
Redes neuronales en el trading: Optimización de LSTM para la predicción de series temporales multivariadas (Final)

Introducción
En el artículo anterior, presentamos los aspectos teóricos del framework DA-CG-LSTM, que está específicamente diseñado para resolver problemas complejos de pronóstico de series temporales multidimensionales dinámicas.
Los mercados financieros modernos son sistemas dinámicos complejos en los que interactúan continuamente numerosos factores: indicadores macroeconómicos, noticias, cambios en los tipos de interés, el comportamiento de los principales participantes y muchos otros parámetros, a menudo ocultos. Las series temporales que reflejan la dinámica de precios y los volúmenes comerciales se convierten en la principal fuente de información sobre los procesos en curso. Sin embargo, el análisis de dichas series requiere que el modelo sea capaz de considerar simultáneamente tanto las tendencias a largo plazo como las fluctuaciones a corto plazo, además de distinguir las señales realmente importantes del ruido de fondo.
Los métodos clásicos de procesamiento de series temporales a menudo resultan insuficientemente flexibles y sensibles ante la variedad de factores del mercado. Su capacidad limitada para centrarse selectivamente en características clave e intervalos temporales provoca una pérdida de calidad en las previsiones si las condiciones de mercado son altamente volátiles. Las limitaciones mencionadas se convirtieron en el punto de partida para la creación del framework DA-CG-LSTM, una arquitectura que combina un mecanismo de atención dual y una estructura de bloques recurrentes modificada.
Una de las principales ventajas del DA-CG-LSTM es su flexibilidad en el manejo de datos multimodales. En escenarios comerciales reales, es importante analizar no solo los niveles de precios, sino también los indicadores derivados y los eventos económicos externos. El framework analizado nos permite adaptarnos dinámicamente a los cambios en la importancia de las características en cada paso temporal, redistribuyendo automáticamente la atención a las fuentes de información más significativas. De esta forma, el modelo es capaz de identificar eficazmente relaciones complejas entre múltiples características y ajustar los pronósticos dependiendo del contexto de la situación actual en el mercado.
Resulta particularmente valioso el mecanismo de atención de doble cascada implementado en la arquitectura. En el primer nivel, el modelo se centra en las características y determina cuáles de ellas tienen actualmente la mayor influencia en la dinámica del mercado. En el segundo nivel, la atención se desplaza hacia los intervalos temporales. El modelo estima qué partes de la historia tienen actualmente el mayor valor para construir un pronóstico del movimiento más probable. Este proceso de dos pasos posibilita un filtrado profundo de la información, lo que permite que el sistema ignore los datos irrelevantes y se centre en las señales que realmente importan, ya sean cambios de tendencia importantes o anomalías locales.
Otra ventaja importante del DA-CG-LSTM es su alta robustez ante datos ruidosos, lo cual resulta fundamental para su aplicación en condiciones reales de mercado. Las series temporales financieras suelen contener muchas fluctuaciones aleatorias que no son causadas por fuerzas del mercado sino por factores aleatorios externos o internos. El bloque CG-LSTM modificado dentro del framework actúa como un filtro adaptativo capaz de reducir dinámicamente la influencia de características ruidosas. Gracias a los mecanismos internos para gestionar los pesos de las características y los pasos temporales, el modelo se centra en identificar patrones estables y repetitivos en el comportamiento de los precios, lo que mejora significativamente la calidad de los pronósticos.
Otra característica distintiva del DA-CG-LSTM es su capacidad de trabajar eficazmente con series temporales largas sin perder sensibilidad a los cambios de corto plazo. En redes recurrentes estándar, el aumento de la longitud de la secuencia analizada a menudo provoca un efecto de atenuación del gradiente, así como una disminución en la calidad del procesamiento de las dependencias de largo alcance. En la arquitectura de framework propuesta por los autores, este problema se resuelve con la ayuda de una etapa temprana de filtrado de información usando atención primaria y una organización especial de memoria en el bloque CG-LSTM. Esto le permite concentrarse en las tendencias a largo plazo y reaccionar rápidamente a las fluctuaciones a corto plazo, como, por ejemplo, noticias o picos de volatilidad intradía.
Esto permite que el framework DA-CG-LSTM combine con éxito la adaptabilidad a datos multidimensionales, la capacidad de filtrar información en profundidad, la resiliencia al ruido y una alta capacidad de aprendizaje durante largos periodos temporales. Estas cualidades lo convierten en una potente herramienta para construir sistemas modernos de pronóstico de series temporales.
El algoritmo DA-CG-LSTM se basa en el procesamiento secuencial de datos a través de varios módulos clave.
En la primera etapa, la representación original de la serie temporal multivariada pasa por un módulo de atención primaria que pondera la importancia de las características individuales en cada paso temporal. Esto nos permite comprimir y enfocar la información analizada en las características más significativas, liberando al modelo de ruido informativo innecesario.
En el siguiente paso, los datos se envían al módulo de atención secundaria, donde el énfasis se desplaza a los intervalos temporales. El modelo evalúa qué periodos de la historia temporal juegan un papel clave en la formación de los valores de pronóstico.
Luego, los datos procesados se introducen en un bloque CG-LSTM modificado donde se agregan las características según su importancia interna y sus interacciones. El bloque CG-LSTM se diferencia del LSTM clásico en que incluye mecanismos de control adicionales que influyen en el funcionamiento de las celdas de memoria dependiendo de la importancia de las características y los intervalos temporales. Esto permite un modelado más preciso de dependencias multidimensionales complejas entre factores del mercado.
La representación agregada resultante, que se forma usando dos capas de atención y CG-LSTM, se utiliza luego para predecir una variable objetivo, por ejemplo, el precio futuro de un activo o su dirección.
Esta arquitectura de múltiples etapas permite que el modelo analice simultáneamente las dependencias de corto y largo plazo, minimice el impacto del ruido y cambie de manera adaptativa la estrategia de procesamiento de datos dependiendo del contexto actual del mercado.
Más abajo le mostramos la visualización del autor del framework DA-CG-LSTM.

En este artículo daremos el siguiente paso en la construcción de nuestra propia visión de los enfoques propuestos por los autores del framework DA-CG-LSTM usando herramientas MQL5. El enfoque principal se centrará en el desarrollo de la arquitectura de modelos entrenables.
Arquitectura de los modelos
Como hemos señalado antes, la arquitectura del framework DA-CG-LSTM se basa en dos componentes fundamentales: los módulos de atención y la unidad recurrente CG-LSTM modificada. Estos elementos forman una estructura de modelo robusta, ofreciéndole la flexibilidad necesaria, la resistencia al ruido del mercado y la capacidad de capturar dependencias temporales complejas de múltiples niveles. Ante la alta volatilidad y el caos de los mercados financieros, estas cualidades no solo resultan deseables: son fundamentales para construir sistemas comerciales confiables.
En la parte práctica del artículo anterior, analizamos con detalle el proceso de creación de un bloque CG-LSTM utilizando MQL5. El componente desarrollado implementa con éxito tres funciones clave: el filtrado de características para eliminar el exceso de ruido, la gestión eficiente del estado interno del modelo para preservar la información a largo plazo y la agregación de datos en diferentes niveles temporales. La capacidad del bloque para suprimir el ruido no estructurado y mantener una dinámica de aprendizaje estable nos permite construir modelos que mantienen la calidad predictiva durante largos periodos de datos históricos.
Para identificar y analizar las relaciones entre las características y las secuencias temporales, los autores de DA-CG-LSTM propusieron usar una versión mejorada del mecanismo de atención lineal. Como parte de nuestro trabajo, hemos decidido utilizar el objeto CNeuronLinearAttention, desarrollado previamente, y que creamos durante el artículo sobre el framework Hidformer. Aunque las características arquitectónicas de las dos soluciones presentan ciertas diferencias, el concepto básico sigue siendo común.
Dadas estas circunstancias, hemos decidido utilizar el módulo de atención existente sin realizar ninguna adaptación adicional. Esto ha permitido acelerar significativamente el proceso de desarrollo y minimizar los riesgos de implementar soluciones nuevas que no han sido suficientemente probadas. Así, en esta etapa, tenemos a nuestra disposición un conjunto completo de componentes para construir el framework DA-CG-LSTM.
El siguiente paso lógico consiste en diseñar la arquitectura de modelos entrenables basados en los componentes preparados. Aquí hemos ido más allá del problema clásico del pronóstico de valores futuros de una serie temporal. En los mercados financieros, debemos no solo poder predecir la dinámica de los precios, sino también usar correctamente estos pronósticos para tomar decisiones comerciales, optimizando el riesgo y el rendimiento potencial.
Para lograr este objetivo, hemos integrado las mejores ideas de la arquitectura HiSSD, que ha demostrado su eficacia para combatir el ruido y gestionar dependencias no lineales complejas. La estructura DA-CG-LSTM se ha integrado en el codificador creando un espacio latente de habilidades globales y locales de los agentes que describen el estado del entorno del mercado. Este espacio sirve como base para las etapas posteriores de análisis y toma de decisiones.
Sobre la estructura básica se ha instalado un sistema de aprendizaje de refuerzo Actor-Director-Critic. Esta integración nos permite no solo realizar previsiones, sino también seleccionar estratégicamente las acciones con el máximo beneficio esperado.
La arquitectura de los modelos entrenados se forma en el método CreateDescriptions. Sus parámetros transmiten los punteros a seis objetos de matriz dinámica, cada uno de los cuales refleja un nivel separado de la arquitectura compleja del modelo:
- El codificador del estado del entorno se encarga de construir el espacio latente de las habilidades del agente global. Dicho codificador resume la información sobre el estado actual del mercado, revelando dependencias ocultas entre los factores analizados que influyen en la dinámica del mercado.
- El controlador de bajo nivel: forma las habilidades locales de los agentes según las características del entorno analizadas. Al analizarlas en el contexto de las habilidades globales, el controlador sintetiza un tensor de acciones posibles que refleja los escenarios comerciales más prometedores, considerando las tendencias del mercado a corto y largo plazo.
- El actor recibe un tensor de opciones de acciones del controlador y, evaluándolo en el contexto del estado de la cuenta actual, el nivel de riesgo y los objetivos estratégicos especificados; luego genera una decisión comercial final orientada a maximizar las ganancias y controlar las pérdidas aceptables.
- El modelo de pronóstico de tendencias probabilísticas ayuda a desarrollar habilidades globales más informativas en los agentes al enriquecerlos con una representación probabilística de la dirección del movimiento esperado del mercado. Esto permite que el modelo considere la naturaleza probabilística de los procesos de mercado y construya estrategias más sostenibles.
- El Director realiza un filtrado primario de acciones, reduciendo la probabilidad de tomar decisiones con un nivel de riesgo deliberadamente alto. Este orienta la política de comportamiento del Actor hacia escenarios más conservadores y fiables que se correspondan con las condiciones actuales del mercado.
- El Crítico analiza la efectividad de las estrategias seleccionadas en el horizonte futuro, ajustando el comportamiento de los agentes de tal manera que se maximice el beneficio total en el largo plazo con un nivel de riesgo razonable.
El método CreateDescriptions incluye una verificación de la validación estricta de los punteros recibidos. De ser necesario, se crean nuevas instancias de objetos descriptivos, garantizando la integridad y corrección de la arquitectura del modelo en todas las etapas de su construcción.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&task, CArrayObj *&actor, CArrayObj *&probability, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!task) { task = new CArrayObj(); if(!task) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Vamos a comenzar describiendo la arquitectura del codificador del entorno. Al igual que en artículos anteriores, como objeto de datos fuente se utiliza una capa neuronal completamente conectada de dimensionalidad suficiente. Esta capa sirve como puerta de entrada al modelo y acepta datos de entrada sin procesar sin ningún preprocesamiento manual.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
La fuente de información son los datos directos de la terminal: cotizaciones de precios, volúmenes comerciales, indicadores de sentimiento del mercado y otros parámetros importantes. Hemos abandonado deliberadamente la etapa de preprocesamiento en el lado del programa. Esta estrategia ciertamente complica el proceso de entrenamiento del modelo, ya que le impone exigencias mucho mayores en cuanto a su capacidad de autoaprendizaje y de filtrado del ruido. Sin embargo, este enfoque permite una estabilidad mucho mayor en la etapa de aplicación práctica.
Debemos entender que un modelo entrenado solo producirá resultados fiables y reproducibles si los datos que recibe en las condiciones del mundo real tienen una distribución similar a la utilizada en el proceso de entrenamiento. El preprocesamiento manual de datos fuera del modelo aumenta el riesgo de desviaciones impredecibles. Después de todo, incluso el más mínimo cambio en los filtros o parámetros puede alterar radicalmente la naturaleza de los datos de origen. En consecuencia, el procesamiento interno de datos se convierte en una parte obligatoria de la propia arquitectura del modelo.
Para minimizar los riesgos y mejorar la calidad del entrenamiento, integramos la etapa básica de procesamiento de datos directamente en la estructura del codificador. Esta función la realiza una capa de normalización por lotes con un mecanismo para añadir ruido aleatorio controlado CNeuronBatchNormWithNoise. La normalización por lotes normaliza datos multimodales heterogéneos a una sola escala, lo cual mejora la estabilidad del entrenamiento y acelera la convergencia del modelo, mientras que una pequeña cantidad de aumento de ruido ayuda a mejorar la capacidad de generalización del modelo, reduciendo la probabilidad de sobreajuste en conjuntos de datos limitados.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos normalizados se envían al módulo de atención lineal, que se encarga de analizar las relaciones entre las características individuales dentro de cada paso temporal.
En esta etapa se presta especial atención a la correcta interpretación de la estructura interna de los datos. Aunque el modelo procesa una serie temporal, en cada paso temporal específico trabaja con el mismo conjunto fijo de características que describen el estado del entorno.
Dada la naturaleza repetitiva de la estructura de datos en cada paso temporal, hemos decidido usar una única matriz de parámetros entrenables para el análisis de todos los pasos temporales. En otras palabras, el modelo aplica un mecanismo de atención general y universal a la serie temporal completa. Esto nos permite lograr varios efectos de importancia crítica a la vez:
- aumentar la consistencia de la interpretación de las características a lo largo de diferentes periodos temporales;
- reducir significativamente el número de parámetros entrenables, lo cual es especialmente importante en condiciones de muestras de entrenamiento limitadas;
- mejorar la capacidad de generalización del modelo minimizando el sobreajuste;
- Acelerar el proceso de aprendizaje optimizando los cálculos.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; prev_count = descr.count = HistoryBars; descr.window = BarDescr; descr.layers = 1; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Tras analizar las interdependencias entre las características en cada paso temporal, el siguiente paso importante es el análisis temporal de los datos de origen. Para implementar esta tarea, primero aplicamos la transposición del tensor original, lo cual nos permite considerar cada característica individual como una secuencia de observaciones a lo largo del tiempo.
El tensor transpuesto se transmite al segundo módulo de atención lineal, que está diseñado específicamente para analizar la dinámica temporal de los datos.
Cabe señalar que, después de la transposición, en realidad estamos trabajando con un conjunto de secuencias temporales unitarias, cada una de las cuales representa la evolución de una característica específica a lo largo del tiempo. Estas características pueden pertenecer a distintas modalidades de datos. Debemos entender que diferentes modalidades pueden exhibir diferentes patrones característicos de reacción ante los mismos eventos del mercado. Por lo tanto, en esta etapa, implementaremos un enfoque más flexible: cada secuencia unitaria utiliza su propia matriz de parámetros entrenables. Este mecanismo permite:
- considerar la especificidad de cada modalidad al interpretar su dinámica temporal;
- Identificar patrones únicos en la reacción de distintos indicadores a los mismos desencadenantes del mercado;
- aumentar la sensibilidad del modelo a señales débiles pero importantes en canales de datos individuales;
- evitar mezclar información entre características que resultan incomparables por naturaleza.
Esta arquitectura es particularmente efectiva en los mercados financieros, pues los datos de diversa naturaleza pueden reaccionar a eventos fundamentales o técnicos con distinta velocidad, amplitud y dirección.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLinerAttention; descr.count = 1; descr.window = HistoryBars; descr.layers = BarDescr; descr.window_out = 32; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Después de pasar por dos niveles de atención, los datos analizados adquieren una estructura sustancialmente más rica, y ya contienen información tanto sobre la relación interna entre características como sobre las dependencias temporales características inherentes a cada modalidad. Sin embargo, para construir una estrategia de toma de decisiones en los mercados financieros que resulte eficaz, es necesario poder agregar estos datos en una forma más compacta y significativa.
Los datos enriquecidos con conexiones internas se transmiten al bloque CG-LSTM, donde se realiza el análisis independiente de las secuencias unitarias formadas en la etapa anterior. Vale la pena señalar que este enfoque difiere notoriamente de la idea original de los autores del framework DA-CG-LSTM. En la arquitectura DA-CG-LSTM clásica, las celdas unitarias recurrentes procesan representaciones multimodales de pasos temporales individuales. Este método permite considerar dependencias intermodales complejas.
Sin embargo, en nuestro proyecto hemos elegido deliberadamente una estrategia alternativa. Hemos desarrollado las ideas integradas en la arquitectura HiSSD, donde se presta especial atención a la predicción independiente de secuencias unitarias relacionadas con agentes individuales. Este enfoque permite una captura más flexible y precisa de los patrones de comportamiento específicos de cada modalidad, al tiempo que minimiza el impacto de posibles interferencias entre distintas fuentes de datos.
La opción de procesamiento de datos usada en el bloque CG-LSTM posibilita:
- una especialización más precisa de estados ocultos para aspectos específicos de los datos;
- la estabilidad del modelo ante cambios en la estructura de la información del mercado;
- el aumento de la interpretabilidad de las habilidades globales, ya que cada vector de habilidades está asociado a una modalidad específica de los datos analizados.
Al diseñar el bloque recurrente, tomamos una decisión sumamente importante: el tamaño del estado oculto de cada elemento CG-LSTM se establece igual al tamaño del vector de habilidades global de un agente. Esto permite que cada secuencia unitaria produzca una representación de salida de tamaño fijo que codifica los aspectos más importantes de su comportamiento a largo plazo. Estos se convierten en la base para la toma de decisiones posteriores en el modelo.
Debemos destacar que la construcción de la matriz de habilidades globales se da en un modo pleno de entrenamiento. El modelo determina de forma independiente qué aspectos del comportamiento de las características son más significativos para que el funcionamiento tenga éxito en condiciones comerciales reales.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGLSTMOCL; descr.count = NSkills; // Common Skkills descr.window = HistoryBars; // Sequence descr.layers = BarDescr; // Variables descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Merece la pena recordar que el programador de alto nivel del framework HiSSD aprende a formar habilidades globales a través del proceso de codificación del estado latente para predecir el próximo estado del sistema con la mayor precisión posible. De manera similar, el objetivo principal del framework DA-CG-LSTM cosiste en predecir series temporales multimodales con la mayor precisión posible. Toda su arquitectura está construida alrededor de este objetivo: un sofisticado sistema de atención, potentes unidades recurrentes y un decodificador que tienen como objetivo extraer patrones ocultos y mejorar la calidad de las predicciones.
Sin embargo, vamos a adoptar un enfoque fundamentalmente diferente y a reorientar intencionalmente la arquitectura hacia una tarea diferente: el entrenamiento del estado latente más informativo, es decir, las llamadas habilidades globales de los agentes. Para nosotros no resulta tan importante predecir con exactitud cada valor posterior de la serie temporal, sino más bien crear una representación interna del mercado que se convierta en una base sólida para el posterior entrenamiento de la política de comportamiento óptimo de los agentes.
En este contexto, vamos a abandonar deliberadamente la compleja arquitectura del decodificador DA-CG-LSTM original. Sus mecanismos de análisis del espacio latente profundo podrían distorsionar o reinterpretar las habilidades globales, haciéndolas menos adecuadas para los fines de control de los agentes.
En lugar de ello, podemos elegir un decodificador minimalista que conste de dos capas convolucionales consecutivas. Este diseño garantiza un procesamiento sencillo de representaciones ocultas, una interferencia mínima con la estructura de las habilidades globales, una alta interpretabilidad de los resultados y un procesamiento independiente de secuencias de características unitarias.
Este enfoque nos permite mantener la pureza y el valor del espacio latente formado, abriendo el camino a un aprendizaje más efectivo de la política de comportamiento del Actor.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; int prev_out = descr.window_out = 4 * NForecast; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NForecast; descr.layers = prev_count; descr.activation = TANH; if(!encoder.Add(descr)) { delete descr; return false; }
Para comparar correctamente los valores previstos con los datos reales, en la etapa final del procesamiento de los resultados del decodificador, transponemos el tensor de resultados a la estructura original de datos.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_out; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
No obstante, incluso después de restaurar la forma, los valores previstos permanecen en forma normalizada. Por consiguiente, el siguiente paso importante es la transformación inversa: agregamos los parámetros estadísticos de la distribución original de características que se han registrado en la etapa de normalización por lotes.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count * prev_out; descr.layers = 1; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
El siguiente paso consiste en observar la arquitectura del controlador de bajo nivel. Este modelo juega un papel clave en la construcción de estrategias de comportamiento local de los agentes basadas en el análisis del estado del entorno en cada momento específico del tiempo.
El controlador recibe como entrada datos del entorno sin procesar, de forma similar a lo que sucede en el codificador de habilidades globales. Su arquitectura se basa esencialmente en la misma estructura: la normalización inicial de datos con la adición de ruido aleatorio, un proceso de análisis en dos etapas mediante módulos de atención lineal y el uso de una unidad CG-LSTM recurrente para el procesamiento secuencial.
La diferencia fundamental entre las habilidades globales y locales no radica en el mecanismo con el que se construyen, sino en las tareas que los agentes resuelven durante el entrenamiento. En el caso del desarrollo de habilidades globales, el énfasis se hace en la creación de un espacio latente generalizado capaz de integrar las dependencias de largo plazo y las características clave del mercado. Las habilidades locales se centran en la rápida adaptación a la situación actual del mercado y en el desarrollo de acciones comerciales específicas para cada paso temporal.
Entonces simplemente copiamos la arquitectura del codificador de habilidades.
//--- Task task.Clear(); //--- Task Encoder for(int i = 0; i <= LatentLayer; i++) if(!task.Add(encoder.At(i))) return false;
Una vez formadas las habilidades locales, el siguiente paso consiste en enriquecerlas con información contextual de las habilidades globales de los agentes. Para resolver este problema, usamos un bloque de atención cruzada de dos capas.
Las habilidades del agente actúan como consultas (Query), mientras que las habilidades globales de todos los agentes se utilizan como claves (Key) y valores (Value). El punto clave es que las habilidades locales de cada agente individual no se interpretan de forma aislada, sino en el contexto amplio del espacio latente general del sistema de agentes al completo. Esto le permitirá tomar decisiones más informadas.
Una característica distintiva de la arquitectura de bloques es la organización en dos etapas del mecanismo de atención cruzada. En la primera etapa se implementa la Cross-Attention básica. Las consultas locales recuperan la información global más relevante. Esta operación permite a los agentes adaptar de forma flexible su comportamiento a corto plazo según el estado actual del entorno y las tendencias estratégicas captadas en las habilidades globales.
La segunda etapa mejora la integración con una capa adicional de atención, que permite identificar relaciones más complejas y profundas entre los objetivos a corto plazo y las directrices estratégicas a largo plazo.
Precisamente a través de la integración de los contextos locales y globales el modelo adquiere la capacidad de generar decisiones comerciales más equilibradas e informadas, aumentando la resiliencia de los agentes ante las señales falsas y el ruido del mercado a corto plazo.
//--- layer LatentLayer+1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { int temp[] = {NSkills, NSkills}; // WIndow if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { int temp[] = {BarDescr, BarDescr}; // Units if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; descr.window_out = 32; descr.layers = 2; descr.batch = 1e4; descr.optimization = ADAM; descr.activation = None; if(!task.Add(descr)) { delete descr; return false; }
Las habilidades locales, enriquecidas con el contexto global, se transfieren a la unidad de toma de decisiones. El papel clave aquí lo desempeña el uso de dos capas convolucionales consecutivas. Esta arquitectura permite la organización eficiente de la operación paralela de MLPs independientes para cada agente individual.
Cada agente interpreta su propio espacio latente local y toma decisiones sin interferir directamente en el funcionamiento de otros agentes. Gracias a la estructura convolucional, se logra una alta eficiencia computacional: todos los agentes se procesan simultáneamente. En este caso, cada uno trabaja con su propia matriz de parámetros del modelo.
La secuencia dual de capas convolucionales ofrece flexibilidad adicional a la arquitectura: la primera capa es responsable de la agregación inicial y la transformación de características, mientras que la segunda capa refina las representaciones locales y forma el tensor de acción final. Este enfoque permite una mejor adaptabilidad y estabilidad del comportamiento de los agentes en condiciones de alta volatilidad en los mercados financieros.
//--- layer LatentLayer+2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = NSkills; descr.step = NSkills; prev_out = descr.window_out = 4 * NActions; prev_count=descr.layers = BarDescr; descr.activation = SoftPlus; if(!task.Add(descr)) { delete descr; return false; } //--- layer LatentLayer+3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 1; descr.window = prev_out; descr.step = prev_out; prev_out = descr.window_out = NActions; descr.layers = prev_count; descr.activation = SIGMOID; if(!task.Add(descr)) { delete descr; return false; }
Las arquitecturas de los modelos del Actor, el Director y el Crítico de nivel superior se han transferido íntegramente del artículo anterior. Su descripción detallada se puede encontrar en el enlace, así que no nos detendremos en ellas ahora. En el archivo adjunto se proporciona una descripción completa de la arquitectura de todos los modelos.
Entrenamiento
El proceso de entrenamiento del modelo se organiza en tres etapas: la formación de una muestra de entrenamiento, el entrenamiento offline de todos los componentes del modelo y el posterior ajuste online. Este enfoque combina la estabilidad fundamental derivada de los datos históricos con una adaptación flexible a las condiciones actuales del mercado.
Todos los programas usados durante el entrenamiento se han transferido sin cambios desde el artículo anterior, por lo que no nos detendremos en un examen detallado de su algoritmo. Simplemente repetiremos los principios básicos del proceso.
El entrenamiento del modelo comienza con la formación de una muestra de entrenamiento. Para este propósito, usamos el asesor Research.mq5, que ejecutamos en el simulador de estrategias de MetaTrader 5 para recopilar datos históricos para el par de divisas EURUSD utilizando un marco temporal de un minuto para todo el año 2024. Para minimizar la carga, cada pasada se limita a un mes de la historia y la diversidad del comportamiento del agente se logra mediante políticas aleatorias. Después del cierre de cada vela, se registran las condiciones del mercado, las lecturas de los indicadores, las características de la cuenta y las acciones del agente, formando trayectorias completas para el búfer de reproducción de experiencias.
Los datos recopilados se convierten en la base para el entrenamiento offline de todos los componentes, que se realiza mediante el asesor Study.mq5. Las trayectorias y los puntos de inicio se seleccionan aleatoriamente del búfer para formar paquetes de entrenamiento de estados secuenciales. Para acelerar la convergencia, se usa la técnica de trayectoria casi perfecta, que permite al codificador predecir varios pasos por delante. En esta etapa se entrenan los Codificadores de Habilidades, el Actor, el Director y el Crítico, formando la política básica de comportamiento del agente.
Tras completar el entrenamiento offline, podemos pasar a la etapa de ajuste en tiempo real. Aquí se utiliza el asesor StudyOnline.mq5. El enfoque principal está en el entrenamiento del Actor bajo la guía del Director y el Crítico. Después del cierre de cada nueva vela, se analiza el entorno, se actualizan las estimaciones de acción y se ajustan los parámetros del modelo. La actualización suave periódica de los modelos objetivo ayuda a mantener un equilibrio entre la estabilidad y la adaptabilidad de la estrategia.
Este enfoque gradual, que combina la adquisición de conocimientos offline y la adaptación online, garantiza una alta eficiencia y estabilidad de los modelos al negociar en condiciones reales de mercado.
Simulación
Ya podemos obtener una evaluación objetiva de la eficacia de las decisiones implementadas y de la política comercial desarrollada utilizando datos que no se han usado en el entrenamiento del modelo. El periodo de prueba utilizado para este propósito va de enero a marzo de 2025. El uso de datos históricos fuera del conjunto de entrenamiento elimina el riesgo de sobreajuste y otorga a los resultados un valor práctico real.
Todos los demás parámetros del experimento (el entorno de mercado, el marco temporal y la configuración del terminal) se han mantenido sin cambios. Esto garantiza que se realice una prueba pura de la calidad de la estrategia aprendida, sin la influencia de factores externos.
Los resultados de la prueba se presentan a continuación y muestran claramente el modelo de comportamiento del agente en condiciones de combate.


Durante el periodo de prueba, el modelo ha completado 37 transacciones comerciales. Un poco más del 40% de ellas se han cerrado con beneficios. Sin embargo, el modelo ha logrado obtener ganancias debido a que la transacción ganadora promedio es más de 2 veces superior a la transacción perdedora promedio. El factor beneficio se ha registrado en 1,67.
Conclusión
En este artículo, presentamos los aspectos teóricos del framework DA-CG-LSTM, que se diferencia de los modelos clásicos por la presencia de componentes innovadores como CG-LSTM y el mecanismo de atención dual. Estos elementos posibilitan una extracción más precisa de las dependencias temporales y permiten tener en cuenta tanto las fluctuaciones a corto plazo como las tendencias a largo plazo.
En la parte práctica hemos presentado una arquitectura modificada y adaptada a las tareas de entrenamiento de agentes comerciales. La simplificación de los decodificadores en favor de bloques convolucionales nos ha permitido centrar el entrenamiento en la extracción de habilidades globales, un factor clave para construir posteriormente una estrategia fiable y adaptativa.
La eficacia de los enfoques implementados se ha probado en una muestra de prueba fuera del periodo de entrenamiento. Aunque la proporción de transacciones rentables ha sido algo superior al 40%, la relación media de beneficios/pérdidas ha garantizado un resultado global positivo.
Cabe destacar que los modelos descritos son todavía de carácter exploratorio. Antes de su aplicación práctica en el trading real, deberemos entrenarlos con datos más representativos y realizar pruebas exhaustivas en diversas condiciones de mercado.
Enlaces
- A Dual-Staged Attention Based Conversion-Gated Long Short Term Memory for Multivariable Time Series Prediction
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor experto para recopilar ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos offline |
| 4 | StudyOnline.mq5 | Asesor | Asesor de entrenamiento de modelos online |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17939
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
|
Ran Investigación 1 mes de 5 minutos, obtuvo 300MB de DACGLSTM.bd. Ran Estudio. Las tasas de error son aterradoras. ¿O es normal para la primera ejecución?
Después del Estudio aparecieron los archivos .nnw de la red neuronal. Comenzó una segunda ronda de recolección de datos, al mes siguiente - Investigación dejó de hacer trades....
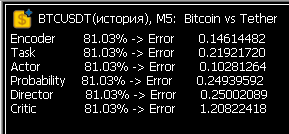
¡Sí! Después de varias semanas de baile de pandereta, ¡los valores de error en Estudio por fin han vuelto a la normalidad! Ahora la neurona aprende de verdad.
Tuvimos que ampliar el algoritmo de recompensas y penalizaciones
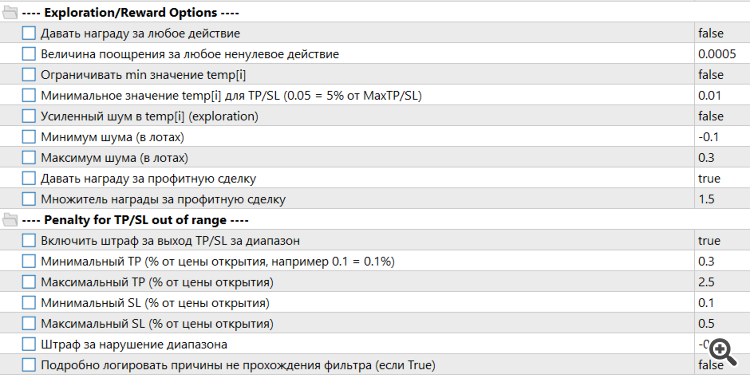
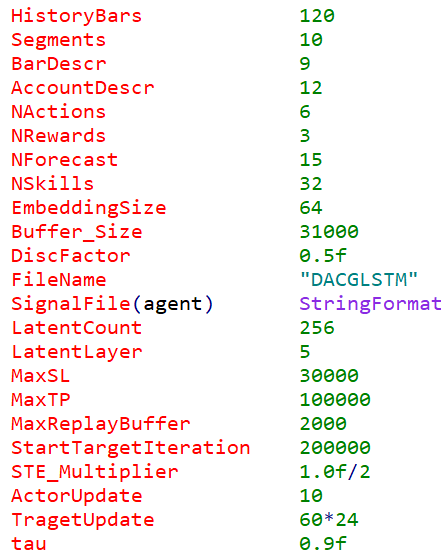
También tuvimos que hacer algunos ajustes importantes en los parámetros de entrada de Trayectoria.
¡Sí! Después de varias semanas de baile de pandereta, ¡los valores de error en Estudio por fin han vuelto a la normalidad! Ahora la neurona está aprendiendo de verdad.
Ahora lo más interesante es cómo operará con nuevos datos... Estoy haciendo modelos de madera - son más claros. Pero en los nuevos datos es el comercio casi al azar, ya que no hay características significativas.
Ahora lo más interesante es cómo va a operar con nuevos datos... Estoy haciendo modelos de madera - son más claros. Pero en los nuevos datos es el comercio casi al azar, ya que no hay características significativas.
Después de unas cuantas rondas de Investigación-Estudio, las operaciones comienzan a cerrarse muy rápidamente. Neuronka está aprendiendo a sobrevivir, no a ganar dinero. Y cuanto más corta es la operación, menos penalizada se siente. El baile de la pandereta continúa. Necesito acertar con el algoritmo de recompensa y penalización, y esa parece ser la parte más difícil. Hasta ahora, sólo intento poner algunos límites duros. Por ejemplo, no permito establecer paradas y tomas inferiores al valor umbral. También estoy tratando de limitar la duración mínima de un comercio para que no se cierran casi inmediatamente después de la apertura. Uso LLM ya sea Grok o ChatGPT 4.1, pero a veces son tan salvajemente estúpidos que mi cabeza no puede soportarlo. Pero poco a poco se sigue avanzando. Se dedica mucho tiempo a los círculos de aprendizaje. También me gustaría unir fuerzas con alguien, el tema es muy prometedor.