
Нейросети в трейдинге: Гибридный торговый фреймворк с предиктивным кодированием (Окончание)

Введение
В предыдущей статье мы детально рассмотрели теоретические аспекты гибридной торговой системы StockFormer, которая сочетает предиктивное кодирование и алгоритмы обучения с подкреплением, для прогнозирования рыночных трендов и динамики финансовых активов. StockFormer представляет собой гибридный фреймворк, объединяющий несколько ключевых технологий и подходов для решения сложных задач на финансовых рынках. Основной особенностью является использование трех модифицированных ветвей Transformer, каждая из которых отвечает за изучение различных аспектов рыночной динамики. Первая ветвь модели занимается извлечением скрытых взаимозависимостей между активами, вторая и третья ветви ориентированы на краткосрочное и долгосрочное прогнозирование, что позволяет системе учитывать как текущие, так и будущие тренды на рынке.
Интеграция этих ветвей происходит с помощью каскада механизмов внимания, который усиливает способность модели к обучению на многоголовых блоках, улучшая обработку и выявление скрытых закономерностей в данных. В результате, система может не только анализировать и прогнозировать тренды на основе исторических данных, но и учитывать динамичные взаимосвязи между различными активами, что особенно важно для разработки торговых стратегий, способных адаптироваться к быстро меняющимся рыночным условиям.
Авторская визуализация фреймворка StockFormer представлена ниже.

В практической части предыдущей статьи были реализованы алгоритмы модуля Diversified Multi-Head Attention (DMH-Attn), который служит основой для улучшения стандартного механизма внимания в модели Transformer. DMH-Attn позволяет значительно повысить эффективность выявления различных паттернов и взаимозависимостей в финансовых временных рядах, что особенно важно при работе с шумными и высоко волатильными данными.
В данной статье мы продолжим начатую работу и сосредоточимся на архитектуре различных частей модели, а так же механизмах их взаимодействия для создания единого пространства состояний. Кроме того, рассмотрим процесс обучения политики поведения Агента принятия торговых решений.
Модели предиктивного кодирования
И начнем мы свою работу с моделей предиктивного кодирования. Авторы фреймворком Stockformer предложили использовать 3 предиктивные модели. Одна из них предназначены для обнаружения зависимостей между данными описания динамики анализируемых финансовых активов. А две других обучаются прогнозированию предстоящего движения рассматриваемого мультимодального временного ряда с разным горизонтом планирования.
Все три модели построены на архитектуре Энкодер—Декодер Transformer с использованием модифицированных модулей DMH-Attn. В своей реализации мы создадим Энкодер и Декодер в виде отдельных моделей.
Модели поиска взаимозависимостей
Архитектура моделей поиска взаимозависимостей во временных рядах анализируемых финансовых активов представлена в методе CreateRelationDescriptions.
bool CreateRelationDescriptions(CArrayObj *&encoder, CArrayObj *&decoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!decoder) { decoder = new CArrayObj(); if(!decoder) return false; }
В параметрах метода мы получаем указатели на 2 динамических массива, в которые нам предстоит передать описание архитектуры Энкодера и Декодера. В теле метода мы проверяем актуальность полученных указателей и, при необходимости, создаем новые экземпляры объектов динамических массивов.
В качестве первого слоя Энкодера мы, как обычно, используем полносвязный слой достаточного размера, который должен принять все данные тензора исходных данных.
Напомню, что на вход Энкодера мы подаем исторические данные на всю глубину анализируемой истории.
//--- Encoder encoder.Clear(); //--- if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
В качестве исходных данных мы используем "сырую" информацию, получаемую от терминала. Как несложно догадаться, получаемые данные мультимодального временного ряда, которые содержат информацию от анализируемых индикаторов и, возможно, нескольких финансовых инструментов, относятся к различным распределениям. Поэтому мы осуществляем первичную обработку исходных данных в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Авторы фреймворка StockFormer предлагают маскировать случайным образом до 50% исходных данных в процессе обучения моделей поиска взаимозависимостей. Модель должна восстановить замаскированные данные по оставшейся информации. Маскированием исходных данных в нашем Энкодере будет заниматься слой Dropout.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDropoutOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; descr.probability = 0.5f; if(!encoder.Add(descr)) { delete descr; return false; }
За ним мы добавим слой обучаемого позиционного кодирования.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLearnabledPE; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И завершает Энкодер модуль диверсифицированного многоголового внимания с 3 вложенными слоями.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronDMHAttention; descr.window = BarDescr; descr.window_out = 32; descr.count = HistoryBars; descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
На вход Декодера модели поиска взаимосвязей анализируемых последовательностей подается тот же мультимодальный временной ряд, с аналогичным маскированием и позиционным кодированием. Поэтому, в большей части архитектуры Энкодера и Декодера идентичны. Мы лишь заменяем модуль диверсифицированного многоголового внимания на аналогичный модуль кросс-внимания, в котором будут сопоставляться данные магистралей Декодера и Энкодера.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {prev_count/descr.windows[0], HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
А так как результаты работы Декодера мы будем сопоставлять с исходными данными, то дополним модель слоем обратной нормализации.
//--- layer 5 prev_count = descr.units[0] * descr.windows[0]; if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = prev_count; descr.layers = 1; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Модели прогнозирования
Обе модели прогнозирования, несмотря на разные горизонты планирования, имеют одинаковую архитектуру, которая представлена в методе CreatePredictionDescriptions. И надо сказать, что на вход Энкодера мы планируем подавать тот же мультимодальный временной ряд, который анализировался выше рассмотренной моделью поиска взаимозависимостей. Поэтому мы полностью переносим архитектуру Энкодеру, исключив лишь слой Dropout, так как в данном случае не используется маскирование исходных данных в процессе обучения моделей.
Декодер модели прогнозирования получает на вход лишь вектор описания последнего бара, значения которого переносятся в полносвязный слой.
//--- Decoder decoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
За ним, как и в выше рассмотренных моделях, идет слой пакетной нормализации, используемый нами для первичной обработки "сырых" исходных данных.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
В рамках данной статьи мы планируем обучать модель анализировать исторические данные одного финансового инструмента. С учетом этого, наличие в исходных данных вектора описания лишь одного бара сводит к минимуму эффективность слоя позиционного кодирования. Поэтому в данном случае мы его не используем. Однако при анализе более одного финансового инструмента я бы рекомендовал добавить позиционное кодирование к исходным данным.
Далее следует трехслойный модуль диверсифицированного многоголового кросс-внимания, который в качестве второго источника данных использует результаты работы соответствующего Энкодера.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; }
И на выходе модели мы добавляем полносвязный слой проекции данных без функции активации.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = BarDescr; descr.activation = None; descr.optimization = ADAM; if(!decoder.Add(descr)) { delete descr; return false; } //--- return true; }
Здесь хочется обратить внимание на 2 момента. Во-первых, в отличие от ранее рассмотренных нами моделей прогнозирования ожидаемых значений продолжения анализируемого временного ряда, авторы фреймворка StockFormer предложили прогнозировать коэффициенты изменения показателей. Таким образом, размер вектора результатов равен тензору исходных данных декодера, независимо от горизонта планирования. И такой подход позволяет нам отказаться от слоя обратной нормализации на выходе декодера. Более того, в таком варианте прогнозирования слой обратной нормализации становится излишним. Ведь коэффициент изменения и показатели исходных данных относятся к разным распределениям.
Второй момент, о котором следует упомянуть — использование полносвязного слоя на выходе декодера. В данном случае, как уже говорилось выше, мы планируем анализировать мультимодальный временной ряд одного финансового инструмента. И мы ожидаем, что все анализируемые унитарные последовательности имеют взаимные корреляции различной степени. Следовательно, коэффициенты их изменения должны быть согласованы. И здесь вполне уместным является использование полносвязного слоя. Если вы планируете осуществлять параллельный анализ нескольких финансовых инструментов, то я бы рекомендовал заменить полносвязный слой на сверточный с независимым прогнозированием коэффициентов изменения показателей по отдельным активам.
На этом мы завершаем рассмотрение архитектуры моделей предиктивного кодирования. С полным описанием их архитектуры вы можете ознакомиться во вложении.
Обучение моделей предиктивного кодирования
В фреймворке StockFormer обучение моделей предиктивного кодирования выделено отдельным этапом. И я предлагаю после рассмотрения архитектуры моделей предиктивного кодирования перейти к построению советника их обучения. Базовые методы советника во многом заимствованы из аналогичных программ, рассмотренных в предыдущих статьях данной серии. Поэтому в рамках данной статьи мы рассмотрим лишь алгоритм непосредственного обучения моделей, организованный в методе Train.
Вначале мы проведем небольшую подготовительную работу. В ходе которой сформируем вектор вероятностей выбора проходов из буфера воспроизведения опыта, присвоив большую вероятность проходам с максимальной доходностью. Таким образом мы смещаем процесс обучения в сторону прибыльных проходов, наполняя обучение положительными примерами.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; matrix<float> predict; bool Stop = false; //--- uint ticks = GetTickCount();
На данном этапе мы также объявим необходимые локальные переменные, используемые для хранения промежуточных данных в ходе процесса обучения. А после завершения подготовительной работы организуем цикл итераций обучения. Общее количество итераций задается во внешних параметрах советника.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize((NForecast + 1)*BarDescr) || MathAbs(state).Sum() == 0) { iter --; continue; }
В теле цикла мы сэмплируем одну траекторию из буфера воспроизведения опыта и начальное состояния окружающей среды на ней. И в обязательном порядке проверяем наличие исторических данных для анализа в выбранном состоянии, а так же наличие фактических данных на заданный горизонт планирования. При успешном прохождении блока контролей, мы переносим исторические значения на заданную глубину анализа в соответствующий буфер данных и осуществляем прямой проход всех предиктивных моделей.
//--- Feed Forward if(!RelateEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !RelateDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(RelateEncoder)) || !ShortEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(ShortEncoder)) || !LongEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !LongDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(LongEncoder))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что несмотря на одинаковую архитектуру, каждая предиктивная модель имеет собственный Энкодер. Такой подход увеличивает количество обучаемых моделей, а вместе с тем — затраты на обучение и эксплуатацию моделей. Но в то же время дает возможность каждой модели определить зависимости, релевантные для решения конкретной задачи.
Кроме того, следует сказать и об использовании тензора исходных данных основной магистрали Декодера. При рассмотрении архитектуры моделей мы говорили, что на вход декодера моделей прогнозирования подаются данные только последнего бара. Здесь же мы видим использование буфера исторических данных на всю глубину анализа во всех случаях. И здесь следует обратиться к формату записи состояния окружающей среды в буфере воспроизведения опыта — его можно представить в виде матрицы. Строки которой соответствую барам, а столбцы — признакам (ценовым показателям и значения индикаторов). Первая строка содержит информацию о последнем баре. Следовательно, при передаче тензор исторических данных, размер которого превышает количество элементов в слое исходных данных, модель возьмет лишь первые данные в размере слоя исходных данных. Именно это нам и надо. Поэтому мы можем не тратить ресурсы на создание дополнительного буфера и излишние копирование данных.
После успешного осуществления прямого прохода, мы переходим к подготовке целей и осуществлению операций обратного прохода. Для моделей обнаружения взаимозависимостей в унитарных временных рядах анализируемого временного ряда, целевыми значениями является сам анализируемый нами мультимодальный временной ряд. Следовательно, мы можем сразу осуществить обратный проход Декодера с передачей градиента ошибки Энкодеру. И на основании полученного градиента скорректируем параметры Энкодера.
//--- Relation if(!RelateDecoder.backProp(GetPointer(bState), (CNet *)GetPointer(RelateEncoder)) || !RelateEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
А вот для моделей прогнозирования целевые значения нам необходимо определить. Как было сказано выше, в качестве целевых значений в данном случае используются коэффициенты изменения анализируемых параметров. Мы исходим из предположения, что горизонт планирования меньше глубины анализа исторических данных. Поэтому для расчета целевых значений мы можем взять из буфера воспроизведения опыта состояние описания окружающей среды, записанное позже анализируемого на заданный горизонт планирования шагов. И трансформировать полученный тензор в матрицу, строки которой будут представлять отдельные бары.
//--- Prediction if(!predict.Resize(1, state.Size()) || !predict.Row(state, 0) || !predict.Reshape(NForecast + 1, BarDescr) ) { iter --; continue; }
Как уже говорилось ранее, первые строки такой матрицы будут содержать более поздние бары. Для определения целевых значений возьмем на 1 строку больше горизонта планирования. Таким образом последняя строка усеченной матрицы будет содержать информацию об анализируемом нами баре.
Здесь надо вспомнить, что в буфере воспроизведения опыта хранятся ненормализованные данные. И, с целью получения коэффициентов изменения цены в адекватном диапазоне данных, в качестве базы мы возьмем максимальные по модулю значения для каждого отдельного параметра в нашей матрице будущих значений. В таком случае, мы ожидаем получить коэффициенты изменения параметров в диапазоне {-2.0, 2.0}.
result = MathAbs(predict).Max(0);
В качестве целевых значений модели краткосрочного прогнозирования авторы фреймворка предлагают использовать коэффициент изменения параметра на следующем баре. Для вычисления такого коэффициента мы возьмем разницу последних 2 строк нашей матрицы прогнозных значений и разделим их на вектор максимальных значений. А полученный результат запишем в соответствующий буфер.
target = (predict.Row(NForecast - 1) - predict.Row(NForecast)) / result; if(!bShort.AssignArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Для модели долгосрочного планирования мы суммируем коэффициенты изменения цены на каждом баре с учетом коэффициента дисконтирования.
for(int i = 0; i < NForecast - 1; i++) target += (predict.Row(i) - predict.Row(i + 1)) / result * MathPow(DiscFactor, NForecast - i - 1); if(!bLong.AssignArray(target)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
И теперь, когда мы определили полный набор целевых значений, можно обновить параметры моделей прогнозирования, с целью минимизации ошибки прогнозирования. Для этого мы сначала выполняем операции обратного прохода Декодера и Энкодера модели краткосрочного прогнозирования, а затем — долгосрочного.
//--- Short prediction if(!ShortDecoder.backProp(GetPointer(bShort), (CNet *)GetPointer(ShortEncoder)) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
//--- Long prediction if(!LongDecoder.backProp(GetPointer(bLong), (CNet *)GetPointer(LongEncoder)) || !LongEncoder.backPropGradient((CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
После корректировки параметров всех обучаемых на данном этапе моделей, нам остается проинформировать пользователя о ходе выполнения операций и перейти к следующей итерации цикла обучения предиктивных моделей.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Relate", percent, RelateDecoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Short", percent, ShortDecoder.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Long", percent, LongDecoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После успешного выполнения всех итераций цикла обучения предиктивных моделей, мы очищаем поле комментариев на графике, где ранее осуществлялось информирование пользователя о ходе обучения моделей.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Relate", RelateDecoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Short", ShortDecoder.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Long", LongDecoder.getRecentAverageError()); ExpertRemove(); //--- }
Результаты обучения моделей выводим в журнал и инициализируем процесс остановки работы нашего советника.
С полным кодом эксперта обучения предиктивных моделей Вы можете ознакомиться во вложении к статье (файл "...\MQL5\Experts\StockFormer\Study1.mq5").
Здесь надо сказать, что в рамках обучения моделей, при подготовке данной статьи, мы использовали структуру исходных данных, применяемую в предыдущих работах. При этом для обучения предиктивных моделей используются только состояния окружающей среды, независимые от действий Агента. Поэтому мы запускаем процесс обучения предиктивных моделей на базе ранее собранной обучающей выборки. А сами тем временем переходим к следующему этапу нашей работы.
Обучение политики
И пока осуществляется обучение предиктивных моделей, мы займемся подготовкой следующего этапа — обучения политики поведения Агента.
Архитектура моделей
А начнем мы работу с подготовки архитектуры обучаемых на данном этапе моделей, которые представлены в методе CreateDescriptions. Однако, стоит отметить, что в фреймворке Stockformer Актер и Критик в качестве исходных данных используют результаты предиктивных моделей, объединенных в единое подпространство с помощью каскада модулей внимания. В нашей библиотеке реализована возможность построения моделей с двумя источниками данных. Поэтому каскад модулей внимания мы разделим на 2 модели. В рамках первой модели мы сопоставим данные двух горизонтов планирования. Здесь авторы фреймворка предлагают использовать данные долгосрочного планирования по основной магистрали, так как они меньше подвержены влиянию шума.
Архитектура модели сопоставления двух горизонтов планирования довольно проста. В ней мы создаем лишь 2 слоя:
- Полносвязный слой исходных данных.
- Диверсифицированный модуль кросс-внимания с 3 внутренними слоями.
//--- Long to Short predict long_short.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!long_short.Add(descr)) { delete descr; return false; } //--- Layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, 1}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!long_short.Add(descr)) { delete descr; return false; }
Мы не используем в данном случае слой нормализации данных, так как на вход модели подаем не сырые данные, а результат работы ранее рассмотренных моделей прогнозирования.
Результаты сопоставления двух горизонтов планирования далее обогащаются информацией о текущем состоянии окружающей среды, которое мы берем на выходе Энкодера модели поиска взаимозависимостей в исходных данных.
Обратите внимание, что обучение модели поиска взаимозависимостей в унитарных последовательностях исходных данных осуществлялось с постановкой цели восстановления маскированной части исходных данных. Следовательно, на данном этапе мы ожидаем, что в представлении модели есть некоторое предиктивное состояние каждого унитарного временного ряда, сформированное на базе остальных унитарных последовательностей. А значит, на выходе Энкодера модели анализа взаимозависимостей мы ожидаем получить тензор исходного описания состояния окружающей среды, очищенный от шума. Ведь выбросы, которые не вписываются в ожидания модели, будут компенсироваться среднестатистическими показателями, сформированными на основании данных других унитарных рядов.
Архитектура модели обогащения прогнозных значений информации о состоянии окружающей среды, практически полностью повторяет представленную выше модель сопоставления двух горизонтов планирования. Мы лишь изменяем размер последовательности во втором источнике данных.
//--- Predict to Relate predict_relate.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!predict_relate.Add(descr)) { delete descr; return false; } //--- Layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; //--- Windows { int temp[] = {BarDescr, BarDescr}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.window_out = 32; //--- Units { int temp[] = {1, HistoryBars}; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = 4; //Heads descr.layers = 3; //Layers descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!predict_relate.Add(descr)) { delete descr; return false; }
После построения каскада модулей внимания, которые объединяют в единое подпространство результаты работы трех предиктивных моделей, мы переходим к построению архитектуры нашего Актера. На вход модели мы подаем результаты работы описанного каскада внимания.
//--- Actor actor.Clear(); //--- Input Layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Полученные предиктивные ожидания мы объединяем с информацией о текущем состоянии счета.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = AccountDescr; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Объединенную информацию проводим через блок принятия решений, представленный в виде MLP со стохастической головой.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = None; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И на выходе модели мы согласуем параметры сделок в отельных направлениях с помощью сверточного слоя с сигмовидной функцией активации.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; }
Модель Критика имеет схожую архитектуру, только вместо состояния счета она анализирует действия Агента и на выходе модели мы не используем стохастическую голову. С полной архитектурой всех используемых моделей вы можете самостоятельно ознакомиться во вложении.
Программа обучения политики
После построения архитектуры моделей мы переходим к организации алгоритмов их обучения. На втором этапе обучения моделей осуществляется поиск оптимальной стратегии поведения Агента для достижения максимальной доходности при минимизации рисков.
Как и ранее, в начале метода обучения мы осуществляем небольшую подготовительную работу. Осуществляем генерацию вектора вероятностей выбора проходов из буфера воспроизведения опыта в зависимости от их результативности и объявляем локальные переменные.
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target, state; bool Stop = false; //--- uint ticks = GetTickCount();
Далее мы организуем цикл обучения моделей, число итераций которого определяется внешними параметрами советника.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter --; continue; } if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter --; continue; }
В теле цикла мы сэмплируем проход и состояние на нем для текущей итерации обучения. И не забываем проверить наличие необходимых данных в выбранном состоянии.
В отличие от предиктивных моделей, для обучения политики нам потребуется больше исходных данных. И после извлечения описания состояния окружающей среды мы соберем из данных буфера воспроизведения опыта информацию о балансе и открытых позициях на анализируемый момент.
//--- Account bAccount.Clear(); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; bAccount.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[1] / PrevBalance); bAccount.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); bAccount.Add(Buffer[tr].States[i].account[2]); bAccount.Add(Buffer[tr].States[i].account[3]); bAccount.Add(Buffer[tr].States[i].account[4] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[5] / PrevBalance); bAccount.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!!bAccount.GetOpenCL()) { if(!bAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
К информации о состоянии счета мы добавляем временную метку анализируемого состояния.
На основании собранной информации мы осуществляем прямой проход моделей предиктивного кодирования, а также каскада модулей внимания, для преобразования результатов предиктивного кодирования в единое подпространство.
//--- Generate Latent state if(!RelateEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !ShortDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(ShortEncoder)) || !LongEncoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL) || !LongDecoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CNet*)GetPointer(LongEncoder)) || !LongShort.feedForward(GetPointer(LongDecoder), -1, GetPointer(ShortDecoder), -1) || !PredictRelate.feedForward(GetPointer(LongShort), -1, GetPointer(RelateEncoder), -1) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что на данном этапе мы не осуществляем прямой проход Декодера модели поиска взаимозависимостей, так как данная модель не используется в процессе обучения политики и эксплуатации модели.
Далее мы осуществляем оптимизацию параметров Критика с целью минимизации ошибки оценки действий Агента. Для этого мы берем из базы воспроизведения опыта фактические действия Агента в выбранном состоянии и осуществляем прямой проход Критика.
//--- Critic target.Assign(Buffer[tr].States[i].action); target.Clip(0, 1); bActions.AssignArray(target); if(!!bActions.GetOpenCL()) if(!bActions.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } Critic.TrainMode(true); if(!Critic.feedForward(GetPointer(PredictRelate), -1, (CBufferFloat*)GetPointer(bActions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
По результатам работы прямого прохода Критика мы получаем некоторую оценку действий, которая на начальном этапе является практически случайной величиной. Однако, для фактических действий, совершенных Агентом при сборе траекторий, в буфере воспроизведения опыта сохранено реальное вознаграждение, полученное от окружающей среды. Следовательно, мы можем обучить Критика, минимизируя ошибку между прогнозным и фактическим вознаграждением.
Извлекаем фактическое вознаграждение из буфера воспроизведения опыта и осуществляем обратный проход Критика.
result.Assign(Buffer[tr].States[i + 1].rewards); target.Assign(Buffer[tr].States[i + 2].rewards); result = result - target * DiscFactor; Result.AssignArray(result); if(!Critic.backProp(Result, (CBufferFloat *)GetPointer(bActions), (CBufferFloat *)GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее мы переходим непосредственно к обучению политики поведения Актера. На основании собранных исходных данных мы осуществляем прямой проход Актера для формирования тензора действий в рамках текущей политики.
//--- Actor Policy if(!Actor.feedForward(GetPointer(PredictRelate), -1, (CBufferFloat*)GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
И тут же осуществляем оценку сформированных действий с помощью Критика.
Critic.TrainMode(false); if(!Critic.feedForward(GetPointer(PredictRelate), -1, (CNet*)GetPointer(Actor), -1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что в процессе оптимизации политики поведения Актера мы отключаем режим обучения для Критика. Это позволит нам передать градиент ошибки Актеру без изменения параметров Критика под нерелевантные данные.
Обучение политики Актера мы осуществляем в 2 этапа. На первом этапе мы проверяем результативность фактических действий из буфера воспроизведения опыта. И при получении положительного вознаграждения минимизируем ошибку между прогнозным и фактическим тензором действий. Таким образом мы обучаем прибыльную политику в стиле обучения с учителем.
if(result.Sum() >= 0) if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient)) || !PredictRelate.backPropGradient(GetPointer(RelateEncoder), -1, -1, false) || !LongShort.backPropGradient(GetPointer(ShortDecoder), -1, -1, false) || !ShortDecoder.backPropGradient((CNet *)GetPointer(ShortEncoder), -1, -1, false) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL) || !LongDecoder.backPropGradient((CNet *)GetPointer(LongEncoder), -1, -1, false) || !LongEncoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Обратите внимание, что при обучении политики Актера мы распространяем градиент ошибки до уровня моделей прогнозирования. Таким образом осуществляется их тонкая настройка для решения фактической задачи оптимизации политики поведения Актера.
На втором этапе осуществляется оптимизация политики поведения Актера распространением градиента ошибки от Критика. Здесь мы осуществляем корректировку политики, независимо от результативности фактических действий Агента в процессе взаимодействия с окружающей средой, так как опираемся на оценку действий текущей политики поведения Критиком. Для этого мы берем оценку действий и улучшаем её на 1%.
Critic.getResults(Result); for(int c = 0; c < Result.Total(); c++) { float value = Result.At(c); if(value >= 0) Result.Update(c, value * 1.01f); else Result.Update(c, value * 0.99f); }
Скорректированное таким образом вознаграждение передаем Критику в качестве цели и осуществляем его обратный проход с передачей градиента ошибки Актеру. В результате данной операции, мы ожидаем получить на уровне результатов модели Актера градиент ошибки, направленный в сторону повышения доходности действий.
if(!Critic.backProp(Result, (CNet *)GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient)) || !PredictRelate.backPropGradient(GetPointer(RelateEncoder), -1, -1, false) || !LongShort.backPropGradient(GetPointer(ShortDecoder), -1, -1, false) || !ShortDecoder.backPropGradient((CNet *)GetPointer(ShortEncoder), -1, -1, false) || !ShortEncoder.backPropGradient((CBufferFloat*)NULL) || !LongDecoder.backPropGradient((CNet *)GetPointer(LongEncoder), -1, -1, false) || !LongEncoder.backPropGradient((CBufferFloat*)NULL) ) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Полученный градиент ошибки распределяем через все модели, аналогично первому этапу обучения.
Далее нам остается проинформировать пользователя о ходе процессе обучения и переходим к следующей итерации цикла.
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Critic", percent, Critic.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После выполнения всех итераций цикла обучения, мы, как и на первом этапе обучения, очищаем поле комментариев на графике инструмента, выводим результаты обучения в журнал и инициализируем процесс завершения работы программы.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic", Critic.getRecentAverageError()); ExpertRemove(); //--- }
Надо сказать, что корректировка алгоритмов работы программ коснулась не только советников обучения моделей, но и экспертов взаимодействия с окружающей средой. Однако, объем корректировки алгоритма программ взаимодействия с окружающей средой во многом идентичен осуществлению представленного выше прямого прохода Актера. Поэтому мы не будем сейчас останавливаться на детальном рассмотрении алгоритмов указанных программ. Я предлагаю оставить их для самостоятельного изучения. Полный код всех программ, используемых при подготовке данной статьи, представлен во вложении в статье.
Тестирование
Мы завершили довольно длинный путь по реализации подходов фреймворка StockFormer средствами MQL5. И подошли к завершительному этапу нашей работы — обучению моделей и оценке полученных результатов на реальных исторических данных.
Выше уже было сказано, что для первого этапа обучения предиктивных моделей была использована обучающая выборка, собранная в рамках предыдущих работ. Напомню, что в используемой обучающей выборке собраны проходы на реальных исторических данных инструмента EURUSD за весь 2023 год, таймфрейм H1. Параметры всех анализируемых индикаторов используются по умолчанию.
На этапе обучения предиктивных моделей используются только исторические данные описания состояния окружающей среды, не зависящие от поведения Агента. Это позволяет нам осуществить обучение указанных моделей, без необходимости обновления обучающей выборки. Процесс обучения моделей повторяется до момента фиксации ошибок в узком диапазоне.
Второй этап обучения — оптимизация политики поведения Актера осуществляется уже итерационно, с периодическим обновлением обучающей выборки для актуализации её в области текущей политики поведения.
Результативность обученной модели мы проверяем в тестере стратегий MetaTrade 5 на исторических данных Января 2024 года. Период, который следует непосредственно за данными обучающей выборки. Результаты тестирования представлены ниже.
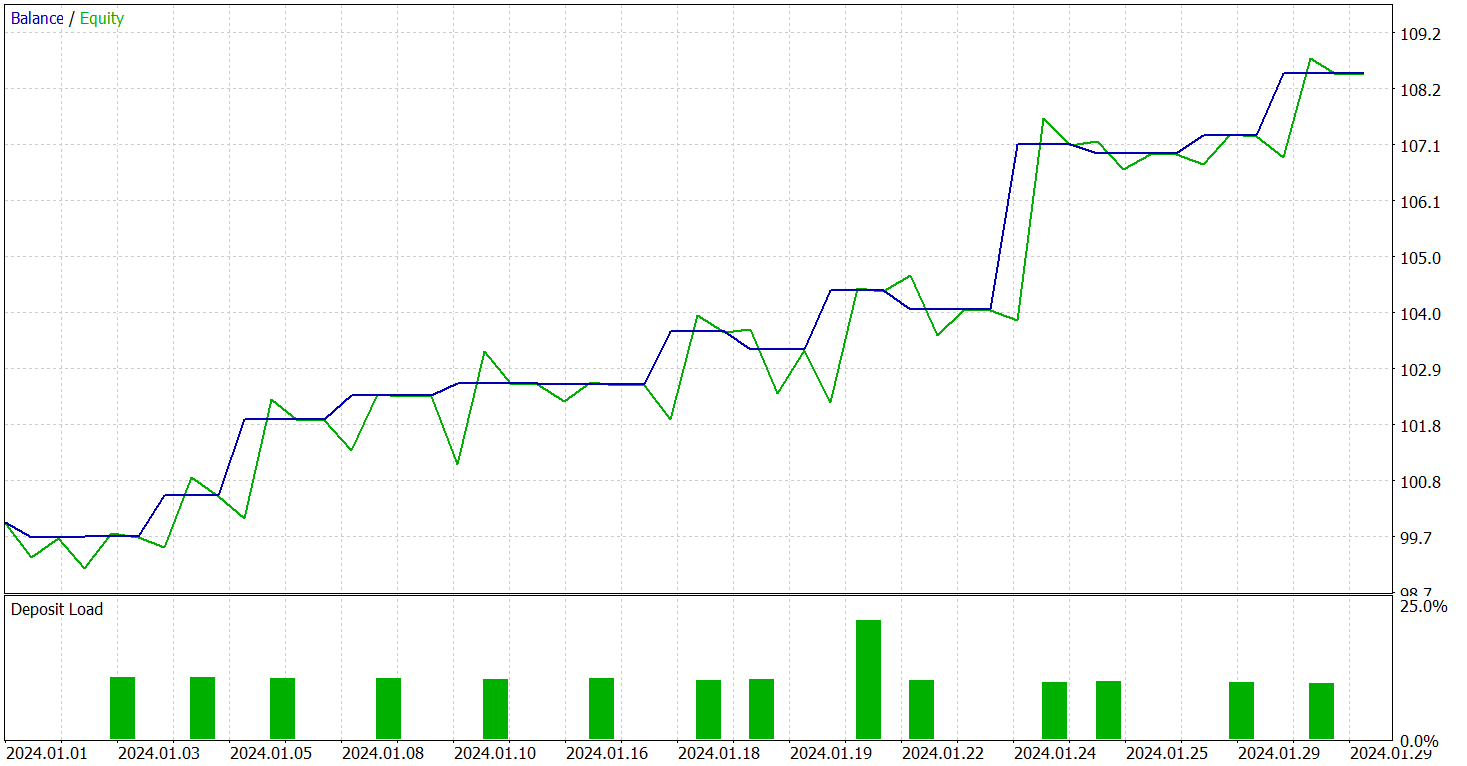
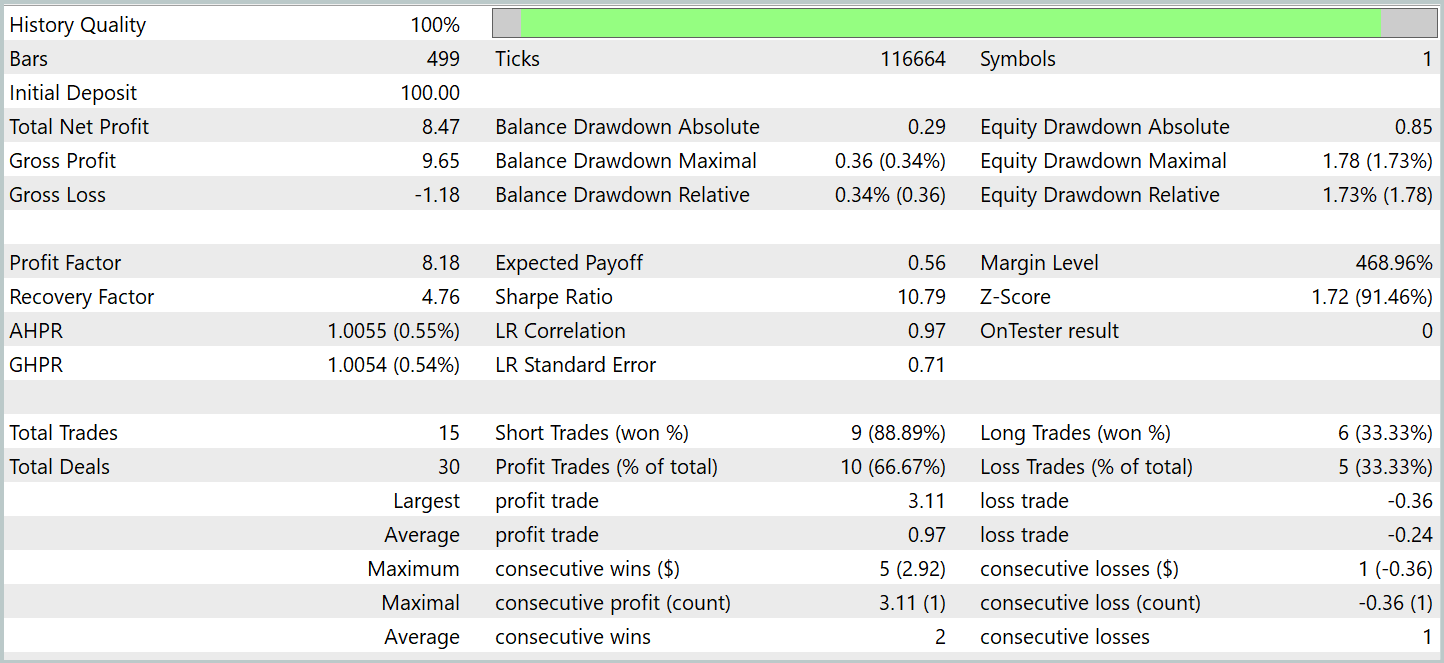
Как следует из представленных данных, за период тестирования модель совершила 15 торговых операций. И 10 из них было закрыто с прибылью, что составило более 66%. Не плохой результат. Особенно с учетом того, что средняя прибыльная сделка в 4 раза превышает аналогичный показатель убыточных операций. Как следствие, мы видим выраженную тенденцию к росту депозита на графике баланса.
Заключение
В двух статьях мы рассмотрели фреймворк StockFormer, предлагающий инновационный подход к обучению торговых стратегий на финансовых рынках. StockFormer сочетает методы предиктивного кодирования и глубокого обучения с подкреплением, позволяя обучать довольно гибкие политики, которые учитывают динамические зависимости между несколькими активами и прогнозируют их поведение как в краткосрочной, так и в долгосрочной перспективах.
Трехветвевое предиктивное кодирование StockFormer позволяет извлекать латентные представления, отражающие краткосрочные тренды, долгосрочные изменения и взаимосвязи между активами. Интеграция этих представлений осуществляется с помощью механизма каскадного многоголового внимания, что обеспечивает создание единого пространства состояний для оптимизации торговых решений.
В практической части были реализованы ключевые компоненты фреймворка средствами MQL5. Мы обучили модели и протестировали их на реальных исторических данных. Результаты экспериментов подтверждают эффективность предложенных подходов. Тем не менее, для применения моделей в реальной торговле требуется их обучение на более крупной выборке исторических данных и дальнейшее всестороннее тестирование.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study1.mq5 | Советник | Советник обучения предиктивного обучения |
| 4 | Study2.mq5 | Советник | Советник обучения политики |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования