
Redes neurais em trading: Previsão probabilística de série temporal (K2VAE)

Introdução
Nos últimos anos, a análise de série temporal fez um verdadeiro avanço. As tarefas de detecção de anomalias, classificação e recuperação de valores ausentes agora são resolvidas com mais precisão e rapidez. No entanto, para os mercados financeiros a previsão probabilística é muito mais importante: não apenas prever o preço de um ativo, mas avaliar o intervalo de cenários possíveis. Essas estimativas ajudam traders e analistas a estruturar estratégias flexíveis, gerenciar riscos e tomar decisões fundamentadas.
Os modelos clássicos lidam muito bem com previsões de curto prazo. No entanto, basta olhar mais adiante para se verificarem erros acumulados, uma volatilidade que amplia as imprecisões e custos computacionais que crescem rapidamente. Especialmente nos mercados financeiros, onde cada evento (relatório de empresa ou surpresa geopolítica) introduz não linearidade e muda as regras do jogo.
Como uma das possíveis opções para resolver esse tipo de tarefa, no trabalho "K²VAE: A Koopman-Kalman Enhanced Variational AutoEncoder for Probabilistic Time Series Forecasting" foi proposto um novo framework baseado em duas ideias fundamentais. Primeiro, a teoria de Koopman transforma processos não lineares em forma linear. Imagine que você observa o gráfico do preço de uma ação através de lentes especiais e ele se transforma em uma linha reta. Essa abordagem facilita a compreensão da dinâmica. Segundo, o filtro de Kalman clássico processa cuidadosamente novos dados, ajustando a previsão sempre que chega uma nova informação: relatório de lucros, mudança nas taxas de juros ou um evento inesperado.
Os autores do trabalho combinaram essas ideias no framework K²VAE, um sistema leve e rápido baseado em um autocodificador variacional. Primeiro, KoopmanNet impõe uma estrutura linear sobre as cotações históricas e indicadores. Em seguida, a KalmanNet, construída com base nas abordagens do filtro de Kalman, refina, passo a passo, a estimativa dos possíveis movimentos e de sua incerteza. Essa arquitetura permite realizar previsões em horizontes de curto e longo prazo, mantendo alta precisão e estabilidade.
Vantagens importantes do framework K²VAE:
- transparência do modelo. A parte linear fornece aos traders sinais compreensíveis, e não uma caixa preta;
- flexibilidade das previsões. É possível obter rapidamente cenários para diferentes ativos: pares de moedas, índices e commodities;
- gestão de riscos. O refinamento adaptativo do intervalo de confiança ajuda a reduzir a tempo o risco de grandes perdas.
Como resultado, K²VAE torna-se uma solução universal para previsões de curto e longo prazo, permitindo não se limitar a um único cenário, mas avaliar imediatamente todo o espectro de possíveis movimentos do mercado. Isso aumenta significativamente a eficiência da gestão de portfólio e a confiabilidade das estratégias de negociação automáticas. Você vê não apenas uma previsão pontual, mas um panorama de riscos e oportunidades potenciais.
Algoritmo K²VAE
Na dinâmica dos mercados financeiros frequentemente nos deparamos com um aparente caos, oscilações de preços, picos repentinos de volatilidade e influência de notícias. A teoria de Koopman oferece uma visão interna: em vez de tentar domar diretamente a não linearidade, transferimos nosso sistema para um espaço especial de medição. Aqui cada vetor de estado xₖ (por exemplo, uma cesta de cotações ou um conjunto de indicadores econômicos) por meio da função ψ transforma-se em uma certa medição onde a evolução é descrita pelo operador linear 𝒦. Em termos simples, espalhamos um gráfico de preços complicado de modo que ele se alinhe, o que torna muito mais fácil analisar e prever a dinâmica principal da série temporal. Essa abordagem ajuda a separar a tendência de longo prazo dos ruídos de curto prazo.
Mesmo com uma representação linear, no entanto, ainda estamos sujeitos à incerteza, pois as cotações mudam a cada segundo, novos relatórios econômicos são divulgados e os bancos centrais ajustam as taxas. É exatamente nesse ponto que entra o filtro de Kalman. Esse algoritmo funciona com um princípio simples e poderoso Previsão e Correção: primeiro prevemos o estado atual do sistema e avaliamos nossa confiança na previsão (matriz Pₖ), depois, ao receber uma medição real (preço, volume de negociação ou indicador macroeconômico), calculamos o coeficiente de Kalman Kₖ. Com sua ajuda ajustamos a previsão inicial à realidade e atualizamos a estimativa de incerteza. Para o trader isso equivale a um treinamento operacional do modelo com dados recentes: relatórios corporativos, mudanças de liquidez ou eventos geopolíticos inesperados são imediatamente integrados à previsão, minimizando o atraso do modelo em relação ao mercado real.
Ao combinar o desdobramento linear do sistema e a filtragem adaptativa, obtemos uma base sólida para previsão probabilística. Mas para não nos limitarmos a apenas um cenário adicionamos o poder do autocodificador variacional. O VAE transforma a tarefa em geração condicional: na entrada estão os dados históricos X (T últimas observações para N ativos) e na saída não está apenas um vetor de valores futuros, mas uma distribuição de possíveis trajetórias Y. O ponto chave é a variável latente Z responsável por fatores ocultos do mercado: correlações, ciclos e choques inesperados. A otimização é realizada por meio do limite inferior da log-verossimilhança. O primeiro componente penaliza o modelo por uma geração fraca e o segundo penaliza o desvio da distribuição latente para regiões extremas distantes de nossas expectativas a priori.
No framework K²VAE esses três elementos (KoopmanNet, KalmanNet e VAE) não apenas coexistem lado a lado, mas se complementam de forma orgânica. Em geral, a arquitetura K²VAE segue um esquema claro de múltiplas etapas, em que cada componente é responsável por uma fase da transformação dos dados analisados em um modelo dinâmico compreensível.
Primeiro o módulo Input Token Embedding divide a série temporal original em tokens, pequenos fragmentos do histórico de preços ou indicadores de liquidez. Essa abordagem é semelhante à forma como um analista divide o gráfico de cotações em segmentos com níveis chave de suporte e resistência. Isso torna os dados mais significativos.
Em seguida, a KoopmanNet leva esses tokens para o chamado espaço de medição. Aqui a complexa não linearidade das séries temporais (correlações entre ativos, picos de volatilidade de curto prazo) é decomposta em componentes lineares simples. Com a ajuda do procedimento de treinamento selecionamos o operador linear de Koopman que, ao iterar sobre o primeiro token, constrói o modelo de evolução. Naturalmente, não existe um espaço de medição ideal que torne o sistema completamente linear, e é daí que surgem vieses nas previsões.
Depois disso entra em ação KalmanNet. De forma semelhante ao filtro de Kalman ela recebe a previsão linear e continua o treinamento com novos dados, refinando a covariância do estado multidimensional e assim formando o posterior variacional Q(Z|X) com semântica transparente. No contexto financeiro, isso é extremamente importante: não apenas construímos a trajetória base do movimento de preço, mas também avaliamos imediatamente o intervalo de possíveis desvios, desde gaps inesperados até reversões em resposta a notícias importantes.
Por fim o decodificador executa a função de medição inversa (ψ⁻¹), retornando as amostras obtidas do espaço latente para o formato usual de série temporal. Ele também é responsável pela modelagem da distribuição final P(Y|Z,X) no horizonte de planejamento. Dessa formaб obtemos um cenário pronto para uso das cotações futuras, e não apenas um, mas um conjunto de trajetórias probabilísticas, cada uma com sua própria avaliação de risco e confiança.
Como resultado K²VAE transforma dados financeiros brutos em um modelo linear dinâmico estruturado com refinamento adaptativo da incerteza e geração de todo o espectro de possíveis movimentos do mercado. Trata-se de uma ferramenta poderosa para planejamento de portfólio, avaliação de riscos e desenvolvimento de estratégias algorítmicas confiáveis.
A divisão da série temporal em patches (patches) é muito mais do que um truque técnico. Na análise financeira isso se assemelha à transição de cotações individuais de tick para velas de cinco minutos ou de trinta minutos, que mostram imediatamente tanto a tendência quanto picos importantes de volatilidade. No framework K²VAE o pré-processamento dos dados é construído com base em uma ideia semelhante, mas vai além da arquitetura tradicional independente por canal, onde cada canal é processado separadamente. Em vez disso, os autores do framework reúnem todas as variáveis (preços de diferentes ativos, volumes de negociação, indicadores técnicos) em um único patch, permitindo que o modelo considere naturalmente as influências cruzadas entre elas.
Inicialmente a série temporal de contexto X, que representa uma matriz de N variáveis ao longo de T passos de tempo, é dividida em vários fragmentos iguais não sobrepostos de comprimento s. Cada um desses patches contém simultaneamente dados de todos os N indicadores em s pontos no tempo, oferecendo um retrato da situação do mercado naquele intervalo. Depois disso transformamos cada fragmento em um vetor de dimensão N·s e o passamos por uma projeção linear que comprime a informação obtida em uma representação embedding compacta de dimensão d. Graças a essa operação o modelo não apenas aprende a examinar o interior de cada patch, mas também identifica automaticamente as combinações mais significativas de variáveis, seja a correlação entre ações do setor tecnológico e ações de semicondutores, ou picos sincronizados de volumes de negociação em diferentes segmentos do mercado.
Essa transição, quase explosiva, de canais separados para tokens multidimensionais traz várias vantagens imediatas. Primeiro, o modelo identifica instantaneamente fenômenos de cluster, quando a volatilidade ou as tendências de preço afetam vários ativos ao mesmo tempo. Segundo, ruídos locais e jitter aleatórios dentro de um patch são suavizados, o que reduz significativamente a quantidade de sinais falsos. E terceiro, graças ao alcance mais amplo de variáveis, ciclos ocultos e padrões de longo prazo tornam-se mais visíveis dentro de cada token, algo que na abordagem tradicional poderia passar despercebido ou ser distorcido pelo processamento independente dos canais.
Assim, K²VAE recebe na entrada não um conjunto de características separadas, mas um recorte complexo da situação de mercado já pronto para análise em cada intervalo s. Isso se torna o ponto de partida para as etapas seguintes.
Em séries financeiras reais, nos deparamos com várias manifestações de não linearidade ao mesmo tempo: as fases dos ciclos de preço podem se deslocar umas em relação às outras, as características estatísticas mudam com a divulgação de relatórios importantes e notícias repentinas rompem padrões habituais. Para domar essa complexidade, os autores do framework K²VAE colocaram as lentes de Koopman, ou seja, transferiram os tokens da zona de oscilações caóticas para um espaço onde sua evolução se torna simples e linear.
Na prática isso funciona assim. Primeiro, cada vetor embedding suavizado do patch X′ᴾ passa por uma pequena, mas poderosa, MLP, que desempenha o papel da função de medição ψ. Em termos simples, transformamos as relações complexas entre preços e indicadores em um novo vetor xᴾᵢ*, no qual a dinâmica oculta fica mais clara.
Reunindo todos esses vetores, obtemos a matriz Xᴾ, na qual cada linha já é uma projeção linearmente legível de um patch. Mas apenas olhar para isso não basta. Para entender como o sistema se move de um passo para outro, usamos o método eDMD (extended Dynamic Mode Decomposition), extraindo de Xᴾ o par anterior e seguinte e calculando o operador 𝒦loc que minimiza a divergência entre eles. Ele é treinado de modo que a primeira coluna de Xᴾ, multiplicada por 𝒦loc, reproduza com a maior precisão possível a segunda, e assim por diante até o fim da série. Essa abordagem permite estruturar localmente as regras de transição passo a passo.
Ao passar do nível local para o global, adicionamos um segundo componente treinável 𝒦glo. Juntos, eles formam o operador completo de Koopman 𝒦 = 𝒦loc + 𝒦glo. É exatamente ele que permite não apenas reconstruir os patches históricos, mas também olhar com confiança para o futuro, multiplicando a primeira projeção x₁ᴾ por 𝒦ⁿ, 𝒦ⁿ⁺¹ e assim por diante. Ao mesmo tempo, m = L/s* patches no espaço de medição correspondem diretamente a L passos nas séries originais.
Como resultado, até mesmo as interações mais complexas entre preços de ações, volumes de negociação e indicadores técnicos tornam-se linearizadas. K²VAE obtém a capacidade de construir previsões de forma rápida e precisa para qualquer horizonte, desde os minutos mais próximos até meses à frente. Ao mesmo tempo, a transparência do modelo é preservada: vemos tanto as regras locais de transição quanto as tendências globais, e a estrutura linear permite que traders e gestores de risco compreendam como determinado cenário é formado.
Depois que KoopmanNet linearizou as principais tendências e reconstruiu a sequência de contexto, inevitavelmente permanecem pequenos erros, a diferença entre as projeções reais dos patches e sua aproximação linear. Os autores do framework K²VAE não ignoram esses resíduos, pelo contrário, eles os reúnem em um único fluxo informacional de diferenças que mostram onde e quanto o modelo linear ficou aquém.
![]()
Essa matriz de discrepâncias leva em conta qualquer surpresa: gaps repentinos, saltos bruscos de volume ou choques de notícias que ainda não tiveram tempo de se refletir no operador de Koopman.
Em seguida, um integrador Transformer leve assume o papel de um orientador experiente: ele analisa toda essa não linearidade acumulada e a transforma em uma série de impulsos de controle U = [u₁, …, uₘ]. Cada vetor uₖ serve como um sinal indicando em que direção a previsão deve ser ajustada no passo k. Graças à capacidade do Transformer de considerar relações entre diferentes pontos no tempo, o modelo aprende a redistribuir informações sobre erros e corrigi-los da forma mais eficiente.
A partir desses comandos de controle, construímos o modelo clássico de processo.
![]()
Onde A é responsável pela transição básica passo a passo, B pela influência do impulso, e wₖ adiciona uma componente de ruído aleatório que reflete fatores imprevisíveis do mercado. O estado inicial z₀ é tomado do último patch real, para que o modelo comece a partir de um ponto o mais preciso possível.
Em seguida observamos a previsão obtida através do modelo de observação.
![]()
Aqui H converte o estado interno para o formato de previsão, e vₖ adiciona ruído de medição que lembra as imprecisões da própria parte linear do modelo. Como observação prioritária adotamos a previsão gerada anteriormente pelo KoopmanNet para o horizonte.
O ciclo tradicional de Previsão e Correção permite que a KalmanNet equilibre dinamicamente as previsões lineares com as informações sobre erros. Primeiro obtemos a previsão preliminar ẑₖ e a matriz de covariância P̂ₖ, que avalia a confiança do modelo.
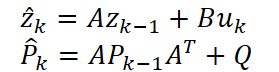
Depois, comparando-a com a observação, calculamos o coeficiente de Kalman Kₖ. Em seguida refinamos o estado e a covariância.
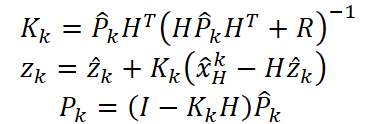
Assim, o modelo não apenas ajusta a previsão, mas também em cada passo mostra claramente o quanto compreende o mercado e onde ainda necessita de confirmação adicional.
Para não perder a informação acumulada sobre erros, os autores do framework conectam os estados finais com os impulsos por meio de uma skip connection.
![]()
Isso garante que, até que KoopmanNet e KalmanNet dominem completamente todas as nuances, o modelo utilizará todo o volume de informação disponível. À medida que o treinamento avança, o valor de U tende a zero, o que significa que a dinâmica linear se torna cada vez mais autossuficiente.
Como resultado, o framework K²VAE obtém não apenas uma previsão de preços, mas imediatamente duas estimativas relacionadas: o próprio valor e o grau de confiança nele. Para o trader e o gestor de risco isso representa um sinal duplo extremamente valioso: a previsão permite planejar operações, enquanto a covariância indica onde é necessário agir com mais cautela e onde é possível assumir mais risco. Essa abordagem transforma a negociação algorítmica, que deixa de ser uma corrida cega por previsões pontuais e passa a ser uma estratégia ponderada de gestão de riscos.
Por fim passamos para a etapa final de geração da previsão probabilística. Neste passo já temos dois resultados principais: os estados latentes corrigidos Z' e as matrizes de covariância P, que descrevem nossa confiança em cada etapa da previsão. São exatamente eles que definem a distribuição variacional da qual extrairemos amostras aleatórias de cenários futuros.
![]()
Para que os gradientes possam passar pela amostragem aleatória, os autores do framework utilizam o conhecido truque de reparametrização. Em vez de extrair diretamente Z de N(Z',P), eles geram um ruído normal padrão ϵ∈N(0,1) e constroem:
![]()
Onde L é a matriz triangular inferior da decomposição P = LLᵀ. Dessa forma, o processo em si torna-se diferenciável e os gradientes fluem livremente da função de perda para os parâmetros tanto de KalmanNet quanto de KoopmanNet.
Em seguida os autores de K²VAE retornam os vetores latentes Zsample obtidos ao formato usual de série temporal usando o decodificador, duas simétricas MLP que espelham o Koopman-Encoder original ψ. A primeira MLP, que denotaremos como ψ⁻¹μ, prevê o vetor de valores médios μ, enquanto a segunda ψ⁻¹σ, prevê o vetor de desvios padrão σ.
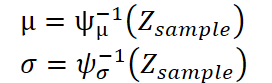
Como resultado cada amostra gerada produz um vetor de valores futuros junto com uma estimativa de dispersão, ou seja, vemos imediatamente não apenas a trajetória mais provável, mas também os limites do intervalo de confiança.
Para reforçar ainda mais a qualidade da transformação inversa, os autores do framework também alimentam ψ⁻¹μ com a sequência reconstruída X̂C.
![]()
Obtemos XRec, a partir da qual é calculado o erro de reconstrução LRec. Isso incentiva a função de medição ψ a construir um sistema realmente linear e o decodificador a retornar com precisão os dados ao espaço original de preços e indicadores.
Por fim, reunindo tudo, definimos a distribuição da previsão.
![]()
Para cada amostra o Decodificador produz o vetor μ e o vetor σ, a partir dos quais é construída uma previsão probabilística completa: mediana, intervalos de confiança e cenários extremos.
Na prática isso significa que o trader ou gestor de risco recebe imediatamente uma visão detalhada dos possíveis movimentos do mercado, desde um deslizamento conservador em um intervalo mínimo até movimentos agressivos acompanhados de volatilidade elevada. Graças à reparametrização e ao treinamento sincronizado de todos os componentes (KoopmanNet, KalmanNet e Decoder), K²VAE fornece um pipeline suave e diferenciável no qual cada iteração melhora não apenas a precisão da previsão média, mas também a confiabilidade da avaliação de riscos.
No centro do treinamento de K²VAE está um conjunto de duas funções de perda complementares que juntas formam um poderoso mecanismo de autoaperfeiçoamento do modelo. A primeira é o objetivo clássico ELBO (Evidence Lower Bound), no qual o modelo busca alcançar simultaneamente duas coisas: garantir que as trajetórias geradas Y sigam a distribuição esperada e evitar que o espaço latente Z se afaste demais de nossas representações a priori.
![]()
O primeiro termo é uma penalidade por má geração de cenários futuros: quanto pior o decodificador reproduz a distribuição Y a partir das amostras Z, maior será a penalização. O segundo termo é a divergência KL entre nosso posterior variacional Q(Z|X) e a distribuição a priori simples P(Z|X)=N(0,I). Graças a isso forçamos o espaço latente a não ultrapassar limites razoáveis e a convergir gradualmente para um estado estável no qual o sistema linear no espaço de medição se torna estável.
Mas o ELBO por si só não garante que nosso espaço de medição realmente se comporte de forma linear. Aqui entra em cena o segundo componente essencial, o erro de reconstrução.
![]()
Os autores do framework comparam a sequência original real X com sua reconstrução XRec, transformada pelo Decodificador a partir da cadeia de saída reconstruída do Koopman. Quanto mais precisamente o modelo consegue retornar os dados ao espaço original, mais corretamente e de forma mais limpa ele constrói a dinâmica linear na camada de medição. Essa função de perda atua como um suporte para a base do modelo, impedindo que a função de medição ψ se desvie do caminho da linearidade.
Como resultado, o objetivo completo de treinamento é simplesmente a soma de duas partes.
![]()
ELBO é responsável pela geração correta e por um espaço latente bem comportado, enquanto o erro de reconstrução garante o rigor da aproximação linear e a qualidade da transformação inversa. Juntas, essas funções fazem com que K²VAE não apenas aprenda a criar cenários plausíveis de evolução do mercado, mas também forme uma estrutura linear dinâmica legível e interpretável, resistente a picos atípicos de volatilidade e a picos inesperados do mercado. Isso oferece aos traders e gestores de risco não apenas uma previsão, mas uma ferramenta completa, transparente e confiável para a tomada de decisões.
A visualização do framework K²VAE apresentada pelos autores é mostrada abaixo.

Implementação com MQL5
Agora que analisamos detalhadamente todos os componentes principais do framework K²VAE, desde a linearização da dinâmica pelo KoopmanNet até o refinamento adaptativo da incerteza pelo KalmanNet e o decodificador final do VAE, é hora de levar a teoria para a prática. Na parte prática do nosso trabalho mostraremos passo a passo como implementar cada um desses módulos diretamente no ambiente MQL5, desde a preparação dos dados brutos e formação dos patches até o treinamento dos parâmetros do modelo e a geração do resultado final. Esse guia prático permitirá que você implemente gradualmente o K²VAE em suas próprias estratégias algorítmicas, preservando toda a flexibilidade e transparência da arquitetura proposta.
Como você já deve ter percebido, o núcleo de K²VAE é construído em torno de várias matrizes chave: o operador de Koopman, as matrizes de transição e de controle em KalmanNet, bem como as projeções de pesos no codificador e no decodificador. Diferentemente da hierarquia usual Convolução → Ativação → Convolução nas redes neurais padrão, aqui os mesmos parâmetros participam simultaneamente de vários pontos do pipeline. Se simplesmente copiássemos essa ideia como está, teríamos que declarar camadas MLP separadas para cada etapa e, consequentemente, duplicar os pesos. Isso não apenas reduziria a velocidade de execução e complicaria o código, mas também distorceria o conceito de um operador linear único.
Por isso precisamos encontrar uma solução alternativa que permita preservar o conceito de parâmetros compartilhados e ao mesmo tempo integrá-los ao mecanismo de treinamento existente. Nesse ponto vale lembrar um método antigo e já comprovado que utilizamos em outros projetos quando enfrentamos a necessidade de matrizes treináveis fora da hierarquia padrão de camadas de redes neurais.
A ideia consiste em implementar uma matriz treinável na forma de um MLP de duas camadas (Multi-Layer Perceptron). A primeira camada recebe um único valor fixo, 1.0, enquanto a segunda expande esse valor em toda a matriz de parâmetros necessária. Essa construção engenhosa permite utilizar os mecanismos padrão de propagação reversa e atualização de pesos mesmo para parâmetros fora da estrutura convencional.
Ou seja, na prática criamos uma pseudo camada cuja função não é processar dados de entrada, mas simplesmente gerar uma matriz paramétrica. Em uma primeira aproximação ela não tem utilidade do ponto de vista computacional, porém é exatamente por ela que passa o gradiente que treina a segunda camada, e essa segunda camada representa justamente nossas matrizes A, B, K, H ou, por exemplo, ψ.
A vantagem dessa abordagem é que ela mantém compatibilidade com a estrutura geral de treinamento de redes neurais. Não há necessidade de criar um mecanismo separado de otimização ou atualizar pesos manualmente. Tudo funciona de acordo com o processo padrão: propagação para frente → erro → distribuição do gradiente → atualização dos parâmetros.
Assim, até mesmo elementos especiais como os operadores de Koopman ou as matrizes de covariância do KalmanNet podem ser integrados à arquitetura com suporte completo ao treinamento.
Quando a tarefa exige apenas uma única matriz parametrizada, a implementação de uma pequena MLP dentro de um único objeto é totalmente adequada. Basta adicionar à estrutura algumas camadas internas, alimentar a entrada com uma constante e obter na saída a matriz necessária que será utilizada nos cálculos. Tudo é simples, transparente e não exige arquitetura adicional.
No entanto, no contexto dos algoritmos KoopmanNet e KalmanNet a situação é diferente. Aqui precisamos de todo um conjunto dessas matrizes. Utilizar implementações isoladas para cada uma delas significaria correr o risco de poluir a arquitetura e perder legibilidade.
Por isso adotamos uma solução mais universal e escalável: separar a lógica de geração das matrizes treináveis em uma classe específica, chamada CParams. Essa classe concentra toda a lógica de inicialização, armazenamento e atualização dos pesos, além de fornecer a matriz necessária no momento adequado. Isso permite:
- gerenciar os parâmetros de forma centralizada,
- escalar facilmente a arquitetura ao adicionar novas matrizes,
- utilizar uma interface única de geração,
- simplificar depuração e visualização.
A estrutura do novo objeto é apresentada abaixo e inclui um esqueleto mínimo, porém funcionalmente completo, para integração em qualquer esquema de redes neurais.
class CParams : public CNeuronBaseOCL { protected: CNeuronBaseOCL cOne; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return FeedForward(); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return UpdateInputWeights(); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return true; } virtual bool calcHiddenGradients(CNeuronBaseOCL *NeuronOCL) override { return true; } public: CParams(void) {}; ~CParams(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) override; virtual bool Identity(const int rows, const int cols); //--- virtual bool FeedForward(void); virtual bool UpdateInputWeights(void); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defParams; } virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
A principal característica da implementação é o uso de uma entrada fictícia cOne, preenchida com valores iguais a 1, que é alimentada na camada treinável. Dessa forma, a matriz resultante formada na saída torna-se o único objeto que contém os parâmetros necessários, prontos para uso direto.
Internamente CParams herda da camada base de rede neural CNeuronBaseOCL, o que o torna totalmente compatível com o restante do framework. A lógica principal de funcionamento está concentrada nos métodos FeedForward e UpdateInputWeights, que são implementados por meio da chamada dos métodos herdados com o mesmo nome usando a entrada de cOne.
A inicialização do objeto é realizada por meio da chamada do método Init, no qual são criadas as interfaces necessárias e configuradas as conexões entre os componentes.
bool CParams::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false; if(!cOne.Init(numNeurons, 0, OpenCL, 1, optimization, iBatch)) return false; cOne.SetActivationFunction(None); if(!cOne.getOutput().Fill(1)) return false; //--- return true; }
Uma implementação cuidadosa nos permite esconder toda a complexidade associadas ao suporte da propagação para frente e da propagação reversa, à otimização de parâmetros e aos buffers no contexto OpenCL, deixando ao usuário apenas a indicação declarativa da forma e da finalidade da matriz.
O resultado final é um bloco universal, escalável e reutilizável de parâmetros treináveis, adequado para grafos complexos de computação. Em outras palavras, obtemos um equivalente flexível de nn.Parameter do PyTorch, porém no ambiente MQL5 com suporte a OpenCL.
Vale destacar um detalhe importante: as operações de propagação para frente (FeedForward) no objeto CParams são executadas exclusivamente durante o treinamento. Isso é lógico, pois é nesse momento que a matriz de pesos deve ser adaptada aos erros do modelo e ajustada levando em consideração a propagação reversa.
bool CParams::FeedForward(void) { if(!bTrain) return true; //--- return CNeuronBaseOCL::feedForward(cOne.AsObject()); }
No entanto, no modo de utilização prática, ou seja, ao utilizar o modelo treinado para previsões ou tomada de decisões, a necessidade de recalcular a matriz desaparece. A matriz obtida durante o treinamento torna-se um parâmetro estático. Ela não é mais modificada e não exige a execução de operações adicionais, especialmente chamadas custosas de kernels OpenCL.
Assim, ao passar para o modo de operação, na prática fixamos os parâmetros e podemos desativar com segurança a propagação para frente, eliminando cálculos desnecessários. Isso reduz a carga sobre os recursos computacionais, acelera a execução do modelo e aumenta sua estabilidade.
Essa abordagem é um exemplo clássico de separação das fases de computação, em que treinamento e utilização são claramente diferenciados tanto na lógica quanto na carga de processamento. Isso torna a arquitetura não apenas mais clara e flexível, mas também mais previsível na prática, o que é especialmente importante em sistemas de tempo real.
O código completo do objeto CParams e de todos os seus métodos é apresentado no anexo.
Já realizamos um trabalho enorme: analisamos os fundamentos teóricos do framework K²VAE, examinamos detalhadamente os módulos principais e até implementamos o objeto CParams, um gerador universal de matrizes parametrizadas indispensável na arquitetura do modelo. Agora temos diante de nós uma tarefa mais ampla: estruturar a lógica clara e coerente de todo o framework, em que cada detalhe seja um componente importante dentro de um mecanismo bem ajustado.
Mas não há motivo para pressa aqui. Configurar esse sistema exige clareza mental, atenção e um olhar renovado. Exatamente por isso fazemos uma pausa até o próximo artigo e voltamos com novas energias e inspiração renovada.
Considerações finais
Neste artigo conhecemos o poderoso e promissor framework K²VAE, que combina as vantagens da dinâmica linear, da inferência variacional e da filtragem treinável. Sua principal força está na capacidade de aproximar linearmente processos não lineares complexos no espaço latente, permanecendo ao mesmo tempo estável diante de ruídos e desvios sistêmicos. Isso oferece não apenas um modelo, mas uma ferramenta com alto grau de interpretabilidade, flexibilidade e precisão, especialmente relevante para tarefas de análise de série temporal e previsão da dinâmica de mercado.
Estamos apenas começando a desvendar o conjunto de ideias que sustenta o framework K²VAE. Neste artigo foram dados os primeiros passos, desde os fundamentos teóricos até a implementação de componentes principais, como as matrizes parametrizadas e a classe universal CParams, que assumiu toda a carga do gerenciamento de pesos fora da arquitetura padrão de redes neurais. Isso se tornou uma etapa importante na preparação para construir a lógica completa do modelo.
No entanto, ainda há muito trabalho pela frente. Precisaremos unir os elementos dispersos em um sistema único e bem estruturado: implementar os mecanismos de filtragem, organizar a dinâmica probabilística no espaço latente, reunir em um todo a arquitetura do Codificador, do Integrador, da KalmanNet e do Decodificador. A tarefa não é simples, mas é exatamente ela que permitirá ao modelo tornar-se um sistema realmente inteligente de tomada de decisão.
Não estamos encerrando o assunto, estamos apenas traçando a trajetória. O principal desenvolvimento ainda está por vir. Por isso faz sentido fazer uma pequena pausa para continuar o caminho com novas energias na próxima parte.
Links
- K²VAE: A Koopman-Kalman Enhanced Variational AutoEncoder for Probabilistic Time Series Forecasting
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA de treinamento offline dos modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA de treinamento online dos modelos |
| 3 | Test.mq5 | Expert Advisor | Expert Advisor para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18734
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso