
Migrando para o MQL5 Algo Forge (Parte 4): Trabalhando com versões e lançamentos
Introdução
Nossa transição para o MQL5 Algo Forge continua e, após configurar o fluxo de trabalho com repositórios próprios, voltamo-nos para uma das principais razões dessa mudança, que é a possibilidade de usar facilmente códigos da comunidade. Na parte 3, vimos como adicionar ao seu projeto uma biblioteca pública de um repositório de terceiros.
O experimento de integração da biblioteca SmartATR ao EA SimpleCandles mostrou claramente que o caminho direto (o simples clone) nem sempre é conveniente, especialmente se o código precisar de ajustes. Elaboramos um fluxo de trabalho detalhado por meio da criação de um fork, que se tornou nossa cópia pessoal do repositório de outro autor para corrigir erros e fazer modificações, com a possibilidade futura de propor essas alterações ao autor por meio de um Pull Request.
Apesar de algumas limitações na interface do MetaEditor, a combinação com a interface web do repositório MQL5 Algo Forge permitiu executar com sucesso toda a cadeia de ações desde o clone até o commit das alterações e a conexão final do projeto com a biblioteca externa. Assim, não apenas resolvemos uma tarefa específica, como também analisamos um modelo de ações universal para integrar qualquer componente de terceiros.
No artigo de hoje, vamos examinar mais de perto a etapa de publicação das alterações feitas no repositório, que formam uma solução completa, seja a adição de uma nova funcionalidade ao projeto ou a correção de um erro identificado. Trata-se do controle de versão ou do lançamento de uma nova versão do produto. Vamos ver como organizar esse processo e quais recursos o repositório MQL5 Algo Forge oferece para isso.
Busca de branch
Nas partes anteriores, recomendamos o uso de uma branch separada no repositório para aplicar um conjunto de alterações que resolvam uma tarefa específica. No entanto, após a finalização do trabalho nessa branch, é recomendável mesclá-la com a principal e excluí-la. Caso contrário, o repositório pode se tornar um emaranhado de galhos secos, no qual até mesmo o próprio dono pode se perder facilmente. Por isso, as branches já utilizadas devem ser excluídas. Porém, às vezes, pode surgir a necessidade de restaurar o código para o estado em que ele estava imediatamente antes da exclusão de uma determinada branch. Como fazer isso?
Antes de tudo, vamos esclarecer que uma branch não passa de uma sequência de commits ordenados no tempo. Tecnicamente, uma branch representa um ponteiro para um commit específico, considerado o último em uma cadeia de commits consecutivos. Portanto, a exclusão de uma branch não apaga os commits. No pior dos casos, eles podem passar a ser considerados pertencentes a outra branch ou até mesmo se fundir em um único commit agregado, mas, de todo modo, continuam existindo no repositório (com raras exceções). Assim, para retornar ao estado "antes da exclusão da branch", é necessário encontrar um dos commits que se encontram em alguma branch existente. Então, a questão é: como encontrar o commit necessário?
Vamos observar o estado do repositório SimpleCandles após as modificações mencionadas na parte 3:
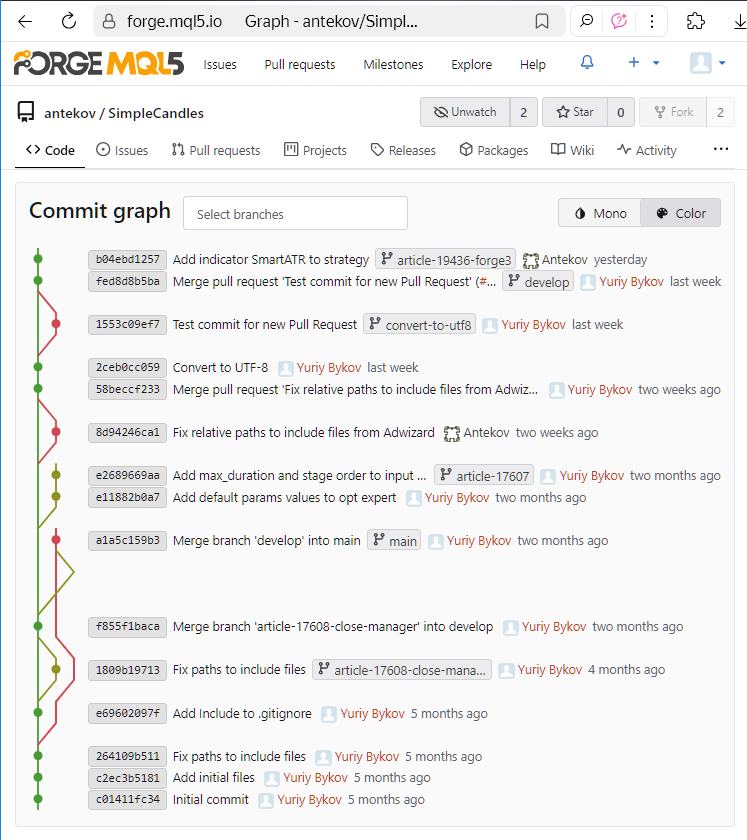
Vemos o histórico dos commits realizados e uma visualização colorida das relações entre as diferentes branches à esquerda. Cada commit exibe seu hash (mais precisamente, uma parte dele) que é um número grande e único que o identifica entre todos os outros. Para reduzir o tamanho da representação, esse número é exibido no formato hexadecimal (por exemplo, b04ebd1257).
Essa árvore de commits pode ser visualizada para qualquer repositório em uma página separada da interface web do repositório MQL5 Algo Forge. Essa captura de tela foi feita há algum tempo. Se acessarmos essa página agora, veremos uma imagem um pouco diferente: na árvore de commits haverá novos commits, e o entrelaçamento das branches também será outro, devido aos novos commits de merge adicionados.
Além disso, ao lado de alguns commits vemos os nomes das branches. Eles são exibidos nos commits mais recentes de cada branch. Na captura de tela apresentada, é possível identificar seis branches diferentes: main, develop, convert-to-utf8, article-17608-close-manager, article-17607 e article-19436-forge3. A última mencionada é a branch com as alterações feitas durante a redação da parte anterior, a parte 3. No entanto, quando trabalhamos na parte 2, também criamos uma branch separada para as alterações planejadas. Ela se chamava article-17698-forge2, e agora já foi excluída, por isso não há nenhum commit associado a esse nome de branch. Onde podemos encontrá-la?
Se observarmos o comentário completo do commit 58beccf233, veremos que ele menciona o nome dessa branch e informa que ela foi mesclada na branch develop:

Portanto, encontramos o commit necessário, mas localizá-lo dessa maneira não é muito prático. Além disso, se não tivéssemos usado o mecanismo de Pull Request para fazer o merge das branches e tivéssemos feito o processo manualmente através dos comandos de console git merge, poderíamos ter inserido um comentário personalizado para o commit de mesclagem. Nesse caso, encontrar esse commit seria ainda mais difícil, pois o nome da branch poderia nem ter sido incluído no comentário.
Agora temos a possibilidade de alternar para esse commit e trazer nosso repositório local ao estado correspondente logo após esse commit. Para isso, podemos usar o hash do commit desejado no comando git checkout. No entanto, há alguns detalhes importantes aqui. Se tentarmos fazer essa alternância para o commit diretamente no MetaEditor, escolhendo-o no histórico aberto ao clicar no item "Git Log" do menu de contexto do projeto:
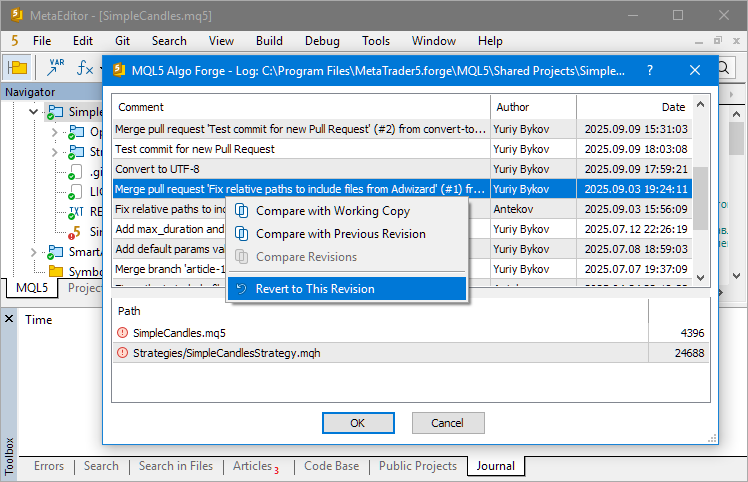
... receberemos uma mensagem de erro:

Talvez isso não seja por acaso. Vamos analisar mais a fundo o que está acontecendo. Comecemos entendendo dois novos conceitos: "tag" e "ponteiro HEAD".
O que são tags
No sistema de controle de versão Git, uma tag (ou marcador) é um nome adicional atribuído a um commit específico. Também podemos defini-la como um ponteiro ou referência para uma versão específica do código no repositório, pois ela realmente aponta para um commit determinado. O uso de tags permite retornar, a qualquer momento, ao estado do código correspondente ao commit marcado. As tags ajudam a destacar momentos importantes no desenvolvimento do projeto, como o lançamento de uma nova versão, a conclusão de uma etapa de trabalho ou o alcance de uma versão estável. Na interface web do repositório MQL5 Algo Forge, as tags de um repositório podem ser visualizadas em uma página separada.
No Git, existem dois tipos de tags: leves e anotadas. As tags leves possuem apenas um nome, enquanto as tags anotadas podem conter informações adicionais como autor, data, comentários e até assinatura digital. Na maioria dos casos, utilizam-se tags leves.
Para criar uma tag através da interface web, é possível acessar a página de qualquer commit (por exemplo, este) e, clicando no botão "Operations", selecionar o item "Create tag":
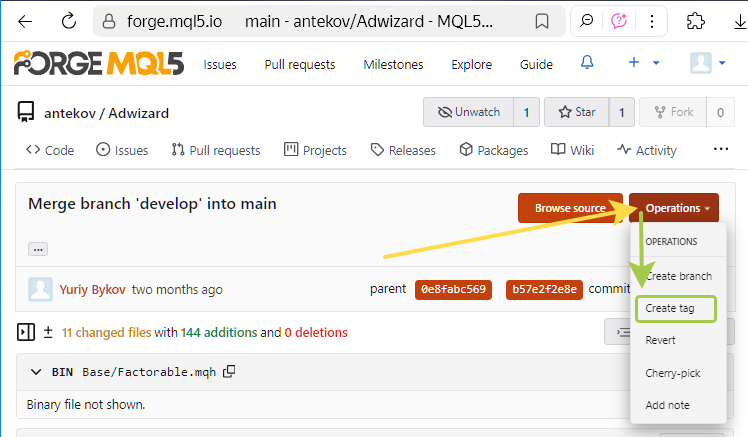
No entanto, não faremos isso por enquanto; voltaremos à criação de tags mais adiante.
Para criar uma tag via comandos de console do Git, utiliza-se o comando git tag. Para criar uma tag leve, basta especificar um único parâmetro, que é o nome da tag a ser criada:
git tag <nome-da-tag>
# Por exemplo
git tag v1.0
Para criar uma tag anotada, é necessário indicar parâmetros adicionais:
git tag -a <nome-da-tag> -m "Descrição da tag"
# Por exemplo:
git tag -a v1.0 -m "Lançamento da versão 1.0"
Além de marcar versões do código destinadas à publicação ou execução, as tags também são usadas para acionar pipelines de CI/CD, indicando que determinadas ações predefinidas devem ser executadas quando um commit com uma tag específica for realizado, ou ainda para marcar etapas significativas no desenvolvimento do projeto, como a conclusão de grandes funcionalidades ou a correção de erros críticos, mesmo que isso não represente o lançamento de uma nova versão.
Ponteiro HEAD
Falando sobre tags, vale também mencionar algo chamado ponteiro HEAD. Seu comportamento é semelhante ao de uma tag com o nome fixo HEAD, que se move automaticamente para o último commit da branch atualmente extraída. O HEAD também pode ser chamado de "marcador da branch atual" ou "ponteiro para a branch ativa". Ele responde à pergunta: "Onde estamos no nosso repositório neste momento?". No entanto, ele não é exatamente uma tag.
Fisicamente, esse ponteiro é armazenado no arquivo .git/HEAD dentro do repositório. O conteúdo de HEAD pode conter tanto uma referência simbólica (como o nome de uma branch ou tag) quanto um hash de commit. Quando alternamos entre branches, o ponteiro HEAD é atualizado automaticamente para apontar para o último commit da branch atual. Quando criamos um novo commit, o Git não apenas gera o objeto de commit, mas também move o ponteiro HEAD para ele.
Dessa forma, o nome "HEAD" pode ser usado nos comandos de console do Git em vez do hash do último commit ou do nome da branch atual. Utilizando os símbolos especiais "~" e "^", podemos referenciar commits anteriores ao último. Por exemplo, "HEAD~2" indica o commit que está dois commits atrás (ou seja, anterior) ao commit mais recente. Mas não entraremos em tantos detalhes agora.
Para prosseguir, é importante mencionar dois estados possíveis em que um repositório pode se encontrar. O estado normal é chamado "attached HEAD" e significa que os novos commits criados serão adicionados à frente do último commit da branch atual. Nesse estado, todas as alterações são registradas de forma sequencial e sem conflitos dentro da branch.
O outro estado, chamado "detached HEAD", ocorre quando o ponteiro HEAD passa a apontar para um commit que não é o último de nenhuma branch. Isso pode acontecer, por exemplo, ao:- alternar o repositório para um commit anterior específico (por exemplo, com o comando git checkout <commit-hash>);
- alternar o repositório para um commit marcado por uma tag (por exemplo, git checkout tags/<tag-name>);
- alternar o repositório para uma branch que ainda existe no repositório remoto, mas já foi removida do repositório local (por exemplo, git checkout origin/<branch-name>).
Esse estado deve ser evitado sempre que possível, pois qualquer modificação feita nele não está associada a nenhuma branch e pode ser perdida ao mudar para outra branch. No entanto, se não planejamos fazer alterações nesse estado, não há problema em permanecer nele temporariamente.
Por enquanto, não há tags
Vamos agora voltar à tentativa de alternar nosso repositório local para um commit específico, que em algum momento foi o último da branch remota article-17698-forge2.
Na verdade, alternar o repositório para o estado de um commit específico não é algo comum no Git. Em um fluxo de trabalho normal, esse tipo de operação raramente é necessário. No entanto, se decidirmos fazê-lo, o repositório entra no estado "detached HEAD" ao ser alternado para um commit determinado pelo seu hash. Nesse caso, o commit está integrado à branch develop, e após ele já existem outros mais recentes, o que significa que não se trata do último da sequência.
Ainda assim, se utilizarmos comandos de console para executar essa operação de alternância, o resultado será alcançado. No entanto, o Git exibirá um aviso claro sobre o estado "detached HEAD":
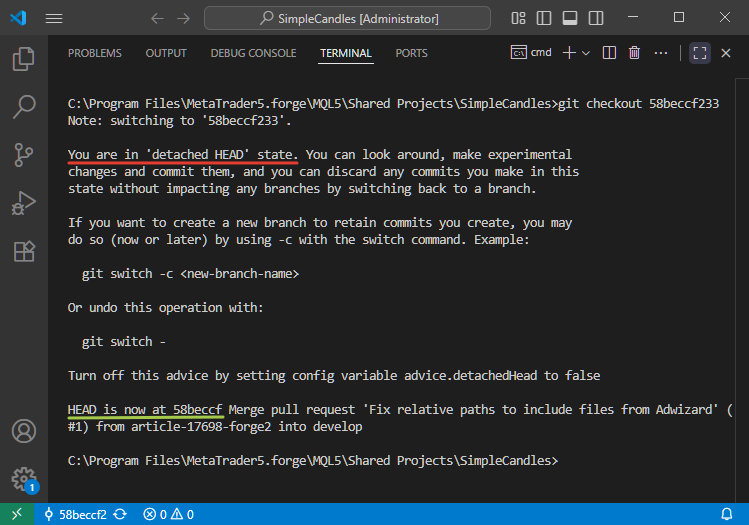
Leitores mais atentos podem notar que, na última captura de tela, alternamos para o commit com o hash 58beccf233, mas o Git mostra que o ponteiro HEAD está agora sobre o commit com o hash 58beccf. Para onde foram os três últimos dígitos? Tudo certo, eles não desapareceram. O Git simplesmente é capaz de interpretar corretamente, nos comandos, não apenas o hash completo, mas também uma parte dele. Assim, em diferentes interfaces de trabalho com o Git, podemos encontrar hashes encurtados com diferentes comprimentos (geralmente entre 4 e 10 caracteres).
Se quisermos ver o hash completo de um commit, podemos fazê-lo facilmente executando o comando git log. O hash completo contém 40 dígitos:
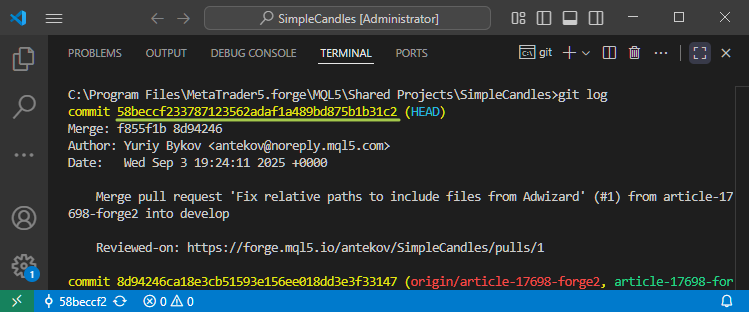
Mas, devido à geração aleatória do hash para cada novo commit, mesmo as primeiras cifras desse número têm uma probabilidade extremamente baixa de se repetirem dentro de um mesmo repositório. Por isso, indicar apenas uma parte curta do hash já é suficiente para que o Git identifique corretamente qual commit está sendo referenciado no comando executado.
Uso da codificação UTF-8
Vale mencionar mais um aspecto interessante. Em versões mais antigas, o editor MetaEditor usava a codificação UTF-16LE para salvar os códigos-fonte. No entanto, os arquivos gravados com essa codificação eram, por algum motivo, considerados binários pelo Git, e não arquivos de texto. Por isso, não era possível visualizar, no momento do commit, quais linhas de código haviam sido modificadas (embora fosse possível vê-las normalmente no Visual Studio Code). O máximo que o Git mostrava era o tamanho dos arquivos antes e depois das alterações incluídas no commit.
Veja como isso aparecia na interface web do repositório MQL5 Algo Forge:
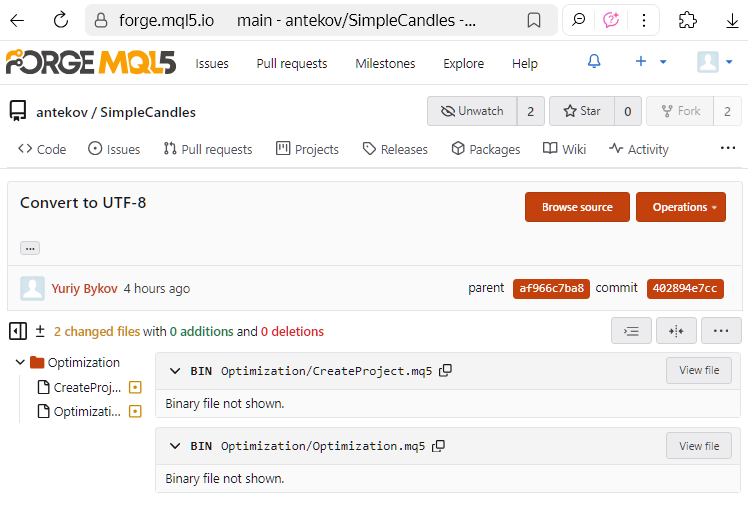
Atualmente, os novos arquivos criados no MetaEditor são salvos com a codificação UTF-8, e o uso de caracteres de alfabetos nacionais não faz com que o editor altere automaticamente para a codificação UTF-16LE. Portanto, é recomendável converter os arquivos antigos que migraram para o novo repositório a partir de versões mais antigas para a codificação UTF-8. Após realizar essa conversão, será possível visualizar exatamente quais linhas e caracteres foram modificados a partir do próximo commit. Na interface web do repositório MQL5 Algo Forge, por exemplo, isso pode ser visualizado da seguinte maneira:
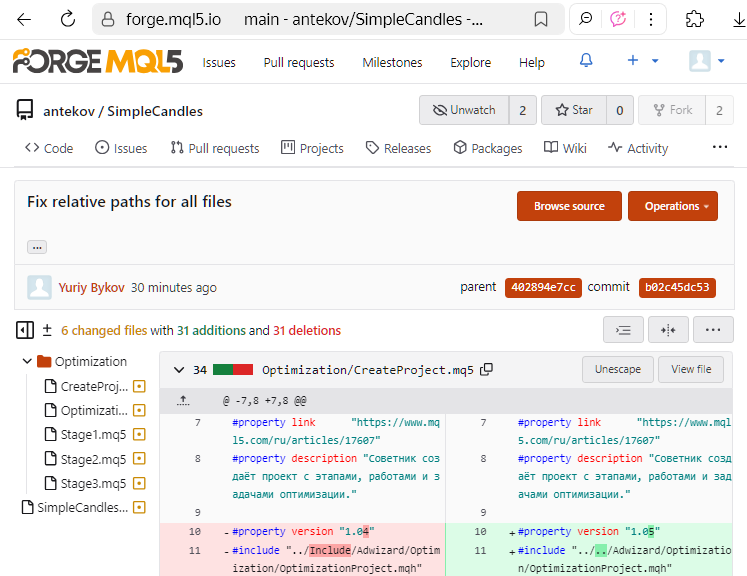
Mas isso foi apenas um parêntese; voltemos à questão sobre a publicação de uma nova versão do código no repositório.
Retornando à tarefa principal
Assim, entre as branches do nosso repositório, destacamos duas: article-17608-close-manager e article-17607. As alterações feitas nelas ainda não foram mescladas à branch develop, pois o trabalho relacionado a essas tarefas ainda não foi concluído. Ou seja, essas branches ainda estão em desenvolvimento, e por isso ainda não é o momento de incorporar suas mudanças à develop. Nosso objetivo é continuar o trabalho em uma delas (article-17607), levá-la até um ponto lógico de conclusão e, em seguida, mesclá-la com a branch develop. O estado final do código será marcado com uma tag de número de versão.
Para isso, primeiro precisamos preparar a branch escolhida para receber novas alterações, já que, durante o tempo em que ela existiu, outras branches paralelas também receberam modificações. Essas alterações já foram integradas à branch develop. Portanto, precisamos garantir que essas atualizações da develop sejam também aplicadas à nossa branch escolhida.
Existem várias maneiras de incorporar as mudanças de develop em article-17607. Por exemplo, podemos criar um Pull Request através da interface web e repetir o processo de mesclagem descrito na parte anterior. No entanto, esse procedimento é mais adequado quando queremos integrar um código novo e ainda não testado a uma branch que contém código estável e validado. No nosso caso, a situação é inversa: queremos trazer alterações de uma branch estável e testada para uma branch com código novo e ainda não verificado. Por isso, é perfeitamente aceitável realizar essa mesclagem utilizando comandos de console do Git. Vamos usar o terminal e acompanhar o andamento do processo no Visual Studio Code.
Primeiro, verificamos o estado atual do repositório. Na seção de controle de versão, vemos o histórico de commits com os nomes das branches indicados. A branch atual é a article-19436-forge3, onde foram feitas as últimas modificações. À direita, no terminal, vemos o resultado do comando git status:
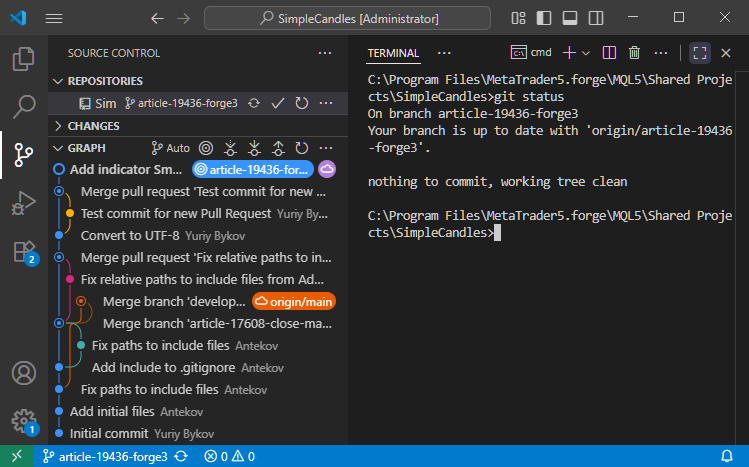
O resultado confirma que nosso repositório está, de fato, na branch article-19436-forge3 e que seu estado está sincronizado com a branch de mesmo nome no repositório remoto.
Agora, alternamos para a branch article-17607 usando o comando git checkout article-17607:
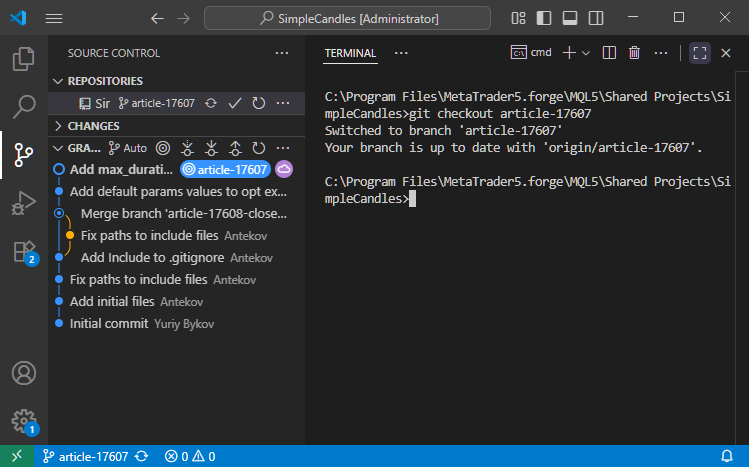
Em seguida, executamos o comando git merge develop para mesclar a branch atual com a branch develop:
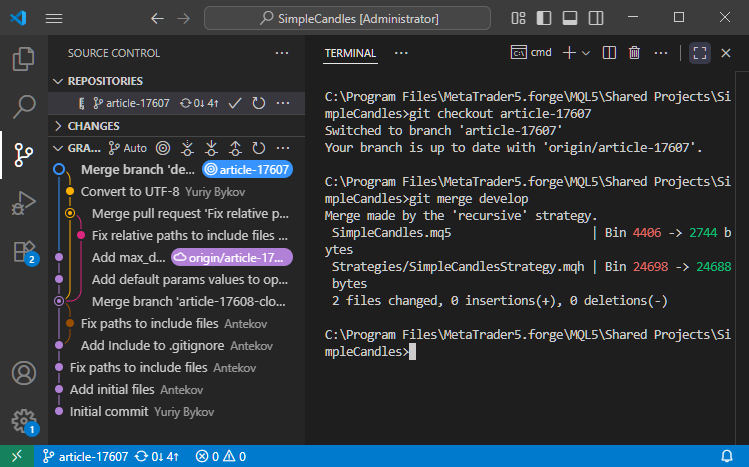
Como as alterações externas afetaram apenas partes do código que não foram modificadas durante o trabalho na branch article-17607, o processo de mesclagem ocorreu sem conflitos. Como resultado, foi criado um novo commit de mesclagem entre as branches.
Agora, executamos o comando git push para enviar as informações sobre as alterações ao repositório remoto:
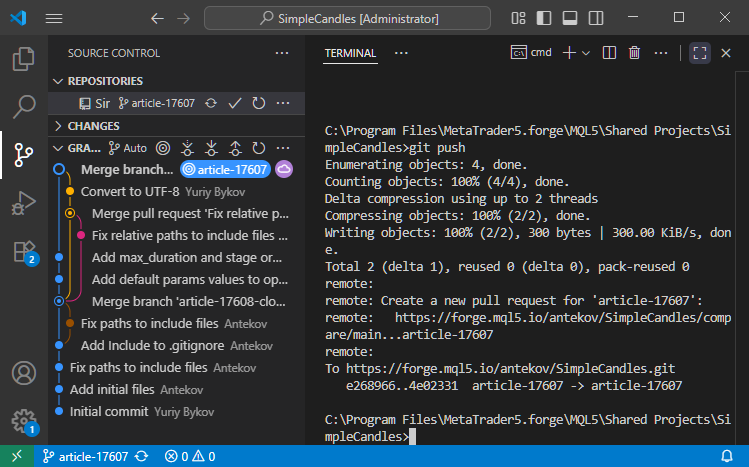
Verificamos o repositório MQL5 Algo Forge e confirmamos que todas as etapas de mesclagem realizadas foram corretamente refletidas no repositório remoto:
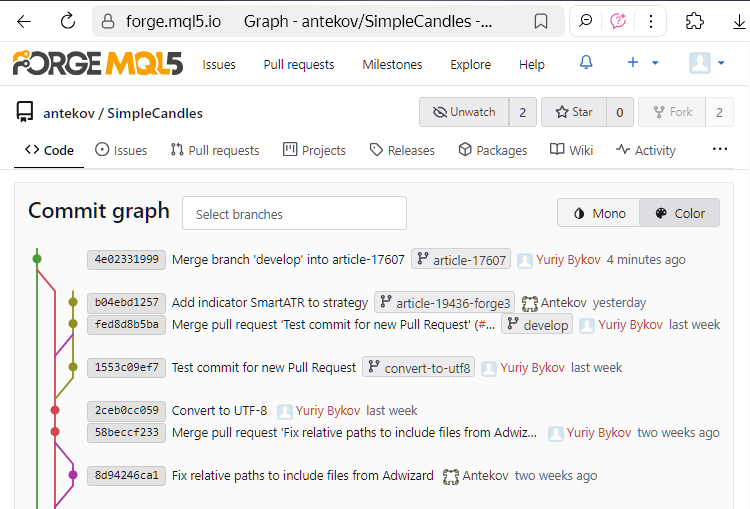
O último commit mostrado na captura de tela é justamente o commit de mesclagem entre as branches develop e article-17607.
Observe também a extremidade isolada da branch article-19436-forge3, que ainda não está conectada a nenhuma outra branch. As modificações dessa branch ainda não foram mescladas com develop, pois o trabalho nela ainda não foi concluído. Portanto, não daremos atenção a ela por enquanto; quando chegar o momento, poderemos retomar essa branch sem problemas.
Com isso, a preparação para continuar o desenvolvimento na branch article-17607 está concluída, e já podemos prosseguir com o trabalho no código. A solução da tarefa que originou essa branch é abordada em outro artigo. Aqui, não repetiremos esse conteúdo, mas seguiremos diretamente para a descrição das etapas de consolidação do estado do código após a conclusão da tarefa.
Executando a mesclagem
Antes de publicar qualquer estado do código, precisamos integrá-lo à branch principal. Nossa branch principal é a main. É nela que serão incorporadas as alterações vindas da branch de desenvolvimento, develop. E, por sua vez, as mudanças das branches de tarefas individuais serão integradas à branch develop. No momento, ainda não estamos prontos para transferir o novo código para a main, portanto, limitaremos nossa ação apenas à mesclagem das alterações com a develop. Para fins de demonstração das possibilidades desse mecanismo, a escolha de qual branch desempenha o papel de principal não é tão relevante.
Vamos observar o estado do repositório SimpleCandles após a conclusão do trabalho na tarefa selecionada:
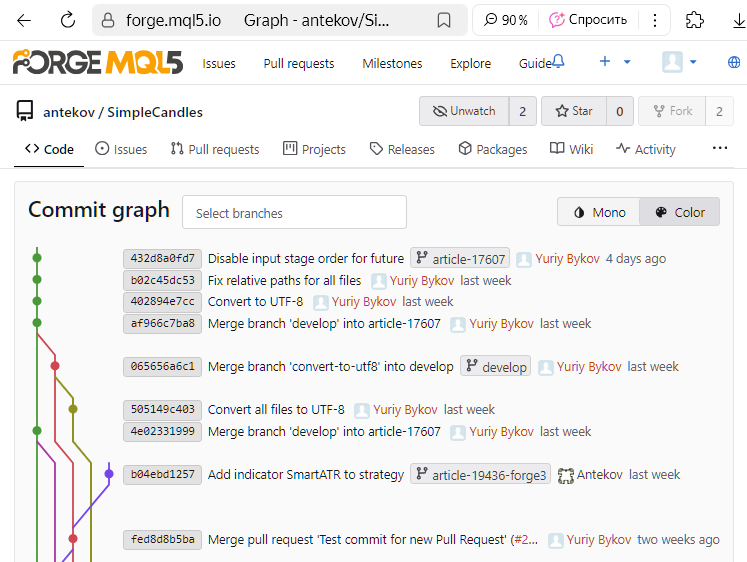
Como podemos ver, o último commit foi feito na branch article-17607. Criamos, então, através da interface web do repositório MQL5 Algo Forge, uma solicitação de mesclagem (Pull Request) dessa branch com a develop, conforme já descrito anteriormente:
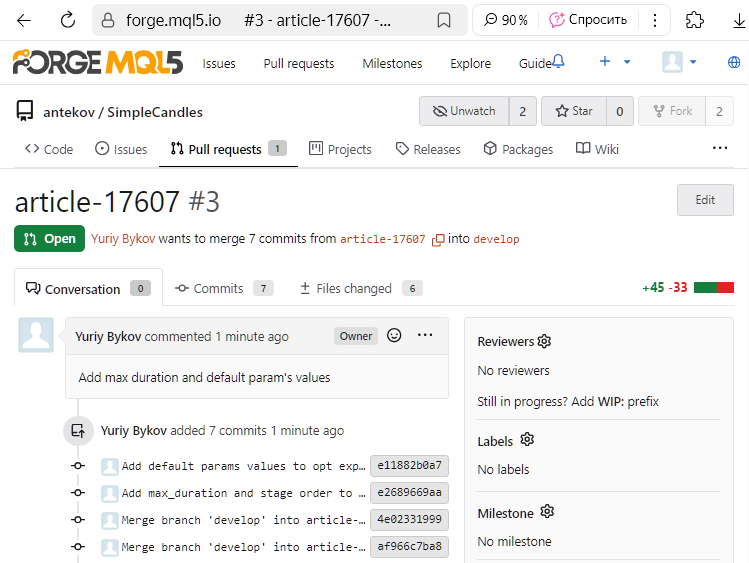
Verificamos se tudo ocorreu conforme o planejado. Voltamos à página do histórico de commits com a visualização da árvore de branches:
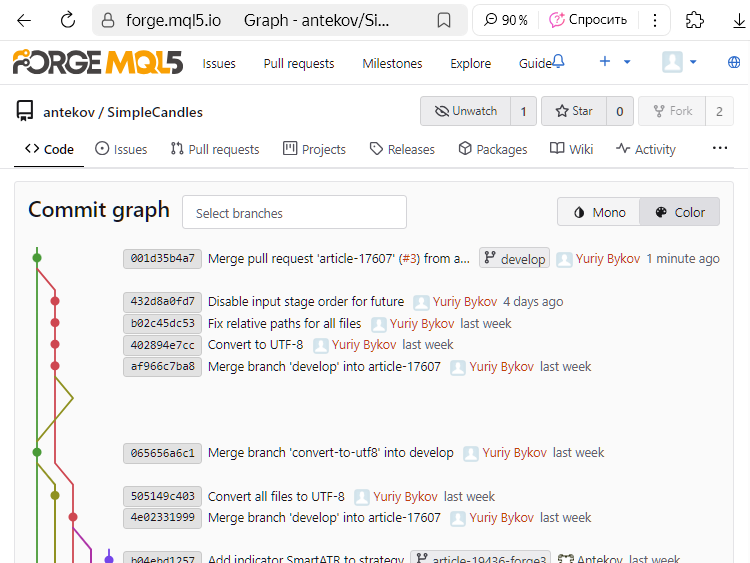
Percebemos que o commit com o hash 432d8a0fd7 já não é mais marcado como o último da branch article-17607. Em seu lugar, surgiu um novo commit com o hash 001d35b4a7, agora identificado como o mais recente da branch develop. Como esse commit registra a fusão das duas branches, passaremos a chamá-lo de commit de mesclagem.
Acessamos a página do commit de mesclagem e criamos uma nova tag. No início do artigo, já mostramos onde essa ação pode ser feita, e agora chegou o momento de executá-la:
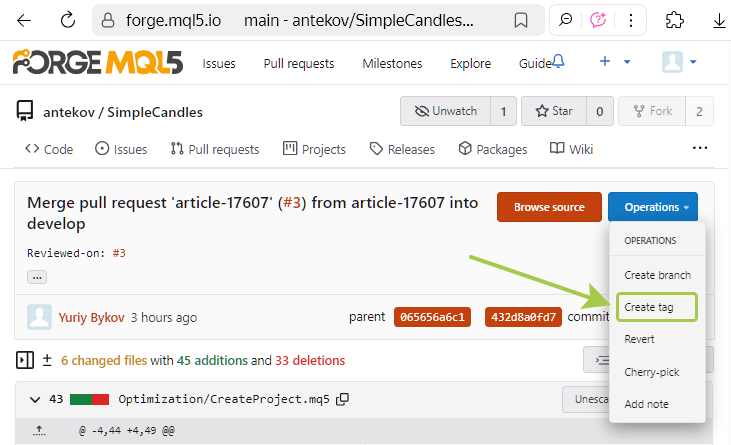
Na janela que aparece, inserimos o nome "v0.1", já que esta ainda está longe de ser uma versão final. Ainda não sabemos quantas adições serão feitas a este projeto, mas esperamos que sejam muitas. Portanto, esse número de versão pequeno serve mais como um lembrete para nós mesmos de que ainda há muito trabalho pela frente. Aliás, parece que a interface web do repositório não permite criar tags anotadas.
Assim, a tag foi criada com sucesso, e o resultado pode ser visto na página seguinte:
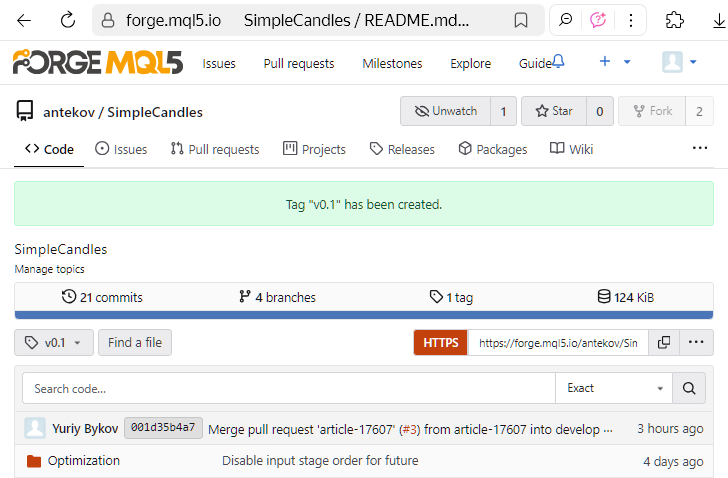
ou na página separada de tags do repositório:
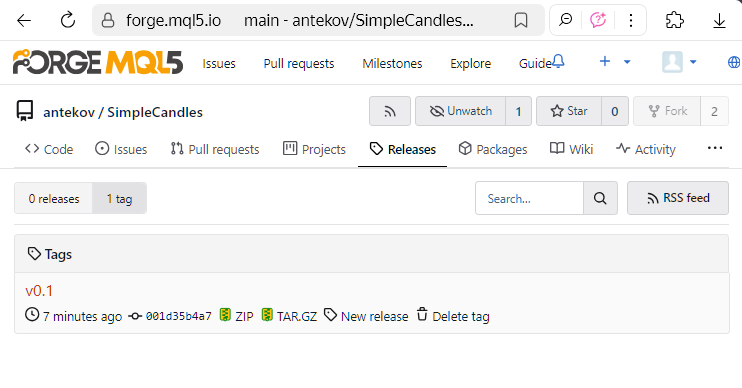
Se executarmos o comando de atualização do repositório local (git pull), a tag criada aparecerá nele. No entanto, na interface do MetaEditor, ainda não há um local para visualizar as tags do repositório, por isso mostramos como elas aparecem no Visual Studio Code. Ao passar o cursor sobre o commit desejado na árvore de commits, uma dica de ferramenta mostra uma marca colorida com o nome da tag associada:
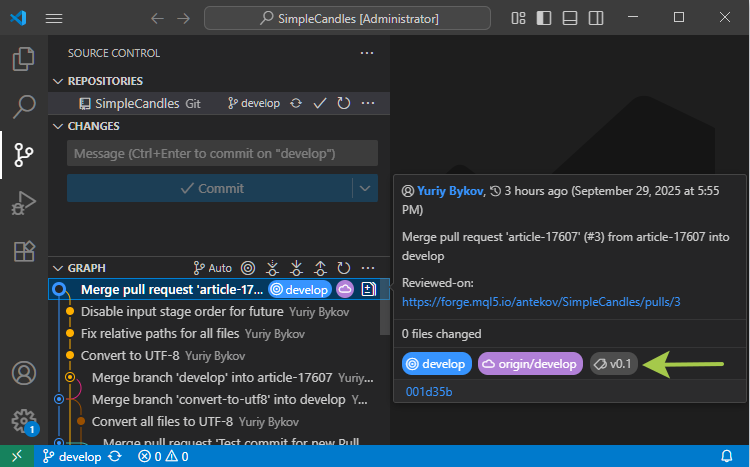
Agora que a tag foi criada, podemos simplesmente deixar como está e usar esse nome no comando git checkout para alternar o repositório exatamente para esse estado do código, ou podemos ir além e criar um release baseado nesse estado.
Criando o release
Os releases são um mecanismo de marcação e distribuição de versões específicas do software, independentemente da linguagem de programação utilizada. Enquanto os "commits" e "branches" representam o "fluxo de trabalho" do desenvolvimento, os "releases" são os "resultados oficiais" desse processo, ou seja, aquilo que queremos disponibilizar publicamente. As principais finalidades desse mecanismo são:
- Controle de versões. Marcamos estados específicos do código no repositório como estáveis, ou seja, como versões sem erros aparentes e com as funcionalidades implementadas de forma correta. Outros usuários poderão usar precisamente essas versões.
- Distribuição de arquivos binários. É possível anexar aos releases arquivos compilados e outros tipos de arquivos (.ex5, .dll, .zip), poupando os usuários da necessidade de compilar o código por conta própria, caso não tenham essa necessidade ou conhecimento técnico.
- Informação ao usuário. É recomendável adicionar uma descrição ao release, normalmente contendo uma lista de alterações realizadas, novas funcionalidades, correções de erros e outras informações relacionadas à publicação dessa versão específica. O principal objetivo dessa descrição é permitir que o usuário entenda se vale a pena atualizar para essa nova versão.
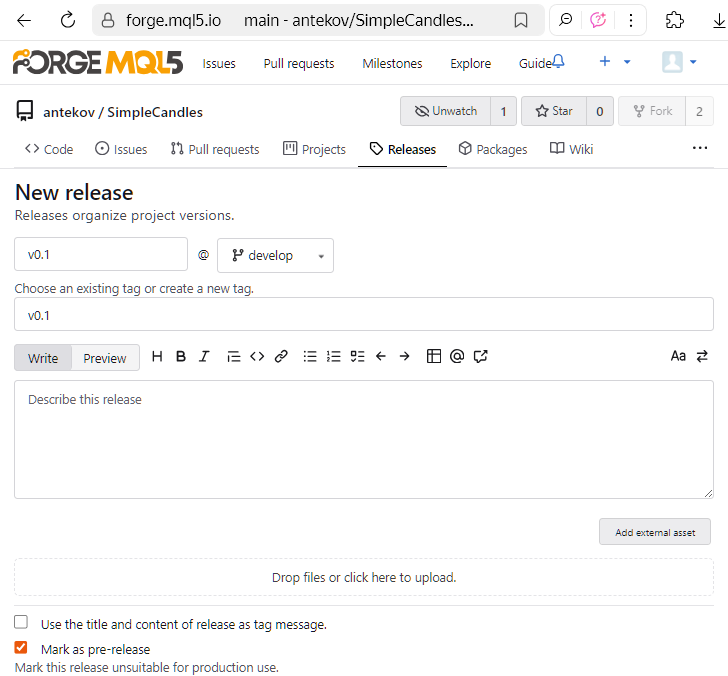
Um release é criado com base em uma tag já existente ou, durante o processo de criação, pode ser gerada uma nova tag ao mesmo tempo. Como já criamos nossa tag anteriormente, agora vamos criar um novo release com base nela. Para isso, na página de tags do repositório, clicamos em "New release" no item correspondente à tag desejada:

- o nome do release, a branch e a tag correspondente (seja uma nova ou uma já existente);
- a descrição do release (Release notes), o que foi adicionado de novo, o que foi corrigido, quais problemas conhecidos foram resolvidos;
- os arquivos anexados, como programas compilados, documentação ou links para fontes externas.
Podemos salvar o release como rascunho, permitindo futuras alterações em suas propriedades, ou publicá-lo imediatamente. A publicação não impede que façamos modificações posteriores, como ajustes ou complementos à descrição do release. Após esse processo, nós e outros usuários poderemos visualizar o release publicado na página de releases do repositório:
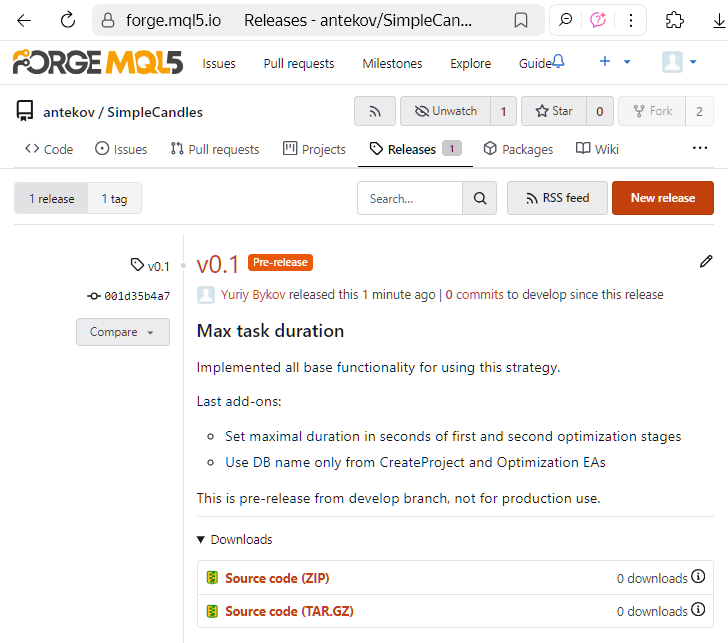
Pronto! A nova versão foi publicada e está pronta para uso. Um pouco mais tarde, editamos o nome do release, que não precisa necessariamente coincidir com o nome da tag, e adicionamos um link para o artigo mencionado anteriormente, contendo a descrição detalhada da solução desenvolvida.
Considerações finais
Neste ponto, fazemos uma breve pausa para analisar o caminho percorrido. Não apenas estudamos os aspectos técnicos do trabalho com o sistema de controle de versões, como também passamos por uma verdadeira transformação: do simples ato de realizar alterações pontuais à criação de um processo completo e estruturado de gerenciamento de código. Um aspecto importante é o domínio da etapa final: a formalização do trabalho concluído na forma de versões oficiais, que representam produtos completos e prontos para serem apresentados aos usuários. Embora nosso repositório ainda não tenha atingido esse nível de maturidade, demos todos os passos necessários para nos prepararmos para essa transição.
A abordagem analisada muda radicalmente a percepção de um projeto. De um simples conjunto de arquivos-fonte, ele se transforma em um sistema organizado, com um histórico claro de alterações e registros de estados de trabalho, permitindo retornar a qualquer momento a uma versão estável. Isso é benéfico para todos, tanto para os desenvolvedores quanto para os usuários das soluções prontas.
Assim, o domínio das ferramentas descritas eleva o trabalho com o repositório MQL5 Algo Forge a um novo nível de qualidade, abrindo caminho para projetos mais complexos e de maior escala no futuro.
Agradecemos pela atenção e até a próxima!
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/19623
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso