаимодействия с окружающей средой.
Однако, обучение стохастической политики актера вносит коррективы и в процесс обучения. Классическое обучение с подкреплением направлено на максимизацию ожидаемой доходности. В процессе обучения, можно сказать, для каждого действия S мы выбираем такое действие A*, которое с наибольшей вероятностью даст нам большую доходность. Такой детерминированный подход выстраивает четкую зависимость St → At → St+1 ⇒ R и не оставляет место стохастичности действий. Для обучения стохастичной политики авторы алгоритма Soft Actor-Critic вводят энтропийную регуляризацию в функцию награды.
![]()
Энтропия (H) в данном контексте является мерой неопределенности или разнообразия политики. А параметр ɑ>0 является коэффициентом температуры и позволяет балансировать между исследованием среды и эксплуатацией модели.
Напомню, энтропия является мерой неопределенности случайной величины и определяется по формуле
![]()
Обратите внимание, что мы говорим о логарифме вероятности выбора действия в диапазоне значений [0, 1]. И на данном интервале допустимых значений график функции энтропии убывающий и лежит в зоне положительных значений. Таким образом, чем ниже вероятность выбора действия, тем выше вознаграждение и модель стимулируется к исследованию окружающей среды.
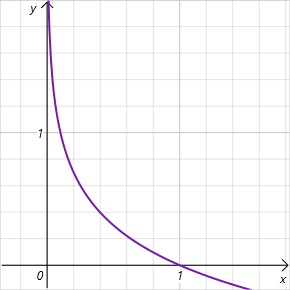
Как можно заметить, в этой связи выдвигаются довольно высокие требования к подбору гиперпараметра ɑ. И в настоящее время существуют различные варианты реализации алгоритма SAC. Среди них есть классический подход с фиксированным параметром. Довольно часто можно встретить реализации с постепенным снижением параметра. Легко заметить, что при ɑ=0 мы приходим к детерминированному обучению с подкреплением. Кроме того, есть различные подходы к оптимизации параметра ɑ самой моделью в процессе обучения.
С функцией вознаграждения разобрались. Переходим к обучению Критика. Аналогично TD3, SAC обучает параллельно 2 модели Критика с использованием MSE в качестве функции потерь. Для прогнозной стоимости будущего состояния используется меньшее значение от двух целевых моделей Критика. Но здесь 2 ключевых отличия.
Во-первых, это рассмотренная выше функция вознаграждения. Энтропийную регуляризацию мы используем как для текущего, так и для последующего состояния. Конечно, с учетом коэффициента дисконтирования, применяемого к стоимости следующего состояния системы.
Второе отличие заключается в Актере. SAC не использует целевой модели Актера. Для выбора действия в текущем и последующем состоянии используется одна обучаемая модель Актера. Тем самым мы подчеркиваем, что достижение будущего вознаграждения достигается с использование текущей политики. Кроме того, использование одной модели Актера позволяет снизить затраты памяти и вычислительных ресурсов.
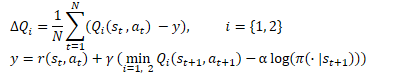
Для обучения политики Актера мы используем подходы DDPG. Градиент ошибки действия мы получаем благодаря обратному распространению градиента ошибки прогнозной стоимости действия через модель Критика. Но в отличии от TD3 (где мы использовали только модель Критика 1), авторы SAC предлагают использовать модель с меньшей оценочной стоимостью действия.
Здесь есть ещё один момент. В процессе обучения мы изменяем политику, что ведет к изменению действий Актера в том или ином состоянии системы. Кроме того, использование стохастической политики Актера также вносит свой вклад в разнообразие действий Актера. В то же время мы обучаем модели на данных из буфера воспроизведения опыта с вознаграждением за другие действия агента. В данном случае мы руководствуемся теоретическим допущением, что в процессе обучения Актера мы двигаемся в направлении максимизации прогнозного вознаграждение. Значит в любом состоянии S стоимость действия с использованием новой политики πnew будет неменьше стоимости действия в старой политике πold.
![]()
Довольно субъективное допущение, но полностью соответствует нашей парадигме обучения моделей. И чтобы не накапливать возможные ошибки, могу порекомендовать в процессе обучения чаще обновлять буфер воспроизведения опыта с учетом обновлений политики Актера.
Обновление целевых моделей осуществляется сглажено с использованием коэффициента τ, аналогично TD3.
И ещё одно отличия от метода TD3. В алгоритме Soft Actor-Critic не используется задержка в обучении Актера и обновлении целевых моделей. Здесь обновление всех моделей происходит на каждом шаге обучения.
Обобщим алгоритм Soft Actor-Critic:
- В функцию вознаграждения вводится энтропийная регуляризация.
- В начале процесса обучения случайными параметрами инициализируются модели Актера и 2 Критиков.
- В результате взаимодействия со средой заполняется буфер воспроизведения опыта. Сохраняем состояние окружающей среды, действие, последующее состояние и вознаграждение.
- После заполнения буфера воспроизведения опыта обучаем модели
- Случайным образом из буфера воспроизведения опыта извлекаем набор данных
- Определяем действие для будущего состояния с учетом текущей политики Актера
- Определяем прогнозную стоимость будущего состояния при использовании текущей политики как минимум 2 целевых моделей Критиков
- Осуществляем обновление моделей Критиков
- Обновляем политику Актера
- Обновляем целевые модели.
Процесс обучения моделей итерационный и повторяется до получения желаемого результата или достижения минимального экстремума в графике функции потерь Критиков.
2. Реализация средствами MQL5
После теоретического ознакомления с алгоритмом Soft Actor-Critic мы переходим к его реализации средствами MQL5. И первое с чем мы сталкиваемся — это определение вероятности того или иного действия. На самом деле довольно простой вопрос для табличной реализации политики Актера. Но вызывает сложности в случае использования нейронных сетей. Ведь мы не ведем статистику состояний окружающей среды и выполняемых действий. Она "зашита" в настраиваемых параметрах нашей модели. И в этой связи я вспомнил о распределенном Q-обучении. Помните, именно тогда мы говорили об изучении вероятностного распределения ожидаемого вознаграждения. Дистрибутивное Q-обучение позволило нам получить вероятностное распределение для заданного числа фиксированных интервальных значений вознаграждения. А модель полностью параметризированной Q-функции (FQF) позволяет изучать как интервальные значения, так и их вероятности.
2.1 Создание класса нового нейронного слоя
Наследуясь от класса CNeuronFQF, мы создадим новый класс нейронного слоя для реализации предложенного алгоритма CNeuronSoftActorCritic. Набор методов нового класса довольно стандартный, но есть и свои особенности.
В частности, в своей реализации мы решили использовать настраиваемые параметры энтропийной регуляризации. Для этого был добавлен нейронный слой cAlphas. В данной реализации используется слой типа CNeuronConcatenate. Так как для принятия решения о размере коэффициентов мы будем использовать эмбединг текущего состояния и квантильное распределение на выходе.
Кроме того, мы добавили отдельный буфер для записи значений энтропии, которые в последующем будем использовать в функции вознаграждения.
Оба добавленных объекта объявлены статичными, что позволяет нам оставить пустыми конструктор и деструктор класса.
class CNeuronSoftActorCritic : public CNeuronFQF { protected: CNeuronConcatenate cAlphas; CBufferFloat cLogProbs; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSoftActorCritic(void) {}; ~CNeuronSoftActorCritic(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcAlphaGradients(CNeuronBaseOCL *NeuronOCL); virtual bool GetAlphaLogProbs(vector<float> &log_probs) { return (cLogProbs.GetData(log_probs) > 0); } virtual bool CalcLogProbs(CBufferFloat *buffer); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronSoftActorCritic; } virtual void SetOpenCL(COpenCLMy *obj); };
Первым мы рассмотрим метод инициализации класса Init. параметры метода полностью повторяют параметры аналогичного метода родительского класса. И в теле метода мы сразу вызываем метод родительского класса. Данный прием мы используем довольно часто. Ведь в родительском классе реализованы все необходимые контроли. А так же осуществляется инициализация всех унаследованных объектов. Одна проверка результатов выполнения метода родительского класса заменяет полный контроль упомянутых операций. И нам остается лишь инициализировать добавленные объекты.
Первым мы инициализируем слой расчёта коэффициентов ɑ. Как уже было сказано выше, на вход данной модели мы подадим эмбединг текущего состояния, размер которого будет равен размеру предыдущего нейронного слоя. И добавим квантильное распределение на выходе текущего слоя, которое будет содержаться во внутреннем слое cQuantile2 (объявлен и инициализирован в родительском классе). На выходе слоя cAlphas мы планируем получить коэффициенты температуры по каждому отдельному действию. Соответственно, и размер слоя будут равен количеству действий.
Коэффициенты должны быть неотрицательными. Для удовлетворения этого требования мы определили Sigmoid в качестве функции активации этого слоя.
В завершении метода мы инициализируем нулевыми значениями буфер энтропии. Его размер также равен количеству действий. И сразу создадим буфер в текущем контексте OpenCL.
bool CNeuronSoftActorCritic::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFQF::Init(numOutputs, myIndex, open_cl, actions, quantiles, numInputs, optimization_type, batch)) return false; //--- if(!cAlphas.Init(0, 0, OpenCL, actions, numInputs, cQuantile2.Neurons(), optimization_type, batch)) return false; cAlphas.SetActivationFunction(SIGMOID); //--- if(!cLogProbs.BufferInit(actions, 0) || !cLogProbs.BufferCreate(OpenCL)) return false; //--- return true; }
Далее мы переходим к реализации процесса прямого прохода. Здесь надо сказать, что непосредственно процесс обучения квантилей и вероятностного распределения мы полностью заимствуем из родительского класса без изменений. Но вот организацию процесса определения коэффициентов температуры и вычисление значений энтропии нам предстоит добавить. Более того, если для вычисления коэффициентов температуры нам достаточно вызвать прямой проход слоя cAlphas, то определение значений энтропии предстоит реализовать с «0».
Энтропию нам предстоит вычислять для каждого действия Актера. На данном этапе мы ожидаем, что здесь будет не большое число действий. Но так как все исходные данные находятся в памяти контекста OpenCL, то и наши операции логично перенести в данную среду. И сначала мы создадим кернел SAC_AlphaLogProbs OpenCL программы для реализации данного функционала.
В параметрах кернела мы будем передавать 5 буферов данных и 2 константы:
- outputs — буфер результатов, содержит взвешенные по вероятности суммы значений квантилей по каждому действию
- quantiles — средние значения квантилей (буфер результатов внутреннего слоя cQuantile2)
- probs — тензор вероятностей (буфер результатов внутреннего слоя cSoftMax)
- alphas — вектор коэффициентов температуры
- log_probs — вектор значений энтропии (в данном случае буфер для записи результатов)
- count_quants — количество квантилей по каждому действию
- activation — тип функции активации.
Сразу надо обратить внимание, что в классе CNeuronFQF не используется функция активации на выходе. Я бы даже сказал, что она противоречит его сущности. Ведь распределение средних значений квантилей ожидаемой награды отграничивается самой фактической наградой в процессе обучения модели. В нашем же случае на выходе слоя мы ожидаем некое значения действия Актера из непрерывного распределения. В силу различных технических или прочих обстоятельств область допустимых действий агента может быть ограничена некоторыми рамками. И это нам позволяет сделать функция активации. Но нам очень важно для получения истинной оценки вероятности, чтобы функция активации была применена уже после определения вероятности фактического действия. Поэтому её реализацию мы добавили в данный кернел.
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float quant1 = -1e37f; float quant2 = 1e37f; float prob1 = 0; float prob2 = 0; float value = outputs[i];
В теле кернела мы идентифицируем текущий поток операций. Он укажет нам порядковый номер анализируемого действия. И тут же мы определим смещение в буферах квантилей и вероятностей.
Дале мы объявил локальные переменные. Для определения вероятности конкретного действия нам потребуется найти 2 ближайших квантиля. В переменную quant1 мы запишем среднее значение ближайшего снизу квантиля. А в переменную quant2 — среднее значение ближайшего сверху квантиля. На начальном этапе мы инициализируем указанные переменные заведомо экстремальными значениями. Соответствующие вероятности мы сохраним в переменные prob1 и prob2, которые инициализируем нулевыми значениями. Ведь в нашем понимание вероятность получение столь экстремальных значений равна «0».
Искомое значение из буфера мы сохраним в локальную переменную value.
Напомню, что ввиду особенностей организации памяти контекста OpenCL доступ к локальным переменным в разы быстрее получения данных из буфера глобальной памяти. И оперируя с локальными переменными мы повышаем быстродействие всей OpenCL программы.
Теперь, когда мы сохранили искомое значение в локальную переменную, можно безболезненно применить функцию активации к буферу результатов работы нейронного слоя.
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; break; default: break; }
Далее мы организовываем цикл перебора всех средних значений квантилей и ищем ближайшие.
Здесь надо обратить внимание, что мы не осуществляли сортировку средних значений квантилей. На определения средневзвешенного значения это не оказывает влияние, и мы ранее отказались от выполнения излишних операций. Поэтому, с большой долей вероятности ближайшие к искомому значению квантили будут находиться не в соседних элементах буфера квантилей. Следовательно, мы перебираем все значения.
И ещё один момент, чтобы не записать в обе переменные значения одного квантиля для нижней границы мы используем логический оператор ">=", а для верхней границы строго "<". При нахождении квантиля ближе ранее сохраненного мы переписываем значение в ранее объявленных соответствующих переменных среднее значение квантиля и его вероятность.
for(int q = 0; q < count_quants; q++) { float quant = quantiles[shift + q]; if(value >= quant && quant1 < quant) { quant1 = quant; prob1 = probs[shift + q]; } if(value < quant && quant2 > quant) { quant2 = quant; prob2 = probs[shift + q]; } }
После завершения всех итераций цикла в наших локальных переменных будут данные ближайших квантилей. И наше искомое значение находится где-то между ними. Однако, наши знания о вероятностном распределении действий ограничены только изученным распределением. В данном случае мы используем допущение о линейной зависимости вероятности между 2 ближайшими квантилями. При достаточно большом количестве квантилей с учетом ограниченного диапазона распределения значений области фактических действий наше допущение не далеко от истины.
float prob = fabs(value - quant1) / fabs(quant2 - quant1); prob = clamp((1-prob) * prob1 + prob * prob2, 1.0e-3f, 1.0f); log_probs[i] = -alphas[i] * log(prob); }
После определения вероятности действия мы определяем энтропию действия и умножаем полученное значение на коэффициент температуры. Для исключения слишком больших значений энтропии я ограничил нижнюю границу вероятности на уровне 0.001.
На этом мы завершаем работу над кернелами прямого прохода и переходим к основной программе. Здесь мы создаем метод прямого прохода нашего класса CNeuronSoftActorCritic::feedForward.
Как Вы помните, здесь мы широко эксплуатируем возможности виртуальных методов в наследуемых объектах. Поэтому параметры данного метода полностью повторяют аналогичные методы всех рассмотренных ранее классов.
В теле метода мы сначала осуществляем вызов метода прямого прохода родительского класса и аналогичный метод слоя вычисления коэффициентов температуры. Здесь нам достаточно проконтролировать результаты выполнения указанных методов.
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false;
Далее нам предстоит вычислить энтропийную составляющую функции вознаграждения. Для этого мы организовываем процесс запуска, рассмотренного выше кернела. Запускать мы его будем в одномерном пространстве задач по числу анализируемы действий.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Как всегда, перед постановкой кернела в очередь выполнения мы организовываем процесс передачи исходных данных в его параметры.
if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Обратите внимание, что мы не проверяем ни один буфер. Дело в том, что все используемые буферы уже прошли контроль на стадии прямого прохода метода родительского класса и слоя вычисления коэффициентов температуры. Не проверялся лишь внутренний буфер для записи результатов работы кернела. Но это внутренний объект, создание которого мы проконтролировали на стадии инициализации объекта класса. Доступ из внешней программы к объекту отсутствует. И вероятность получения ошибки в данном моменте достаточно низкая. Поэтому мы идем на такой риск в угоду быстродействию нашей программы.
В завершении метода осуществляем постановку кернела в очередь исполнения и проверяем результат выполнения операций.
if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Хочу ещё раз обратить внимание, что в данном случае мы проверяем результат постановки кернела в очередь выполнения, но не результаты выполнения операций внутри кернела. Для получения результатов нам необходимо будет загрузить данные буфера cLogProbs в основную память. Этот функционал реализован в методе GetAlphaLogProbs. Код метода умещается в одну строчку и приведен в блоке описания структуры класса.
На этом мы завершаем работу по организации процессе прямого прохода класса. И переходим к созданию функционала обратного прохода. Надо сказать, что основная часть функционала уже реализована в методе родительского класса. И, как это не покажется странным, мы даже не будем переопределять метод распределения градиента ошибки через нейронный слой. Дело в том, что распределение градиента ошибки на энтропийную регуляризацию немного не укладывается в нашу общую структуру. Градиент ошибки по действию мы получаем от модели Критика с его последнего слоя. Саму же энтропийную регуляризацию мы включили в функцию вознаграждения. Соответственно её ошибка будет также на уровне прогнозирования вознаграждения, т.е. на уровне слоя результатов Критика. И здесь мы получаем 2 вопроса:
- Введение дополнительного буфера градиентов нарушит выстроенную нами модель виртуализации методов обратного прохода.
- На стадии обратного прохода Актера у нас просто нет данных об ошибке Критика. Необходимо построение нового процесса для всей модели.
Мы решили обойтись, так сказать, "малой кровью" и создали новый параллельный процесс только для градиента ошибки энтропийной регуляризации без полного пересмотра процесса обратного распространения ошибки в модели.
Вначале мы создадим кернел в программе OpenCL. Его код довольно прост. Мы лишь умножаем полученный градиент ошибки на энтропию. И затем скорректируем полученное значение на производную функции активации слоя вычисления коэффициентов температуры.
__kernel void SAC_AlphaGradients(__global float *outputs, __global float *gradient, __global float *log_probs, __global float *alphas_grad, const int activation ) { const int i = get_global_id(0); float out = outputs[i]; //--- float grad = -gradient[i] * log_probs[i]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); grad = clamp(grad + out, -1.0f, 1.0f) - out; grad = grad * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); grad = clamp(grad + out, 0.0f, 1.0f) - out; grad = grad * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) grad = grad * 0.01f; break; default: break; } //--- alphas_grad[i] = grad; }
Здесь надо обратить внимание, что для упрощения вычислений мы просто умножаем градиент на значение из буфера log_probs. Как вы помните, при прямом прохода мы записали сюда значение энтропии с учетом коэффициента температуры. И с математической точки зрения нам необходимо разделить значение из буфера на данную величину. Но для температуры мы используем сигмоиду в качестве функции активации. Следовательно, её значение всегда в диапазоне [0,1]. Деление на положительное число меньше 1 лишь увеличит градиент ошибки. И в данном случае мы осознанно не делаем этого.
После завершения работы над кернелом SAC_AlphaGradients мы переходим к работе над основной программой и создадим метод CNeuronSoftActorCritic::calcAlphaGradients. На данном этапе мы сначала будем ставить кернел в очередь выполнения и только потом вызывать методы внутренних объектов. Поэтому, перед началом процесса мы организуем блок контролей.
bool CNeuronSoftActorCritic::calcAlphaGradients(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL || !NeuronOCL.getGradient() || !NeuronOCL.getGradientIndex()<0) return false;
Далее мы определяем пространство задач кернела и передаем исходные данные в его параметры.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_outputs, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_alphas_grad, cAlphas.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_gradient, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaGradients, def_k_sac_alg_activation, (int)cAlphas.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
После чего осуществляем постановку кернела в очередь выполнения и не забываем проконтролировать выполнение операций.
if(!OpenCL.Execute(def_k_SAC_AlphaGradients, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
В завершении метода мы вызываем метод обратного прохода нашего внутреннего слоя вычисления коэффициентов температуры.
return cAlphas.calcHiddenGradients(GetPointer(cQuantile0), cQuantile2.getOutput(), cQuantile2.getGradient()); }
Кроме того, мы переопределим метод обновления параметров нейронного слоя CNeuronSoftActorCritic::updateInputWeights. Алгоритм данного метода довольно прост. В нем лишь вызываются аналогичные методы родительского класса и внутренних объектов. С полным кодом данного метода можно ознакомиться во сложении. Там же вы найдете полный код всех методов и классов, используемых в данной статье. В том числе и методы работы с файлами нашего нового класса, на которых мы сейчас не будем останавливаться.
2.2 Внесение изменений в класс CNet
После завершения работы с новым классом мы объявим константы для обслуживания созданных кернелов. И не забудем добавить новые кернелы в процесс инициализации объекта контекста и программы OpenCL. Данный функционал мы повторяли уже более 50 раз при создании каждого нового кернела и не будем на нем останавливаться.
А нам пришло время вспомнить, что в функционале нашей библиотеке отсутствует возможность прямого доступа пользователя к конкретному нейронному слою. Весь процесс взаимодействия построен через функционал работы модели в целом на уровне классе CNet. И для получения пользователем значений энтропийной составляющей мы создадим метод CNet::GetLogProbs.
В параметрах метод получает указатель на вектор для записи значений.
В теле метода мы организовываем блок контролей с пошаговым снижение уровня объектов. Вначале мы проверяем наличие объекта динамического массива нейронных слоев. Затем спускаемся на уровень ниже и проверяем указатель на объект последнего нейронного слоя. Далее мы опускаемся ещё ниже и проверяем тип последнего нейронного слоя. Это должен быть наш новый слой CNeuronSoftActorCritic.
bool CNet::GetLogProbs(vectorf &log_probs) { //--- if(!layers) return false; int total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; CLayer *layer = layers.At(total - 1); if(!layer.At(0) || layer.At(0).Type() != defNeuronSoftActorCritic) return false; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
И лишь только после успешного прохождения всех уровней контроля вы обращаемся к аналогичному методу нашего нейронного слоя.
return neuron.GetAlphaLogProbs(log_probs);
}
Обратите внимание, на данном этапе мы ограничиваемся только последним слоем в модели. Это подразумевает, что использование слоя возможно только в качестве последнего слоя Актера.
И еще один момент, данный метод только считывает данные из буфера и не запускает процесс их вычисления. Поэтому его вызов имеет смысл только после прямого прохода Актера. На самом деле, это не является каким-либо ограничением. Ведь в нашем представление энтропийная регуляризация будет использоваться лишь для формирования награды в процессе сбора первичных данных и обучения моделей. В данных процессах прямой проход Актера с генерацией действия к выполнению первичен.
Для нужд обратного прохода мы создадим метод CNet::AlphasGradient. Как мы уже говорили выше, распределение градиента по энтропии выходит за рамки ранее выстроенного нами процесса. Это отражается и на алгоритме данного метода. Мы построили метод таким образом, что вызывать его будем для Критика. А в параметрах метода передавать указатель на объект Актера.
Соответствующим образом выстроен и алгоритм блока контролей данного метода. Вначале мы проверяем актуальность указателя на объект Актера и наличие в нем последнего слоя CNeuronSoftActorCritic.
bool CNet::AlphasGradient(CNet *PolicyNet) { if(!PolicyNet || !PolicyNet.layers) return false; int total = PolicyNet.layers.Total(); if(total <= 0) return false; CLayer *layer = PolicyNet.layers.At(total - 1); if(!layer || !layer.At(0)) return false; if(layer.At(0).Type() != defNeuronSoftActorCritic) return true; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
Вторая часть блока контролей осуществляет аналогичные проверки для последнего слоя Критика. Здесь, конечно, нет ограничения по типу нейронного слоя.
if(!layers) return false; total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; layer = layers.At(total - 1);
И только после успешного прохождения всех контролей мы обращаемся к методу распределения градиента нашего нового нейронного слоя.
return neuron.calcAlphaGradients((CNeuronBaseOCL*) layer.At(0)); }
Надо честно сказать, что использование полностью параметризированной модели позволяет нам определить вероятности отдельных действий. Но не позволяет создать поистине стохастическую политику Актера. Стохастичность Актера подразумевает семплирование действий из выученного распределения, чего мы не можем организовать на стороне контекста OpenCL. В вариационном автоэнкодере для решения подобной проблемы мы использовали фокус с репараметризацией и вектором случайных значений, сгенерированных на стороне основной программы. Но в данном случае для семплирования нам потребуется загрузка вероятностного распределения. Вместо этого, на стадии сбора базы примеров мы будем семплировать значения в некотором окружении расчетной величины (по аналогии с TD3) и затем запрашивать у модели энтропию таких действий. Для этих целей мы создадим метод CNet::CalcLogProbs. Его алгоритм напоминает построение метода GetLogProbs, но в отличии от предыдущего в параметрах мы будем получать указатель на буфер данных с семплированными значениями. А в результате операций метода в том же буфере мы получим их вероятности.
С полным кодом всех классов и их методов можно ознакомиться во вложении.
2.3 Создание советников обучения модели
После завершения работы над созданием новых объектов для нашей модели мы переходим к организации процесса её создания и обучения. Как и ранее, в данном процессе мы задействуем 3 советника:
- Research — сбор базы примеров
- Study — обучение моделей
- Test — проверка полученных результатов.
С целью сокращения объема статьи и экономии Вашего времени мы остановимся лишь на изменениях, которые были внесены в версии аналогичных советников из предыдущей статьи для организации рассматриваемого алгоритма.
Прежде всего — архитектура модели. Здесь мы изменили лишь последний слой Актера, заменив его на новый класс CNeuronSoftActorCritic. Размер слоя мы указали по количеству действий и 32 квантиля по каждому действию (как рекомендовали авторы метода FQF).
В качестве функции активации мы используем сигмоиду, аналогично экспериментам в предыдущей статье.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- Actor ......... ......... //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftActorCritic; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- Critic ......... ......... //--- return true; }
Алгоритм советника "...\SoftActorCritic\Research.mq5" был перенесен практически без изменений из предыдущей статьи. Ни блок сбора исторических данных, ни блок совершения торговых операций не претерпел изменений. Изменения были внесены лишь в функцию OnTick в части вознаграждения от окружающей среды. Как было сказано выше, алгоритмом Soft Actor-Critic в функцию вознаграждения добавляется энтропийная регуляризация.
Как и ранее, в качестве вознаграждения мы используем относительное изменение величины баланса счета. Мы так же добавляем штраф за отсутствие открытых позиций. Но далее нам необходимо добавить энтропийную регуляризацию. Выше мы создали для этого метод CalcLogProbs. Но есть один нюанс. В квантильном распределении нашего класса хранятся значения до функции активации. А в процессе принятия решения мы используем активированные результаты работы модели Актера. В качестве функции активации на выходе Актера мы используем сигмоиду.
![]()
Путем математических преобразований мы приходим к
![]()
Воспользуемся данным свойством и скорректируем семплированные действия в необходимый вид. После чего перенесем данные из вектора в буфер данных и, по возможности, перенесем информацию в память контекста OpenCL.
После выполнения такой подготовительной работы мы запрашиваем у Актера энтропию совершенных действий.
Обратите внимание, что мы получили энтропию 6 действий с учетом коэффициента температуры. Но вознаграждение у нас одно число для оценки всей совокупности текущего состояния и действия. В данном реализации мы использовали суммарное значение энтропии, что вполне вписывается в контекст вероятностей и логарифмов. Ведь вероятность сложного события равна произведению вероятностей его составляющих событий. А логарифм произведения равен сумме логарифмом отдельных множителей. Однако, я допускаю использование других подходов. Их целесообразность для каждого отдельного кейса может быть проверена в процессе обучения. Не бойтесь экспериментировать.
void OnTick() { //--- ......... ......... //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; temp.Clip(0.001f, 0.999f); temp = MathLog((temp - 1.0f) * (-1.0f) / temp) * (-1); Result.AssignArray(temp); if(Result.GetIndex() >= 0) Result.BufferWrite(); if(Actor.CalcLogProbs(Result)) { Result.GetData(temp); reward += temp.Sum(); } if(!Base.Add(sState, reward)) ExpertRemove(); }
Наиболее существенные изменения были внесены в процесс обучения модели в советнике "...\SoftActorCritic\Study.mq5". Остановимся подробнее на функции Train указанного советника. Именно здесь организован весь процесс обучения модели.
В начале функции мы семплируем из буфера воспроизведения опыта набор данных, как это мы и делали ранее.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Далее мы определяем прогнозную стоимость будущего состояния. Алгоритм повторяет аналогичный процесс в реализации метода TD3. Одно отличие в отсутствии целевой модели Актера. Здесь для определения действия в будущем состоянии мы используем обучаемую модель Актера.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Мы заполняем буферы исходных данных и вызываем методы прямого прохода Актера и 2 целевых моделей Критика.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Как и в методе TD3, для обучения Критика мы используем наименьшее из прогнозных значений стоимости состояния. Но в данном случае мы добавляем энтропийную составляющую.
vector<float> log_prob; if(!Actor.GetLogProbs(log_prob)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) + log_prob.Sum() - Buffer[tr].Revards[i + 1]);
Здесь следует обратить внимание, что в процессе сохранения траектории мы сохраняли накопительную сумму вознаграждений до конца прохода с учетом коэффициента дисконтирования. При этом вознаграждение за каждый отдельный переход в новое состояние включает энтропийную регуляризацию. Для обучения моделей Критиков мы корректируем сохраненное накопительное вознаграждение на поправку использования обновленной политики. Для этого мы берем разность минимальной прогнозной стоимости последующего состояния с учетом энтропийной составляющей и сохраненного в буфере воспроизведения опыта накопительного вознаграждения этого состояния. Полученное значение корректируем на коэффициент дисконтирования и прибавляем к сохраненной стоимости текущего состояния. В данном случае мы используем допущение о не снижении стоимости действий в процессе оптимизации моделей.
Далее нам предстоит этап обучения моделей Критиков. Для этого мы заполняем буферы данных текущем состоянием системы.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); //--- Account.BufferWrite();
Обратите внимание, в данном случае мы уже не проверяем наличие буфера описания состояния счета в контексте OpenCL. Мы сразу после сохранения данных просто вызываем метод переноса данных в контекст. Это возможно благодаря тому свойству, что все модели у нас работают в одном контексте OpenCL. О преимуществе такого подхода мы уже говорили ранее. При вызове методов прямого прохода целевых моделей буфер уже был создан в контексте. В противном случае мы бы получили ошибку при их выполнении. Поэтому на данном этапе мы уже не тратим время и ресурсы на излишнюю проверку.
После загрузки данных мы вызываем метод прямого прохода Актера и загрузим энтропийную составляющую вознаграждения.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Actor.GetLogProbs(log_prob);
На данном этапе у нас есть все необходимые данные для прямого и обратного проходов Критиков. Но на данном этапе мы сделали небольшое отступление от авторского алгоритма. Дело в том, что авторы метода после обновления параметров Критиков, для обновления политики Актера предлагают использовать Критика с минимальной оценкой. По нашим наблюдениям, несмотря на отклонения в оценках, градиент ошибки по действия практически неизменен. И мы решили просто чередовать модели Критиков. На четных итерациях мы обновляем модель Критика 2 на основе действий из буфера воспроизведения опыта. А политику Актера обучаем на основании оценок первого Критика.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward-log_prob.Sum()); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
На нечетных итерациях мы меняем использование моделей Критиков.
else { if(!Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Critic2.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Обратите внимание на последовательность вызова методов обратного прохода. Сначала мы осуществляем обратный проход Критика. Затем проводим градиент через энтропийную составляющую. Далее мы осуществляем обратный проход по блоку первичной обработки данных Актера. Это позволяет нам адаптировать сверточные слои к требованиям Критика. И только потом осуществляем полный обратный проход Актера для оптимизации политики его действий.
В завершении операций функции мы обновляем целевые модели и выводим информационное сообщение пользователю для визуального контроля процесса обучения.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
С полным кодом советника Вы можете ознакомиться во вложении. Там же вы найдете и код советника тестирования. Внесенные в него изменения аналогичны изменениям советника сбора первичных данных, и мы не будем на них останавливаться.
3.Тестирование
Обучение и тестирование модели осуществлялось на исторических данных инструмента EURUSD тайм-фрейм H1 за период январь — май 2023 года. Параметры индикаторов и все гиперпараметры использовались установленные по умолчанию.
К своему сожалению, должен признать, что в процессе работы над статьей мне не удалось обучить модель, способную генерировать прибыль на обучающей выборке. По результатам тестирования моя модель за 5 месяцев периода обучения потеряла 3.8%.

Из положительного можно отметить, что максимальная прибыльная сделка в 3.6 превышает максимальный убыток на 1 сделку. Средняя прибыльная сделка лишь немного превышает среднюю убыточную. Но вот доля прибыльных сделок составляет 49%. По существу, этого 1% не хватило до выхода в "0".
На данных вне обучающей выборки ситуация осталась практически неизменной. Даже доля прибыльных сделок увеличилась до 51%. Но уменьшилась величина средней прибыльной сделки, и мы опять получили убыток.

Стабильность работы модели вне обучающей выборки является положительным фактором. Но остается вопрос как нам избавиться от убытков. Возможно, причина в наших изменениях алгоритма. А может быть причина в завышенном коэффициенте температуры, стимулирующем большее исследование рынка.
Кроме того, причина может быть в слишком большом разбросе семплированных значений действий. При семплировании действия с вероятность близкой к "0" большая энтропия завышает их вознаграждения и это искажает политику Актера. Для поиска причины нам потребуются дополнительные тесты, с результатами которых я вас обязательно познакомлю.
Заключение
В данной статье мы познакомились с алгоритмом Soft Actor-Critic (SAC), предназначенным для решения задач в непрерывном пространстве действий. Он основан на идее максимизации энтропии политики, что позволяет агенту исследовать различные стратегии и находить оптимальные решения в стохастических средах с учетом максимального разнообразия действий.
Авторы метода предложили использовать энтропийную регуляризацию, которая добавляется в целевую функцию обучения. Это позволяет алгоритму стимулировать исследование новых действий и предотвращает слишком жесткую фиксацию на определенных стратегиях.
Мы реализовали данный метод средствами MQL5, но, к сожалению, не смогли обучить прибыльную стратеги. Тем не менее, обученная модель демонстрирует стабильность работы на обучающей выборке и вне её. Что свидетельствует о способности метода обобщать полученный опыт и переносить его на неизвестные состояния окружающей среды.
Мы ставим перед собой цели поиска возможностей обучения прибыльной политики Актера и результаты этой работы представим читателю позже.
Ссылки
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- Нейросети — это просто (Часть 48): Методы снижения переоценки значений Q-функции
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Study.mq5 | Советник | Советник обучения агента |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
I discovered a new NN sequence: enjoy <3
Картинку также можно просто перетащить в текст или вставить её с помощью Ctrl+V