
Redes neurais em trading: Modelo adaptativo multiagente (Conclusão)

Introdução
No artigo anterior, conhecemos o framework MASA, que representa um sistema multiagente baseado na integração única de agentes interativos. Na arquitetura MASAagente MASARL, baseado em métodos de aprendizado por reforço, otimiza a lucratividade geral do portfólio de investimentos. Ao mesmo tempo, um agente baseado em um algoritmo alternativo busca otimizar o portfólio retornado pelo agente de RL, com o objetivo de minimizar os riscos potenciais.
Graças à clara separação de funcionalidades entre os agentes, o modelo aprende continuamente e se adapta ao ambiente básico do mercado financeiro. O esquema multiagente MASA alcança portfólios de investimento mais equilibrados, tanto do ponto de vista da lucratividade quanto dos riscos potenciais.
A visualização do framework MASA feita pelo autor é apresentada abaixo.
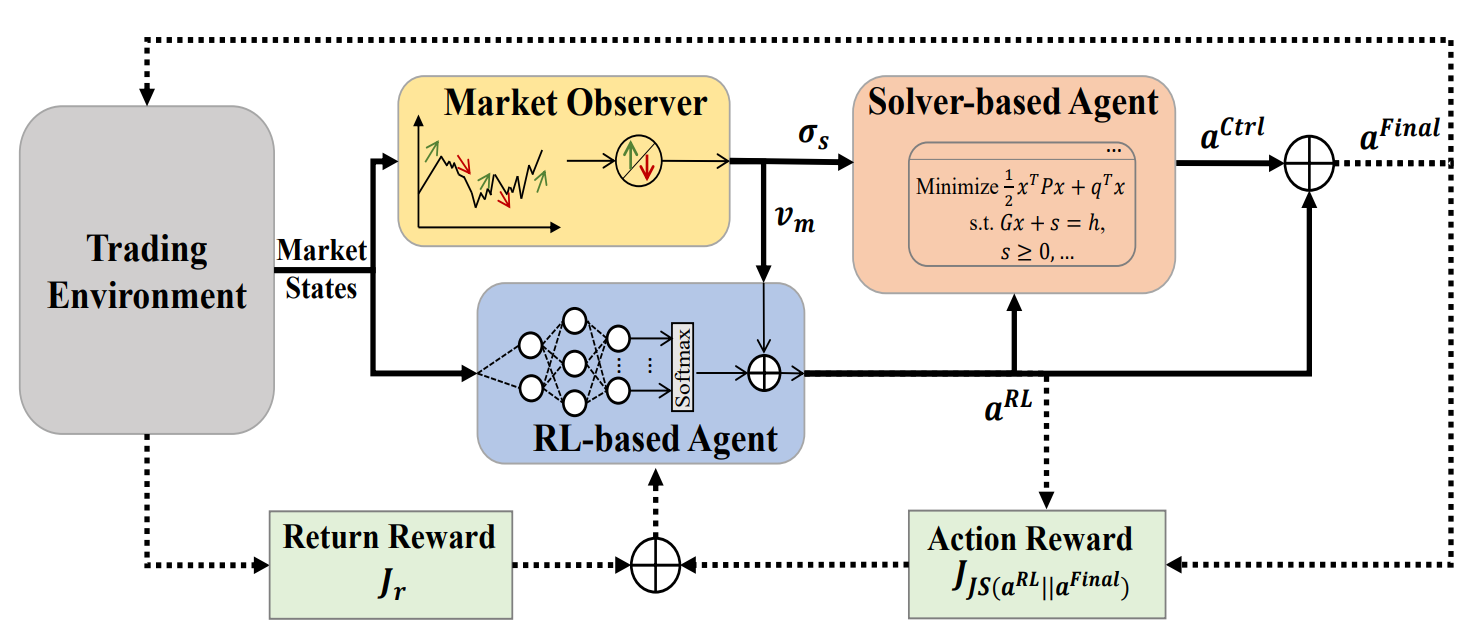
Na parte prática do artigo anterior, foram apresentados os algoritmos de implementação do funcional de agentes individuais do framework MASA, que estruturamos como objetos separados. Vamos continuar o trabalho iniciado.
1. Camada integrada do MASA
No artigo anterior, foram criados três agentes separados, cada um executando uma funcionalidade específica dentro do framework MASA. Hoje, vamos unificá-los em um único sistema. Para isso, criaremos um novo objeto chamado CNeuronMASA, cuja estrutura é apresentada abaixo.
class CNeuronMASA : public CNeuronBaseSAMOCL { protected: CNeuronMarketObserver cMarketObserver; CNeuronRevINDenormOCL cRevIN; CNeuronRLAgent cRLAgent; CNeuronControlAgent cControlAgent; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMASA(void) {}; ~CNeuronMASA(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers_mo, uint forecast, uint segments_rl, float rho, uint layers_rl, uint n_actions, uint heads_contr, uint layers_contr, int NormLayer, CNeuronBatchNormOCL *normLayer, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMASA; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override; //--- virtual int GetNormLayer(void) { return cRevIN.GetNormLayer(); } virtual bool SetNormLayer(int NormLayer, CNeuronBatchNormOCL *normLayer); };
Devo admitir que há alguns pontos na estrutura apresentada deste novo objeto que merecem atenção especial.
Claro, chama atenção de imediato a quantidade relativamente grande de parâmetros no método de inicialização Init. Isso se deve à necessidade de atender às demandas dos nossos três agentes, cada um com suas particularidades arquitetônicas.
Além disso, há um detalhe que entra em conflito com o conceito da nossa biblioteca. O método de propagação para frente possui uma única fonte de dados brutos, o que está de acordo com o framework analisado. A situação atual do mercado é alimentada tanto no agente de RL quanto no agente de observação do mercado. Porém, no método de distribuição dos gradientes de erro surgem objetos de uma segunda fonte de dados, a qual não aparece nem no método de propagação para frente nem na descrição original do framework MASA.
Essa solução nada convencional foi adotada para organizar um processo alternativo de treinamento do agente de observação do mercado. Para os mesmos fins, foi adicionado um objeto interno de desnornalização dos dados. Discutiremos essa decisão com mais detalhes durante a construção dos algoritmos dos métodos da nossa classe.
Todos os objetos internos da nossa nova classe são declarados como estáticos, o que nos permite deixar vazios o construtor e o destrutor do objeto. O processo de inicialização da nova instância da classe é organizado diretamente no método Init. Como já mencionado anteriormente, o método de inicialização contém um grande número de parâmetros, mas, na prática, eles apenas duplicam os parâmetros de inicialização dos agentes criados anteriormente.
bool CNeuronMASA::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads_mo, uint layers_mo, uint forecast, uint segments_rl, float rho, uint layers_rl, uint n_actions, uint heads_contr, uint layers_contr, int NormLayer, CNeuronBatchNormOCL *normLayer, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseSAMOCL::Init(numOutputs, myIndex, open_cl, n_actions, rho, optimization_type, batch)) return false;
No corpo do método, seguindo a tradição já estabelecida, primeiro chamamos o método com o mesmo nome da classe base. Neste caso, utilizamos como classe base uma camada neural totalmente conectada com SAM otimização.
E aqui vale lembrar que o resultado do framework MASA é formado na saída do agente controlador, na forma de um tensor de ações. Portanto, o tamanho da camada no método de inicialização da classe base é definido no nível do espaço de ações do Ator.
Em seguida, chamamos sequencialmente os métodos de inicialização dos nossos agentes. Primeiro inicializamos o agente de observação do mercado, passando a ele os parâmetros correspondentes.
Lembro que o agente de observação do mercado recebe como entrada um tensor com a descrição da situação atual do mercado, e retorna valores previstos no formato da mesma sequência multimodal para o horizonte de planejamento definido.
//--- Market Observation if(!cMarketObserver.Init(0, 0, OpenCL, window, window_key, units_count, heads_mo, layers_mo, forecast, optimization, iBatch)) return false; if(!cRevIN.Init(0, 1, OpenCL, cMarketObserver.Neurons(), NormLayer, normLayer)) return false;
Logo após, inicializamos a camada de desnornalização, cujo tamanho corresponde aos resultados do agente de observação do mercado.
Depois inicializamos o agente de RL, que recebe como entrada o mesmo tensor com a descrição da situação atual do mercado. Porém, ele retorna um tensor de ações do Ator, de acordo com a política aprendida.
//--- RL Agent if(!cRLAgent.Init(0, 2, OpenCL, window, units_count, segments_rl, fRho, layers_rl, n_actions, optimization, iBatch)) return false;
Por último, inicializamos o agente controlador, que recebe como entrada os resultados dos dois agentes anteriores e retorna o tensor de ações do Ator ajustado.
if(!cControlAgent.Init(0, 3, OpenCL, 3, window_key, n_actions / 3, heads_contr, window, forecast, layers_contr, optimization, iBatch)) return false;
Aqui é importante notar que, na nossa implementação, o agente de RL e o agente controlador interpretam de maneira diferente o tensor de ações do Ator gerado pelo agente de RL. E isso não se deve apenas à divisão de funcionalidades entre os agentes.
Na saída do agente de RL, é utilizada uma camada totalmente conectada, que gera de forma independente cada elemento no tensor de ações do Ator, com base na análise realizada da situação de mercado e na política de comportamento aprendida. No entanto, temos conhecimento prévio sobre a exclusão mútua de ações em direções opostas (compra e venda de um ativo), e os parâmetros da operação em cada direção ocupam 3 elementos no vetor de descrição das ações.
Levando isso em consideração, informamos ao agente controlador que o tensor de ações é apresentado como uma sequência multimodal, na qual cada elemento da sequência é descrito por um vetor de três elementos (dimensão do vetor de uma única operação). Dessa forma, pedimos ao agente controlador que avalie os riscos de executar a operação em cada direção individualmente.
Ao final do método de inicialização do nosso objeto do framework MASA, realizamos a substituição dos ponteiros para os buffers das interfaces externas e definimos a função de ativação sigmoide como padrão.
if(!SetOutput(cControlAgent.getOutput(), true) || !SetGradient(cControlAgent.getGradient(), true)) return false; SetActivationFunction(SIGMOID); //--- return true; }
Depois disso, encerramos a execução do método de inicialização, retornando o resultado lógico da execução das operações para o programa chamador.
É importante dizer algumas palavras sobre a definição da função de ativação. Na saída da nossa nova classe, obtemos o tensor de ações do Ator. Que é inicialmente gerado pelo agente de RL e, em seguida, ajustado pelo agente controlador. É evidente que o espaço de valores na saída dos dois agentes e do nosso objeto deve ser idêntico. Por isso, reescrevemos o método de definição da função de ativação, com o objetivo de sincronizá-la entre todos os objetos mencionados.
void CNeuronMASA::SetActivationFunction(ENUM_ACTIVATION value) { cControlAgent.SetActivationFunction(value); cRLAgent.SetActivationFunction((ENUM_ACTIVATION)cControlAgent.Activation()); CNeuronBaseSAMOCL::SetActivationFunction((ENUM_ACTIVATION)cControlAgent.Activation()); }
Após concluir o trabalho de inicialização do objeto, passamos à construção do algoritmo de propagação para frente. E aqui tudo é bastante simples. Apenas chamamos, de forma sequencial, os métodos com o mesmo nome dos nossos agentes. Primeiro, obtemos os resultados da análise da situação atual do mercado e o tensor preliminar de ações do Ator.
bool CNeuronMASA::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cMarketObserver.FeedForward(NeuronOCL.AsObject())) return false; if(!cRLAgent.FeedForward(NeuronOCL.AsObject())) return false;
Depois disso, passamos os resultados obtidos para o agente controlador, para que tome a decisão final.
if(!cControlAgent.FeedForward(cRLAgent.AsObject(), cMarketObserver.getOutput())) return false; //--- return true; }
E claro, antes de encerrar a execução do método, retornamos o resultado lógico da execução das operações para o programa chamador.
Aqui vale observar que, na visualização autoral do framework MASA apresentada anteriormente, é claramente mostrado o processo de formação do vetor final de ações, como sendo a soma dos resultados do agente de RL e do agente controlador. Na nossa implementação, porém, aceitamos os resultados do agente controlador, como os valores finais, eliminando a ligação residual com o agente de RL. Mas é necessário lembrar da arquitetura do nosso agente controlador.
Lembro que o agente controlador na nossa implementação é estruturado como um decodificador Transformer. E, como você sabe, a arquitetura do Transformer já prevê conexões residuais, tanto nos módulos de atenção quanto no bloco FeedForward. Portanto, o fluxo de informação das conexões residuais com o agente de RL já está embutido na arquitetura do agente controlador, e não precisamos organizar conexões residuais adicionais.
E agora chegamos à organização dos processos de propagação reversa. Mais precisamente, à construção do algoritmo de distribuição do gradiente de erro calcInputGradients, cujas soluções não convencionais já começamos a discutir ao explorar a estrutura da classe CNeuronMASA.
Para começar, vamos observar os resultados esperados do trabalho dos nossos agentes. Dois deles retornam o tensor de ações do Ator. E é bastante lógico, durante o treinamento, utilizar um conjunto de ações ideais como alvo no caso de aprendizado supervisionado, ou sua projeção sobre as recompensas, no caso de aprendizado por reforço.
No entanto, temos também o agente de observação do mercado, que retorna valores previstos de uma série temporal multimodal dos indicadores do instrumento financeiro analisado. E aqui surge a questão do treinamento desse agente, ou mais precisamente, a definição dos objetivos de aprendizado. Claro, podemos deixar o gradiente de erro passar pelo agente controlador e assim capturar a influência do agente de observação do mercado na decisão de ajuste dos resultados do agente de RL. Mas até que ponto essa abordagem estaria de acordo com a tarefa de prever o movimento futuro do instrumento financeiro em análise?
Acredito que, neste caso, seria mais adequado treinar separadamente o agente de observação do mercado para a previsão da série temporal futura, como fizemos anteriormente com o codificador do estado da conta. Mas o problema é que o agente de observação do mercado é parte integrante do nosso modelo. E não podemos separá-lo em um processo de treinamento independente. Assim, surge a ideia de transmitir dois valores-alvo no nível da camada. E isso já representa uma mudança radical no algoritmo da nossa biblioteca. Como você pode imaginar, isso abre um vasto campo para melhorias.
Soluções não convencionais frequentemente nos ajudam a evitar grandes volumes de trabalho, resolvendo a tarefa proposta com o mínimo de esforço. E se usássemos o mecanismo de transmissão de objetos de uma segunda fonte de dados brutos para fornecer dois objetivos ao objeto? Vamos adotar essa ideia e reescrever o método de distribuição do gradiente de erro utilizando duas fontes de dados brutos — mas desta vez, os buffers do segundo objeto serão usados para transmitir o tensor de valores-alvo ao agente de observação do mercado.
bool CNeuronMASA::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL) return false;
No entanto, essa ideia não está isenta de “armadilhas ocultas”. E uma delas é a compatibilidade dos dados. O fato é que, normalmente, alimentamos o modelo com dados brutos e não processados, recebidos diretamente do terminal. Eles passam por um pré-processamento na camada de normalização em lote, e todas as demais camadas neurais do nosso modelo já operam com dados normalizados. Inclusive o objeto CNeuronMASA. É perfeitamente lógico que a saída do agente de observação do mercado também seja uma previsão normalizada, o que facilita o trabalho do agente controlador. Só que os valores-alvo subsequentes da série temporal multimodal que estamos analisando só podem ser fornecidos em formato bruto. Por isso, adicionamos uma camada de desnornalização dos dados, que não foi utilizada no método de propagação para frente. Mas, ao organizar o processo de distribuição do gradiente de erro, primeiro adicionamos aos resultados do agente de observação do mercado os parâmetros estatísticos de distribuição dos dados brutos.
if(!cRevIN.FeedForward(cMarketObserver.AsObject())) return false;
E com isso, já podemos comparar os valores-alvo com a nossa previsão e distribuir o gradiente de erro até o agente de observação do mercado.
