Нейросети в трейдинге: Ансамбль агентов с использованием механизмов внимания (MASAAT)

Введение
Управление портфелем финансовых инструментов — ключевой аспект инвестиционных решений, целью которого является повышение доходности при минимизации рисков через динамическое распределение капитала между активами. Высокая волатильность финансовых рынков, где цены на активы зависят от множества факторов, затрудняет управление оптимальным портфелем, соответствующим двум противоречивым целям: максимизация прибыли и минимизация рисков. Традиционные финансовые модели, разработанные с учетом различных инвестиционных принципов, часто оказываются эффективными только на одном рынке и могут терпеть неудачу в сложных условиях динамических рынков.
В последнее время акцент смещается на применение методов машинного обучения для анализа нестационарных ценовых рядов. Среди них выделяются стратегии глубокого обучения и обучения с подкреплением, которые показали значительные успехи в вычислительных финансах. Однако, ценовые данные на финансовых рынках часто представляют собой шумные временные ряды, в которых сложно выделить информацию, указывающую на будущие тенденции.
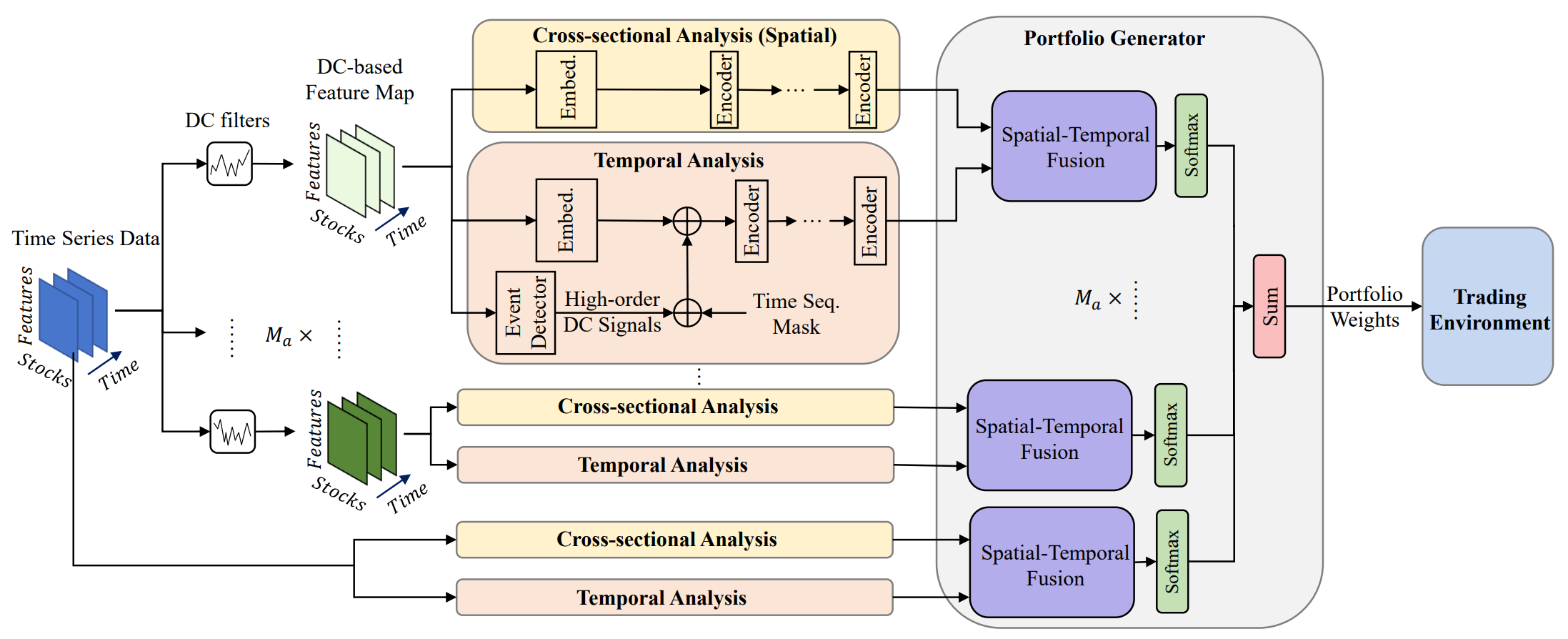
Один из вариантов решения указанных проблем представлен в работе "Developing an attention-based ensemble learning framework for financial portfolio optimisation". Её авторы предложили инновационную адаптивную торговую структуру с интегрированными механизмами внимания и анализа временных рядов (Multi-Agent and Self-Adaptive portfolio optimisation framework integrated with Attention mechanisms and Time series — MASAAT). В рамках представленного фреймворка создается множество агентов для наблюдения и анализа направленных изменений цен активов на различных уровнях детализации, с целью тщательного пересмотра портфелей для балансировки общей доходности и инвестиционных рисков на высоковолатильных финансовых рынках.
С помощью фильтров направленного движения, использующих различные пороговые значения для фиксации значительных изменений цен, агенты сначала извлекают характеристики тенденций из обычных временных ценовых рядов, стараясь быть в курсе переходов состояний рынка под разными точками зрения. Этот подход предоставляет новый способ генерации токенов в последовательности, так что модуль поперечного анализа на основе внимания (CSA) и модуль временного анализа (TA) агентов, созданных в рамках предлагаемой структуры, могут эффективно фиксировать корреляции между активами и зависимости между временными точками. В частности, при реконструкции карт признаков, токен последовательностей в модуле CSA основан на характеристиках отдельных активов, нацеленных на оптимизацию встраивания оценок внимания между активами, в то время как токен последовательностей в модуле TA основан на особенностях отдельных временных точек, пытаясь выделить релевантность между текущими и предыдущими временными точками.
Кроме того, информация о зависимостях активов и временных точек объединяется в пространственно-временном блоке внимания. Благодаря четкому разделению функционала между модулями CSA и TA, для непрерывного анализа тенденций активов агенты получают больше информации для предложения портфелей с учетом их конкретных точек зрения. В конечном счете, предоставление предложенных портфелей различными агентами объединяется в новый ансамблевый портфель для быстрого реагирования на текущие рыночные условия. Даже если какой-либо отдельный агент не в состоянии оценить рыночные тенденции и генерирует предвзятые предложения, предлагаемая структура MASAAT, интегрированная с несколькими агентами, все равно может адаптивно скорректировать окончательный портфель для уменьшения негативных последствий.
Алгоритм MASAAT
Фреймворк MASAAT применяет несколько фильтров выявления направленного движения в терминах различных пороговых значений для захвата значительных изменений цен активов из многомасштабных рецептивных полей для анализа возможного влияния на будущие движения цен. В частности, рецептивные поля представляют различные уровни колебаний цен на активы, что дает агентам возможность интуитивно воспринимать динамические состояния рынка с помощью различных фильтров. Кроме того, путем реконструкции активно-ориентированных функций направленного движения в модуле CSA и ориентированных на временные точки тенденций в модуле TA в виде токенов последовательностей, мультиагентная схема MASAAT может одновременно собирать пространственную и временную информацию в различных степенях изменения цен. Это помогает определить направление и масштаб будущих трендов. Аналогичным образом, исходные данные ценовых рядов будут непосредственно преобразованы в ценовые характеристики, ориентированные на активы и временные точки, с последующим извлечением перекрестной и временной информации из модулей CSA и TA.
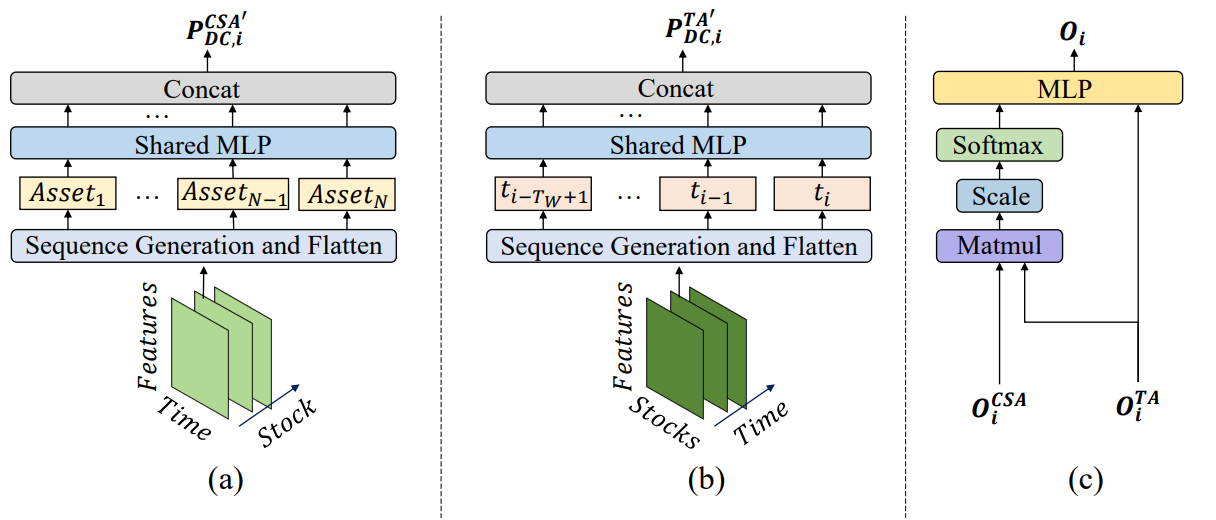
Стоит отметить, что модули CSA и TA основаны на энкодерах с механизмами Self-Attention, в которых оценки внимания рассчитываются по глобальной последовательности на всех токенах таким образом, что измерение сходства всех активов может быть справедливо вычислено, в то время как нейронная сеть на основе свертки очень чувствительна к взаимному положению активов в картах признаков и фокусируется на локальных областях в соответствии с размером ядра свертки. С другой стороны, благодаря оценкам внимания, указывающим на схожесть токенов, торговые сигналы, генерируемые предлагаемым фреймворком, могут быть более объяснимыми. Впоследствии, используя механизм внимания в пространственно-временном блоке для построения отображения между последовательностью активов и последовательностью исторических временных точек, торговые агенты генерируют эмбединги, представляющие оценки внимания каждого актива к каждой временной точке в пределах данного окна наблюдения, а затем предлагают свои варианты инвестиционных портфелей. Генератор портфелей обобщает все предложения от различных агентов для создания нового пересмотренного портфеля для адаптации к текущей финансовой среде.
Пусть N — количество активов в портфеле, M — количество признаков наблюдения с финансовых рынков, а Ma — количество торговых агентов. Для заданной глубины анализируемой истории агент в первую очередь наблюдает за ценовыми особенностями 𝐏 ∈ RN×M×Tw в течении периода наблюдения Tw. Затем функции на основе тенденций 𝐏DC={𝐏DC,1, 𝐏DC,2,…,𝐏DC,𝐌a} ∈ RMa, 𝐏DC,i ∈ RN×M×Tw получаются с помощью фильтров направленного движения. Как уже упоминалось выше, метод 𝐏DC,i будет преобразован в 𝐏DC,i,CSA ∈ RN×MTw для модуля CSA и 𝐏DC,i,TA ∈ RTw×NM для модуля ТА с последующим анализом взаимозависимостей в энкодере Transformer. Аналогично и оригинальный ценовой ряд 𝐏 преобразуется в 𝐏CSA ∈ RN×MTw и 𝐏TA ∈ RTw×NM.
После анализа зависимостей между токенами в предоставленной последовательности, модули CSA и TA возвращают эмбединги ориентированные на активы 𝐎CSA ∈ RN×D и временные точки 𝐎TA ∈ RTw×D, где D — это размер вектора одного эмбединга. Впоследствии эти эмбединги объединяются для создания нового портфеля, а затем дополнительно интегрируются с результатами работы других агентов, для получения конечного вектора зависимостей W𝐭 и корректировки портфеля.
После выполнения торговых операций, вознаграждение rt будет собрано и сохранено в буфер воспроизведения опыта Ď, вместе с W𝐭, 𝐏 и 𝐏DC. Кроме того, политика Актера π будет итеративно обновляться по мере изучения буфера воспроизведения опыта Ď с использованием метода градиента политики.
Поскольку более высокая прибыль обычно сопряжена с более высокими рисками, диверсификация инвестиционных рисков является важной, но сложной задачей, в которой торговые агенты должны присвоить соответствующие веса активам различной природы для хеджирования. Таким образом, постоянное изучение корреляций между активами поможет агентам лучше управлять рисками в высокотурбулентных условиях.
Исходные функции тенденций будут преобразованы для генерации соответствующих токенов последовательностей перед изучением корреляций между активами с помощью энкодеров, основанных на Self-Attention. Оптимизированный вектор внимания измеряет корреляцию между двумя различными активами, в которой два актива с похожими векторами внимания подразумевают более релевантные свойства.
В дополнение к исследованию корреляции между двумя активами, в фреймворке MASAAT предпринята попытка исследовать релевантность временных точек в пределах данного периода наблюдения для прогнозирования ценового тренда на разных уровнях. Временной анализ рассматривает временную точку как токен в последовательности, чтобы изучить корреляции между временными точками с помощью энкодеров Transformer. Соответственно, базовые трендовые модели двух временных точек считаются схожими, когда их векторы внимания близки.
После сбора информации из модулей CSA и TA агенты MASAAT объединяют оценки активов и временных точек с помощью механизма внимания, пытаясь получить оценки внимания каждого актива к каждой временной точке в течении периода наблюдения. Результат в виде предлагаемого портфеля каждого агента может быть представлен в виде:
![]()
где 𝐕i и bi — изучаемые параметры MLP.
Результаты каждого торгового агента, с точки зрения нескольких уровней детализации изменений цен, будут объединены для создания нового портфеля для реагирования на текущий финансовый рынок. По сравнению с портфелем, полученным от одного агента, множественные агенты MASAAT предоставляют несколько потенциальных портфелей в соответствии с наблюдениями за особенностями рынка с разных точек зрения. Это может расширить возможности системы для работы с различными финансовыми рынками, особенно когда рынок очень волатилен.
Авторская визуализация фреймворка MASAAT представлена ниже.
Реализация средствами MQL5
После рассмотрения теоретических аспектов предложенного фреймворка MASAAT, мы переходим к практической части нашей статьи, в которой рассмотрим вариант реализации собственного видения предложенных подходов средствами MQL5. Как вы могли заметить, MASAAT представляет собой комплексный фреймворк. И для четкого разделения функционала между отдельными блоками, мы создадим блочную структуру фреймворка в виде отдельных объектов, каждый их которых будет выполнять часть функционала MASAAT.
И начнем мы свою работу с построения механизма определения тенденций. Надо сказать, что с задачей определения локальных тенденций прекрасно справится слой кусочно-линейного представления временного ряда. Но есть один нюанс: построенный нами ранее объект может выполнить роль лишь одного агента. А для реализации фреймворка MASAAT нам необходимо дать пользователю гибкий функционал к созданию моделей с различным количеством агентов.
Мы, конечно, можем создать динамический массив с сохранением в нем указателей на несколько объектов кусочно-линейного представления анализируемого временного ряда с различными пороговыми значениями изменения признаков. Но в таком варианте приходим к их последовательной работе. А это не самый оптимальный вариант. Поэтому мы создадим новый объект, в котором организуем параллельную работу агентов выявления тенденций. Но сначала нам необходимо создать соответствующие кернелы на стороне OpenCL-программы.
Дополнение OpenCL-программы
При попытке модернизации существующих кернелов кусочно-линейного представления временных рядов мы сталкиваемся с необходимостью замены дискретного числа порогового значения изменения признака на вектор значений, содержащий пороговые уровни для каждого агента. Подобное изменение потребует не только модификации алгоритма кернела, но и приведет к полному пересмотру структуры объектов, работающих с ним. Поэтому мы приняли решение о создании новых кернелов прямого и обратного проходов, часть алгоритма которых будет заимствована из уже имеющихся.
Для организации прямого прохода был создан кернел PLRMultiAgents. В параметрах кернела мы получаем 4 указателя на буферы данных. Из них 2 буфера содержат исходные значения в виде анализируемого временного ряда и пороговых значений изменения признаков для каждого агента. В два других мы запишем результаты анализа и флаги указания наличия экстремума.
__kernel void PLRMultiAgents(__global const float *inputs, __global float *outputs, __global int *isttp, const int transpose, __global const float *min_step ) { const size_t i = get_global_id(0); const size_t lenth = get_global_size(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1); const size_t a = get_global_id(2); const size_t agents = get_global_size(2);
Данный кернел мы планируем выполнять в трехмерном пространстве задач. По первому измерению мы укажем размер анализируемой последовательности. Второе измерение определят количество унитарных рядов в мультимодальной последовательности. А последнее — соответствует количеству агентов. В теле кернела мы сразу идентифицируем текущий поток по всем измерения пространства задач. После чего определим смещение в буферах данных.
//--- constants const int shift_in = ((bool)transpose ? (i * variables + v) : (v * lenth + i)); const int step_in = ((bool)transpose ? variables : 1); const int shift_ag = a * lenth * variables;
Здесь стоит обратить внимание, что все агенты анализируют одну мультимодальную последовательность. Поэтому идентификатор агента оказывает влияние только на смещение в буферах результатов и значений порогового отклонения цены.
После небольшой подготовительной работы, мы переходим к поиску экстремумов. Каждый поток определяет наличие точки разворота тренда в позиции текущего элемента. Крайние точки анализируемого временного ряда автоматически получают статус точки разворота тренда, так как они априори являются крайними точками сегмента.
//--- look for ttp float value = IsNaNOrInf(inputs[shift_in], 0); bool bttp = false; if(i == 0 || i == lenth - 1) bttp = true;
В остальных случаях мы сначала ищем ближайшее отклонение значений анализируемого ряда на минимально-необходимое значение до текущего элемента в анализируемой унитарной последовательности. В процессе сохраняем минимальное и максимальное значения в проверенном интервале.
else { float prev = value; int prev_pos = i; float max_v = value; float max_pos = i; float min_v = value; float min_pos = i; while(fmax(fabs(prev - max_v), fabs(prev - min_v)) < min_step[a] && prev_pos > 0) { prev_pos--; prev = IsNaNOrInf(inputs[shift_in - (i - prev_pos) * step_in], 0); if(prev >= max_v && (prev - min_v) < min_step[a]) { max_v = prev; max_pos = prev_pos; } if(prev <= min_v && (max_v - prev) < min_step[a]) { min_v = prev; min_pos = prev_pos; } }
Затем аналогичным образом ищем ближайший последующий элемент с минимально-необходимым отклонением.
float next = value; int next_pos = i; while(fmax(fabs(next - max_v), fabs(next - min_v)) < min_step[a] && next_pos < (lenth - 1)) { next_pos++; next = IsNaNOrInf(inputs[shift_in + (next_pos - i) * step_in], 0); if(next > max_v && (next - min_v) < min_step[a]) { max_v = next; max_pos = next_pos; } if(next < min_v && (max_v - next) < min_step[a]) { min_v = next; min_pos = next_pos; } }
А затем проверяем наличие экстремумом на анализируемой позиции.
if( (value >= prev && value > next) || (value > prev && value == next) || (value <= prev && value < next) || (value < prev && value == next) ) if(max_pos == i || min_pos == i) bttp = true; }
Обратите внимание, что во время поиска элементов с минимально-необходимым отклонением, мы собрали некий коридор значений из нескольких элементов последовательности, которые могут формировать некоторое плато экстремума. Поэтому флаг точки разворота тренда элемент получает только в том случае, если является экстремумом в таком коридоре. При наличии нескольких элементов с одинаковыми значения флаг экстремума мы присваиваем первому из них.
Сохраним полученный флаг и очистим буфер результатов. При этом синхронизируем потоки рабочей группы.
isttp[shift_in + shift_ag] = (int)bttp; outputs[shift_in + shift_ag] = 0; barrier(CLK_LOCAL_MEM_FENCE);
Дальнейшие операции выполняются только потоками, в которых определена точка разворота тренда. Остальные просто не удовлетворяют поставленным условиям и практически завершают выполнение операций.
Мы сначала определим позицию текущего экстремума. Для этого посчитаем количество экстремумов по сохраненным флагам до анализируемой позиции и предусмотрительно сохраним в локальной переменной позицию предшествующего экстремума в буфере исходных данных.
//--- calc position int pos = -1; int prev_in = 0; int prev_ttp = 0; if(bttp) { pos = 0; for(int p = 0; p < i; p++) { int current_in = ((bool)transpose ? (p * variables + v) : (v * lenth + p)); if((bool)isttp[current_in + shift_ag]) { pos++; prev_ttp = p; prev_in = current_in; } } }
Затем определим параметры линейного приближения тенденции текущего сегмента.
//--- cacl tendency if(pos > 0 && pos < (lenth / 3)) { float sum_x = 0; float sum_y = 0; float sum_xy = 0; float sum_xx = 0; int dist = i - prev_ttp; for(int p = 0; p < dist; p++) { float x = (float)(p); float y = IsNaNOrInf(inputs[prev_in + p * step_in], 0); sum_x += x; sum_y += y; sum_xy += x * y; sum_xx += x * x; } float slope = IsNaNOrInf((dist * sum_xy - sum_x * sum_y) / (dist > 1 ? (dist * sum_xx - sum_x * sum_x) : 1), 0); float intercept = IsNaNOrInf((sum_y - slope * sum_x) / dist, 0);
После чего сохраним полученные значения в буфер результатов.
int shift_out = ((bool)transpose ? ((pos - 1) * 3 * variables + v) : (v * lenth + (pos - 1) * 3)) + shift_ag; outputs[shift_out] = slope; outputs[shift_out + step_in] = intercept; outputs[shift_out + 2 * step_in] = ((float)dist) / lenth; }
Напомню, что каждый полученный сегмент характеризуется 3 параметрами:
- slope — угол наклона линии тенденции;
- intercept — смещение линии тенденции в подпространстве исходных данных;
- dist — длина сегмента.
Сохранение длины последовательности в виде целочисленного значения, в данном случае, не лучший вариант. Ведь для эффективной работы модели желателен нормализованный формат представления данных. Поэтому мы переводим целочисленный размер сегмента в долю длины анализируемой унитарной последовательности. Для этого разделим количество элементов в сегменте на число элементов во всей последовательности унитарного временного ряда. А чтобы не попасть в "ловушку целочисленных операций", мы предварительно переведем количество элементов в сегменте из типа int в тип float.
Дополнительно, мы создадим отдельное ответвление операций для последнего сегмента. Дело в том, что на данном этапе мы не знаем количество сегментов, которые будут сформированы в тот или иной момент времени. Гипотетически, при значительных колебаниях элементов временного ряда и малом пороговом значении есть вероятность получить точки разворота тенденции в каждом элементе временного ряда. Такой поворот событий маловероятен, тем не менее, мы бы не хотели увеличения объема данных. Вместе с тем мы не желаем и потери данных.
Поэтому мы исходим из априорных знаний представления тайм-серий в MQL5 и понимания структуры анализируемых данных, — последние по времени данные находятся в начале нашего временного ряда. Им уделим больше внимания. Данные, находящиеся в конце анализируемой последовательности, имеют большую глубину истории и, вероятно, оказывают меньшее влияние на последующие события. Хотя такие зависимости мы не будем исключать.
Как следствие, для записи результатов работы каждого агента мы используем размер буфера данных, аналогичный размеру тензора исходных значений временного ряда. Это позволяет нам записать количество сегментов в 3 раза меньше длины последовательности (3 элемента для записи 1 сегмента). Мы ожидаем, что такого объема более чем достаточно. Тем не менее перестрахуемся и, при наличии большего количества сегментов, во избежание потери данных, объединяем данные последних сегментов в один.
else { if(pos == (lenth / 3)) { float sum_x = 0; float sum_y = 0; float sum_xy = 0; float sum_xx = 0; int dist = lenth - prev_ttp; for(int p = 0; p < dist; p++) { float x = (float)(p); float y = IsNaNOrInf(inputs[prev_in + p * step_in], 0); sum_x += x; sum_y += y; sum_xy += x * y; sum_xx += x * x; } float slope = IsNaNOrInf((dist * sum_xy - sum_x * sum_y) / (dist > 1 ? (dist * sum_xx - sum_x * sum_x) : 1),0); float intercept = IsNaNOrInf((sum_y - slope * sum_x) / dist, 0); int shift_out = ((bool)transpose ? ((pos - 1) * 3 * variables + v) : (v * lenth + (pos - 1) * 3)) + shift_ag; outputs[shift_out] = slope; outputs[shift_out + step_in] = intercept; outputs[shift_out + 2 * step_in] = IsNaNOrInf((float)dist / lenth, 0); } } }
В большинстве же случаев мы ожидаем наличия меньшего количества сегментов, и тогда последние элементы нашего буфера результатов будут заполнены нулевыми значениями.
Как можно заметить, в алгоритме прямого прохода мы не используем обучаемые параметры. Поэтому весь алгоритм обратного прохода сводится к распределению градиента ошибки, который мы реализовали в кернеле PLRMultiAgentsGradient.
Здесь следует вспомнить, что все агенты анализируют один временной ряд. Следовательно, на уровень исходных данных нам предстоит собрать градиент ошибки от всех агентов. Мы ожидаем использование относительно не большого количества агентов. Поэтому не стали сильно усложнять логику кернела. Вместо этого практически полностью перенесли ранее реализованный алгоритм кернла распределения градиента ошибки одного агента. Лишь добавили параметр указания количества агентов, а в теле кернела организовали цикл сбора градиентов ошибки от всех агентов. Я предлагаю данный кернел оставить для самостоятельного изучения. Полный код OpenCL-программы вы можете найти во вложении.
Объект механизма определения тенденций
После завершения работы на стороне OpenCL-программы мы переходим к нашей основной библиотеке и реализуем алгоритм мультиагентного выявления тенденций в объекте CNeuronPLRMultiAgentsOCL. Как вы могли заметить, мы практически дополняем объект кусочно-линейного представления временного ряда. Именно поэтому мы и выбрали его в качестве родительского класса. Структура нового объекта представлена ниже.
class CNeuronPLRMultiAgentsOCL : public CNeuronPLROCL { protected: int iAgents; CBufferFloat cMinDistance; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); //--- virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); public: CNeuronPLRMultiAgentsOCL(void) : iAgents(1) {}; ~CNeuronPLRMultiAgentsOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint units_count, bool transpose, vector<float> &min_distance, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPLRMultiAgentsOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual void SetOpenCL(COpenCLMy *obj); };
В новом классе мы объявляем константу количества используемых агентов (iAgents) и буфер хранения пороговых значений изменения признаков в анализируемом временном ряде (cMinDistance).
Использование статического объявления внутренних объектов позволяет нам оставить пустыми конструктор и деструктор класса. А инициализация всех объявленных и унаследованных объектов осуществляется в методе Init.
bool CNeuronPLRMultiAgentsOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window_in, uint units_count, bool transpose, vector<float> &min_distance, ENUM_OPTIMIZATION optimization_type, uint batch) { iAgents = (int)min_distance.Size(); if(iAgents <= 0) return false;
Обратите внимание, что в параметрах метода мы передаем только вектор пороговых значений. При этом не указываем количество используемых агентов. Их количество мы определяем по размеру получаемого вектора пороговых значений. Таким образом мы сокращаем количество внешних параметров метода и гарантируем соответствие значения параметра и длины буфера.
В теле метода после сохранения количества агентов во внутренней переменной и проверки корректности значения (для нормальной работы нужен хотя бы один агент) мы вызываем метод инициализации базового объекта, в теле которого осуществляется инициализация основных интерфейсов.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window_in * units_count * iAgents, optimization_type, batch)) return false;
Обратите внимание, что мы используем метод инициализации базового объекта, а не прямого родительского класса. Это связано с тем, что мы увеличиваем размер буфера результатов пропорционально числу агентов. Однако, теперь нам придется осуществить инициализацию и унаследованных объектов.
Вначале сохраним значения полученных параметров в унаследованные переменные.
iVariables = (int)window_in; iCount = (int)units_count; bTranspose = transpose;
А затем инициализируем буфер флагов наличия экстремумов.
icIsTTP = OpenCL.AddBuffer(sizeof(int) * Neurons(), CL_MEM_READ_WRITE); if(icIsTTP < 0) return false;
Обратите внимание, что значения буфера флагов экстремумов переопределяются после каждого прямого прохода. А размер данного буфера равен размеру результатов. Очевидно, что нам нет необходимости сохранять значения указанного буфера, поэтому мы создаем его только в памяти OpenCL-контекста. Здесь же мы сохраним только указатель на созданный буфер.
Далее мы инициализируем буфер пороговых значений.
if(!cMinDistance.AssignArray(min_distance) || !cMinDistance.BufferCreate(OpenCL)) return false; //--- return true; }
После чего завершим работу метода, передав логический результат выполнения операций вызывающей программе.
Кроме того, мы переопределили методы прямого и обратного проходов. Однако, в этих методах осуществляется лишь вызов вышепредставленных кернелов. Алгоритм методов не выделяется какими-либо сложностями, поэтому предлагаю его оставить для самостоятельного изучения.
На этом мы завершаем работу с объектом мультиагентного определения локальных тенденций CNeuronPLRMultiAgentsOCL. С полным кодом его методов вы можете ознакомиться во вложении.
Модуль поперечного внимания активов (CSA)
После получения разномасштабного кусочно-линейного представления анализируемого временного ряда, каждый агент берет свой масштаб и осуществляет его всесторонний анализ. Фреймворком MASAAT предусмотрен анализ временного ряда в двух проекциях: активов и временных точек.
За анализ временного ряда в фреймворке MASAAT отвечает модуль поперечного внимания активов, который мы реализуем в виде объекта CNeuronCrossSectionalAnalysis. Но прежде чем приступить к реализации, давайте немного обсудим алгоритм построения модуля CSA.
Как было сказано в теоретическом описании фреймворка MASAAT, в модуле CSA для анализа зависимостей между активами используется энкодер с механизмом Self-Attention. В нашей библиотеке довольно много реализаций подобных энкодеров. Однако есть нюанс параллельной работы нескольких агентов, когда каждый агент анализирует зависимости только в отдельно взятой области исходных данных. Но если хорошо подумать, то можно найти и такой.
К примеру, блок независимого анализа отдельных каналов CNeuronMVMHAttentionMLKV, который мы реализовали в рамках работы над фреймворком InjectTST. Неплохое решение. Но в чистом виде данный блок работает несколько в иной плоскости: он может проанализировать зависимости в различных масштабах одного актива, а нам необходимо найти зависимости между активами в рамках одного масштаба. Поэтому перед подачей исходных данных в блок независимого анализа отдельных каналов, нам необходимо транспонировать анализируемый трехмерный тензор по первым двум измерениям. К слову сказать, такой слой транспонирования в нашей библиотеке тоже есть (CNeuronTransposeRCDOCL).
С энкодером кажется определились. Однако, перед подачей данных в энкодер необходимо создать эмбединги траекторий каждого актива. Авторы фреймворка предлагают использовать для этого MLP, параметры которой едины для всех активов. Как и ранее в подобных случаях, мы будем использовать сверточные слои. Точнее, мы добавим только один сверточный слой с GELU в качестве функции активации. А роль второго слоя MLP генерации эмбедингов будет выполнять внутренний слой энкодера, ответственный за формирование сущностей Query, Key и Value.
Итак, мы определились со структурой нашего модуля CSA. В нем будем последовательно использовать слой транспонирования данных, сверточный слой эмбединга и блок независимого анализа каналов. Но давайте подумаем: может лучше поставить сначала сверточный слой, а за ним транспонировать данные? Результат операций не изменится. Вопрос в эффективности решения.
На вход модуля CSA мы подаем некое представление временного ряда ценового движения анализируемых активов. Следовательно, с ростом глубины анализируемой истории растет и объем исходных данных. А так как мы используем кусочно-линейное представление временного ряда, то ожидаем заполнение нулевыми значениями значительной части исходных данных. Это позволяет использовать эмбединги гораздо меньшего размера. А значит, установив слой транспонирования после сверточного слоя формирования эмбедингов мы можем значительно сократить размер транспонируемого тензора, что позволит сократить количество операций и повысит эффективность работы модели.
После определения основных ключевых аспектов реализации, мы можем перейти к работе по построению нового объекта CNeuronCrossSectionalAnalysis, структура которого представлена ниже.
class CNeuronCrossSectionalAnalysis : public CNeuronMVMHAttentionMLKV { protected: CNeuronConvOCL cEmbeding; CNeuronTransposeRCDOCL cTransposeRCD; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronCrossSectionalAnalysis(void) {}; ~CNeuronCrossSectionalAnalysis(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) const override { return defNeuronCrossSectionalAnalysis; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
Обратите внимание, что в качестве родительского класса мы используем блок независимого анализа каналов. Такое решение позволяет нам не включать данный блок в число внутренних объектов, а необходимый функционал выполнять унаследованными ресурсами. Оставшиеся объекты мы объявляем статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех объектов осуществляется в методе Init, который полностью унаследовал структуру параметров от одноименного метода родительского класса.
bool CNeuronCrossSectionalAnalysis::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint heads_kv, uint units_count, uint layers, uint layers_to_one_kv, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronMVMHAttentionMLKV::Init(numOutputs, myIndex, open_cl, window_key, window_key, heads, heads_kv, variables, layers, layers_to_one_kv, units_count, optimization_type, batch)) return false;
В теле метода мы, как обычно, сначала вызываем одноименный метод родительского класса. Но тут есть нюанс. В процессе реализации функционала модуля CSA мы планируем полноценно использовать все унаследованные методы. В рамках прямого прохода, на вход метода родительского класса планируется подача транспонированных эмбедингов исходных данных. Поэтому, при вызове метода инициализации родительского класса, мы изменяем размер окна исходных данных на размерность эмбединга и переставляем параметры длины анализируемой последовательности с количеством независимых переменных.
После успешного выполнения операций инициализации объектов родительского класса, мы последовательно инициализируем сверточный слой эмбединга и транспонирования данных.
if(!cEmbeding.Init(0, 0, OpenCL, window, window, window_key, units_count, variables, optimization, iBatch)) return false; cEmbeding.SetActivationFunction(GELU); if(!cTransposeRCD.Init(0,1,OpenCL,variables,units_count,window_key,optimization,iBatch)) return false;
После чего нам остается принудительно отключить функцию активации и завершить работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
SetActivationFunction(None); //--- return true; }
Далее мы реализуем алгоритм прямого прохода нашего модуля CSA в методе feedForward. Надо сказать, что здесь нас не ожидают какие-либо осложнения. В параметрах метода мы получаем указатель на объект исходных данных, который сразу передаем в одноименный метод сверточного слоя эмбедингов.
bool CNeuronCrossSectionalAnalysis::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cEmbeding.FeedForward(NeuronOCL)) return false; if(!cTransposeRCD.FeedForward(cEmbeding.AsObject())) return false; //--- return CNeuronMVMHAttentionMLKV::feedForward(cTransposeRCD.AsObject()); }
Результаты обработки исходных данных сверточным слоем мы транспонируем и передаем в одноименный метод родительского класса. После чего завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
Алгоритм методов обратного прохода так же прост. Поэтому я предлагаю их оставить для самостоятельного ознакомления. А мы завершаем работу над объектом CNeuronCrossSectionalAnalysis. С полным кодом всех его методов Вы можете самостоятельно ознакомиться во вложении.
Мы исчерпали объем статьи и наш рабочий день завершен. Однако работа ещё не окончена. Сделаем небольшой перерыв и доведем её до логического завершения в следующей статье.
Заключение
В данной статье мы познакомились с мультиагентной адаптивной структурой оптимизации инвестиционного портфеля с интегрированными механизмами внимания и анализа временных рядов MASAAT, которая эксплуатирует ансамбль торговых агентов для анализа ценовых данных с различных точек зрения. Что позволяет уменьшить предвзятость генерируемых торговых действий. Перекрестный анализ, основанный на механизмах внимания, в каждом агенте используется для фиксации корреляций между активами и временными точками в течение периода наблюдения с различных точек зрения, за которыми следует модуль пространственно-временного слияния, пытающийся объединить полученную информацию.
В практической части статьи начата реализация собственного видения предложенных подходов средствами MQL5. И в следующей статье мы продолжим начатую работу. А так же проверим эффективность построенного решения на реальных исторических данных.
Ссылки
- Developing An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования