
Redes neurais em trading: Segmentação periódica adaptativa (Conclusão)

Introdução
Nos trabalhos anteriores analisamos passo a passo como o framework LightGTS transforma séries temporais em partituras musicais. Primeiro, no módulo Period Patching, os dados analisados são automaticamente divididos em ciclos completos, determinados por meio de FFT. Em seguida, cada ciclo é projetado em um token com a ajuda da Flex Projection Layer, que permite processar de forma flexível fragmentos de diferentes comprimentos. No codificador, esses tokens são enriquecidos com Rotary Positional Encoding (RoPE), um método compacto para incorporar deslocamentos de fase e posições relativas, após o que blocos clássicos de Transformer com atenção multi-cabeça unem padrões locais em um único contexto. Para gerar a previsão é utilizado o mecanismo Periodical Parallel Decoding, que cria instantaneamente toda a sequência de saída sem autorregressão. O resultado é ajustado no módulo Flex-resize, que preserva a consistência periódica.

Neste ponto já implementamos com sucesso no código as ideias-chave do LightGTS: aprendemos a dividir automaticamente a série temporal em fragmentos periódicos por meio de patching adaptativo e a transformar cada um deles em um token informativo. Também adicionamos nossos próprios ajustes aos algoritmos originais, refinamos a lógica de projeção flexível e obtivemos representações prontas dos ciclos locais do mercado. Hoje daremos o próximo passo no caminho de construir nossa própria visão das abordagens propostas pelos autores do framework LightGTS.
Mecanismo RoPE
Depois que a convolução adaptativa extraiu da série temporal bruta um conjunto concentrado de tokens informativos, chega o momento de passá-los por um poderoso filtro de blocos Transformer. Na arquitetura Encoder–Decoder tradicional, vetores de codificação posicional sinusoidal ou treinável são simplesmente adicionados a esses tokens, após o que eles são enviados ao mecanismo de atenção. Os autores do framework LightGTS propõem utilizar um método muito mais elegante e flexível, Rotary Positional Encoding (RoPE). Em vez de vetores fixos de codificação de posição, cada token é rotacionado no espaço de incorporação.
A ideia principal do RoPE consiste em introduzir um deslocamento vetorial de fase proporcional à posição do token e às suas dimensões, sem recorrer a parâmetros adicionais. Vale observar que essa técnica foi apresentada pela primeira vez no trabalho "RoFormer: Enhanced Transformer with Rotary Position Embedding", no qual os autores demonstraram que a rotação de pares de coordenadas das entidades Query e Key por meio de uma matriz de rotação permite ao modelo capturar de forma confiável deslocamentos relativos no tempo.
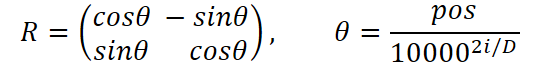
O método é facilmente generalizado para espaços multidimensionais dividindo a dimensão em pares de valores. Daí surge uma limitação, a dimensão do espaço deve ser par.

Graças a essa rotação, mesmo com tamanho variável das janelas e passo dinâmico, o modelo entende com precisão quais tokens estão mais próximos no tempo e quais estão mais distantes. Como resultado, o mecanismo Self-Attention transforma-se em um detector extremamente sensível de padrões temporais, pois ele não apenas compara o conteúdo de Query e Key, mas também leva em consideração as diferenças de fase entre os tokens. Como consequência, após várias camadas de atenção multi-cabeça e Feed-Forward, os tokens já saem profundamente contextualizados.
Agora que mergulhamos nas bases matemáticas e conceituais do Rotary Positional Encoding, é hora de descer ao caldeirão da implementação e observar como tudo isso pode ser traduzido para o código de um programa OpenCL. Já possuímos tokens prontos, um array de vetores, cada um com D dimensões. Além disso, prepararemos previamente tabelas de senos e cossenos para cada posição. Nossa tarefa consiste em rotacionar cada vetor no espaço de incorporação de forma que a fase reflita a marca temporal, sem perder a velocidade geral do pipeline. Para isso criamos o kernel RoPE, que opera em um espaço tridimensional de tarefas. A primeira dimensão corresponde ao índice do par de coordenadas dentro do vetor. Sua dimensão é igual à metade do comprimento do vetor. A segunda dimensão indica o comprimento da sequência, isto é, o número de tokens. A terceira indica o número de sequências unitárias.
Observe que, para facilitar o trabalho com pares de valores, utilizamos o tipo vetorial de representação de dados float2.
__kernel void RoPE(__global const float2* __attribute__((aligned(8))) inputs, __global const float2* __attribute__((aligned(8))) position_emb, __global float2* __attribute__((aligned(8))) outputs ) { const size_t id_d = get_global_id(0); // dimension const size_t id_u = get_global_id(1); // unit const size_t id_v = get_global_id(2); // variable const size_t dimension = get_global_size(0); const size_t units = get_global_size(1); const size_t variables = get_global_size(2);
No corpo do kernel primeiro identificamos as coordenadas do fluxo atual de operações no espaço tridimensional de tarefas. Isso é necessário para que cada fluxo saiba exatamente com qual fragmento de dados deverá trabalhar, qual par de coordenadas do vetor precisa processar, a qual token ele pertence e de qual variável, ou canal, ele vem.
Assim que as coordenadas do fluxo são conhecidas, o próximo passo consiste em calcular os deslocamentos nos arrays planos dos buffers OpenCL. Apesar da lógica possuir estrutura multidimensional, todos os dados em OpenCL são armazenados de forma linear e, por isso, é necessário calcular manualmente onde exatamente na memória se encontra o elemento de interesse.
const int shift_in = (id_v * units + id_u) * dimension + id_d; const int shift_pos = id_u * dimension + id_d; const float2 inp = inputs[shift_in]; const float2 pe = position_emb[shift_pos];
Para reduzir ao mínimo os acessos custosos à memória global, carregamos imediatamente o par inicial de coordenadas e os fatores correspondentes de seno e cosseno em variáveis vetoriais locais, uma espécie de registradores de trabalho do kernel. Cada acesso aos buffers da memória global é significativamente mais caro do que operar com vetores já armazenados localmente. Isso permite praticamente eliminar recargas repetidas da memória global e manter os dados mais utilizados nos registradores ou na memória local da GPU, o que acelera consideravelmente todo o processo de rotação dos tokens e torna a execução do kernel o mais eficiente possível.
Quando todos os ingredientes, dados originais e valores sin/cos estão à mão, estamos prontos para iniciar a ação principal, o deslocamento de fase. É exatamente ele que dá aos tokens a percepção do tempo e garante o funcionamento correto do mecanismo de atenção.
float2 result = 0; result.s0 = inp.s0 * pe.s0 - inp.s1 * pe.s1; result.s1 = inp.s0 * pe.s1 + inp.s1 * pe.s0; //--- outputs[shift_in] = result; }
Aqui utilizamos operações aritméticas simples sobre variáveis locais, quatro multiplicações e duas somas para cada par de valores. Graças ao carregamento prévio dos dados, esta etapa é executada quase instantaneamente.
Depois disso, o par de coordenadas rotacionado é imediatamente gravado no buffer de resultados.
Esse é todo o truque. Por meio de uma simples multiplicação pelos valores cos e sin previamente preparados, atribuímos a cada token a informação de fase e de tempo relativo, sem adicionar um único novo parâmetro. Como resultado, esse kernel demonstra:
- Paralelismo máximo, cada fluxo de operações trabalha de forma independente.
- Sobrecarga zero no treinamento, a codificação posicional não contém parâmetros treináveis.
- Integração perfeita com os módulos de atenção subsequentes, as incorporações levam em consideração não apenas o conteúdo dos tokens, mas também suas diferenças de fase.
Apesar de o RoPE não introduzir no modelo nenhum parâmetro treinável, é importante que os gradientes possam fluir corretamente através dessa camada, retornando aos dados originais. Para isso criamos um kernel especial de propagação reversa CalcHiddenGradRoPE, que executa a rotação inversa dos vetores.
A ideia é simples. O kernel de propagação para frente multiplicava os dados originais (x, y) por uma matriz de rotação. No sentido inverso precisamos aplicar sua versão transposta, isto é, uma rotação por −θ, onde cos(−θ)=cosθ e sin(−θ)=−sinθ.
O algoritmo do kernel de propagação reversa é praticamente idêntico ao analisado acima para a propagação para frente. Utiliza-se o mesmo espaço de tarefas e os deslocamentos nos buffers globais de dados são determinados de maneira análoga. A pequena diferença aparece apenas na etapa de rotação dos vetores. Além disso, os dados de entrada para a execução das operações são os gradientes de erro no nível dos resultados.
__kernel void CalcHiddenGradRoPE(__global float2* __attribute__((aligned(8))) inputs_gr, __global const float2* __attribute__((aligned(8))) position_emb, __global const float2* __attribute__((aligned(8))) outputs_gr ) { const size_t id_d = get_global_id(0); // dimension const size_t id_u = get_global_id(1); // unit const size_t id_v = get_global_id(2); // variable const size_t dimension = get_global_size(0); const size_t units = get_global_size(1); const size_t variables = get_global_size(2); //--- const int shift_in = (id_v * units + id_u) * dimension + id_d; const int shift_pos = id_u * dimension + id_d; const float2 grad = outputs_gr[shift_in]; const float2 pe = position_emb[shift_pos]; //--- float2 grad_x; grad_x.s0 = grad.s0 * pe.s0 + grad.s1 * pe.s1; grad_x.s1 = grad.s1 * pe.s0 - grad.s0 * pe.s1; //--- inputs_gr[shift_in] = grad_x; }
Não há desvios condicionais nem fórmulas complexas, apenas quatro multiplicações e um par de somas. Graças a isso, os gradientes da camada RoPE são revertidos com a mesma rapidez e economia com que os tokens foram rotacionados na propagação para frente.
Como resultado, CalcHiddenGradRoPE transforma a camada RoPE em um participante completo do processo de treinamento. Podemos incluí-la em qualquer profundidade da rede, e ela retornará os gradientes aos tensores de entrada sem perdas, preservando a velocidade e o paralelismo da execução.
Agora que nossos kernels OpenCL para Rotary Positional Encoding estão totalmente refinados, chegou o momento de levar esse poder para o ambiente MQL5 e conectá-lo a um robô de trading. Já temos um mecanismo pronto de rotação de tokens na GPU, resta apenas criar uma pequena camada de encapsulamento que se encaixe na estrutura habitual dos EAs em MQL5. É exatamente para isso que criaremos a classe CNeuronRoPE, cuja estrutura é apresentada abaixo.
class CNeuronRoPE : public CNeuronPositionEncoder { protected: uint iWindow; uint iVariables; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL)override; public: CNeuronRoPE(void) : iWindow(0), iVariables(0) {}; ~CNeuronRoPE(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronRoPE; } };
Na classe CNeuronRoPE tudo é organizado da forma mais simples possível. Ela possui apenas duas variáveis, iWindow, que define a dimensionalidade do vetor de um único token, e iVariables, que define o número de canais. Todo o restante da funcionalidade pesada, relacionada aos buffers e à verificação de parâmetros, é herdado de CNeuronPositionEncoder, portanto o construtor e o destrutor permanecem vazios. A base do funcionamento de toda a camada é definida no método Init.
bool CNeuronRoPE::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint count, uint window, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(window % 2 > 0) return false; if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, count * window * variables, optimization_type, batch)) return false;
Logo no início do método realizamos uma verificação simples, porém extremamente importante, a dimensionalidade de cada token deve ser par, pois o RoPE opera com pares de coordenadas. Sem esse postulado condicional não é possível avançar, pois não poderíamos rotacionar de forma inequívoca os pares de valores. Após passar com sucesso por esse ponto de controle, transferimos o controle para o método com o mesmo nome da classe pai, no qual já estão organizados os demais pontos de controle e o algoritmo de inicialização das interfaces herdadas.
Em seguida salvamos os parâmetros do tensor dos dados originais nas variáveis internas.
iWindow = window; iVariables = variables;
Depois passamos à construção da matriz de incorporação fundamental para o RoPE, um array bidimensional no qual nas colunas pares estará cos(θ) e nas colunas ímpares estará sin(θ).
No início criamos a matriz pe com o tamanho necessário. Trata-se de uma estrutura que preencheremos imediatamente com valores de seno e cosseno. Para compreender como cada coluna da matriz responderá ao seu passo da série temporal, no início formamos um vetor de posições, a partir de um vetor unitário criamos a soma de prefixos e subtraímos uma unidade, obtendo [0, 1, 2, …, count–1]. É exatamente esse vetor que indica qual passo estamos codificando no momento.
matrix<float> pe = matrix<float>::Zeros(count, iWindow); vector<float> position = vector<float>::Ones(count); position = position.CumSum() - 1;
Em seguida ocorre a etapa principal, percorremos todos os pares de dimensionalidades, pois cada par de coordenadas do token requer seus próprios ângulos. Para cada par pegamos o vetor de posições e o dividimos por um denominador crescente igual a pow(10000, 2 * i / iWindow), com o objetivo de reduzir a velocidade de rotação das dimensões superiores e acelerar as inferiores. Como resultado obtemos um array de ângulos, não simples números, mas um vetor θ para todas as posições.
for(uint i = 0; i < iWindow / 2; i++) { vector<float> temp = position / MathPow(10000.0f, 2.0f * i / window); pe.Col(MathCos(temp), i * 2); pe.Col(MathSin(temp), i * 2 + 1); }
Depois, em cada coluna par da matriz pe gravamos os cossenos dos ângulos obtidos, e na coluna vizinha ímpar gravamos os senos. Assim a matriz se transforma em uma verdadeira fábrica, onde cada coluna possui seu par de valores [cos(θ), sin(θ)], prontos para rotacionar qualquer token. Todos esses cálculos são executados apenas uma vez no código da CPU, para depois transmitir aos kernels da GPU um conjunto de funções já preparado.
A matriz preenchida é enviada ao buffer de dados e finalizamos o método retornando à aplicação chamadora um resultado lógico da execução das operações.
PositionEncoder.BufferFree(); if(!PositionEncoder.AssignArray(pe)) return false; SetActivationFunction(None); //--- return PositionEncoder.BufferCreate(open_cl); }
Graças a essa abordagem, nossos kernels OpenCL recebem como entrada uma tabela pronta de senos e cossenos e podem operar em potência máxima, sem se distrair com operações matemáticas adicionais.
Como resultado, toda a configuração inicial fica concentrada em um único método, basta alterar os parâmetros window ou variables e a camada se adapta imediatamente às novas condições. Esse método garante que o código permaneça rigoroso e claro, ao mesmo tempo em que mantemos controle total sobre o comportamento do módulo RoPE.
Quando chega a etapa da propagação para frente, basta simplesmente chamar o método feedForward, passando a ele um ponteiro para o objeto de dados de origem já preenchido com tokens. Sob o capô o método presta atenção aos detalhes, verifica a validade do ponteiro recebido, configura o enfileiramento do kernel RoPE com os tamanhos corretos do grupo de trabalho, aguarda sua conclusão e retorna o controle. Na saída obtemos um buffer de tokens rotacionados, prontos para serem enviados ao módulo de atenção.
Durante o processo de treinamento entra em cena o método calcInputGradients. Esse método executa o kernel CalcHiddenGradRoPE. A própria lógica é praticamente um espelho da propagação para frente, as mesmas coordenadas e os mesmos deslocamentos, porém a rotação ocorre na direção inversa para retornar o gradiente à representação original. O resultado final é cuidadosamente colocado no buffer de gradientes da entrada e flui sem obstáculos para as camadas anteriores do modelo.
Ambos os métodos, na essência, são encapsulamentos dos kernels correspondentes e são construídos com base no algoritmo que já lhe é familiar. Por isso não nos deteremos em sua análise detalhada neste artigo. O código completo da classe apresentada e de todos os seus métodos pode ser consultado no anexo.
Agora que os tokens passaram pelo filtro de fase do RoPE, eles estão prontos para entrar no coração do modelo, o módulo de atenção. O framework LightGTS por padrão constrói sua lógica em torno do esquema clássico Codificador–Decodificador, e não precisaremos reinventar nada, pois todos os componentes necessários já existem em nossa biblioteca. Basta enviar os tokens rotacionados para um dos módulos existentes de Self-Attention, onde a atenção multi-cabeça funcionará de forma eficaz, conectando padrões locais ao contexto global da série temporal.
Na versão original do LightGTS, os autores propõem que após o codificador seja tomado o último token oculto e replicado exatamente tantas vezes quanto necessário para cobrir o horizonte de planejamento especificado, para que o decodificador possa gerar imediatamente toda a sequência de saída. Nós demos um passo ousado em direção à simplificação, não precisamos de replicação. Primeiro, nossa tarefa não é obter números extremamente precisos, mas extrair da representação latente toda a informação valiosa para o Agente que tomará as decisões de trading. Segundo, executamos os cálculos a cada nova barra, e isso sempre é mais curto do que um ciclo completo de periodicidade do mercado. Portanto, um único último token para cada sequência unitária é totalmente suficiente.
Assim, ignorando múltiplas cópias, enviamos esse último embedding pela via principal diretamente ao decodificador. Ali ele encontra novamente a mesma atenção multi-cabeça e Feed-Forward, porém sem repetições desnecessárias, o modelo se baseia em uma representação limpa e concentrada que contém toda a informação atual sobre os movimentos recentes do mercado. Essa abordagem economiza recursos, simplifica a lógica e permite que o Agente aja com máxima rapidez, pois cada barra exige uma reação imediata e precisamos não de mil cópias do token, mas de um único sinal forte pronto para levar ao lucro.
Arquitetura dos modelos
Finalmente chegamos ao ponto culminante, o momento em que todos os módulos cuidadosamente ajustados se unem em um único sistema que funciona de forma coordenada. Em nosso projeto MQL5 isso ocorre na função CreateDescriptions, onde passo a passo construímos sete ramos da rede neural: o codificador, três fluxos de previsão e três componentes do Agente — Actor, Director e Critic.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&forecast1, CArrayObj *&forecast2, CArrayObj *&forecast3, CArrayObj *&actor, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!forecast1) { forecast1 = new CArrayObj(); if(!forecast1) return false; } if(!forecast2) { forecast2 = new CArrayObj(); if(!forecast2) return false; } if(!forecast3) { forecast3 = new CArrayObj(); if(!forecast3) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Primeiro verificamos a correção dos ponteiros para os arrays dinâmicos de cada um dos contêineres. Caso algum deles ainda não tenha sido criado, alocamos cuidadosamente memória para um novo array dinâmico. Esses contêineres se tornarão o esqueleto sobre o qual serão adicionadas as descrições das camadas neurais do nosso modelo.
No codificador tudo começa com uma camada totalmente conectada básica, para a qual chegam os dados brutos, uma sequência de barras históricas, cada uma descrita por um conjunto de características.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida introduzimos a normalização em lote com adição de ruído, que suaviza gradualmente a distribuição das ativações. Depois disso passamos à primeira operação sobre os dados brutos, na qual são extraídas as diferenças entre pontos vizinhos da série. Isso nos permite enfatizar a dinâmica das mudanças.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatDiff; prev_count = descr.count = HistoryBars; descr.layers = BarDescr; descr.step = 1; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
A próxima camada adiciona harmônicas das marcas temporais aos dados brutos, transformando cada barra não apenas em um conjunto de características de preço e volume, mas também em um ponto na escala temporal.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = 2 * BarDescr; uint prev_out = descr.window_out = NSkills; { uint temp[] = {PeriodSeconds(PERIOD_H1), PeriodSeconds(PERIOD_D1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count;
Depois disso transpomos o resultado para prepará-lo para envio à convolução adaptativa CNeuronAdaptConv. À primeira vista isso pode parecer apenas uma operação técnica comum, porém é exatamente nesse momento que ocorre a transição principal, reorganizamos a estrutura dos dados de forma que cada sequência unitária possa ser dividida em patches adaptativos, segmentos compactos e localizados da série temporal que contêm padrões locais.
Isso permite que CNeuronAdaptConv se adapte de forma flexível ao caráter dos dados brutos. Alguns patches capturam movimentos impulsivos, outros capturam trechos de estabilidade ou oscilações. Na prática não estamos entregando ao modelo apenas um array plano de valores, mas uma representação estruturada com uma hierarquia espaço-temporal claramente definida. Graças a isso o codificador ganha a capacidade de preservar tanto o contexto de curto prazo quanto identificar padrões profundos e ocultos em séries temporais complexas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAdaptConv; descr.count = Segments; descr.window = 2*prev_out/Segments; descr.variables = prev_count; prev_out = descr.window_out = EmbeddingSize; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_count = descr.count; uint prev_var = descr.variables;
O próximo passo é o RoPE (Rotary Positional Embedding), um mecanismo que à primeira vista pode parecer redundante, considerando que as marcas temporais já foram adicionadas aos dados brutos. No entanto a principal diferença aqui está no nível de aplicação.
As marcas temporais adicionadas pertencem a barras individuais, isto é, aos dados brutos. Elas servem para fixar as coordenadas temporais absolutas de cada observação antes do início do processamento estrutural.
Depois disso os dados passam pela etapa de patching, como resultado da qual cada grupo de barras consecutivas é combinado em segmentos. Esse segmento então é transformado em um único token, uma representação agregada de um trecho temporal local. É exatamente a esses tokens obtidos que o RoPE é aplicado.
Dessa forma o RoPE não codifica posições dentro do patch, pois nesse estágio elas já foram condensadas em uma única representação. Em vez disso ele incorpora informação sobre a posição do próprio patch dentro da sequência geral. Em outras palavras, RoPE permite que o modelo compreenda em que ordem os patches aparecem em relação uns aos outros, algo fundamental para a análise da estrutura global da série temporal analisada.
Esse posicionamento do RoPE faz dele um complemento ideal: Em conjunto com as marcas temporais no nível das barras, ele fornece consciência temporal hierárquica, desde os valores detalhados no nível das barras até as posições relativas dos blocos agregados.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRoPE; descr.count = prev_count; descr.window = prev_out; descr.variables = prev_var; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Após aplicar o RoPE realizamos novamente a transposição dos dados, desta vez com o objetivo de permitir que o próximo módulo Multi-Head Self-Attention leia de forma eficiente o array de vetores de tokens levando em conta sua sequência cronológica. Trata-se de um passo puramente técnico, porém importante, pois o mecanismo de atenção precisa enxergar os dados na forma correta. Caso contrário obteríamos apenas caos, e não uma comparação ponderada entre os tokens.
Em seguida entra em ação o Self-Attention, configurado com os parâmetros de 4 cabeças de atenção e 3 camadas sequenciais. Essa arquitetura permite que o modelo analise em paralelo diferentes aspectos das relações entre os tokens, cada cabeça concentra-se em seu próprio subespaço de características. É como se fossem 4 especialistas, cada um avaliando à sua maneira a importância das conexões entre os patches.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeRCDOCL; descr.count = prev_var; descr.window = prev_count; descr.step = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronComplexMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_out / 2 * prev_var; descr.window_out = descr.window / 4; descr.layers = 3; descr.step = 4; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui vale destacar um ponto importante: o mecanismo RoPE não é apenas uma forma de adicionar informação de ordem. Ele realiza a rotação dos vetores de tokens no plano complexo utilizando elementos da matemática complexa. Essa abordagem permite levar explicitamente em conta a posição relativa dos tokens, incorporando deslocamentos de fase nas incorporações.
É justamente por isso que, diferentemente da implementação original do framework LightGTS, na qual foi utilizado um Self-Attention comum, aplicamos deliberadamente a versão complexa do módulo de atenção CNeuronComplexMLMHAttentionOCL. Isso garante coerência matemática, pois se a codificação posicional é realizada no domínio complexo, então a camada de atenção também deve ser capaz de operar com grandezas complexas.
Como resultado o modelo ganha a capacidade não apenas de enxergar as relações entre os tokens, mas também de considerar seus deslocamentos de fase, algo extremamente importante ao trabalhar com estruturas periódicas e ondulatórias das séries temporais financeiras. Três camadas de atenção fornecem profundidade ao processamento, permitindo modelar tanto dependências locais quanto dependências mais distantes na série temporal. Dessa forma é construída uma representação contextual rica, uma espécie de visão comprimida de toda a sequência preparada para as próximas etapas do modelo.
Como decodificador utilizamos o módulo CNeuronTimeMoEAttention, que combina o poder da atenção multi-cabeça com a mecânica elegante da mistura esparsa de especialistas (MoE). Esse módulo foi desenvolvido especialmente para a análise eficiente de séries temporais e para a construção de representações latentes expressivas, algo particularmente importante em aplicações financeiras nas quais cada detalhe da dinâmica temporal possui relevância.
Uma inovação importante é a substituição do bloco FeedForward clássico por um bloco de mistura esparsa de especialistas, CNeuronTimeMoESparseExperts. Essa abordagem permite distribuir de forma flexível e eficiente os recursos computacionais entre diferentes especialistas, cada um analisando sua própria parte das características, o que aumenta a qualidade do processamento e reduz a redundância.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTimeMoEAttention; descr.window_out = EmbeddingSize; { uint temp[] = {prev_out, prev_out, 8, TopK}; //Window Main, Window Cross, Experts dimension, TopK if(ArrayCopy(descr.windows, temp) < ArraySize(temp)) return false; } { uint temp[] = {prev_var, prev_var * prev_count, NExperts}; //Units Main, Units Cross, Experts if(ArrayCopy(descr.units, temp) < ArraySize(temp)) return false; } descr.layers = 3; descr.step = 4; // Attention heads descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }//--- CLayerDescription *latent = descr;
Como resultado do funcionamento do codificador dos estados do ambiente, obtemos uma representação latente compacta, porém expressiva, dos dados analisados.
Essa representação não é apenas um conjunto de vetores. Trata-se de uma descrição refinada e rica da situação atual do mercado, na qual são preservadas todas as características mais importantes da dinâmica, da sazonalidade e das anomalias de curto prazo. O codificador parece absorver o comportamento do mercado, filtra o ruído e concentra a essência, transmitindo-a na forma de tokens de formato compacto.
Esses tokens não armazenam toda a história. Em vez disso eles acumulam significado, agregam relações de causa e efeito e isolam os fatores mais importantes. São exatamente esses tokens que passam a ser a fonte universal de conhecimento para todos os demais componentes do sistema: os blocos de previsão, o módulo de tomada de decisões (Actor) e os avaliadores (Director e Critic).
Na prática o codificador em nossa arquitetura é o único canal de compressão semântica pelo qual passa toda a informação histórica e atual do mercado. O resultado de seu funcionamento pode ser comparado a uma fotografia de alta qualidade de uma cena complexa, comprimida, porém nítida, rica em detalhes que são importantes para a análise posterior e para a tomada de decisões.
Durante o processo de treinamento, para formar um espaço latente rico e estável, utilizamos três modelos de previsão paralelos, cada um trabalhando com um horizonte de planejamento diferente. Essa abordagem permite que nosso codificador capture tanto impulsos de curto prazo quanto tendências de mercado de longo prazo, sem perder a capacidade de generalização.
Cada um desses modelos recebe acesso à mesma saída do codificador, porém é treinado com seu próprio alvo correspondente ao horizonte de planejamento específico. Durante a propagação reversa do erro, os gradientes de todos os três modelos são agregados, permitindo que o codificador seja treinado simultaneamente para uma tarefa multidimensional:
- ser rápido e preciso no horizonte mais próximo;
- manter estabilidade diante do ruído do mercado;
- não perder a orientação estratégica.
Dessa forma, já na etapa de treinamento fazemos com que o espaço latente absorva diferentes níveis da lógica de mercado, o que posteriormente oferece uma vantagem significativa a todos os demais componentes do sistema. O estado formado por esse codificador é igualmente adequado tanto para a geração de decisões de trading (Actor) quanto para a avaliação de sua qualidade (Critic e Director).
A arquitetura dos modelos de previsão foi completamente transferida de nossos trabalhos anteriores sem alterações. Como ela já demonstrou bom desempenho em várias tarefas, não faz sentido analisar seus detalhes neste artigo.
No entanto, a arquitetura do Actor (Actor) passou por melhorias significativas, destinadas a aumentar a adaptabilidade e a expressividade da política. A estrutura atualizada inclui sete níveis, cada um adicionando capacidades específicas ao modelo. No início, assim como antes, é utilizada uma camada totalmente conectada básica, na qual transmitimos informações sobre o estado atual da conta e as posições abertas.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida aplica-se a normalização em lote para estabilizar o treinamento e alinhar a escala das características obtidas de diferentes fontes.
A camada de atenção cruzada multi-cabeça permite que o modelo compare o estado atual da conta com o contexto da situação de mercado analisada, que é recebido do codificador do estado do ambiente.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { uint temp[] = {AccountDescr, // Inputs window latent.windows[0] // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {1, // Inputs units latent.units[0] // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; // Heads descr.window_out = 8; descr.batch = 1e4; descr.layers = 2; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Graças à arquitetura de atenção em dois níveis com quatro cabeças, o modelo consegue selecionar aspectos relevantes do contexto para gerar ações.
Em seguida vem uma MLP de tomada de decisão com três camadas. Aqui cada camada utiliza sua própria função de ativação. A tangente hiperbólica permite comprimir os tokens em um espaço contínuo compacto com sensibilidade reforçada às fronteiras.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = BatchSize; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Depois vem uma não linearidade suave que preserva valores positivos. Isso é importante para gerar os parâmetros das ações.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = SoftPlus; descr.batch = BatchSize; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
E forma os logits para a amostragem posterior das ações. O número duplo de saídas está relacionado à parametrização da média e da variância no espírito das políticas probabilísticas.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SoftPlus; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A introdução de uma camada variacional permite gerar ações de forma estocástica, mantendo ao mesmo tempo controle sobre a distribuição. Isso aumenta a capacidade de exploração do Agente.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A etapa final é uma convolução aplicada às ações já geradas. Isso permite reforçar dependências locais entre os parâmetros das ações e introduzir filtros probabilísticos suaves, que transformam a ação para o intervalo [0, 1].
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
De modo geral, a nova arquitetura do módulo Actor demonstra uma interação mais profunda com o contexto, alta variabilidade de comportamento e capacidade de considerar dependências históricas ao tomar decisões de trading.
Os modelos de avaliação Director (Director) e Critic (Critic), assim como os componentes de previsão, foram transferidos sem quaisquer alterações de trabalhos anteriores. Essa parte da arquitetura já foi testada ao longo do tempo e demonstrou bons resultados no treinamento de Agentes. A arquitetura completa de todos os componentes treináveis é apresentada no anexo.
Teste
O processo de treinamento do modelo foi dividido em duas etapas, o que permitiu construir o sistema de forma sequencial, confiável e sem pressa.
Primeiro realizamos o treinamento offline. Para isso foram utilizados 15 anos de histórico do par EURUSD no timeframe M1. Esse volume de dados cobre uma enorme variedade de situações de mercado, desde longos períodos de consolidação até tendências rápidas, desde trechos estáveis até períodos de alta volatilidade. O modelo recebeu uma oportunidade única de observar como o mercado se comporta em diferentes condições. O codificador aprendeu a reconhecer padrões, identificar estruturas significativas e codificar o estado do mercado em um vetor de características compacto e rico. Esse vetor se torna a base para todas as decisões que o Agente tomará posteriormente. O Actor durante o processo de treinamento aprendeu a estratégia de comportamento com base nos sinais de retorno do Critic e do Director, o que permitiu formar um modelo de comportamento estável e coerente.
Depois passamos para a segunda etapa, o ajuste online do modelo utilizando dados históricos de 2024. Aqui o treinamento foi transferido para condições próximas do tempo real: o modelo interagia com o mercado no regime vela a vela, enfrentando ruído de mercado, oscilações aleatórias e distorções temporais. Graças a isso foi possível não apenas continuar o treinamento do modelo, mas também adaptar seu comportamento à dinâmica real do mercado, ajustar a estratégia e aumentar a robustez em condições de incerteza.
Após a conclusão do treinamento realizamos um teste completo com novos dados, as cotações de Janeiro–Março 2025. Todas as configurações foram fixadas antecipadamente e não foram alteradas durante o teste. Isso garantiu objetividade e transparência na avaliação, excluindo qualquer forma de ajuste ou intervenção. Os resultados do teste são apresentados abaixo.
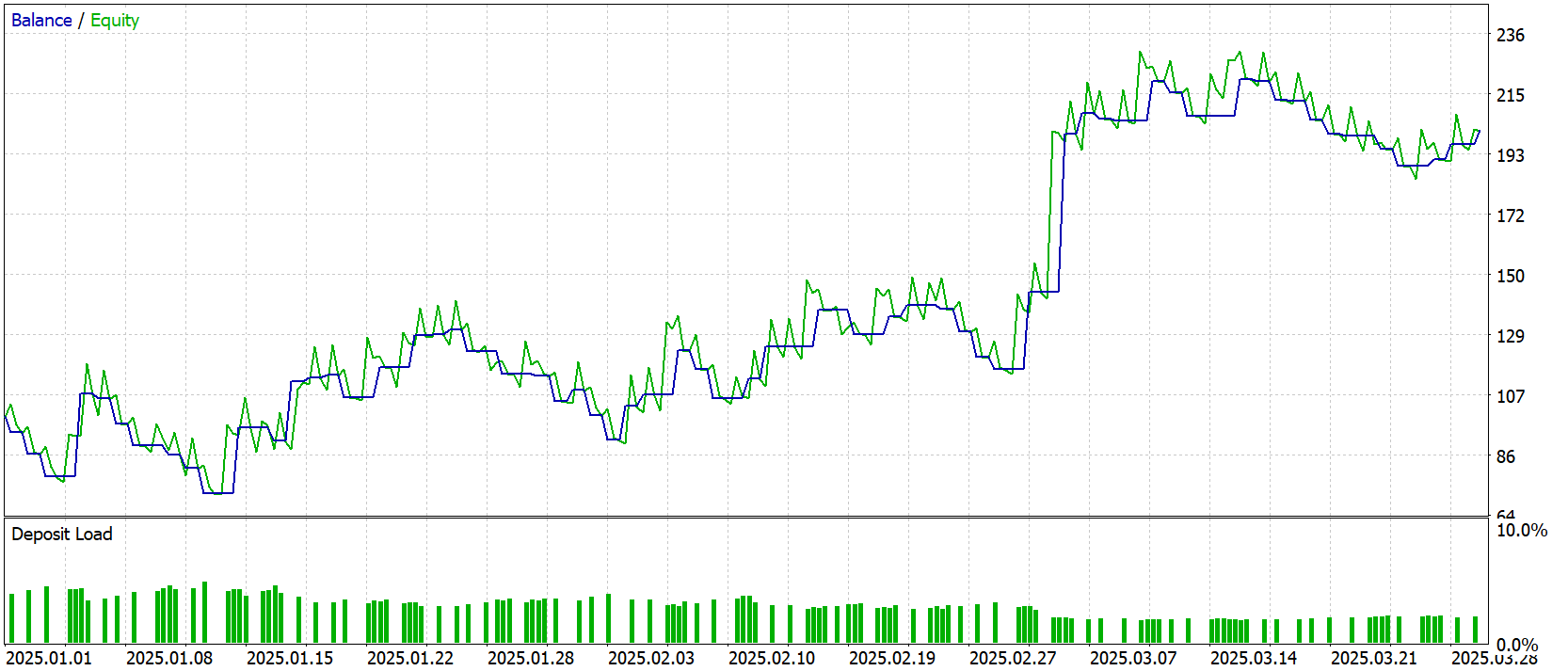
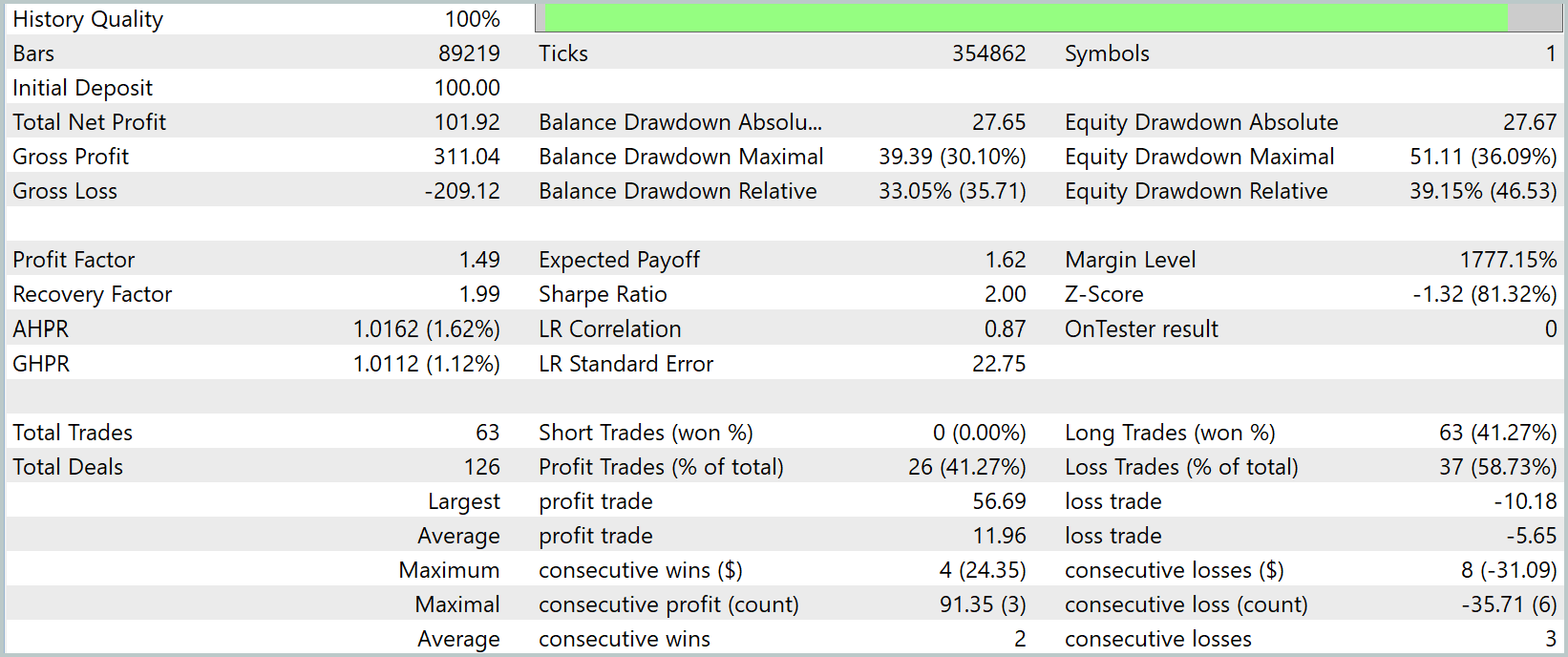
Durante três meses de teste no gráfico de um minuto (M1) nosso modelo demonstrou um crescimento impressionante do capital, de $100 para quase $202, praticamente dobrando o depósito. Ao mesmo tempo, apenas cerca de 41 % das operações foram lucrativas, porém o ganho médio de $12 superou amplamente a perda média de $5,6, resultando em um profit factor de 1,49. No gráfico de Equity observam-se claramente recuperações rápidas após cada retração, e o Recovery Factor próximo de dois confirma uma recuperação relativamente rápida após a retração máxima de 36 %.
No entanto, apesar de todos os resultados positivos, chama atenção um viés sério: o modelo entra de forma consistente apenas em posições longas, acompanhando a tendência global de alta. No timeframe de um minuto isso se manifesta de forma especialmente evidente, enquanto as cotações sobem o agente obtém lucro, mas ao menor sinal de reversão ele perde a oportunidade de lucrar com posições short.
Para tornar a estratégia realmente universal ainda será necessário trabalhar na sua otimização.
Considerações finais
Durante este trabalho criamos uma arquitetura flexível de redes neurais: desde o patching adaptativo e RoPE até módulos complexos como Time-MoEAttention e Actor–Director–Critic. O sistema é capaz de capturar tanto impulsos de curto prazo quanto tendências de longo prazo, e a previsão tripla em diferentes horizontes torna o modelo mais robusto ao ruído do mercado. A próxima tarefa consiste em otimizar a estratégia para trading bidirecional, adicionando suporte tanto para posições long quanto short, além de ajustar o gerenciamento de risco para ambas as direções. Somente após passar por uma etapa de testes em larga escala e por um ajuste fino com dados reais poderemos obter um sistema de trading automatizado realmente competitivo.
Links
- LightGTS: A Lightweight General Time Series Forecasting Model
- RoFormer: Enhanced Transformer with Rotary Position Embedding
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA de treinamento offline dos modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA de treinamento online dos modelos |
| 3 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18686
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso