
Employing Game Theory Approaches in Trading Algorithms

In conditions where the speed of decision-making is critical and the market is characterized by a high degree of uncertainty, a different approach to creating trading systems is required.
AdaptiveQ Enhanced is a trading Expert Advisor developed based on deep reinforcement learning (DQN) methods, game theory, and causal analysis. The Expert Advisor analyzes the market by modeling 531,441 unique states, taking into account interrelationships between the seven major currency pairs. The key element of the algorithm is the Nash equilibrium, which is used to select the optimal strategy under conditions of mutual influence of symbols.
The new version of the system implements an expanded set of actions: in addition to the standard purchase and sale operations, the functions of position building and selective closing of profitable transactions have been added. This ensures adaptability and flexibility in various market scenarios. The article examines practical implementation of these approaches in MQL5 and demonstrates how the combination of adaptive learning, game theory and AI allows you to build more accurate and sustainable trading strategies.
Theoretical foundations: from reinforcement learning to Nash equilibrium
Deep reinforcement learning (DQN)
Before diving into technical aspects of the code, let's lay a theoretical foundation. Our system is based on deep Q-learning (Deep Q-Network (DQN), which is a modern version of a reinforcement learning algorithm that has proven effective not only in games, but also in solving complex financial problems.
In classical reinforcement learning, an agent (in our case it is a trading system) interacts with the environment (market) by performing certain actions (opening/closing positions). For each action, the agent receives a reward and moves to a new state. The agent's goal is to maximize the cumulative reward over time.
Mathematically, this is expressed in terms of a Q-function that evaluates the expected usefulness of an a action in s state:
Q(s, a) = r + γ max Q(s', a')
where r is the immediate reward, γ is the discount factor (how much we value future rewards), s' is the new state, and a' is possible actions in the new state.
Game theory and Nash equilibrium
Traditional trading systems consider each symbol in isolation. Our approach is fundamentally different: we apply game theory to account for interrelationships between currency pairs.
A Nash equilibrium is a state in which no player can improve their score by unilaterally changing their strategy. In the context of our system, this means that we find the optimal strategy for each currency pair, subject to strategies of all other pairs.
In the code, this is implemented through the DetermineActionNash() function, which now works with an expanded space of six possible actions. Each action is evaluated not only based on the data of a specific currency pair, but also taking into account correlations with other symbols:
void DetermineActionNash(int symbolIdx) { double actionScores[TOTAL_ACTIONS]; // Get basic estimates of actions from Q-matrix for(int action = 0; action < TOTAL_ACTIONS; action++) { actionScores[action] = qMatrix[tradeStates[symbolIdx].currentStateIdx][action][symbolIdx]; } // Correction based on correlation with other symbols (Nash) for(int otherIdx = 0; otherIdx < TOTAL_SYMBOLS; otherIdx++) { if(otherIdx != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherIdx]; for(int action = 0; action < TOTAL_ACTIONS; action++) { double otherScore = qMatrix[tradeStates[otherIdx].currentStateIdx][action][otherIdx]; // Take correlation into account only if there is significant relationship if(MathAbs(corr) > 0.3) { actionScores[action] += corr * otherScore * 0.05; } } } }
Pay attention to the fine—tuning - a correlation is taken into account only if its absolute value exceeds 0.3. This allows you to filter out the "noise" and focus on the really significant relationships between currency pairs.
Causal inference in a multidimensional action space
In the updated version of AdaptiveQ Enhanced, our system has received an expanded arsenal of possible actions:
- Opening a Buy position
- Opening a Sell position
- Adding volume to existing Buy positions
- Adding volume to existing Sell positions
- Closing only profitable Buy positions
- Closing only profitable Sell positions
This significantly enriches the strategic potential of the system. Now it can not only open and close positions, but also increase volumes when the trend develops in the right direction, as well as selectively lock in profits, leaving loss positions open in anticipation of a market reversal.
It is pecifically interesting to close only profitable positions. This mechanism allows the system to lock in profits without realizing losses, which significantly improves overall profitability:
void ClosePositionsByTypeIfProfitable(string symbol, ENUM_POSITION_TYPE posType) { CTrade trade; CPositionInfo pos; for(int i = PositionsTotal() - 1; i >= 0; i--) { if(pos.SelectByIndex(i)) { if(pos.Symbol() == symbol && pos.PositionType() == posType) { double profit = pos.Profit(); // Close only if position is in profit if(profit > 0) { trade.PositionClose(pos.Ticket()); } } } } }
Technical implementation: AdaptiveQ Enhanced anatomy
Huge state space and multi-level analysis
One of the key features of our system is its huge state space (531,441 unique states). This provides a detailed analysis of market conditions and allows the system to adapt to a wide range of scenarios.
In the updated version, each state has become even more informative. Now the system analyzes the market not only on the current timeframe, but simultaneously on three different time intervals: M15, H1 and H4. This multi-timeframe approach allows AdaptiveQ Enhanced to get a complete picture of market dynamics — from short-term fluctuations to medium-term trends.
For each timeframe, the system tracks a whole range of parameters:
- The difference between the price and 20 moving averages (from MA10 to MA200)
- Binary flags of price position relative to key MA levels
- Values of RSI and Stochastic technical indicators
- Momentum of price movement
All this data is converted into a unique state index, which is then used to access the Q-matrix:
int ConvertToStateIndex(MarketState &state) { double range = state.price_high - state.price_low; if(range == 0) range = 0.0001; // Basic components from prices int o_idx = (int)((state.price_open - state.price_low) / range * 9); int c_idx = (int)((state.price_close - state.price_low) / range * 9); int m_idx = (int)((state.momentum + 0.001) / 0.002 * 9); // Basic index from main components int stateIdx = o_idx * 81 + c_idx * 9 + m_idx; // Add components from difference with MA for current timeframe int ma_idx = 0; for(int i = 0; i < 10; i++) { int diff_idx = (int)((state.ma_diff[i] + 0.01) / 0.02 * 9); diff_idx = MathMin(MathMax(diff_idx, 0), 8); ma_idx += diff_idx * (int)MathPow(9, i % 3); } // Add components from indicators for each timeframe ulong tf_state = 0; for(int tfIdx = 0; tfIdx < TOTAL_TIMEFRAMES; tfIdx++) { // RSI: 0-100 -> 0-9 int rsi_idx = (int)(state.tf_rsi[tfIdx] / 10); rsi_idx = MathMin(MathMax(rsi_idx, 0), 9); tf_state = tf_state * 10 + rsi_idx; // Stochastic %K: 0-100 -> 0-9 int stoch_k_idx = (int)(state.tf_stoch_k[tfIdx] / 10); stoch_k_idx = MathMin(MathMax(stoch_k_idx, 0), 9); tf_state = tf_state * 10 + stoch_k_idx; // Binary flags for MA: selecting key MAs (10, 50, 100, 200) int ma_flags = 0; ma_flags |= state.tf_ma_above[tfIdx][0] << 0; // MA10 ma_flags |= state.tf_ma_above[tfIdx][4] << 1; // MA50 ma_flags |= state.tf_ma_above[tfIdx][9] << 2; // MA100 ma_flags |= state.tf_ma_above[tfIdx][19] << 3; // MA200 tf_state = tf_state * 16 + ma_flags; } // Hash base index and indicators together ulong hash = stateIdx + ma_idx + (ulong)tf_state; // Reduce to range TOTAL_STATES through hash return (int)(hash % TOTAL_STATES); }
Take a closer look at this feature. An amazing transformation is taking place here: a multidimensional space of market parameters is transformed into a unique status identifier. It is as if we created a multidimensional market map, where each point corresponds to a specific combination of prices and indicators, and then collapsed it into a one-dimensional index using a hash function.
Caching and performance optimization
Given computational complexity of the system, we paid special attention to optimization. Caching not only of prices and correlations, but also of the values of all indicators used has been added to the new version:
// Cache for prices and correlations (performance optimization) double bidCache[TOTAL_SYMBOLS], askCache[TOTAL_SYMBOLS]; double correlationMatrix[TOTAL_SYMBOLS][TOTAL_SYMBOLS]; double pointCache[TOTAL_SYMBOLS]; // Cache for Point // Cache for indicators double maCache[TOTAL_SYMBOLS][10]; double maTFCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; int maAboveCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; double rsiCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochKCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochDCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];Moreover, the system now saves indicator handles between calls, which allows to avoid their repeated creation:
// Indicator handles to avoid multiple creation int rsiHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; int stochHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];And to save computing resources, a mechanism for periodically updating indicators has been added:
// Time of last update of indicators datetime lastMAUpdate = 0; datetime lastIndicatorsUpdate = 0; int indicatorUpdateInterval = 60; // Update indicators every minute void UpdateIndicatorsCache() { datetime currentTime = TimeCurrent(); if(currentTime - lastIndicatorsUpdate < indicatorUpdateInterval) return; // ... indicator update code ... lastIndicatorsUpdate = currentTime; }
This technique may seem trivial, but in practice it provides significant performance gains, which is critically important for a system operating simultaneously with seven currency pairs on three timeframes.
Adaptive learning with an opportunity cost mechanism
The heart of our system is the adaptive learning engine, which has now become even more advanced. Unlike classic Q-learning, AdaptiveQ Enhanced uses the concept of "opportunity cost," which allows the system to learn faster from its mistakes.
When the system makes a decision, it not only evaluates the actual reward from the chosen action, but also models a potential outcome of alternative actions. If it turns out that another action could bring more profit, the system adjusts its strategy more aggressively:// Check whether an action resulted in a loss and whether it was possible to make a reward with an alternative action bool wasLoss = reward < 0; bool couldProfit = tradeStates[symbolIdx].alternativeReward > 0 && tradeStates[symbolIdx].opportunityCost < 0; // Apply adaptive learning rate for cases of opportunity cost if(wasLoss && couldProfit) { // Increase learning rate to quickly adapt to incorrect decisions double adaptiveLearningRate = MathMin(learningRate * adaptiveMultiplier, 0.9); // Additionally, reduce the Q-value in proportion to the opportunity cost newQ -= adaptiveLearningRate * MathAbs(tradeStates[symbolIdx].opportunityCost) * opportunityCostWeight; }
This is similar to how an experienced trader not only learns from his mistakes, but also analyzes missed opportunities, adjusting his strategy more aggressively when he sees that an alternative solution would be significantly better. Thanks to adaptiveMultiplier parameter, the user can configure how intensively the system will learn from missed opportunities.
Another innovative aspect of learning is the causal effect between currency pairs:
// Update Q-values for other symbols based on correlation (causal learning) for(int otherSymbol = 0; otherSymbol < TOTAL_SYMBOLS; otherSymbol++) { if(otherSymbol != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherSymbol]; // Apply update only if correlation is significant if(MathAbs(corr) > 0.2) { qMatrix[tradeStates[symbolIdx].previousStateIdx][tradeStates[symbolIdx].previousAction][otherSymbol] += learningRate * reward * corr * 0.1; } } }
When the system gains experience on one currency pair, it can transfer it to other related symbols, subject to the degree of their correlation. This creates a "cross-learning" effect, which significantly speeds up the process of adapting the system to market conditions.
Practical aspects of using AdaptiveQ Enhanced
Advanced customization and risk management features
AdaptiveQ Enhanced offers an impressive set of parameters for fine-tuning the system to individual trader preferences:
input OPERATION_MODE OperationMode = MODE_LEARN_AND_TRADE; // System operating mode input CLOSE_STRATEGY CloseStrategy = STRATEGY_CLOSE_ALL; // Close strategy input POSITION_MODE PositionMode = MODE_MULTI; // Position mode input double TradeVolume = 0.01; // Base volume of trade input double AddVolumePercent = 50.0; // Percentage of base volume to add to position input int TakeProfit = 2500; // Take Profit (points) input int StopLoss = 1500; // Stop Loss (points) input double LearningRate = 0.1; // Learning rate input double DiscountFactor = 0.9; // Discount factor input double AdaptiveMultiplier = 1.5; // Adaptive learning rate multiplier input double OpportunityCostWeight = 0.2; // Opportunity cost weight input int MaxPositionsPerSymbol = 5; // Maximum number of positions per symbol
The system can operate in three position modes: MODE_SINGLE allows you to have only one position for each symbol, MODE_MULTI allows you to open up to MaxPositionsPerSymbol of unidirectional positions, and MODE_OPPOSITE allows you to simultaneously have positions in opposite directions.
The AddVolumePercent parameter deserves special attention. It determines how much volume will be added to an existing position when ACTION_ADD_BUY and ACTION_ADD_SELL are being performed. This enables to implement a position building strategy when the system adds volume in the direction of a successful trend.
Intelligent position management
A feature to selectively close only profitable positions is one of the most interesting innovations in AdaptiveQ Enhanced. This allows the system to lock in profits while giving loss positions a chance to recover:
case ACTION_CLOSE_PROFITABLE_BUYS: if(tradeStates[symbolIdx].buyPositions > 0) { // Close only profitable BUY positions ClosePositionsByTypeIfProfitable(symbol, POSITION_TYPE_BUY); tradeStates[symbolIdx].actionSuccessful = true; } break;
Combined with the feature to open multiple positions, this creates interesting dynamics: the system can gradually build up positions as a trend develops, then partially lock in profits at the first signs of a reversal, saving some positions for a potential continuation of the movement.
Periodic saving and loading of the trained model
The highlight of our system is still the feature to save and load a trained Q-matrix. In the new version, this mechanism has become even more reliable, thanks to periodic automatic saving:
void CheckAndSaveQMatrix() { if(IsNewBar() && OperationMode == MODE_LEARN_AND_TRADE) { Print("Periodic saving of Q-matrix..."); SaveQMatrix(); } }
The system checks for the appearance of a new bar and periodically saves the accumulated knowledge. This protects against the loss of training data in the event of an unexpected shutdown.
The entire system operates like this:
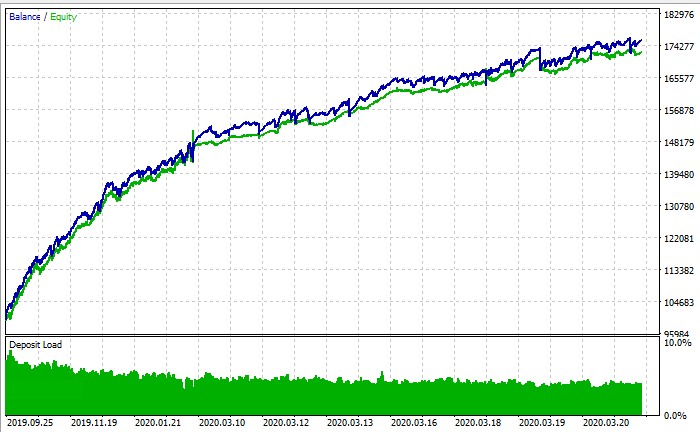
Conclusion: New horizons for algorithmic trading
The AdaptiveQ Enhanced trading expert advisor is not just another algorithmic trading tool, but a fundamentally new approach to analyzing and forecasting financial markets. By combining deep reinforcement learning, game theory, and causal inference with an expanded arsenal of trading actions and multi-timeframe analysis, we have created a system capable of capturing complex relationships between different currency pairs and making optimal trading decisions.
The mechanism of adaptive learning rate, subject to opportunity cost, proved to be particularly effective. When the system makes a wrong decision, and an alternative action could bring profit, it increases the learning rate in accordance with AdaptiveMultiplier (1.5 times by default). This is a kind of "high—intensity lesson" - the system learns faster from its mistakes than from successes, which corresponds to human psychology, as well.
The future of algorithmic trading lies precisely in the field of adaptive systems that can learn and evolve with the market. And AdaptiveQ Enhanced is not just an experiment, but a working tool that opens up new horizons for research and development. The code provided in this article is available for experimentation and further improvement. I invite the MQL5 community to participate in the development of this concept and the creation of even more advanced trading systems based on artificial intelligence and game theory.
The world of finance is becoming more complex and interconnected. And only systems capable of perceiving this complexity and adapting to it will be able to successfully compete in the markets of the future. AdaptiveQ Enhanced is a step in this direction, a step towards smarter, more adaptive, and ultimately more profitable algorithmic trading.
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/17546
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Greetings, I am very interested in your project, but I am new to this field. I can't understand how to run the Expert Advisor in the strategy tester. As I understand it is impossible to fully configure and train it through the tester? Or am I doing something wrong? I would be grateful for the OS
Where I have relatives in the Netherlands from? 👀
How come I have relatives in the Netherlands? 👀
Ahahahahah, not in the Netherlands)))) VPN is such a thing)))))
PS: bottom line in the strategy tester is it possible to run training or not? According to the balance chart screenshot it's a strategy tester, but whatever I do I don't even get close to + in it
The author presents “AdaptiveQ Enhanced,” a multi-symbol FX EA that claims to combine DQN, Nash equilibrium, causal analysis, seven major currency pairs, six actions, and 531,441 states. The action set includes buy, sell, add to buy, add to sell, and closing only profitable buys or sells.
My main problem: the article uses fancy labels more than real substance. Its “Nash equilibrium” is not an actual equilibrium solve; it is just taking a symbol’s Q-scores and nudging them with other symbols’ Q-scores weighted by rolling correlation when |corr| > 0.3 . That is not game theory in any serious sense. The same issue exists with the “causal” language: the cross-symbol update is literally based on reward times correlation when |corr| > 0.2 . Correlation is not causality.
The state design also looks shaky. The article says it builds a rich multi-timeframe state from prices, MA differences, RSI, stochastic, and MA flags, then hashes that multidimensional information and reduces it with hash % TOTAL_STATES . So different market situations can collapse into the same bucket. Calling that “531,441 unique states” sounds more impressive than it really is.
The position logic is the ugliest part. The EA can run in multi-position or opposite-position mode, add volume to existing positions, allow up to 5 positions per symbol, and selectively close only profitable positions while leaving losers open “to recover.” That is not smart inventory management to me; that is a dressed-up path to ugly exposure.
What is good: the engineering side is more serious than average MQL5 fluff. Caching indicator handles, periodic updates, and saving/loading the Q-matrix are practical implementation details.
So in my opinion an interesting experiment and weak trading design. Too much branding around “AI/game theory/causal inference,” not enough proof that it has a real edge. I would not build on this logic directly.