
Возможности Мастера MQL5, которые вам нужно знать (Часть 36): Q-обучение с цепями Маркова
Введение
Пользовательские классы сигналов для собранных в Мастере советников могут играть различные роли, которые стоит изучить. В статье мы рассмотрим, как алгоритм Q-обучения в паре с цепями Маркова может помочь усовершенствовать процесс обучения многослойной сети перцептрона. Q-обучение — один из нескольких (примерно 12) алгоритмов обучения с подкреплением, поэтому по сути это также взгляд на то, как этот предмет может быть реализован в виде пользовательского сигнала и протестирован в собранном с помощью мастера советнике.
Мы рассмотрим, что такое обучение с подкреплением, алгоритм Q-обучения и этапы его цикла, изучим, как цепи Маркова могут быть интегрированы в Q-обучение, а затем, как всегда, завершим отчетами тестера стратегий. Обучение с подкреплением можно использовать в качестве независимого генератора сигналов, поскольку его циклы ("эпизоды") по сути являются формой обучения, которая количественно оценивает результаты как "вознаграждения" для каждой из "сред", в которых задействован "актер". Термины в кавычках будут определены ниже. Однако мы не используем обучение с подкреплением как необработанный сигнал, а скорее полагаемся на его возможности для дальнейшего процесса обучения, дополняя им многослойный перцептрон (MLP).
Учитывая положение обучения с подкреплением как третьего стандарта в машинном обучении наряду с обучением с учителем и обучением без учителя, я подумал, что мы могли бы больше задействовать его в функции потерь многослойного перцептрона, поскольку в некотором смысле он действует как переход между контролем и отсутствием контроля, используя "вознаграждение критика" (CriticRewards) и "состояния среды" (environment-states) соответственно. Оба цитируемых термина вводятся в следующем разделе. Однако это означает, что большая часть прогнозирования по-прежнему остается за MLP, а обучение с подкреплением играет скорее подчиненную роль. Кроме того, использование цепей Маркова также является дополнением к обучению с подкреплением, поскольку выбор "актеров" из "Q-Map" часто достаточен для реализации алгоритма Q-обучения, однако мы включаем его здесь, чтобы получить представление о разнице, если таковая имеется, в результатах тестирования.
Обзор обучения с подкреплением
Обучение с подкреплением, которое мы представили выше как третью опору машинного обучения, является способом балансировки между Исследованием (Exploration) и Эксплуатацией (Exploitation) в процессе обучения. Это стало возможным благодаря циклическому подходу к оценке каждого раунда обучения, где раунды обучения называются эпизодами. Цикл представлен на схеме ниже:
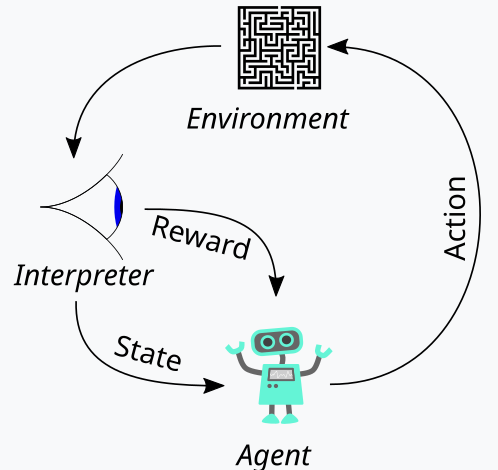
Итак, у нас есть последовательность шагов для процесса обучения с подкреплением. В начале находится "Агент", который действует от имени основной стороны, которой в нашем случае является MLP, чтобы выбрать идеальный курс действий при столкновении с обновленной картой, ядром или матрицей Q-обучения. Эта карта представляет собой запись всех возможных состояний среды, а также распределение вероятностей возможных действий, которые следует предпринять для каждого из доступных состояний.
Лучшим способом проиллюстрировать это будет рассмотрение реализации среды, которую мы выбрали для этой статьи. Как трейдеры, мы часто пытаемся определить рынки не только по их краткосрочным действиям, но и по их трендовым или долгосрочным характеристикам. Итак, если мы сосредоточимся на трех основных показателях, а именно на бычьем настрое, медвежьем настрое и флэте, то каждый из этих трех показателей может иметь индикаторы на более коротком и более длинном таймфреймах. Таким образом, по сути, наша "среда" представляет собой 9-индексное пространство (3 x 3 для краткосрочной и долгосрочной перспективы), где индекс 0 обозначает медвежий настрой в краткосрочной и долгосрочной перспективе, индекс 4 обозначает боковой тренд как в краткосрочной, так и в долгосрочной перспективе, индекс 8 обозначает бычий настрой на обоих временных горизонтах и т. д.
Выбор среды осуществляется с помощью одноименной функции, исходный код которой приведен ниже:
//+------------------------------------------------------------------+ // Indexing new Environment data to conform with states //+------------------------------------------------------------------+ void Cql::Environment(vector &E_Row, vector &E_Col, vector &E) { if(E_Row.Size() == E_Col.Size() && E_Col.Size() > 0) { E.Init(E_Row.Size()); E.Fill(0.0); for(int i = 0; i < int(E_Row.Size()); i++) { if(E_Row[i] > 0.0 && E_Col[i] > 0.0) { E[i] = 0.0; } else if(E_Row[i] > 0.0 && E_Col[i] == 0.0) { E[i] = 1.0; } else if(E_Row[i] > 0.0 && E_Col[i] < 0.0) { E[i] = 2.0; } else if(E_Row[i] == 0.0 && E_Col[i] > 0.0) { E[i] = 3.0; } else if(E_Row[i] == 0.0 && E_Col[i] == 0.0) { E[i] = 4.0; } else if(E_Row[i] == 0.0 && E_Col[i] < 0.0) { E[i] = 5.0; } else if(E_Row[i] < 0.0 && E_Col[i] > 0.0) { E[i] = 6.0; } else if(E_Row[i] < 0.0 && E_Col[i] == 0.0) { E[i] = 7.0; } else if(E_Row[i] < 0.0 && E_Col[i] < 0.0) { E[i] = 8.0; } } } }
Этот код применяется строго к нашей 9-индексной среде и не может использоваться в матрицах сред другого размера. При определении этой матрицы среды мы используем дополнительный входной параметр, называемый scale (масштаб). Эта шкала помогает соразмерять или соотносить наш долгосрочный горизонт с нашим краткосрочным окном. Значение по умолчанию — 5, что означает, что на одной оси матрицы среды мы отмечаем состояние как бычье, нейтральное или медвежье на основе изменений цены за период, который в 5 раз длиннее другого периода, значения которого "отложены" на другой оси. Я говорю "отложены", потому что эти две оси просто предоставляют координатные точки текущего состояния. Индексация от 0 до 8 — это просто преобразование этой матрицы в массив, но, как вы можете видеть из приложенного исходного кода, постоянное упоминание row (ряд) и col (столбец) просто указывает на возможные значения координат x и y из матрицы окружения, которые определяют текущее состояние.
Карта Q-обучения воспроизводит этот массив состояний среды, добавляя весовые коэффициенты для возможных действий, которые следует предпринять в любом из этих состояний среды. Поскольку в нашем случае мы рассматриваем 3 возможных действия, которые можно выполнить в каждом состоянии, а именно покупку, продажу или отсутствие действий, каждое состояние на карте Q-обучения имеет массив размером 3, который хранит оценку того, какое действие является наиболее подходящим. Чем выше оценка, тем лучше вариант. Другим важным субъектом в нашей диаграмме цикла выше является наблюдатель, которого мы будем называть "критиком". Именно критик в первую очередь обязан определять "вознаграждение" за действия актера. Что такое вознаграждение? Это зависит от того, для чего используется обучение с подкреплением, но для наших целей, исходя из возможных трех действий актера, мы используем в качестве вознаграждения сырую прибыль в виде тикового значения от изменения цены.
Таким образом, если это изменение цены отрицательное и нашим последним действием была продажа, то величина этого изменения действует как вознаграждение. То же самое касается случая, если изменение положительное после предыдущей покупки. Однако если последним действием была покупка, и мы имеем отрицательное изменение цены, то размер этого отрицательного значения действует как штраф, таким же образом, как изменения цены после продажи всегда умножаются на отрицательную единицу, то есть любой полученный отрицательное произведение будет действовать как штраф за наши действия в этом конкретном состоянии (которое является нашей средой или индексацией краткосрочного и долгосрочного движения рыночной цены).
Однако это значение вознаграждения необходимо нормализовать, и именно поэтому мы используем функцию CriticRreward, которая поддерживает его в диапазоне от 0,0 до 1,0. Все отрицательные значения находятся в диапазоне от 0,0 до 0,5, а положительные нормализованы до диапазона от 0,5 до 1,0. Необходимый исходный код приведен ниже:
//+------------------------------------------------------------------+ // Normalize reward via off-policy //+------------------------------------------------------------------+ double Cql::CriticReward(double MaxProfit, double MaxLoss, double Float) { double _reward = 0.0; if(MaxProfit >= Float && Float >= MaxLoss && MaxLoss < MaxProfit) { _reward = (Float - MaxLoss) / (MaxProfit - MaxLoss); } return(_reward); }
Обновление значения вознаграждения всегда будет происходить в процессе обучения, а не один раз в начале. Это означает, что нам постоянно необходимо передавать параметры, обновляющие значения максимального вознаграждения (reward-max), минимального вознаграждения (reward-min) и плавающего вознаграждения (reward-float), в функцию обратного распространения (back-propagation), чтобы их можно было включить в процесс. Чтобы добиться этого, начнем с изменения структуры обучения, которая используется для хранения переменных обучения, вызываемых при каждом запуске обратного распространения. Использование структуры на самом деле делает наш код легко модифицируемым, поскольку нам нужно только добавить необходимые нам дополнительные новые переменные к существующему списку переменных внутри структуры. При этом снижается вероятность ошибок, что резко контрастирует с необходимостью изменения списка входных параметров в функцию, которой требуются переменные в этой структуре. Такой подход делал бы код слишком громоздким. Измененная структура обучения теперь выглядит так:
//+------------------------------------------------------------------+ //| Learning Struct | //+------------------------------------------------------------------+ struct Slearning { Elearning type; int epochs; double rate; double initial_rate; double prior_rate; double min_rate; double decay_rate_a; double decay_rate_b; int decay_epoch_steps; double polynomial_power; double ql_reward_max; double ql_reward_min; double ql_reward_float; vector ql_e; Slearning() { type = LEARNING_FIXED; rate = 0.005; prior_rate = 0.1; epochs = 50; initial_rate = 0.1; min_rate = __EPSILON; decay_rate_a = 0.25; decay_rate_b = 0.75; decay_epoch_steps = 10; polynomial_power = 1.0; ql_reward_max = 0.0; ql_reward_min = 0.0; ql_reward_float = 0.0; ql_e.Init(1); ql_e.Fill(0.0); }; ~Slearning() {}; };
Кроме того, нам придется внести некоторые изменения в функцию обратного распространения в момент вызова функции потерь. Это связано с тем, что мы ввели новое или подчиненное перечисление для функций потерь, список которых выглядит следующим образом:
//+------------------------------------------------------------------+ //| Custom Loss-Function Enumerator | //+------------------------------------------------------------------+ enum Eloss { LOSS_TYPICAL = -1, LOSS_SVR = 1, LOSS_QL = 2 };
Одним из перечислений является LOSS_SVR, который занимается измерением потерь с использованием регрессии опорных векторов — подхода, который мы рассматривали в предыдущей статье. Два других — это потеря LOSS_TYPICAL, при выборе которого по умолчанию используется список встроенных функций потерь в MQL5, и LOSS_QL, где QL означает Q-обучение. При его выборе обучение с подкреплением информирует процесс обучения, предоставляя целевой вектор (или метку), с которым можно сравнивать прогнозы MLP. Выражения if в функции обратного распространения осуществляют проверку следующим образом:
//+------------------------------------------------------------------+ //| BACKWARD PROPAGATION OF THE MULTI-LAYER-PERCEPTRON. | //+------------------------------------------------------------------+ //| | //| -Extra Validation check of MLP architecture settings is performed| //| at run-time. | //| Chcecking of 'validation' parameter should ideally be performed | //| at class instance initialisation. | //| | //| -Run-time Validation of learning rate, decay rates and epoch | //| index is performed as these are optimisable inputs. | //+------------------------------------------------------------------+ void Cmlp::Backward(Slearning &Learning, int EpochIndex = 1) { ... if(THIS.loss_custom == LOSS_SVR) { _last_loss = SVR_Loss(); } else if(THIS.loss_custom == LOSS_QL) { double _reward = QL.CriticReward(Learning.ql_reward_max, Learning.ql_reward_min, Learning.ql_reward_float); if(QL.act == 0) { _reward *= -1.0; } else if(QL.act == 1) { _reward = -1.0 * fabs(_reward); } QL.CriticState(_reward, Learning.ql_e); _last_loss = output.LossGradient(QL.Q_Loss(), THIS.loss_typical); } ... }
Добавление этой пользовательской функции потерь не обязательно отменяет необходимость в старых функциях потерь, которые использовались на основе встроенных перечислений в MQL5. Мы просто переименовали его из loss в typical_loss, и если входное значение custom_loss равно LOSS_TYPICAL, то это значение необходимо будет указать.
После нормализации значения вознаграждения оно используется для обновления карты Q-обучения в функции CriticState. Обновление значений Q регулируется следующей формулой:
![]()
где:
- Q(s,a) - Q-значение для выполнения действия a в состоянии s. Это представляет собой ожидаемое будущее вознаграждение за пару "состояние-действие" (state-action).
- α - скорость обучения, значение от 0 до 1, которое контролирует, насколько новая информация перекрывает старую. Меньшее значение α означает, что агент обучается медленнее, тогда как большее значение α делает его более восприимчивым к недавнему опыту.
- r - последняя награда, полученная после выполнения действия a в состоянии s.
- γ - коэффициент дисконтирования, значение от 0 до 1, который дисконтирует будущие вознаграждения. Более высокий γ заставляет агента больше ценить долгосрочные вознаграждения, тогда как более низкий γ заставляет его больше фокусироваться на немедленных вознаграждениях.
- max a′ Q(s′,a′) - максимальное значение Q для следующего состояния s′ по всем возможным действиям a′. Это оценка агентом наилучшего возможного будущего вознаграждения, начиная со следующего состояния s′
Фактическое обновление карты Q-обучения можно реализовать на MQL5 следующим образом:
//+------------------------------------------------------------------+ // Update Q-value using off-policy (Q-learning formula) //+------------------------------------------------------------------+ void Cql::CriticState(double Reward, vector &E) { int _e_row_new = 0, _e_col_new = 0; SetMarkov(int(E[E.Size() - 1]), _e_row_new, _e_col_new); e_row[1] = e_row[0]; e_col[1] = e_col[0]; e_row[0] = _e_row_new; e_col[0] = _e_col_new; int _new_best_q = Action(); double _weighting = Q[e_row[0]][e_col[0]][_new_best_q]; if(THIS.use_markov) { LetMarkov(e_row[1], e_col[1], E); int _old_index = GetMarkov(e_row[1], e_col[1]); int _new_index = GetMarkov(e_row[0], e_col[0]); _weighting *= markov[_old_index][_new_index]; } Q[e_row[1]][e_col[1]][act] += THIS.alpha * (Reward + (THIS.gamma * _weighting) - Q[e_row[1]][e_col[1]][act]); }
При обновлении карты применяется правило обновления вне политики (off-policy rule), при котором для обновления старого действия используется лучшее действие следующего состояния. Это контрастирует с действием в рамках политики (on-policy action), где текущее действие используется в следующем состоянии для выполнения того же обновления. Это связано с тем, что для любого состояния, определяемого координатой строки и координатой столбца в матрице среды, существует стандартный массив возможных действий, которые может выполнить агент. При обновлениях вне политики, которые использует Q-обучение, выбирается наиболее взвешенное действие, однако при использовании алгоритмов, использующих обновления в соответствии с политикой, текущее действие сохраняется при выполнении обновления. Выбор лучшего действия осуществляется с помощью функции Action, код которой приведен ниже:
//+------------------------------------------------------------------+ // Choose an action using epsilon-greedy //+------------------------------------------------------------------+ int Cql::Action() { int _best_act = 0; if (double((rand() % SHORT_MAX) / SHORT_MAX) < THIS.epsilon) { // Explore: Choose random action _best_act = (rand() % THIS.actions); } else { // Exploit: Choose best action double _best_value = Q[e_row[0]][e_col[0]][0]; for (int i = 1; i < THIS.actions; i++) { if (Q[e_row[0]][e_col[0]][i] > _best_value) { _best_value = Q[e_row[0]][e_col[0]][i]; _best_act = i; } } } //update last action act = _best_act; return(_best_act); }
Обучение с подкреплением немного похоже на обучение с учителем в том смысле, что существует метрика вознаграждения, которая используется для корректировки и точной настройки веса действий в каждом состоянии среды. С другой стороны, оно похоже и на обучение без учителя использованием матрицы среды, значения координат которой (два значения для индекса строки и индекса столбца) служат входными данными для MLP, который ее использует. Таким образом, MLP выступает в качестве классификатора, который пытается определить правильное распределение вероятностей для трех применимых действий, когда в качестве входных данных представлены координаты состояния среды. Затем обучение происходит так же, как и в любом классификаторе MLP, но на этот раз мы стремимся минимизировать разницу между прогнозируемым распределением вероятностей MLP и распределением вероятностей в ядре Q-обучения в координатах карты Q-обучения, предоставленных в качестве входных данных для MLP.
Роль марковских переходов
Цепи Маркова — это вероятностные стохастические модели, которые используют матрицы перехода для отображения вероятностей перехода из одного состояния в другое при подаче временной последовательности этих состояний. Эти вероятностные модели по своей сути не имеют памяти, поскольку вероятность перехода в следующее состояние основана исключительно на текущем состоянии, а не на истории состояний до него. Эти переходы можно использовать для придания значимости различным состояниям, определенным в матрице среды.
Теперь матрица среды из нашего варианта использования в пользовательском сигнале учитывает только три состояния рынка: бычий, медвежий и флэт на краткосрочном горизонте и долгосрочном временном интервале, что делает ее матрицей 3 x 3, что, таким образом, подразумевает девять возможных состояний. Поскольку у нас есть девять возможных состояний, это означает, что наша матрица марковского перехода будет иметь размер 9 x 9, чтобы отобразить переходы из одного состояния среды в другое. Следовательно, необходимо иметь возможность преобразовать пару индексов в матрице среды в один индекс, который можно использовать в матрице марковского перехода. На самом деле нам понадобятся две функции: одна для преобразования пары индексов строки и столбца среды в один индекс для матрицы Маркова, а другая для реконструкции индексов строки и столбца матрицы среды при представлении индекса матрицы марковского перехода. Эти две функции называются GetMarkov и SetMarkov соответственно, а их исходный код приведен ниже:
//+------------------------------------------------------------------+ // Getting markov index from environment row & col //+------------------------------------------------------------------+ int Cql::GetMarkov(int Row, int Col) { return(Row + (THIS.environments * Col)); }
А также:
//+------------------------------------------------------------------+ // Getting environment row & col from markov index //+------------------------------------------------------------------+ void Cql::SetMarkov(int Index, int &Row, int &Col) { Col = int(floor(Index / THIS.environments)); Row = int(fmod(Index, THIS.environments)); }
Нам необходимо получить марковский эквивалентный индекс двух координат состояния среды в начале выполнения марковских вычислений, поскольку мы будем переходить из этого состояния. Получив этот индекс, мы извлекаем вероятности перехода в другие состояния по этому столбцу в матрице переходов, поскольку каждый из них служит весом. Как и ожидалось, все они в сумме дают единицу, и поскольку субъект уже выбрал следующее состояние из Q-карты, мы используем его вероятность в качестве числителя для знаменателя единицы, то есть только его вероятность используется в качестве веса для увеличения нового значения в Q-карте в процессе обучения. Исходный код, реализующий это, уже представлен выше в функции критического состояния.
Этот процесс обучения по сути обесценивает приращение обучения пропорционально его вероятности в матрице марковского перехода.
Кроме того, мы выполняем расчеты матрицы перехода всякий раз, когда регистрируется новый бар и временной ряд цен обновляется. Код для выполнения этих расчетов приведен ниже:
//+------------------------------------------------------------------+ // Function to update markov matrix //+------------------------------------------------------------------+ void Cql::LetMarkov(int OldRow, int OldCol, vector &E) // { matrix _transitions; // Count the transitions _transitions.Init(markov.Rows(), markov.Cols()); _transitions.Fill(0.0); vector _states; // Count the occurrences of each state _states.Init(markov.Rows()); _states.Fill(0.0); // Count transitions from state i to state ii for (int i = 0; i < int(E.Size()) - 1; i++) { int _old_state = int(E[i]); int _new_state = int(E[i + 1]); _transitions[_old_state][_new_state]++; _states[_old_state]++; } // Reset prior values to zero. markov.Fill(0.0); // Compute probabilities by normalizing transition counts for (int i = 0; i < int(markov.Rows()); i++) { for (int ii = 0; ii < int(markov.Cols()); ii++) { if (_states[i] > 0) { markov[i][ii] = double(_transitions[i][ii] / _states[i]); } else { markov[i][ii] = 0.0; // No transitions from this state } } } }
Поскольку матрица перехода не имеет памяти, наш код выше всегда начинается с новой объявленной матрицы, а переменная класса, которая содержит вероятности, также заполняется нулевыми значениями, чтобы отменить любую предыдущую историю. Подход к вычислению переходов прост, поскольку мы получаем количество последовательности каждого состояния в первом цикле for, а затем выполняем еще один цикл for, который делит накопленное количество, полученное для каждого перехода, на общее количество состояний, из которых совершаются переходы.
Реализация пользовательского класса сигналов
Как уже упоминалось, мы используем MLP, который является классификатором для выполнения основного прогнозирования, а обучение с подкреплением играет лишь подчиненную роль в качестве функции потерь. Обучение с подкреплением также можно оптимизировать или обучить для выдачи пригодных для использования торговых сигналов путем максимизации вознаграждений критиков. Однако это не то, чем мы здесь занимаемся. Его роль вторична по отношению к многослойному перцептрону, поскольку в обучении с учитиелм, как и в обучении без учителя, он используется для количественной оценки целевой функции.
Как и в предыдущих статьях, где мы использовали MLP, мы используем изменения цен в качестве источника входных данных. Напомним, матрица среды, используемая в этой статье, представляет собой матрицу 3 x 3, которая служит сеткой возможных состояний рынка при взвешивании на краткосрочном и долгосрочном таймфреймах. Каждая из осей для краткосрочного и долгосрочного таймфрейма имеет метрики или показания от бычьего к нейтральному и медвежьему, которые составляют сетку 3 x 3. Аналогичной этой матрице является матрица или карта Q-обучения, которая также имеет сетку 3 x 3 с добавлением массива возможных действий, открытых для субъекта, которые ведут подсчет пригодности каждого действия для каждого состояния. Именно этот массив пригодности служит меткой или целью обучения для нашего MLP.
Однако входными данными для MLP будут не сырые изменения цен, как это было в наших недавних статьях с MLP, а скорее координаты состояния среды для самого последнего или текущего изменения цен за краткосрочный и долгосрочный таймфреймы. Термин "таймфрейм" здесь используется исключительно для иллюстрации различных временных масштабов или горизонтов, в которых измеряются изменения цен. У нас нет двух отдельных таймфреймов в качестве входных данных для класса сигналов, которые управляют измерением этих изменений. Вместо этого у нас есть один входной целочисленный параметр m_scale, который является кратным того, насколько "длинный таймфрейм" больше короткого. Поскольку короткий таймфрейм использует изменения в пределах одного ценового бара, длинный таймфрейм получает показания об изменении за период, эквивалентный входному параметру scale. Обработка выполняется в функции GetOutput следующим образом:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CSignalQLM::GetOutput(int &Output) { m_learning.rate = m_learning_rate; for(int i = m_epochs; i >= 1; i--) { MLP.LearningType(m_learning, i); for(int ii = m_train_set; ii >= 0; ii--) { vector _in, _in_row, _in_row_old, _in_col, _in_col_old; if ( _in_row.Init(m_scale) && _in_row.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, m_scale) && _in_row.Size() == m_scale && _in_row_old.Init(m_scale) && _in_row_old.CopyRates(m_symbol.Name(), m_period, 8, ii + 1 + 1, m_scale) && _in_row_old.Size() == m_scale && _in_col.Init(m_scale) && _in_col.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, m_scale) && _in_col.Size() == m_scale && _in_col_old.Init(m_scale) && _in_col_old.CopyRates(m_symbol.Name(), m_period, 8, m_scale + ii + 1, m_scale) && _in_col_old.Size() == m_scale ) { _in_row -= _in_row_old; _in_col -= _in_col_old; vector _in_e; _in_e.Init(m_scale); MLP.QL.Environment(_in_row, _in_col, _in_e); int _row = 0, _col = 0; MLP.QL.SetMarkov(int(_in_e[m_scale - 1]), _row, _col); _in.Init(__MLP_INPUTS); _in[0] = _row; _in[1] = _col; MLP.Set(_in); MLP.Forward(); if(ii > 0) { vector _target, _target_data; if ( _target_data.Init(2) && _target_data.CopyRates(m_symbol.Name(), m_period, 8, ii, 2) && _target_data.Size() == 2 ) { _target.Init(__MLP_OUTPUTS); _target.Fill(0.0); double _type = _target_data[0] - _in_row[1]; int _index = (_type < 0.0 ? 0 : (_type > 0.0 ? 2 : 1)); _target[_index] = 1.0; MLP.Get(_target); m_learning.ql_e = _in_e; m_learning.ql_reward_float = _in_row[m_scale - 1]; m_learning.ql_reward_max = _in_row.Max(); m_learning.ql_reward_min = _in_row.Min(); if(i == m_epochs && ii == m_train_set) { MLP.QL.Action(); } MLP.Backward(m_learning, i); } } Output = (MLP.output.Max()==MLP.output[0]?0:(MLP.output.Max()==MLP.output[1]?1:2)); } } } }
Итак, как видно из исходного кода выше, нам нужно 4 вектора, чтобы получить показания координат для наших входных параметров MLP. После того, как они определены, с помощью функции Environment, которая преобразует два изменения цен в один индекс Маркова, и функции SetMarkov, которая предоставляет эти две координаты из индекса MARKOV, мы заполняем ими вектор in, который является нашими входными данными. Классификатор MLP имеет очень простую архитектуру 2-8-3, которая представляет собой 2 входа, скрытый слой размером 8 и 3 выхода, которые соответствуют трем возможным действиям, доступным актеру. Выходные данные MLP по сути представляют собой карту вероятностей, которая дает значения для открытия короткой позиции (индекс 0), бездействия (индекс 1) и открытия длинной позиции (индекс 2).
Обучение с подкреплением измеряет, насколько далеки эти результаты от аналогичных векторов, привязанных к каждому состоянию среды.
Результаты тестера стратегий
Итак, как всегда, мы проводим оптимизацию и тестовые прогоны с реальными тиковыми данными исключительно для того, чтобы продемонстрировать, как советник, собранный с помощью Мастера MQL5 с этим классом сигналов, может выполнять свои основные функции. Руководства по использованию прилагаемого кода с Мастером MQL5 можно найти здесь и здесь. В этих статьях не рассматривается большая часть кропотливой работы по подготовке собранного советника или торговой системы к работе на реальном счете. Она остается на усмотрение читателя. Мы проводим прогоны по паре GBPJPY на 2023 год на дневном таймфрейме. Мы ввели цепи Маркова в качестве альтернативы взвешиванию значений карты Q-обучения, и поэтому проводим два теста: один без взвешивания цепей Маркова и один с взвешиванием. Результаты:


И тогда результаты без марковского взвешивания будут такими:


Эти результаты тестирования не достигаются при наилучших настройках оптимизации, и при этих настройках не проводятся пошаговые тесты, поэтому их не надо рассматривать, как призыв к дополнительному использованию цепей Маркова с Q-обучением как таковым, хотя веские аргументы и более комплексный режим тестирования могут служить доводами в пользу их использования.
Заключение
В этой статье мы подчеркнули, что еще можно сделать с помощью Мастера MQL5, внедрив обучение с подкреплением — альтернативный вариант машинного обучения, помимо устоявшихся методов обучения с учителем и без учителя. Мы стремились использовать его при обучении классификатора MLP, используя для информирования и руководства процессом обучения, а не как генератор необработанных сигналов, что также возможно. При этом, сосредоточившись на алгоритме Q-обучения, мы использовали цепи Маркова, матрицу вероятностей перехода, которая может выступать в качестве веса для процесса обучения с подкреплением, и представили тестовые прогоны советника в двух сценариях: при обучении без цепей Маркова и при обучении с ними.
Я думаю, это было немного сложнее по сравнению с моими предыдущими статьями, поскольку мы ссылались на два класса для нашего пользовательского сигнала и использовали множество чувствительных входных параметров со значениями по умолчанию без какой-либо серьезной настройки. Также потребовалось введение множества новых терминов. Однако это лишь начало нашего изучения такой обширной и глубокой темы, как обучение с подкреплением, и поэтому я надеюсь, что в будущих статьях она не будет столь пугающей.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15743
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Реализация торговой стратегии Rapid-Fire с использованием индикаторов Parabolic SAR и простой скользящей средней (SMA) на MQL5
Реализация торговой стратегии Rapid-Fire с использованием индикаторов Parabolic SAR и простой скользящей средней (SMA) на MQL5
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования