
Нейросети в трейдинге: Мультиагентная адаптивная модель (Окончание)

Введение
В предыдущей статье мы познакомились с фреймворком MASA, который представляет собой мультиагентную систему, основан на уникальной интеграции взаимодействующих агентов. В архитектуре MASARL-агент, основанный на методах обучения с подкреплением, оптимизирует общую доходность инвестиционного портфеля. В то же время, агент на основе альтернативного алгоритма стремится оптимизировать инвестиционной портфель, возвращаемого RL-агентом, с целью минимизации потенциальных рисков.
Благодаря четкому разделению функционала между агентами, модель постоянно учится и адаптируется к базовой среде финансового рынка. Мультиагентная схема MASA достигает более сбалансированных инвестиционных портфелей, как с точки зрения их доходности, так и с точки зрения потенциальных рисков.
Авторская визуализация фреймворка MASA представлена ниже.
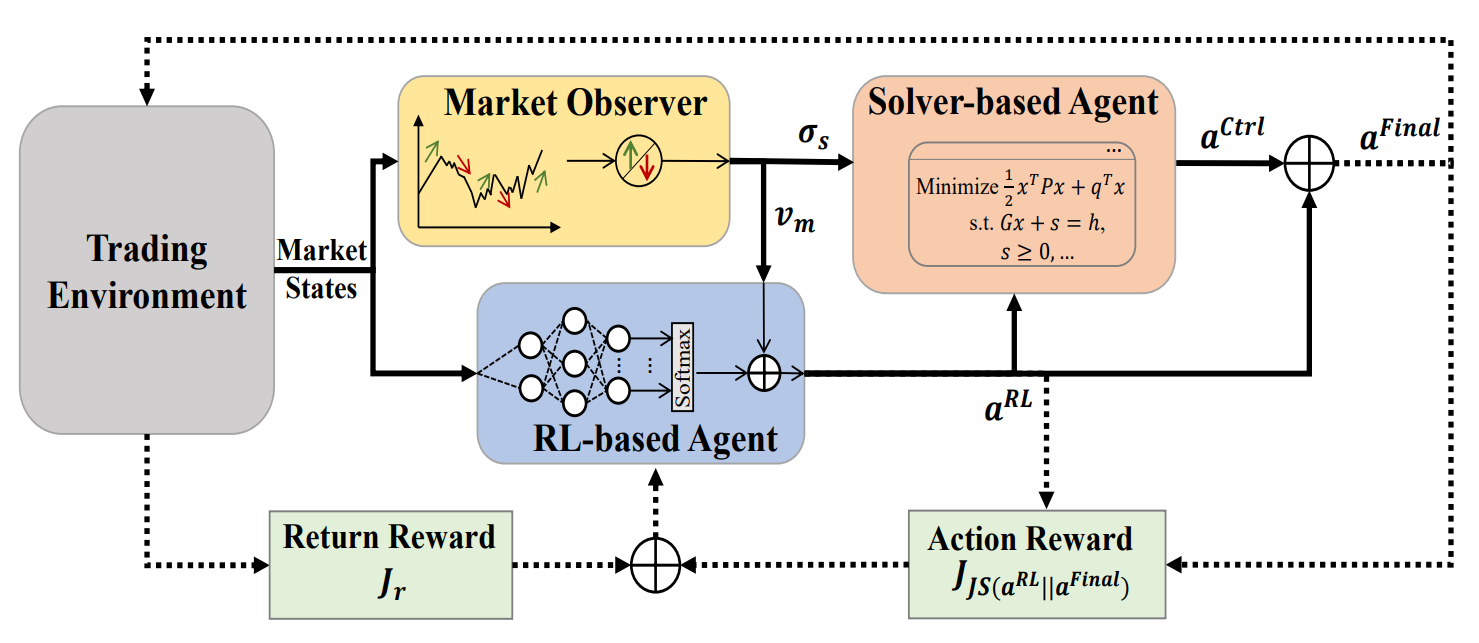
В практической части предыдущей статьи были представлены алгоритмы реализации функционала отдельных агентов фреймворка MASA, которые мы реализовали в виде отдельных объектов. Продолжаем начатую работу.
1. Комплексный слой MASA
В предыдущей статье были созданы три отдельных агента, каждый из которых выполнял определенный функционал в рамках фреймворка MASA. Сегодня мы объединим их в единую систему. И для этого создадим новый объект CNeuronMASA, структура которого представлена ниже.
class CNeuronMASA : public CNeuronBaseSAMOCL { protected: CNeuronMarketObserver cMarketObserver; CNeuronRevINDenormOCL cRevIN; CNeuronRLAgent cRLAgent; CNeuronControlAgent cControlAgent; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMASA(void) {}; ~CNeuronMASA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers_mo, uint forecast, uint segments_rl, float rho, uint layers_rl, uint n_actions, uint heads_contr, uint layers_contr, int NormLayer, CNeuronBatchNormOCL *normLayer, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMASA; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override; //--- virtual int GetNormLayer(void) { return cRevIN.GetNormLayer(); } virtual bool SetNormLayer(int NormLayer, CNeuronBatchNormOCL *normLayer); };
Должен признать, что в представленной структуре нового объекта есть несколько моментов, которые заслуживают отдельного внимания.
Конечно, сразу бросается в глаза относительно большое количество параметров метода инициализации Init. Это вызвано необходимостью покрытия потребностей наших трех агентов, каждый их которых имеет свои архитектурные особенности.
Кроме того, есть один нюанс, который идет в разрез с концепцией нашей библиотеки. Метод прямого прохода имеет один источник исходных данных, что соответствует рассматриваемому фреймворку. На вход RL-агента и агента наблюдения за рынком подается текущая рыночная ситуация. Но вот в методе распределения градиентов ошибки появляются объекты второго источника данных, которого не наблюдается ни в методе прямого прохода, ни в авторском изложении фреймворка MASA.
Столь не стандартное решение было принято для организации альтернативного процесса обучения агента наблюдения за рынком. Для этих же целей был добавлен внутренний объект обратной нормализации данных. Более подробно данное решение мы обсудим в процессе построения алгоритмов методов нашего класса.
Все внутренние объекты нашего нового класса объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор объекта. Непосредственно процесс инициализации нового экземпляра класса организован в методе Init. Как уже было сказано выше, метод инициализации содержит большое количество параметров, но фактически они дублируют параметры инициализации ранее созданных агентов.
bool CNeuronMASA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads_mo, uint layers_mo, uint forecast, uint segments_rl, float rho, uint layers_rl, uint n_actions, uint heads_contr, uint layers_contr, int NormLayer, CNeuronBatchNormOCL *normLayer, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseSAMOCL::Init(numOutputs, myIndex, open_cl, n_actions, rho, optimization_type, batch)) return false;
В теле метода мы, по уже сложившейся традиции, сначала вызываем одноименный метод родительского класса. В данном случае, в качестве родительского класса мы используем полносвязный нейронный слой с SAM-оптимизацией.
И здесь следует вспомнить, что результат фреймворка MASA формируется на выходе агента-контролера в виде тензора действий. Следовательно, размер слоя в методе инициализации родительского класса мы указываем на уровне пространства действий Актера.
Далее мы последовательно вызываем методы инициализации наших агентов. Первым инициализируем агента наблюдения за рынком, передав ему соответствующие параметры.
Напомню, что агент наблюдения за рынком получает на вход тензор описания текущей рыночной ситуации, а на выходе возвращает прогнозные значения в формате той же мультимодальной последовательности на заданный горизонт планирования.
//--- Market Observation if(!cMarketObserver.Init(0, 0, OpenCL, window, window_key, units_count, heads_mo, layers_mo, forecast, optimization, iBatch)) return false; if(!cRevIN.Init(0, 1, OpenCL, cMarketObserver.Neurons(), NormLayer, normLayer)) return false;
И тут же инициализируем слой обратной нормализации, размер которого равен результатам работы агента наблюдения за рынком.
Следующим мы инициализируем RL-агент, который на вход получает тот же тензор описания текущей рыночной ситуации. Но возвращает уже тензор действий Актера, в соответствии с выученной политикой.
//--- RL Agent if(!cRLAgent.Init(0, 2, OpenCL, window, units_count, segments_rl, fRho, layers_rl, n_actions, optimization, iBatch)) return false;
И последним инициализируем агент-контролер, который на вход получает результаты работы двух предыдущих агентов и возвращает скорректированный тензор действий Актера.
if(!cControlAgent.Init(0, 3, OpenCL, 3, window_key, n_actions / 3, heads_contr, window, forecast, layers_contr, optimization, iBatch)) return false;
Здесь следует обратить внимание, что в нашей реализации RL-агент и агент-контролер по-разному смотрят на тензор действий Актера, генерируемый RL-агентом. И дело не только в разделении функциональности агентов.
На выходе RL-агента используется полносвязный слой, который генерирует независимо каждый элемент в тензоре действий Актера, исходя из проведенного анализа рыночной ситуации и выученной политики поведения. Однако, у нас есть априорные знания о взаимном исключении разнонаправленных действий (покупка и продажа актива), и параметры сделки в каждом направлении занимают 3 элемента в векторе описания действий.
Принимая во внимание вышесказанное, мы указываем агенту-контролеру, что тензор действий представлен мультимодальной последовательностью, в которой каждый элемент последовательности описывается вектором из трех элементов (размерность вектора описания одной сделки). Таким образом, мы просим агента-контролера оценить риски совершения сделки в каждом отдельном направлении.
В завершение метода инициализации нашего объекта фреймворка MASA, мы осуществим подмену указателей на буферы внешних интерфейсов и установим сигмовидную функцию активации по умолчанию.
if(!SetOutput(cControlAgent.getOutput(), true) || !SetGradient(cControlAgent.getGradient(), true)) return false; SetActivationFunction(SIGMOID); //--- return true; }
После чего, завершаем работу метода инициализации, вернув логический результат выполнения операций вызывающей программе.
Следует несколько слов сказать об установке функции активации. На выходе нашего нового класса мы получаем тензор действий Актера. Который сначала генерируется RL-агентом, а затем корректируется агентом-контролером. Очевидно, что пространство значений на выходе обоих агентов и нашего объекта должны быть идентичны. Поэтому мы переопределяем метод указания функции активации, с целью её синхронизации для всех упомянутых объектов.
void CNeuronMASA::SetActivationFunction(ENUM_ACTIVATION value) { cControlAgent.SetActivationFunction(value); cRLAgent.SetActivationFunction((ENUM_ACTIVATION)cControlAgent.Activation()); CNeuronBaseSAMOCL::SetActivationFunction((ENUM_ACTIVATION)cControlAgent.Activation()); }
После завершения работы над инициализацией объекта, мы переходим к построению алгоритма прямого прохода. И здесь все довольно просто. Мы лишь последовательно вызываем одноименные методы наших агентов. Вначале получаем результаты анализа текущего состояния рынка и предварительный тензор действий Актера.
bool CNeuronMASA::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cMarketObserver.FeedForward(NeuronOCL.AsObject())) return false; if(!cRLAgent.FeedForward(NeuronOCL.AsObject())) return false;
После чего передаем полученные результаты агенту-контролеру для принятия окончательного решения.
if(!cControlAgent.FeedForward(cRLAgent.AsObject(), cMarketObserver.getOutput())) return false; //--- return true; }
И конечно, перед завершением работы метода, мы вернем логический результат выполнения операций вызывающей программе.
Здесь следует обратить внимание, что в представленной выше авторской визуализации фреймворка MASA явно просматривается формирование финального вектора действий, как сумма результатов RL-агента и агента-контролера. В нашей же реализации, мы принимаем результаты работы агента-контролера, как финальные значения, исключив остаточную связь с RL-агентом. Но здесь следует вспомнить архитектуру нашего агента-контролера.
Напомню, что агент-контролер в нашей реализации представлен в виде декодера Transformer. А, как вы знаете, архитектурой Transformer предусмотрены остаточные связи, как в модулях внимания, так и в блоке FeedForward. Следовательно, поток информации остаточных связей к RL-агенту уже заложен в архитектуре агента-контролера, и нам нет необходимости организовывать дополнительные остаточные связи.
И теперь мы подошли к организации процессов обратного прохода. А точнее, к построению алгоритма распределения градиента ошибки calcInputGradients, о нестандартных решениях которого мы начали разговор ещё при ознакомлении со структурой класса CNeuronMASA.
Для начала, давайте посмотрим на ожидаемые результаты работы наших агентов. Два из них возвращают тензор действий Актера. И вполне логично в процессе обучения использовать набор оптимальных действий в качестве целеуказания в случае обучения с учителем, либо их проекцию на вознаграждения — при обучении с подкреплением.
Однако, у нас есть ещё агент наблюдения за рынком, который возвращает прогнозные значения мультимодального временного ряда показателей анализируемого финансового инструмента. И тут возникает вопрос обучения данного агента, а точнее вопрос постановки целей. Конечно, мы можем пропустить градиент ошибки через агент-контролер и получить влияние агента наблюдения за рынком на принятие решения о коррекции результатов RL-агента. Но насколько такой подход будет соответствовать поставленной задаче прогнозирования предстоящего движения анализируемого финансового инструмента?
Думаю, в данном случае правильнее осуществить отдельное обучение агента наблюдения за рынком прогнозированию предстоящего временного ряда, как мы это делали ранее для Энкодера состояния счета. Но проблема заключается в том, что агента наблюдения за рынком является составной частью нашей модели. И мы не можем выделить его в отдельный процесс обучения. И в таком случае возникает идея передачи на уровень слоя двух целевых значений. А это уже кардинальное изменение алгоритма работы нашей библиотеки. И как вы понимаете, обширное поле для доработок.
Нестандартные решения нам часто помогаю избежать больших объемов работы, решив поставленную задачу так сказать "малой кровью". А давайте, используем механизм передачи объектов второго источника исходных данных для предоставления объекту двух целей? Возьмем на вооружение эту идею и переопределим метод распределения градиента ошибки с использованием двух источников исходных данных, только на этот раз буферы второго объекта будут использоваться для передачи тензора целевых значений для агента наблюдения за рынком.
bool CNeuronMASA::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL) return false;
Однако, эта идея не лишена "подводных камней". И один из них — сопоставимость данных. Дело в том, что на вход модели мы обычно подаем сырые необработанные исходные данные, получаемые от терминала. Они проходят первичную обработку в слое пакетной нормализации, и все остальные нейронные слои нашей модели работают уже с нормализованными данными. В том числе и создаваемый нами объект CNeuronMASA. И вполне логично, что на выходе агента наблюдения за рынком мы так же получаем нормализованный прогноз, с которым удобно работать агенту-контролеру. Да только вот целевые последующие значения анализируемого мультимодального временного ряда мы можем предоставить только в сыром виде. Поэтому нами был добавлен слой обратной нормализации данных, который мы не использовали в методе прямого прохода. Но при организации процесса распределения градиента ошибки, мы сначала добавим к результатам работы агента наблюдения за рынком статистические параметры распределения исходных данных.
if(!cRevIN.FeedForward(cMarketObserver.AsObject())) return false;
И в таком виде мы уже можем сравнить целевые значения с нашим прогнозом и распределить градиент ошибки до агента наблюдения за рынком.
if(!cRevIN.FeedForward(cMarketObserver.AsObject())) return false; float error = 1.0f; if(!cRevIN.calcOutputGradients(SecondGradient, error)) return false; if(!cMarketObserver.calcHiddenGradients(cRevIN.AsObject())) return false;
Затем, мы распределим градиент ошибки агента-контролера между RL-агентом и агентом наблюдения за рынком. И тут нам необходимо сохранить ранее полученный градиент ошибки на уровне агента наблюдения за рынком. Поэтому мы получаем ошибку данного агента во вспомогательный буфер, после чего, суммируем значения, полученные по двум информационным потокам.
if(!cRLAgent.calcHiddenGradients(cControlAgent.AsObject(), cMarketObserver.getOutput(), cMarketObserver.getPrevOutput(), (ENUM_ACTIVATION)cMarketObserver.Activation()) || !SumAndNormilize(cMarketObserver.getGradient(), cMarketObserver.getPrevOutput(), cMarketObserver.getGradient(), 1, false, 0, 0, 0, 1)) return false;
Ещё один момент, на который следует обратить внимание, — это результаты работы RL-агента и агента-контролера. Оба указанных агента возвращают тензор действий Актера. Первый — по результатам собственного анализа текущей рыночной ситуации. Второй — после оценки рисков предоставленного тензора действий, с учетом прогнозных значений предстоящего ценового движения, полученного от агента наблюдения за рынком. В идеальных условиях результаты работы обоих агентов должны совпадать. Поэтому для RL-агента мы вводим ошибку отклонения от результатов работы агента-контролера.
CBufferFloat *temp = cRLAgent.getGradient(); if(!cRLAgent.SetGradient(cRLAgent.getPrevOutput(), false) || !cRLAgent.calcOutputGradients(cControlAgent.getOutput(), error) || !SumAndNormilize(temp, cRLAgent.getPrevOutput(), temp, 1, false, 0, 0, 0, 1) || !cRLAgent.SetGradient(temp, false)) return false;
И конечно, операции определения дополнительной ошибки не должны удалить ранее накопленный градиент ошибки. Поэтому мы используем алгоритм подмены буферов данных с последующим суммированием значений, полученных от двух информационных потоков.
После распределения градиента ошибки между внутренними агентами, нам предстоит передать его на уровень исходных данных. И здесь нам снова предстоит собрать градиент ошибки по двум информационным потокам: от RL-агента и агента наблюдения за рынком. Как и ранее, в подобных случаях, мы сначала передаем градиент ошибки от агента наблюдения за рынком.
if(!NeuronOCL.calcHiddenGradients(cMarketObserver.AsObject())) return false;
После чего, осуществляем подмену буфера и спускаем градиент ошибки от RL-агента.
temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(NeuronOCL.getPrevOutput(), false) || !NeuronOCL.calcOutputGradients(cRLAgent.getOutput(), error) || !SumAndNormilize(temp, NeuronOCL.getPrevOutput(), temp, 1, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
Суммируем значения, полученные по двум информационным потокам, и возвращаем указатели на буферы данных в исходное состояние.
На данном этапе мы распределили градиент ошибки между всеми участниками процесса, в соответствии с их влиянием на итоговый результат работы модели. И теперь нам остается обновить параметры модели в сторону минимизации ошибки. Данный функционал выполняется в методе updateInputWeights. Алгоритм данного метода довольно прост. Мы лишь последовательно вызываем одноименные методы внутренних агентов. И мы не будем сейчас останавливаться на детальном его рассмотрении. Только не забывайте, что наши внутренние агенты эксплуатируют подходы SAM-оптимизации. А это значит, что вызов методов внутренних агентов должен осуществлять в последовательности обратной прямому проходу.
На этом мы завершаем рассмотрение алгоритмов для создания методов нового класса CNeuronMASA. С полным кодом данного объекта и всех его методов вы можете самостоятельно ознакомиться во вложении.
2. Архитектура моделей
Ну а мы, после завершения работы по построению новых объектов, переходим к рассмотрению архитектуры обучаемых моделей. И здесь, надо сказать, мы тоже внесли изменения и некоторые нестандартные решения.
Прежде всего, мы отказались от отдельной модели Энкодера состояния окружающей среды. И это не удивительно. В нашем классе CNeuronMASA 2 агента осуществляют параллельный анализ текущего состояния окружающей среды.
Второй момент связан с включением информации о состоянии счета. Если ранее мы передавали её модели Актера в виде второго источника исходных данных, то сейчас мы заняли этот информационный поток тензором целевых значений агента наблюдения за рынком. Поэтому мы просто добавили информацию о состоянии счета в конец тензора описания состояния окружающей среды.
Итак, на вход Актера мы подаем общий тензор исходных данных, который включает описания состояния окружающей среды и информацию о состоянии счета.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- Actor actor.Clear(); //--- if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные "сырые" исходные данные проходят первичную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Далее нам следует обратить внимание, что вектор информации о состоянии счета нарушает структуру тензора описания состояния окружающей среды. Его длина может отличаться от размера описания одного элемента в мультимодальной последовательности анализируемого временного ряда, что не вписывается структуру используемых нами далее модулей внимания. Поэтому нам стоит привести исходные данные к матричному виду. Этот функционал мы возложим на слой обучаемых эмбедингов.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; descr.count = 1; descr.window_out = BarDescr; { int temp[HistoryBars + 1]; if(ArrayInitialize(temp, BarDescr) < (HistoryBars + 1)) return false; temp[HistoryBars] = AccountDescr; if(ArrayCopy(descr.windows, temp) < (HistoryBars + 1)) return false; } descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Данный слой разбивает на блоки заданной длины вектор исходных данных и проецирует каждый такой блок в подпространство заданной размерности, независимо от исходного размера блока. Это достигается путем обучения независимой матрицы проецирования для каждого блока.
Мы знаем, что большая часть исходного тензора представлена однотипными векторами описания отдельных состояний окружающей среды (баров), и выделяется только последний элемент (информация о состоянии счета). Поэтому, мы сначала инициализируем массив анализируемых окон достаточной длины фиксированными значениями, а затем изменяем только размер последнего элемента анализируемой последовательности.
Обратите внимание, что на выходе слоя эмбединга мы устанавливаем размер одного элемента последовательности равным размеру описания одного бара. Это очень важный момент. Для целей анализа данных мы могли бы использовать любой размер одного элемента последовательности на выходе слоя эмбединга. Но в нашей модели есть агент наблюдения за рынком, который возвращает прогнозные значения в размерности исходных данных. И вполне логично, что прогнозные значения анализируемого мультимодального временного ряда должны соответствовать целевым значениям, используемым при обучении модели. А они идентичны исходным данным. Круг замкнулся.
Использование обучаемых эмбедингов неявно выполняет функцию позиционного кодирования. Как уже было сказано выше, каждый элемент последовательности получает собственную уникальную матрицу проекции данных. А значит, наличие двух одинаковых векторов в исходных данных на разных позициях вернет разные проекции в целевом подпространстве. И при последующем анализе, они будут четко различимы.
Полученные эмбединги передаются на вход нашего нового объекта фреймворка MASA. И здесь есть целый ряд моментов на которые следует обратить внимание.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMASA; //--- Windows { int temp[] = {BarDescr, NForecast, 2 * NActions}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; descr.count = HistoryBars+1; //--- Heads { int temp[] = {4, 4}; if(ArrayCopy(descr.heads, temp) < (int)temp.Size()) return false; } //--- Layers { int temp[] = {3, 3, 3}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window = BarDescr; descr.probability = Rho; descr.step = 1; // Normalization layer descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
В динамическом массиве descr.windows мы указываем основные параметры последовательностей, анализируемых внутренними агентами. Здесь мы последовательно указываем размерность одного элемента последовательности исходных данных, горизонт планирования последующего временного ряда и пространство действий Актера.
На последний параметр следует обратить особое внимание. При построении архитектуры внутренних агентов мы говорили об организации прямой зависимости между состоянием окружающей среды и генерируемым действием, что исключает стохастичность поведения Актера. Тем не менее, в своей реализации мы обучаем именно стохастическую политику Актера. Поэтому мы в 2 раза увеличиваем пространство действий, получаемое на выходе фреймворка MASA. Легко заметить, что это соответствует эксплуатируемому нами ранее подходу при организации стохастической политики. Полученный на выходе фреймворка MASA вектор мы логически делим на 2 равные части, которые представляют средние значения и дисперсии пространства действий Актера в анализируемом состоянии окружающей среды. Именно поэтому мы отключаем функцию активации данного слоя.
Каждый используемый нами модуль внимания использует по 4 головы. И каждый Агент включает по 3 внутренних слоя Энкодера/Декодера.
Как уже было сказано выше, результаты работы фреймворка MASA мы передаем на слой валентного состояния автоэнкодера, для генерации случайных действий Актера в заданном распределении.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученный вектор действий мы проецируем в заданные границы с помощью сверточного слоя и сигмовидной функции активации.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; }
А на выходе модели мы используем слой частотного согласования результатов работы модели с целевыми значениями.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Следующим этапом мы переходим к построению архитектуры Критика. Здесь можно сказать, что в основном архитектура модели заимствована из предыдущих работ. Однако, отказ от отдельной модели Энкодера состояния окружающей среды привел к добавлению блока анализа исходного состояния и в модель Критика. Здесь мы использовали фреймворк PSformer для анализа текущего состояния. При этом, в исходных данных Критика отсутствует информация о состоянии счета. Мое субъективное мнение, что подобная информация не представляет ценности для Критика. Результативность сделки зависит от конъюнктуры рынка, а не от состояния счета на момент открытия.
Конечно, здесь можно поспорить, что указание чрезмерно большого или малого объема может привести к ошибке выполнения торговой операции и, как следствие, отсутствия открытой позиции. Но определение объема сделки лежит в функционале Актера. И должен ли Критик реагировать на столь частные случаи? Вопрос в распределении функционала между моделями.
Второй вопрос — это вопрос открытых позиций и накопленных прибыли или убытков. Это результативность предыдущих торговых операций, а Критик оценивает текущую. И даже если мы предполагаем, что Критик оценивает не отдельную операцию, а текущую политику, то и в этом случае он оценивает результативность политики до конца эпизода, но никак не в обратном порядке.
Следовательно, на вход модели мы подаем только информацию о текущем состоянии окружающей среды.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Как и ранее, "сырые" исходные данные обрабатываются слоем пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
И передаются на 3 последовательных слоя фреймворка PSformer.
//--- layer 2 - 4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPSformer; descr.window = BarDescr; descr.count = HistoryBars; descr.window_out = Segments; descr.probability = Rho; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
Далее мы используем последовательно сверточный и полносвязный слои для понижения размерности полученного тензора.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = int(LatentCount / descr.count); descr.probability = Rho; descr.activation = GELU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = Rho; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
И объединяем результаты анализа состояния окружающей среды с действиями агента в слое конкатенации данных.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = LatentCount; descr.step = NActions; descr.activation = GELU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
После чего, идет модуль принятия решения, состоящий из 4 полносвязных слоев.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; }
И на выходе мы используем слой частотного согласования результатов работы модели с целевыми значениями.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
После успешного указания архитектуры двух обучаемых моделей, мы завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
3. Программа обучение моделей
Мы уверенно приближаемся к логическому завершению нашей работы. И теперь переходим к построению программы обучения моделей. Вполне очевидно, что исключение одной обучаемой модели накладывает свой отпечаток на алгоритм построения программы обучения. Более того, при построении модуля фреймворка MASA, мы договорились использовать поток информации второго источника исходных данных в качестве дополнительного потока целевых значений. Поэтому не будем тратить время и рассмотрим алгоритм обучения моделей, который мы реализовали в методе Train.
Как и ранее, вначале мы проведем небольшую подготовительную работу. Здесь мы сформируем вектор вероятностей выбора траекторий из буфера воспроизведения опыта в зависимости от результативности проходов.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
И объявим необходимые локальные переменные.
Далее, мы организовываем цикл обучения, количество итераций которого задается внешними параметрами нашего советника.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i+NForecast].state) || !state.Resize(NForecast*BarDescr) || MathAbs(state).Sum() == 0 || !bForecast.AssignArray(state)) { iter --; continue; }
В теле цикла мы сэмплируем одну траекторию и состояние окружающей среды на ней. И тут же проверяем наличие исторических и последующих данных из сэмплированного состояния на заданную глубину анализа и горизонт планирования. В случае негативного результата хотя бы на одной точке контроля, мы переходим к сэмплированию новой траектории и состояния на ней.
При наличии необходимых данных, мы переносим их в соответствующие буфера. Затем мы добавляем к описанию состояния окружающей среды информацию о состоянии счета на момент анализа.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bState.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bState.Add(Buffer[tr].States[i].account[1] / PrevBalance); bState.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bState.Add(Buffer[tr].States[i].account[2]); bState.Add(Buffer[tr].States[i].account[3]); bState.Add(Buffer[tr].States[i].account[4] / PrevBalance); bState.Add(Buffer[tr].States[i].account[5] / PrevBalance); bState.Add(Buffer[tr].States[i].account[6] / PrevBalance);
И тут же добавляем временную метку анализируемого состояния окружающей среды.
//--- double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
После подготовки исходных данных, мы переходим к процессу обучения моделей. И первым итерации обучения осуществляет Критик. На вход модели мы подаем анализируемое состояние окружающей среды и вектор действий, которые фактически выполнил Актер в момент сбора обучающей выборки. Ведь именно для этих действий у нас есть реальное вознаграждение от окружающей среды. И выполняем операции прямого прохода, оценивая фактические действия Актера.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bActions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Легко догадаться, что в результате выполнения операций прямого прохода Критика мы бы хотели получить тензор вознаграждений, близкий к фактически полученному от окружающей среды. Поэтому мы извлекаем из буфера воспроизведения опыта фактическое вознаграждение за выполненные действия и осуществляем операции обратного прохода Критика, минимизируя ошибку.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CBufferFloat *)GetPointer(bActions), (CBufferFloat *)GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее идет процесс обучения политики Актера, который мы осуществляем в 2 этапа. Вначале мы осуществляем прямой проход Актера для генерации тензора действий.
//--- Actor Policy if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
За которым следует выполнение операций прямого прохода Критика. Только на этот раз оцениваются действия, сгенерированные Актером.
Critic.TrainMode(false); if(!Critic.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(Actor), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Здесь стоит обратить внимание, что на данном этапе мы отключаем режим обучения Критика. Это позволит нам исключить влияние некорректных значений на изучение политики вознаграждения.
Затем мы проверяем результативность анализируемого прохода. И если политика поведения Актера при выполнении анализируемого прохода дала положительный результат, то мы в стиле обучения с учителем приближаем текущую политику Актера к положительной. Это первый этап обучения Актера.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions),(CBufferFloat*)GetPointer(bForecast),GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
На втором этапе обучения Актера, мы ставим перед Критиком задачу увеличения вознаграждения и спускаем градиент ошибки до уровня действий Актера.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); } if(!Critic.backProp(Result, (CNet *)GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)GetPointer(bForecast),GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Таким образом, мы хотим, чтобы Критик указал Актеру направление корректировки политики в сторону повышения общей доходности. После чего, корректируем политику актера в заданном направлении.
Теперь нам остается лишь проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации обучения моделей.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После успешного выполнения всех итераций обучения моделей, мы очищаем поле комментариев на графике финансового инструмента, где выводили информацию для пользователя.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Выводим в журнал результаты обучения моделей и инициализируем процесс завершения работы программы.
На этом мы завершаем рассмотрение алгоритмов построения фреймворка MASA и реализации программ обучения моделей. С полным их кодом вы можете самостоятельно ознакомиться во вложении.
4. Тестирование
Вот и подошла к своему логическому завершению наша работа по реализации подходов, предложенных авторами фреймворка MASA, средствами MQL5. И мы переходим к самому волнительному этапу — оценке эффективности реализованных подходов на реальных исторических данных.
Важно отметить, что мы осуществляем "оценку эффективности реализованных" подходов, а не "предложенных". Ведь при реализации мы внесли изменения в авторскую версию фреймворка.
Модели будут обучаться на исторических данных 2023 года по финансовому инструменту EURUSD, таймфрейм H1. Параметры всех используемых индикаторов остаются по умолчанию.
Для начального обучения использовалась обучающая выборка, собранная в предыдущих работах, которая периодически обновлялась в процессе обучения моделей с целью её актуализации к текущей политике Актера.
Поле нескольких циклов обучения моделей и обновления обучающей выборки, мы получили политику, которая показывает прибыльность на обучающей и тестовой выборках.
Тестирование обученной политики проводилось на исторических данных за Январь 2024 года, при этом остальные параметры оставались неизменными. Результаты тестирования указаны ниже.
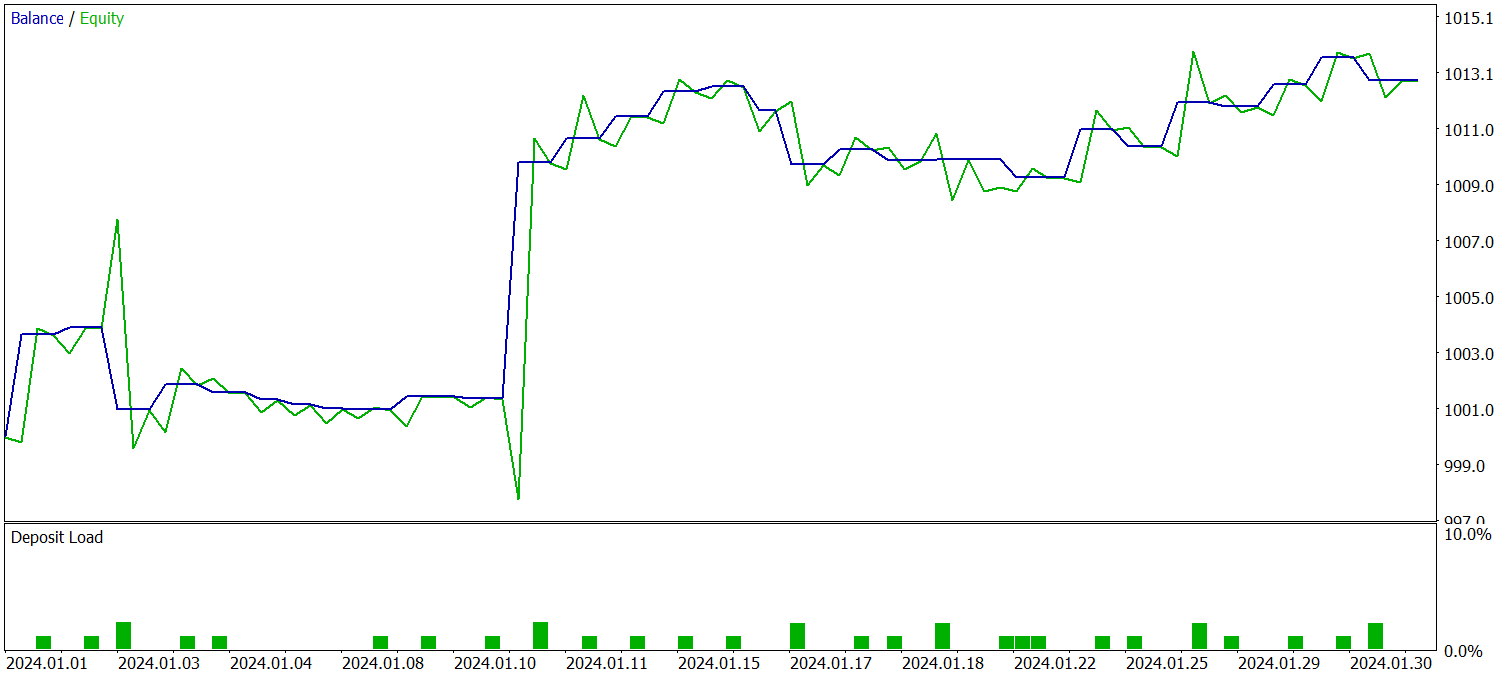
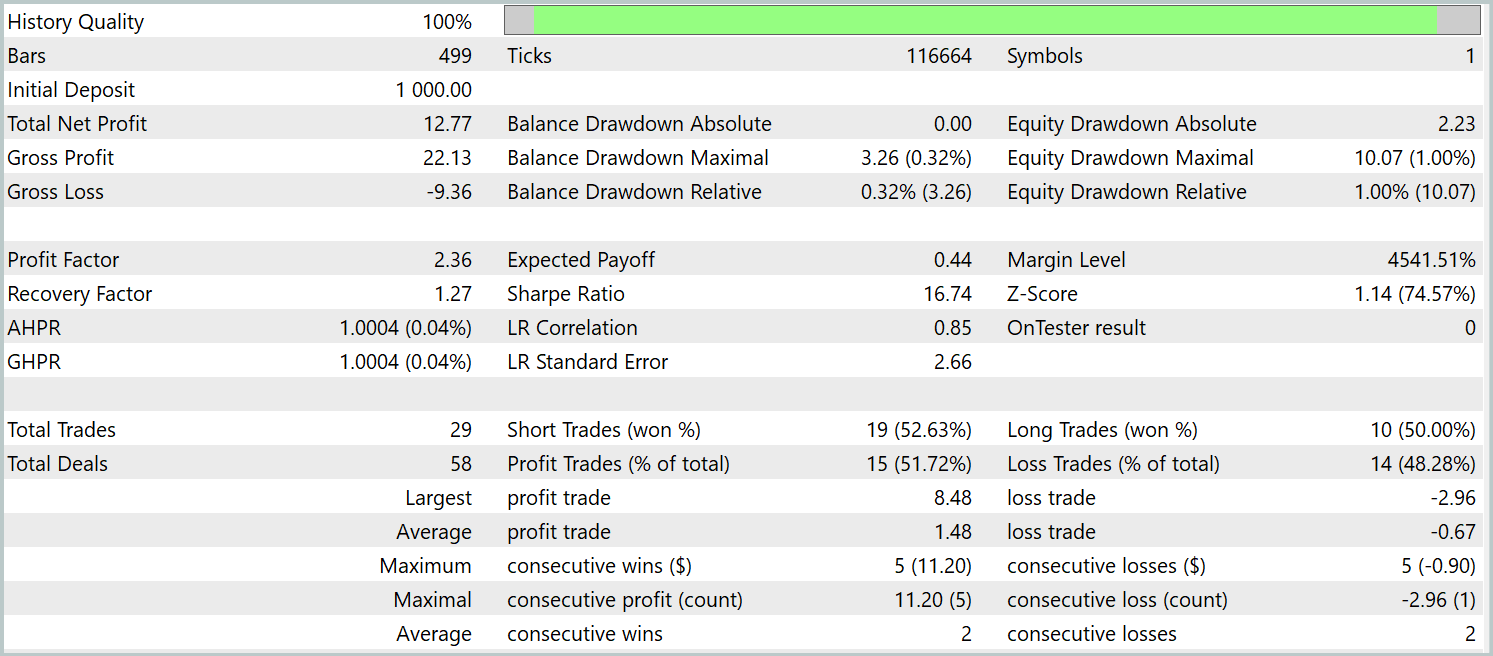
За период тестирования модель совершила 29 торговых операций, половина из которых была закрыта с прибылью. Однако благодаря тому, что средняя прибыльная сделка более чем в 2 раза превышает аналогичный показатель убыточных операций, мы получили выраженную тенденцию к росту депозита. Это может свидетельствовать о потенциале реализованного фреймворка.
Заключение
Мы ознакомились с инновационной методикой управления инвестиционными портфелями на нестабильных финансовых рынках — мультиагентной адаптивной системой MASA. Этот фреймворк эффективно объединяет достоинства RL-алгоритмов и адаптивных методов оптимизации, что позволяет эффективно увеличивать доходность модели наряду со снижением рисков.
В практической части мы реализовали свое видение предложенных подходов средствами MQL5. Провели обучение моделей на реальных исторических данных. Полученные результаты тестирования свидетельствуют о существующем потенциале предложенных подходов. Тем не менее, перед применением модели в реальной торговле, необходимо провести комплекс дополнительных мероприятий по её обучению на более репрезентативной выборке и всестороннего тестирования.
Ссылки
- Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования