
Возможности Мастера MQL5, которые вам нужно знать (Часть 49): Обучение с подкреплением и проксимальной оптимизацией политики
Введение
Мы продолжаем нашу серию статей о Мастере MQL5, в которой в последнее время мы чередуем простые паттерны из распространенных индикаторов и алгоритмы обучения с подкреплением. Рассмотрев индикаторные модели (Аллигатор Билла Вильямса) в предыдущей статье, теперь мы возвращаемся к обучению с подкреплением. На этот раз мы рассматриваем проксимальную оптимизацию политики (Proximal Policy Optimization, PPO). Сообщается, что этот алгоритм, впервые опубликованный 7 лет назад, является предпочтительным алгоритмом обучения с подкреплением для ChatGPT. В последнее время этот подход к обучению с подкреплением пользуется особой популярностью. Алгоритм PPO нацелен на оптимизацию политики (функции, определяющей действия субъекта) таким образом, чтобы повысить общую производительность за счет предотвращения резких изменений, которые могли бы сделать процесс обучения нестабильным.
Он не делает этого самостоятельно, а работает в тандеме с другими алгоритмами обучения с подкреплением, некоторые из которых мы рассмотрели в этой серии и которые в общем случае можно разделить на две категории. Алгоритмы, основанные на политике, и алгоритмы, основанные на значениях. Мы уже рассмотрели примеры каждого из них в этой серии статей. Алгоритмами на основе политики были Q-обучение иSARSA. Алгоритм временных различий является алгоритмом на основе значений. Так что же такое PPO?
Как упоминалось выше, "проблема", которую решает PPO, заключается в предотвращении слишком больших изменений политики во время обновлений. Основная идея заключается в том, что если не вмешиваться в управление частотой и масштабом обновлений, агент может: забыть то, чему он научился, принять ошибочное решение или работать хуже в окружающей среде. Таким образом, PPO гарантирует, что обновления будут небольшими, но значимыми. PPO работает, начиная с политики, которая заранее определена с ее параметрами. Здесь политика — это просто функции, которые определяют действия субъекта на основе вознаграждений и состояний среды.
При наличии политики взаимодействие агента с окружающей средой будет осуществляться с целью сбора данных. Такой "сбор данных" даст представление о паре "состояние-действие-вознаграждение", а также о вероятностях различных действий, предпринимаемых в рамках этой политики. Далее следует определить целевую функцию. Как упоминалось во введении выше, PPO занимается сдерживанием величины обновлений в обучении с подкреплением, и для достижения этой цели мы используем функцию "отсечения" (clipping). Эта функция определяется следующим уравнением:
![]()
где:
- r t (θ)=πθ(at∣st)/πθ old (at∣st) - отношение вероятностей между новой политикой (с параметрами θ) и старой политикой (с параметрами θ old).
- Â t — оценка преимущества в момент времени t, которая измеряет, насколько лучше действие по сравнению со средним действием в данном состоянии.
- ϵ — гиперпараметр (часто 0,1 или 0,2), который управляет диапазоном отсечения, ограничивая размер шага обновления политики.
Оценку преимущества можно определить несколькими способами, однако в нашей реализации мы используем следующий способ:
![]()
где:
- Q(s t ,a t ) - это значение Q (ожидаемая доходность) для действия a t в состоянии s t.
- V(s t ) - это функция значения для состояния s t, представляющего ожидаемую доходность, если мы будем следовать политике, начиная с этого состояния.
Этот метод количественной оценки функции преимущества подчеркивает зависимость или использование алгоритмов, основанных на политике, и алгоритмов, основанных на ценностях, о чем мы также упоминали выше. После того как мы определили нашу целевую функцию, мы приступаем к обновлению нашей политики. Обновление корректирует параметры политики с целью максимизации усеченной целевой функции. Это гарантирует, что изменения в политике будут постепенными и не будут соответствовать последним данным. Затем этот процесс повторяется посредством взаимодействия с окружающей средой с использованием обновленной политики, постоянного сбора данных и уточнения политики.
Почему PPO популярен? Его проще реализовать по сравнению с такими алгоритмами, как trust region policy optimization. Он обеспечивает стабильные обновления благодаря отсечению (формулу которого мы привели выше), очень эффективен в том смысле, что может хорошо работать с современными нейронными сетями и может справляться с масштабными задачами. Он также универсален, поскольку может хорошо работать как в непрерывном, так и в дискретном пространстве. Другой способ рассмотреть интуицию, лежащую в основе PPO, — представить, что человек учится играть в игру. Если вы будете постоянно резко менять свой подход к игре после каждой попытки, вы наверняка потеряете несколько хороших приемов и тактик, которые вы, возможно, усвоили в начале. PPO служит способом обеспечения того, чтобы в процессе обучения игре вы вносили только небольшие, постепенные и обдуманные изменения, избегая радикальных перемен, которые могут ухудшить вашу игру.
Во многих отношениях именно этот спор об исследовании и эксплуатации призван разрешить метод обучения с подкреплением. Можно утверждать, что на начальном этапе большинства процессов обучения необходимы радикальные изменения в подходе, которые больше способствуют исследованию, чем эксплуатации. В этих начальных ситуациях PPO, очевидно, не будет особо полезен. Тем не менее, поскольку можно утверждать, что в большинстве дисциплин и областей обучения пропоненты находятся скорее на этапе тонкой настройки, чем первоначального открытия, PPO пользуется большой популярностью. С этой целью PPO широко используется в робототехнике, например, для обучения роботов ходьбе или манипулированию объектами, а также в видеоиграх, где, например, ИИ обучается играть в сложные игры, такие как шахматы или Дота.
Роль PPO в обучении с подкреплением для трейдеров
PPO как алгоритм политики, работающий совместно с другими основными алгоритмами обучения с подкреплением, не имеет большого количества альтернатив. Из немногих доступных, которые стоит упомянуть, — это Deep Q-Networks, которые мы рассматривали в здесь, метод асинхронного преимущества актера-критика (Asynchronous Advantage Actor-Critic) и оптимизация политики доверенного региона (Trusted Region Policy Optimization). Рассмотрим, чем PPO отличается от каждой из этих реализаций. Если начать с DQN, то он использует Q-обучение и может сталкиваться с нестабильностью из-за крупных обновлений политики, особенно в условиях непрерывных действий. Под непрерывными пространствами действий подразумеваются циклы RL, где выбор актера не предопределен перечислимыми вариантами, такими как "купить-продать-держать", а задается числом с плавающей запятой или double в таких случаях использования, как определение идеального размера позиции для следующей сделки.
Однако PPO, возможно, более стабилен и прост в реализации, поскольку не требует отдельной целевой сети или даже воспроизведения опыта - концепции, которую мы рассмотрим в будущей статье. Благодаря упрощенному процессу обучения PPO работает напрямую как в дискретных, так и в непрерывных пространствах действий, тогда как DQN больше подходит для дискретных пространств.
Метод асинхронного преимущества актера-критика (A3C ), который нам еще предстоит рассмотреть в этой серии, имеет тенденцию использовать несколько циклов RL (или агентов) для обновления общей политики в разное время. Это обычно увеличивает сложность модели, в которой фигурируют несколько циклов RL. С другой стороны, PPO зависит от синхронных обновлений и ограничения политики для сохранения стабильного процесса обучения без чрезмерно агрессивных обновлений, которые могут создать риск краха политики.
Оптимизация политики доверенного региона (TRPO) также имеет ряд отличительных черт. Главным из них является то, что TRPO использует сложный процесс оптимизации для ограничения изменений политики, процесс, который часто требует решения ограниченной задачи оптимизации. С другой стороны, PPO упрощает процесс посредством отсечения, как упоминалось выше, где, ограничивая обновления, можно добиться вычислительной эффективности, сохраняя при этом аналогичный уровень стабильности и производительности.
Во введении стоит упомянуть еще несколько характеристик PPO, поэтому мы рассмотрим их, прежде чем перейти к основной части. PPO, как уже подчеркивалось выше, использует механизм отсечения для обновления политики с непосредственной целью — избежать слишком радикальных обновлений. Однако, возможно, непреднамеренным последствием этого является обеспечение баланса между эксплуатацией и исследованием — ключевого принципа обучения с подкреплением. Это может быть выгодно трейдерам, особенно работающим в условиях высокой волатильности, где чрезмерное использование прибыли может оказаться бесполезным занятием, и вместо этого более подходящей стратегией будет "держать порох сухим", чтобы получить долгосрочное представление о рынках.
Однако в случаях, когда требуется некоторое исследование, PPO может задействовать энтропийную регуляризацию, которая не позволит алгоритму стать слишком уверенным в конкретном действии, так что он будет меньше полагаться на отсечение обновлений политики. Регуляризацию энтропии мы рассмотрим в следующей статье.
PPO также эффективен при работе на больших пространствах. Это объясняется тем, что его структура "актер-критик" позволяет ему лучше прогнозировать значения в домене субъекта, даже если они непрерывны, как уже упоминалось выше; но, что еще важнее, снижение дисперсии обновлений политики благодаря использованию суррогатной функции потерь может привести к более последовательному поведению в сделках, даже в случаях, когда RL работает в условиях высокой волатильности, например, в условиях рынка Форекс.
PPO также хорошо масштабируется, поскольку ему не приходится хранить большие буферы воспроизведения опыта, которые часто требуют больших ресурсов. Это преимущество, вероятно, может подойти для таких вариантов использования, как высокочастотная торговля с большим количеством инструментов или даже для сложных настроек правил торговли.
PPO может быть эффективен при обучении на основе ограниченных данных. Такая эффективность выборки данных по сравнению с аналогами делает его чрезвычайно эффективным в условиях, когда получение рыночных данных может быть затруднено или требует больших затрат. Это очень болезненный сценарий для многих трейдеров, которым необходимо, например, тестировать свои стратегии на длительных исторических периодах в реальных условиях. Хотя тестер стратегий MetaTrader может генерировать тиковые данные, если реальные тики недоступны, часто предпочтительнее тестировать стратегию на реальных тиковых данных предполагаемого торгового брокера.
Для многих брокеров этот объем данных в реальном времени редко бывает достаточно доступным, и даже в тех случаях, когда доступны требуемые годы для тестового периода, проверка качества может выявить существенные пробелы в наборе данных. Это особая проблема для финансовых данных, поскольку, если сравнивать с другими областями, такими как разработка видеоигр или моделирование, генерация больших объемов данных и последующее обучение обычно не вызывают затруднений. Более того, ключевые сигналы часто зависят от редких событий, таких как рыночные обвалы или подъемы, и они не происходят достаточно часто, чтобы модели могли на них учиться.
PPO "обходит" эти проблемы, поскольку по своей сути является эффективным на основе выборок, будучи способным обучаться на ограниченных объемах данных. Необходимость больших объемов данных для разработки эффективной политики не является обязательным условием для PPO. Отчасти это стало возможным благодаря оценке преимуществ, которая позволяет эффективнее использовать имеющиеся рыночные данные меньшими порциями и в меньшем количестве эпизодов. Это может быть ключевым фактором при моделировании редких, но важных событий, поскольку PPO постепенно учится как на удачных, так и на неудачных сделках даже в условиях нехватки данных.
Для большинства торговых систем "вознаграждения", которые обычно количественно определяются как прибыль или убыток, могут быть существенно отсрочены от любого решения. Такая ситуация сопряжена с трудностями, поскольку становится проблематичным приписать заслугу конкретному действию, совершенному ранее. Например, при входе в длинную позицию в определенное время вознаграждение может быть получено только через несколько дней или даже недель, что явно бросает вызов алгоритмам обучения с подкреплением в плане изучения того, какие действия или состояния среды точно приводят к получению того или иного вознаграждения.
Этот сценарий еще больше ослабляется рыночным шумом и случайностью, которые так присущи многим ценовым движениям на рынке, что затрудняет определение того, стал ли положительный результат результатом хорошего решения или спонтанного движения рынка. Функция преимущества, уравнение которой было приведено выше, помогает PPO лучше оценить ожидаемую награду от конкретного действия, учитывая как значение (долгосрочное весовое значение V(st )), так и состояния-действия, объединяющие Q-значения (представленные как Q(st , at )) таким образом, что принимаемые решения лучше сбалансированы относительно обеих крайностей.
Настройка класса сигнала PPO в MQL5
Для реализации в MQL5 мы будем использовать класс Cql, который был нашим основным источником во всех статьях по обучению с подкреплением. Нам необходимо внести в него изменения, чтобы расширить его для поддержки PPO, и первым из них является введение структуры данных для обработки данных PPO. Необходимый код представлен ниже:
//+------------------------------------------------------------------+ //| PPO | //+------------------------------------------------------------------+ struct Sppo { matrix policy[]; matrix gradient[]; };
В приведенной выше структуре данных есть два массива, размер которых изменяется в зависимости от количества доступных действий для актера в цикле обучения с подкреплением. Каждая из матриц как для градиента, так и для политики имеет размер, равный числу состояний, в типичной квадратной форме. Таким образом, массив матрицы политики служит эквивалентом нашей Q-карты, поскольку он регистрирует веса и, следовательно, вероятность выбора каждого действия в каждом состоянии. Мы придерживаемся тех же простых состояний среды, которые мы использовали в этих сериях рыночных трендов: бычьих, медвежьих и боковых. Подводя итог, эти 3 состояния регистрируются как в краткосрочном, так и в более долгосрочном периоде.
При определении временных горизонтов большинство людей тяготеют к таймфреймам и, например, смотрят, является ли ценовое движение определенной ценной бумаги бычьим или медвежьим на дневном таймфрейме, а затем повторяют этот процесс на часовом таймфрейме, чтобы получить два набора показателей. Мы же просто использовали задержку в заданное количество ценовых баров, чтобы отделить краткосрочную перспективу от долгосрочной.
Это запаздывающее значение является настраиваемым входным параметром, который мы обозначаем как Signal_PPO_RL_Scale или m_scale в коде класса сигнала, а процесс сопоставления двух трендов ценового движения фиксируется в функции get output, которая будет представлена далее в этой статье. Однако на данный момент, если вернуться к PPO, реализация этого изменения в классе Cql в первую очередь подразумевает введение двух новых функций. Это функции set-policy и get-clipping. При определении следующего действия актера мы не вызываем ни одну из этих функций, по сути, они могли бы быть защищенными функциями в классе Cql.
Настройка политики вызывается в функциях в рамках и вне политики (set on policy function and the set-off policy function). Необходимый код:
//+------------------------------------------------------------------+ //| PPO policy update function | //+------------------------------------------------------------------+ void Cql::SetPolicy() { matrix _policies; _policies.Init(THIS.actions, Q_PPO.policy[acts[0]].Rows()*Q_PPO.policy[acts[0]].Cols()); _policies.Fill(0.0); for(int ii = 0; ii < int(Q_PPO.policy[acts[0]].Rows()); ii++) { for(int iii = 0; iii < int(Q_PPO.policy[acts[0]].Cols()); iii++) { for(int i = 0; i < THIS.actions; i++) { _policies[i][GetMarkov(ii, iii)] += Q_PPO.policy[i][ii][iii]; } } } vector _probabilities; _probabilities.Init(Q_PPO.policy[acts[0]].Rows()*Q_PPO.policy[acts[0]].Cols()); _probabilities.Fill(0.0); for(int ii = 0; ii < int(Q_PPO.policy[acts[0]].Rows()); ii++) { for(int iii = 0; iii < int(Q_PPO.policy[acts[0]].Cols()); iii++) { for(int i = 0; i < THIS.actions; i++) { _policies.Row(i).Activation(_probabilities, AF_SOFTMAX); double _old = _probabilities[states[1]]; double _new = _probabilities[states[0]]; double _advantage = Q_SA[i][ii][iii] - Q_V[ii][iii]; double _clip = GetClipping(_old, _new, _advantage); Q_PPO.gradient[i][ii][iii] = (_new - _old) * _clip; } } } for(int i = 0; i < THIS.actions; i++) { for(int ii = 0; ii < int(Q_PPO.policy[i].Rows()); ii++) { for(int iii = 0; iii < int(Q_PPO.policy[i].Cols()); iii++) { Q_PPO.policy[i][ii][iii] += THIS.alpha * Q_PPO.gradient[i][ii][iii]; } } } }
В рамках этой функции мы по сути охватываем 3 шага обновления значений политики для нашей структуры PPO, код которой мы привели выше. Эти значения политики определяют выбор следующего действия в функции action. Это старая функция, о которой мы упоминали в предыдущих статьях. Ее использование здесь актуально, поскольку мы внесли больше изменений в ее листинг:
//+------------------------------------------------------------------+ //| Choose an action using epsilon-greedy approach | //+------------------------------------------------------------------+ void Cql::Action(vector &E) { int _best_act = 0; if (double((rand() % SHORT_MAX) / SHORT_MAX) < THIS.epsilon) { // Explore: Choose random action _best_act = (rand() % THIS.actions); } else { // Exploit: Choose best action double _best_value = Q_SA[0][e_row[0]][e_col[0]]; for (int i = 1; i < THIS.actions; i++) { if (Q_SA[i][e_row[0]][e_col[0]] > _best_value) { _best_value = Q_SA[i][e_row[0]][e_col[0]]; _best_act = i; } } } //update last action act[1] = act[0]; act[0] = _best_act; //markov decision process e_row[1] = e_row[0]; e_col[1] = e_col[0]; LetMarkov(e_row[1], e_col[1], E); int _next_state = 0; for (int i = 0; i < int(markov.Cols()); i++) { if(markov[int(E[0])][i] > markov[int(E[0])][_next_state]) { _next_state = i; } } //printf(__FUNCSIG__+" next state is: %i, with best act as: %i ",_next_state,_best_act); int _next_row = 0, _next_col = 0; SetMarkov(_next_state, _next_row, _next_col); e_row[0] = _next_row; e_col[0] = _next_col; states[1] = states[0]; states[0] = GetMarkov(_next_row, _next_col); td_value = Q_V[_next_row][_next_col]; td_policies[1][0] = td_policies[0][0]; td_policies[1][1] = td_policies[0][1]; td_policies[1][2] = td_policies[0][2]; td_policies[0][0] = _next_row; td_policies[0][1] = td_value; td_policies[0][2] = _next_col; q_sa_act = 1; q_ppo_act = 1; for (int i = 0; i < THIS.actions; i++) { if(Q_SA[i][_next_row][_next_col] > Q_SA[q_sa_act][_next_row][_next_col]) { q_sa_act = i; } if(Q_PPO.policy[i][_next_row][_next_col] > Q_PPO.policy[q_ppo_act][_next_row][_next_col]) { q_ppo_act = i; } } //update last acts acts[1] = acts[0]; acts[0] = q_ppo_act; }
Возвращаясь к функции установки политики и ее трем шагам, первый из них количественно определяет общий вес политики для каждого действия по всем состояниям. По сути, это форма выравнивания матрицы состояний среды с помощью функции get-Markov, которая возвращает один индекс из двух значений индекса (которые представляют краткосрочные и долгосрочные закономерности). Получив эти кумулятивные веса для каждого действия в матрице, которую мы обозначили как _policies, мы можем приступить к расчету градиентов обновления весов наших политик.
Градиенты, которые хранятся в массиве матрицы градиентов, который мы ввели в структуру PPO выше, обновляют наши веса политики, подобно тому, как нейронная сеть обновляет свои веса. Однако получение значений градиента, как и в большинстве современных нейронных сетей, представляет собой довольно сложный процесс. Во-первых, нам необходимо определить вектор _probabilities, размер которого соответствует сглаженному индексу состояний среды. В данном случае это 3 х 3, что дает 9. Еще одно введение или изменение в класс Cql, которое мы сделали с помощью PPO, — это введение массива состояний размером 2. Этот массив просто регистрирует или буферизует последние два индекса состояния среды, которые были "испытаны" субъектом, и цель этой регистрации — помочь в обновлении градиентов.
Таким образом, с помощью матрицы _policies, где для каждого действия и сглаженного индекса состояния у нас есть кумулятивный вес политики, мы получаем распределение вероятностей по всем состояниям для каждого действия. Теперь, поскольку весовой коэффициент политики может быть отрицательным, нам необходимо нормализовать необработанные значения до диапазона 0–1, и один из самых простых способов сделать это — использовать встроенные функции активации с активацией SoftMax. Мы выполняем эти активации построчно, и после этого получаем вероятности для предыдущего состояния и текущего состояния среды. Опять же, для краткости здесь используются сглаженные индексы.
Другой важный показатель, который нам необходимо получить на этом этапе, — это преимущество. Напомним, как упоминалось выше, это преимущество помогает нам нормализовать или сбалансировать обновления веса нашей политики, чтобы учесть как краткосрочные веса, основанные на действиях состояния, так и долгосрочные веса, основанные на стоимости, - процесс, который делает выбор действий PPO более эффективным при сопряжении краткосрочного ценового действия с долгосрочными вознаграждениями, как уже утверждалось выше. Это преимущество достигается за счет вычитания матрицы весов Q-значений, которую мы ввели в статье об алгоритме временных различий, из матрицы пар "состояние-действие", которую мы ввели в нашей первой статье об обучении с подкреплением. Обе переименованы, но их работа и принципы остаются прежними.
Имея преимущество, мы затем вычисляем, на сколько нам нужно обрезать обновления. Как упоминалось во введении выше, PPO отличается от других алгоритмов управления политикой тем, как он смягчает свои обновления, гарантируя, что они не будут слишком радикальными и будут в основном постепенными для достижения долгосрочного успеха. Определение _clip выполняется функцией get-clipping, исходный код которой приведен ниже:
//+------------------------------------------------------------------+ //| Helper function to compute the clipped PPO objective | //+------------------------------------------------------------------+ double Cql::GetClipping(double OldProbability, double NewProbability, double Advantage) { double _ratio = NewProbability / OldProbability; double _clipped_ratio = fmin(fmax(_ratio, 1 - THIS.epsilon), 1 + THIS.epsilon); return fmin(_ratio * Advantage, _clipped_ratio * Advantage); }
Код в этой функции очень короткий, и старая вероятность не должна быть равна нулю; в противном случае для проверки к знаменателю можно добавить значение эпсилон. Получив _clip, который по сути является нормализованной дробью, мы умножаем его на разницу между двумя вероятностями. Здесь следует отметить, что преимущество, а также произведение между обрезкой и разницей вероятностей могут быть положительными или отрицательными. Это подразумевает, что градиенты обновления также могут быть знаковыми, то есть отрицательными или положительными.
Это приводит к фактическому обновлению весовых коэффициентов политики, что, как упоминалось выше, очень похоже на обновление весовых коэффициентов нейронной сети, и они также, основываясь на градиентах, указанных выше, могут быть отрицательными или положительными. Подписание весовых коэффициентов политики PPO является причиной того, что нам необходимо активировать с помощью SoftMax суммы весов каждого действия при расчете распределений вероятностей, выделенных на втором этапе установления политики. После обновления весовых коэффициентов политики они используются следующим образом в измененной функции действия, обновленный список которой был представлен выше.
Корректировка старой функции Action очень мала, поскольку мы просто проверяем величину веса политики, где выбирается действие с наибольшим весом, следуя нашему режиму обновления PPO, описанному выше. Учитывая следующее действие, мы теперь можем получить его с помощью функции get output, которая также, как уже было сказано выше, определяет матрицы состояния среды. Ее листинг приведен ниже.
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CSignalPPO::GetOutput(Cql *QL, int RewardSign) { vector _in, _in_row, _in_row_old, _in_col, _in_col_old; if ( _in_row.Init(m_scale) && _in_row.CopyRates(m_symbol.Name(), m_period, 8, 0, m_scale) && _in_row.Size() == m_scale && _in_row_old.Init(m_scale) && _in_row_old.CopyRates(m_symbol.Name(), m_period, 8, 1, m_scale) && _in_row_old.Size() == m_scale && _in_col.Init(m_scale) && _in_col.CopyRates(m_symbol.Name(), m_period, 8, 0, m_scale) && _in_col.Size() == m_scale && _in_col_old.Init(m_scale) && _in_col_old.CopyRates(m_symbol.Name(), m_period, 8, m_scale, m_scale) && _in_col_old.Size() == m_scale ) { _in_row -= _in_row_old; _in_col -= _in_col_old; vector _in_e; _in_e.Init(m_scale); QL.Environment(_in_row, _in_col, _in_e); int _row = 0, _col = 0; QL.SetMarkov(int(_in_e[m_scale - 1]), _row, _col); double _reward_float = RewardSign*_in_row[m_scale - 1]; double _reward_max = RewardSign*_in_row.Max(); double _reward_min = RewardSign*_in_row.Min(); double _reward = QL.GetReward(_reward_max, _reward_min, _reward_float, RewardSign); if(m_policy) { QL.SetOnPolicy(_reward, _in_e); } else if(!m_policy) { QL.SetOffPolicy(_reward, _in_e); } } }
Как и функция действия выше, она очень похожа на ту, что мы использовали в статьях по обучению с подкреплением, и изменения кажутся практически несущественными (за исключением некоторых важных упущений), учитывая, что ключевые функции, которые мы теперь вызываем с помощью PPO, скрыты, а именно: функция установки политики и функция обрезки. Очевидно, что это урезанная версия функции get output, которую мы использовали ранее. В качестве резюме к сказанному выше, m_scale можно рассматривать здесь как нашу задержку, которая отделяет краткосрочные рыночные тренды от долгосрочных при использовании единого таймфрейма. Читатель может рассмотреть альтернативы, использующие другие таймфреймы, но в этом случае альтернативный таймфрейм необходимо будет добавить в качестве входных данных. "Значительные" изменения в классе пользовательских сигналов произошли в функциях условий покупки и продажи, код которых представлен ниже:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalPPO::LongCondition(void) { int result = 0; GetOutput(RL_BUY, 1); if(RL_BUY.q_ppo_act==0) { result = 100; } return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalPPO::ShortCondition(void) { int result = 0; GetOutput(RL_SELL, -1); if(RL_SELL.q_ppo_act==2) { result = 100; } return(result); }
Этот список почти идентичен тому, что мы использовали, за исключением ссылки на q_ppo_act, а не на действие, выбранное исключительно из марковского процесса принятия решений.
Отчеты и анализ тестера стратегий
Соберем пользовательский класс сигналов в советник с помощью Мастера MQL5. Новички могут найти руководства здесь и здесь. Если извлечь некоторые благоприятные параметры из оптимизации пары GBPJPY за 2022 год на 4-часовом таймфрейме, то они дадут нам следующие результаты:
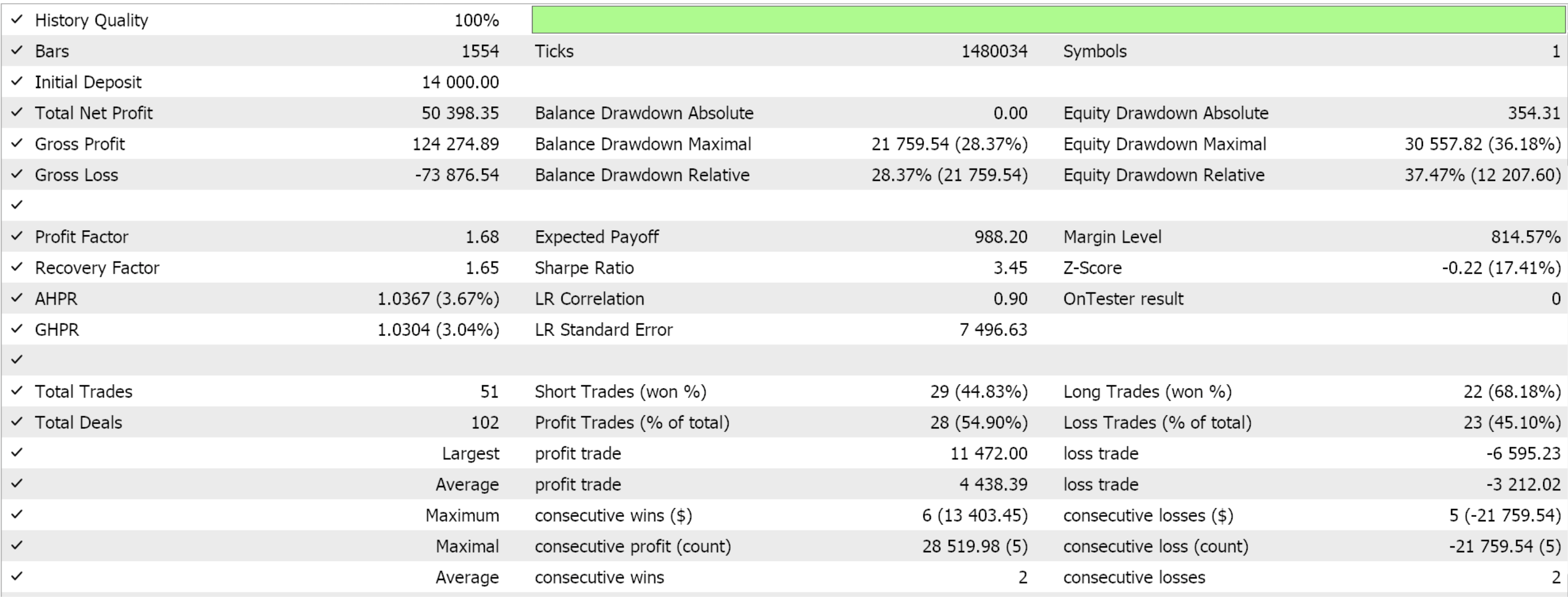

Как всегда, представленные здесь результаты призваны продемонстрировать потенциал пользовательского сигнала. Входные параметры, используемые для этого отчета, не проходили перекрестную проверку и, следовательно, не являются общими. Читателю предлагается адаптировать советник под свои ожидания.
Моя философия заключается в том, что любой советник, независимо от того, будет ли он использоваться полностью автоматически или для поддержки ручной торговой системы, никогда не может приносить более 50% прибыли относительно всей "торговой системы". Другая половина — это всегда человеческие эмоции. Поэтому, даже если вы покажете "Грааль" кому-то, кто не знаком с его тонкостями и принципами работы, он наверняка пойдет на поводу у своих эмоций и начнет сомневаться во многих его ключевых торговых решениях. Таким образом, представляя пользовательский сигнал без его "граалевых" настроек, читатель может не только понять, почему советник мог работать успешно в течение короткого оптимизированного периода, представленного в статьях, но и понять, почему он может работать по-разному в различные периоды тестирования, и эти два фрагмента информации должны помочь начать процесс выявления настроек, которые могут работать в течение более длительных периодов.
Я считаю, что процесс разработки трейдером собственных настроек или комбинирования различных пользовательских сигналов в работоспособный советник - это уже половина успеха.
Заключение
Мы рассмотрели очередной алгоритм обучения с подкреплением — проксимальную оптимизацию политики. Это очень популярный и эффективный метод благодаря его способности модерировать обновления политики во время эпизодов обучения с подкреплением.
Алгоритм PPO представляет собой новаторский подход к обучению с подкреплением, сочетающий стабильность политики и адаптивность, которые имеют решающее значение для разных практических задача, включая трейдинг. Его специализированная стратегия отсечения охватывает как дискретные, так и непрерывные действия и обеспечивает масштабируемую эффективность без интенсивной зависимости от ресурсов, что делает ее бесценной для сложных систем, сталкивающихся с широким спектром рыночных условий.
| Название файла | Описание |
|---|---|
| Cql.mqh | Исходный класс обучения с подкреплением |
| SignalWZ_49.mqh | Файл класса пользовательских сигналов |
| wz_49.mqh | Собранный в Мастере советник, заголовок которого отображает используемые файлы |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16448
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования