
Нейросети в трейдинге: Оптимизация LSTM для целей прогнозирования многомерных временных рядов (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическими аспектами фреймворка DA-CG-LSTM, специально разработанного для решения сложных задач прогнозирования динамических многомерных временных рядов.
Современные финансовые рынки представляют собой сложные динамические системы, в которых непрерывно взаимодействует множество факторов: макроэкономические индикаторы, новости, изменения процентных ставок, поведение крупных игроков и множество других, зачастую скрытых параметров. Временные ряды, отражающие динамику цен и объёмов торгов, становятся основным источником информации о происходящих процессах. Однако анализ таких рядов требует от модели способности одновременно учитывать как долгосрочные тренды, так и краткосрочные колебания. А также уметь отличать действительно важные сигналы от фонового шума.
Классические методы обработки временных рядов, зачастую, оказываются недостаточно гибкими и чувствительными к многообразию рыночных факторов. Их ограниченная способность к выборочному вниманию, ключевым признакам и временным интервалам приводит к потере качества прогнозов в условиях высокой изменчивости рынка. Именно эти ограничения и стали отправной точкой для создания фреймворка DA-CG-LSTM — архитектуры, объединяющей двойной механизм внимания и модифицированную структуру рекуррентных блоков.
Одной из ключевых сторон DA-CG-LSTM является гибкость в обработке мультимодальных данных. В реальных торговых сценариях важно анализировать не только ценовые уровни, но и производные индикаторы, а также внешние экономические события. Рассматриваемый нами фреймворк позволяет динамически адаптироваться к изменениям важности признаков на каждом временном шаге, автоматически перераспределяя внимание на наиболее значимые источники информации. Таким образом, модель способна эффективно выявлять сложные взаимосвязи между множеством признаков и корректировать прогнозы, в зависимости от контекста текущей рыночной ситуации.
Особую ценность представляет реализованный в архитектуре двойной каскадный механизм внимания. На первом уровне внимание модели сосредотачивается на признаках — определяется, какие характеристики в данный момент оказывают наибольшее влияние на динамику рынка. На втором уровне внимание смещается на временные интервалы. Модель оценивает, какие участки в истории на данный момент обладают наибольшей ценностью для построения прогноза наиболее вероятного движения. Этот двухступенчатый процесс обеспечивает глубокую фильтрацию информации, позволяя системе игнорировать второстепенные данные и концентрироваться на действительно значимых сигналах, будь то крупные изменения трендов, или локальные аномалии.
Следующим важным достоинством DA-CG-LSTM стала высокая устойчивость к зашумлённым данным, которая критически важна для применения в реальных рыночных условиях. Финансовые временные ряды, как правило, содержат множество случайных колебаний, обусловленных не рыночными причинами, а внешними или внутренними случайными факторами. Модифицированный CG-LSTM-блок внутри фреймворка выступает в роли адаптивного фильтра, способного динамически снижать влияние зашумленных признаков. Благодаря внутренним механизмам управления весами признаков и временных шагов, модель фокусируется на выявлении стабильных, повторяющихся паттернов поведения цены, что заметно увеличивает качество прогнозов.
Ещё одной отличительной чертой DA-CG-LSTM является способность эффективно работать с длинными временными рядами без потери чувствительности к краткосрочным изменениям. В стандартных рекуррентных сетях увеличение длины анализируемой последовательности часто приводит к эффекту затухания градиента и к снижению качества обработки дальних зависимостей. В предложенной авторами фреймворка архитектуре эта проблема решается за счёт раннего этапа фильтрации информации с помощью первичного внимания и специальной организации памяти в CG-LSTM-блоке. Это позволяет сохранять в фокусе как долгосрочные тренды, так и быстро реагировать на кратковременные колебания, такие как новости или внутридневные всплески волатильности.
Это позволяет фреймворку DA-CG-LSTM удачно сочетать в себе адаптивность к многомерным данным, способность к глубокой фильтрации информации, устойчивость к шуму и высокую обучаемость на длинных временных отрезках. Указанные качества делают его мощным инструментом для построения современных систем прогнозирования временных рядов.
Алгоритм DA-CG-LSTM строится на последовательной обработке данных через несколько ключевых модулей.
На первом этапе исходное представление многомерного временного ряда проходит через модуль первичного внимания, который взвешивает важность отдельных признаков на каждом временном шаге. Это позволяет сжать и акцентировать анализируемую информацию до наиболее значимых характеристик, избавляя модель от лишнего информационного шума.
На следующем этапе данные направляются в модуль вторичного внимания, где акцент смещается на временные интервалы. Модель оценивает, какие отрезки временной истории играют ключевую роль для формирования прогнозных значений.
Обработанные данные затем поступают в модифицированный CG-LSTM-блок, в котором происходит агрегация признаков с учётом их внутренней значимости и взаимодействия. Блок CG-LSTM отличается от классического LSTM тем, что включает в себя дополнительные управляющие механизмы, влияющие на работу ячеек памяти в зависимости от важности признаков и временных интервалов. Это позволяет более точно моделировать сложные многомерные зависимости между рыночными факторами.
Итоговое агрегированное представление, сформированное с помощью двух уровней внимания и CG-LSTM, затем используется для прогнозирования целевой переменной — например, будущей цены актива или направления её изменения.
Эта многоступенчатая архитектура позволяет модели одновременно учитывать как краткосрочные, так и долгосрочные зависимости, минимизировать влияние шума и адаптивно изменять стратегию обработки данных, в зависимости от текущего рыночного контекста.
Авторская визуализация фреймворка DA-CG-LSTM представлена ниже.

В настоящей статье мы сделаем следующий шаг в построении собственного видения подходов, предложенных авторами фреймворка DA-CG-LSTM, средствами MQL5. Основной акцент будет сделан на разработке архитектуры обучаемых моделей
Архитектура моделей
Как уже отмечалось ранее, основу архитектуры фреймворка DA-CG-LSTM составляют два фундаментальных компонента: модули внимания и модифицированный рекуррентный блок CG-LSTM. Эти элементы формируют прочную конструкцию модели, обеспечивая ей необходимую гибкость, устойчивость к рыночным шумам и способность захватывать сложные многоуровневые временные зависимости. В условиях высокой волатильности и хаотичности финансовых рынков, такие качества становятся не просто желательными — они критически необходимы для построения надёжных торговых систем.
В практической части предыдущей статьи мы подробно разобрали процесс создания блока CG-LSTM средствами MQL5. Разработанный компонент успешно реализует три важнейших функции: фильтрацию признаков для устранения лишнего шума, эффективное управление внутренним состоянием модели для сохранения долгосрочной информации и агрегацию данных на разных временных уровнях. Способность блока к подавлению неструктурированного шума и удержанию устойчивой динамики обучения позволяет строить модели, которые не теряют качества прогнозов на длительных отрезках исторических данных.
Для выявления и анализа взаимосвязей между признаками и временными последовательностями, авторы DA-CG-LSTM предложили использовать усовершенствованную версию механизма линейного внимания. В рамках нашей работы мы решили использовать ранее разработанный объект CNeuronLinearAttention, построенного в процессе работы над фреймворком Hidformer. Хотя архитектурные особенности двух решений имеют определённые различия, базовая концепция остаётся общей.
Учитывая эти обстоятельства, мы приняли решение использовать готовый модуль внимания без внесения дополнительных адаптаций. Это позволило существенно ускорить процесс разработки и минимизировать риски внедрения новых, недостаточно протестированных решений. Таким образом, на данном этапе, в нашем распоряжении имеется полноценный набор компонентов для построения фреймворка DA-CG-LSTM.
Следующий логичный шаг — проектирование архитектуры обучаемых моделей на базе подготовленных компонентов. Здесь мы пошли дальше классической задачи прогнозирования будущих значений временного ряда. На финансовых рынках важно не только уметь прогнозировать динамику цен, но и правильно использовать эти прогнозы для принятия торговых решений, оптимизируя риск и потенциальную доходность.
Для достижения этой цели, мы интегрировали лучшие идеи из архитектуры HiSSD, которая доказала свою эффективность в борьбе с шумами и в обработке сложных нелинейных зависимостей. Структура DA-CG-LSTM была интегрирована в энкодер созданием латентного пространства глобальных и локальных навыков агентов, описывающих состояние рыночной среды. Это пространство служит фундаментом для последующих этапов анализа и принятия решений.
Поверх базовой структуры была наложена система обучения с подкреплением Actor-Director-Critic. Такая интеграция позволяет не просто строить прогнозы, но и стратегически выбирать действия с максимальной ожидаемой выгодой.
Архитектура обучаемых моделей формируется в методе CreateDescriptions. В его параметрах передаются указатели на шесть объектов динамических массивов, каждый из которых отражает отдельный уровень комплексной архитектуры модели:
- Энкодер состояния окружающей среды — отвечает за построение латентного пространства глобальных навыков агентов. Он обобщает информацию о текущем состоянии рынка, выявляя скрытые зависимости между анализируемыми факторами, влияющими на рыночную динамику.
- Низкоуровневый контроллер — формирует локальные навыки агентов, опираясь на анализируемые признаки окружающей среды. Анализируя их в контексте глобальных навыков, контроллер синтезирует тензор возможных действий, который отражает наиболее перспективные торговые сценарии с учётом краткосрочных и долгосрочных рыночных трендов.
- Актёр — принимает тензор вариантов действий от контроллера и, оценивая его в контексте текущего состояния счёта, уровня риска и заданных стратегических целей, генерирует итоговое торговое решение, направленное на максимизацию прибыли при контроле допустимых потерь.
- Вероятностная модель прогнозирования тенденций — способствует формированию более информативных глобальных навыков агентов, обогащая их вероятностным представлением направления ожидаемого движения рынка. Это позволяет модели учитывать вероятностную природу рыночных процессов и строить более устойчивые стратегии.
- Режиссёр — осуществляет первичную фильтрацию действий, снижая вероятность принятия решений с заведомо высоким уровнем риска. Он направляет политику поведения Актёра в сторону более консервативных и надёжных сценариев, соответствующих текущим условиям рынка.
- Критик — анализирует эффективность выбранных стратегий на горизонте будущего, корректируя поведение агентов таким образом, чтобы в долгосрочной перспективе максимизировать суммарную прибыль при разумном уровне риска.
Метод CreateDescriptions включает строгую проверку валидности получаемых указателей. В случае необходимости, создаются новые экземпляры описательных объектов, обеспечивая целостность и корректность архитектуры модели на всех этапах её построения.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Начнём с описания архитектуры энкодера состояния окружающей среды. В качестве объекта исходных данных, как и в предыдущих работах, используется полносвязный нейронный слой достаточной размерности. Этот слой служит своеобразными воротами в модель, принимая сырые исходные данные без предварительной ручной обработки.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Источник информации — непосредственные данные терминала: ценовые котировки, объемы торгов, индикаторы настроения рынка и прочие важные параметры. Мы сознательно отказались от этапа предварительной обработки на стороне программы. Такая стратегия, безусловно, усложняет процесс обучения модели, так как предъявляет к ней гораздо более высокие требования в части способности к самообучению и фильтрации шумов. Однако, этот подход позволяет добиться гораздо большей устойчивости на этапе практического применения.
Важно понимать: обученная модель будет демонстрировать надёжные и воспроизводимые результаты только в том случае, если данные, поступающие на её вход в реальных условиях эксплуатации, имеют распределение, схожее с используемым в процессе обучения. Предварительная ручная обработка данных вне модели увеличивает риск непредсказуемых отклонений. Ведь даже малейшее изменение фильтров или параметров может радикально изменить характер исходных данных. Следовательно, внутренняя обработка данных становится обязательной частью самой архитектуры модели.
С целью минимизации рисков и повышения качества обучения, мы интегрировали базовый этап обработки данных прямо в структуру энкодера. Эту функцию выполняет слой пакетной нормализации с механизмом добавления контролируемого случайного шума CNeuronBatchNormWithNoise. Пакетная нормализация приводит разнородные мультимодальные данные к единому масштабу, улучшая стабильность обучения и ускоряя сходимость модели. А небольшая аугментация за счёт шума помогает повысить обобщающую способность модели, снижая вероятность переобучения на ограниченных объёмах данных.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Нормализованные данные передаются в модуль линейного внимания, который отвечает за анализ взаимозависимостей между отдельными признаками внутри каждого временного шага.
На этом этапе особое внимание уделяется правильной интерпретации внутренней структуры данных. Несмотря на то, что модель обрабатывает временной ряд, на каждом конкретном временном шаге она имеет дело с одним и тем же фиксированным набором признаков, описывающих состояние окружающей среды.
Учитывая повторяющуюся природу структуры данных на каждом временном срезе, мы приняли решение использовать единую матрицу обучаемых параметров для анализа всех временных шагов. Иными словами, модель применяет общий, универсальный механизм внимания для всего временного ряда. Это позволяет добиться сразу нескольких критически важных эффектов:
- повысить согласованность интерпретации признаков на разных временных отрезках;
- существенно сократить количество обучаемых параметров, что особенно важно в условиях ограниченных обучающих выборок;
- улучшить обобщающую способность модели, минимизируя переобучение;
- ускорить процесс обучения за счёт оптимизации вычислений.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.layers = 1; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
После анализа взаимозависимостей между признаками на каждом временном шаге, следующим важным этапом становится временной анализ исходных данных. Для реализации этой задачи, вначале применяем транспонирование исходного тензора, что позволяет нам рассматривать каждый отдельный признак как последовательность наблюдений во времени.
Транспонированный тензор передаётся во второй модуль линейного внимания, специально предназначенный для анализа временной динамики данных.
Следует отметить, что после транспонирования, мы фактически имеем дело с множеством унитарных временных последовательностей, каждая из которых представляет собой эволюцию одного конкретного признака во времени. Эти признаки могут принадлежать к разным модальностям данных. Важно понимать, что различные модальности могут демонстрировать различные характерные паттерны реакции на одни и те же рыночные события. Поэтому, на данном этапе, мы реализуем более гибкий подход: для каждой унитарной последовательности используется собственная матрица обучаемых параметров. Такой механизм позволяет:
- учитывать специфику каждой модальности при интерпретации её временной динамики;
- выявлять уникальные закономерности в реакции разных признаков на одни и те же рыночные триггеры;
- повысить чувствительность модели к слабым, но важным сигналам в отдельных каналах данных;
- избежать смешивания информации между несопоставимыми по природе признаками.
Подобная архитектура особенно эффективна на финансовых рынках, где данные различной природы могут реагировать на фундаментальные или технические события с разной скоростью, амплитудой и направленностью.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; descr.count = 1; descr.window = HistoryBars; descr.layers = BarDescr; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
После прохождения двух уровней внимания, анализируемые данные приобретают существенно более богатую структуру. Они уже содержат в себе информацию, как о внутренней взаимосвязи между признаками, так и о характерных временных зависимостях, присущих каждой модальности. Однако, для построения эффективной стратегии принятия решений на финансовых рынках, необходимо уметь агрегировать эти данные в более компактную и осмысленную форму.
Обогащённые внутренними связями данные передаются в CG-LSTM блок, где осуществляется независимый анализ унитарных последовательностей, сформированных на предыдущем этапе. Стоит отметить, что подобный подход существенно отличается от оригинального замысла авторов фреймворка DA-CG-LSTM. В классической архитектуре DA-CG-LSTM ячейки рекуррентного блока обрабатывают мультимодальные представления отдельных временных шагов. Такой метод позволяет учитывать сложные межмодальные зависимости.
Однако в нашем проекте, мы сознательно выбрали альтернативную стратегию. Развиваем идеи, заложенные в архитектуре HiSSD, где особое внимание уделяется независимому прогнозированию унитарных последовательностей, относящихся к отдельным агентам. Такой подход позволяет более гибко и точно улавливать специфические поведенческие паттерны каждой модальности, минимизируя влияние потенциальных перекрёстных шумов между различными источниками данных.
Используемый вариант обработки данных в CG-LSTM блоке обеспечивает:
- более чёткую специализацию скрытых состояний под конкретные аспекты данных;
- устойчивость модели к изменениям структуры рыночной информации;
- повышение интерпретируемости глобальных навыков, поскольку каждый вектор навыков связан с конкретной модальностью анализируемых данных.
При проектировании рекуррентного блока мы приняли принципиально важное решение: размер скрытого состояния каждого CG-LSTM-элемента установлен равным размеру вектора глобальных навыков одного агента. Это позволяет каждой унитарной последовательности формировать выходное представление фиксированного размера, в котором закодированы наиболее важные аспекты её долгосрочного поведения. Они становятся фундаментом для дальнейшего принятия решений в модели.
Важно подчеркнуть, что построение матрицы глобальных навыков происходит в полностью обучаемом режиме. Модель самостоятельно определяет, какие аспекты поведения признаков являются наиболее значимыми для успешного функционирования в условиях реальной торговли.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGLSTMOCL; descr.count = NSkills; // Common Skkills descr.window = HistoryBars; // Sequence descr.layers = BarDescr; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Следует напомнить, что высокоуровневый планировщик фреймворка HiSSD учится формировать глобальные навыки через процесс кодирования латентного состояния, для максимально точного прогнозирования следующего состояния системы. Аналогично, основная задача фреймворка DA-CG-LSTM заключается в максимально точном прогнозировании мультимодального временного ряда. Вся его архитектура построена вокруг этой цели: сложная система внимания, мощные рекуррентные блоки и декодер направлены на извлечение скрытых закономерностей и повышение качества прогнозов.
Однако, мы используем принципиально иной подход и намеренно переориентируем архитектуру под другую задачу: обучение максимально информативного латентного состояния — так называемых глобальных навыков агентов. Нам не столько важно точно спрогнозировать каждое следующее значение временного ряда, сколько создать такое внутреннее представление рынка, которое станет прочной основой для последующего обучения оптимальной политики поведения агентов.
В этом контексте мы сознательно отказались от сложной архитектуры оригинального декодера DA-CG-LSTM. Его глубокие механизмы анализа латентного пространства могли бы исказить или переинтерпретировать глобальные навыки, что сделало бы их менее пригодными для целей управления агентами.
Вместо этого, мы выбрали минималистичный декодер, состоящий из двух последовательных сверточных слоев. Такая конструкция обеспечивает прямолинейную обработку скрытых представлений, минимальное вмешательство в структуру глобальных навыков, высокую интерпретируемость результатов и независимую обработку унитарных последовательностей признаков.
Такой подход позволяет сохранить чистоту и ценность сформированного латентного пространства, открывая путь к более эффективному обучению политики поведения Актера.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; int prev_out = descr.window_out = 4 * NForecast; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Для корректного сопоставления прогнозных значений с фактическими данными, на завершающем этапе обработки результатов работы декодера мы выполняем транспонирование тензора результатов обратно к исходной структуре данных.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Однако, даже после восстановления формы, прогнозные значения остаются в нормализованном виде. Поэтому, следующим важным этапом является обратная трансформация — добавляются статистические параметры исходного распределения признаков, которые были зафиксированы на этапе пакетной нормализации.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Следующим этапом переходим к рассмотрению архитектуры низкоуровневого контроллера. Эта модель играет ключевую роль в построении локальных стратегий поведения агентов, на основе анализа состояния окружающей среды в каждый конкретный момент времени.
Контроллер принимает на вход сырые данные окружающей среды — аналогично тому, как это происходило в энкодере глобальных навыков. В основе его архитектуры, фактически, лежит та же самая структура: первичная нормализация данных с добавлением случайного шума, двухступенчатый процесс анализа через модули линейного внимания, а также использование рекуррентного блока CG-LSTM для последовательной обработки.
Фундаментальное отличие между глобальными и локальными навыками заключается не в механизме их построения, а в задачах, которые агенты решают в процессе обучения. В случае формирования глобальных навыков, акцент делается на создании обобщённого латентного пространства, способного интегрировать долгосрочные зависимости и ключевые характеристики рынка. Локальные же навыки ориентированы на оперативную адаптацию к текущему состоянию рынка и выработку конкретных торговых действий для каждого отдельного временного шага.
Поэтому мы просто копируем архитектуру энкодера навыков.
//--- Task task.Clear(); //--- Task Encoder for(int i = 0; i <= LatentLayer; i++) if(!task.Add(encoder.At(i))) return false;
После формирования локальных навыков, следующим шагом становится их обогащение контекстной информацией глобальных навыков агентов. Для решения этой задачи мы используем двухслойный блок кросс-внимания.
Навыки агентов выступают в роли запросов (Query), тогда как глобальные навыки всех агентов используются в роли ключей (Key) и значений (Value). Принципиальный момент: локальные навыки каждого отдельного агента интерпретируются не в изоляции, а в широком контексте общего латентного пространства всей системы агентов. Это позволяет принимать более взвешенные решения.
Особенностью архитектуры блока является двухступенчатая организация механизма крсс-внимания. На первой ступени реализуется базовый Cross-Attention. Локальные запросы извлекают наиболее релевантные фрагменты глобальной информации. Эта операция позволяет агентам гибко адаптировать своё краткосрочное поведение, в соответствии с текущим состоянием окружающей среды и стратегическими тенденциями, зафиксированными в глобальных навыках.
На второй ступени усиливается интеграция с помощью дополнительного слоя внимания, который позволяет выявлять более сложные и глубокие взаимосвязи между краткосрочными целями и долгосрочными стратегическими ориентирами.
Именно благодаря интеграции локального и глобального контекстов, модель получает способность вырабатывать более взвешенные, обоснованные торговые решения, повышая устойчивость агентов к ложным сигналам и краткосрочным рыночным шумам.
//--- layer LatentLayer+1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {NSkills, NSkills}; // WIndow if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {BarDescr, BarDescr}; // Units if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; descr.window_out = 32; descr.layers = 2; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!task.Add(descr)) { delete descr; return false; }
Локальные навыки, обогащённые глобальным контекстом, передаются в блок принятия решений. Здесь ключевую роль играет использование двух последовательных сверточных слоёв. Такая архитектура позволяет эффективно организовать параллельную работу независимых MLP для каждого отдельного агента.
Каждый агент интерпретирует своё собственное локальное латентное пространство и принимает решения, не вмешиваясь напрямую в работу других агентов. Благодаря сверточной структуре, достигается высокая вычислительная эффективность: все агенты обрабатываются одновременно. При этом каждый работает с собственной матрицей параметров модели.
Двойная последовательность сверточных слоёв обеспечивает дополнительную гибкость архитектуры: первый слой отвечает за первичную агрегацию и преобразование признаков, тогда как второй слой уточняет локальные представления и формирует финальный тензор действий. Такой подход позволяет добиться лучшей адаптивности и устойчивости поведения агентов в условиях высокой волатильности финансовых рынков.
//--- layer LatentLayer+2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; prev_out = descr.window_out = 4 * NActions; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!task.Add(descr)) { delete descr; return false; } //--- layer LatentLayer+3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NActions; descr.layers = prev_count; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
Архитектуры моделей верхнеуровневого Актера, Режиссера и Критика полностью перенесены из предыдущей работы. Их детальное описание можно найти по ссылке. И мы не будем сейчас на них останавливаться. Полное описание архитектуры всех моделей представлено во вложении.
Обучение
Процесс обучения моделей организован в три этапа: формирование обучающей выборки, офлайн-обучение всех компонентов модели и последующая тонкая настройка в режиме онлайн. Такой подход сочетает фундаментальную устойчивость, полученную на исторических данных, с гибкой адаптацией к текущим рыночным условиям.
Все программы, используемые в процессе обучения перенесены без изменений из предыдущей работы, поэтому мы не будем детально останавливаться на рассмотрении их алгоритма. Повторим лишь базовые принципы процесса.
Обучение моделей начинается с формирования обучающей выборки. С этой целью используется советник Research.mq5, который запускаем в тестере стратегий MetaTrader5 для сбора исторических данных валютной пары EURUSD с использованием минутного таймфрейма за весь 2024 год. Чтобы минимизировать нагрузку, каждый проход ограничивается одним месяцем истории, а разнообразие поведения агентов достигается за счёт случайных политик. После закрытия каждой свечи, фиксируются состояния рынка, показатели индикаторов, характеристики счёта и действия агентов, формируя полные траектории для буфера воспроизведения опыта.
Собранные данные становятся основой для офлайн-обучения всех компонентов, которое выполняется с помощью советника Study.mq5. Из буфера случайным образом выбираются траектории и стартовые точки, для формирования обучающих пакетов последовательных состояний. Для ускорения сходимости, применяется методика почти идеальной траектории, позволяющая энкодеру прогнозировать несколько шагов вперёд. На этом этапе обучаются Энкодеры навыков, Актёр, Режиссер и Критик, формируя базовую политику поведения агента.
После завершения офлайн-обучения, переходим к стадии тонкой настройки в режиме реального времени. Здесь используется советник StudyOnline.mq5. Основное внимание уделяется обучению Актёра под управлением Режиссера и Критика. После закрытия каждой новой свечи, проводится анализ состояния окружающей среды, обновление оценок действий и корректировка параметров моделей. Периодическое мягкое обновление целевых моделей помогает поддерживать баланс между стабильностью и адаптивностью стратегии.
Такой поэтапный подход, сочетающий накопление знаний в офлайн-режиме и адаптацию в онлайне, обеспечивает высокую эффективность и устойчивость моделей при торговле в реальных рыночных условиях.
Тестирование
Объективную оценку эффективности реализованных решений и сформированной торговой политики можно получить на данных, не участвовавших в обучении моделей. Для этой цели использовался тестовый период — Январь–Март 2025 года. Использование исторических данных за пределами обучающей выборки позволяет исключить риск переобучения и придаёт результатам реальную практическую ценность.
Все прочие параметры эксперимента (рыночная среда, таймфрейм и настройки терминала) были оставлены без изменений. Это обеспечило чистоту проверки именно качества выученной стратегии, без влияния внешних факторов.
Результаты тестирования представлены ниже и наглядно демонстрируют поведенческую модель агента в боевых условиях.


За период тестирования модель совершила 37 торговых операций. Чуть более 40% из них было закрыто с прибылью. Тем не менее, модель смогла получить прибыль благодаря тому, что средняя прибыльная сделка более чем 2 раза превышает аналогичный показатель убыточных торговых операций. Показатель профит-фактор был зафиксирован на отметке 1.67.
Заключение
В данной работе мы познакомились с теоретическими аспектами фреймворка DA-CG-LSTM, отличающегося от классических моделей наличием инновационных компонентов — таких, как CG-LSTM и двойной механизм внимания. Эти элементы обеспечивают более точное извлечение временных зависимостей и позволяют учитывать как краткосрочные колебания, так и долгосрочные тренды.
В практической части была представлена модифицированная архитектура, адаптированная для задач обучения торговых агентов. Упрощение декодеров в пользу сверточных блоков позволило сосредоточить обучение на извлечении глобальных навыков — ключевого фактора для последующего построения устойчивой и адаптивной стратегии.
Эффективность реализованных подходов была проверена на тестовой выборке за пределами периода обучения. Несмотря на то, что доля прибыльных сделок составила чуть более 40 %, соотношение средних прибылей и убытков обеспечило общий положительный результат.
Следует подчеркнуть, что описанные модели пока носят исследовательский характер. Перед практическим применением в реальной торговле они требуют обучения на более репрезентативных данных и проведения комплексного тестирования в различных рыночных условиях.
Ссылки
- A Dual-Staged Attention Based Conversion-Gated Long Short Term Memory for Multivariable Time Series Prediction
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 4 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 HTTP и Connexus (Часть 2): Понимание архитектуры HTTP и дизайна библиотеки
HTTP и Connexus (Часть 2): Понимание архитектуры HTTP и дизайна библиотеки
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
|
Прогнал в Research 1 месяц 5-ти минутки, получилось 300МБ DACGLSTM.bd. Запустил Study. Проценты ошибок пугающие. Или это норм для самого первого прогона?
После Study появились файлы нейросети .nnw. Запустил повторный круг сбора данных, уже на следующем месяце - Research перестал совершать торговые операции...
Ура! После нескольких недель танцев с бубнами наконец-то значения ошибок в Study пришло в норму! Теперь нейронка реально учится.
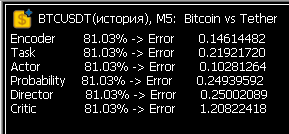
Пришлось расширить алгоритм наград и штрафов
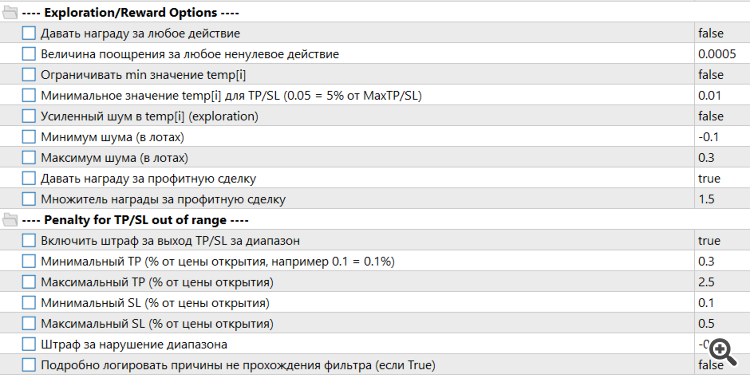
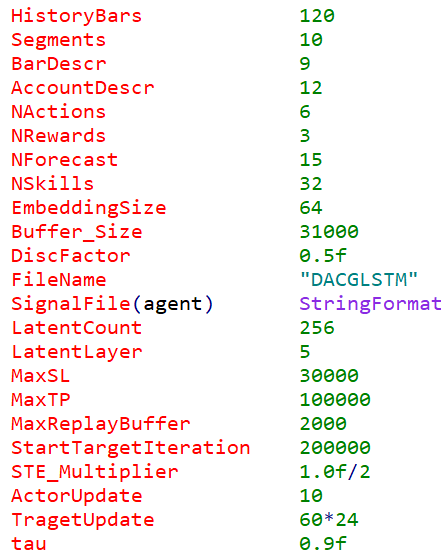
А также сильно скорректировать входные параметры Trajectory
Ура! После нескольких недель танцев с бубнами наконец-то значения ошибок в Study пришло в норму! Теперь нейронка реально учится.
Теперь самое интересное - как будет торговать на новых данных.. занимаюсь деревянными моделями - они понятнее. Но на новых данных почти рандомная торговля, т.к. нет значимых фич.
Теперь самое интересное - как будет торговать на новых данных.. занимаюсь деревянными моделями - они понятнее. Но на новых данных почти рандомная торговля, т.к. нет значимых фич.
До реальной торговли мне надо ещё дойти) После нескольких кругов Research-Study сделки начинают закрываться очень быстро. Нейронка учится выживать, а не зарабатывать. И чем короче сделка, тем ей больше кажется, что меньше штрафа она получает. Танцы с бубнами продолжаются. Нужно выстроить правильно алгоритм наград и штрафов, и это походу самое сложное. Пока просто пытаюсь жёстко ограничивать. Например, не давать выставлять стопы и тейки меньше порогового значения. Ещё пробую ограничивать минимальное время жизни сделки, чтобы они не закрывались почти сразу после открытия. Я использую LLM либо Grok, либо ChatGPT 4.1, но они иногда так дико тупят, что голова не вывозит. Но мало по малу всё-таки продвижения идут. Много времени уходит на круги обучения. Ещё бы силы с кем-нибудь объединить, тема то очень перспективная.