Integrando MQL5 com pacotes de processamento de dados (Parte 4): Manipulação de Big Data

Introdução
Os mercados financeiros continuam evoluindo, e os traders não lidam mais apenas com gráficos de preços e indicadores simples — eles enfrentam uma enxurrada de dados vindos de todas as partes do mundo. Nesta era de big data, o sucesso na negociação não depende apenas de estratégia; depende de quão eficientemente você consegue filtrar montanhas de informações para encontrar insights acionáveis. Este artigo, o quarto de nossa série sobre integração do MQL5 com ferramentas de processamento de dados, concentra-se em capacitá-lo a lidar com conjuntos de dados massivos de forma contínua. Desde dados de ticks em tempo real até arquivos históricos que abrangem décadas, a capacidade de dominar big data está rapidamente se tornando a marca registrada de um sistema de negociação sofisticado.
Imagine analisar milhões de pontos de dados para descobrir tendências sutis do mercado ou incorporar conjuntos de dados externos, como sentimento social ou indicadores econômicos, ao seu ambiente de negociação MQL5. As possibilidades são infinitas — mas apenas se você tiver as ferramentas certas. Neste artigo, exploraremos como elevar o MQL5 além de seus recursos nativos, integrando-o a bibliotecas avançadas de processamento de dados e soluções de big data. Se você é um trader experiente buscando refinar sua vantagem ou um desenvolvedor curioso explorando o potencial da tecnologia financeira, este guia promete ser transformador. Fique atento para descobrir como transformar dados esmagadores em uma vantagem decisiva.
Coletar Dados Históricos
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTC H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Save the data to a CSV file filename = "BTC_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Para recuperar dados históricos, primeiro estabelecemos uma conexão com o terminal MetaTrader 5 usando a função mt5.initialize(). Isso é essencial porque o pacote Python se comunica diretamente com a plataforma MetaTrader 5 em execução. Configuramos o código para definir o intervalo de tempo desejado para extração dos dados, especificando as datas de início e término. Os objetos datetime são criados no fuso horário UTC para garantir consistência entre diferentes fusos. O script então usa a função mt5.copy-rates-range() para solicitar dados históricos de uma hora para o símbolo BTC/USD, começando em 6 de agosto de 2024 até a data e hora atuais.
Após desconectar do terminal MetaTrader 5 usando mt5.shutdown() para evitar conexões desnecessárias adicionais. Os dados recuperados são exibidos inicialmente em seu formato bruto para confirmar a extração bem-sucedida. Convertendo então esses dados em um DataFrame do pandas para facilitar a manipulação e análise. Além disso, o código converte os carimbos de data Unix em um formato de data legível, garantindo que os dados estejam bem estruturados e prontos para processamento ou análise adicional.
filename = "XAUUSD_H1_2nd.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Como meu Sistema Operacional é Linux, preciso salvar os dados recebidos em um arquivo. Mas para aqueles que estão no Windows, é possível simplesmente recuperar os dados com o seguinte script:
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2024, 8, 6, tzinfo=timezone.utc) utc_to = datetime.now(timezone) # Set to the current date and time # Get bars from BTCUSD H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("BTCUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Display data directly print("\nDisplay dataframe with data") print(rates_frame.head(10))
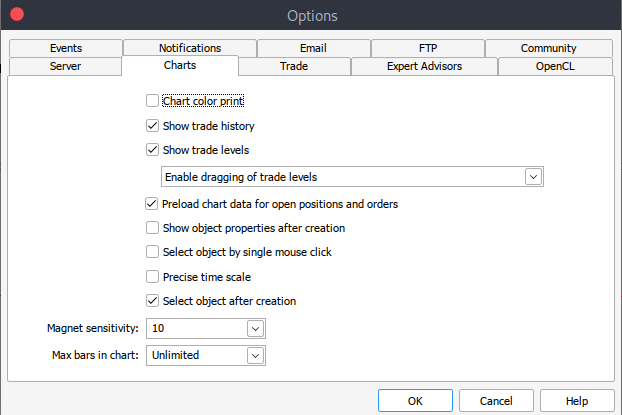
E se, por algum motivo, você não conseguir obter dados históricos, pode recuperá-los manualmente na sua plataforma MetaTrader 5 com os seguintes passos. Abra sua plataforma MetaTrader e, no topo do painel do MetaTrader 5, navegue para > Tools e depois > Options, onde você chegará às opções de Charts. Você então terá que selecionar o número de barras no gráfico que deseja baixar. É melhor escolher a opção de barras ilimitadas, já que trabalharemos com datas e não saberemos quantas barras existem em determinado período.
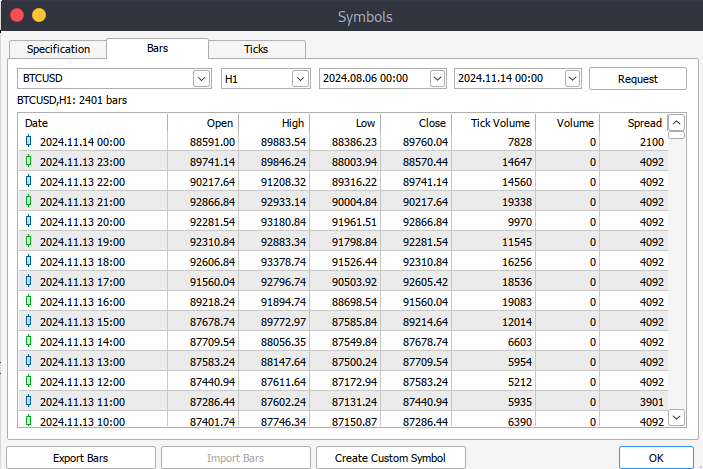
Depois disso, você deverá baixar os dados propriamente ditos. Para fazer isso, navegue para > View e depois > Symbols, onde você chegará à aba Specifications. Simplesmente navegue para > Bars ou Ticks, dependendo do tipo de dado que deseja baixar. Prossiga e insira o período de início e término dos dados históricos que deseja baixar. Após isso, clique no botão de solicitação para baixar os dados e salvá-los no formato .csv.
MetaTrader 5 Manipulação de Big Data no Jupyter Lab
import pandas as pd # Load the uploaded BTC 1H CSV file file_path = '/home/int_junkie/Documents/DataVisuals/BTCUSD_H1.csv' btc_data = pd.read_csv(file_path) # Display basic information about the dataset btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Saída:
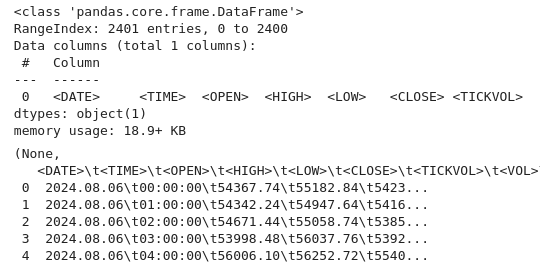
A partir do código acima, como sempre, inspecionamos os dados e entendemos a estrutura do conjunto de dados. Verificamos os tipos de dados, o formato e a completude (usando info()). Também obtemos o conteúdo e a disposição do conjunto de dados (usando head()). Este é um primeiro passo comum na análise exploratória de dados para garantir que os dados foram carregados corretamente e para se familiarizar com sua estrutura.
# Reload the data with tab-separated values btc_data = pd.read_csv(file_path, delimiter='\t') # Display basic information and the first few rows after parsing btc_data_info = btc_data.info() btc_data_head = btc_data.head() btc_data_info, btc_data_head
Saída:
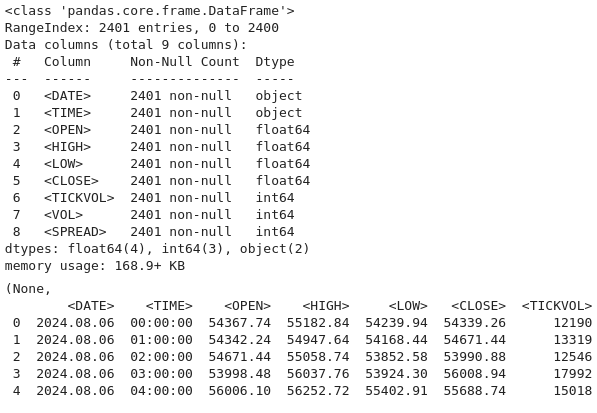
Agora usamos este código para recarregar o conjunto de dados a partir de um arquivo presumido como usando valores separados por tabulação (TSV) em vez do formato padrão separado por vírgulas. Ao especificar delimiter=\t em pd.read-csv() os dados são analisados corretamente em um DataFrame do Pandas para análise posterior. Em seguida, usamos btc-data-infor para exibir metadados sobre o conjunto de dados, como número de linhas, colunas, tipos de dados e quaisquer valores ausentes.
# Combine <DATE> and <TIME> into a single datetime column and set it as the index btc_data['DATETIME'] = pd.to_datetime(btc_data['<DATE>'] + ' ' + btc_data['<TIME>']) btc_data.set_index('DATETIME', inplace=True) # Drop the original <DATE> and <TIME> columns as they're no longer needed btc_data.drop(columns=['<DATE>', '<TIME>'], inplace=True) # Display the first few rows after modifications btc_data.head()
Saída:
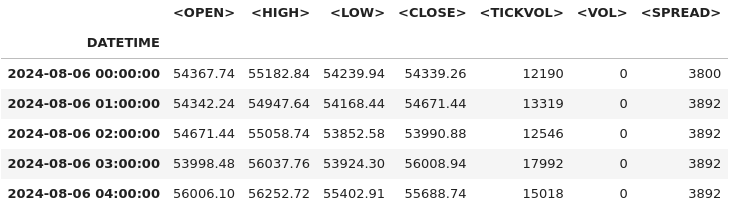
# Check for missing values and duplicates missing_values = btc_data.isnull().sum() duplicate_rows = btc_data.duplicated().sum() # Clean data (if needed) btc_data_cleaned = btc_data.drop_duplicates() # Results missing_values, duplicate_rows, btc_data_cleaned.shape
Saída:
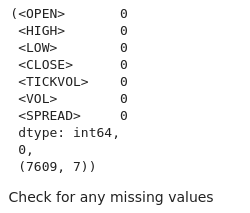
Podemos ver pelo resultado que não temos valores ausentes no nosso conjunto de dados.
# Check for missing values print("Missing values per column:\n", btc_data.isnull().sum()) # Check for duplicate rows print("Number of duplicate rows:", btc_data.duplicated().sum()) # Drop duplicate rows if any btc_data = btc_data.drop_duplicates()
Saída:
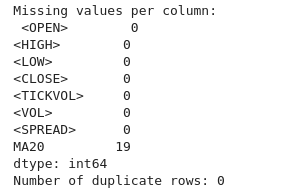
Pelo resultado, também podemos ver que não temos linhas ou colunas duplicadas
# Calculate a 20-period moving average btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() import ta # Add RSI using the `ta` library btc_data['RSI'] = ta.momentum.RSIIndicator(btc_data['<CLOSE>'], window=14).rsi()
Aqui, calculamos uma média móvel de 20 períodos e um RSI de 14 períodos com base nos preços de fechamento do DataFrame btc-data. Esses indicadores, amplamente utilizados na análise técnica, são adicionados como novas colunas (MA-20 e RSI) para análise ou visualização adicional. Essas etapas ajudam traders a identificar tendências e possíveis condições de sobrecompra ou sobrevenda no mercado.
import matplotlib.pyplot as plt # Plot closing price and MA20 plt.figure(figsize=(12, 6)) plt.plot(btc_data.index, btc_data['<CLOSE>'], label='Close Price') plt.plot(btc_data.index, btc_data['MA20'], label='20-period MA', color='orange') plt.legend() plt.title('BTC Closing Price and Moving Average') plt.show()
Saída:
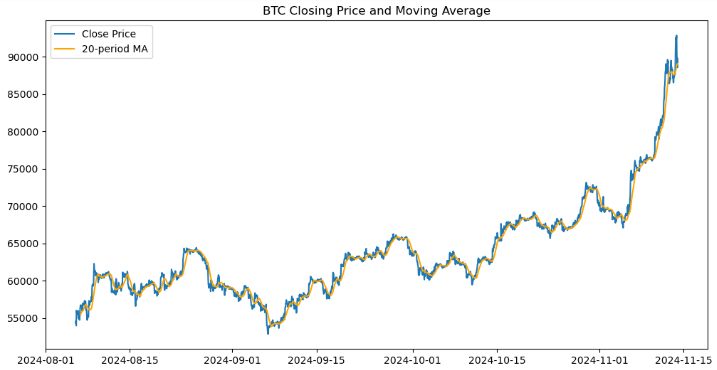
Criamos uma representação visual dos preços de fechamento do Bitcoin e de sua média móvel de 20 períodos (MA20) usando a biblioteca Matplotlib. Inicializamos uma figura de 12x6 polegadas e plotamos os preços de fechamento em relação ao índice do DataFrame, rotulando-os como “Close Price”. Sobrepomos um segundo gráfico para a média móvel de 20 períodos em laranja, rotulada como “20-period MA”. Uma legenda é adicionada para distinguir as duas linhas, e o gráfico recebe o título “BTC Closing Price and Moving Average”. Por fim, o gráfico é exibido, oferecendo uma visualização clara das tendências de preços e de como elas se relacionam com a média móvel.
import numpy as np # Add log returns btc_data['Log_Returns'] = (btc_data['<CLOSE>'] / btc_data['<CLOSE>'].shift(1)).apply(lambda x: np.log(x)) # Save the cleaned data btc_data.to_csv('BTCUSD_H1_cleaned.csv')
Agora calculamos os retornos logarítmicos dos preços de fechamento do Bitcoin e salvamos o conjunto de dados atualizado em um novo arquivo CSV. Os retornos logarítmicos são calculados dividindo cada preço de fechamento pelo preço de fechamento do período anterior e aplicando o logaritmo natural ao resultado. Isso é feito usando o método shift(1) para alinhar cada preço com seu antecessor, seguido da aplicação de uma função lambda com np.log. Os valores calculados, armazenados em uma nova coluna chamada Log-returns, fornecem uma medida mais adequada para análise de variações de preços, especialmente útil em modelagem financeira e análise de risco. Por fim, o conjunto de dados atualizado, incluindo a nova coluna Log-returns, é salvo em um arquivo chamado BTCUSD-H1-cleaned.csv para análise posterior.
import seaborn as sns import matplotlib.pyplot as plt # Correlation heatmap sns.heatmap(btc_data.corr(), annot=True, cmap='coolwarm') plt.title('Correlation Heatmap') plt.show()
Saída:
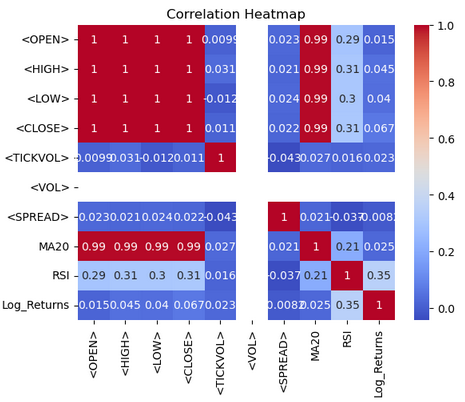
A partir do mapa de calor, visualizamos as correlações entre colunas numéricas no DataFrame btc-data usando Seaborn e Matplotlib A função btc-data.corr() calcula coeficientes de correlação pareados para todas as colunas numéricas, quantificando as relações lineares entre elas. A função sns.heatmap() exibe essa matriz de correlação como um mapa de calor, com annot=True para exibir os valores de correlação em cada célula e cmap='coolwarm' para usar uma paleta de cores divergente que facilita a interpretação. Tons quentes (vermelho) representam correlações positivas, enquanto tons frios (azul) indicam correlações negativas. Um título, “Correlation Heatmap”, é adicionado usando Matplotlib, e o gráfico é exibido com plt.show(). Essa visualização ajuda a identificar padrões e relações no conjunto de dados de forma rápida.
from sklearn.model_selection import train_test_split # Define features and target variable X = btc_data.drop(columns=['<CLOSE>']) y = btc_data['<CLOSE>'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Preparamos o DataFrame btc-data para aprendizado de máquina dividindo-o em subconjuntos de treinamento e teste. Primeiro, as variáveis preditoras (x) são definidas removendo a coluna <CLOSE> do conjunto de dados, enquanto a variável alvo (y) é definida como a coluna <CLOSE>, representando o valor a ser previsto. A função train-test-split do Scikit-learn é então usada para dividir os dados em conjuntos de treinamento e teste, com 80% dos dados destinados ao treinamento e 20% ao teste, conforme especificado por test-size=0.2. O random-state=42 garante que a divisão seja reproduzível, mantendo consistência entre diferentes execuções.
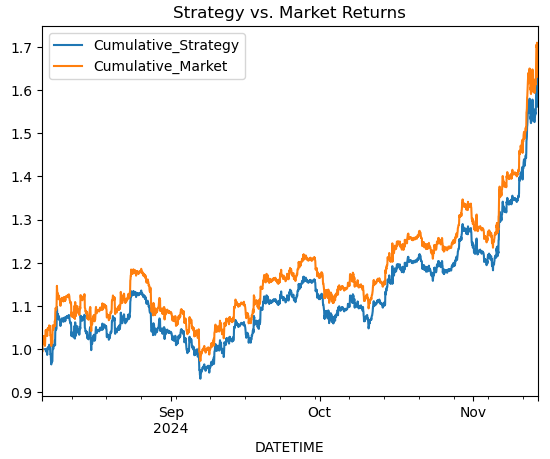
# Simple Moving Average Crossover Strategy btc_data['Signal'] = (btc_data['MA20'] > btc_data['RSI']).astype(int) btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'].shift(1) * btc_data['Returns'] # Plot cumulative returns btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data[['Cumulative_Strategy', 'Cumulative_Market']].plot(title='Strategy vs. Market Returns') plt.show()
Saída:
# Calculate short-term and long-term moving averages btc_data['MA20'] = btc_data['<CLOSE>'].rolling(window=20).mean() btc_data['MA50'] = btc_data['<CLOSE>'].rolling(window=50).mean() # Generate signals: 1 for Buy, -1 for Sell btc_data['Signal'] = 0 btc_data.loc[btc_data['MA20'] > btc_data['MA50'], 'Signal'] = 1 btc_data.loc[btc_data['MA20'] < btc_data['MA50'], 'Signal'] = -1 # Shift signal to avoid look-ahead bias btc_data['Signal'] = btc_data['Signal'].shift(1)
# Calculate returns btc_data['Returns'] = btc_data['<CLOSE>'].pct_change() btc_data['Strategy_Returns'] = btc_data['Signal'] * btc_data['Returns'] # Calculate cumulative returns btc_data['Cumulative_Market'] = (1 + btc_data['Returns']).cumprod() btc_data['Cumulative_Strategy'] = (1 + btc_data['Strategy_Returns']).cumprod() # Plot performance import matplotlib.pyplot as plt plt.figure(figsize=(12, 6)) plt.plot(btc_data['Cumulative_Market'], label='Market Returns') plt.plot(btc_data['Cumulative_Strategy'], label='Strategy Returns') plt.title('Strategy vs. Market Performance') plt.legend() plt.show()
Saída:
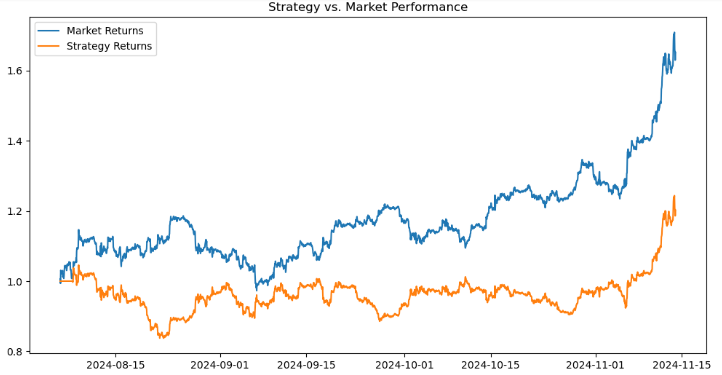
Ao avaliar o desempenho de uma estratégia de negociação em comparação ao mercado, visualizamos os resultados. Primeiro, calculamos os retornos do mercado como a variação percentual nos preços <CLOSE> usando pct-change() e armazenamos na coluna Returns. Os retornos da estratégia são calculados multiplicando a coluna signal (representando sinais de negociação como 1 para compra, -1 para venda ou 0 para manter) pelos retornos do mercado e armazenando o resultado em strategy-returns. Os retornos acumulados tanto do mercado quanto da estratégia são calculados usando (1 + returns).comprod(), simulando o crescimento composto de US$ 1 investido no mercado (Cumulative-market) ou seguindo a estratégia (Cumulative-strategy).
# Add RSI from ta.momentum import RSIIndicator btc_data['RSI'] = RSIIndicator(btc_data['<CLOSE>'], window=14).rsi() # Add MACD from ta.trend import MACD macd = MACD(btc_data['<CLOSE>']) btc_data['MACD'] = macd.macd() btc_data['MACD_Signal'] = macd.macd_signal() # Target variable: 1 if next period's close > current close btc_data['Target'] = (btc_data['<CLOSE>'].shift(-1) > btc_data['<CLOSE>']).astype(int)
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, classification_report # Define features and target features = ['MA20', 'MA50', 'RSI', 'MACD', 'MACD_Signal'] X = btc_data.dropna()[features] y = btc_data.dropna()['Target'] # Split data X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a Random Forest Classifier model = RandomForestClassifier(n_estimators=100, random_state=42) model.fit(X_train, y_train) # Evaluate the model y_pred = model.predict(X_test) print("Accuracy:", accuracy_score(y_test, y_pred)) print(classification_report(y_test, y_pred))
Saída:
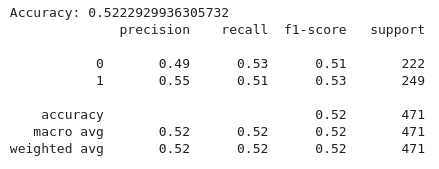
A partir do código acima, implementamos um pipeline de aprendizado de máquina para classificar sinais de negociação com base em indicadores técnicos usando um classificador Random Forest. Primeiro, o conjunto de variáveis preditoras (x) é definido, incluindo indicadores como médias móveis de 20 e 50 períodos (MA20, MA50), Índice de Força Relativa (RSI) e recursos relacionados ao MACD (MACD, MACD-Signals). A variável alvo (y) é definida como a coluna target, que geralmente indica sinais de compra, venda ou manutenção. Tanto os dados (x) quanto (y) são então divididos em conjuntos de treinamento e teste, com 80% para treinamento e 20% para teste, garantindo consistência via (random-state=42).
Um Classificador Random Forest é inicializado com 100 árvores de decisão (n-estimators=100) e treinado com os dados de treinamento (X-train e Y-train). As previsões do modelo no conjunto de teste (X-test) são avaliadas usando o accuracy score para determinar sua precisão e o classification report para fornecer métricas detalhadas como precisão, recall e F1-score para cada classe.
Implementamos então o modelo usando o seguinte código:
import joblib # Save the model joblib.dump(model, 'btc_trading_model.pkl')
Colocando tudo junto no MQL5
Vamos conectar o MQL5 ao script Python que estará executando nosso modelo treinado; teremos que configurar um canal de comunicação entre o MQL5 e o Python. Neste caso, usaremos WebRequest.
//+------------------------------------------------------------------+ //| BTC-Big-DataH.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #include <Trade\Trade.mqh> CTrade trade;
Todos os includes necessários e a biblioteca de negociação (trade.mqh) para gerenciamento de trades.
// Function to get predictions from Python API double GetPrediction(double &features[]) { // Convert the features array to a JSON-like string string jsonRequest = "["; for (int i = 0; i < ArraySize(features); i++) { jsonRequest += DoubleToString(features[i], 6); if (i != ArraySize(features) - 1) jsonRequest += ","; } jsonRequest += "]"; // Define the WebRequest parameters string url = "http://127.0.0.1:5000/predict"; string hdrs = {"Content-Type: application/json"}; // Add headers if needed char data[]; StringToCharArray(jsonRequest, data); // Convert JSON request string to char array char response[]; ulong result_headers_size = 0; //-------------------------------------------------------------------------------------- string cookie=NULL; char post[], resultsss[]; // Send the WebRequest int result = WebRequest("POST", url, cookie, NULL, 500, post, 0, resultsss, hdrs); // Handle the response if (result == -1) { Print("Error sending WebRequest: ", GetLastError()); return -1; // Return an error signal } // Convert response char array back to a string string responseString; CharArrayToString(response, (int)responseString); // Parse the response (assuming the server returns a numeric value) double prediction = StringToDouble(responseString); return prediction; }
A função GetPrediction() envia um conjunto de características de entrada para uma API baseada em Python e recupera uma previsão. As características são passadas como um array de doubles, que são convertidos em uma string no formato JSON para corresponder ao formato de entrada esperado pela API. Essa conversão envolve iterar pelo array de características e anexar cada valor a uma estrutura semelhante a um array JSON. A função DoubleToString garante que os valores sejam representados com seis casas decimais. A string JSON gerada é então convertida em um array de char.
A função então se prepara para fazer uma requisição POST ao endpoint da API (http://127.0.0.1:5000/predict) usando web request. Os parâmetros necessários são definidos. Uma vez que a resposta da API é recebida, ela é convertida de volta para uma string usando CharArrayToString. Se a web request falhar, um erro é registrado e a função retorna -1.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick(){ // Calculate indicators double MA20 = iMA(_Symbol, PERIOD_CURRENT, 20, 0, MODE_SMA, PRICE_CLOSE); double MA50 = iMA(_Symbol, PERIOD_CURRENT, 50, 0, MODE_SMA, PRICE_CLOSE); double RSI = iRSI(_Symbol, PERIOD_CURRENT, 14, PRICE_CLOSE); // Declare arrays to hold MACD data double MACD_Buffer[1], SignalLine_Buffer[1], Hist_Buffer[1]; // Get MACD handle int macd_handle = iMACD(NULL, 0, 12, 26, 9, PRICE_CLOSE); if (macd_handle != INVALID_HANDLE) { // Copy the most recent MACD values into buffers if (CopyBuffer(macd_handle, 0, 0, 1, MACD_Buffer) <= 0) Print("Failed to copy MACD"); if (CopyBuffer(macd_handle, 1, 0, 1, SignalLine_Buffer) <= 0) Print("Failed to copy Signal Line"); if (CopyBuffer(macd_handle, 2, 0, 1, Hist_Buffer) <= 0) Print("Failed to copy Histogram"); } // Assign the values from the buffers double MACD = MACD_Buffer[0]; double SignalLine = SignalLine_Buffer[0]; // Assign features double features[5]; features[0] = MA20; features[1] = MA50; features[2] = RSI; features[3] = MACD; features[4] = SignalLine; // Get prediction double signal = GetPrediction(features); if (signal == 1){ MBuy(); // Adjust lot size } else if (signal == -1){ MSell(); } }
O OnTick começa calculando indicadores técnicos essenciais: as Médias Móveis Simples de 20 e 50 períodos (MA20 e MA50) para acompanhar a direção da tendência, e o Índice de Força Relativa (RSI) de 14 períodos para medir o momentum do mercado. Além disso, ele recupera valores da linha MACD, linha de Sinal e Histograma usando a função iMACD, armazenando esses valores em buffers após validar o handle do MACD. Esses indicadores calculados são organizados em um array features, que serve como entrada para um modelo de machine learning acessado pela função GetPrediction. Esse modelo prevê uma ação de negociação, retornando 1 para sinal de compra ou -1 para sinal de venda. Com base na previsão, a função executa uma operação de compra com MBuy ou de venda com MSell().
Python API
Abaixo está uma API web usando Flask para fornecer previsões de um modelo de machine learning pré-treinado para decisões de negociação de BTC.
from flask import Flask, request, jsonify import joblib import pandas as pd # Load the model model = joblib.load('btc_trading_model.pkl') app = Flask(__name__) @app.route('/predict', methods=['POST']) def predict(): data = request.json df = pd.DataFrame(data) prediction = model.predict(df) return jsonify(prediction.tolist()) app.run(port=5000)
Conclusão
Em resumo, desenvolvemos uma solução de negociação completa combinando manipulação de big data, machine learning e automação. Começando com dados históricos de BTC/USD, processamos e limpamos esses dados para extrair características significativas como médias móveis, RSI e MACD. Usamos esses dados processados para treinar um modelo de machine learning capaz de prever sinais de negociação. O modelo treinado foi implantado como uma API baseada em Flask, permitindo que sistemas externos consultem previsões. No MQL5, implementamos um Expert Advisor que coleta valores de indicadores em tempo real, os envia para a API Flask para obter previsões e executa trades com base nos sinais retornados.
Essa solução integrada de negociação capacita traders ao combinar a precisão dos indicadores técnicos com a inteligência do machine learning. Ao utilizar um modelo treinado com dados históricos, o sistema se adapta à dinâmica do mercado, fazendo previsões informadas que podem melhorar os resultados das negociações. A implantação do modelo por meio de uma API oferece flexibilidade, permitindo que traders o integrem a diversas plataformas como o MQL5.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/16446
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 A Arte de Registrar Logs (Parte 3): Explorando os handlers para armazenamento de logs
A Arte de Registrar Logs (Parte 3): Explorando os handlers para armazenamento de logs
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso