
Aplicação da teoria dos jogos em algoritmos de trading

Em um contexto no qual a velocidade de tomada de decisões é fundamental e o mercado é caracterizado por um alto grau de incerteza, é necessário um enfoque diferente para a criação de sistemas de trading.
O AdaptiveQ Enhanced é um EA desenvolvido com base em métodos de aprendizado profundo por reforço (DQN), teoria dos jogos e análise causal. Ele analisa o mercado modelando 531 441 estados únicos e levando em conta as interrelações entre os sete principais pares de moedas. O elemento-chave do algoritmo é o equilíbrio de Nash, aplicado para escolher a estratégia ótima em condições de influência mútua entre os instrumentos.
A nova versão do sistema conta com um conjunto ampliado de ações: além das operações padrão de compra e venda, foram adicionadas funções de aumento de posição e de fechamento seletivo de operações lucrativas. Isso garante adaptabilidade e flexibilidade em diversos cenários de mercado. O artigo discute a aplicação prática dessas abordagens em MQL5 e demonstra como a combinação de aprendizado adaptativo, teoria dos jogos e inteligência artificial (IA) permite criar estratégias de trading mais precisas e resilientes.
Fundamentos teóricos: do aprendizado por reforço ao equilíbrio de Nash
Aprendizado profundo por reforço (DQN)
Antes de mergulharmos nos aspectos técnicos do código, vamos estabelecer a base teórica. No núcleo do nosso sistema está o aprendizado profundo Q (Deep Q-Network, DQN) — uma versão moderna do algoritmo de aprendizado por reforço que provou sua eficácia não apenas em jogos, mas também na solução de desafios financeiros complexos.
No aprendizado por reforço clássico, o agente (neste caso, o sistema de trading) interage com o ambiente (o mercado), executando determinadas ações (abertura/fechamento de posições). Para cada ação o agente recebe uma recompensa e passa para um novo estado. O objetivo do agente é maximizar a recompensa acumulada ao longo do tempo.
Matematicamente, isso é expresso pela função Q, que avalia a utilidade esperada da ação a no estado s:
Q(s, a) = r + γ max Q(s', a')
onde r — recompensa imediata, γ — fator de desconto (o quanto valorizamos recompensas futuras), s' — novo estado, e a' — possíveis ações no novo estado.
Teoria dos jogos e equilíbrio de Nash
Os sistemas de trading tradicionais analisam cada instrumento isoladamente. Nosso enfoque é fundamentalmente diferente: aplicamos a teoria dos jogos para levar em conta as interrelações entre os pares de moedas.
O equilíbrio de Nash é um estado em que nenhum jogador pode melhorar seu resultado alterando unilateralmente sua estratégia. No contexto do nosso sistema, isso significa que encontramos a estratégia ótima para cada par de moedas considerando as estratégias de todos os demais pares.
No código, isso é implementado pela função DetermineActionNash(), que agora opera em um espaço ampliado de seis ações possíveis. Cada ação é avaliada não apenas com base nos dados do par de moedas específico, mas também levando em conta as correlações com outros instrumentos:
void DetermineActionNash(int symbolIdx) { double actionScores[TOTAL_ACTIONS]; // Получаем базовые оценки действий из Q-матрицы for(int action = 0; action < TOTAL_ACTIONS; action++) { actionScores[action] = qMatrix[tradeStates[symbolIdx].currentStateIdx][action][symbolIdx]; } // Корректировка на основе корреляции с другими символами (Нэш) for(int otherIdx = 0; otherIdx < TOTAL_SYMBOLS; otherIdx++) { if(otherIdx != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherIdx]; for(int action = 0; action < TOTAL_ACTIONS; action++) { double otherScore = qMatrix[tradeStates[otherIdx].currentStateIdx][action][otherIdx]; // Учитываем корреляцию только если есть значимая связь if(MathAbs(corr) > 0.3) { actionScores[action] += corr * otherScore * 0.05; } } } }
Observe o ajuste sutil, pois a correlação é considerada apenas se seu valor absoluto exceder 0.3. Isso permite filtrar o "ruído" e concentrar-se nas interrelações realmente significativas entre os pares de moedas.
Inferência causal em um espaço de ações multidimensional
Na versão atualizada do AdaptiveQ Enhanced nosso sistema recebeu um arsenal expandido de ações possíveis:
- Abertura de posição Buy
- Abertura de posição Sell
- Adição de volume às posições Buy existentes
- Adição de volume às posições Sell existentes
- Fechamento apenas das posições Buy lucrativas
- Fechamento apenas das posições Sell lucrativas
Isso amplia significativamente o potencial estratégico do sistema. Agora, ele não apenas abre e fecha posições, como também aumenta volumes à medida que a tendência se desenvolve na direção desejada. Além disso, ele fixa lucros seletivamente e mantém posições com perdas abertas, na expectativa de uma reversão do mercado.
É particularmente interessante a implementação do fechamento apenas das posições lucrativas, pois esse mecanismo permite ao sistema fixar lucro sem realizar perdas, o que melhora substancialmente a rentabilidade geral:
void ClosePositionsByTypeIfProfitable(string symbol, ENUM_POSITION_TYPE posType) { CTrade trade; CPositionInfo pos; for(int i = PositionsTotal() - 1; i >= 0; i--) { if(pos.SelectByIndex(i)) { if(pos.Symbol() == symbol && pos.PositionType() == posType) { double profit = pos.Profit(); // Закрываем только если позиция в прибыли if(profit > 0) { trade.PositionClose(pos.Ticket()); } } } } }
Implementação técnica: anatomia do AdaptiveQ Enhanced
Enorme espaço de estados e análise multinível
Uma das características centrais do nosso sistema é o enorme espaço de estados (531,441 estados únicos). Isso garante uma análise detalhada das condições de mercado e permite que o sistema se adapte a um amplo espectro de cenários.
Na versão atualizada, cada estado tornou-se ainda mais informativo. Agora o sistema analisa o mercado não apenas no timeframe atual, mas simultaneamente em três intervalos de tempo distintos: M15, H1 e H4. Essa abordagem multitimeframe permite ao AdaptiveQ Enhanced obter uma visão completa da dinâmica do mercado, desde oscilações de curto prazo até tendências de médio prazo.
Para cada timeframe o sistema monitora um conjunto completo de parâmetros:
- Diferença entre o preço e 20 médias móveis (de MA10 a MA200)
- Flags binárias da posição do preço em relação aos níveis-chave de MA
- Valores dos indicadores técnicos RSI e Stochastic
- Momentum do movimento do preço
Todos esses dados são convertidos em um índice de estado único, que é então usado para acessar a matriz Q:
int ConvertToStateIndex(MarketState &state) { double range = state.price_high - state.price_low; if(range == 0) range = 0.0001; // Базовые компоненты из цен int o_idx = (int)((state.price_open - state.price_low) / range * 9); int c_idx = (int)((state.price_close - state.price_low) / range * 9); int m_idx = (int)((state.momentum + 0.001) / 0.002 * 9); // Базовый индекс из основных компонентов int stateIdx = o_idx * 81 + c_idx * 9 + m_idx; // Добавляем компоненты из разницы с MA для текущего таймфрейма int ma_idx = 0; for(int i = 0; i < 10; i++) { int diff_idx = (int)((state.ma_diff[i] + 0.01) / 0.02 * 9); diff_idx = MathMin(MathMax(diff_idx, 0), 8); ma_idx += diff_idx * (int)MathPow(9, i % 3); } // Добавляем компоненты из индикаторов для каждого таймфрейма ulong tf_state = 0; for(int tfIdx = 0; tfIdx < TOTAL_TIMEFRAMES; tfIdx++) { // RSI: 0-100 -> 0-9 int rsi_idx = (int)(state.tf_rsi[tfIdx] / 10); rsi_idx = MathMin(MathMax(rsi_idx, 0), 9); tf_state = tf_state * 10 + rsi_idx; // Stochastic %K: 0-100 -> 0-9 int stoch_k_idx = (int)(state.tf_stoch_k[tfIdx] / 10); stoch_k_idx = MathMin(MathMax(stoch_k_idx, 0), 9); tf_state = tf_state * 10 + stoch_k_idx; // Бинарные флаги для MA: выбираем ключевые МА (10, 50, 100, 200) int ma_flags = 0; ma_flags |= state.tf_ma_above[tfIdx][0] << 0; // MA10 ma_flags |= state.tf_ma_above[tfIdx][4] << 1; // MA50 ma_flags |= state.tf_ma_above[tfIdx][9] << 2; // MA100 ma_flags |= state.tf_ma_above[tfIdx][19] << 3; // MA200 tf_state = tf_state * 16 + ma_flags; } // Хэшируем вместе базовый индекс и индикаторы ulong hash = stateIdx + ma_idx + (ulong)tf_state; // Приводим к диапазону TOTAL_STATES через хэш return (int)(hash % TOTAL_STATES); }
Observe esta função mais atentamente. Aqui ocorre uma transformação surpreendente: o espaço multidimensional dos parâmetros de mercado é convertido em um identificador de estado único. É como se tivéssemos criado um mapa multidimensional do mercado, onde cada ponto corresponde a uma combinação específica de preços e indicadores e, em seguida, o comprimíssemos em um índice unidimensional usando uma função hash.
Cache e otimização de desempenho
Considerando a complexidade computacional do sistema, dedicamos especial atenção à otimização. Na nova versão foi adicionado cache não apenas de preços e correlações, mas também dos valores de todos os indicadores utilizados:
// Кэш для цен и корреляций (оптимизация быстродействия) double bidCache[TOTAL_SYMBOLS], askCache[TOTAL_SYMBOLS]; double correlationMatrix[TOTAL_SYMBOLS][TOTAL_SYMBOLS]; double pointCache[TOTAL_SYMBOLS]; // Кэш для Point // Кэш для индикаторов double maCache[TOTAL_SYMBOLS][10]; double maTFCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; int maAboveCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; double rsiCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochKCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochDCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];Além disso, o sistema agora preserva os handles dos indicadores entre chamadas, o que evita sua criação repetida:
// Хендлы для индикаторов, чтобы избежать многократного создания int rsiHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; int stochHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];E para economizar recursos computacionais foi adicionado um mecanismo de atualização periódica dos indicadores:
// Время последнего обновления индикаторов datetime lastMAUpdate = 0; datetime lastIndicatorsUpdate = 0; int indicatorUpdateInterval = 60; // Обновлять индикаторы каждую минуту void UpdateIndicatorsCache() { datetime currentTime = TimeCurrent(); if(currentTime - lastIndicatorsUpdate < indicatorUpdateInterval) return; // ... код обновления индикаторов ... lastIndicatorsUpdate = currentTime; }
Esse artifício pode parecer trivial, mas na prática oferece um ganho significativo de desempenho, algo crítico para um sistema que opera simultaneamente com sete pares de moedas em três timeframes.
Aprendizado adaptativo com mecanismo de custo de oportunidade
O coração do nosso sistema é o mecanismo de aprendizado adaptativo, agora ainda mais avançado. Ao contrário do Q-learning clássico, o AdaptiveQ Enhanced emprega o conceito de "custo de oportunidade" (opportunity cost), que permite ao sistema aprender mais rapidamente com seus erros.
Quando o sistema toma uma decisão, ele não apenas avalia a recompensa efetiva da ação escolhida, mas também simula o resultado potencial de ações alternativas. Se constata que outra ação poderia gerar maior lucro, o sistema ajusta sua estratégia de forma mais agressiva:// Проверяем, привело ли действие к убытку и можно ли было получить прибыль с альтернативным действием bool wasLoss = reward < 0; bool couldProfit = tradeStates[symbolIdx].alternativeReward > 0 && tradeStates[symbolIdx].opportunityCost < 0; // Применяем адаптивную скорость обучения для случаев упущенной выгоды if(wasLoss && couldProfit) { // Увеличиваем скорость обучения для быстрой адаптации к неправильным решениям double adaptiveLearningRate = MathMin(learningRate * adaptiveMultiplier, 0.9); // Дополнительно уменьшаем Q-значение пропорционально упущенной выгоде newQ -= adaptiveLearningRate * MathAbs(tradeStates[symbolIdx].opportunityCost) * opportunityCostWeight; }
É semelhante ao que faz um trader experiente, que não apenas aprende com seus erros, mas também analisa as oportunidades perdidas, ajustando sua estratégia mais agressivamente quando percebe que a decisão alternativa teria sido muito melhor. Graças ao parâmetro adaptiveMultiplier, o usuário pode definir quão intensamente o sistema aprenderá com oportunidades perdidas.
Outro aspecto inovador do aprendizado é a influência causal entre os pares de moedas:
// Обновляем Q-значения для других символов на основе корреляции (каузальное обучение) for(int otherSymbol = 0; otherSymbol < TOTAL_SYMBOLS; otherSymbol++) { if(otherSymbol != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherSymbol]; // Применяем обновление только если корреляция значима if(MathAbs(corr) > 0.2) { qMatrix[tradeStates[symbolIdx].previousStateIdx][tradeStates[symbolIdx].previousAction][otherSymbol] += learningRate * reward * corr * 0.1; } } }
Quando o sistema adquire experiência em um par de moedas, ele pode transferi-la para outros instrumentos relacionados, levando em conta o grau de sua correlação. Isso cria um efeito de "aprendizado cruzado", que acelera significativamente o processo de adaptação do sistema às condições de mercado.
Aspectos práticos do uso do AdaptiveQ Enhanced
Recursos avançados de configuração e gestão de riscos
O AdaptiveQ Enhanced oferece um conjunto impressionante de parâmetros para ajustar finamente o sistema às preferências individuais do trader:
input OPERATION_MODE OperationMode = MODE_LEARN_AND_TRADE; // Режим работы системы input CLOSE_STRATEGY CloseStrategy = STRATEGY_CLOSE_ALL; // Стратегия закрытия input POSITION_MODE PositionMode = MODE_MULTI; // Режим позиций input double TradeVolume = 0.01; // Базовый объем сделки input double AddVolumePercent = 50.0; // Процент от базового объема для добавления к позиции input int TakeProfit = 2500; // Take Profit (пункты) input int StopLoss = 1500; // Stop Loss (пункты) input double LearningRate = 0.1; // Скорость обучения input double DiscountFactor = 0.9; // Фактор дисконтирования input double AdaptiveMultiplier = 1.5; // Множитель адаптивной скорости обучения input double OpportunityCostWeight = 0.2; // Вес упущенной выгоды input int MaxPositionsPerSymbol = 5; // Максимальное количество позиций на один символ
O sistema pode operar em três modos de posições: MODE_SINGLE permite ter apenas uma posição por símbolo, MODE_MULTI autoriza abrir até MaxPositionsPerSymbol posições na mesma direção, e MODE_OPPOSITE permite manter simultaneamente posições em direções opostas.
Merece atenção especial o parâmetro AddVolumePercent, que define qual volume será adicionado à posição existente nas ações ACTION_ADD_BUY e ACTION_ADD_SELL. Isso possibilita implementar uma estratégia de expansão de posições, na qual o sistema adiciona volume na direção de uma tendência bem-sucedida.
Gerenciamento inteligente de posições
A possibilidade de fechamento seletivo apenas das posições lucrativas, que é uma das inovações mais interessantes do AdaptiveQ Enhanced. Isso permite que o sistema fixe lucro enquanto dá às posições com prejuízo a chance de se recuperar:
case ACTION_CLOSE_PROFITABLE_BUYS: if(tradeStates[symbolIdx].buyPositions > 0) { // Закрываем только прибыльные позиции BUY ClosePositionsByTypeIfProfitable(symbol, POSITION_TYPE_BUY); tradeStates[symbolIdx].actionSuccessful = true; } break;
Em combinação com a capacidade de abrir múltiplas posições, isso cria uma dinâmica interessante: o sistema pode aumentar gradualmente as posições conforme a tendência se desenvolve, em seguida fixar parcialmente o lucro nos primeiros sinais de reversão, mantendo parte das posições para um possível movimento de continuação.
Salvamento periódico e carregamento do modelo treinado
O ponto alto do nosso sistema continua sendo a capacidade de salvar e carregar a Q-matrix treinada. Na nova versão esse mecanismo tornou-se ainda mais confiável graças ao salvamento automático periódico:
void CheckAndSaveQMatrix() { if(IsNewBar() && OperationMode == MODE_LEARN_AND_TRADE) { Print("Периодическое сохранение Q-матрицы..."); SaveQMatrix(); } }
O sistema verifica o surgimento de uma nova barra e periodicamente salva o conhecimento acumulado, protegendo contra a perda de dados de treinamento em caso de encerramento inesperado.
É assim que todo o sistema funciona:
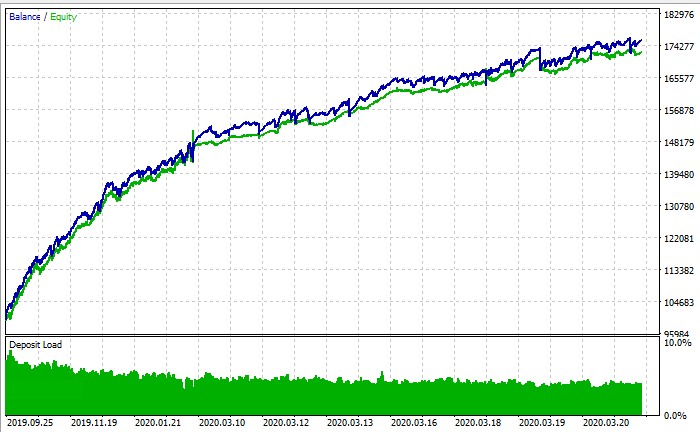
Considerações finais: novos horizontes da negociação algorítmica
O EA AdaptiveQ Enhanced não é apenas mais uma ferramenta para negociação algorítmica, mas sim uma abordagem fundamentalmente nova à análise e previsão dos mercados financeiros. Ao combinar aprendizado profundo por reforço, teoria dos jogos e inferência causal com um arsenal ampliado de ações de trading e análise multitimeframe, criamos um sistema capaz de captar interrelações complexas entre diferentes pares de moedas e tomar decisões de trading ótimas.
O mecanismo de velocidade adaptativa de aprendizado com consideração do custo de oportunidade mostrou-se especialmente eficaz. Quando o sistema toma uma decisão incorreta e uma ação alternativa poderia gerar lucro, ele aumenta a velocidade de aprendizado de acordo com AdaptiveMultiplier (por padrão em 1.5 vezes). É uma espécie de "lição de intensidade elevada", o sistema aprende mais rápido com seus erros do que com seus acertos, o que também corresponde à psicologia humana.
O futuro da negociação algorítmica está exatamente no domínio dos sistemas adaptativos, capazes de aprender e evoluir junto com o mercado. E o AdaptiveQ Enhanced não é apenas um experimento, mas uma ferramenta operacional que abre novos horizontes para pesquisa e desenvolvimento. O código apresentado neste artigo está disponível para experimentos e aperfeiçoamentos futuros. Convido a comunidade MQL5 a participar do desenvolvimento deste conceito e da criação de sistemas de trading ainda mais avançados com base em inteligência artificial e teoria dos jogos.
O mundo financeiro torna-se cada vez mais complexo e interconectado. E apenas sistemas capazes de perceber essa complexidade e adaptar-se a ela conseguirão competir com sucesso nos mercados do futuro. O AdaptiveQ Enhanced é um passo nessa direção, um passo em direção a uma negociação algorítmica mais inteligente, mais adaptativa e, em última análise, mais lucrativa.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17546
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Saudações, estou muito interessado em seu projeto, mas sou novo nesse campo. Não consigo entender como executar o Expert Advisor no testador de estratégias. Pelo que entendi, é impossível configurá-lo totalmente e treiná-lo por meio do testador? Ou estou fazendo algo errado? Ficaria muito grato se me ajudassem com o sistema operacional
Onde tenho parentes na Holanda? 👀
Como é possível que eu tenha parentes na Holanda? 👀
Ahahahahah, não na Holanda)))) VPN é uma coisa dessas)))))
PS: no final das contas, no testador de estratégia, é possível executar o treinamento ou não? De acordo com a captura de tela do gráfico de saldo, é um testador de estratégia, mas, independentemente do que eu faça, não chego nem perto de + nele
O autor apresenta o "AdaptiveQ Enhanced", um EA de FX com vários símbolos que afirma combinar DQN, equilíbrio de Nash, análise causal, sete pares de moedas principais, seis ações e 531.441 estados. O conjunto de ações inclui comprar, vender, adicionar para comprar, adicionar para vender e fechar somente compras ou vendas lucrativas.
Meu principal problema: o artigo usa mais rótulos sofisticados do que substância real. Seu "equilíbrio de Nash" não é uma solução de equilíbrio real; ele está apenas pegando os Q-scores de um símbolo e os empurrando com os Q-scores de outros símbolos ponderados pela correlação de rolagem quando |corr| > 0,3 . Isso não é teoria dos jogos em nenhum sentido sério. O mesmo problema existe com a linguagem "causal": a atualização de símbolos cruzados é literalmente baseada na recompensa vezes a correlação quando |corr| > 0,2 . Correlação não é causalidade.
O design do estado também parece instável. O artigo diz que ele constrói um estado rico de vários períodos de tempo a partir de preços, diferenças de MA, RSI, estocástico e sinalizadores de MA e, em seguida, faz um has h dessas informações multidimensionais e as reduz com hash % TOTAL_STATES . Assim, diferentes situações de mercado podem ser reunidas em um mesmo balde. Chamar isso de "531.441 estados exclusivos" parece mais impressionante do que realmente é.
A lógica de posição é a parte mais feia. O EA pode ser executado no modo de posições múltiplas ou opostas, adicionar volume às posições existentes, permitir até 5 posições por símbolo e fechar seletivamente apenas as posições lucrativas, deixando as perdedoras abertas "para recuperação". Para mim, isso não é um gerenciamento de estoque inteligente; é um caminho bem-acabado para uma exposição feia.
O que é bom: a parte de engenharia é mais séria do que as bobagens comuns da MQL5. O armazenamento em cache dos identificadores de indicadores, as atualizações periódicas e o salvamento/carregamento da matriz Q são detalhes práticos de implementação.
Portanto, na minha opinião, um experimento interessante e um projeto de negociação fraco. Há muita propaganda em torno de "IA/teoria dos jogos/inferência causal", mas não há provas suficientes de que ela tenha uma vantagem real. Eu não me basearia diretamente nessa lógica.