if(!cRevIN.FeedForward(cMarketObserver.AsObject())) return false; float error = 1.0f; if(!cRevIN.calcOutputGradients(SecondGradient, error)) return false; if(!cMarketObserver.calcHiddenGradients(cRevIN.AsObject())) return false;
Em seguida, distribuímos o gradiente de erro do agente controlador entre o agente de RL e o agente de observação do mercado. E aqui precisamos preservar o gradiente de erro anteriormente obtido no nível do agente de observação do mercado. Para isso, capturamos o erro deste agente em um buffer auxiliar e, em seguida, somamos os valores obtidos pelos dois fluxos de informação.
if(!cRLAgent.calcHiddenGradients(cControlAgent.AsObject(), cMarketObserver.getOutput(), cMarketObserver.getPrevOutput(), (ENUM_ACTIVATION)cMarketObserver.Activation()) || !SumAndNormilize(cMarketObserver.getGradient(), cMarketObserver.getPrevOutput(), cMarketObserver.getGradient(), 1, false, 0, 0, 0, 1)) return false;
Outro ponto que merece atenção está nos resultados do agente de RL e do agente controlador. Ambos retornam o tensor de ações do Ator. O primeiro faz isso com base na sua própria análise da situação atual do mercado. O segundo, após avaliar os riscos do tensor de ações fornecido, considerando os valores previstos do movimento futuro dos preços recebidos do agente de observação do mercado. Em condições ideais, os resultados dos dois agentes deveriam coincidir. Por isso introduzimos para o agente de RL um erro de desvio em relação aos resultados do agente controlador.
CBufferFloat *temp = cRLAgent.getGradient(); if(!cRLAgent.SetGradient(cRLAgent.getPrevOutput(), false) || !cRLAgent.calcOutputGradients(cControlAgent.getOutput(), error) || !SumAndNormilize(temp, cRLAgent.getPrevOutput(), temp, 1, false, 0, 0, 0, 1) || !cRLAgent.SetGradient(temp, false)) return false;
E claro, as operações de definição de erro adicional não devem apagar o gradiente de erro acumulado anteriormente. Por isso, usamos um algoritmo de substituição dos buffers de dados com posterior soma dos valores obtidos a partir dos dois fluxos de informação.
Após a distribuição do gradiente de erro entre os agentes internos, precisamos repassá-lo para o nível dos dados brutos. E aqui novamente teremos que reunir o gradiente de erro a partir de dois fluxos de informação: do agente de RL e do agente de observação do mercado. Como feito anteriormente em situações semelhantes, primeiro transmitimos o gradiente de erro do agente de observação do mercado.
if(!NeuronOCL.calcHiddenGradients(cMarketObserver.AsObject())) return false;
Depois disso, realizamos a substituição do buffer e propagamos o gradiente de erro do agente de RL.
temp = NeuronOCL.getGradient(); if(!NeuronOCL.SetGradient(NeuronOCL.getPrevOutput(), false) || !NeuronOCL.calcOutputGradients(cRLAgent.getOutput(), error) || !SumAndNormilize(temp, NeuronOCL.getPrevOutput(), temp, 1, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
Somamos os valores obtidos dos dois fluxos de informação e restauramos os ponteiros dos buffers de dados ao estado original.
Neste ponto, distribuímos o gradiente de erro entre todos os participantes do processo, conforme sua influência no resultado final do trabalho do modelo. Agora, só nos resta atualizar os parâmetros do modelo no sentido de minimizar o erro. Essa funcionalidade é executada no método updateInputWeights. O algoritmo deste método é bastante simples. Apenas chamamos, de forma sequencial, os métodos com o mesmo nome dos agentes internos. E não entraremos agora em uma análise detalhada. Só não se esqueça de que nossos agentes internos utilizam abordagens de SAM otimização. E isso significa que a chamada dos métodos dos agentes internos deve ser feita na ordem inversa à da propagação para frente.
Com isso, concluímos a análise dos algoritmos para criação dos métodos da nova classe CNeuronMASA. O código completo deste objeto e de todos os seus métodos pode ser consultado por você no anexo.
2. Arquitetura dos modelos
Agora, após concluir o trabalho de construção dos novos objetos, passamos à análise da arquitetura dos modelos a serem treinados. E aqui, vale dizer, também introduzimos mudanças e algumas soluções não convencionais.
Antes de tudo, abrimos mão do modelo separado de codificador do estado do ambiente. E isso não é surpreendente. Na nossa classe CNeuronMASA, dois agentes realizam paralelamente a análise do estado atual do ambiente.
O segundo ponto está relacionado à inclusão da informação sobre o estado da conta. Se antes essa informação era passada ao modelo do Ator como uma segunda fonte de dados brutos, agora utilizamos esse fluxo de informação para transmitir o tensor de valores-alvo do agente de observação do mercado. Por isso, simplesmente adicionamos a informação do estado da conta ao final do tensor de descrição do estado do ambiente.
Portanto, o Ator recebe como entrada um tensor unificado de dados brutos, que inclui a descrição do estado do ambiente e a informação do estado da conta.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&critic) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- Actor actor.Clear(); //--- if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os dados brutos recebidos passam por um pré-processamento na camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, devemos observar que o vetor com a informação do estado da conta rompe a estrutura do tensor de descrição do estado do ambiente. Seu comprimento pode ser diferente do tamanho da descrição de um único elemento na sequência multimodal da série temporal analisada, o que não se encaixa na estrutura dos módulos de atenção que utilizaremos a seguir. Por isso, é necessário converter os dados brutos para uma forma matricial. Essa funcionalidade ficará a cargo da camada de incorporações treináveis.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; descr.count = 1; descr.window_out = BarDescr; { int temp[HistoryBars + 1]; if(ArrayInitialize(temp, BarDescr) < (HistoryBars + 1)) return false; temp[HistoryBars] = AccountDescr; if(ArrayCopy(descr.windows, temp) < (HistoryBars + 1)) return false; } descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Essa camada divide em blocos de comprimento definido o vetor de dados brutos e projeta cada um desses blocos em um subespaço de dimensionalidade estabelecida, independentemente do tamanho original do bloco. Isso é alcançado por meio do treinamento de uma matriz de projeção independente para cada bloco.
Sabemos que a maior parte do tensor de entrada é composta por vetores do mesmo tipo, representando descrições de estados individuais do ambiente (barras), sendo que apenas o último elemento se refere à informação do estado da conta. Por isso, primeiro inicializamos o array de janelas analisadas com valores fixos e comprimento suficiente, e em seguida, alteramos apenas o tamanho do último elemento da sequência analisada.
Observe que na saída da camada de incorporações, definimos o tamanho de um único elemento da sequência igual ao tamanho da descrição de uma barra. Esse é um ponto muito importante. Para fins de análise de dados, poderíamos usar qualquer tamanho para um elemento da sequência na saída da camada de incorporações. Mas no nosso modelo existe o agente de observação do mercado, que retorna previsões com a mesma dimensionalidade dos dados brutos. E é perfeitamente lógico que os valores previstos da série temporal multimodal analisada devam corresponder aos valores-alvo utilizados no treinamento do modelo. E esses valores são idênticos aos dados brutos. O ciclo se fecha.
O uso de incorporações treináveis cumpre implicitamente a função de codificação posicional. Como mencionado anteriormente, cada elemento da sequência recebe sua própria matriz de projeção de dados. Isso significa que dois vetores idênticos em posições diferentes nos dados brutos resultarão em projeções distintas no subespaço-alvo. E na análise posterior, essas projeções serão claramente distinguíveis.
As incorporações obtidas são passadas como entrada para o nosso novo objeto do framework MASA. E aqui há uma série de pontos aos quais devemos prestar atenção.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMASA; //--- Windows { int temp[] = {BarDescr, NForecast, 2 * NActions}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; descr.count = HistoryBars+1; //--- Heads { int temp[] = {4, 4}; if(ArrayCopy(descr.heads, temp) < (int)temp.Size()) return false; } //--- Layers { int temp[] = {3, 3, 3}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window = BarDescr; descr.probability = Rho; descr.step = 1; // Normalization layer descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
No array dinâmico descr.windows, especificamos os principais parâmetros das sequências analisadas pelos agentes internos. Aqui, indicamos sequencialmente a dimensionalidade de um elemento da sequência dos dados brutos, o horizonte de previsão da série temporal subsequente e o espaço de ações do Ator.
O último parâmetro merece atenção especial. Ao construir a arquitetura dos agentes internos, falamos sobre a organização de uma dependência direta entre o estado do ambiente e a ação gerada, o que exclui a aleatoriedade no comportamento do Ator. No entanto, na nossa implementação, estamos treinando especificamente uma política estocástica para o Ator. Por isso, dobramos o espaço de ações na saída do framework MASA. É fácil perceber que isso está de acordo com a abordagem anteriormente utilizada por nós ao organizar uma política estocástica. O vetor obtido na saída do framework MASA é dividido logicamente em duas partes iguais, que representam os valores médios e as variâncias do espaço de ações do Ator no estado do ambiente analisado. É justamente por esse motivo que desativamos a função de ativação nesta camada.
Cada módulo de atenção que usamos opera com 4 cabeças. E cada Agente inclui 3 camadas internas de Codificador/Decodificador.
Como já foi dito anteriormente, os resultados do framework MASA são passados para a camada de estado valente do autocodificador, para gerar ações aleatórias do Ator conforme a distribuição definida.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
O vetor de ações resultante é projetado para os limites definidos com a ajuda de uma camada convolucional e da função de ativação sigmoide.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; }
E na saída do modelo, utilizamos uma camada de alinhamento de frequência entre os resultados do modelo e os valores-alvo.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NActions; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Na etapa seguinte, passamos à construção da arquitetura do Crítico. Aqui, pode-se dizer que, em geral, a arquitetura do modelo foi herdada de trabalhos anteriores. No entanto, a eliminação do modelo separado de codificador do estado do ambiente levou à adição de um bloco de análise do estado bruto também no modelo do Crítico. Para isso, utilizamos o framework PSformer para analisar o estado atual. Ao mesmo tempo, os dados brutos do Crítico não incluem a informação sobre o estado da conta. Na minha opinião pessoal, essa informação não tem valor para o Crítico. O sucesso de uma operação depende das condições do mercado, não do estado da conta no momento da abertura.
Claro que é possível argumentar que indicar um volume excessivamente alto ou baixo pode levar a uma falha na execução da operação de trading e, como consequência, à ausência de uma posição aberta. Mas a definição do volume da operação é funcionalidade do Ator. E o Crítico deve reagir a casos tão específicos? Isso remete à questão da divisão de funcionalidades entre os modelos.
O segundo ponto diz respeito às posições abertas e aos lucros ou prejuízos acumulados, ou seja, ao desempenho de operações anteriores, enquanto o Crítico avalia a operação atual. E mesmo que se assuma que o Crítico avalia não uma única operação, mas a política atual, ainda assim ele avalia a efetividade da política até o fim do episódio, e não de forma retrospectiva.
Portanto, o modelo recebe como entrada apenas a informação do estado atual do ambiente.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Como antes, os dados brutos são processados por uma camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
E são enviados para três camadas sequenciais do framework PSformer.
//--- layer 2 - 4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPSformer; descr.window = BarDescr; descr.count = HistoryBars; descr.window_out = Segments; descr.probability = Rho; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } }
Em seguida, utilizamos uma camada convolucional e uma camada totalmente conectada, aplicadas em sequência, para reduzir a dimensionalidade do tensor obtido.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = int(LatentCount / descr.count); descr.probability = Rho; descr.activation = GELU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = Rho; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Depois, combinamos os resultados da análise do estado do ambiente com as ações do agente em uma camada de concatenação de dados.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = LatentCount; descr.step = NActions; descr.activation = GELU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
Na sequência, temos o módulo de tomada de decisão, composto por quatro camadas totalmente conectadas.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = NRewards; descr.activation = None; descr.optimization = ADAM; descr.probability = Rho; if(!critic.Add(descr)) { delete descr; return false; }
E na saída, utilizamos uma camada de alinhamento de frequência entre os resultados do modelo e os valores-alvo.
//--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = NRewards; descr.count = 1; descr.step = int(false); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- return true; }
Após definirmos com sucesso a arquitetura dos dois modelos treináveis, encerramos a execução do método, retornando o resultado lógico da execução das operações para o programa chamador.
3. Programa de treinamento dos modelos
Agora estamos nos aproximando com segurança do desfecho lógico do nosso trabalho. E passamos à construção do programa de treinamento dos modelos. É evidente que a exclusão de um dos modelos treináveis impacta diretamente o algoritmo de construção do programa de treinamento. Além disso, ao estruturar o módulo do framework MASA, acordamos utilizar o fluxo de informação de uma segunda fonte de dados brutos como um fluxo adicional de valores-alvo. Por isso, sem perder tempo, vamos direto à análise do algoritmo de treinamento dos modelos, implementado no método Train.
Como antes, começamos com uma breve preparação. Aqui, formamos um vetor de probabilidades de seleção de trajetórias do buffer de reprodução de experiência com base na efetividade das passagens.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
E declaramos as variáveis locais necessárias.
A seguir, organizamos o laço de treinamento, cujo número de iterações é definido por parâmetros externos do nosso EA.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i+NForecast].state) || !state.Resize(NForecast*BarDescr) || MathAbs(state).Sum() == 0 || !bForecast.AssignArray(state)) { iter --; continue; }
No corpo do laço, amostramos uma trajetória e o estado do ambiente correspondente. E imediatamente verificamos a existência de dados históricos e subsequentes a partir do estado amostrado, dentro da profundidade de análise e horizonte de planejamento definidos. Caso os dados estejam ausentes em pelo menos um dos pontos de controle, passamos à amostragem de uma nova trajetória e estado.
Se os dados necessários estiverem disponíveis, os transferimos para os buffers correspondentes. Em seguida, adicionamos à descrição do estado do ambiente a informação sobre o estado da conta no momento da análise.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bState.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bState.Add(Buffer[tr].States[i].account[1] / PrevBalance); bState.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bState.Add(Buffer[tr].States[i].account[2]); bState.Add(Buffer[tr].States[i].account[3]); bState.Add(Buffer[tr].States[i].account[4] / PrevBalance); bState.Add(Buffer[tr].States[i].account[5] / PrevBalance); bState.Add(Buffer[tr].States[i].account[6] / PrevBalance);
Logo depois, adicionamos a marca temporal do estado do ambiente analisado.
//--- double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Após a preparação dos dados brutos, passamos ao processo de treinamento dos modelos. E quem realiza a primeira iteração de treinamento é o Crítico. No modelo, alimentamos o estado do ambiente analisado e o vetor de ações que o Ator realmente executou no momento da coleta do conjunto de treinamento. Afinal, são para essas ações que temos a recompensa real fornecida pelo ambiente. E executamos as operações de propagação para frente, avaliando as ações efetivamente tomadas pelo Ator.
//--- Critic bActions.AssignArray(Buffer[tr].States[i].action); Critic.TrainMode(true); if(!Critic.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bActions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
É fácil deduzir que, como resultado da execução das operações de propagação para frente do Crítico, esperamos obter um tensor de recompensas próximo ao que foi efetivamente recebido do ambiente. Por isso, extraímos do buffer de reprodução de experiência a recompensa real pelas ações executadas e realizamos as operações de propagação reversa do Crítico, minimizando o erro.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CBufferFloat *)GetPointer(bActions), (CBufferFloat *)GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Em seguida, inicia-se o processo de treinamento da política do Ator, que realizamos em duas etapas. Primeiro, executamos a propagação para frente do Ator para gerar o tensor de ações.
//--- Actor Policy if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Logo após, realizamos as operações de propagação para frente do Crítico. Só que, desta vez, são avaliadas as ações geradas pelo Ator.
Critic.TrainMode(false); if(!Critic.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(Actor), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aqui vale destacar que, nesta etapa, desativamos o modo de treinamento do Crítico. Isso nos permite evitar a influência de valores incorretos no aprendizado da política de recompensas.
Depois, avaliamos a efetividade da passagem analisada. E, se a política de comportamento do Ator durante essa passagem tiver obtido resultado positivo, então, no estilo de aprendizado supervisionado, aproximamos a política atual do Ator da política bem-sucedida. Essa é a primeira etapa do treinamento do Ator.
if(Buffer[tr].States[0].rewards[0] > 0) if(!Actor.backProp(GetPointer(bActions),(CBufferFloat*)GetPointer(bForecast),GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Na segunda etapa do treinamento do Ator, atribuirmos ao Crítico a tarefa de aumentar a recompensa e propagamos o gradiente de erro até o nível das ações do Ator.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); } if(!Critic.backProp(Result, (CNet *)GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)GetPointer(bForecast),GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Com isso, queremos que o Crítico indique ao Ator a direção para ajustar sua política visando aumentar a rentabilidade geral. Em seguida, corrigimos a política do Ator na direção indicada.
Agora, só nos resta informar o usuário sobre o andamento do processo de treinamento e passar para a próxima iteração de treinamento dos modelos.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a conclusão bem-sucedida de todas as iterações de treinamento dos modelos, limpamos o campo de comentários no gráfico do instrumento financeiro, onde exibimos informações ao usuário.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Registramos no diário os resultados do treinamento dos modelos e iniciamos o processo de encerramento do programa.
Com isso, encerramos a análise dos algoritmos de construção do framework MASA e da implementação dos programas de treinamento dos modelos. O código completo pode ser consultado por você no anexo.
4. Testes
E finalmente chegamos ao desfecho lógico do nosso trabalho de implementação das abordagens propostas pelos autores do framework MASA com os recursos do MQL5. E agora passamos à etapa mais emocionante: a avaliação da efetividade das abordagens implementadas com base em dados históricos reais.
É importante destacar que estamos realizando uma “avaliação da efetividade dos métodos implementados”, e não apenas dos “propostos”. Afinal, durante a implementação, fizemos modificações na versão original do framework apresentada pelos autores.
Os modelos foram treinados com dados históricos do ano de 2023 para o instrumento financeiro EURUSD, no timeframe H1. Os parâmetros de todos os indicadores utilizados permaneceram em seus valores padrão.
Para o treinamento inicial, foi utilizada uma base de dados coletada em trabalhos anteriores, que foi periodicamente atualizada durante o processo de treinamento dos modelos, com o objetivo de alinhar a amostra à política atual do Ator.
Após alguns ciclos de treinamento dos modelos e atualização da base de dados, obtivemos uma política que demonstra lucratividade tanto na amostra de treinamento quanto na de teste.
O teste da política treinada foi realizado com dados históricos de janeiro de 2024, mantendo todos os outros parâmetros inalterados. Os resultados do teste estão indicados abaixo.
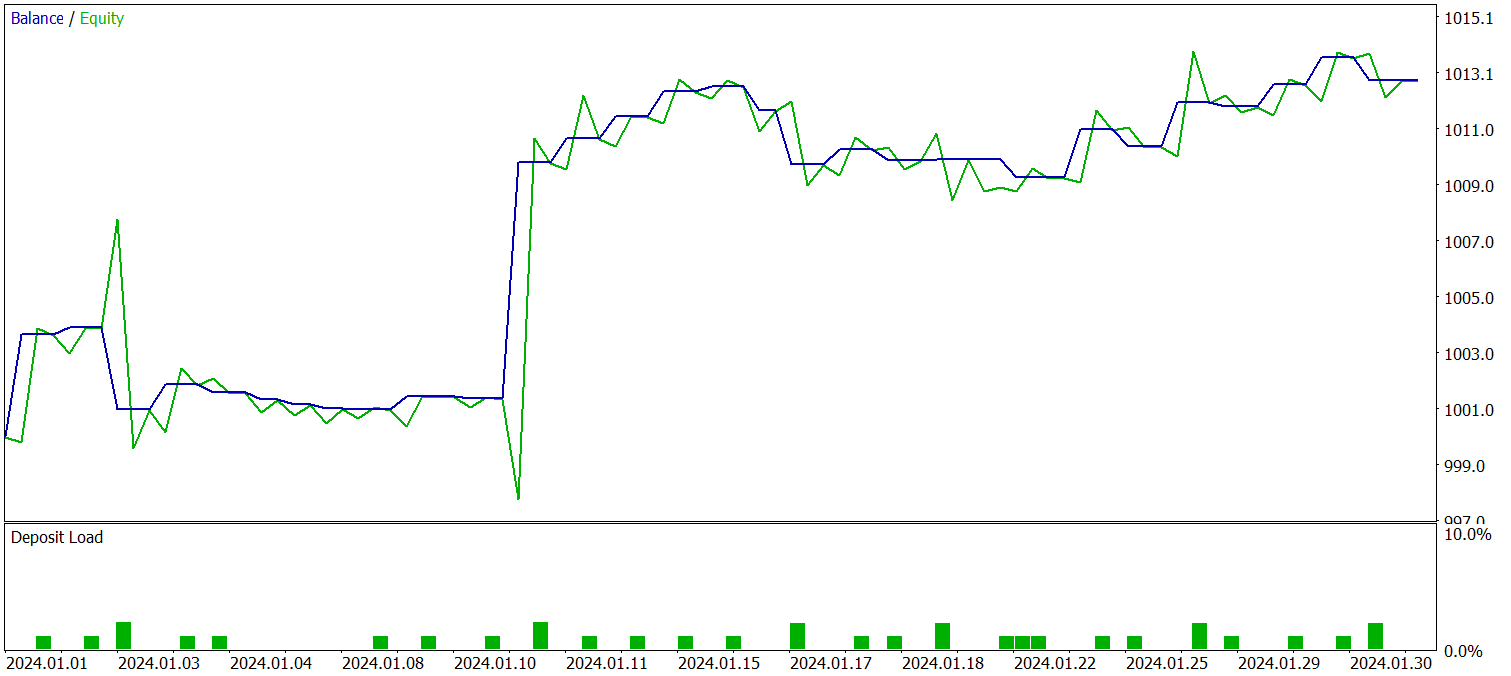
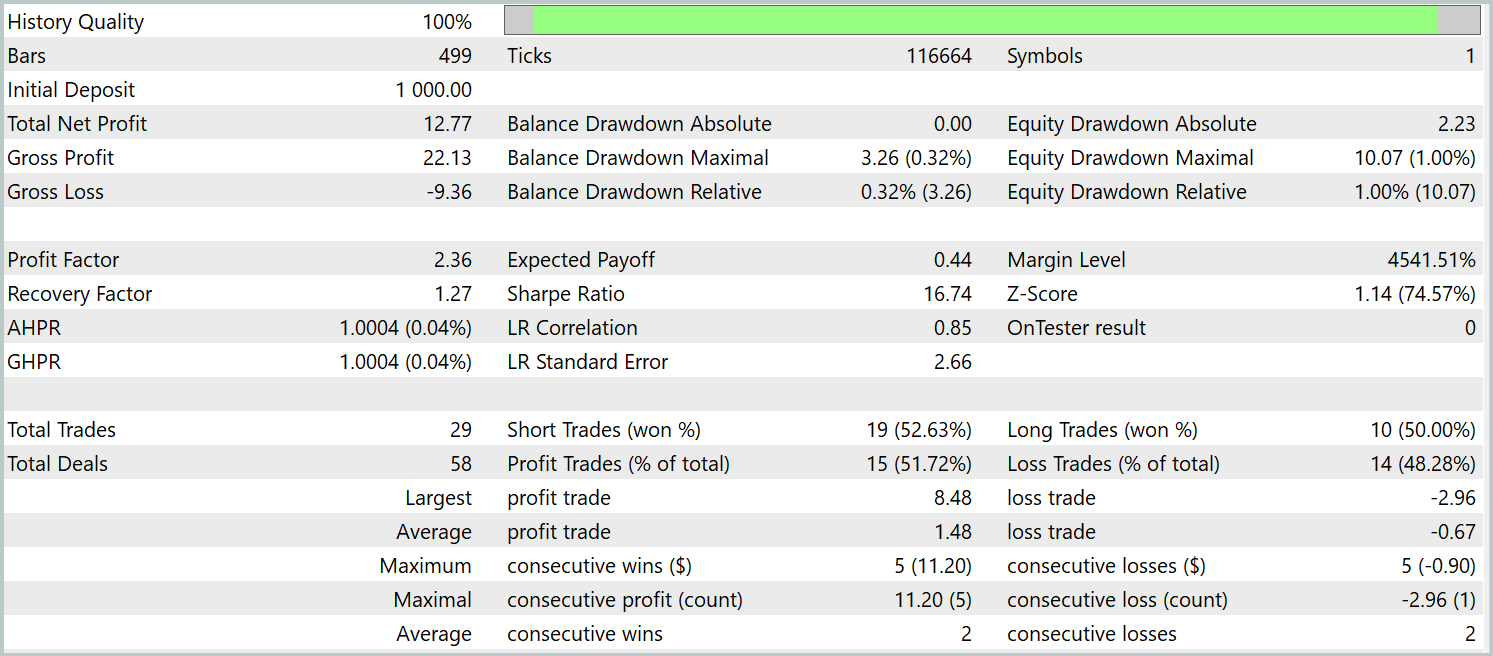
Durante o período de teste, o modelo realizou 29 operações de trading, metade das quais foi encerrada com lucro. No entanto, graças ao fato de que a média das operações lucrativas foi mais de duas vezes maior do que a média das operações com prejuízo, observamos uma tendência clara de crescimento do saldo da conta. Isso pode indicar o potencial do framework implementado.
Considerações finais
Conhecemos uma metodologia inovadora para gestão de portfólios de investimentos em mercados financeiros instáveis, ou seja, o sistema adaptativo multiagente MASA. Esse framework combina de forma eficaz os pontos fortes dos RL-algoritmos com métodos adaptativos de otimização, o que permite aumentar a lucratividade do modelo ao mesmo tempo que reduz os riscos.
Na parte prática, implementamos nossa própria visão das abordagens propostas, utilizando os recursos do MQL5. Realizamos o treinamento dos modelos com dados históricos reais. Os resultados obtidos nos testes demonstram o potencial existente nas abordagens propostas. No entanto, antes de aplicar o modelo em operações reais, é necessário realizar um conjunto adicional de medidas, incluindo o treinamento com uma amostra mais representativa e uma bateria abrangente de testes.
Links
- Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos com método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de Modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16570
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso