
Redes neurais em trading: Framework híbrido de negociação com codificação preditiva (Conclusão)

Introdução
Na parte anterior deste artigo, analisamos em detalhes os aspectos teóricos do sistema híbrido de negociação StockFormer, que combina codificação preditiva e algoritmos de aprendizado por reforço para prever tendências de mercado e a dinâmica de ativos financeiros. O StockFormer é um framework híbrido que une diversas tecnologias e abordagens-chave para lidar com problemas complexos nos mercados financeiros. Sua principal característica é o uso de três ramificações modificadas do Transformer, cada uma encarregada de aprender diferentes aspectos da dinâmica de mercado. A primeira ramificação da rede foca na extração de interdependências ocultas entre ativos; a segunda e a terceira são voltadas para previsões de curto e longo prazo, permitindo à rede considerar tanto tendências atuais quanto futuras no mercado.
A integração dessas ramificações ocorre por meio de uma cascata de mecanismos de atenção, o que aprimora a capacidade do modelo de aprender com blocos multicabeças, ampliando a análise e a detecção de padrões ocultos nos dados. Como resultado, o sistema pode não só analisar e prever tendências com base em dados históricos, mas também considerar interrelações dinâmicas entre diferentes ativos, algo crucial na criação de estratégias de negociação capazes de se adaptar às rápidas mudanças do mercado.
A visualização original do framework StockFormer está apresentada abaixo.
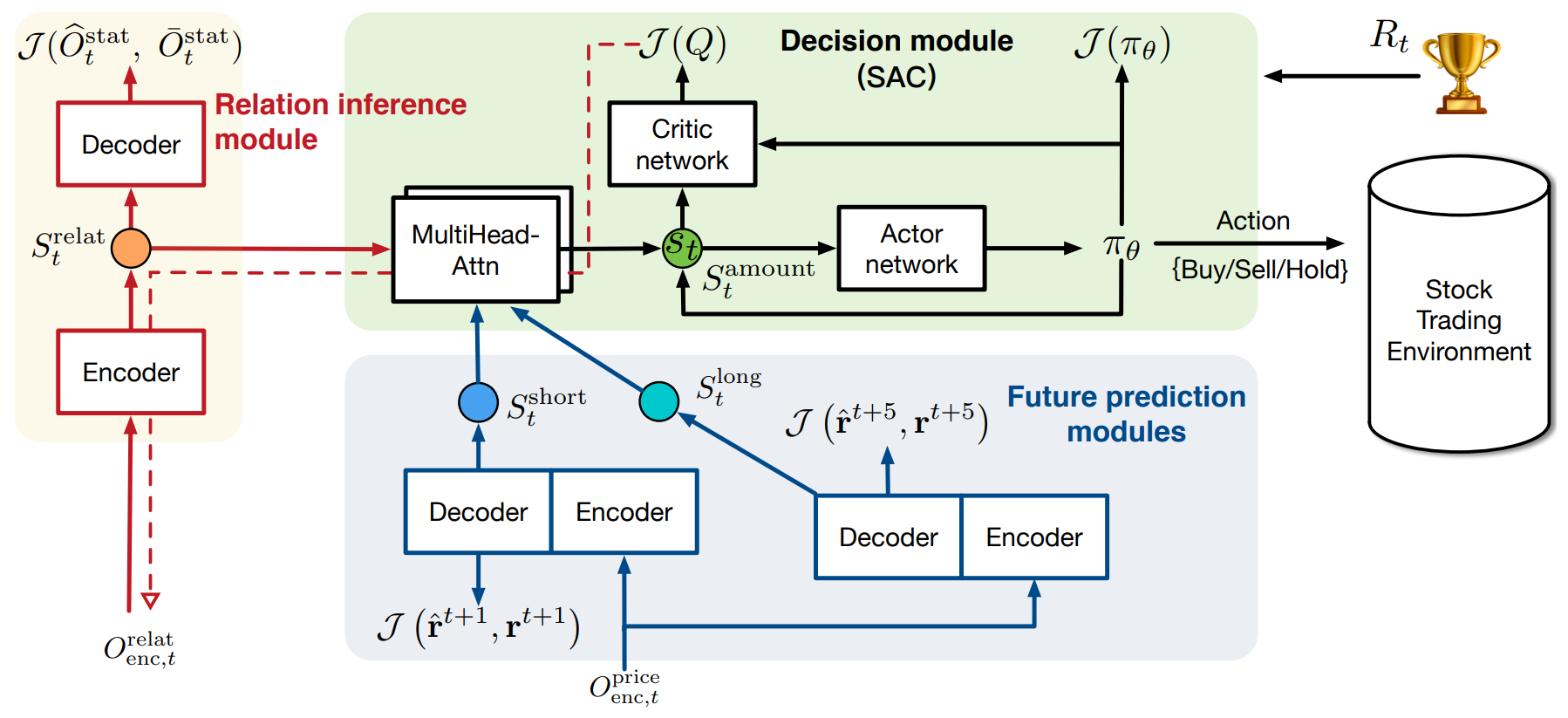
Na parte prática da seção anterior, foram implementados os algoritmos do módulo Diversified Multi-Head Attention (DMH-Attn), que serve como base para aprimorar o mecanismo de atenção padrão do modelo Transformer. O DMH-Attn permite aumentar significativamente a eficácia na identificação de diversos padrões e interdependências em séries temporais financeiras, o que é especialmente importante quando se trabalha com dados ruidosos e de alta volatilidade.
Neste artigo, continuaremos o trabalho iniciado e focaremos na arquitetura das diferentes partes do modelo, assim como nos mecanismos de sua interação para criar um espaço de estados unificado. Além disso, abordaremos o treinamento da política de comportamento do Agente de tomada de decisão de negociação.
Modelos de codificação preditiva
Começamos com os modelos de codificação preditiva. Os autores do framework StockFormer propuseram o uso de 3 modelos preditivos. Um deles é destinado à detecção de dependências entre os dados que descrevem a dinâmica dos ativos financeiros analisados. Os outros dois são treinados para prever o movimento futuro da série temporal multimodal considerada, com diferentes horizontes de planejamento.
Os três modelos são baseados na arquitetura Encoder—Decoder Transformer com o uso de módulos DMH-Attn modificados. Em nossa implementação, criaremos o Codificador e o Decodificador como modelos separados.
Modelos de busca por interdependências
A arquitetura dos modelos de busca por interdependências em séries temporais dos ativos financeiros analisados é apresentada no método CreateRelationDescriptions.
bool CreateRelationDescriptions(CArrayObj *&encoder, CArrayObj *&decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
Nos parâmetros do método, recebemos ponteiros para 2 arrays dinâmicos, nos quais iremos transmitir a descrição da arquitetura do Codificador e do Decodificador. No corpo do método, verificamos a validade dos ponteiros recebidos e, se necessário, criamos novas instâncias dos objetos de arrays dinâmicos.
Como primeiro layer do Codificador, usamos, como de costume, uma camada totalmente conectada com tamanho suficiente, que deve receber todos os dados do tensor dos dados brutos.
Vale lembrar que alimentamos o Codificador com os dados históricos até a profundidade total do histórico analisado.
//--- Encoder encoder.Clear(); //--- if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Usamos as informações "brutas" provenientes do terminal como dados de entrada. Como é fácil imaginar, os dados recebidos da série temporal multimodal, que contêm informações dos indicadores analisados e, possivelmente, de vários instrumentos financeiros, pertencem a diferentes distribuições. Por isso, realizamos um pré-processamento dos dados brutos usando uma camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Os autores do framework StockFormer propõem mascarar aleatoriamente até 50% dos dados brutos durante o treinamento dos modelos de busca por interdependências. O modelo deve reconstruir os dados mascarados com base nas informações restantes. O mascaramento dos dados brutos em nosso Codificador será realizado pela camada Dropout.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; descr.probability = 0.5f; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, adicionamos uma camada de codificação posicional treinável.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
E finalizamos o Codificador com o módulo de atenção multicabeça diversificada, composto por 3 camadas aninhadas.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDMHAttention; descr.window = BarDescr; descr.window_out = 32; descr.count = HistoryBars; descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Na entrada do Decodificador do modelo de busca por interdependências das sequências analisadas, é fornecida a mesma série temporal multimodal, com mascaramento e codificação posicional semelhantes. Por isso, boa parte da arquitetura do Codificador e do Decodificador é idêntica. Apenas substituímos o módulo de atenção multicabeça diversificada por um módulo equivalente de atenção cruzada, no qual serão comparados os dados das trilhas do Decodificador e do Codificador.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {prev_count/descr.windows[0], HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
E como os resultados do Decodificador serão comparados com os dados brutos, complementamos o modelo com uma camada de normalização reversa.
//--- layer 5 prev_count = descr.units[0] * descr.windows[0]; if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count; descr.layers = 1; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Modelos de previsão
Ambos os modelos de previsão, apesar dos diferentes horizontes de planejamento, compartilham a mesma arquitetura, representada no método CreatePredictionDescriptions. Vale dizer que planejamos alimentar o Codificador com a mesma série temporal multimodal, que foi analisada anteriormente pelo modelo de busca por interdependências. Por isso, replicamos integralmente a arquitetura do Codificador, apenas excluindo a camada Dropout, já que nesta etapa o mascaramento dos dados brutos não é utilizado durante o treinamento das redes.
O Decodificador do modelo de previsão recebe como entrada apenas o vetor de descrição da última barra, cujos valores são repassados para uma camada totalmente conectada.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
Em seguida, como nos modelos anteriores, usamos uma camada de normalização em lote, aplicada ao pré-processamento dos dados brutos.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
No escopo deste artigo, planejamos treinar o modelo para analisar dados históricos de um único instrumento financeiro. Com isso em mente, a presença do vetor de descrição de apenas uma barra nos dados brutos reduz significativamente a utilidade da camada de codificação posicional. Por isso, neste caso, optamos por não utilizá-la. No entanto, para análises que envolvem mais de um instrumento financeiro, eu recomendaria adicionar a codificação posicional aos dados brutos.
Na sequência, incluímos um módulo de atenção cruzada multicabeça diversificada com três camadas, que usa os resultados do Codificador correspondente como uma segunda fonte de dados.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
E na saída do modelo, adicionamos uma camada totalmente conectada de projeção dos dados, sem função de ativação.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Aqui, vale destacar dois pontos. Primeiro, ao contrário dos modelos anteriores que previam os valores esperados de continuação da série temporal analisada, os autores do framework StockFormer propuseram prever os coeficientes de variação dos indicadores. Assim, o tamanho do vetor de saída é igual ao tensor dos dados brutos do Decodificador, independentemente do horizonte de planejamento. Essa abordagem nos permite eliminar a camada de normalização reversa na saída do Decodificador. Mais do que isso, neste formato de previsão, a camada de normalização reversa se torna desnecessária. Pois o coeficiente de variação e os dados brutos pertencem a distribuições diferentes.
O segundo ponto que vale mencionar diz respeito ao uso da camada totalmente conectada na saída do Decodificador. Neste caso, como já foi dito anteriormente, planejamos analisar uma série temporal multimodal de um único instrumento financeiro. E esperamos que todas as sequências unitárias analisadas apresentem correlações mútuas em diferentes graus. Portanto, os coeficientes de variação devem estar alinhados. Nessa situação, o uso de uma camada totalmente conectada é bastante adequado. Caso você esteja planejando realizar uma análise paralela de vários instrumentos financeiros, eu recomendaria substituir a camada totalmente conectada por uma convolucional, com previsão independente dos coeficientes de variação dos indicadores para cada ativo.
Com isso, encerramos a análise da arquitetura dos modelos de codificação preditiva. A descrição completa de suas arquiteturas pode ser consultada no anexo.
Treinamento dos modelos de codificação preditiva
No framework StockFormer, o treinamento dos modelos de codificação preditiva é definido como uma etapa separada. E eu proponho que, após termos revisado a arquitetura desses modelos, passemos à construção do EA responsável por seu treinamento. Os métodos básicos do EA são, em grande parte, baseados em programas semelhantes já abordados nas partes anteriores desta série de artigos. Por isso, neste artigo, focaremos apenas no algoritmo do treinamento propriamente dito das redes, implementado no método Train.
Primeiramente, faremos uma breve preparação. Durante essa etapa, criaremos um vetor de probabilidades para selecionar trajetórias do buffer de replay, atribuindo maior probabilidade às trajetórias com a maior rentabilidade. Dessa forma, deslocamos o processo de aprendizado para trajetórias lucrativas, preenchendo o treinamento com exemplos positivos.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; matrix<float> predict; bool Stop = false; //--- uint ticks = GetTickCount();
Neste ponto, também declararemos as variáveis locais necessárias para armazenar dados intermediários durante o processo de aprendizado. E, após concluir essa preparação, estruturamos o laço de iteração do treinamento. O número total de iterações é definido nos parâmetros externos do EA.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize((NForecast + 1)*BarDescr) || MathAbs(state).Sum() == 0) { iter --; continue; }
No corpo do laço, extraímos uma trajetória do buffer de replay e o estado inicial do ambiente nessa trajetória. E obrigatoriamente verificamos se há dados históricos disponíveis para análise nesse estado selecionado, bem como a presença de dados reais no horizonte de planejamento especificado. Se a verificação dos controles for bem-sucedida, transferimos os valores históricos até a profundidade definida para o buffer de dados correspondente e executamos a propagação para frente de todos os modelos preditivos.
//--- Feed Forward if(!RelateEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !RelateDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(RelateEncoder)) || !ShortEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(ShortEncoder)) || !LongEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !LongDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(LongEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Observe que, apesar de possuírem a mesma arquitetura, cada modelo preditivo conta com seu próprio Codificador. Essa abordagem aumenta o número de modelos a serem treinados e, com isso, também os custos de treinamento e uso dessas redes. Porém, ao mesmo tempo, oferece a cada modelo a possibilidade de identificar dependências relevantes para a resolução de sua tarefa específica.
Além disso, vale destacar o uso do tensor de dados brutos na trilha principal do Decodificador. Ao analisarmos a arquitetura dos modelos, foi dito que os dados de entrada dos Decodificadores nos modelos de previsão são apenas os valores do último barra. Aqui, no entanto, vemos a utilização do buffer de dados históricos em toda a profundidade de análise em todos os casos. Para entender isso, devemos considerar o formato de registro do estado do ambiente no buffer de replay, que pode ser representado como uma matriz. As linhas correspondem aos barras e as colunas representam os atributos (valores de preço e indicadores). A primeira linha contém as informações do último barra. Sendo assim, ao transmitir um tensor de dados históricos cujo tamanho excede o número de elementos na camada de dados brutos, o modelo simplesmente utilizará os primeiros dados equivalentes ao tamanho dessa camada. E é exatamente isso que queremos. Portanto, não precisamos desperdiçar recursos criando buffers adicionais nem fazendo cópias desnecessárias de dados.
Após a execução bem-sucedida da propagação para frente, passamos à preparação dos alvos e à realização das operações de propagação reversa. Para os modelos de detecção de interdependências em séries temporais unitárias da série analisada, os valores-alvo são a própria série temporal multimodal analisada. Sendo assim, podemos realizar diretamente a propagação reversa do Decodificador com a transmissão do gradiente de erro ao Codificador. E com base nesse gradiente, ajustamos os parâmetros do Codificador.
//--- Relation if(!RelateDecoder.backProp(GetPointer(bState), (CNet *)GetPointer(RelateEncoder)) || !RelateEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Já para os modelos de previsão, precisamos definir os valores-alvo. Como mencionado anteriormente, neste caso os valores-alvo são os coeficientes de variação dos parâmetros analisados. Partimos da premissa de que o horizonte de planejamento é menor que a profundidade da análise dos dados históricos. Por isso, para calcular os valores-alvo, podemos utilizar o estado do ambiente, registrado no buffer de replay após o estado analisado, com uma defasagem correspondente ao horizonte de planejamento. E transformamos o tensor obtido em uma matriz, cujas linhas representarão os diferentes barras.
//--- Prediction if(!predict.Resize(1, state.Size()) || !predict.Row(state, 0) || !predict.Reshape(NForecast + 1, BarDescr) ) { iter --; continue; }
Como já foi dito anteriormente, as primeiras linhas dessa matriz conterão os barras mais recentes. Para definir os valores-alvo, pegaremos uma linha a mais do que o horizonte de planejamento. Assim, a última linha da matriz truncada conterá informações do barra que estamos analisando.
Aqui é importante lembrar que o buffer de replay armazena dados não normalizados. E, para obter coeficientes de variação de preço dentro de um intervalo adequado, usaremos como base os valores absolutos máximos de cada parâmetro individual na nossa matriz de valores futuros. Com isso, esperamos obter coeficientes de variação dos parâmetros no intervalo de {-2.0, 2.0}.
result = MathAbs(predict).Max(0);
Como valores-alvo para o modelo de previsão de curto prazo, os autores do framework propõem usar o coeficiente de variação do parâmetro no próximo barra. Para calcular esse coeficiente, pegamos a diferença entre as duas últimas linhas da matriz de valores previstos e a dividimos pelo vetor de valores máximos. O resultado obtido é então gravado no buffer correspondente.
target = (predict.Row(NForecast - 1) - predict.Row(NForecast)) / result; if(!bShort.AssignArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Para o modelo de planejamento de longo prazo, somamos os coeficientes de variação do preço em cada barra, considerando o fator de desconto.
for(int i = 0; i < NForecast - 1; i++) target += (predict.Row(i) - predict.Row(i + 1)) / result * MathPow(DiscFactor, NForecast - i - 1); if(!bLong.AssignArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E agora que definimos o conjunto completo de valores-alvo, podemos atualizar os parâmetros dos modelos de previsão com o objetivo de minimizar o erro de previsão. Para isso, primeiro executamos as operações de propagação reversa do Decodificador e do Codificador do modelo de curto prazo e, em seguida, do modelo de longo prazo.
//--- Short prediction if(!ShortDecoder.backProp(GetPointer(bShort), (CNet *)GetPointer(ShortEncoder)) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
//--- Long prediction if(!LongDecoder.backProp(GetPointer(bLong), (CNet *)GetPointer(LongEncoder)) || !LongEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Após ajustar os parâmetros de todos os modelos treinados nesta etapa, resta apenas informar o usuário sobre o andamento das operações e passar para a próxima iteração do ciclo de treinamento das redes preditivas.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Relate", percent, RelateDecoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Short", percent, ShortDecoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Long", percent, LongDecoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Ao final da execução de todas as iterações do ciclo de treinamento dos modelos preditivos, limpamos o campo de comentários no gráfico, onde anteriormente era exibida a informação sobre o andamento do processo de aprendizado.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Relate", RelateDecoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Short", ShortDecoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Long", LongDecoder.getRecentAverageError()); ExpertRemove(); //--- }
Os resultados do treinamento dos modelos são registrados no log e inicializamos o processo de encerramento do nosso EA.
O código completo do EA de treinamento dos modelos preditivos pode ser consultado no anexo do artigo (arquivo "...\MQL5\Experts\StockFormer\Study1.mq5").
Aqui vale dizer que, durante o treinamento dos modelos para esta publicação, usamos a estrutura de dados brutos adotada em trabalhos anteriores. Nesse caso, para o treinamento das redes preditivas, utilizamos apenas estados do ambiente que são independentes das ações do Agente. Por isso, iniciamos o processo de treinamento dos modelos preditivos com base no conjunto de dados de treinamento previamente coletado. E, com isso, passamos para a próxima etapa do nosso trabalho.
Treinamento da política
Enquanto ocorre o treinamento das redes preditivas, vamos nos dedicar à preparação da próxima etapa, ou seja, o treinamento da política de comportamento do Agente.
Arquitetura dos modelos
Começamos esse trabalho com a definição da arquitetura dos modelos treinados nesta etapa, representados no método CreateDescriptions. No entanto, vale destacar que, no framework StockFormer Ator e Crítico, utilizam como dados brutos os resultados das redes preditivas, unificados em um subespaço comum por meio de uma cascata de módulos de atenção. Nossa biblioteca já conta com a possibilidade de construir modelos com duas fontes de dados. Por isso, dividiremos a cascata de módulos de atenção em duas redes. Na primeira rede, faremos a correspondência entre os dados de dois horizontes de planejamento. Aqui, os autores do framework recomendam o uso dos dados de longo prazo da trilha principal, por serem menos sensíveis ao ruído.
A arquitetura da rede que compara os dois horizontes de planejamento é bastante simples. Nela, criamos apenas duas camadas:
- Camada totalmente conectada para os dados de entrada.
- Módulo de atenção cruzada diversificada com 3 camadas internas.
//--- Long to Short predict long_short.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!long_short.Add(descr)) { delete descr; return false; } //--- Layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, 1}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!long_short.Add(descr)) { delete descr; return false; }
Neste caso, não utilizamos uma camada de normalização dos dados, pois a entrada da rede não são dados brutos, e sim os resultados dos modelos de previsão já analisados.
Os resultados da correspondência entre os dois horizontes de planejamento são então enriquecidos com informações sobre o estado atual do ambiente, obtidas na saída do Codificador do modelo de detecção de interdependências nos dados brutos.
Vale ressaltar que o treinamento do modelo de detecção de interdependências nas sequências unitárias dos dados brutos foi feito com o objetivo de reconstruir a parte mascarada desses dados. Portanto, nesta etapa, esperamos que a rede represente um certo estado preditivo de cada série temporal unitária, formado com base nas demais sequências unitárias. Isso significa que, na saída do Codificador da rede de análise de interdependências, esperamos obter um tensor de descrição do estado do ambiente limpo de ruídos. Afinal, os valores atípicos que não se encaixam nas expectativas do modelo serão compensados por valores médios calculados a partir das outras séries unitárias.
A arquitetura da rede que enriquece os valores previstos com informações sobre o estado do ambiente é praticamente idêntica à rede de comparação dos dois horizontes de planejamento descrita acima. Apenas alteramos o tamanho da sequência na segunda fonte de dados.
//--- Predict to Relate predict_relate.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!predict_relate.Add(descr)) { delete descr; return false; } //--- Layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!predict_relate.Add(descr)) { delete descr; return false; }
Após a construção da cascata de módulos de atenção, que unifica em um subespaço comum os resultados das três redes preditivas, passamos à estruturação da arquitetura do nosso Ator. Na entrada da rede, fornecemos os resultados gerados por essa cascata de atenção.
//--- Actor actor.Clear(); //--- Input Layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
As expectativas preditivas obtidas são então combinadas com informações sobre o estado atual da conta.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Essa informação consolidada passa por um bloco de tomada de decisão, estruturado como uma MLP com cabeça estocástica.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Na saída do modelo, os parâmetros das operações em diferentes direções são ajustados por meio de uma camada convolucional com função de ativação sigmoide.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; }
A rede do Crítico possui arquitetura semelhante, com a diferença de que, no lugar do estado da conta, ela analisa as ações do Agente, e na sua saída não utilizamos cabeça estocástica. A arquitetura completa de todos os modelos utilizados pode ser consultada no anexo.
Programa de treinamento da política
Após construir a arquitetura dos modelos, passamos à organização dos algoritmos de seu treinamento. Na segunda etapa do aprendizado das redes, buscamos a estratégia ideal de comportamento do Agente para alcançar a máxima rentabilidade com o menor risco possível.
Como nas etapas anteriores, o método de treinamento começa com uma pequena preparação. Geramos um vetor de probabilidades para seleção de trajetórias no buffer de replay, com base nos resultados de cada uma, e declaramos as variáveis locais.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
Em seguida, organizamos o laço de treinamento das redes, cujo número de iterações é definido pelos parâmetros externos do EA.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; }
No corpo do laço, extraímos uma trajetória e o respectivo estado para a iteração atual do treinamento. E, como sempre, verificamos se há dados suficientes disponíveis no estado selecionado.
Diferente das redes preditivas, o treinamento da política exige mais dados brutos. E após obtermos a descrição do estado do ambiente, reunimos a partir do buffer de replay as informações de saldo e posições abertas no momento analisado.
//--- Account bAccount.Clear(); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!!bAccount.GetOpenCL()) { if(!bAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Às informações sobre o estado da conta, adicionamos a marca temporal do estado analisado.
Com base nas informações coletadas, executamos a propagação para frente dos modelos de codificação preditiva, assim como da cascata de módulos de atenção, a fim de transformar os resultados das redes preditivas em um único subespaço.
//--- Generate Latent state if(!RelateEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(ShortEncoder)) || !LongEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !LongDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(LongEncoder)) || !LongShort.feedForward(GetPointer(LongDecoder), -1, GetPointer(ShortDecoder), -1) || !PredictRelate.feedForward(GetPointer(LongShort), -1, GetPointer(RelateEncoder), -1) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Observe que, nesta etapa, não realizamos a propagação para frente do Decodificador do modelo de detecção de interdependências, pois este modelo não é utilizado durante o treinamento da política nem na exploração da rede.
Em seguida, realizamos a otimização dos parâmetros do Crítico com o objetivo de minimizar o erro na avaliação das ações do Agente. Para isso, extraímos do buffer de replay as ações reais do Agente no estado selecionado e executamos a propagação para frente do Crítico.
//--- Critic target.Assign(Buffer[tr].States[i].action); target.Clip(0, 1); bActions.AssignArray(target); if(!!bActions.GetOpenCL()) if(!bActions.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } Critic.TrainMode(true); if(!Critic.feedForward(GetPointer(PredictRelate), -1, (CBufferFloat*)GetPointer(bActions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Com base nos resultados dessa propagação do Crítico, obtemos uma estimativa das ações, que nas etapas iniciais é praticamente um valor aleatório. No entanto, para as ações reais executadas pelo Agente durante a coleta das trajetórias, o buffer de replay armazena a recompensa efetiva recebida do ambiente. Sendo assim, podemos treinar o Crítico, minimizando o erro entre a recompensa prevista e a real.
Extraímos essa recompensa real do buffer de replay e executamos a propagação reversa do Crítico.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CBufferFloat *)GetPointer(bActions), (CBufferFloat *)GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Depois, passamos diretamente ao treinamento da política de comportamento do Ator. Com base nos dados brutos coletados, realizamos a propagação para frente do Ator para gerar o tensor de ações conforme a política atual.
//--- Actor Policy if(!Actor.feedForward(GetPointer(PredictRelate), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
E logo em seguida avaliamos as ações geradas com o Crítico.
Critic.TrainMode(false); if(!Critic.feedForward(GetPointer(PredictRelate), -1, (CNet*)GetPointer(Actor), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Vale destacar que, durante a otimização da política de comportamento do Ator, desativamos o modo de aprendizado do Crítico. Isso nos permite transmitir o gradiente de erro ao Ator sem que os parâmetros do Crítico sejam afetados por dados não relevantes.
O treinamento da política do Ator é realizado em duas etapas. Na primeira, verificamos a eficácia das ações reais registradas no buffer de replay. Se houver recompensa positiva, minimizamos o erro entre o tensor de ações previsto e o real. Assim, treinamos uma política lucrativa no estilo de aprendizado supervisionado.
if(result.Sum() >= 0) if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient)) || !PredictRelate.backPropGradient(GetPointer(RelateEncoder), -1, -1, false) || !LongShort.backPropGradient(GetPointer(ShortDecoder), -1, -1, false) || !ShortDecoder.backPropGradient((CNet *)GetPointer(ShortEncoder), -1, -1, false) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL) || !LongDecoder.backPropGradient((CNet *)GetPointer(LongEncoder), -1, -1, false) || !LongEncoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Observe que, ao treinar a política do Ator, propagamos o gradiente de erro até o nível das redes preditivas. Dessa forma, realizamos um ajuste fino dessas redes para adequá-las à tarefa prática de otimização da política de comportamento do Ator.
Na segunda etapa, a otimização da política do Ator é feita por meio da propagação do gradiente de erro a partir do Crítico. Aqui, ajustamos a política independentemente do desempenho das ações reais executadas pelo Agente na interação com o ambiente, pois nos baseamos na avaliação das ações da política atual feita pelo Crítico. Para isso, pegamos a avaliação das ações e a incrementamos em 1%.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
A recompensa ajustada é então enviada ao Crítico como valor-alvo, e realizamos sua propagação reversa, transmitindo o gradiente de erro ao Ator. Como resultado dessa operação, esperamos obter, nos resultados do modelo do Ator, um gradiente de erro orientado para aumentar a lucratividade das ações.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient)) || !PredictRelate.backPropGradient(GetPointer(RelateEncoder), -1, -1, false) || !LongShort.backPropGradient(GetPointer(ShortDecoder), -1, -1, false) || !ShortDecoder.backPropGradient((CNet *)GetPointer(ShortEncoder), -1, -1, false) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL) || !LongDecoder.backPropGradient((CNet *)GetPointer(LongEncoder), -1, -1, false) || !LongEncoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
O gradiente de erro obtido é distribuído por todas as redes, da mesma forma que na primeira etapa do treinamento.
Em seguida, resta apenas informar o usuário sobre o andamento do processo de aprendizado e avançar para a próxima iteração do ciclo.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Ao final da execução de todas as iterações do ciclo de treinamento, assim como na primeira etapa, limpamos o campo de comentários no gráfico do ativo, registramos os resultados do treinamento no log e iniciamos o processo de encerramento do programa.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Vale destacar que os ajustes nos algoritmos de funcionamento dos programas afetaram não apenas os EAs de treinamento dos modelos, mas também os especialistas responsáveis pela interação com o ambiente. No entanto, a natureza dessas modificações no algoritmo das redes de interação com o ambiente é amplamente semelhante à propagação para frente do Ator. Portanto, não vamos nos aprofundar agora na análise detalhada dos algoritmos desses programas. Sugiro deixá-los para estudo autônomo. O código completo de todos os programas utilizados na elaboração deste artigo está disponível no anexo da publicação.
Testes
Concluímos um caminho bastante extenso na implementação das abordagens do framework StockFormer utilizando os recursos do MQL5. E agora chegamos à etapa final do nosso trabalho, que é o treinamento das redes e a avaliação dos resultados obtidos com base em dados históricos reais.
Foi mencionado anteriormente que, para a primeira etapa do treinamento das redes preditivas, utilizamos um conjunto de dados de treino coletado em trabalhos anteriores. Vale lembrar que esse conjunto reúne trajetórias baseadas em dados históricos reais do instrumento EURUSD ao longo de todo o ano de 2023, no timeframe H1. Os parâmetros de todos os indicadores analisados foram utilizados com seus valores padrão.
Na etapa de treinamento das redes preditivas, são usados apenas dados históricos de descrição do estado do ambiente, independentes das ações do Agente. Isso nos permite treinar essas redes sem a necessidade de atualizar o conjunto de dados de treino. O treinamento dos modelos é repetido até que os erros se estabilizem em um intervalo restrito.
A segunda etapa, o treinamento da política de comportamento do Ator, já é realizada de forma iterativa, com atualizações periódicas do conjunto de treino para mantê-lo coerente com a política atual.
A eficácia do modelo treinado foi avaliada no testador de estratégias do MetaTrader 5 com dados históricos de janeiro de 2024. Período imediatamente posterior ao dos dados do conjunto de treino. Resultados dos testes são apresentados a seguir.
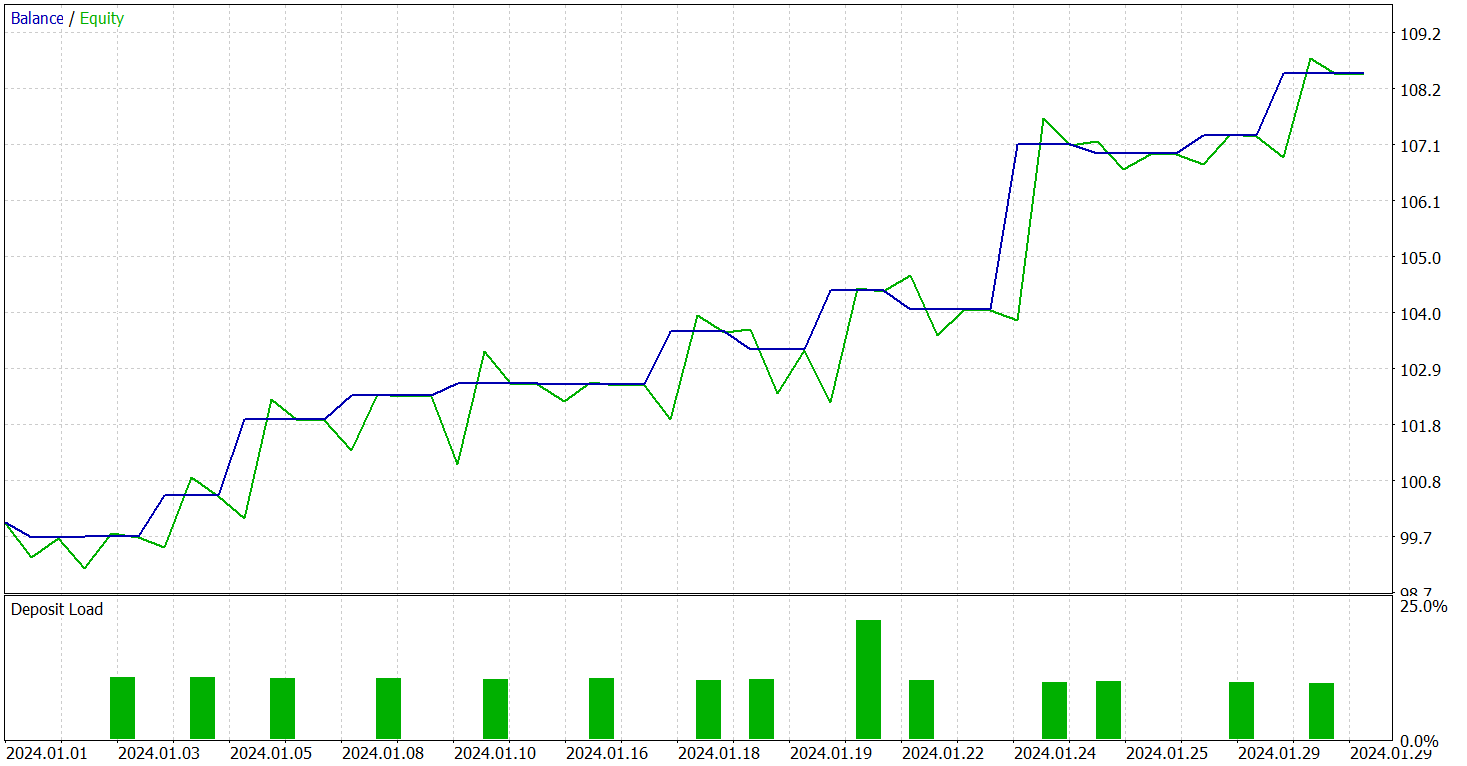
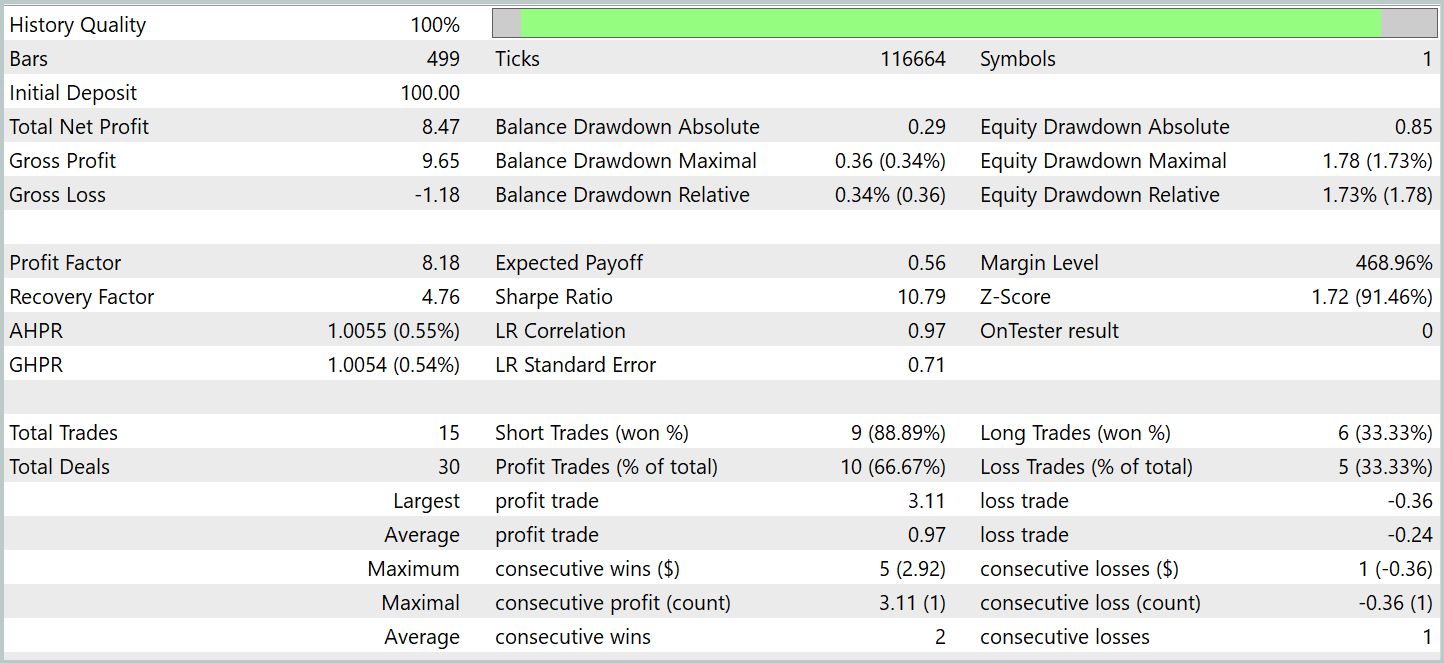
Conforme indicam os dados apresentados, durante o período de teste o modelo executou 15 operações de negociação. E 10 delas foram encerradas com lucro, o que corresponde a mais de 66%. Um resultado bastante promissor. Especialmente se considerarmos que o lucro médio por operação vencedora foi 4 vezes maior que o prejuízo médio das operações perdedoras. Como consequência, observamos uma tendência clara de crescimento do saldo no gráfico de balanço.
Considerações finais
Ao longo de dois artigos, exploramos o framework StockFormer, que propõe uma abordagem inovadora para treinar estratégias de negociação nos mercados financeiros. O StockFormer combina métodos de codificação preditiva com aprendizado profundo por reforço, permitindo o treinamento de políticas bastante flexíveis, capazes de considerar dependências dinâmicas entre múltiplos ativos e prever seu comportamento tanto no curto quanto no longo prazo.
A codificação preditiva em três ramificações do StockFormer permite extrair representações latentes que capturam tendências de curto prazo, variações de longo prazo e interrelações entre ativos. A integração dessas representações é feita por meio de um mecanismo de atenção multicabeça em cascata, possibilitando a criação de um espaço unificado de estados para otimização das decisões de negociação.
Na parte prática, implementamos os componentes principais do framework utilizando os recursos do MQL5. Treinamos os modelos e os testamos em dados históricos reais. Os resultados dos experimentos confirmam a eficácia das abordagens propostas. No entanto, para aplicação das redes em negociações reais, será necessário um treinamento com um conjunto maior de dados históricos e testes adicionais mais abrangentes.
Links
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA de coleta de exemplos com o método Real-ORL |
| 3 | Study1.mq5 | Expert Advisor | EA de treinamento preditivo |
| 4 | Study2.mq5 | Expert Advisor | EA de treinamento de política |
| 5 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e arquitetura das redes |
| 7 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para construção da rede neural |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código em OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16713
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Introdução ao Connexus (Parte 1): Como usar a função WebRequest?
Introdução ao Connexus (Parte 1): Como usar a função WebRequest?
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso