
Datenwissenschaft und ML (Teil 31): CatBoost AI-Modelle für den Handel verwenden

„CatBoost ist eine Gradient-Boosting-Bibliothek, die sich dadurch auszeichnet, dass sie kategoriale Merkmale auf effiziente und skalierbare Weise behandelt und so eine erhebliche Leistungssteigerung für viele reale Probleme bietet.“
— Anthony Goldbloom.
Was ist CatBoost?
CatBoost ist eine Open-Source-Softwarebibliothek mit Gradient-Boosting-Algorithmen für Entscheidungsbäume, die speziell für die Herausforderungen beim Umgang mit kategorialen Merkmalen und Daten beim maschinellen Lernen entwickelt wurde.
Es wurde von Yandex entwickelt und im Jahr 2017 als Open-Source-Version veröffentlicht, mehr dazu hier.
Obwohl CatBoost im Vergleich zu Techniken des maschinellen Lernens wie der linearen Regression oder SVM erst vor kurzem eingeführt wurde, erlangte es in der KI-Gemeinschaft große Popularität und stieg auf Plattformen wie Kaggle an die Spitze der am häufigsten verwendeten Modelle für maschinelles Lernen.
Was CatBoost so viel Aufmerksamkeit verschafft hat, ist seine Fähigkeit, automatisch mit kategorischen Merkmalen im Datensatz umzugehen, was für viele Algorithmen des maschinellen Lernens eine Herausforderung darstellen kann.
- Catboost-Modelle bieten in der Regel eine bessere Leistung im Vergleich zu anderen Modellen mit minimalem Aufwand, selbst mit den Standardparametern und -einstellungen können diese Modelle in Bezug auf die Genauigkeit gute Ergebnisse erzielen.
- Im Gegensatz zu neuronalen Netzen, für deren Programmierung und Funktionsweise Fachwissen erforderlich ist, ist die Implementierung von CatBoost unkompliziert.

Dieser Artikel geht davon aus, dass Sie ein grundlegendes Verständnis von maschinellem Lernen, Entscheidungsbäumen, XGBoost, LightGBM und ONNX haben.
Wie funktioniert CatBoost?
CatBoost basiert auf einem Gradient-Boosting-Algorithmus, genau wie Light Gradient Machine (LightGBM) und Extreme Gradient Boosting (XGBoost). Dabei werden mehrere Entscheidungsbaummodelle nacheinander erstellt, wobei jedes Modell auf dem vorherigen aufbaut und versucht, die Fehler der vorherigen Modelle zu korrigieren.
Die endgültige Vorhersage ist eine gewichtete Summe der Vorhersagen aller an dem Prozess beteiligten Modelle.
Das Ziel dieser Gradient Boosted Decision Trees (GBDTs) ist es, die Verlustfunktion zu minimieren. Dies geschieht durch Hinzufügen eines neuen Modells, das die Fehler des vorherigen Modells korrigiert.
Behandlung kategorischer Merkmale
Wie ich bereits erklärt habe, kann CatBoost kategoriale Merkmale verarbeiten, ohne dass eine explizite Kodierung wie One-hot-Kodierung oder Label-Kodierung erforderlich ist, die für andere maschinelle Lernmodelle erforderlich ist.
Diese Kodierung erfolgt durch Berechnung einer bedingten Verteilung des Ziels für jeden kategorialen Merkmalswert.
Eine weitere wichtige Neuerung in CatBoost ist die Verwendung von einer geordneten Verstärkung (ordered boosting) bei der Berechnung der Statistiken für kategoriale Merkmale. Dieses geordnete Verstärkung stellt sicher, dass die Kodierung für jede Instanz auf den Informationen der zuvor beobachteten Datenpunkte basiert.
Dies trägt dazu bei, Datenlecks zu vermeiden und eine Überanpassung zu verhindern.
Es verwendet symmetrische Entscheidungsbaumstrukturen
Im Gegensatz zu LightGBM und XGBoost, die asymmetrische Bäume verwenden, verwendet CatBoost symmetrische Entscheidungsbäume für den Entscheidungsprozess. Bei einem symmetrischen Baum werden sowohl der linke als auch der rechte Zweig bei jeder Teilung symmetrisch auf der Grundlage derselben Teilungsregel konstruiert; dieser Ansatz hat mehrere Vorteile, wie zum Beispiel:
- Es führt zu einem schnelleren Training, da beide Splits symmetrisch sind.
- Effiziente Speichernutzung aufgrund der einfacheren Baumstruktur.
- Symmetrische Bäume sind robuster gegenüber kleinen Störungen in den Daten.
CatBoost vs. XGBoost und LightGBM, ein detaillierter Vergleich
Wir wollen verstehen, wie sich CatBoost von anderen gradientenverstärkte Entscheidungsbäumen unterscheidet. Verstehen wir die Unterschiede zwischen diesen drei, damit wir wissen, wann wir einen dieser drei verwenden sollten und wann nicht.
Aspekt | CatBoost | LichtGBM | XGBoost |
|---|---|---|---|
Behandlung kategorischer Merkmale | Ausgestattet mit automatischer Kodierung und geordneter Verstärkung für den Umgang mit kategorialen Variablen. | Erfordert eine manuelle Kodierung, z. B. One-Hot-Kodierung, Kennzeichnungskodierung usw. | Erfordert eine manuelle Kodierung, z. B. One-Hot-Kodierung, Kennzeichnungskodierung usw. |
Struktur des Entscheidungsbaums | Es verfügt über symmetrische Entscheidungsbäume, die ausgewogen sind und gleichmäßig wachsen. Sie gewährleisten schnellere Vorhersagen und ein geringeres Risiko der Überanpassung. | Sie hat eine blattweise Wachstumsstrategie (asymmetrisch), die sich auf die Blätter mit dem höchsten Verlust konzentriert. Dies führt zu tiefen und unausgewogenen Bäumen, die eine höhere Genauigkeit, aber auch ein größeres Risiko der Überanpassung aufweisen können. | Es hat eine stufenweise Wachstumsstrategie (asymmetrisch), die den Baum auf der Grundlage der besten Aufteilung für jeden Knoten wachsen lässt. Dies führt zu flexiblen, aber langsameren Vorhersagen und einem potenziellen Risiko der Überanpassung. |
Modellgenauigkeit | Sie bieten eine gute Genauigkeit bei der Arbeit mit Datensätzen, die viele kategoriale Merkmale enthalten, aufgrund des geordneten Boostings und des geringeren Risikos einer Überanpassung bei kleineren Daten. | Sie bieten eine gute Genauigkeit, insbesondere bei großen und hochdimensionalen Datensätzen, da sich die blattweise Wachstumsstrategie auf die Verbesserung der Leistung in Bereichen mit hohen Fehlern konzentriert. | Sie bieten bei den meisten Datensätzen eine gute Genauigkeit, werden aber von CatBoost bei kategorischen Datensätzen und von LightGBM bei sehr großen Datensätzen aufgrund seiner weniger aggressiven Baumwachstumsstrategie tendenziell übertroffen. |
Geschwindigkeit und Genauigkeit trainieren | Ist in der Regel langsamer zu trainieren als LightGBM, aber effizienter bei kleinen bis mittelgroßen Datensätzen, insbesondere wenn kategoriale Merkmale beteiligt sind. | Ist in der Regel die schnellste dieser drei, vor allem bei großen Datensätzen, da der Baum blattweise wächst, was bei hochdimensionalen Daten effizienter ist. | Oft ist er der mit Abstand langsamste der drei. Es ist sehr effizient für große Datensätze. |
Einsatz eines CatBoost-Modells
Bevor wir den Code für CatBoost schreiben können, müssen wir ein Problemszenario erstellen. Wir wollen die Handelssignale (Kauf/Verkauf) vorhersagen, indem wir die Daten Open, High, Low, Close und einige kategorische Merkmale wie Day (das aktuelle Datum), Day of Week (von Montag bis Sonntag), Day of Year (von 1 bis 365) und den Month (von Januar bis Dezember) verwenden.
Die OHLC-Werte (Open, High, Low, Close) sind kontinuierliche Merkmale, während der Rest kategorische Merkmale sind. Ein Skript zur Erfassung dieser Daten finden Sie in den Anhängen.
Wir beginnen damit, das CatBoost-Modell nach der Installation zu importieren.
Installation
Befehlszeile
pip install catboost
Importieren.
Python-Code
import numpy as np import pandas as pd import catboost from catboost import CatBoostClassifier from sklearn.pipeline import Pipeline from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report import seaborn as sns import matplotlib.pyplot as plt sns.set_style("darkgrid")
Wir können die Daten visualisieren, um zu sehen, was es damit auf sich hat.
df = pd.read_csv("/kaggle/input/ohlc-eurusd/EURUSD.OHLC.PERIOD_D1.csv")
df.head()Ergebnis:
| Open | High | Low | Close | Day | DayofWeek | DayofYear | Month | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 |
Beim Sammeln von Daten in einem MQL5-Skript habe ich die Werte DayofWeek (Montag bis Sonntag) und Month (Januar - Dezember) als Ganzzahlen anstelle von Zeichenketten abgerufen, da ich sie in einer Matrix speichere, die es mir nicht erlaubt, Zeichenketten hinzuzufügen, obwohl sie von Natur aus kategorische Variablen sind. So wie es jetzt aussieht, werden wir sie wieder in Kategorien umwandeln und sehen, wie CatBoost damit umgehen kann.
Lassen Sie uns die Zielvariable vorbereiten.
Python-Code
new_df = df.copy() # Create a copy of the original DataFrame # we Shift the 'Close' and 'open' columns by one row to ge the future close and open price values, then we add these new columns to the dataset new_df["target_close"] = df["Close"].shift(-1) new_df["target_open"] = df["Open"].shift(-1) new_df = new_df.dropna() # Drop the rows with NaN values resulting from the shift operation open_values = new_df["target_open"] close_values = new_df["target_close"] target = [] for i in range(len(open_values)): if close_values[i] > open_values[i]: target.append(1) # buy signal else: target.append(0) # sell signal new_df["signal"] = target # we create the signal column and add the target variable we just prepared print(new_df.shape) new_df.head()
Ergebnis:
| Open | High | Low | Close | Day | DayofWeek | DayofYear | Month | target_close | target_open | signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 | 1.09399 | 1.09678 | 0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 | 1.09805 | 1.09701 | 1 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 | 1.09742 | 1.09639 | 1 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 | 1.09757 | 1.10302 | 0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 | 1.10297 | 1.10431 | 0 |
Da wir nun die Signale haben, die wir vorhersagen können, sollten wir die Daten in Trainings- und Testproben aufteilen.
X = new_df.drop(columns = ["target_close", "target_open", "signal"]) # we drop future values y = new_df["signal"] # trading signals are the target variables we wanna predict X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42)
Wir definieren eine Liste von kategorischen Merkmalen, die in unserem Datensatz vorhanden sind.
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"]
Anhand dieser Liste können wir dann diese kategorischen Merkmale in das Format einer Zeichenkette konvertieren, da kategorische Variablen in der Regel als Zeichenkette vorliegen.
X_train[categorical_features] = X_train[categorical_features].astype(str) X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
Ergebnis:
<class 'pandas.core.frame.DataFrame'> Index: 6999 entries, 9068 to 7270 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Open 6999 non-null float64 1 High 6999 non-null float64 2 Low 6999 non-null float64 3 Close 6999 non-null float64 4 Day 6999 non-null object 5 DayofWeek 6999 non-null object 6 DayofYear 6999 non-null object 7 Month 6999 non-null object dtypes: float64(4), object(4) memory usage: 492.1+ KB
Wir haben jetzt kategorische Variablen mit Objektdatentypen aus Zeichenketten. Wenn Sie diese Daten mit einem anderen maschinellen Lernmodell als CatBoost ausprobieren, werden Sie Fehler erhalten, da Objektdatentypen in den typischen Trainingsdaten für maschinelles Lernen nicht zulässig sind.
Trainieren eines CatBoost-Modells
Bevor wir die Fit-Methode aufrufen, die für das Training des CatBoost-Modells verantwortlich ist, sollten wir einige der vielen Parameter verstehen, die dieses Modell ausmachen.
Parameter | Beschreibung |
|---|---|
Iterations | Dies ist die Anzahl der zu erstellenden Entscheidungsbaum-Iterationen. Mehr Iterationen führen zu einer besseren Leistung, bergen aber auch das Risiko einer Überanpassung. |
learning_rate | Dieser Faktor steuert die Verteilung der einzelnen Bäume auf die endgültige Vorhersage. Eine geringere Lernrate erfordert mehr Iterationen, bis die Bäume konvergieren, führt aber oft zu besseren Modellen. |
depth | Dies ist die maximale Tiefe der Bäume. Tiefere Bäume können komplexere Muster in den Daten erfassen, führen aber oft zu einer Überanpassung. |
cat_features | Dies ist eine Liste von kategorischen Indizes. Obwohl das CatBoost-Modell in der Lage ist, die kategorischen Merkmale zu erkennen, ist es eine gute Praxis, dem Modell ausdrücklich mitzuteilen, welche Merkmale kategorisch sind. Dies hilft dem Modell, die kategorialen Merkmale aus menschlicher Sicht zu verstehen, da die Methoden zur automatischen Erkennung kategorialer Variablen manchmal versagen können. |
l2_leaf_reg | Dies ist der Koeffizient für die L2 Regulierung. Sie hilft, eine Überanpassung zu verhindern, indem größere Blattgewichte bestraft werden. |
border_count | Dies ist die Anzahl der Splits für jedes kategoriale Merkmal. Je höher diese Zahl ist, desto besser ist die Leistung und desto länger ist die Berechnungszeit. |
eval_metric | Dies ist der Bewertungsmaßstab, der beim Training verwendet wird. Es hilft bei der effektiven Überwachung der Modellleistung. |
early_stopping_rounds | Wenn dem Modell Validierungsdaten zur Verfügung gestellt werden, wird der Trainingsfortschritt gestoppt, wenn für diese Anzahl von Runden keine Verbesserung der Genauigkeit des Modells festgestellt wird. Dieser Parameter trägt dazu bei, die Überanpassung zu reduzieren und kann viel Trainingszeit sparen. |
Wir können ein Wörterbuch für die oben genannten Parameter definieren.
params = dict( iterations=100, learning_rate=0.01, depth=10, l2_leaf_reg=5, bagging_temperature=1, border_count=64, # Number of splits for categorical features eval_metric='Logloss', random_seed=42, # Seed for reproducibility verbose=1, # Verbosity level # early_stopping_rounds=10 # Early stopping for validation )
Schließlich können wir das Catboost-Modell innerhalb der Sklearn-Pipeline definieren und dann die Fit-Methode für das Training aufrufen, indem wir dieser Methode Evaluierungsdaten und eine Liste von kategorialen Merkmalen übergeben.
pipe = Pipeline([ ("catboost", CatBoostClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test), catboost__cat_features=categorical_features)
Outputs
90: learn: 0.6880592 test: 0.6936112 best: 0.6931239 (3) total: 523ms remaining: 51.7ms 91: learn: 0.6880397 test: 0.6936100 best: 0.6931239 (3) total: 529ms remaining: 46ms 92: learn: 0.6880350 test: 0.6936051 best: 0.6931239 (3) total: 532ms remaining: 40ms 93: learn: 0.6880280 test: 0.6936103 best: 0.6931239 (3) total: 535ms remaining: 34.1ms 94: learn: 0.6879448 test: 0.6936110 best: 0.6931239 (3) total: 541ms remaining: 28.5ms 95: learn: 0.6878328 test: 0.6936387 best: 0.6931239 (3) total: 547ms remaining: 22.8ms 96: learn: 0.6877888 test: 0.6936473 best: 0.6931239 (3) total: 553ms remaining: 17.1ms 97: learn: 0.6877408 test: 0.6936508 best: 0.6931239 (3) total: 559ms remaining: 11.4ms 98: learn: 0.6876611 test: 0.6936708 best: 0.6931239 (3) total: 565ms remaining: 5.71ms 99: learn: 0.6876230 test: 0.6936898 best: 0.6931239 (3) total: 571ms remaining: 0us bestTest = 0.6931239281 bestIteration = 3 Shrink model to first 4 iterations.
Evaluierung des Modells
Wir können Sklearn-Metriken verwenden, um die Leistung dieses Modells zu bewerten.
# Make predicitons on training and testing sets y_train_pred = pipe.predict(X_train) y_test_pred = pipe.predict(X_test) # Training set evaluation print("Training Set Classification Report:") print(classification_report(y_train, y_train_pred)) # Testing set evaluation print("\nTesting Set Classification Report:") print(classification_report(y_test, y_test_pred))
Outputs
Training Set Classification Report: precision recall f1-score support 0 0.55 0.44 0.49 3483 1 0.54 0.64 0.58 3516 accuracy 0.54 6999 macro avg 0.54 0.54 0.54 6999 weighted avg 0.54 0.54 0.54 6999 Testing Set Classification Report: precision recall f1-score support 0 0.53 0.41 0.46 1547 1 0.49 0.61 0.54 1453 accuracy 0.51 3000 macro avg 0.51 0.51 0.50 3000 weighted avg 0.51 0.51 0.50 3000
Das Ergebnis ist ein Modell mit durchschnittlicher Leistung. Nachdem ich die Liste der kategorischen Merkmale entfernt hatte, stieg die Modellgenauigkeit im Trainingssatz auf 60 %, im Testsatz blieb sie jedoch gleich.
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
Ergebnis:
91: learn: 0.6844878 test: 0.6933503 best: 0.6930500 (30) total: 395ms remaining: 34.3ms 92: learn: 0.6844035 test: 0.6933539 best: 0.6930500 (30) total: 399ms remaining: 30ms 93: learn: 0.6843241 test: 0.6933791 best: 0.6930500 (30) total: 404ms remaining: 25.8ms 94: learn: 0.6842277 test: 0.6933732 best: 0.6930500 (30) total: 408ms remaining: 21.5ms 95: learn: 0.6841427 test: 0.6933758 best: 0.6930500 (30) total: 412ms remaining: 17.2ms 96: learn: 0.6840422 test: 0.6933796 best: 0.6930500 (30) total: 416ms remaining: 12.9ms 97: learn: 0.6839896 test: 0.6933825 best: 0.6930500 (30) total: 420ms remaining: 8.58ms 98: learn: 0.6839040 test: 0.6934062 best: 0.6930500 (30) total: 425ms remaining: 4.29ms 99: learn: 0.6838397 test: 0.6934259 best: 0.6930500 (30) total: 429ms remaining: 0us bestTest = 0.6930499562 bestIteration = 30 Shrink model to first 31 iterations.
Training Set Classification Report: precision recall f1-score support 0 0.61 0.53 0.57 3483 1 0.59 0.67 0.63 3516 accuracy 0.60 6999 macro avg 0.60 0.60 0.60 6999 weighted avg 0.60 0.60 0.60 6999
Um dieses Modell im Detail zu verstehen, erstellen wir das Diagramm der Merkmalsbedeutung.
# Extract the trained CatBoostClassifier from the pipeline
catboost_model = pipe.named_steps['catboost']
# Get feature importances
feature_importances = catboost_model.get_feature_importance()
feature_im_df = pd.DataFrame({
"feature": X.columns,
"importance": feature_importances
})
feature_im_df = feature_im_df.sort_values(by="importance", ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(data = feature_im_df, x='importance', y='feature', palette="viridis")
plt.title("CatBoost feature importance")
plt.xlabel("Importance")
plt.ylabel("feature")
plt.show()Output
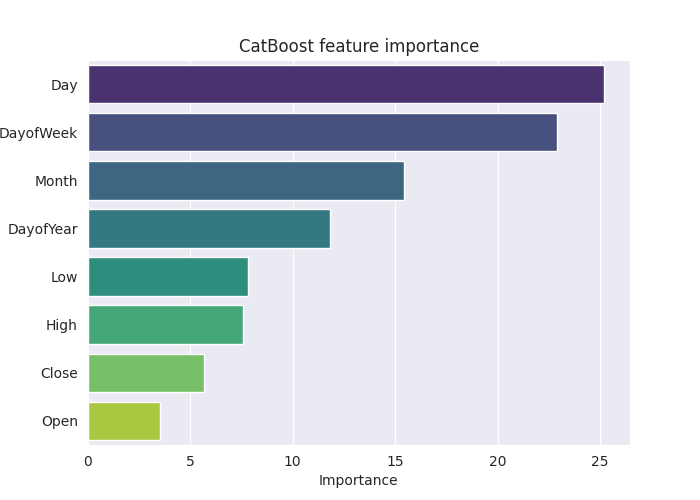
Die obige „Merkmalsbedeutungsdarstellung“ gibt Aufschluss darüber, wie das Modell Entscheidungen getroffen hat. Es scheint, dass das CatBoost-Modell die kategorialen Variablen als die wichtigsten Merkmale für das endgültige vorhergesagte Ergebnis des Modells ansieht und nicht die kontinuierlichen Variablen.
Speichern des CatBoost-Modells in ONNX
Um dieses Modell im MetaTrader 5 zu verwenden, müssen wir es im ONNX-Format speichern. Das Speichern des CatBoost-Modells kann nun etwas kompliziert sein, im Gegensatz zu Sklearn- und Keras-Modellen, die über Methoden zur einfacheren Konvertierung verfügen.
Ich konnte sie speichern, nachdem ich den Instruktionen aus ihrer Dokumentation gefolgt war. Ich habe mir aber nicht die Mühe gemacht, den Großteil des Codes zu verstehen.
from onnx.helper import get_attribute_value import onnxruntime as rt from skl2onnx import convert_sklearn, update_registered_converter from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost import CatBoostClassifier from catboost.utils import convert_to_onnx_object def skl2onnx_parser_castboost_classifier(scope, model, inputs, custom_parsers=None): options = scope.get_options(model, dict(zipmap=True)) no_zipmap = isinstance(options["zipmap"], bool) and not options["zipmap"] alias = _get_sklearn_operator_name(type(model)) this_operator = scope.declare_local_operator(alias, model) this_operator.inputs = inputs label_variable = scope.declare_local_variable("label", Int64TensorType()) prob_dtype = guess_tensor_type(inputs[0].type) probability_tensor_variable = scope.declare_local_variable( "probabilities", prob_dtype ) this_operator.outputs.append(label_variable) this_operator.outputs.append(probability_tensor_variable) probability_tensor = this_operator.outputs if no_zipmap: return probability_tensor return _apply_zipmap( options["zipmap"], scope, model, inputs[0].type, probability_tensor ) def skl2onnx_convert_catboost(scope, operator, container): """ CatBoost returns an ONNX graph with a single node. This function adds it to the main graph. """ onx = convert_to_onnx_object(operator.raw_operator) opsets = {d.domain: d.version for d in onx.opset_import} if "" in opsets and opsets[""] >= container.target_opset: raise RuntimeError("CatBoost uses an opset more recent than the target one.") if len(onx.graph.initializer) > 0 or len(onx.graph.sparse_initializer) > 0: raise NotImplementedError( "CatBoost returns a model initializers. This option is not implemented yet." ) if ( len(onx.graph.node) not in (1, 2) or not onx.graph.node[0].op_type.startswith("TreeEnsemble") or (len(onx.graph.node) == 2 and onx.graph.node[1].op_type != "ZipMap") ): types = ", ".join(map(lambda n: n.op_type, onx.graph.node)) raise NotImplementedError( f"CatBoost returns {len(onx.graph.node)} != 1 (types={types}). " f"This option is not implemented yet." ) node = onx.graph.node[0] atts = {} for att in node.attribute: atts[att.name] = get_attribute_value(att) container.add_node( node.op_type, [operator.inputs[0].full_name], [operator.outputs[0].full_name, operator.outputs[1].full_name], op_domain=node.domain, op_version=opsets.get(node.domain, None), **atts, ) update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, skl2onnx_convert_catboost, parser=skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, )
Nachfolgend sehen Sie die Konvertierung des endgültigen Modells und das Speichern mit der Dateierweiterung .onnx.
model_onnx = convert_sklearn( pipe, "pipeline_catboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("CatBoost.EURUSD.OHLC.D1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Bei der Visualisierung in Netron sieht die Modellstruktur genauso aus wie bei XGBoost und LightGBM.

Dies ist sinnvoll, da es sich um einen weiteren Gradient Boosted Decision Tree handelt. Sie haben im Wesentlichen ähnliche Strukturen.
Als ich versuchte, das CatBoost-Modell in einer Pipeline in ONNX mit kategorialen Variablen zu konvertieren, schlug der Prozess fehl und verursachte einen Fehler.
CatBoostError: catboost/libs/model/model_export/model_exporter.cpp:96: ONNX-ML format export does yet not support categorical features
Ich musste sicherstellen, dass die kategorischen Variablen im Typ float64 (double) waren, so wie wir sie ursprünglich in MetaTrader 5 gesammelt haben. Dies behebt den Fehler und hilft bei der Arbeit mit diesem Modell in MQL5, dass wir uns keine Sorgen über die Vermischung von Double- oder Float-Werten mit ganzen Zahlen machen müssen.
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"] # Remove these two lines of code operations # X_train[categorical_features] = X_train[categorical_features].astype(str) # X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
Trotz dieser Änderung war das CatBoost-Modell davon nicht betroffen (es lieferte die gleichen Genauigkeitswerte), da es mit Datensätzen unterschiedlicher Art arbeiten kann.
Erstellen eines CatBoost Expert Advisors (Handelsroboter)
Wir können damit beginnen, das ONNX-Modell als Ressource in den Haupt-Expert Advisor einzubetten.
MQL5-Code
#resource "\\Files\\CatBoost.EURUSD.OHLC.D1.onnx" as uchar catboost_onnx[]
Wir importieren die Bibliothek zum Laden des CatBoost-Modells.
#include <MALE5\Gradient Boosted Decision Trees(GBDTs)\CatBoost\CatBoost.mqh>
CCatBoost cat_boost;
Wir müssen die Daten auf die gleiche Weise sammeln, wie wir die Trainingsdaten in der OnTick-Funktion gesammelt haben.
void OnTick() { ... ... ... if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar ... ... ... }
So erhalten wir schließlich das vorhergesagte Signal und den Wahrscheinlichkeitsvektor zwischen der bärischen Signalklasse 0 und der bullischen Signalklasse 1.
vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal);
Wir können diesen EA abschließen, indem wir eine Handelsstrategie kodieren, die auf den Vorhersagen des Modells basiert.
Die Strategie ist einfach: Wenn das Modell ein Kaufsignal vorhersagt, kaufen wir und schließen einen Verkaufsposition, wenn es eine solche gibt. Wir tun das Gegenteil, wenn das Modell ein Abwärtssignal vorhersagt.
void OnTick() { //--- if (!NewBar()) return; //--- Trade at the opening of each bar if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(min_lot, Symbol(), ticks.ask, 0, 0); //Open a buy trade ClosePosition(POSITION_TYPE_SELL); //close the opposite trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(min_lot, Symbol(), ticks.bid, 0, 0); //open a sell trade ClosePosition(POSITION_TYPE_BUY); //close the opposite trade } }
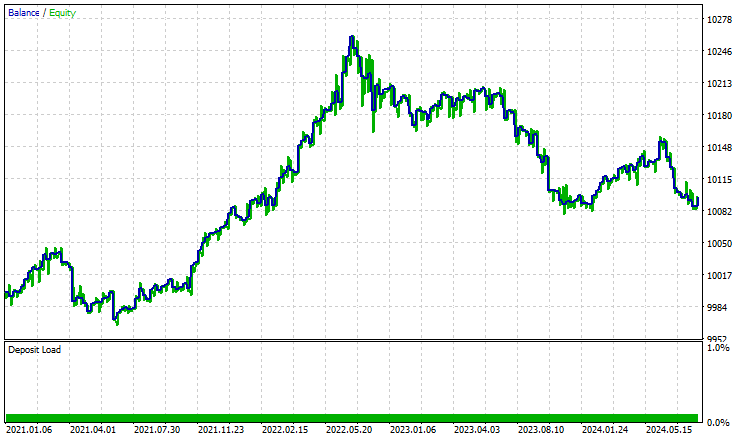
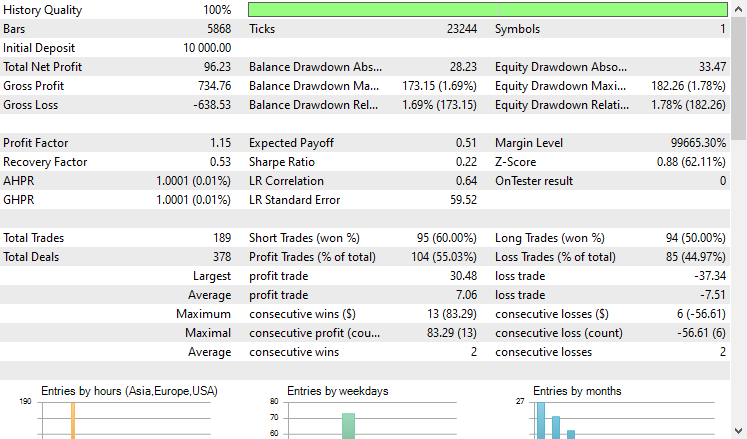
Ich habe einen Test mit dem Strategy Tester vom 2021.01.01 bis 2024.10.8 auf einem 4-Stunden-Zeitrahmen durchgeführt, wobei die Modellierung auf „Nur offene Preise" eingestellt war. Nachstehend das Ergebnis.
 '
'
Der EA schlug sich, gelinde gesagt, gut und lieferte 55% profitable Handelsgeschäfte, die einen Gesamtnettogewinn von $96 USD erbrachten. Nicht schlecht für einen einfachen Datensatz, ein einfaches Modell und ein minimales Handelsvolumen.
Abschließende Überlegungen
CatBoost und andere Gradient-Boost-Entscheidungsbäume sind die ideale Lösung, wenn Sie in einer Umgebung mit begrenzten Ressourcen arbeiten und ein Modell suchen, das „einfach funktioniert“, ohne dass Sie sich mit den langweiligen und manchmal unnötigen Dingen beschäftigen müssen, die beim Feature-Engineering und der Modellkonfiguration anfallen, wenn Sie mit zahlreichen Maschinenmodellen arbeiten.
Trotz ihrer Einfachheit und der geringen Einstiegshürde gehören sie zu den besten und effektivsten KI-Modellen, die in vielen realen Anwendungen eingesetzt werden.
Mit freundlichen Grüßen.
Verfolgen Sie die Entwicklung von Modellen für maschinelles Lernen und vieles mehr in dieser Artikelserie auf diesem GitHub repo.
Tabelle der Anhänge
Dateiname | Dateityp | Beschreibung und Verwendung |
|---|---|---|
Experts\CatBoost EA.mq5 | Expert Advisor | Handelsroboter zum Laden des Catboost-Modells im ONNX-Format und Testen der Handelsstrategie im MetaTrader 5. |
Include\CatBoost.mqh | #include-Datei |
|
Files\ CatBoost.EURUSD.OHLC.D1.onnx | ONNX-Modell | Trainiertes CatBoost-Modell, gespeichert im ONNX-Format. |
| Skripte\CollectData.mq5 | MQL5-Skript | Ein Skript zur Erfassung der Trainingsdaten. |
Jupyter Notebook\CatBoost-4-trading.ipynb | Python/Jupyter notebook | Der gesamte Python-Code, der in diesem Artikel besprochen wird, ist in diesem notebook zu finden. |
Quellen und Referenzen
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/16017
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Der Body im Connexus (Teil 4): Hinzufügen des HTTP-Hauptteils
Der Body im Connexus (Teil 4): Hinzufügen des HTTP-Hauptteils
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
und es gibt auch das Problem des Exports des Klassifizierungsmodells nach ONNX
Hinweis
Bei der binären Klassifizierung wird das Label falsch abgeleitet. Dies ist ein bekannter Fehler in der onnxruntime-Implementierung. Ignorieren Sie den Wert dieses Parameters im Falle einer binären Klassifizierung.
Ich habe eine kleine Frage oder Sorge, die ich gerne teilen möchte.
Ich glaube, das zugrunde liegende Problem könnte mit dem hier beschriebenen zusammenhängen:
https://catboost.ai/docs/en/concepts/apply-onnx-ml
Besonderheiten:
Derzeit werden nur Modelle unterstützt, die auf Datensätzen ohne kategoriale Merkmale trainiert wurden.
Im Jupyter-Notizbuch catboost-4-trading.ipynb, das ich heruntergeladen habe, ist der Code zur Anpassung der Pipeline wie folgt geschrieben:
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
Es scheint, dass der Parameter"catboost__cat_features=categorical_features" weggelassen wurde, so dass das Modell möglicherweise ohne Angabe von kategorischen Merkmalen trainiert wurde.
Dies könnte erklären, warum das Modell ohne Probleme als ONNX gespeichert werden konnte.
Wenn dies der Fall ist, dann könnte vielleicht die CatBoost-eigene Methode"save_model" direkt verwendet werden, so wie hier:
model = pipe.named_steps['catboost']
model_filename = "CatBoost.EURUSD.OHLC.D1.onnx"
model.save_model(model_filename, format='onnx')
Ich hoffe, dass diese Beobachtung hilfreich sein könnte.