
Ciência de Dados e Aprendizado de Máquina (Parte 16): Uma nova perspectiva sobre árvores de decisão

Visão geral
Em um dos artigos anteriores desta série, falei sobre árvores de decisão. Aprendemos o que são árvores de decisão e criamos um algoritmo para classificar dados meteorológicos. Entretanto, o código e as explicações apresentados naquele artigo aparentemente não foram claros o suficiente, pois continuo recebendo mensagens solicitando uma abordagem mais eficaz para a construção de árvores de decisão. Por isso, achei que seria útil escrever um segundo artigo e fornecer um código de melhor qualidade. Além disso, um bom entendimento das árvores de decisão é muito importante para a transição para o próximo estágio — os algoritmos de floresta aleatória, que discutiremos nos próximos artigos.
O que é uma árvore de decisão?
Uma árvore de decisão é uma estrutura em forma de árvore, semelhante a um fluxograma, onde cada nó interno representa uma verificação de um atributo (ou característica), cada ramo representa o resultado da verificação e cada nó folha representa a classe ou valor contínuo. O nó mais alto em uma árvore de decisão é conhecido como "raiz", e as folhas são os resultados ou previsões.
O que é um nó?
Em uma árvore de decisão, um nó é um componente fundamental que representa um ponto de tomada de decisão baseado em uma característica ou atributo específico. Existem dois tipos principais de nós em uma árvore de decisão: internos e folhas.
Nó interno- Um nó interno é um ponto de tomada de decisão na árvore onde é realizada uma verificação de uma característica específica. A verificação é baseada em uma condição determinada, como se o valor da característica excede um valor limite ou se pertence a uma determinada categoria.
- Os nós internos têm ramos (arestas) que levam a nós filhos. O resultado da verificação determina qual ramo seguir.
- Os nós internos, que representam dois nós filhos à esquerda e à direita, são nós dentro do nó central da árvore.
- Um nó folha é o ponto final na árvore, onde é tomada a decisão final ou previsão. Ele indica a classe na tarefa de classificação ou o valor previsto na tarefa de regressão.
- Os nós folhas não têm ramos saindo deles, sendo os pontos finais do processo de tomada de decisão.
- No código, vamos representá-los por uma variável do tipo double.
class Node { public: // for decision node uint feature_index; double threshold; double info_gain; // for leaf node double leaf_value; Node *left_child; //left child Node Node *right_child; //right child Node Node() : left_child(NULL), right_child(NULL) {} // default constructor Node(uint feature_index_, double threshold_=NULL, Node *left_=NULL, Node *right_=NULL, double info_gain_=NULL, double value_=NULL) : left_child(left_), right_child(right_) { this.feature_index = feature_index_; this.threshold = threshold_; this.info_gain = info_gain_; this.value = value_; } void Print() { printf("feature_index: %d \nthreshold: %f \ninfo_gain: %f \nleaf_value: %f",feature_index,threshold, info_gain, value); } };
Ao contrário de alguns algoritmos de aprendizado de máquina que codificamos do zero nesta série, uma árvore de decisão pode ser complicada de representar em código e, por vezes, confusa, pois a implementação das árvores requer o uso de classes e funções recursivas. Por minha experiência, pode ser muito difícil representar isso em qualquer linguagem que não seja Python.
Componentes do nó:
Um nó em uma árvore de decisão geralmente contém as seguintes informações:
01. Condições de verificação
Os nós internos têm condições de verificação baseadas em uma característica específica e um valor limiar ou categoria. Essa condição determina como os dados são divididos nos nós filhos.
Node *build_tree(matrix &data, uint curr_depth=0);
02. Característica e valor limiar
Indica qual característica é verificada no nó, bem como o valor limiar ou a categoria usada para a divisão.
uint feature_index; double threshold;
03. Rótulo ou valor da classe
Um nó folha armazena o rótulo da classe prevista (para classificação) ou o valor (para regressão).
double leaf_value; 04. Nós filhos
Os nós internos têm nós filhos, correspondentes a diferentes resultados da condição de verificação. Cada nó filho representa um subconjunto de dados que satisfaz a condição.
Node *left_child; //left child Node Node *right_child; //right child Node
Exemplo:
Vamos considerar uma árvore de decisão simples para classificar se uma fruta é uma maçã ou uma laranja, com base em sua cor.
[Nó]
Característica: cor
Condição de verificação: a cor é vermelha?
Se True, seguimos para o nó filho esquerdo, e se False, para o nó filho direito.
[Nó folha — maçã]
-Rótulo da classe: maçã
[Nó folha — laranja]
-Rótulo da classe: laranja
Tipos de árvores de decisão:
CART (Classification and Regression Trees) — usadas tanto para tarefas de classificação quanto de regressão. Dividem os dados com base no critério de Gini para classificação e no erro quadrático médio para regressão.
ID3 (Iterative Dichotomiser 3) — usado principalmente para tarefas de classificação. Utiliza o conceito de entropia e ganho de informação para tomar decisões.
C4.5 — versão aprimorada do ID3, usada para classificação. Usa a razão de ganho para eliminar o viés em relação a atributos com muitos níveis.
Como vamos usar uma árvore de decisão para fins de classificação, construiremos o algoritmo ID3, que opera com base no ganho de informação, cálculo de critérios e características categóricas:
ID3 (Iterative Dichotomiser 3)
ID3 usa o critério de ganho de informação para escolher a melhor divisão dos dados em cada nó interno da árvore. O critério de ganho de informação mede a redução da entropia ou incerteza após a divisão do conjunto de dados.double CDecisionTree::information_gain(vector &parent, vector &left_child, vector &right_child) { double weight_left = left_child.Size() / (double)parent.Size(), weight_right = right_child.Size() / (double)parent.Size(); double gain =0; switch(m_mode) { case MODE_GINI: gain = gini_index(parent) - ( (weight_left*gini_index(left_child)) + (weight_right*gini_index(right_child)) ); break; case MODE_ENTROPY: gain = entropy(parent) - ( (weight_left*entropy(left_child)) + (weight_right*entropy(right_child)) ); break; } return gain; }
Entropia — medida de incerteza ou desordem em um conjunto de dados. O algoritmo ID3 busca reduzir a entropia, escolhendo divisões de características que resultem em subconjuntos com rótulos de classe mais homogêneos.
double CDecisionTree::entropy(vector &y) { vector class_labels = matrix_utils.Unique_count(y); vector p_cls = class_labels / double(y.Size()); vector entropy = (-1 * p_cls) * log2(p_cls); return entropy.Sum(); }
Para obter mais flexibilidade, pode-se escolher entre a entropia e o critério de Gini, que também é frequentemente usado em árvores de decisão e realiza a mesma função que a entropia. Ambos avaliam impurezas ou desordem em um conjunto de dados.
double CDecisionTree::gini_index(vector &y) { vector unique = matrix_utils.Unique_count(y); vector probabilities = unique / (double)y.Size(); return 1.0 - MathPow(probabilities, 2).Sum(); }
Fórmulas para calcular esses valores:
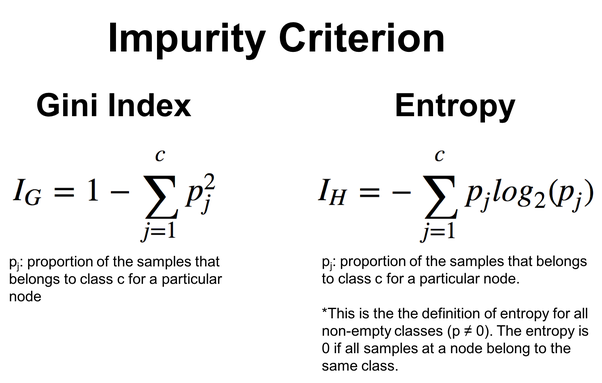
O algoritmo ID3 é especialmente adequado para características categóricas, e a escolha das características e dos valores de limiar é baseada na redução da entropia para a separação em categorias. Veremos esse princípio em ação com um exemplo de algoritmo de árvore de decisão abaixo.
Algoritmo da árvore de decisão
01. Critérios de divisão
Os critérios padrão para separar os dados durante a classificação são o índice de Gini e a entropia, enquanto para tarefas de regressão é o erro quadrático médio. Vamos focar nas funções de divisão do algoritmo da árvore de decisão, começando pela estrutura que armazena informações dos dados a serem divididos.
//A struct containing splitted data information struct split_info { uint feature_index; double threshold; matrix dataset_left, dataset_right; double info_gain; };
Usando um valor de limiar, dividimos os dados e colocamos os objetos com valores menores que esse limiar na matriz dataset_left, e os demais em dataset_right. Depois disso, retornamos uma instância da estrutura Split_info.
split_info CDecisionTree::split_data(const matrix &data, uint feature_index, double threshold=0.5) { int left_size=0, right_size =0; vector row = {}; split_info split; ulong cols = data.Cols(); split.dataset_left.Resize(0, cols); split.dataset_right.Resize(0, cols); for (ulong i=0; i<data.Rows(); i++) { row = data.Row(i); if (row[feature_index] <= threshold) { left_size++; split.dataset_left.Resize(left_size, cols); split.dataset_left.Row(row, left_size-1); } else { right_size++; split.dataset_right.Resize(right_size, cols); split.dataset_right.Row(row, right_size-1); } } return split; }
Dentre as diversas divisões, o algoritmo precisa determinar a melhor, ou seja, a que fornece o maior ganho de informação.
split_info CDecisionTree::get_best_split(matrix &data, uint num_features) { double max_info_gain = -DBL_MAX; vector feature_values = {}; vector left_v={}, right_v={}, y_v={}; //--- split_info best_split; split_info split; for (uint i=0; i<num_features; i++) { feature_values = data.Col(i); vector possible_thresholds = matrix_utils.Unique(feature_values); //Find unique values in the feature, representing possible thresholds for splitting. for (uint j=0; j<possible_thresholds.Size(); j++) { split = this.split_data(data, i, possible_thresholds[j]); if (split.dataset_left.Rows()>0 && split.dataset_right.Rows() > 0) { y_v = data.Col(data.Cols()-1); right_v = split.dataset_right.Col(split.dataset_right.Cols()-1); left_v = split.dataset_left.Col(split.dataset_left.Cols()-1); double curr_info_gain = this.information_gain(y_v, left_v, right_v); if (curr_info_gain > max_info_gain) // Check if the current information gain is greater than the maximum observed so far. { #ifdef DEBUG_MODE printf("split left: [%dx%d] split right: [%dx%d] curr_info_gain: %f max_info_gain: %f",split.dataset_left.Rows(),split.dataset_left.Cols(),split.dataset_right.Rows(),split.dataset_right.Cols(),curr_info_gain,max_info_gain); #endif best_split.feature_index = i; best_split.threshold = possible_thresholds[j]; best_split.dataset_left = split.dataset_left; best_split.dataset_right = split.dataset_right; best_split.info_gain = curr_info_gain; max_info_gain = curr_info_gain; } } } } return best_split; }
A função busca características comuns e valores de limiar possíveis para encontrar a melhor divisão, que maximiza o ganho de informação. O resultado é a estrutura split_info, contendo informações sobre o objeto, valor de limiar e subconjuntos relacionados à melhor divisão.
02. Construção da árvore
As árvores de decisão são construídas por meio da divisão recursiva do conjunto de dados com base nas características até que uma condição de parada seja atendida (por exemplo, alcançar uma profundidade específica ou número mínimo de amostras).
Node *CDecisionTree::build_tree(matrix &data, uint curr_depth=0) { matrix X; vector Y; matrix_utils.XandYSplitMatrices(data,X,Y); //Split the input matrix into feature matrix X and target vector Y. ulong samples = X.Rows(), features = X.Cols(); //Get the number of samples and features in the dataset. Node *node= NULL; // Initialize node pointer if (samples >= m_min_samples_split && curr_depth<=m_max_depth) { split_info best_split = this.get_best_split(data, (uint)features); #ifdef DEBUG_MODE Print("best_split left: [",best_split.dataset_left.Rows(),"x",best_split.dataset_left.Cols(),"]\nbest_split right: [",best_split.dataset_right.Rows(),"x",best_split.dataset_right.Cols(),"]\nfeature_index: ",best_split.feature_index,"\nInfo gain: ",best_split.info_gain,"\nThreshold: ",best_split.threshold); #endif if (best_split.info_gain > 0) { Node *left_child = this.build_tree(best_split.dataset_left, curr_depth+1); Node *right_child = this.build_tree(best_split.dataset_right, curr_depth+1); node = new Node(best_split.feature_index,best_split.threshold,left_child,right_child,best_split.info_gain); return node; } } node = new Node(); node.leaf_value = this.calculate_leaf_value(Y); return node; }
if (best_split.info_gain > 0):
A linha de código acima verifica se há ganho de informação.
Dentro desse bloco ocorre o seguinte:
Node *left_child = this.build_tree(best_split.dataset_left, curr_depth+1);
Criamos recursivamente o nó filho esquerdo.
Node *right_child = this.build_tree(best_split.dataset_right, curr_depth+1);
Criamos recursivamente o nó filho direito.
node = new Node(best_split.feature_index, best_split.threshold, left_child, right_child, best_split.info_gain);
Criamos um nó de decisão com informações da melhor divisão.
node = new Node(); Se não for necessária uma divisão adicional, criamos um novo nó folha.
node.value = this.calculate_leaf_value(Y); Definimos o valor do nó folha usando a função calculate_leaf_value.
return node; Retornamos o nó representando a divisão atual ou a folha.
Para facilitar o trabalho com as funções, a função build_tree pode ser deixada dentro da função fit, que é geralmente usada em módulos de aprendizado de máquina no Python.
void CDecisionTree::fit(matrix &x, vector &y) { matrix data = matrix_utils.concatenate(x, y, 1); this.root = this.build_tree(data); }
Fazemos previsões durante o treinamento e teste do modelo
vector CDecisionTree::predict(matrix &x) { vector ret(x.Rows()); for (ulong i=0; i<x.Rows(); i++) ret[i] = this.predict(x.Row(i)); return ret; }
Fazemos previsões em tempo real
double CDecisionTree::predict(vector &x) { return this.make_predictions(x, this.root); }
Todo o trabalho pesado é feito na função make_predictions:
double CDecisionTree::make_predictions(vector &x, const Node &tree) { if (tree.leaf_value != NULL) // This is a leaf leaf_value return tree.leaf_value; double feature_value = x[tree.feature_index]; double pred = 0; #ifdef DEBUG_MODE printf("Tree.threshold %f tree.feature_index %d leaf_value %f",tree.threshold,tree.feature_index,tree.leaf_value); #endif if (feature_value <= tree.threshold) { pred = this.make_predictions(x, tree.left_child); } else { pred = this.make_predictions(x, tree.right_child); } return pred; }
Mais detalhes sobre essa função:
if (feature_value <= tree.threshold): Dentro desse bloco ocorre o seguinte:
Chamamos recursivamente a função make_predictions para o nó filho esquerdo.
pred = this.make_predictions(x, *tree.left_child); Caso contrário, se (Else, If) o valor da característica for maior que o valor de limiar:
Chamamos recursivamente a função make_predictions para o nó filho direito.
pred = this.make_predictions(x, *tree.right_child); return pred; Retornamos a previsão.
Calculamos os valores da folha
A função abaixo calcula o valor da folha:
double CDecisionTree::calculate_leaf_value(vector &Y) { vector uniques = matrix_utils.Unique_count(Y); vector classes = matrix_utils.Unique(Y); return classes[uniques.ArgMax()]; }
A função retorna o elemento de Y com o maior número, ou seja, encontra o elemento mais comum na lista.
Tudo isso se resume à classe CDecisionTree.
enum mode {MODE_ENTROPY, MODE_GINI}; class CDecisionTree { CMatrixutils matrix_utils; protected: Node *build_tree(matrix &data, uint curr_depth=0); double calculate_leaf_value(vector &Y); //--- uint m_max_depth; uint m_min_samples_split; mode m_mode; double gini_index(vector &y); double entropy(vector &y); double information_gain(vector &parent, vector &left_child, vector &right_child); split_info get_best_split(matrix &data, uint num_features); split_info split_data(const matrix &data, uint feature_index, double threshold=0.5); double make_predictions(vector &x, const Node &tree); void delete_tree(Node* node); public: Node *root; CDecisionTree(uint min_samples_split=2, uint max_depth=2, mode mode_=MODE_GINI); ~CDecisionTree(void); void fit(matrix &x, vector &y); void print_tree(Node *tree, string indent=" ",string padl=""); double predict(vector &x); vector predict(matrix &x); };
Agora, vamos ver como tudo funciona na prática, como construir a árvore e como usá-la para previsão durante o treinamento e teste, bem como no trading em tempo real. Vamos trabalhar com a amostra de dados iris-CSV e testar o funcionamento da classe.
Treinaremos o modelo da árvore de decisão a cada inicialização do EA, começando com o carregamento dos dados de treinamento do arquivo CSV:
int OnInit() { matrix dataset = matrix_utils.ReadCsv("iris.csv"); //loading iris-data decision_tree = new CDecisionTree(3,3, MODE_GINI); //Initializing the decision tree matrix x; vector y; matrix_utils.XandYSplitMatrices(dataset,x,y); //split the data into x and y matrix and vector respectively decision_tree.fit(x, y); //Building the tree decision_tree.print_tree(decision_tree.root); //Printing the tree vector preds = decision_tree.predict(x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(y, preds)); //Measuring the accuracy return(INIT_SUCCEEDED); }
É assim que a matriz do conjunto de dados se vê na saída. A última coluna passou pelo codificador.aA última coluna foi passada por um codificador. Um (1) significa Setosa, dois (2) significa Versicolor e três (3) significa Virginica.
Print("iris-csv\n",dataset);
MS 0 08:54:40.958 DecisionTree Test (EURUSD,H1) iris-csv PH 0 08:54:40.958 DecisionTree Test (EURUSD,H1) [[5.1,3.5,1.4,0.2,1] CO 0 08:54:40.958 DecisionTree Test (EURUSD,H1) [4.9,3,1.4,0.2,1] ... ... NS 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [5.6,2.7,4.2,1.3,2] JK 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [5.7,3,4.2,1.2,2] ... ... NQ 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [6.2,3.4,5.4,2.3,3] PD 0 08:54:40.959 DecisionTree Test (EURUSD,H1) [5.9,3,5.1,1.8,3]]
Saída da árvore
Se observarmos atentamente o código, podemos notar a função print_tree, que aceita a raiz da árvore como um dos argumentos. Essa função tenta imprimir uma visão geral da árvore no log. Vamos olhar mais de perto seu funcionamento.
void CDecisionTree::print_tree(Node *tree, string indent=" ",string padl="") { if (tree.leaf_value != NULL) Print((padl+indent+": "),tree.leaf_value); else //if we havent' reached the leaf node keep printing child trees { padl += " "; Print((padl+indent)+": X_",tree.feature_index, "<=", tree.threshold, "?", tree.info_gain); print_tree(tree.left_child, "left","--->"+padl); print_tree(tree.right_child, "right","--->"+padl); } }
Mais detalhes sobre essa função:
Estrutura do nó:
A função assume que a classe Node representa a árvore de decisão. Cada nó pode ser um nó de decisão ou um nó terminal. Os nós de decisão têm índice de característica feature_index, limiar threshold, ganho de informação info_gain e valor da folha leaf_value.
Saída do nó de decisão:
Se o nó atual não for um nó terminal (ou seja, tree.leaf_value tem valor NULL), a função imprime informações sobre o nó de decisão. Imprime a condição para divisão, como "X_2 <= 1.9 ? 0.33" e o nível de indentação.
Saída do nó folha:
Se o nó atual for um nó folha (ou seja, tree.leaf_value não é NULL), imprime o valor final junto com o nível de indentação. Por exemplo, "left: 0.33".
Recursão:
A função então chama recursivamente a si mesma para o filho esquerdo e direito do nó atual Node. O argumento padl adiciona indentação à mensagem, tornando a estrutura em árvore mais legível.
Saída de print_tree para a árvore de decisão construída dentro da função OnInit:
CR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) : X_2<=1.9?0.3333333333333334 HO 0 09:26:39.990 DecisionTree Test (EURUSD,H1) ---> left: 1.0 RH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) ---> right: X_3<=1.7?0.38969404186795487 HP 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->---> left: X_2<=4.9?0.08239026063100136 KO 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> left: X_3<=1.6?0.04079861111111116 DH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 2.0 HM 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 3.0 HS 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> right: X_3<=1.5?0.2222222222222222 IH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 3.0 QM 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 2.0 KP 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->---> right: X_2<=4.8?0.013547574039067499 PH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> left: X_0<=5.9?0.4444444444444444 PE 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 2.0 DP 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 3.0 EE 0 09:26:39.990 DecisionTree Test (EURUSD,H1) --->--->---> right: 3.0
Impressionante.
Abaixo é mostrada a precisão do nosso modelo treinado:
vector preds = decision_tree.predict(x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(y, preds)); //Measuring the accuracy
Resultado
PM 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Confusion Matrix CE 0 09:26:39.990 DecisionTree Test (EURUSD,H1) [[50,0,0] HR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) [0,50,0] ND 0 09:26:39.990 DecisionTree Test (EURUSD,H1) [0,1,49]] GS 0 09:26:39.990 DecisionTree Test (EURUSD,H1) KF 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Classification Report IR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) MD 0 09:26:39.990 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support EQ 0 09:26:39.990 DecisionTree Test (EURUSD,H1) 1.0 50.00 50.00 100.00 50.00 50.0 HR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) 2.0 51.00 50.00 100.00 50.50 50.0 PO 0 09:26:39.990 DecisionTree Test (EURUSD,H1) 3.0 49.00 50.00 100.00 49.49 50.0 EH 0 09:26:39.990 DecisionTree Test (EURUSD,H1) PR 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Accuracy 0.99 HQ 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Average 50.00 50.00 100.00 50.00 150.0 DJ 0 09:26:39.990 DecisionTree Test (EURUSD,H1) W Avg 50.00 50.00 100.00 50.00 150.0 LG 0 09:26:39.990 DecisionTree Test (EURUSD,H1) Train Acc = 0.993
Alcançamos uma precisão de 99,3%, indicando a implementação bem-sucedida da nossa árvore de decisão. Essa precisão é consistente com o que esperaríamos de um modelo Scikit-Learn ao resolver um problema simples com o conjunto de dados.
Vamos continuar treinando e testando o modelo em dados fora da amostra.
matrix train_x, test_x; vector train_y, test_y; matrix_utils.TrainTestSplitMatrices(dataset, train_x, train_y, test_x, test_y, 0.8, 42); //split the data into training and testing samples decision_tree.fit(train_x, train_y); //Building the tree decision_tree.print_tree(decision_tree.root); //Printing the tree vector preds = decision_tree.predict(train_x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(train_y, preds)); //Measuring the accuracy //--- preds = decision_tree.predict(test_x); //making the predictions on a test data Print("Test Acc = ",metrics.confusion_matrix(test_y, preds)); //Measuring the accuracy
Resultado
QD 0 14:56:03.860 DecisionTree Test (EURUSD,H1) : X_2<=1.7?0.34125 LL 0 14:56:03.860 DecisionTree Test (EURUSD,H1) ---> left: 1.0 QK 0 14:56:03.860 DecisionTree Test (EURUSD,H1) ---> right: X_3<=1.6?0.42857142857142855 GS 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->---> left: X_2<=4.9?0.09693877551020412 IL 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->---> left: 2.0 MD 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->---> right: X_3<=1.5?0.375 IS 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->--->---> left: 3.0 QR 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->--->--->---> right: 2.0 RH 0 14:56:03.860 DecisionTree Test (EURUSD,H1) --->---> right: 3.0 HP 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Confusion Matrix FG 0 14:56:03.860 DecisionTree Test (EURUSD,H1) [[42,0,0] EO 0 14:56:03.860 DecisionTree Test (EURUSD,H1) [0,39,0] HK 0 14:56:03.860 DecisionTree Test (EURUSD,H1) [0,0,39]] OL 0 14:56:03.860 DecisionTree Test (EURUSD,H1) KE 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Classification Report QO 0 14:56:03.860 DecisionTree Test (EURUSD,H1) MQ 0 14:56:03.860 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support OQ 0 14:56:03.860 DecisionTree Test (EURUSD,H1) 1.0 42.00 42.00 78.00 42.00 42.0 ML 0 14:56:03.860 DecisionTree Test (EURUSD,H1) 3.0 39.00 39.00 81.00 39.00 39.0 HK 0 14:56:03.860 DecisionTree Test (EURUSD,H1) 2.0 39.00 39.00 81.00 39.00 39.0 OE 0 14:56:03.860 DecisionTree Test (EURUSD,H1) EO 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Accuracy 1.00 CG 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Average 40.00 40.00 80.00 40.00 120.0 LF 0 14:56:03.860 DecisionTree Test (EURUSD,H1) W Avg 40.05 40.05 79.95 40.05 120.0 PR 0 14:56:03.860 DecisionTree Test (EURUSD,H1) Train Acc = 1.0 CD 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Confusion Matrix FO 0 14:56:03.861 DecisionTree Test (EURUSD,H1) [[9,2,0] RK 0 14:56:03.861 DecisionTree Test (EURUSD,H1) [1,10,0] CL 0 14:56:03.861 DecisionTree Test (EURUSD,H1) [2,0,6]] HK 0 14:56:03.861 DecisionTree Test (EURUSD,H1) DQ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Classification Report JJ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) FM 0 14:56:03.861 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support QM 0 14:56:03.861 DecisionTree Test (EURUSD,H1) 2.0 12.00 11.00 19.00 11.48 11.0 PH 0 14:56:03.861 DecisionTree Test (EURUSD,H1) 3.0 12.00 11.00 19.00 11.48 11.0 KD 0 14:56:03.861 DecisionTree Test (EURUSD,H1) 1.0 6.00 8.00 22.00 6.86 8.0 PP 0 14:56:03.861 DecisionTree Test (EURUSD,H1) LJ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Accuracy 0.83 NJ 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Average 10.00 10.00 20.00 9.94 30.0 JR 0 14:56:03.861 DecisionTree Test (EURUSD,H1) W Avg 10.40 10.20 19.80 10.25 30.0 HP 0 14:56:03.861 DecisionTree Test (EURUSD,H1) Test Acc = 0.833
O modelo tem 100% de precisão nos dados de treinamento e 83% de precisão nos dados fora da amostra.
Árvore de decisão e IA no trading
Por outra parte, estamos interessados em uma aplicação específica dos modelos baseados em árvore de decisão — o trading. Para usar esse modelo no trading, precisamos formular o problema a ser resolvido.
Problema:
Usaremos o modelo de IA da árvore de decisão para fazer previsões na barra atual sobre a direção do mercado: para cima ou para baixo.
Como em qualquer modelo, forneceremos ao nosso modelo um conjunto de dados para treinamento. Para isso, utilizaremos dois tipos de indicadores osciladores: o indicador RSI e o oscilador estocástico. Essencialmente, precisamos que o modelo entenda os padrões entre esses dois indicadores e como eles determinam o movimento do preço na barra atual.
Estrutura de dados:
Abaixo está a estrutura onde são armazenados os dados coletados para treinamento e teste. O mesmo se aplica aos dados usados para previsão em tempo real.
struct data{ vector stoch_buff, signal_buff, rsi_buff, target; } data_struct;
Coleta de dados, treinamento e teste da árvore de decisão
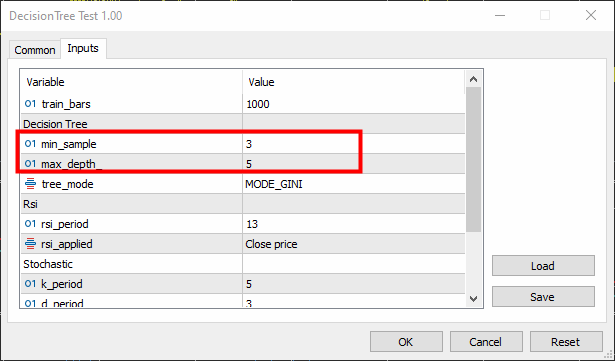
void TrainTree() { matrix dataset(train_bars, 4); vector v; //--- Collecting indicator buffers data_struct.rsi_buff.CopyIndicatorBuffer(rsi_handle, 0, 1, train_bars); data_struct.stoch_buff.CopyIndicatorBuffer(stoch_handle, 0, 1, train_bars); data_struct.signal_buff.CopyIndicatorBuffer(stoch_handle, 1, 1, train_bars); //--- Preparing the target variable MqlRates rates[]; ArraySetAsSeries(rates, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, 1,train_bars, rates); data_struct.target.Resize(size); //Resize the target vector for (int i=0; i<size; i++) { if (rates[i].close > rates[i].open) data_struct.target[i] = 1; else data_struct.target[i] = -1; } dataset.Col(data_struct.rsi_buff, 0); dataset.Col(data_struct.stoch_buff, 1); dataset.Col(data_struct.signal_buff, 2); dataset.Col(data_struct.target, 3); decision_tree = new CDecisionTree(min_sample,max_depth_, tree_mode); //Initializing the decision tree matrix train_x, test_x; vector train_y, test_y; matrix_utils.TrainTestSplitMatrices(dataset, train_x, train_y, test_x, test_y, 0.8, 42); //split the data into training and testing samples decision_tree.fit(train_x, train_y); //Building the tree decision_tree.print_tree(decision_tree.root); //Printing the tree vector preds = decision_tree.predict(train_x); //making the predictions on a training data Print("Train Acc = ",metrics.confusion_matrix(train_y, preds)); //Measuring the accuracy //--- preds = decision_tree.predict(test_x); //making the predictions on a test data Print("Test Acc = ",metrics.confusion_matrix(test_y, preds)); //Measuring the accuracy }
Definimos a amostra mínima (parâmetro min-sample) como 3 e a profundidade máxima (max-depth) como 5.
Resultado
KR 0 16:26:53.028 DecisionTree Test (EURUSD,H1) : X_0<=65.88930872549261?0.0058610536710859695 CN 0 16:26:53.028 DecisionTree Test (EURUSD,H1) ---> left: X_0<=29.19882857713344?0.003187469522387243 FK 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->---> left: X_1<=26.851851851853503?0.030198175526895188 RI 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->---> left: X_2<=7.319205739522295?0.040050858232676456 KG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=23.08345903222593?0.04347468770545693 JF 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_0<=21.6795921184317?0.09375 PF 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 ER 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: -1.0 QF 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_2<=3.223853479489069?0.09876543209876543 LH 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 FJ 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 MM 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 MG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->---> right: 1.0 HH 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->---> right: X_0<=65.4606831930956?0.0030639039663222234 JR 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->---> left: X_0<=31.628407983040333?0.00271101025966336 PS 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=31.20436037455599?0.0944903581267218 DO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_2<=14.629981942657205?0.11111111111111116 EO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: 1.0 IG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: -1.0 EI 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: 1.0 LO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->---> right: X_0<=32.4469112469684?0.003164795835173595 RO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_1<=76.9736842105244?0.21875 RO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 PG 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 MO 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_0<=61.82001028403415?0.0024932856070305487 LQ 0 16:26:53.028 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 EQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 LE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> right: X_2<=84.68660541575225?0.09375 ED 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: -1.0 LM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 NE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) ---> right: X_0<=85.28191275702572?0.024468404842877933 DK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->---> left: X_1<=25.913621262458935?0.01603292204455742 LE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> left: X_0<=72.18709160232456?0.2222222222222222 ED 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_1<=15.458937198072245?0.4444444444444444 QQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: 1.0 CS 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: -1.0 JE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 QM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> right: X_0<=69.83504428897093?0.012164425148527835 HP 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=68.39798826749553?0.07844460227272732 DL 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: X_1<=90.68322981366397?0.06611570247933873 DO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: 1.0 OE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 LI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_1<=88.05704099821516?0.11523809523809525 DE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: 1.0 DM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: -1.0 LG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: X_0<=70.41747488780877?0.015360959832756427 OI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: 1.0 PI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_0<=70.56490391752676?0.02275277028755862 CF 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 MO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 EG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->---> right: X_1<=97.0643939393936?0.10888888888888892 CJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> left: 1.0 GN 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->---> right: X_0<=90.20261550045987?0.07901234567901233 CP 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> left: X_0<=85.94461490761033?0.21333333333333332 HN 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> left: -1.0 GE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->---> right: X_1<=99.66856060606052?0.4444444444444444 GK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> left: -1.0 IK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->--->--->---> right: 1.0 JM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) --->--->--->---> right: -1.0 KE 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Confusion Matrix DO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [[122,271] QF 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [51,356]] HS 0 16:26:53.029 DecisionTree Test (EURUSD,H1) LF 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Classification Report JR 0 16:26:53.029 DecisionTree Test (EURUSD,H1) ND 0 16:26:53.029 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support GQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) 1.0 173.00 393.00 407.00 240.24 393.0 HQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) -1.0 627.00 407.00 393.00 493.60 407.0 PM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) OG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Accuracy 0.60 EO 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Average 400.00 400.00 400.00 366.92 800.0 GN 0 16:26:53.029 DecisionTree Test (EURUSD,H1) W Avg 403.97 400.12 399.88 369.14 800.0 LM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Train Acc = 0.598 GK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Confusion Matrix CQ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [[75,13] CK 0 16:26:53.029 DecisionTree Test (EURUSD,H1) [86,26]] NI 0 16:26:53.029 DecisionTree Test (EURUSD,H1) RP 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Classification Report HH 0 16:26:53.029 DecisionTree Test (EURUSD,H1) LR 0 16:26:53.029 DecisionTree Test (EURUSD,H1) _ Precision Recall Specificity F1 score Support EM 0 16:26:53.029 DecisionTree Test (EURUSD,H1) -1.0 161.00 88.00 112.00 113.80 88.0 NJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) 1.0 39.00 112.00 88.00 57.85 112.0 LJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) EL 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Accuracy 0.51 RG 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Average 100.00 100.00 100.00 85.83 200.0 ID 0 16:26:53.029 DecisionTree Test (EURUSD,H1) W Avg 92.68 101.44 98.56 82.47 200.0 JJ 0 16:26:53.029 DecisionTree Test (EURUSD,H1) Test Acc = 0.505
O modelo mostrou uma precisão de 60% durante o treinamento e 50,5% durante o teste. O resultado, para dizer o mínimo, não é muito bom. Podem haver muitas razões, incluindo a qualidade dos dados usados para construir o modelo ou a presença de preditores ruins. A causa mais comum pode ser que os parâmetros do modelo foram definidos incorretamente.
Para corrigir isso, é necessário ajustar os parâmetros para encontrar os mais adequados para os objetivos específicos.
Agora, vamos escrever uma função que fará previsões em tempo real.
int desisionTreeSignal() { //--- Copy the current bar information only data_struct.rsi_buff.CopyIndicatorBuffer(rsi_handle, 0, 0, 1); data_struct.stoch_buff.CopyIndicatorBuffer(stoch_handle, 0, 0, 1); data_struct.signal_buff.CopyIndicatorBuffer(stoch_handle, 1, 0, 1); x_vars[0] = data_struct.rsi_buff[0]; x_vars[1] = data_struct.stoch_buff[0]; x_vars[2] = data_struct.signal_buff[0]; return int(decision_tree.predict(x_vars)); }
Usaremos uma lógica simples para trading:
Se a árvore de decisão prever -1, indicando que a vela fechará em baixa, abriremos uma posição de venda. Se prever a classe 1, indicando que a vela fechará em alta, abriremos uma posição de compra.
void OnTick() { //--- if (!train_once) // You want to train once during EA lifetime TrainTree(); train_once = true; if (isnewBar(PERIOD_CURRENT)) // We want to trade on the bar opening { int signal = desisionTreeSignal(); double min_lot = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); SymbolInfoTick(Symbol(), ticks); if (signal == -1) { if (!PosExists(MAGICNUMBER, POSITION_TYPE_SELL)) // If a sell trade doesnt exist m_trade.Sell(min_lot, Symbol(), ticks.bid, ticks.bid+stoploss*Point(), ticks.bid - takeprofit*Point()); } else { if (!PosExists(MAGICNUMBER, POSITION_TYPE_BUY)) // If a buy trade doesnt exist m_trade.Buy(min_lot, Symbol(), ticks.ask, ticks.ask-stoploss*Point(), ticks.ask + takeprofit*Point()); } } }
Realizei um teste no período de um mês, de 01.01.2023 a 01.02.2023, com preços de abertura, apenas para ver se tudo funcionaria.
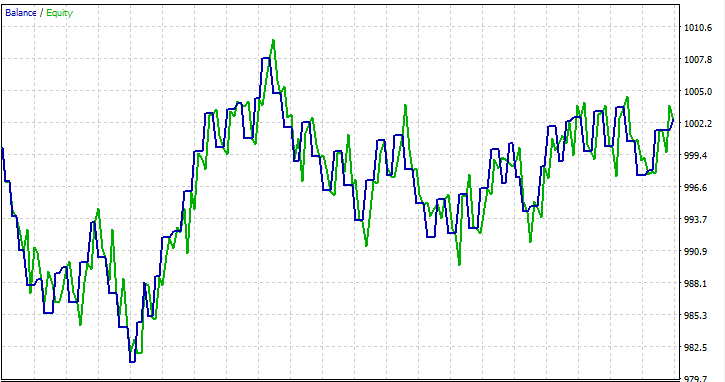
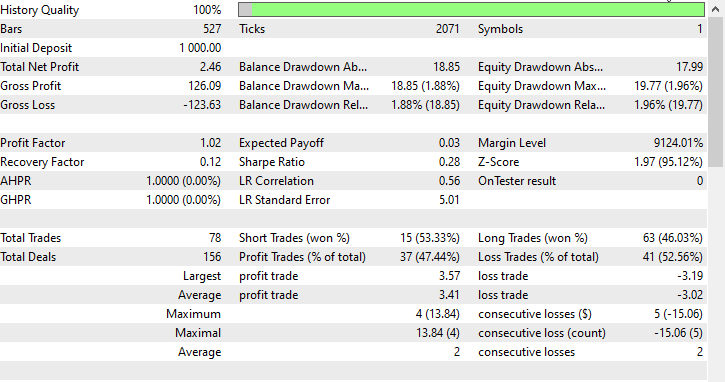
Perguntas frequentes sobre árvores de decisão no trading:
| Pergunta | Resposta |
|---|---|
| A normalização dos dados de entrada é importante para árvores de decisão? | Não, a normalização geralmente não é fundamental para árvores de decisão. As árvores de decisão se dividem com base nos valores de limiar dos atributos, e a escala dos atributos não afeta a estrutura da árvore. No entanto, é recomendado verificar o impacto da normalização no desempenho do modelo. |
| Como as árvores de decisão lidam com variáveis categóricas nos dados de trading? | As árvores de decisão podem lidar naturalmente com variáveis categóricas. Elas realizam divisões binárias com base no cumprimento de uma condição, incluindo condições para variáveis categóricas. A árvore determinará os pontos ótimos de divisão para os atributos categóricos. |
| É possível usar árvores de decisão para previsão de séries temporais no trading? | Embora as árvores de decisão possam ser usadas para previsão de séries temporais no trading, elas não capturam tão efetivamente padrões temporais complexos como, por exemplo, redes neurais recorrentes (RNN) e outros modelos semelhantes. Métodos de conjunto, como florestas aleatórias, podem fornecer maior confiabilidade. |
| As árvores de decisão são suscetíveis ao overfitting? | Árvores de decisão, especialmente as profundas, podem ser propensas ao overfitting devido ao ruído nos dados de treinamento. Para prevenir o overfitting em programas de trading, métodos como poda e limitação da profundidade da árvore podem ser utilizados. |
| As árvores de decisão são adequadas para a análise da importância das características em modelos de trading? | Sim, as árvores de decisão fornecem uma maneira natural de avaliar a importância das características. As características que mais contribuem para as decisões de divisão no topo da árvore são geralmente mais importantes. Essa análise pode fornecer insights sobre os fatores que influenciam as decisões de trading. |
| As árvores de decisão são sensíveis a valores atípicos nos dados? | As árvores de decisão podem ser sensíveis a eles, especialmente se a árvore for profunda. Valores atípicos podem levar a certas divisões devido ao ruído. Para reduzir essa sensibilidade, pode-se aplicar etapas de pré-processamento, durante as quais esses valores atípicos são detectados e removidos. |
| Existem hiperparâmetros específicos ajustáveis para árvores de decisão em modelos de trading? | Sim, os principais hiperparâmetros ajustáveis incluem:
Pode-se usar validação cruzada para encontrar os valores ótimos dos hiperparâmetros para conjuntos de dados específicos. |
| As árvores de decisão podem fazer parte de uma abordagem de ensemble? | Sim, as árvores de decisão podem fazer parte de métodos de ensemble, como florestas aleatórias, que combinam várias árvores para melhorar a eficiência geral da previsão. Os métodos de ensemble são frequentemente robustos e eficazes em aplicações de trading. |
Vantagens das árvores de decisão:
Interpretabilidade:
- As árvores de decisão são fáceis de entender e interpretar. A representação gráfica da estrutura em árvore permite visualizar claramente os processos de tomada de decisão.
Trabalho com não-linearidade:
- As árvores de decisão podem capturar relações não lineares nos dados, tornando-as adequadas para resolver problemas onde os limites de decisão não são lineares.
Trabalho com tipos de dados mistos:
- As árvores de decisão podem aceitar dados numéricos e categóricos sem a necessidade de pré-processamento significativo.
Importância das características:
- As árvores de decisão fornecem uma maneira natural de avaliar a importância das características, ajudando a identificar os fatores críticos que influenciam a variável alvo.
Não fazem suposições sobre a distribuição dos dados:
- Isso as torna bastante universais e aplicáveis a diferentes conjuntos de dados.
Resistência a valores atípicos:
- As árvores de decisão são relativamente resistentes a valores atípicos, pois as divisões são baseadas em comparações relativas e não são influenciadas por valores absolutos.
Seleção automática de variáveis:
- O processo de construção da árvore inclui a seleção automática de variáveis, reduzindo a necessidade de seleção manual de características.
Podem lidar com valores ausentes:
- As árvores de decisão podem lidar com valores ausentes nos objetos sem a necessidade de imputação, pois as divisões são feitas com base nos dados disponíveis.
Desvantagens das árvores de decisão:
Overfitting:
- As árvores de decisão tendaem a overfitting, especialmente se forem profundas e capturarem o ruído nos dados de treinamento. Para resolver esse problema, técnicas como a poda são utilizadas.
Instabilidade:
- Pequenas mudanças nos dados podem levar a alterações significativas na estrutura da árvore, tornando as árvores de decisão instáveis.
Propensão a classes dominantes:
- Em conjuntos de dados com classes desequilibradas, as árvores de decisão podem ser tendenciosas em relação à classe dominante, resultando em desempenho subótimo para classes menos representadas.
Solução global e local:
- As árvores de decisão buscam divisões localmente ótimas em cada nó, o que pode não levar a uma solução globalmente ótima.
Expressividade limitada:
- As árvores de decisão nem sempre conseguem expressar relações complexas nos dados em comparação com modelos mais sofisticados, como redes neurais.
Não são adequadas para saídas contínuas:
- Embora as árvores de decisão sejam adequadas para tarefas de classificação, elas não são ideais para tarefas que requerem saídas contínuas.
Sensíveis a dados ruidosos:
- As árvores de decisão podem ser sensíveis a dados ruidosos, e valores atípicos podem levar a divisões baseadas em ruído, em vez de padrões significativos.
Propensão a características dominantes:
- Características com muitos níveis ou categorias podem parecer mais importantes devido à forma como as divisões são feitas, potencialmente levando a vieses. Esse problema pode ser mitigado com métodos como a normalização das características.
Isso é tudo, obrigado pela atenção.
Você pode acompanhar o desenvolvimento do projeto e contribuir com o algoritmo de árvore de decisão e muitas outras modelos de IA no meu repositório do GitHub: https://github.com/MegaJoctan/MALE5/tree/master
Conteúdo do anexo:
| tree.mqh | Arquivo de inclusão principal. Código da árvore de decisão que discutimos principalmente no artigo. |
| metrics.mqh | Funções e código para medir o desempenho de modelos de aprendizado de máquina. |
| matrix_utils.mqh | Funções auxiliares para trabalhar com matrizes. |
| preprocessing.mqh | Biblioteca para pré-processamento de dados brutos, tornando-os utilizáveis em modelos de aprendizado de máquina. |
| DecisionTree Test.mq5(EA) | Arquivo principal. EA para executar a árvore de decisão. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13862
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso