
Возможности Мастера MQL5, которые вам нужно знать (Часть 41): Сети Deep-Q
Введение
Сети Deep-Q (Deep-Q-Networks, DQN) - еще один алгоритм обучения с подкреплением, помимо Q-обучения, рассмотренного в этой статье. В отличие от Q-обучения, алгоритм использует нейронные сети для прогнозирования значения q и следующего действия, которое должен выполнить агент. Он похож/связан с Q-обучением тем, что по-прежнему используется Q-таблица, в которой хранятся накопленные знания о действиях и состояниях из предыдущих "эпизодов". В Википедии алгоритм описывается на той же странице, что и Q-обучение и определяется как вариант Q-обучения.
Класс сигнала вместе с классом трейлинг-стопа и классом управления капиталом — это три основных модуля, которые необходимо определить при создании советника, собранного с помощью Мастера. Новички могут узнать о сборке советников в Мастере здесь и здесь. Исходный код, прикрепленный в конце этой статьи, предназначен для использования в соответствии с руководствами по сборке в Мастере, приведенными по этим ссылкам. Рассмотрим определение пользовательского класса сигналов для использования в советнике, собранном с помощью Мастера.
Однако это не единственный способ, которым мы можем исследовать DQN, поскольку можно также создать и протестировать реализации для пользовательского класса трейлинга или пользовательского класса управления капиталом. Мы сосредоточимся на классе сигналов, поскольку определение условий длинных и коротких позиций в этих советниках имеет решающее значение и во многих случаях наилучшим образом демонстрирует потенциал торговых настроек. В предыдущих статьях серии мы подробно останавливаемся на методах и различных настройках, которые можно использовать при разработке советников с помощью Мастера, поэтому я рекомендую новым читателям ознакомиться с прошлыми статьями, особенно если они хотят разнообразить свой подход. В этих статьях рассматриваются не только различные пользовательские сигналы, но и пользовательские реализации классов трейлинга и управления капиталом.
Как мы уже видели в статье о Q-обучении, настройка DQN реализована как поддержка функции потерь, поскольку мы строго рассматриваем обучение с подкреплением как третий способ обучения помимо обучения с учителем и без учителя. Как упоминалось в статье о Q-обучении, это не означает, что ее нельзя реализовать как независимую модель для использования в обучении, без подчиненного MLP. Этот альтернативный способ использования обучения с подкреплением будет рассмотрен в будущих статьях, где не будет подчиненного MLP, а прогнозы действий агента вместо этого будут информировать об условиях на покупку и продажу.
Обзор обучения с подкреплением
Для начала было бы неплохо сделать краткий обзор того, что такое обучение с подкреплением. Это альтернативный способ машинного обучения, в основе которого лежит изучение взаимодействия агента и среды. Агент — это субъект, принимающий решения, цель которого — изучить наилучшие действия для максимизации совокупного вознаграждения. Окружающая среда — это все, что находится "вне" агента, что выступает в качестве хоста для критика/наблюдателя и обеспечивает обратную связь агенту в форме новых состояний и вознаграждений (вознаграждений за точные прогнозы агента). Таким образом, цикл начинается с того, что агент наблюдает за текущим состоянием окружающей среды, делает прогнозы относительно изменений этого состояния, а затем выбирает соответствующее действие, подходящее для этого состояния.
Состояния являются отражением состояния или ситуации окружающей среды. Как только агент выбирает или выполняет действие, переход в состояниях среды происходит предварительно/одновременно, так что его действия оцениваются с точки зрения того, насколько они подходят для этой новой среды. Эта оценка количественно выражается как "вознаграждение". Для взвешивания процесса принятия решения агентом при прогнозировании следующего состояния использовалась матрица Марковской цепи без памяти, но фактические переходы определяются средой, которая в нашем случае отмечена перекрестной таблицей между направлением рынка и временным горизонтом. Действия, предпринимаемые агентом, хотя и могут быть непрерывными (или иметь бесконечный диапазон возможностей), часто являются дискретными, то есть они принимают предопределенный набор вариантов, которые в нашем случае были либо продажей, либо покупкой, либо бездействием. Однако в нашем случае этот список можно было бы расширить, например, чтобы он соответствовал формату рыночных ордеров, чтобы учитывались не только рыночные, но и отложенные ордера.
Аналогичным образом, наша метрика вознаграждений переоценивалась на каждом новом баре, поскольку убыток или прибыль от предыдущего действия или ордера могли быть "обновлены" для количественной оценки благоприятных отклонений к неблагоприятным отклонениям в виде соотношения или любой другой гибридной метрики. Эта метрика вознаграждения вместе с текущим состоянием и предыдущим выбранным действием используются для обновления Q-таблицы, источник для которой был предоставлен в функции Critic Source класса CQL. Как уже упоминалось выше, мы рассматриваем обучение с подкреплением исключительно как альтернативу обучению с учителем и без учителя, так как оно служит для строгой количественной оценки нашей функции потерь. Однако существуют случаи, когда обучение с подкреплением применяется вне этой "определенной" среды и используется как независимая модель для составления прогнозов, где действия агента применяются вне обучения. Эти сценарии здесь не рассматриваются, но могут быть рассмотрены в будущих статьях.
Введение в алгоритм Deep Q-Network
DQN основан на Q-обучении, первом алгоритме обучения с подкреплением, который мы рассмотрели, и его главной целью, которая по-прежнему остается целью DQN, является прогнозирование значений q. Как уже было сказано выше, это точки данных, которые классифицируют различные состояния среды и регистрируются в Q-таблице. Отличие от алгоритма Q-обучения заключается в использовании нейронных сетей для прогнозирования следующего значения q, а не в использовании Q-Map или таблицы, используемых алгоритмом Q-обучения, как было продемонстрировано в нашей первой статье об обучении с подкреплением. Кроме того, есть воспроизведение опыта и целевая сеть, описанные в разделах ниже. Таким образом, политика эпсилон-жадности (epsilon-greedy policy), которая ранее применялась в Q-Map, больше не применима к DQN, поскольку в игру вступают нейронные сети.
Таким образом, DQN сопоставляет будущие вознаграждения за каждое возможное действие во всех применимых состояниях с помощью нейронной сети. Это отображение состояний, которые трейдеры могут рассматривать как различные весовые коэффициенты для каждого возможного действия (купить-продать-держать) в различных рыночных условиях (бычий настрой-медвежий настрой-флэт), действительно обеспечивает весовые коэффициенты, и эти весовые коэффициенты определяют торговую позицию. DQN отлично справляются с обработкой сложных и многомерных сред, которые являются частью основных характеристик финансовых рынков. Финансовые рынки динамичны и нелинейны, на них влияют такие крайне изменчивые и независимые факторы, как изменения цен, макроэкономические показатели и настроения рынка.
Традиционное Q-обучение, как правило, сталкивается с этой проблемой, поскольку использует дискретные Q-таблицы с конечным и управляемым числом состояний, что контрастирует с DQN, который очень эффективен, учитывая использование нейронных сетей. DQN также хорошо подходят для улавливания нелинейных зависимостей на рынках по различным классам активов, которые также служат сигналами входа в определенные торговые стратегии, например, в стратегии кэрри-трейд с использованием йены. Кроме того, использование DQN обеспечивает лучшее обобщение, при котором сеть может лучше адаптироваться к новым данным и рыночным условиям, поскольку нейронные сети, как правило, более гибкие, чем q-таблицы. Это имеет решающее значение на финансовых рынках, где условия могут быстро меняться, и агенту приходится адаптироваться к незнакомым ситуациям. DQN также более устойчивы к рыночному шуму, чем традиционное Q-обучение. На финансовых рынках действия агентов часто имеют отложенное вознаграждение(например, удержание позиции, которая может принести прибыль только через несколько дней или недель). Использование уравнения Беллмана с коэффициентом дисконта (гамма) позволяет ему оценивать немедленные и долгосрочные выгоды, благодаря чему сеть учится балансировать между быстрой прибылью и долгосрочными выгодами, что имеет важное значение при принятии стратегических решений для финансовых портфелей.
Прогнозирование значений Q с помощью DQN
Мы используем DQN для нормализации функции потерь MLP, поскольку в этой статье, как уже упоминалось, мы рассматриваем DQN исключительно как альтернативный подход к обучению, а не как независимую модель, которую можно использовать для составления собственных прогнозов, как типичный MLP. Такое применение DQN в упрощенном варианте "обучения с подкреплением" означает, что мы в целом придерживаемся подхода, описанного в этой статье. Таким образом, это подразумевает, что у нас есть экземпляр MLP, который действует как агент, и который мы называем DQN_ONLINE в нашем интерфейсе класса сигнала, который вкратце описан ниже:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CSignalDQN : public CExpertSignal { protected: int m_actions; // LetMarkov possible actions int m_environments; // Environments, per matrix axis int m_train_set; // int m_epochs; // Epochs double m_learning_rate; // Alpha Elearning m_learning_type; double m_train_deposit; double m_train_criteria; double m_initial_weight; double m_initial_bias; int m_state_lag; int m_target_counts; int m_target_counter; Smlp m_mlp; Smlp m_dqn; Slearning m_learning; public: void CSignalDQN(void); void ~CSignalDQN(void); //--- methods of setting adjustable parameters ... ... protected: void GetOutput(int &Output); Cmlp *MLP,*DQN_ONLINE,*DQN_TARGET; };
Эта сеть принимает в качестве входных данных текущее состояние и выводит вектор или q-значения для каждого из возможных действий. Архитектура сети, которую можно корректировать или настраивать, следует соотношению 2-6-3, где 2 — размер входного слоя. Как указывалось ранее, значение 2 выбрано, поскольку мы имеем дело с парой индексов или координат. Одна координата измеряет тип тренда в краткосрочной перспективе, другая рассматривает тренд в долгосрочной.
Скрытому слою просто назначается размер 6, однако, как уже указывалось, этот размер и добавление дополнительных скрытых слоев можно настроить. Мы выбрали 6 из входного размера, умноженного на выходной размер. Итак, наш размер вывода равен 3, как и в статье о q-обучении, где он представляет собой количество возможных действий, предпринимаемых агентом. Эти действия — купить, продать или держать. Выходное значение, являющееся вектором вероятностей для выполнения каждого из этих действий, подразумевает, что DQN является сетью-классификатором. Выходное значение этой DQN с подкреплением служит целевым значением для родительской сети MLP. Получив эти выходные данные, мы можем обучить MLP. Однако нельзя упускать из виду и обучение DQN, которое происходит не так, как в других сетях. Вместо того чтобы работать с другим вездесущим набором данных состояний и q-значений, мы используем другую нейронную сеть, которую мы называем DQN_TARGET, чтобы предоставить целевые векторы для обучения сети DQN_ONLINE.
Роль целевой сети
Целевая сеть (target network), как и онлайн-сеть (DQN, которая обеспечивает цель MLP), также принимает состояние среды в качестве входных данных и выводит вектор q-значений для каждого возможного действия. Главное отличие от онлайн-сети заключается в том, что входные данные о состоянии среды относятся к состоянию, которое следует за текущим. Кроме того, поскольку это еще одна нейронная сеть, можно было бы ожидать, что она будет обучаться методом обратного распространения (backpropagation), но вместо этого с заданным интервалом она просто копирует онлайн-сеть. Целевая сеть обеспечивает более стабильные целевые значения при вычислении временной разницы, что снижает риски колебаний и расхождений во время обучения.
Без независимой целевой сети, материнского MLP и онлайн-сети целевые значения постоянно менялись бы в колеблющемся нестабильном поведении. Это связано с тем, что обе сети будут обновляться одновременно. При использовании целевой сети процесс обучения стабилизируется, поскольку оба алгоритма будут меньше расходиться/колебаться. Как упоминалось выше, целевая сеть не подвергается обратному распространению, как обычный MLP, а копирует онлайн-сеть через заданные интервалы. Обычно эти интервалы имеют размер около 10 000, а наш входной параметр для их модуляции обозначен как m_target_counts и по умолчанию ему присвоено значение всего 65! Это связано с тем, что мы проводим тестирование на дневном таймфрейме только в течение года, поэтому у нас есть 260 ценовых баров для тестирования. Это регулируемый параметр, поэтому при более длительном периоде тестирования или меньшем временном интервале 10 000 шагов вполне осуществимы. Расчет целевого значения q осуществляется по следующей формуле:
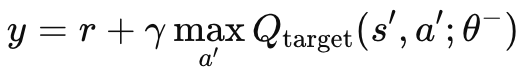
где:
- y - целевое значение Q, которое представляет собой предполагаемую доходность (будущее вознаграждение), начиная с текущего состояния s, совершая действие a и затем следуя оптимальной политике.
- r - немедленное вознаграждение, получаемое после совершения действия a в состоянии s.
- γ - коэффициент дисконтирования, определяющий важность будущих вознаграждений. Это значение от 0 до 1.
- max a′ Qtarget(s′,a′;θ−) - максимальное прогнозируемое значение Q для следующего состояния s′ по всем возможным действиям a′, оцененное целевой сетью с параметрами θ−.
- Qtarget(s′,a′;θ−) - Q-значение для следующей пары состояние-действие (s′,a′)(s', a')(s′,a′), предсказанное целевой сетью.
- θ− - параметры (веса) целевой сети, которые периодически обновляются на основе параметров основной сети.
Эта формула реализована в MQL5 с помощью критической целевой функции, которую мы добавляем к классу CQL. Этот класс мы уже использовали в нашей вводной статье по обучению с подкреплением. Функция указана ниже:
//+------------------------------------------------------------------+ // Critic Target for DQN //+------------------------------------------------------------------+ vector Cql::CriticTarget(vector &Rewards, vector &TargetOutput) { vector _target = Rewards + (THIS.gamma * TargetOutput); return(_target); }
Возникает проблема бутстреппинга. Как мы видели в предыдущей статье об обучении с подкреплением, в традиционном Q-обучении сеть обновляет значения q на основе своих собственных предсказаний, что может привести к каскаду ошибок (бутстреппингу), если предсказания неточны. Это связано с тем, что значения q для одного состояния зависят от значений q последующих состояний, что потенциально может привести к усилению ошибки.
Таким образом, роль целевой сети заключается в том, чтобы смягчить этот эффект, предоставив более медленно движущуюся цель. Поскольку параметры целевой сети обновляются реже (обычно каждые несколько десятков тысяч шагов), она изменяется более постепенно, чем онлайн-сеть. Это замедляет скорость распространения ошибок, тем самым решая проблему бутстреппинга.
В ситуациях, где мы имеем дело с нелинейной динамикой, например, в сложных условиях финансовых рынков или в любых других областях, например, в видеоиграх, отношения между состояниями и вознаграждениями, как правило, являются крайне нелинейными. Стабильность, обеспечиваемая целевой сетью, имеет решающее значение для эффективного обучения DQN в этих условиях. Без этой целевой сети онлайн-сеть (DQN) с большей вероятностью будет отклоняться при столкновении со сложными или быстро меняющимися средами из-за быстрых обновлений как значений q, так и целей.
Кроме того, целевую сеть можно улучшить, добавив расширение, которое часто называют "двойной DQN", которое устраняет смещение, вызванное переоценкой. Это реализуется путем использования как онлайн-сетей, так и целевых сетей по отдельности для выбора и оценки действий. Это разделение процессов выбора и оценки действий между онлайн-сетями и целевыми сетями. Онлайн-сеть используется для выбора действия, а целевая сеть его оценивает.
Воспроизведение опыта и его роль в обучении
Воспроизведение опыта (experience replay) — это метод буферизации, при котором агент DQN, обучающийся с подкреплением, сохраняет свой "опыт" состояния, действия, вознаграждения и следующего состояния в буфере воспроизведения (replay buffer). Затем этот опыт выбирается случайным образом во время обучения для обновления весов и смещений DQN агента. Этот подход, как и следовало ожидать, полезен для разрушения последовательной корреляции, возникающей при рассмотрении только последовательных точек данных, и, таким образом, может оказаться более подходящим для реальных сценариев, таких как финансовые рынки. На финансовых рынках последовательные точки данных, будь то цена, объем контрактов или волатильность, как правило, сильно коррелируют, поскольку на них влияют схожие рыночные условия и поведение участников. Обучение агента DQN на таких последовательно коррелированных данных, как правило, приводит к переобучению и отсутствию обобщения, поскольку агент DQN привыкает использовать определенные шаблоны, которые плохо обобщаются на различные рыночные условия.
Чтобы разорвать эти временные корреляции, DQN обычно обучается на мини-пакетах случайно выбранных точек данных опыта из буфера воспроизведения. Случайная выборка, в частности, помогает разрушить временные корреляции, в результате чего агент получает лучшее распределение опыта, которое лучше соответствует базовой динамике рынка. Помимо лучшего обобщения, процесс обучения в долгосрочной перспективе становится более стабильным и лучше сходится. Это связано с тем, что воспроизведение опыта снижает дисперсию обновлений в процессе обучения.
Без воспроизведения опыта обновления веса сети происходили бы всплесками последовательно полученных высококоррелированных выборок, которые прерывались бы совершенно другим обновлением из-за других условий среды, что, как правило, делало бы весь процесс обновления очень нестабильным, потенциально приводя к нестабильности в процессе обучения. Используя случайную выборку из разнообразного набора данных, агент DQN выполняет более плавные и стабильные обновления, улучшая сходимость к оптимальной политике.
Эффективное использование исторических данных — это то, что также обеспечивается методом воспроизведения опыта, поскольку агент многократно переучивается на основе опыта (благодаря случайному выбору), что особенно ценно на финансовых рынках, где получение больших объемов разнообразных и репрезентативных данных в любой конкретный момент времени является сложной задачей. По сути, это позволяет DQN извлекать уроки из редких или значимых событий, таких как обвалы или подъемы рынка, даже если в настоящее время они не происходят. Это делает агента более подготовленным к таким событиям, если они произойдут.
Воспроизведение опыта также усиливает исследовательский потенциал обучения с подкреплением, в отличие от простой эксплуатации. Это снижает вероятность "катастрофического забывания", когда агент многократно производит выборку из своего буфера воспроизведения, что позволяет ему закреплять знания о старых стратегиях и не позволяет им перезаписываться новым опытом; и, наконец, это допускает даже более специализированные случаи воспроизведения опыта, такие как приоритетное воспроизведение опыта, когда выборки данных с большими ошибками функции потерь получают приоритет с учетом их более высокого потенциала обучения, что делает обучение более эффективным и целенаправленным.
Мы упоминаем воспроизведение опыта в этой статье, поскольку это ключевой принцип DQN, однако мы продемонстрируем его возможности в MQL5 в следующих статьях, где DQN будет не только гибридной функцией потерь, но и основной моделью прогнозирования для нашего класса сигналов.
Временное принятие решений
Часто принимаемые решения, даже за пределами торговли, в таких областях, как робототехника или видеоигры, имеют отсроченные последствия для будущих результатов, которые не обязательно проявляются немедленно, но проявляются в течение более длительных временных горизонтов. Применительно к трейдингу можно вспомнить о новостных релизах и отчетах компаний, но эта взаимосвязь устанавливает временную зависимость. Эта временная связь учитывается в приведенном выше уравнении q-значения через гамма-фактор. Гамма позволяет сбалансировать краткосрочные и долгосрочные вознаграждения, что дает q-значениям DQN возможность заглядывать дальше вперед и оценивать кумулятивное влияние действий с течением времени. Утверждается, что результатом является то, что некоторые вознаграждения задерживаются, а гамма гарантирует, что агент не игнорирует долгосрочные вознаграждения, продолжая при этом следить за немедленными, что может быть важно при торговле. Например, зачастую позиции, открытые в ответ на важные решения по процентным ставкам, не сразу приносят благоприятные результаты. Неблагоприятные периоды колебаний обычно являются определяющими для этих позиций, и поэтому возможность иметь и использовать сигналы, которые это учитывают, такие как DQN, может быть преимуществом.
Изменения в коде
Чтобы использовать нашу DQN в гибридной функции потерь, нам сначала нужно добавить наше пользовательское перечисление потерь, чтобы оно выглядело так:
//+------------------------------------------------------------------+ //| Custom Loss-Function Enumerator | //+------------------------------------------------------------------+ enum Eloss { LOSS_TYPICAL = -1, LOSS_SVR = 1, LOSS_QL = 2, LOSS_DQN = 3 };
Мы добавляем новое перечисление LOSS_DQN, которое будет выбрано, когда функция потерь использует DQN. Дополнительные изменения, которые нам необходимо внести, как и в первой статье об обучении с подкреплением, касаются функции обратного распространения, где выбор подходящего типа потерь определяет значение, используемое при вычислении дельт. Эти изменения следующие:
//+------------------------------------------------------------------+ //| BACKWARD PROPAGATION OF THE MULTI-LAYER-PERCEPTRON. | //+------------------------------------------------------------------+ //| | //| -Extra Validation check of MLP architecture settings is performed| //| at run-time. | //| Chcecking of 'validation' parameter should ideally be performed | //| at class instance initialisation. | //| | //| -Run-time Validation of learning rate, decay rates and epoch | //| index is performed as these are optimisable inputs. | //+------------------------------------------------------------------+ void Cmlp::Backward(Slearning &Learning, int EpochIndex = 1) { if(!validated) { printf(__FUNCSIG__ + " invalid network arch! "); return; } .... //COMPUTE DELTAS vector _last, _last_derivative; _last.Init(inputs.Size()); if(hidden_layers == 0) { _last = weights[hidden_layers].MatMul(inputs); } else if(hidden_layers > 0) { _last = weights[hidden_layers].MatMul(hidden_outputs[hidden_layers - 1]); } _last.Derivative(_last_derivative, THIS.activation); vector _last_loss = output.LossGradient(label, THIS.loss_typical); if(THIS.loss_custom == LOSS_SVR) { _last_loss = SVR_Loss(); } else if(THIS.loss_custom == LOSS_QL) { .... } else if(THIS.loss_custom == LOSS_DQN) { double _reward = QL.CriticReward(Learning.ql_reward_max, Learning.ql_reward_min, Learning.ql_reward_float); vector _rewards; _rewards.Init(Learning.dqn_target.Size()); _rewards.Fill(0.0); if(_reward > 0.0) { _rewards[0] = 1.0; } else if(_reward == 0.0) { _rewards[1] = 1.0; } else if(_reward < 0.0) { _rewards[2] = 1.0; } vector _target = QL.CriticTarget(_rewards, Learning.dqn_target); _last_loss = output.LossGradient(_target, THIS.loss_typical); } .... }
Другие основные изменения, которые мы внесли в код, относятся к классу CQL и уже были выделены выше, где представлена формула q-значения для DQN. Функция get output, которую мы используем для генерации пороговых значений условий, не сильно отличается от той, что мы рассматривали в предыдущей статье по основам q-обучения. Она представлена ниже:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CSignalDQN::GetOutput(int &Output) { m_learning.rate = m_learning_rate; for(int i = m_epochs; i >= 1; i--) { MLP.LearningType(m_learning, i); for(int ii = m_train_set; ii >= 0; ii--) { int _states = 2; vector _in, _in_old, _in_row, _in_row_old, _in_col, _in_col_old; if ( _in_row.Init(_states) && _in_row.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, _states) && _in_row.Size() == _states && _in_row_old.Init(_states) && _in_row_old.CopyRates(m_symbol.Name(), m_period, 8, ii + 1 + 1, _states) && _in_row_old.Size() == _states && _in_col.Init(_states) && _in_col.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, _states) && _in_col.Size() == _states && _in_col_old.Init(_states) && _in_col_old.CopyRates(m_symbol.Name(), m_period, 8, m_state_lag + ii + 1, _states) && _in_col_old.Size() == _states ) { _in_row -= _in_row_old; _in_col -= _in_col_old; // m_learning.ql_reward_max = _in_row.Max(); m_learning.ql_reward_min = _in_row.Min(); if(m_learning.ql_reward_max == m_learning.ql_reward_min) { m_learning.ql_reward_max += m_symbol.Point(); } MLP.Set(_in_row); MLP.Forward(); // MLP.QL.THIS.environments = m_environments; // vector _in_e; _in_e.Init(1); MLP.QL.Environment(_in_row, _in_col, _in_e); // int _row = 0, _col = 0; MLP.QL.SetMarkov(int(_in_e[_states - 1]), _row, _col); _in.Init(2); _in[0] = _row; _in[1] = _col; DQN_ONLINE.Set(_in); DQN_ONLINE.Forward(); // MLP.QL.SetMarkov(int(_in_e[_states - 2]), _row, _col); _in_old.Init(2); _in_old[0] = _row; _in_old[1] = _col; DQN_TARGET.Set(_in_old); DQN_TARGET.Forward(); m_learning.dqn_target = DQN_TARGET.output; if(ii > 0) { vector _target, _target_data, _target_data_old; if ( _target_data.Init(2) && _target_data.CopyRates(m_symbol.Name(), m_period, 8, ii, 2) && _target_data.Size() == 2 && _target_data_old.Init(2) && _target_data_old.CopyRates(m_symbol.Name(), m_period, 8, ii + 1, 2) && _target_data_old.Size() == 2 ) { _target.Init(__MLP_OUTPUTS); _target.Fill(0.0); _target_data -= _target_data_old; double _type = _target_data[1] - _in_row[1]; int _index = (_type < 0.0 ? 0 : (_type > 0.0 ? 2 : 1)); _target[_index] = 1.0; MLP.Get(_target); if(i == m_epochs && ii == m_train_set) { DQN_ONLINE.Backward(m_learning, i); if(m_target_counter >= m_target_counts) { DQN_TARGET = DQN_ONLINE; m_target_counter = 0; } MLP.Backward(m_learning, i); } } } Output = (MLP.output.Max()==MLP.output[0]?0:(MLP.output.Max()==MLP.output[1]?1:2)); } } } }
Как уже упоминалось выше, у нас есть две сети DQN: онлайн-сеть и целевая сеть. Кроме того, конечно, есть родительский MLP, который принимает в качестве входных данных близкие изменения цен, как в статье о q-обучении. Нам не следует ссылаться на класс QL, за исключением вызова критической целевой функции для получения q-значений DQN, как упомянуто выше. Однако поскольку класс QL позволяет нам получать доступ к координатам состояния среды (при задании индекса), а также составлять индекс из координат состояния, мы обращаемся к нему, чтобы получить входные данные для двух сетей DQN. Как уже упоминалось, мы не используем q-map для наших прогнозов, а полагаемся на онлайн-сеть DQN, обученную целевой сетью. Как онлайн-, так и целевые DQN просто принимают состояния среды (старое и новое соответственно) и обучаются прогнозировать вектор значений q (для каждого действия агента).
Отчеты тестера стратегий
Мы тестировали MLP с обучением с подкреплением через сети Deep-Q на EURGBP в течение 2023 года на дневном временном интервале. Ниже приведены наши результаты, которые призваны лишь продемонстрировать возможность торговли и не гарантируют результатов в будущем.


Заключение
Мы рассмотрели реализацию и тестирование альтернативного алгоритма обучения с подкреплением Deep-Q-Networks в советниках, собранных с помощью Мастера. Обучение с подкреплением - это третий метод машинного обучения, помимо обучения с учителем и без учителя, и хотя он представляет собой другой подход к машинному обучению, в последующих статьях мы рассмотрим сценарии, в которых он фактически может служить основной моделью и генератором сигналов.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/16008
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 Арбитражный трейдинг Forex: Матричная торговая система на возврат к справедливой стоимости с ограничением риска
Арбитражный трейдинг Forex: Матричная торговая система на возврат к справедливой стоимости с ограничением риска
 Нейросети в трейдинге: Прогнозирование временных рядов при помощи адаптивного модального разложения (ACEFormer)
Нейросети в трейдинге: Прогнозирование временных рядов при помощи адаптивного модального разложения (ACEFormer)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования