
Нейросети в трейдинге: Мультиагентная адаптивная модель (MASA)

Введение
Компьютерные технологии становятся неотъемлемой частью финансовой аналитики, предлагая новые подходы к решению сложных задач. В последние годы обучение с подкреплением доказало свою эффективность в динамическом управлении инвестиционными портфелями в условиях турбулентных финансовых рынков. Однако существующие методы часто фокусируются на максимизации доходности, не уделяя должного внимания управлению рисками, особенно в условиях неопределенности, вызванной пандемией, природными катастрофами и региональными конфликтами.
Для устранения этого недостатка, в работе "Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management" был предложен мультиагентный адаптивный фреймворк MASA (Multi-Agent and Self-Adaptive). Он основан на уникальной интеграции двух взаимодействующих агентов: первый оптимизирует доходность с использованием алгоритма TD3, а второй минимизирует риски с помощью эволюционных алгоритмов или других оптимизационных методов. Дополнительно в MASA интегрирован наблюдатель рынка, который использует глубокие нейронные сети для анализа рыночных трендов и их передачи в качестве обратной связи.
Авторы MASA провели тестирование модели на данных индексов CSI 300, Dow Jones Industrial Average (DJIA) и S&P 500 за последние 10 лет. Полученные ими результаты демонстрируют превосходство MASA над традиционными RL-подходами в управлении портфелями.
1. Алгоритм MASA
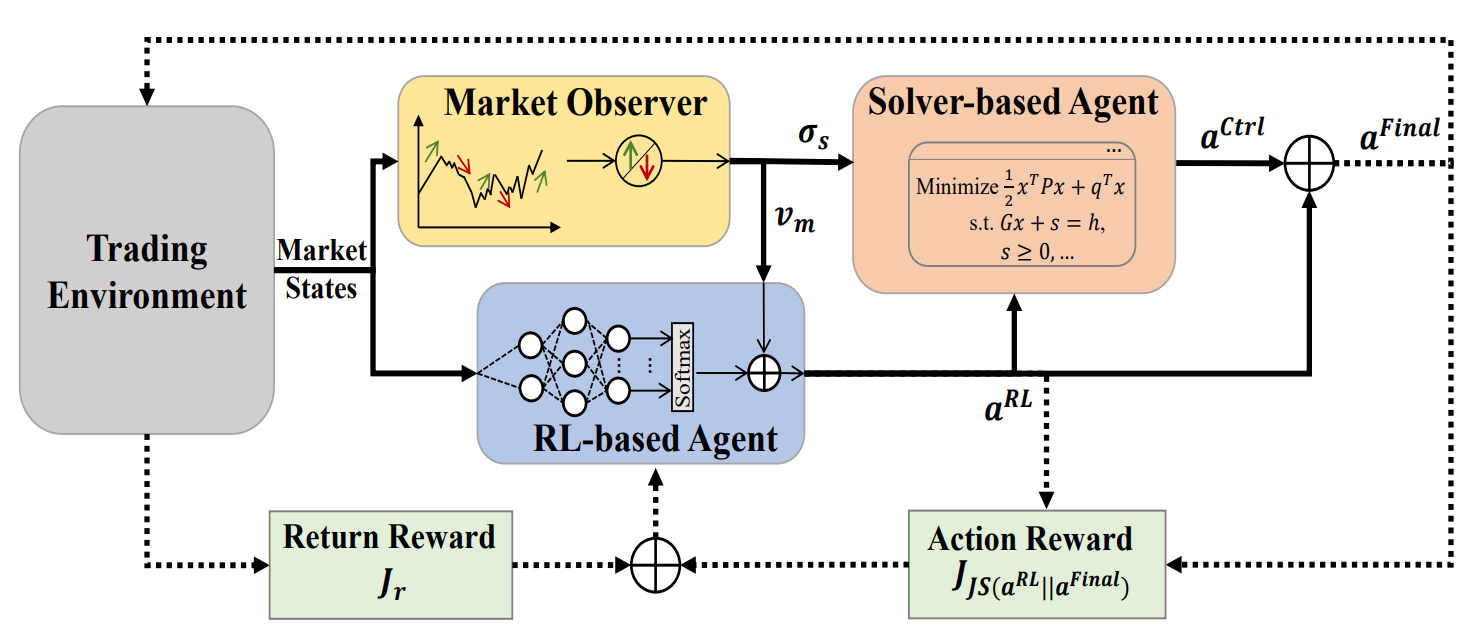
С целью преодоления ловушки RL-подходов, склоняющихся к оптимизации доходности инвестиций, авторы фреймворка предлагают мультиагентную адаптивную структуру (MASA), в которой два взаимодействующих и реактивных агента (один агент на основе RL, а второй — на основе альтернативного алгоритма оптимизации), используются для реализации принципиально новой схемы мультиагентного RL с целью динамической балансировки компромисса между общей доходностью вновь пересмотренного портфеля и потенциальных рисков, особенно в условиях сильной турбулентности финансовых рынков.
В предложенной авторами фреймворка архитектуре RL-агент, основанный на алгоритме TD3, оптимизирует общую доходность текущего инвестиционного портфеля. В то же время агент на основе альтернативного алгоритма оптимизации работает над дальнейшей адаптацией инвестиционного портфеля, возвращаемого RL-агентом, таким образом, чтобы свести к минимуму его потенциальные риски после рассмотрения оценки рыночного тренда, предоставленного рыночным наблюдателем.
По сути, за счет четкого разделения функционала между агентами, модель постоянно учится и адаптируется к базовой среде финансового рынка. Мультиагентная схема MASA может достичь более сбалансированных инвестиционных портфелей, как с точки зрения их доходности, так и с точки зрения потенциальных рисков, по сравнению с портфелями, полученными с помощью подходов, основанных только на RL.
Стоит отметить, что структура MASA принимает слабосвязанную и конвейерную вычислительную модель между тремя взаимодействующими и интеллектуальными агентами. Таким образом, общий подход на основе мультиагентного RL более устойчив и надежен, поскольку общая структура будет продолжать работать, когда любой отдельный агент выходит из строя.
Перед началом процесса итеративного обучения модели, инициализируется вся соответствующая информация, включая политику RL, информацию о состоянии рынка, хранящуюся в агенте Market Observer, и так далее.
В процессе обучения информация о текущем состоянии рынка Ot (например, самый последний нисходящий или восходящий тренд базового финансового рынка за последние несколько торговых дней) будет собираться в качестве основной информации для последующего анализа агентом по наблюдению за рынком. Кроме того, вознаграждение за ранее выполненное действие At−1,Final будет получено в качестве обратной связи для RL-алгоритма и пересмотра политики поведения RL-агента.
Затем вызывается агент наблюдения за рынком, для вычисления предлагаемой границы риска σs,t и вектора рынка Vm,t, как некоторые дополнительные признаки для обновления RL-агента и Контролера в соответствии с последними рыночными условиями.
Для поддержания гибкости и адаптивности предложенной структуры MASA, могут использоваться различные подходы, в том числе алгоритмические или глубокие нейронные сети. Что еще более важно, следует отметить, что как агенты, основанные на RL, так и агенты, основанные на альтернативных алгоритмах оптимизации, уже защищены текущей рыночной информацией в качестве наиболее ценной обратной связи, полученной из существующей торговой среды. Предоставленная агентом по наблюдению за рынком информация о предполагаемой конъюнктуре рынка, используется исключительно в качестве дополнительной информации для быстрой адаптации и повышения производительности как RL-агента, так и агента-контролера, особенно когда последние рыночные условия очень изменчивы.
В худших ситуациях, когда характеристики, предложенные агентом мониторинга рынка, могут быть неправильными из-за «шумов» и вводить в заблуждение остальных агентов при определении оптимальных действий в определённые дни торгов, адаптивный характер механизма вознаграждения, основанного на RL, позволяет адаптироваться к базовой торговой среде в процессе последующих итераций обучения. Кроме того, способность интеллектуального агента мониторинга рынка к самокоррекции в процессе обучения помогает обеспечить условие, что такие вводящие в заблуждение шумы могут быть эффективно и оперативно исправлены на протяжении более длительного времени торгов.
Интересно, что по результатам экспериментов, проведенных авторами фреймворка, наблюдаются довольно впечатляющие улучшения в конечной производительности агентов, основанных как на RL, так и на альтернативных оптимизаторах, даже когда используется относительно простой алгоритмический подход для реализации агента-наблюдателя за рынком в предлагаемой структуре MASA на сложных наборах данных CSI 300, DJIA и S&P 500 за последние 10 лет.
Очевидно, что для глубокого понимания конечного влияния информации, предлагаемой агентом по наблюдению за рынком, на два других интеллектуальных агента, к которым должна быть применена предложенная структура MASA, необходимо провести тщательный анализ в более сложных наборах данных или других прикладных областях.
После вызова агента по наблюдению за рынком, RL-агент будет запущен для генерации текущего действия At,RL в качестве весов портфеля, которые могут быть пересмотрены в дальнейшем последующим Контролером на основе альтернативного алгоритма оптимизации, после рассмотрения собственной стратегии управления рисками и предложенных рыночных условий, предоставленных агентом по наблюдению за рынком. В целом, благодаря принятию этой слабосвязанной и конвейерной вычислительной модели, полученная в результате среда MASA будет продолжать работать, как надежная система MAS, даже в случае сбоя какого-либо отдельного агента.
При помощи руководящего механизма, основанного на вознаграждении, принятого фреймворком MASA для бережного реагирования на постоянно меняющуюся окружающую среду, агенты принятия решений могут итеративно увеличивать текущий инвестиционный портфель в отношении как целей общей доходности, так и потенциальных рисков, после рассмотрения ценной обратной связи от агента наблюдения за рынком. В то же время, механизм руководства, основанный на вознаграждении, использует меру дивергенции, основанную на энтропии, для продвижения разнообразия генерируемых наборов действий в качестве интеллектуальной и адаптируемой стратегии, для удовлетворения потребностей в крайне изменчивой среде различных финансовых рынков.
Авторская визуализация фреймворка MASA представлена ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов фреймворка MASA, мы переходим к практической части нашей работы, в которой реализуем собственное видение предложенных подходов средствами MQL5.
Как было сказано выше, фреймворк MASA включает 3 агента. Для большей наглядности и читаемости кода мы создадим по объекту для каждого агента, которые позже объединим в единую структуру.
2.1 Агент наблюдения за рынком
Свою работу мы начнем с создания агента наблюдения за рынком. Авторы фреймворка MASA говорят о возможности использования различных алгоритмов анализа рынков — от самых простых аналитических подходов до сложных глубоких моделей. Основная задача агента наблюдения за рынком — определить основные тренды, с целью прогнозирования наиболее вероятностного предстоящего движения.
В своей реализации мы будем использовать смешанный подход. Вначале мы воспользуемся алгоритмом кусочно-линейного представления временных рядом для выявления текущих тенденций. Затем, мы проанализируем зависимости выявленных тенденций отдельных унитарных последовательностей в модуле внимания c относительным кодированием. И на выходе агента — попытаемся спрогнозировать наиболее вероятное поведения рынка на заданный горизонт планирования при помощи MLP.
Вышеописанный комплексный алгоритм агента наблюдения за рынком мы создадим в рамках нового объекта CNeuronMarketObserver. Его структура представлена ниже.
class CNeuronMarketObserver : public CNeuronRMAT { public: CNeuronMarketObserver(void) {}; ~CNeuronMarketObserver(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMarketObserver; } };
Легко заметить, что описанный выше алгоритм имеет линейную структуру. Поэтому, в качестве родительского класса нашего нового объекта был выбран CNeuronRMAT, в рамках которого организован процесс функционирования небольшой линейной модели. Это позволяет нам ограничиться созданием новой структуры агента наблюдения за рынком в рамках метода инициализации Init. А весь основной функционал уже организован в методах родительского класса.
В параметрах метода инициализации объекта Init мы получаем основные константы, определяющие архитектуру нашего агента наблюдения за рынком. Среди них:
- window — размер вектора описания одного элемента последовательности (количество унитарных временных рядов);
- window_key — размерность внутренних сущностей блока внимания (Query, Key, Value);
- units_count — глубина анализируемой истории:
- heads — количество голов внимания;
- layers — количество слоев в блоке внимания;
- forecast — горизонт прогнозирования предстоящего движения.
bool CNeuronMarketObserver::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * forecast, optimization_type, batch)) return false;
В теле метода мы сразу вызываем одноименный метод базового полносвязного слоя, который является общим родительским классом для всех нейронных слоев в нашей библиотеке. В рамках метода родительского класса организована инициализация базовых интерфейсов нашего объекта.
Обратите внимания на 2 момента. Во-первых, мы используем метод инициализации базового класса, а не прямого родительского. Ведь архитектура нашего агента сильно отличается от родительского объекта.
Во-вторых, при вызове метода родительского класса мы указываем размер объекта, как произведение горизонта планирования на размер вектора описания одного элемента последовательности. Именно такой тензор мы ожидаем получить в результате работы нашего агента наблюдения за рынком.
Далее очищаем динамический массив указателей на внутренние объекты.
//--- Clear layers' array
cLayers.Clear();
cLayers.SetOpenCL(OpenCL);
На этом мы завершаем подготовительную работу и переходим к непосредственной организации структуры нашего агента наблюдения за рынком.
На вход модели мы ожидаем получить мультимодальный временной ряд в виде последовательности векторов описания отдельных состояний системы (в нашем случае баров). Поэтому, для организации работы в разрезе отдельных унитарных последовательностей, нам необходимо транспонировать полученные данные.
//--- Tranpose input data int lay_count = 0; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, units_count, window, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; }
И затем преобразуем полученные унитарные последовательности в кусочно-линейное представление.
//--- Piecewise linear representation lay_count++; CNeuronPLROCL *plr = new CNeuronPLROCL(); if(!plr || !plr.Init(0, lay_count, OpenCL, units_count, window, false, optimization, iBatch) || !cLayers.Add(plr)) { delete plr; return false; }
Для анализа зависимостей между отдельными унитарными последовательностями, мы воспользуемся уже имеющимся модулем внимания с относительным кодированием, в параметрах которого укажем нужное количество внутренних слоев.
//--- Self-Attention for Variables lay_count++; CNeuronRMAT *att = new CNeuronRMAT(); if(!att || !att.Init(0, lay_count, OpenCL, units_count, window_key, window, heads, layers, optimization, iBatch) || !cLayers.Add(att)) { delete att; return false; }
На основе данных, полученных на выходе блока внимания, мы постараемся спрогнозировать предстоящие значения для каждой унитарной последовательности. Здесь, в качестве MLP для независимого прогнозирования значений каждого унитарного временного ряда, мы воспользуемся сверточным блоком с остаточной связью CResidualConv.
//--- Forecast mapping lay_count++; CResidualConv *conv = new CResidualConv(); if(!conv || !conv.Init(0, lay_count, OpenCL, units_count, forecast, window, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; }
В завершении нам остается лишь провести обратную трансформацию данных, для представления их в размерности исходных данных.
//--- Back transpose forecast lay_count++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, window, forecast, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; }
А для сокращения операций копирования данных, мы воспользуемся отработанной технологией подмены указателей на буфера внешних интерфейсов обмена информацией.
if(!SetOutput(transp.getOutput(), true) || !SetGradient(transp.getGradient(), true)) return false; //--- return true; }
После чего, завершаем работу метода инициализации, вернув логический результат выполнения операций, вызывающей программе.
Как уже было сказано выше, весь основной функционал работы данного класса унаследован от родительского объекта. Следовательно, мы завершаем работу над агентом наблюдения за рынком. А с полным кодом данного класса вы можете ознакомиться во вложении.
2.2 RL-агент
Следующим этапом мы переходим к построению RL-агента. В структуре фреймворка MASA он работает параллельно агенту наблюдения за рынком и проводит независимый анализ рыночной ситуации с последующим принятием решении в соответствии с выученной политикой поведения.
Авторы фреймворка MASA предлагают использовать в качестве RL-агента модель, обученную с использованием подходов алгоритма TD3. Мы немного отойдем от предложенного варианта реализации и используем иную архитектуру RL-агента. Для независимого анализа текущего состояния окружающей среды мы будем использовать фреймворк PSformer. А за принятие решения на основании проведенного анализа, будет отвечать небольшой перцептрон с использованием подходов SAM-оптимизации.
Алгоритм нашего RL-агента мы реализуем в новом объекте CNeuronRLAgent, структура которого представлена ниже.
class CNeuronRLAgent : public CNeuronRMAT { public: CNeuronRLAgent(void) {}; ~CNeuronRLAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, uint layers, uint n_actions, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const override { return defNeuronRLAgent; } };
Как можно заметить, здесь мы эксплуатируем тот же подход с наследованием функционала линейной модели от родительского объекта CNeuronRMAT. Следовательно, нам достаточно указатель новую архитектуру модуля в методе инициализации Init.
bool CNeuronRLAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, uint layers, uint n_actions, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, n_actions, optimization_type, batch)) return false;
Структура параметров метода очень похожа на представленную при построении агента наблюдения за рынком. Но есть и некоторая специфика. К примеру, горизонт планирования forecast заменен на пространство действий агента n_actions. Кроме того, добавлены специфические параметры количества сегментов (segments) и коэффициент области размытия (rho).
Как и ранее, в теле метода мы вызываем одноименный метод прародителя (базового полносвязного слоя), только в качестве размера тензора результатов объекта указываем пространство действий нашего RL-агента.
Поле чего очищаем динамический массив указателей на внутренние объекты.
//--- Clear layers' array
cLayers.Clear();
cLayers.SetOpenCL(OpenCL);
Получаемые на вход модели исходные данные мы сразу передаем в PSformer, нужное количество слоев которого создаем в теле цикла.
//--- State observation int lay_count = 0; for(uint i = 0; i < layers; i++) { CNeuronPSformer *psf = new CNeuronPSformer(); if(!psf || !psf.Init(0, lay_count, OpenCL, window, units_count, segments, rho, optimization,iBatch)|| !cLayers.Add(psf)) { delete psf; return false; } lay_count++; }
Далее наш RL-агент принимает решение об оптимальном действии, пропуская результаты проведенного анализа текущего состояния окружающей среды через блок принятия решений, который состоит из сверточного и полносвязнного слоев. Вначале сверточный слой понижает размерность тензора исходных данных.
CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(n_actions, lay_count, OpenCL, window, window, 1, units_count, 1, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; } conv.SetActivationFunction(GELU); lay_count++;
А затем, полносвязный слой генерирует тензор действий.
CNeuronBaseSAMOCL *flat = new CNeuronBaseSAMOCL(); if(!flat || !flat.Init(0, lay_count, OpenCL, n_actions, optimization, iBatch) || !cLayers.Add(flat)) { delete flat; return false; } SetActivationFunction(SIGMOID);
Обратите внимание, что в данном случае мы не используем стохастическую политику Актера. Однако мы не исключаем возможности её использования, о чем поговорим позже.
Для вектора действий мы по умолчанию используем сигмовидную функцию активации, ограничивая область значений в диапазоне от 0 до 1. Тем не менее, функция активации может быть изменена из внешней программы.
Теперь нам остается лишь осуществить подмену указателей на буферы данных интерфейсов и завершить работу метода, передав логический результат выполнения операций вызывающей программе.
if(!SetOutput(flat.getOutput(), true) || !SetGradient(flat.getGradient(), true)) return false; //--- return true; }
На этом мы завершаем рассмотрение объекта RL-агента. С полным кодом данного класса и всех его методов вы можете ознакомиться во вложении.
2.3 Контролер
Выше мы уже построили объекты двух агентов из трех. И теперь нам необходимо организовать функционал третьего агента — Контролера. В его функционале лежит оценка рисков и корректировка действий RL-агента на основании анализа состояния окружающей среды, проведенного агентом наблюдения за рынком.
Как несложно заметить, основное отличие последнего агента — наличие двух источников исходных данных. При этом нам необходимо проанализировать зависимости и влияние одного источника данных на значения другого. На мой взгляд, с этой задачей идеально справится структура декодера Transformer. Однако, вместо ванильных Self- и Cross-Attention, мы воспользуемся аналогичными модулями с относительным кодированием.
Для реализации данного алгоритма мы создадим новый объект CNeuronControlAgent, который унаследует базовый функционал все от того же CNeuronRMAT. Однако, наличие двух источников данных потребует от нас дополнительной работы по переопределению методов. Структура нового класса представлена ниже.
class CNeuronControlAgent : public CNeuronRMAT { protected: virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronControlAgent(void) {}; ~CNeuronControlAgent(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronControlAgent; } };
Как и ранее, структура внутренних объектов нашего агента задается в методе инициализации Init, в параметрах которого мы видим знакомые константы описания архитектуры декодера Transformer.
bool CNeuronControlAgent::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { //--- Init parent object if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false; //--- Clear layers' array cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
В теле метода, аналогично двум предыдущим случаям, мы вызываем одноименный метод базового полносвязного слоя, указав размерность результатов на уровне тензора основных исходных данных. После чего, очищаем динамический массив хранения указателей на внутренние объекты.
Далее мы переходим к созданию архитектуры нашего агента-контролера. И тут необходимо вспомнить, что на выходе агента наблюдения за рынком мы получаем прогноз предстоящего рыночного движения в виде мультимодального временного ряда, который представлен последовательностью векторов описания отдельных состояний окружающей среды (в нашем случае баров).
Здесь можно рассматривать 2 подхода: сопоставление действий RL-агента с каждым баром, или отдельными унитарными последовательностями. При этом мы понимаем, что агент наблюдения за рынком нам предоставил лишь прогнозные данные, вероятность осуществления которых далека от 100%. И существует вероятность отклонений абсолютно во всех значениях.
Давайте рассуждать логически. Сколько нам даст информации вектор описания одной прогнозной свечи, где велика доля отклонений различной степени в каждом элементе? Вопрос спорный, и на него сложно дать ответ, не имея понимания о точности отдельных прогнозов.
С другой стороны, если посмотреть на отдельный унитарный ряд, то, помимо отдельных значений, можно выделить и тенденцию предстоящего движения. И так как тенденция формируется не одним значением, а их совокупностью, то логично ожидать её подтверждение, даже при отклонении некоторых элементов.
Более того, все унитарные последовательности в нашем мультимодальном временном ряде имеют некоторые зависимости между собой. И при подтверждении прогнозной тенденции одного унитарного временного ряда значениями другого, вероятность такого прогноза повышается.
С учетом вышесказанного, было принято решение об анализе зависимости действий агента от прогнозных значений унитарных последовательностей. Для этого мы сначала перенесем данные второго источника данных в специально подготовленный базовый нейронный слой.
int lay_count = 0; CNeuronBaseOCL *flat = new CNeuronBaseOCL(); if(!flat || !flat.Init(0, lay_count, OpenCL, window_kv * units_kv, optimization, iBatch) || !cLayers.Add(flat)) { delete flat; return false; }
А затем переформатируем его в представление унитарных последовательностей.
lay_count++; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, lay_count, OpenCL, units_kv, window_kv, optimization, iBatch) || !cLayers.Add(transp)) { delete transp; return false; } lay_count++;
Далее нам предстоит выстроить архитектуру нашего декодера, нужное количество слоев которого создается в цикле. А число итераций данного цикла определяется внешними параметрами метода инициализации.
//--- Attention Action To Observation for(uint i = 0; i < layers; i++) { if(units_count > 1) { CNeuronRelativeSelfAttention *self = new CNeuronRelativeSelfAttention(); if(!self || !self.Init(0, lay_count, OpenCL, window, window_key, units_count, heads, optimization, iBatch) || !cLayers.Add(self)) { delete self; return false; } lay_count++; }
Здесь стоит обратить внимание, что на входе ванильного декодера Transformer данные вначале обрабатываются модулем Self-Attention. В данном модуле осуществляется анализ зависимостей между отдельными элементами исходных данных. В своей реализации мы заменяем его на аналогичный, с использованием алгоритма относительного кодирования. Однако, создаем вышеуказанный модуль только при условии наличия в исходной последовательности более одного элемента. Ведь согласитесь, при наличии только одного элемента в исходных данных нам негде искать зависимости. И модуль Self-Attention становится избыточным.
Следующим мы создаем модуль кросс-внимания, в котором и анализируются зависимости между элементами двух источников данных.
CNeuronRelativeCrossAttention *cross = new CNeuronRelativeCrossAttention(); if(!cross || !cross.Init(0, lay_count, OpenCL, window, window_key, units_count, heads, units_kv, window_kv, optimization, iBatch) || !cLayers.Add(cross)) { delete cross; return false; } lay_count++;
А завершает каждый слой декодера блок FeedForward, в качестве которого мы используем сверточный блок с обратной связью.
CResidualConv *ffn = new CResidualConv(); if(!ffn || !ffn.Init(0, lay_count, OpenCL, window, window, units_count, optimization, iBatch) || !cLayers.Add(ffn)) { delete ffn; return false; } lay_count++; }
После чего, переходим к следующей итерации цикла и созданию нового слоя декодера.
Здесь стоит отметить, что аналогично архитектуре декодера Transformer на выходе сверточного блока с обратной связью осуществляется нормализация данных. Тем не менее, нам может потребоваться ограничение пространства действий Актера в заданном диапазоне, которое обычно вводится функцией активации. Поэтому, после создания необходимого количества слоев декодера, мы добавим еще один сверточный слой с указанием необходимой функции активации.
CNeuronConvSAMOCL *conv = new CNeuronConvSAMOCL(); if(!conv || !conv.Init(0, lay_count, OpenCL, window, window, window, units_count, 1, optimization, iBatch) || !cLayers.Add(conv)) { delete conv; return false; } SetActivationFunction(SIGMOID);
По аналогии с RL-агентом, мы указываем сигмовидную функцию активации по умолчанию. При этом остается возможность изменить её из внешней программы.
В завершении метода инициализации, мы осуществим подмену указателей на буфера интерфейсов и вернем логический результат выполнения операций вызывающей программе.
//--- if(!SetOutput(conv.getOutput(), true) || !SetGradient(conv.getGradient(), true)) return false; //--- return true; }
После завершения работы по инициализации объекта, мы переходим к построению алгоритмов прямого прохода, которые реализуем в методе feedForward.
bool CNeuronControlAgent::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!SecondInput) return false;
В параметрах метода мы получаем указатели на 2 объекта исходных данных. Основной поток исходных данных представлен в виде нейронного слоя, а дополнительные — передаются в буфере данных. И для удобства работы с обоими источниками данных, мы осуществим подмену буфера данных результатов специально созданного внутреннего слоя на объект, полученный в параметрах метода.
CNeuronBaseOCL *second = cLayers[0]; if(!second) return false; if(!second.SetOutput(SecondInput, true)) return false;
Затем мы транспонируем тензор второго источника данных, для представления мультимодального временного ряда в виде последовательности унитарных рядов.
second = cLayers[1]; if(!second || !second.FeedForward(cLayers[0])) return false;
И организуем цикл последовательного перебора оставшихся внутренних нейронных слоев с вызовом их методов прямого прохода и передачей им данных из обоих источников.
CNeuronBaseOCL *first = NeuronOCL; CNeuronBaseOCL *main = NULL; for(int i = 2; i < cLayers.Total(); i++) { main = cLayers[i]; if(!main || !main.FeedForward(first, second.getOutput())) return false; first = main; } //--- return true; }
После успешного выполнения всех итераций цикла, нам остается лишь вернуть логический результат выполнения операций вызывающей программе и завершить работу метода.
Как можно заметить, алгоритм метода прямого прохода довольно прост. И это достигается, благодаря использованию уже готовых блоков для конструирования более сложной архитектуры.
Однако есть некоторая сложность при построении метода распределения градиента ошибки, связанная с использованием второго источника данных. Дело в том, что по основной магистрали мы последовательно передаем данные от одного внутреннего слоя к другому. А вот второй источник данных — един для всех слоев декодера. Точнее, для всех модулей кросс-внимания. Соответственно и градиент ошибки на второй источник данных нам предстоит собрать со всех модулей кросс-внимания. Предлагаю посмотреть на решение данного вопроса в коде.
Алгоритм распределения градиента ошибки реализован в методе calcInputGradients. В параметрах данного метода мы получаем указатели на объекты двух потоков исходных данных и их градиентов ошибки. Наша задача — распределить градиент ошибки между источниками исходных данных, в соответствии с их влиянием на результат.
bool CNeuronControlAgent::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
В теле метода сразу проверяем актуальность полученных указателей. Ведь мы не сможем передать данные в несуществующие объекты.
Как и в случае прямого прохода, второй источник данных представлен в виде буферов. И мы осуществим подмену указателей в соответствующем внутренним слое.
CNeuronBaseOCL *main = cLayers[0]; if(!main) return false; if(!main.SetGradient(SecondGradient, true)) return false; main.SetActivationFunction(SecondActivation); //--- CNeuronBaseOCL *second = cLayers[1]; if(!second) return false; second.SetActivationFunction(SecondActivation);
При этом, не забудем синхронизировать функции активации внутреннего слоя и последующего слоя транспонирования данных с функцией активации исходных данных. Это необходимо для корректной передачи градиента ошибки.
Далее роль второго источника данных будет выполнять наш внутренний слой транспонирования. И для удобства работы, мы сохраним указатели на его объекты интерфейсов в локальные переменные.
CBufferFloat *second_out = second.getOutput(); CBufferFloat *second_gr = second.getGradient(); CBufferFloat *temp = second.getPrevOutput(); if(!second_gr.Fill(0)) return false;
И обязательно очистим буфер градиентов ошибки от ранее накопленных данных.
После чего организуем цикл обратного перебора внутренних нейронных слоев. Но обратите внимание, что в теле цикла мы работаем только с объектами декодера.
Напомню, что первые два внутренних объекта используются для обслуживания второго источника данных.
for(int i = cLayers.Total() - 2; i >= 2; i--) { main = cLayers[i]; if(!main) return false;
В теле цикла мы изымаем из массива указатель на объект соответствующего нейронного слоя и сразу проверяем актуальность полученного указателя.
Далее следует вспомнить, что не все объекты декодера работают с двумя источниками исходных данных. Поэтому наш алгоритм разветвляется в зависимости от типа объекта, передающего градиент ошибки. В случае модуля кросс-внимания, мы сначала передаем градиент ошибки второго источника данных от текущего слоя в буфер временного хранения данных. А затем, суммируем полученные значения с ранее накопленными.
if(cLayers[i + 1].Type() == defNeuronRelativeCrossAttention) { if(!main.calcHiddenGradients(cLayers[i + 1], second_out, temp, SecondActivation) || !SumAndNormilize(temp, second_gr, second_gr, 1, false, 0, 0, 0, 1)) return false; }
В остальных случаях мы просто передаем градиент ошибки по основной магистрали. И переходим к следующей итерации цикла.
else { if(!main.calcHiddenGradients(cLayers[i + 1])) return false; } }
После выполнения всех итераций цикла, нам остается передать градиент ошибки на уровень исходных данных. Вначале работаем по основной магистрали и передадим градиент ошибки на уровень первого источника данных.
if(!NeuronOCL.calcHiddenGradients(main.AsObject(), second_out, temp, SecondActivation)) return false;
Но здесь следует вспомнить, что первым слоем декодера может быть как модуль Self-Attention, так и Cross-Attention. В последнем случае используется 2 источника исходных данных. Следовательно, нам необходимо проверить тип объекта, передающего градиент ошибки, и, в случае необходимости, добавить градиент ошибки второго источника данных к ранее накопленным значениям.
if(main.Type() == defNeuronRelativeCrossAttention) { if(!SumAndNormilize(temp, second_gr, second_gr, 1, false, 0, 0, 0, 1)) return false; }
И теперь мы передаем весь накопленный градиент по второй магистрали данных на уровень соответствующего источника.
main = cLayers[0]; if(!main.calcHiddenGradients(second.AsObject())) return false; //--- return true; }
После чего завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
Алгоритм метода обновления параметров модели updateInputWeights довольно прост. Мы лишь в цикле вызываем одноименные методы внутренних объектов, которые содержат обучаемые параметры. И мы не будем сейчас останавливаться на детальном его рассмотрении. Но помните, что в построенной архитектуре объекта мы использовали объекты с SAM-оптимизацией параметров. Поэтому перебор внутренних объектов должен осуществляться в обратном порядке.
На этом мы завершаем рассмотрение алгоритмов построения методов агента-контролера. А с полным кодом нового класса и всех его методов вы можете самостоятельно ознакомиться во вложении.
Сегодня мы славно потрудились, но наша работа еще не закончена. Мы лишь сделаем небольшой перерыв и в следующей статье доведем её до логического завершения.
Заключение
Мы познакомились с инновационным подходом к управлению инвестиционными портфелями в условиях нестабильных финансовых рынков — мультиагентной адаптивной структурой MASA. Предложенный фреймворк успешно сочетает преимущества RL-алгоритмов для оптимизации доходности и адаптивных оптимизационных методов для минимизации рисков, а также включает модуль наблюдения за рынком для анализа текущих тенденций.
В практической части мы реализовали каждый из предложенных агентов средствами MQL5 в виде отдельных модулей. И в следующей статье мы объединим их в целостную структуру, а также оценим эффективность реализованных решений на реальных исторических данных.
Ссылки
- Developing A Multi-Agent and Self-Adaptive Framework with Deep Reinforcement Learning for Dynamic Portfolio Risk Management
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования