
Нейросети в трейдинге: Обобщение временных рядов без привязки к данным (Окончание)

Введение
Финансовые рынки — живой организм. Их пульс задают миллионы сделок, сотни экономических отчётов и непрерывная череда новостей. В такой среде прибыль получает тот, кто умеет не просто быстро реагировать, а предугадывать точки изменения тенденций. Именно для этого был разработан Mamba4Cast — фреймворк прогнозирования временных рядов, вдохновлённый последними разработками в области нейросетевой архитектуры и адаптированный под специфику высокочастотных последовательностей.
Мы подошли к заключительной фазе знакомства с данным фреймворком. Вначале разобрали теоретический каркас и общую схему обработки признаков. Во второй части — углубились в механику. Теперь соберем всё воедино, чтобы показать: модель не только существует на бумаге, но и работает в реальной рыночной среде.
Сам фреймворк устроен как цепочка модулей, каждый из которых исполняет свою специализированную функцию. Первый блок отвечает за извлечение признаков. Здесь модель воспринимает сырые данные: цену открытия, закрытия, high/low, объёмы. Все они проходят через компактный слой, выделяющий локальные закономерности. Можно сказать, это как обученный глаз трейдера, замечающий паттерны в хаосе графика.
Затем приходит очередь сверточных слоёв. Эти блоки работают, как фильтры рынка, извлекая устойчивые сигналы и нивелируя шум. Пики волатильности, затухающие тренды, формирующиеся фазы консолидации — всё это ловится и обрабатывается. В данном случае используется многооконная архитектура, где каждая свертка ориентирована на разные горизонты. Таким образом, фреймворк учится одновременно видеть и ближайшие флуктуации, и более длинные колебательные циклы.
Ключевой модуль — SSM (State Space Model) — хранит в себе способность к долговременной памяти. Это особенно важно в финансовых данных, где закономерности часто проявляются не мгновенно, а на горизонтах десятков свечей. Например, серия ложных пробоев может завершиться мощным импульсом — и модель должна быть готова к такому сценарию. Именно SSM позволяет не забывать контекст и поддерживать обоснованное прогнозирование даже в условиях рыночной неопределённости.
Особую ценность Mamba4Cast придаёт механизм прогнозирования на весь горизонт планирования. Это соответствует реальным задачам трейдеров. Подобный подход можно сравнить с работой водителя: он смотрит под колёса, но и держит взгляд вдаль, считывая динамику потока. Такой гибридный режим даёт более стабильную и комплексную политику поведения.
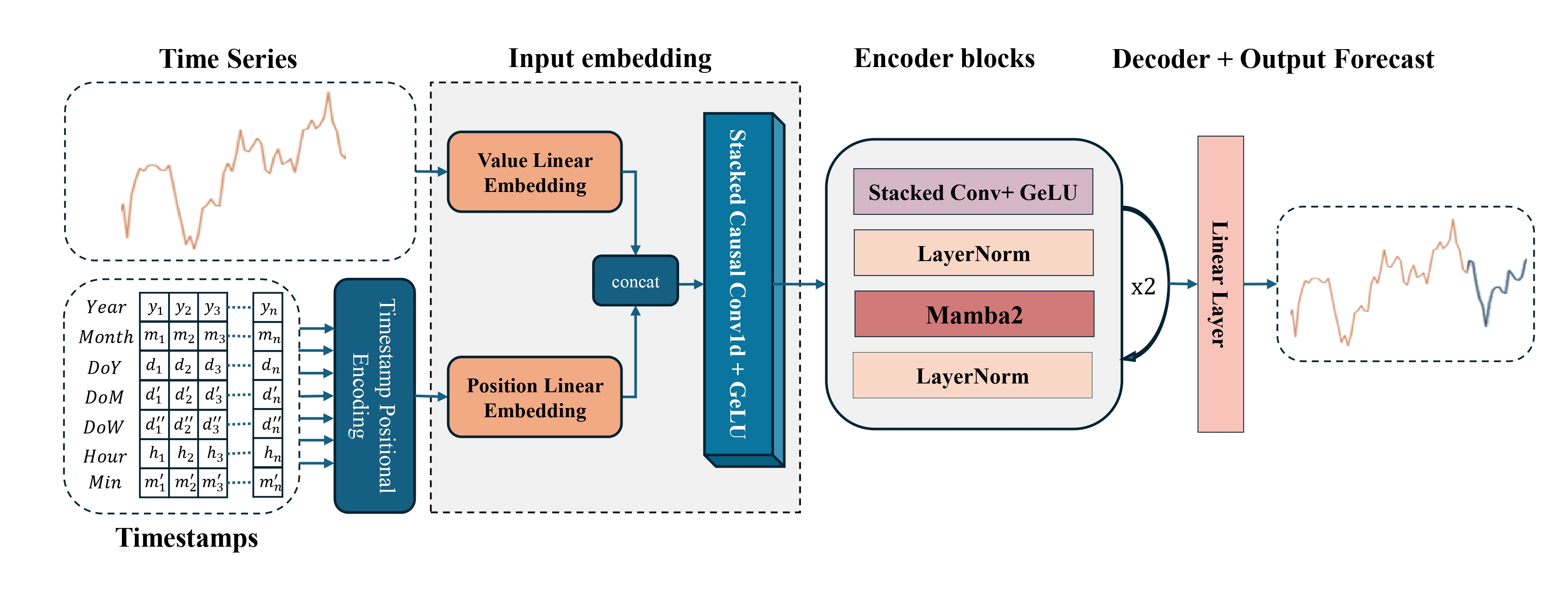
В этой статье вы увидите финальный облик модели: её архитектуру, процессы обучения и реальные результаты. Мы покажем, как соединяются теория и практика, как абстрактная модель превращается в рабочий инструмент анализа рынка.
Архитектура моделей
Сегодня мы начнём работу с построения архитектуры обучаемой модели — полноценного торгового Агента, способного принимать решения и совершать операции в реальном времени. Подобно трейдеру, который внимательно анализирует текущую рыночную ситуацию, оценивает поведение цены, объёмы, настроение рынка и только затем принимает решение на вход в позицию — наш Агент также должен уметь видеть и понимать рынок, а не слепо следовать сигналам. Поэтому мы не ограничиваемся задачей прогнозирования одной следующей цены — наша цель глубже: создать модель, которая сможет распознавать паттерны поведения рынка, реагировать на быстро меняющиеся условия и адаптироваться к различным фазам рыночного цикла.
В этом контексте фреймворк Mamba4Cast реализуется в виде одного из ключевых элементов общей системы — Энкодера состояния окружающей среды. Именно здесь начинается формирование рыночного восприятия модели, превращающее набор чисел в осмысленную картину происходящего. Энкодер станет своеобразным торговым глазомАгента, обученным распознавать значимые движения, скрытые закономерности и потенциальные точки входа задолго до их подтверждения на графике.
В данной работе мы по-прежнему придерживаемся фреймворка обучения Actor-Director-Critic. Обучаемая нами система включает четыре ключевые модели, каждая из которых отвечает за свой аспект принятия торговых решений:
- Энкодер окружающей среды — глаза агента, формирует эмбеддинги состояния рынка;
- Актер (Actor) — модель, предлагающая конкретные торговые действия на основе полученного эмбеддинга;
- Режиссёр (Director) — модель, классифицирующая предложенные Актером действия на хорошие и плохие, направляя процесс обучения и предотвращая ошибочные решения;
- Критик (Critic) — оценивает ценность действий Актера в контексте рыночного состояния и формирует сигнал обратной связи для оптимизации стратегии.
Архитектура всех моделей задаётся методом CreateDescriptions, в параметрах которого передаются четыре указателя на динамические массивы. Именно в эти массивы поочерёдно записываются описания слоёв и параметров каждой из перечисленных моделей — от Энкодера до Критика, что позволяет гибко управлять структурой и легко адаптировать фреймворк под новые требования.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&actor, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
В теле метода CreateDescriptions сначала проверяется актуальность полученных указателей на четыре динамических массива. При необходимости, создаются новые объекты — это гарантирует корректность последующей записи описания архитектуры без риска конфликтов памяти.
Далее переходим к описанию архитектуры Энкодера состояния окружающей среды. В качестве объекта получения исходных данных используется полносвязный слой достаточного размера. В него мы передаём сырые данные, без предварительной обработки, прямо из терминала: цены открытия/закрытия, high/low, объёмы, а также показатели технических индикаторов.
Так как эти данные обладают разными статистическими характеристиками и масштабами, для стабилизации процесса обучения модели требуется выравнивание распределений. Здесь на помощь приходит слой пакетной нормализации. Он преобразует входные векторы так, чтобы каждый признак имел близкое к нулю среднее и дисперсию около "1", что способствует ускоренной сходимости и повышает стабильность обучения. Вместо классической реализации, мы используем модифицированный вариант — слой нормализации с добавлением шума. Это решение помогает улучшить обобщающую способность модели за счёт искусственного увеличения разнообразия обучающих данных.
На выходе такой связки Энкодер получает унифицированные признаки, готовые к дальнейшей обработке.//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Затем, мы генерируем эмбеддинги временных шагов с помощью модуля CMamba4CastEmbedding. Именно здесь векторы признаков обогащаются гармониками двух ключевых временных интервалов — H1 (часовой) и D1 (суточный). За счёт добавления синусоидальных и косинусоидальных компонент, модель получает информацию о типичных часовых колебаниях и повторяющихся дневных ритмах. Это позволяет агенту учитывать типичные рыночные циклы — утренние разогревы, дневные тенденции и вечерние штилевые фазы.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = BarDescr; int prev_out = descr.window_out = NSkills; { int temp[] = {PeriodSeconds(PERIOD_H1), PeriodSeconds(PERIOD_D1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Использование мультиоконного сверточного блока с тремя окнами свёртки позволит сделать эмбеддинги более насыщенными. При этом важно отметить, что свёртка выполняется не по временной оси, а горизонтально, внутри одного бара, где анализируются взаимосвязи между признаками.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.window_out * descr.windows.Size());
На финальном этапе кодирования исходного сигнала мы добавим слой нормализации. Его задача — устранить перекосы в распределении признаков, сделать анализируемые данные более однородными и обеспечить стабильную работу модели в процессе обучения. Такой шаг помогает избежать смещения градиентов и ускоряет сходимость без потери качества.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее переходим непосредственно к построению архитектуры энкодера. И здесь мы планируем работу в рамках унитарных временных последовательностей отдельных признаков. Поэтому предварительно осуществим транспонирование нашего тензора признаков.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; prev_out = descr.count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
При этом стоит обратить внимание, что здесь мы имеем дело уже далеко не с теми признаками, которые ранее получили от терминала. На данном этапе у нас сформировались совершенно иные обогащенные признаки, каждый из которых представляет определенный срез с описания бара, ранее полученного от терминала.
Блок энкодера Mamba4Cast состоит из стека свёрток и SSM-модуля. Между модулями предусмотрен слой нормализации для выравнивания признаков. В сверточном стеке мы применяем модули мультиоконной свёртки. Здесь каждый фильтр фокусируется на своём временном окне и выделяет соответствующие паттерны рынка. С целью сохранения размерности данных, после каждого модуля мультиоконной свертки используется слой макспулинга, который выбирает значение максимального фильтра в каждом окне, тем самым уменьшая пространственные измерения, не меняя глубину признаков.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; int filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
В SSM мы отказались от оригинального Mamba2, предложенного авторами фреймворка Mamba4Cast, и выбрали модуль Chimera, который обеспечивает анализ данных в двухмерной плоскости и позволяет учитывать перекрёстные зависимости между временными и пространственными компонентами.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronChimera; //--- Window { int temp[] = {prev_out, prev_out/2}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units { int temp[] = {prev_count, prev_count*2}; //In, Out if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.windows[1]; prev_count=descr.units[1]; //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И завершает модуль слой пакетной нормализации. О преимуществах такого подхода мы уже говорили выше.
В архитектуре нашего энкодера предусмотрены 2 последовательных блока, каждый из которых состоит из мультиоконного стека свёрток, слоя макспулинга и SSM-модуля Chimera, обеспечивая поэтапное обогащение признаков и сохранение контекста.
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMultiWindowsConvWPadOCL; descr.step = 3; descr.count = (prev_out + descr.step - 1) / descr.step; filt=descr.window_out = 5; { int temp[] = {3, 5, 7}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.layers = prev_count; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = int(descr.count * descr.windows.Size()); //--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = prev_count * prev_out; descr.window = filt; descr.step = filt; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 17 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 18 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronChimera; //--- Window { int temp[] = {prev_out, prev_out/2}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units { int temp[] = {prev_count, prev_count*2}; //In, Out if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } prev_out=descr.windows[1]; prev_count=descr.units[1]; //--- layer 19 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count*prev_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
В качестве декодера для независимого прогнозирования унитарных временных последовательностей, на всём горизонте планирования мы используем два последовательных свёрточных слоя. Между ними установлен SoftPlus, обеспечивающий необходимую нелинейность. На выходе декодера применяется гиперболический тангенс (tanh), поскольку его диапазон значений соответствует шкале нормализованных данных, что позволяет сохранить согласованность между входом и выходом модели.
//--- layer 20 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = 4 * NForecast; descr.layers = prev_count; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 21 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Однако здесь стоит напомнить, что для перехода к работе в режиме унитарных временных последовательностей, мы предварительно выполнили транспонирование тензора анализируемых признаков. Поэтому, прежде чем передавать результаты декодера дальше, необходимо восстановить их исходную форму путём обратного транспонирования.
//--- layer 22 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; prev_out = descr.count; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Следующим шагом восстановления структуры данных является понижение размерности, которая была увеличена в процессе формирования эмбеддингов. Это необходимо для приведения тензора результатов к форме, совместимой с исходными данными.
//--- layer 23 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = BarDescr; descr.layers = 1; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Завершающим этапом работы энкодера состояния счёта является операция обратной нормализации. На этом шаге, значения, полученные после всех преобразований, возвращаются к масштабам исходных данных, что позволяет корректно интерпретировать результат работы модели.
//--- layer 24 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Далее переходим к описанию архитектуры Актёра. Его основная задача — провести оценку текущего состояния счёта и открытых позиций в контексте анализируемого состояния рыночной среды. На основе полученной информации, Актёр формирует торговое решение — операцию, которая потенциально способна обеспечить максимальную доходность при минимальных рисках.
В данном контексте на вход Актёру подаётся тензор, представляющий текущее состояние счёта. Этот тензор содержит агрегированную информацию о балансе, объёмах открытых позиций, направлении торговли и других ключевых параметрах, отражающих финансовое состояние торгового агента.
CLayerDescription *latent = encoder.At(LatentLayer-1); //--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные данные обрабатываются с помощью слоя пакетной нормализации, который стабилизирует распределение признаков и ускоряет процесс обучения модели.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Затем применяется слой кросс-внимания, позволяющий сопоставить текущее состояние счёта с рыночной ситуацией. При этом, в качестве контекста используется латентное представление окружающей среды, ранее сформированное Энкодером.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {AccountDescr, // Inputs window latent.windows[1] // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {1, // Inputs units latent.units[1] // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 32; descr.batch = 1e4; descr.layers = 2; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
В рамках данного эксперимента мы использовали стек из двух последовательно расположенных модулей кросс-внимания. Такая конфигурация позволяет глубже сопоставлять внутреннее состояние счёта с динамикой рыночной среды, усиливая способность модели выявлять причинно-следственные связи между текущей позицией и внешними условиями.
Важно понимать, что для слоя кросс-внимания в качестве контекста мы берем не общее представление текущего состояния окружающей среды, а латентное представление Энкодера, которое сформировалось после обработки исходного сигнала в виде эмбеддингов отдельных унитарных последовательностей признаков. Проще говоря, энкодер (блок внутри модели Энкодера состояния окружающей среды) переводит каждый признак в свой компактный вектор чувств, и именно эти векторы попадают в модуль кросс-внимания в качестве контекста.
Представьте, что модуль кросс-внимания — это дирижёр. У него есть мелодии от каждого инструмента (эмбеддинги признаков) и партитура текущего баланса счетa. Дирижёр определяет, какие инструменты сейчас должны звучать громче, то есть, какие признаки важнее для принятия решения, и подчёркивает именно их.
Благодаря этому, механизм кросс-внимания сопоставляет скрытые паттерны рынка с текущей позицией и выбирает сигналы, которые помогут принять эффективное торговое решение.
Результаты контекстного анализа проходят через три полносвязных слоя (MLP), каждый из которых последовательно уточняет представление о целевом действии. На выходе последнего слоя формируется торговое решение — конкретное предложение по открытию, удержанию или закрытию позиции с учётом текущего состояния счёта и рыночной конъюнктуры.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = 1e4; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Модели Режиссёра и Критика обладают схожей архитектурой: они анализируют тензор действий, предложенных Актёром, в контексте текущей рыночной ситуации. На выходе этих моделей формируется соответствующая оценка — одобрение или отклонение предложенного действия с точки зрения стратегии и риска.
Детальную реализацию архитектур этих компонентов я предлагаю оставить для самостоятельного изучения. Полный исходный код описания архитектуры всех обучаемых моделей, включая Режиссёра и Критика, представлен во вложении.
Обучение моделей
После ознакомления с архитектурой моделей, переходим непосредственно к этапу их обучения. Здесь важно отметить: авторы фреймворка Mamba4Cast для тестирования и обучения своих моделей использовали синтетические временные ряды. Это решение имеет ряд преимуществ, особенно в контексте разработки и отладки архитектур глубокого обучения.
Во-первых, синтетика даёт полный контроль над параметрами данных: можно заранее задать амплитуду, частоту, тренды, сезонность, уровень шума и даже включить редкие или аномальные события. Это позволяет точечно проверять, как модель реагирует на различные характеристики временных рядов и выявлять её слабые места в строго контролируемой среде.
Во-вторых, искусственно сгенерированные ряды исключают влияние грязных или неполных данных, что особенно важно на ранних этапах обучения. В отличие от реальных рыночных данных, синтетика не содержит пропусков, артефактов сбора или искажений, которые могут маскировать истинные ошибки модели.
Третье преимущество — масштабируемость. Генерация синтетических данных не требует затрат на сбор и хранение исторических данных и позволяет быстро создавать обучающие выборки нужного объёма для решения задачи любой сложности. Это особенно актуально при использовании ресурсоёмких моделей, где необходима богатая и сбалансированная обучающая среда.
И наконец, синтетика — это надёжный инструмент для стресс-тестов. Мы можем моделировать экстремальные рыночные ситуации, не дожидаясь их в реальной жизни. Такие сценарии позволяют проверить устойчивость модели к неожиданным колебаниям.
С другой стороны, реальный рынок — это не стерильная лаборатория, а скорее бурное море, где правила часто пишутся на ходу. Именно поэтому, несмотря на все плюсы синтетических данных, обучение и валидация модели исключительно на синтетике — путь односторонний и потенциально опасный.
Во-первых, в реальных рыночных данных всегда присутствует шум, пропуски, неочевидные корреляции и грязные участки, которых не бывает в искусственно созданной среде. Модель, не обученная на таких особенностях, может теряться при первом же контакте с реальностью — особенно на низколиквидных активах или в периоды высокой волатильности.
Во-вторых, рынок подвержен эффекту неожиданности: новости, санкции, слияния, геополитика, поведение крупных игроков — всё это влияет на цены, но практически невозможно смоделировать достоверно синтетически. И здесь особенно важно, чтобы модель умела адаптироваться и работать в условиях неполной информации.
В-третьих, поведенческие паттерны участников рынка (от страха до жадности) создают уникальную динамику, которую трудно воссоздать с помощью генераторов. Модель, не видевшая таких паттернов, рискует переобучиться на чистую среду и не распознавать важные сигналы в реальной торговле.
Именно поэтому наиболее эффективным считается гибридный подход: синтетика используется на ранних этапах — для калибровки архитектуры, подбора гиперпараметров, отладки обучения. А затем подключаются реальные данные, чтобы обучить модель жить в полевых условиях, научить её ошибаться, адаптироваться и принимать решения в нестабильной среде.
Сегодня у нас нет в распоряжении полноценного генератора синтетических финансовых последовательностей. Однако, как говорится, если гора не идёт к Магомету…
Для первого этапа обучения мы попробуем приблизить свойства синтетики с помощью предварительной обработки реальных исторических данных. Как уже упоминалось ранее, синтетические ряды обычно не содержат артефактов, пропусков и прочего рыночного шума. Чтобы добиться аналогичной чистоты в реальных данных, мы применим простое скользящее усреднение с коротким окном по каждому из анализируемых признаков. Это позволит:
- сгладить локальные аномалии и резкие всплески,
- нивелировать влияние единичных выбросов,
- повысить устойчивость модели на этапе обучения.
Важно отметить, что мы сознательно выбираем небольшое окно усреднения, чтобы сохранить динамику и форму сигнала. Наша цель — не выровнять всё до плоской линии, а лишь приглушить шум, который может ввести модель в заблуждение. Подобную логигу реализуем в советнике "…\MQL5\Experts\Mamba4Cast\StudyMA.mq5". В рамках данной статьи мы рассмотрим лишь метод Train, в котором реализован процесс обучения моделей.
Алгоритм метода начинается с создания вектора распределения вероятностей выбора отдельных траекторий из буфера воспроизведения опыта.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
На начальном этапе все траектории получают равные вероятности, что позволяет обеспечить более полное изучение всей истории.
Затем, инициализируем локальные переменные, которые мы будем использовать для временного хранения данных в процессе обучения моделей.
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); matrix<float> hstate = matrix<float>::Zeros(1, HistoryBars * BarDescr); bool Stop = false; int average = 5; //--- uint ticks = GetTickCount();
После завершения подготовительной работы, переходим к созданию системы циклов обучения моделей. Внешний цикл отвечает за контроль общего числа итераций обучения.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; } if( !cEncoder.Clear() || !cActor.Clear() || !cDirector.Clear() || !cCritic.Clear() ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } result = vector<float>::Zeros(NActions);
Здесь мы сэмплируем одну траекторию из буфера воспроизведения опыта и состояние начала пакета обучения. Тут же сбрасываем внутреннее состояние всех моделей, исключая влияние нерелевантной памяти на данных новой траектории. После чего, инициализируем вложенный цикл обучения моделей внутри пакета.
for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!hstate.Assign(Buffer[tr].States[i].state) || MathAbs(hstate).Sum() == 0 || !hstate.Reshape(HistoryBars, BarDescr)) { iter -= Batch + start - i; break; }
В теле вложенного цикла загружаем из буфера воспроизведения опыта исторические данные описания анализируемого состояния окружающей среды и организовываем цикл их сглаживания скользящим усреднением.
for(int h = HistoryBars - 1; h > 0; h--) { state = vector<float>::Zeros(BarDescr); for(int a = MathMax(h - average + 1, 0); a <= h; a++) state += hstate.Row(a); if(!hstate.Row(state / MathMin(average, h + 1), h)) { iter -= Batch + start - i; break; } }
Сглаженные значения переносим в буфер данных описания анализируемого состояния окружающей среды.
if(!hstate.Reshape(1, HistoryBars * BarDescr) || !bState.AssignArray(hstate.Row(0))) { iter -= Batch + start - i; break; }
Далее следует вспомнить, что для корректной работы фреймворка Mamba4Cast нам необходимы временные метки каждого бара. Однако, в созданной нами ранее структуре буфера воспроизведения опыта сохраняется только одна временная метка для каждого состояния окружающей среды, которая соответствует последнему бару. С целью создания необходимого буфера временных меток, мы осуществляем обратный проход по состояниям окружающей среды из буфера воспроизведения опыта от текущего состояния на заданную глубину анализа и собираем временные метки.
bTime.Clear(); bTime.Reserve(HistoryBars); double time = (double)Buffer[tr].States[i].account[7]; for(int t = i; t >= MathMax(0, i - HistoryBars + 1); t--) if(!bTime.Add((float)(double)Buffer[tr].States[t].account[7])) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } if(bTime.Total() < HistoryBars) { float period = MathMin(Buffer[tr].States[i + 1].account[7] - Buffer[tr].States[i].account[7], Buffer[tr].States[i + 2].account[7] - Buffer[tr].States[i + 1].account[7]); do { if(!bTime.Add(bTime[-1] - period)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } } while(bTime.Total() < HistoryBars); } if(bTime.GetIndex() >= 0) if(!bTime.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Алгоритм заполнения буфера описания состояния счета перенесем из аналогичных программ без изменения.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; float profit = float(bState[0] / _Point * (result[0] - result[3])); bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После подготовки необходимых исходных данных, переходим к выполнению прямого прохода всех моделей. Первым осуществляет прямой проход Энкодер состояния окружающей среды. В своей работе он использует сглаженные данные описания состояния рынка и буфер временных меток.
//--- Feed Forward if(!cEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее следует Актер. Он анализирует буфер состояния счета и контекст окружающей среды из латентного состояния Энкодера.
if(!cActor.feedForward((CBufferFloat*)GetPointer(bAccount), 1, false, GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Энкодер состояния окружающей среды мы обучаем прогнозированию последующих состояний. Критически важно понимать: мы не генерируем цель вручную и не применяем скользящее усреднение, как это делается на этапе подготовки исходных данных. Вместо этого, мы просто загружаем готовое состояние среды, которое уже находится в буфере воспроизведения, с заданным сдвигом вперёд на горизонт планирования.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; } for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
И после формирования целевых значений, мы можем осуществить корректировку параметров Энкодера, вызвав метод обратного прохода.
//--- State Encoder Result.AssignArray(fstate); if(!cEncoder.backProp(Result, (CBufferFloat*)NULL, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее, на основании имеющихся фактических данных о будущем ценовом движении, мы можем сформировать "почти идеальное" торговое решение.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(pos > 0 && tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } } else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(pos > 0 && tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } else { ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); float max_sl = float(MaxSL * Point()); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax] / 2 > MathAbs(target[argmin]) && MathAbs(target[argmin]) < max_sl) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin] / 2) && target[argmax] < max_sl) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); } if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(pos > 0 && tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[5] = result[1] = tp; result[4] = result[2] = sl; result[3] = 0; bActions.AssignArray(result); } } else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(pos > 0 && tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0] / 100 * 0.01, 0.011)); result[2] = result[4] = tp; result[1] = result[5] = sl; result[0] = 0; bActions.AssignArray(result); } } } } }
Следует отметить, что такое торговое решение формируется с учетом торговой операции, совершенной на предыдущем шаге. Агент не работает с разрозненными сигналами вакуума, а выстраивает цепочку действий. И каждое последующее решение опирается на уже совершённую сделку. Благодаря этому подходу, мы получаем не набор разрозненных ордеров, а полноценную стратегию, в которой каждое решение логически вытекает из предыдущего. Именно эти почти идеальные торговые операции мы используем для обучения Актера.
//--- Actor Policy bActions.GetData(result); if(!cActor.backProp(GetPointer(bActions), (CNet*)GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Эти же торговые операции мы используем для обучения Критика. Цель — сделать функцию оценки действий, близкой к реальной политике Актера. Мы передаём Критику ту же почти идеальную последовательность операций, а вознаграждение определяем, исходя из изменения цены на следующем баре.
//--- Critic if(!cCritic.feedForward(GetPointer(bActions), 1, false, (CNet*)GetPointer(cEncoder), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } float reward = float((bActions[0] - bActions[3]) * fstate[0, 0] / Point()); Result.Clear(); if(!Result.Add(reward) || !cCritic.backProp(Result, (CNet*)GetPointer(cEncoder), LatentLayer) || !cEncoder.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer, true) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Таким образом, Критик учится давать адекватную оценку действиям Актера, основываясь на реальном изменении цены, и помогает выстраивать более точную и устойчивую стратегию.
Немного по‑другому обстоят дела с обучением Режиссера. Нельзя кормить его только позитивными кейсами — иначе он никогда не научится отличать плохие действия от хороших. Поэтому, на каждом шаге мы случайным образом выбираем, как будет выглядеть обучающий пример:
- Положительный. Подаём на вход почти идеальное действие, которое только что вычислили по фактическим данным, и даём метку "1" (успех).
- Отрицательный. Формируем вектор случайных значений той же размерности, что и пространство действий, и присваиваем метку "0" (неудача).
После этого, вызываем методы прямого и обратного прохода Director.
//--- Director Result.Clear(); if((MathRand() / 32767.0) > 0.5) Result.Add(1); else { target = vector<float>::Zeros(NActions); for(int i = 0; i < NActions; i++) target[i] = float(MathRand() / 32767.0); bActions.AssignArray(target); Result.Add(0); } if(!cDirector.feedForward(GetPointer(bActions), 1, false, (CNet*)GetPointer(cEncoder), LatentLayer) || !cDirector.backProp(Result, (CNet*)GetPointer(cEncoder), LatentLayer) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Такой подход гарантирует, что Режиссер научится не только поощрять хорошие, но и распознавать лохмотья плохих решений, помогая Актеру избегать неэффективных действий.
Теперь нам остается проинформировать пользователя о ходе обучения и перейти к следующей итерации системы циклов.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-12s %6.2f%% -> Error %15.8f\n", "Encoder", percent, cEncoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, cActor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Director", percent, cDirector.getRecentAverageError()); str += StringFormat("%-16s %6.2f%% -> Error %15.8f\n", "Critic", percent, cCritic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После завершения процесса обучения моделей, выводим в журнал полученные результаты и инициализируем завершение работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", cEncoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", cActor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Director", cDirector.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", cCritic.getRecentAverageError()); ExpertRemove(); //--- }
В программы офлайн- и онлайн-обучения моделей на реальных исторических данных были внесены лишь точечные изменения в контексте создания буфера временных меток. И мы не будем сейчас останавливаться на подробном их изучении. Их полный код представлен во вложении и вы можете самостоятельно с ними ознакомиться. Там же представлены программы взаимодействия с окружающей средой.
Обучение нашей системы выстроено в три этапа, каждый из которых плавно готовит модель к реальным рыночным условиям.
Сначала мы проводим первичное офлайн-обучение на реальных исторических данных с использованием вышеописанного метода их сглаживания. Данный этап осуществляется без обновления обучающей выборки. Используемый нами в Энкодере состояния окружающей среды слой пакетной нормализации с добавлением шума позволит создать достаточную аугментацию исходных данных и значительно расширит обучающую выборку в представлении модели.
Представьте, что каждая свеча и каждый индикатор проходят через фильтр лёгкой деформации — это создаёт множество вариантов одной и той же ситуации и не позволяет модели заучивать лишь одни и те же паттерны. В итоге Энкодер учится видеть сущность движения, несмотря на малейшие искажения.
На втором офлайн-этапе используются исторические данные без сглаживания: модель знакомится с настоящим лицом рынка — резкими всплесками, провалами и шумными флуктуациями. Такой переход от идеализированного рынка к сырым данным помогает Агенту адаптироваться к реальным рыночным колебаниям, научиться удерживать стабильность прогнозов и не пугаться внезапных аномалий. Мы внимательно следим за динамикой ошибки прогнозирования и прекращаем обучение, как только метрика несколько проходов подряд удерживается в узком диапазоне — это признак того, что модель вчувствовалась в данные.
Наконец, на третьем этапе, агент выходит в тестер стратегий для онлайн-обучения. Здесь мы наблюдаем поведение кривой баланса. Если после нескольких последовательных проходов баланс зависает и не демонстрирует ожидаемого роста, мы деликатно возвращаемся к офлайн-обучению: корректируем политику Актера по почти идеальной траектории и снова запускаем дообучение.
Такой поэтапный подход обеспечивает одновременно высокую точность прогнозов и устойчивость торговых решений в любых условиях рынка.
Тестирование
Мы проделали огромную работу по адаптации и реализации подходов, предложенных авторами фреймворка Mamba4Cast. Теперь настал момент истины — проверка эффективности реализованных на реальных данных.
В качестве обучающей выборки мы использовали минутные котировки EURUSD за весь 2024 год. Для чистоты эксперимента, финальное тестирование проводилось на исторических данных за Январь–Март 2025 года — периода, который не участвовал в обучении. Все остальные параметры остались без изменений, чтобы оценка стратегии была объективной и честной.
Результаты тестирования представлены ниже.


Надо признать, что здесь мы наблюдаем довольно высокую частоту торговых операций. Среднее время удержания позиции чуть более 3 минут. И в целом, за период тестирования модель совершила 2677 сделок, 1240 из них было закрыто с прибылью. Несмотря на то, что количество убыточных позиций было немного больше, за период тестирования модель смогла получить прибыль и наблюдаем довольно уверенный рост линии баланса. Отчасти это можно объяснить открытием позиций с довольно коротким стопом и дальнейшим её сопровождением. В подтверждение такого предположения свидетельствует малый разрыв между средней и максимальной убыточной позицией. В то же время, максимальная прибыльная торговая операция почти в 7 раз превышает среднюю прибыль от одной сделки.
Заключение
Мы прошли полный путь — от идеи и архитектуры фреймворка Mamba4Cast до его практической реализации, обучения и строгого тестирования на реальных исторических данных. Научили Энкодерчувствовать рынок, а Актёра — принимать решения с учётом рисков. Режиссёра — фильтровать лучшие и худшие сигналы. Критика — оценивать действия по реальным результатам.
Тестирование на EURUSDM1 за Январь–Март 2025 показало, что Mamba4Cast умеет не только прогнозировать, но и защищаться от шумов, адаптироваться к неожиданностям и сохранять прибыльность в длительной перспективе.
Однако, все представленные в статье программы носят демонстрационный характер и служат иллюстрацией возможностей фреймворка Mamba4Cast. Прежде чем применять предложенные решения в реальной торговле, необходимо провести обучение моделей на действительно репрезентативной выборке данных и выполнить всестороннее тестирование — только так можно гарантировать надёжность и безопасность вашей торговой стратегии.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 4 | StudyMA.mq5 | Советник | Советник офлайн обучения моделей на усредненных данных |
| 5 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 6 | Test.mq5 | Советник | Советник для тестирования модели |
| 7 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 8 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 9 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.


 Как интегрировать концепцию Smart Money (OB) в сочетании с индикатором Фибоначчи для оптимального входа в сделку
Как интегрировать концепцию Smart Money (OB) в сочетании с индикатором Фибоначчи для оптимального входа в сделку
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования