
数据科学和机器学习(第 31 部分):利用 CatBoost AI 模型进行交易

“CatBoost 是一个梯度增强库,它是如此与众不同,以高效、且可扩展的方式处理分类特征,为许多现世问题提供了显著的性能提升。”
— 安东尼·戈德布鲁姆(Anthony Goldbloom)。
什么是 CatBoost?
CatBoost 是一个基于决策树的梯度增强算法开源软件库,它专为解决机器学习中处理分类特征和数据的挑战而设计。
它由 Yandex 开发,并于 2017 年开源,阅读更多。
尽管与线性回归或 SVM 等机器学习技术相比,CatBoost 是最近推出的,但它在 AI 社区中获得广泛欢迎,并在如 Kaggle 这样的平台上爬升到最常用机器学习模型的榜首。
CatBoost 之所以获得如此多的关注,是因其自动处理数据集中分类特征的能力,这对许多机器学习算法来说颇具挑战性。
- 相比其它模型,Catboost 模型通常以最小的工作量提供更好的性能,即使按默认参数和设置,这些模型也能在准确性方面执行优良。
- 不同于需要领域知识进行编码、并令其工作的神经网络,CatBoost 的实现很简单。

本文假设您对机器学习、决策树、XGBoos、LightGBMt 和 ONNX 均有基本了解。
CatBoost 如何运作?
CatBoost 基于梯度增强算法,就像 “轻量梯度机器”(LightGBM)和 “极值梯度增强”(XGBoost)一样。它的工作原理是按顺序构建若干决策树模型,其中每个模型都建立在前一个模型的基础上,因其试图纠正之前模型的误差。
最终预测是把该过程中所涉及的全部模型所做预测的加权合计。
这些梯度增强决策树(GBDT)的意向是把损失函数最小化,而这是通过添加一个新模型来纠正之前模型的误差来实现的。
处理分类特征
正如我早前所解释,CatBoost 能处理分类特征,无需其它机器学习模型所需的显式编码,像是独热编码、或标签编码,这是因为 CatBoost 为分类特征引入了基于目标的编码。
计算每个分类特征值的目标条件分布来执行编码。
CatBoost 中的另一个关键创新就是在计算分类特征的统计数据时使用有序增强。这种有序增强可确保任何实例的编码都基于以前所观察数据点的信息。
这有助于避免数据泄漏,及避免过度拟合。
它使用对称决策树结构
不同于使用非对称树的 LightGBM 和 XGBoost,CatBoost 使用对称决策树进行决策过程。在对称树中,每个切分处的左右分支构造都是基于相同的切分规则,这种方式有若干优点,例如:
- 它可以加快训练速度,因为两个切分是对称的。
- 由于树结构更简单,因此内存使用效率更高。
- 对称树针对数据中的小扰动更可靠。
CatBoost 对比 XGBoost 和 LightGBM,详细比较
我们了解 CatBoost 与其它梯度增强决策树有何不同。我们了解这三者之间的区别,这样我们就知道何时使用这三者之一,何时不用。
层面 | CatBoost | LightGBM | XGBoost |
|---|---|---|---|
分类特征处理 | 依据自动编码和有序增强,来处理分类变量。 | 需要手工编码处理,诸如独热编码、标签编码、等等。 | 需要手工编码处理,诸如独热编码、标签编码、等等。 |
决策树结构 | 它具有对称决策树,且是平衡的、并均匀增长。它们可确保更快的预测、和更低的过拟合风险。 | 它有一个逐叶生长策略(不对称),其专注于损失最大的叶片。这种结果出现在深度和不平衡的树,其能运营更高的精度,但过拟合的风险更大。 | 它有一个“级别增长策略”(非对称),树的增长基于每个节点的最佳切分。这会导致预测灵活,但速度较慢,且存在过度拟合的潜在风险。 |
模型准确性 | 在处理包含许多分类特征的数据集时,因为有序增强、并降低了对较小数据进行过度拟合的风险,它们提供了良好的准确性。 | 特别是在大型和高维数据集上,因为逐叶生长策略专注于提升高误差区域的性能,故它们提供了良好的准确性。 | 它们能在大多数数据集上提供良好的准确性,但由于 LightGBM 的树生长策略不那么激进,因此在分类数据集上往往优于 CatBoost,在非常大的数据集上表现优于 LightGBM。 |
训练速度和准确性 | 通常比 LightGBM 训练慢,但在中小型数据集上效率更高,尤其是在涉及分类特征时。 | 通常是这三者中最快的,尤其是在大型数据集上,因为它的叶状树生长在高维数据中效率更高。 | 通常是这三个中最慢的。它对于大型数据集非常有效。 |
部署 CatBoost 模型
在我们为 CatBoost 编写代码之前,我们创建一个问题场景。我们想用数据来预测交易信号(Buy/Sell);开盘价、最高价、最低价、收盘价和几个分类特征,例如日期(即当前日期)、星期几(从星期一到星期日)、一年中的日期(从 1 到 365)、和月份(从 1 月到 12 月)。
OHLC(开盘价,最高价,最低价,收盘价)值是连续特征,而其余值是分类特征。收集数据的脚本位于附件之中。
在安装之后,我们首先导入 CatBoost 模型。
安装
命令行
pip install catboost
导入。
Python 代码
import numpy as np import pandas as pd import catboost from catboost import CatBoostClassifier from sklearn.pipeline import Pipeline from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report import seaborn as sns import matplotlib.pyplot as plt sns.set_style("darkgrid")
我们能可视化数据,看看它的全部内容。
df = pd.read_csv("/kaggle/input/ohlc-eurusd/EURUSD.OHLC.PERIOD_D1.csv")
df.head()成果
| 开盘价 | 最高价 | 最低价 | 收盘价 | 月内日期 | 周内日期 | 年内日期 | 月 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 |
在 MQL5 脚本中收集数据时,我把获取的 DayofWeek(周一至周日)、和 Month(1 月 - 12 月)值以整数取代字符,因为我要把它们存储在矩阵中,故不允许我添加字符串,尽管它们本质上是分类变量,但现在它们还不是,故我们要再次将它们转换为分类,看看 CatBoost 如何处理它们。
我们准备目标变量。
Python 代码
new_df = df.copy() # Create a copy of the original DataFrame # we Shift the 'Close' and 'open' columns by one row to ge the future close and open price values, then we add these new columns to the dataset new_df["target_close"] = df["Close"].shift(-1) new_df["target_open"] = df["Open"].shift(-1) new_df = new_df.dropna() # Drop the rows with NaN values resulting from the shift operation open_values = new_df["target_open"] close_values = new_df["target_close"] target = [] for i in range(len(open_values)): if close_values[i] > open_values[i]: target.append(1) # buy signal else: target.append(0) # sell signal new_df["signal"] = target # we create the signal column and add the target variable we just prepared print(new_df.shape) new_df.head()
成果
| 开盘价 | 最高价 | 最低价 | 收盘价 | 月内日期 | 周内日期 | 年内日期 | 月 | target_close | target_open | 信号 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 | 21.0 | 3.0 | 264.0 | 9.0 | 1.09399 | 1.09678 | 0 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 | 22.0 | 4.0 | 265.0 | 9.0 | 1.09805 | 1.09701 | 1 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 | 23.0 | 5.0 | 266.0 | 9.0 | 1.09742 | 1.09639 | 1 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 | 26.0 | 1.0 | 269.0 | 9.0 | 1.09757 | 1.10302 | 0 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 | 27.0 | 2.0 | 270.0 | 9.0 | 1.10297 | 1.10431 | 0 |
现在我们有了可以预测的信号,我们将数据拆分为训练样本和测试样本。
X = new_df.drop(columns = ["target_close", "target_open", "signal"]) # we drop future values y = new_df["signal"] # trading signals are the target variables we wanna predict X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42)
我们定义了一份列表,列举数据集中存在的分类特征。
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"]
然后,我们能用该列表将这些分类特征转换为字符串格式,因为分类变量通常采用字符串格式。
X_train[categorical_features] = X_train[categorical_features].astype(str) X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
成果
<class 'pandas.core.frame.DataFrame'> Index: 6999 entries, 9068 to 7270 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Open 6999 non-null float64 1 High 6999 non-null float64 2 Low 6999 non-null float64 3 Close 6999 non-null float64 4 Day 6999 non-null object 5 DayofWeek 6999 non-null object 6 DayofYear 6999 non-null object 7 Month 6999 non-null object dtypes: float64(4), object(4) memory usage: 492.1+ KB
现在,我们有了含有对象数据类型的分类变量,其数据类型是字符串数据类型。如果您尝试将此数据用于 CatBoost 以外的机器学习模型,则会出现错误,因为典型的机器学习训练数据中不允许使用这样的对象数据类型。
训练 CatBoost 模型
在调用负责训练 CatBoost 模型的 fit 方法之前,我们先了解一些该模型正常运行的众多参数。
参数 | 说明 |
|---|---|
Iterations迭代 | 这是要构建的决策树迭代数。 迭代次数越多,性能越好,但也存在过度拟合的风险。 |
learning_rate | 该因子控制每棵树到最终预测的分布。 较小的学习率需要更多的迭代才能令树收敛,但通常会产生更好的模型。 |
depth | 这是树的最大深度。 较深的树可在数据中捕获更复杂的形态,但通常可能导致过度拟合。 |
cat_features | 这是分类索引的列表。 尽管 CatBoost 模型能够检测分类特征,但最好明确指示模型的哪些特征是分类特征。 这有助于模型从人类的角度理解分类特征,因为自动检测分类变量的方法有时会失败。 |
l2_leaf_reg | 这是 L2 正则化系数。 它有助于通过惩罚较大的叶片权重来防止过度拟合。 |
border_count | 这是每个分类特征的切分数量。该数字越高,性能越好,并增加计算时间。 |
eval_metric | 这是训练期间将用到的评估量值。 它有助于有效地监控模型性能。 |
early_stopping_rounds | 当往模型提供验证数据时,如果在该轮数内未观察到模型准确性的提高,则训练进度将停止。 该参数有助于减少过拟合,并可节省大量训练时间。 |
我们可为上述参数定义一个字典。
params = dict( iterations=100, learning_rate=0.01, depth=10, l2_leaf_reg=5, bagging_temperature=1, border_count=64, # Number of splits for categorical features eval_metric='Logloss', random_seed=42, # Seed for reproducibility verbose=1, # Verbosity level # early_stopping_rounds=10 # Early stopping for validation )
最后,我们可在 Sklearn 管道中定义 Catboost 模型,然后调用 fit 方法进行训练,给出该方法评估数据和分类特征列表。
pipe = Pipeline([ ("catboost", CatBoostClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test), catboost__cat_features=categorical_features)
输出
90: learn: 0.6880592 test: 0.6936112 best: 0.6931239 (3) total: 523ms remaining: 51.7ms 91: learn: 0.6880397 test: 0.6936100 best: 0.6931239 (3) total: 529ms remaining: 46ms 92: learn: 0.6880350 test: 0.6936051 best: 0.6931239 (3) total: 532ms remaining: 40ms 93: learn: 0.6880280 test: 0.6936103 best: 0.6931239 (3) total: 535ms remaining: 34.1ms 94: learn: 0.6879448 test: 0.6936110 best: 0.6931239 (3) total: 541ms remaining: 28.5ms 95: learn: 0.6878328 test: 0.6936387 best: 0.6931239 (3) total: 547ms remaining: 22.8ms 96: learn: 0.6877888 test: 0.6936473 best: 0.6931239 (3) total: 553ms remaining: 17.1ms 97: learn: 0.6877408 test: 0.6936508 best: 0.6931239 (3) total: 559ms remaining: 11.4ms 98: learn: 0.6876611 test: 0.6936708 best: 0.6931239 (3) total: 565ms remaining: 5.71ms 99: learn: 0.6876230 test: 0.6936898 best: 0.6931239 (3) total: 571ms remaining: 0us bestTest = 0.6931239281 bestIteration = 3 Shrink model to first 4 iterations.
评估模型
我们可用 Sklearn 量值来评估该模型的性能。
# Make predicitons on training and testing sets y_train_pred = pipe.predict(X_train) y_test_pred = pipe.predict(X_test) # Training set evaluation print("Training Set Classification Report:") print(classification_report(y_train, y_train_pred)) # Testing set evaluation print("\nTesting Set Classification Report:") print(classification_report(y_test, y_test_pred))
输出
Training Set Classification Report: precision recall f1-score support 0 0.55 0.44 0.49 3483 1 0.54 0.64 0.58 3516 accuracy 0.54 6999 macro avg 0.54 0.54 0.54 6999 weighted avg 0.54 0.54 0.54 6999 Testing Set Classification Report: precision recall f1-score support 0 0.53 0.41 0.46 1547 1 0.49 0.61 0.54 1453 accuracy 0.51 3000 macro avg 0.51 0.51 0.50 3000 weighted avg 0.51 0.51 0.50 3000
成果是一个性能一般的模型。我意识到,在删除分类特征列表后,模型准确率在训练集上上升到 60%,但在测试集中保持不变。
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
成果
91: learn: 0.6844878 test: 0.6933503 best: 0.6930500 (30) total: 395ms remaining: 34.3ms 92: learn: 0.6844035 test: 0.6933539 best: 0.6930500 (30) total: 399ms remaining: 30ms 93: learn: 0.6843241 test: 0.6933791 best: 0.6930500 (30) total: 404ms remaining: 25.8ms 94: learn: 0.6842277 test: 0.6933732 best: 0.6930500 (30) total: 408ms remaining: 21.5ms 95: learn: 0.6841427 test: 0.6933758 best: 0.6930500 (30) total: 412ms remaining: 17.2ms 96: learn: 0.6840422 test: 0.6933796 best: 0.6930500 (30) total: 416ms remaining: 12.9ms 97: learn: 0.6839896 test: 0.6933825 best: 0.6930500 (30) total: 420ms remaining: 8.58ms 98: learn: 0.6839040 test: 0.6934062 best: 0.6930500 (30) total: 425ms remaining: 4.29ms 99: learn: 0.6838397 test: 0.6934259 best: 0.6930500 (30) total: 429ms remaining: 0us bestTest = 0.6930499562 bestIteration = 30 Shrink model to first 31 iterations.
Training Set Classification Report: precision recall f1-score support 0 0.61 0.53 0.57 3483 1 0.59 0.67 0.63 3516 accuracy 0.60 6999 macro avg 0.60 0.60 0.60 6999 weighted avg 0.60 0.60 0.60 6999
为了更详尽地理解这个模型,我们来创建特征重要性图板。
# Extract the trained CatBoostClassifier from the pipeline
catboost_model = pipe.named_steps['catboost']
# Get feature importances
feature_importances = catboost_model.get_feature_importance()
feature_im_df = pd.DataFrame({
"feature": X.columns,
"importance": feature_importances
})
feature_im_df = feature_im_df.sort_values(by="importance", ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(data = feature_im_df, x='importance', y='feature', palette="viridis")
plt.title("CatBoost feature importance")
plt.xlabel("Importance")
plt.ylabel("feature")
plt.show()输出:
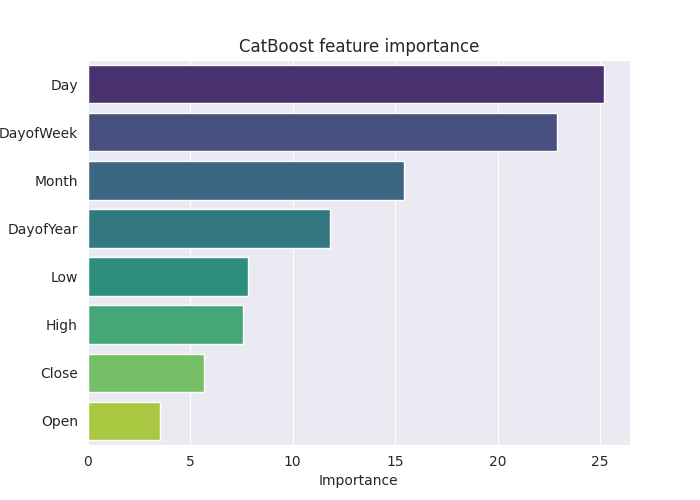
上面的 “特征重要性图板” 说出了模型如何做出决策的整个故事。CatBoost 模型似乎认为分类变量比连续变量对模型的最终预测结果影响最大。
将 CatBoost 模型保存为 ONNX
为了在 MetaTrader 5 中使用该模型,我们必须将其保存为 ONNX 格式。现在保存 CatBoost 模型可能有点棘手,不像 Sklearn 和 Keras 模型,它们的方法更容易转换。
按照文档中的说明操作,我已能够保存它。我对理解大部分代码没有耐心。
from onnx.helper import get_attribute_value import onnxruntime as rt from skl2onnx import convert_sklearn, update_registered_converter from skl2onnx.common.shape_calculator import ( calculate_linear_classifier_output_shapes, ) # noqa from skl2onnx.common.data_types import ( FloatTensorType, Int64TensorType, guess_tensor_type, ) from skl2onnx._parse import _apply_zipmap, _get_sklearn_operator_name from catboost import CatBoostClassifier from catboost.utils import convert_to_onnx_object def skl2onnx_parser_castboost_classifier(scope, model, inputs, custom_parsers=None): options = scope.get_options(model, dict(zipmap=True)) no_zipmap = isinstance(options["zipmap"], bool) and not options["zipmap"] alias = _get_sklearn_operator_name(type(model)) this_operator = scope.declare_local_operator(alias, model) this_operator.inputs = inputs label_variable = scope.declare_local_variable("label", Int64TensorType()) prob_dtype = guess_tensor_type(inputs[0].type) probability_tensor_variable = scope.declare_local_variable( "probabilities", prob_dtype ) this_operator.outputs.append(label_variable) this_operator.outputs.append(probability_tensor_variable) probability_tensor = this_operator.outputs if no_zipmap: return probability_tensor return _apply_zipmap( options["zipmap"], scope, model, inputs[0].type, probability_tensor ) def skl2onnx_convert_catboost(scope, operator, container): """ CatBoost returns an ONNX graph with a single node. This function adds it to the main graph. """ onx = convert_to_onnx_object(operator.raw_operator) opsets = {d.domain: d.version for d in onx.opset_import} if "" in opsets and opsets[""] >= container.target_opset: raise RuntimeError("CatBoost uses an opset more recent than the target one.") if len(onx.graph.initializer) > 0 or len(onx.graph.sparse_initializer) > 0: raise NotImplementedError( "CatBoost returns a model initializers. This option is not implemented yet." ) if ( len(onx.graph.node) not in (1, 2) or not onx.graph.node[0].op_type.startswith("TreeEnsemble") or (len(onx.graph.node) == 2 and onx.graph.node[1].op_type != "ZipMap") ): types = ", ".join(map(lambda n: n.op_type, onx.graph.node)) raise NotImplementedError( f"CatBoost returns {len(onx.graph.node)} != 1 (types={types}). " f"This option is not implemented yet." ) node = onx.graph.node[0] atts = {} for att in node.attribute: atts[att.name] = get_attribute_value(att) container.add_node( node.op_type, [operator.inputs[0].full_name], [operator.outputs[0].full_name, operator.outputs[1].full_name], op_domain=node.domain, op_version=opsets.get(node.domain, None), **atts, ) update_registered_converter( CatBoostClassifier, "CatBoostCatBoostClassifier", calculate_linear_classifier_output_shapes, skl2onnx_convert_catboost, parser=skl2onnx_parser_castboost_classifier, options={"nocl": [True, False], "zipmap": [True, False, "columns"]}, )
下面是模型的最终转换,并将其保存为 .onnx 文件扩展名。
model_onnx = convert_sklearn( pipe, "pipeline_catboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("CatBoost.EURUSD.OHLC.D1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
在 Netron 中可视化时,模型结构看起来与 XGBoost 和 LightGBM 相同。

这是有意义的,因为它只是另一棵梯度增强决策树。它们的核心结构相似。
当我尝试将管道中的 CatBoost 模型转换为具有分类变量的 ONNX 时,该过程失败,并引发错误。
CatBoostError: catboost/libs/model/model_export/model_exporter.cpp:96: ONNX-ML format export does yet not support categorical features
我必须确保分类变量是 float64(双精度)类型,就像我们最初在 MetaTrader 5 中收集它们一样,这可修复错误,并有助于在 MQL5 中与该模型打交道,我们不必担心将双精度或浮点值与整数混合。
categorical_features = ["Day","DayofWeek", "DayofYear", "Month"] # Remove these two lines of code operations # X_train[categorical_features] = X_train[categorical_features].astype(str) # X_test[categorical_features] = X_test[categorical_features].astype(str) X_train.info() # we print the data types now
尽管如此修改,但 CatBoost 模型并未受到影响(提供相同的准确率值),因为它可处理各种性质的数据集。
创建 CatBoost 智能交易系统(交易机器人)
我们可先将 ONNX 模型作为资源嵌入到主智能系统当中。
MQL5 代码
#resource "\\Files\\CatBoost.EURUSD.OHLC.D1.onnx" as uchar catboost_onnx[]
我们导入加载 CatBoost 模型的函数库。
#include <MALE5\Gradient Boosted Decision Trees(GBDTs)\CatBoost\CatBoost.mqh>
CCatBoost cat_boost;
我们必须按照在 OnTick 函数中收集训练数据的相同方式收集数据。
void OnTick() { ... ... ... if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar ... ... ... }
然后,我们最终可获得预测信号和熊市信号类别 0、与牛市信号类别 1 之间的概率向量。
vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal);
我们可据从模型获得的预测编写交易策略来包装这个 EA。
策略很简单,当模型预测到看涨信号时,我们买入并把做空交易(如果存在)平仓。当模型预测看跌信号时,我们反向行事。
void OnTick() { //--- if (!NewBar()) return; //--- Trade at the opening of each bar if (CopyRates(Symbol(), timeframe, 1, 1, rates) < 0) //Copy information from the previous bar { printf("Failed to obtain OHLC price values error = ",GetLastError()); return; } MqlDateTime time_struct; string time = (string)datetime(rates[0].time); //converting the date from seconds to datetime then to string TimeToStruct((datetime)StringToTime(time), time_struct); //converting the time in string format to date then assigning it to a structure vector x = {rates[0].open, rates[0].high, rates[0].low, rates[0].close, time_struct.day, time_struct.day_of_week, time_struct.day_of_year, time_struct.mon}; //input features from the previously closed bar vector proba = cat_boost.predict_proba(x); //predict the probability between the classes long signal = cat_boost.predict_bin(x); //predict the trading signal class Comment("Predicted Probability = ", proba,"\nSignal = ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(min_lot, Symbol(), ticks.ask, 0, 0); //Open a buy trade ClosePosition(POSITION_TYPE_SELL); //close the opposite trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(min_lot, Symbol(), ticks.bid, 0, 0); //open a sell trade ClosePosition(POSITION_TYPE_BUY); //close the opposite trade } }
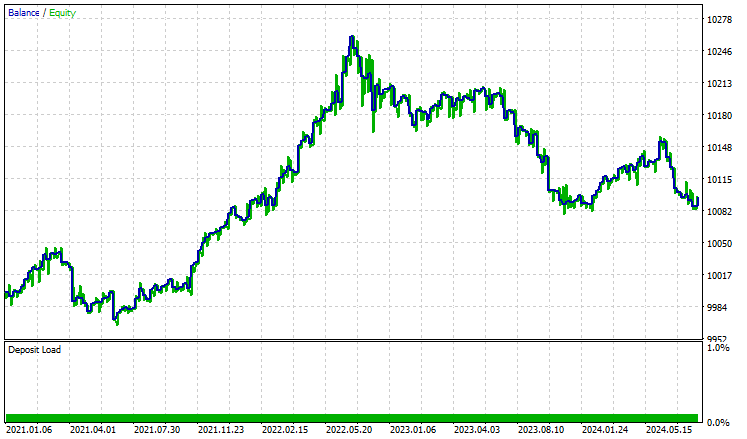
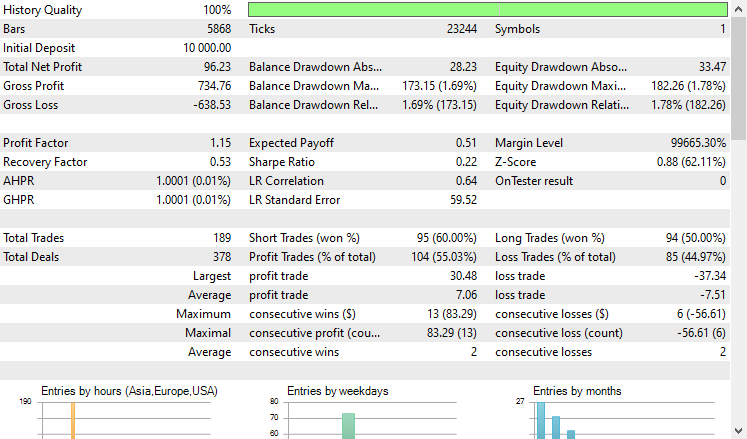
我在策略测试器上据 2021.01.01 到 2024.10.8、H4 时间帧进行了测试,建模设置为“仅开盘价”。下面是成果
 '
'
EA 做得很好,至少可以说,提供了 55% 的盈利交易,提供了总共 96 美元的净盈利。对于简单的数据集、简单的模型、和最小的交易量设置来说,这还不错。
后记
当您在有限的资源环境中工作,并寻找一个 “正常工作 ”的模型时,CatBoost 和其它梯度增强决策树是首选解决方案,无需被迫去做很多无聊的、有时是不必要的工作,而这些涉及我们在处理大量机器模型时经常面临的特征工程和模型配置。
尽管它们简单、且入场门槛最小,但它们是在许多实际应用中能用的最好、及最有效的 AI 模型之一。
此致敬意。
跟踪机器学习模型的开发,在 GitHub 存储库 上有更多本系列文章的讨论内容。
附件表
文件名 | 文件类型 | 说明/用法 |
|---|---|---|
Experts\CatBoost EA.mq5 | 智能系统 | 交易机器人,以 ONNX 格式加载 Catboost 模型,并在 MetaTrader 5 中测试交易策略。 |
Include\CatBoost.mqh | 包含文件 |
|
Files\ CatBoost.EURUSD.OHLC.D1.onnx | ONNX 模型 | 以 ONNX 格式保存的经训练的 CatBoost 模型。 |
| MQL5 脚本 | MQL5 脚本 | 收集训练数据的脚本。 |
Jupyter Notebook\CatBoost-4-trading.ipynb | Python/Jupyter 笔记簿 | 本文中讨论的所有 Python 代码都可在该笔记簿中找到。 |
源码 & 参考
- 机器学习中的 CatBoost:详细指南
CatBoost - 新一代梯度提升 - Anna Veronika Dorogush
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/16017
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

还有将分类器模型导出到 ONNX 的问题
注释
二进制分类的标签推断不正确。这是 onnxruntime 实现中的一个已知错误。如果是二进制分类,请忽略此参数的值。
我有一个小问题或顾虑,希望与大家分享。
我认为根本问题可能与此处描述的内容有关:
https://catboost.ai/docs/en/concepts/apply-onnx-ml
具体问题:
目前只支持在无分类特征的数据集上训练的模型。
在我下载的 Jupyter Notebook catboost-4-trading.ipynb 中,管道拟合代码是这样写的:
pipe.fit(X_train, y_train, catboost__eval_set=(X_test, y_test))
似乎省略了参数"catboost__cat_features=categorical_features",因此模型可能是在没有指定分类特征的情况下训练的。
这也许可以解释为什么模型可以顺利保存为 ONNX。
如果是这种情况,那么也许可以直接使用 CatBoost 原生方法"save_model" ,就像这样:
model = pipe.named_steps['catboost']
model_filename = "CatBoost.EURUSD.OHLC.D1.onnx"
model.save_model(model_filename, format='onnx')
希望我的看法对您有所帮助。