
Expert Advisor Autônomo com MQL5 e Python (Parte III): Decifrando o Algoritmo do Boom 1000

Vamos analisar todos os mercados sintéticos da Deriv individualmente, começando com o mercado sintético mais conhecido da plataforma: o Boom 1000. O Boom 1000 é conhecido por seu comportamento volátil e imprevisível. O mercado é caracterizado por velas de baixa lentas, curtas e de tamanho igual, seguidas aleatoriamente por velas de alta violentas, do tamanho de arranha-céus. As velas de alta são especialmente desafiadoras de mitigar, pois os ticks associados à vela normalmente não são enviados ao terminal do cliente, o que significa que todos os stop losses são ultrapassados com slippage garantido todas as vezes.
Portanto, a maioria dos traders bem-sucedidos criou estratégias baseadas, de forma geral, em aproveitar apenas as oportunidades de compra ao operar o Boom 1000. Portanto, a maioria dos traders bem-sucedidos criou estratégias baseadas, de forma geral, em aproveitar apenas as oportunidades de compra ao operar o Boom 1000. Portanto, dada sua natureza altista extremamente forte, traders bem-sucedidos buscam usar isso a seu favor, atribuindo mais peso às configurações de compra no Boom 1000 do que fariam com configurações de venda.
Por outro lado, se pudermos simplesmente criar uma nova variável dependente, cujo valor dependa dos níveis de preço do instrumento sintético da Deriv, talvez tenhamos criado uma nova relação que podemos modelar com mais precisão do que ao tentar prever diretamente o Boom 1000. Em outras palavras, se aplicarmos indicadores ao mercado e modelarmos a relação do indicador com o mercado, poderemos obter níveis mais altos de precisão. Com sorte, nosso novo alvo não só nos trará maior precisão, como também será um reflexo fiel das mudanças reais de preço. Ou seja, se a leitura do indicador estiver prevista para cair, espera-se que os níveis de preço também caiam. Lembre-se de que o aprendizado de máquina é centrado em aproximar uma função, assumindo que temos os inputs dessa função. Enquanto não temos nenhum dos inputs que a Deriv usa em seu algoritmo gerador de números aleatórios, ao aplicar um indicador ao mercado deles, temos acesso a todos os inputs dos quais o indicador depende.
Visão Geral da Metodologia
Para avaliar a viabilidade da estratégia proposta, buscamos 100.000 linhas de dados M1 e a leitura do indicador RSI para cada um desses momentos no tempo a partir do nosso terminal MetaTrader 5, usando um script personalizado que escrevi especialmente para hoje. Após ler os dados com o script, realizamos uma análise exploratória. Descobrimos que, em 83% das vezes em que a leitura do RSI cai, os níveis de preço no Boom 1000 também caem. Isso nos mostra que há valor em ser capaz de prever o valor do RSI, pois isso nos dá uma ideia de onde os preços estarão. No entanto, isso também significa que aproximadamente 17% das vezes o RSI nos levará ao erro.
Observamos níveis fracos de correlação entre o RSI e os níveis de preço no Boom 1000 — leituras de 0,016. Nenhum dos gráficos de dispersão que executamos revelou qualquer relação discernível nos dados. Tentamos inclusive plotagens em dimensões superiores, mas isso também foi em vão; os dados parecem bastante difíceis de separar de forma eficaz.
Nossos esforços não pararam por aí — em seguida, dividimos nosso conjunto de dados em duas metades: uma para treinamento e otimização, e outra para validação e teste de overfitting. Também criamos dois alvos: um que capturava as mudanças nos níveis de preço, enquanto o segundo capturava as mudanças na leitura do RSI.
Prosseguimos com o treinamento de dois classificadores idênticos de rede neural profunda para prever as mudanças nos níveis de preço e nos níveis do RSI, respectivamente. O primeiro modelo atingiu níveis de acurácia de cerca de 53%, enquanto o segundo atingiu níveis de aproximadamente 63%. Além disso, a variância dos nossos erros ao prever mudanças no RSI foi menor, o que implica que o segundo modelo pode ter aprendido de forma mais eficaz. Infelizmente, não conseguimos ajustar nossa rede neural profunda sem overfitting no conjunto de treinamento — isso nos é sugerido pelo fato de não termos superado o desempenho da rede neural padrão nos dados de validação não vistos. Realizamos validação cruzada em séries temporais com 5 dobras, sem embaralhamento aleatório, para medir nossos níveis de acurácia tanto no treinamento quanto na validação.
Selecionamos o modelo padrão do RSI como o melhor desempenho e prosseguimos para exportá-lo no formato ONNX e, por fim, construímos nosso Expert Advisor personalizado para o Boom 1000, baseado em IA, em MQL5.
Buscando os Dados
Para começar, primeiro precisamos buscar os dados de que necessitamos a partir do nosso terminal MetaTrader 5 — essa tarefa é realizada por nosso prático script MQL5. O script que escrevi buscará as cotações de mercado associadas ao Boom 1000, o timestamp de cada vela e a leitura relevante do RSI, antes de escrever tudo isso em formato CSV para nós. Observe que definimos o buffer do RSI como série antes de exportar os dados — esse passo é crucial, caso contrário seus dados do RSI estarão em ordem cronológica reversa, o que não é o que você quer.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","RSI"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), rsi_buffer[i] ); Print("Time: ",iTime(Symbol(),PERIOD_CURRENT,i),"Close: ",iClose(Symbol(),PERIOD_CURRENT,i),"RSI",rsi_buffer[i]); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Limpeza de Dados
Agora estamos prontos para começar a preparar nossos dados para visualização. Vamos primeiro importar as bibliotecas de que precisamos.#Import the libraries we need import pandas as pd import numpy as np
Exibir as versões das bibliotecas.
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}")
Versão do Numpy: 1.26.4
Agora leia o arquivo CSV.
#Read in the data we need boom_1000 = pd.read_csv("Market Data Boom 1000 Index.csv")
Vamos ver os dados.
#Let's see the data boom_1000
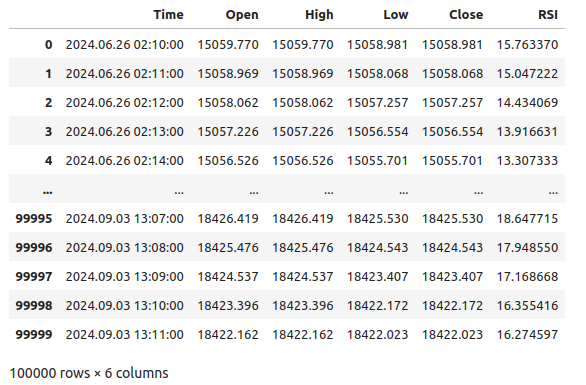
Fig 1: Nossos dados de mercado do Boom 1000
Vamos agora definir nosso horizonte de previsão.
#Define how far into the future we should forecast look_ahead = 20
Precisamos agora definir nosso horizonte de previsão e também adicionar rótulos adicionais aos dados para visualização e fins de plotagem.
#Let's add targets and labels for plotting boom_1000["Price Target"] = boom_1000["Close"].shift(-look_ahead) boom_1000["RSI Target"] = boom_1000["RSI"].shift(-look_ahead) #Let's also add binary targets for plotting purposes boom_1000["Price Binary Target"] = np.nan boom_1000["RSI Binary Target"] = np.nan #Label the binary targets boom_1000.loc[boom_1000["Price Target"] < boom_1000["Close"],"Price Binary Target"] = 0 boom_1000.loc[boom_1000["Price Target"] > boom_1000["Close"],"Price Binary Target"] = 1 boom_1000.loc[boom_1000["RSI Target"] < boom_1000["RSI"],"RSI Binary Target"] = 0 boom_1000.loc[boom_1000["RSI Target"] > boom_1000["RSI"],"RSI Binary Target"] = 1 #Drop na values boom_1000.dropna(inplace=True)
Vamos agora definir nossos inputs do modelo e os dois alvos que queremos comparar.
#Define the predictors and targets predictors = ["Open","High","Low","Close","RSI"] old_target = "Price Binary Target" new_target = "RSI Binary Target"
Análise Exploratória dos Dados
Vamos importar as bibliotecas de que precisamos.
#Exploratory data analysis import seaborn as sns
Exibir a versão da biblioteca em uso.
print(f"Seaborn version {sns.__version__}") Seaborn version 0.13.2Vamos avaliar a pureza dos sinais gerados pelo RSI. Pureza, neste caso, responde à pergunta: “Se o nível do RSI cair, os preços também cairão?” Calculamos essa quantidade primeiro contando o número de instâncias em que o RSI e o Alvo Binário de Preço não eram iguais, e depois dividimos essa contagem pelo número total de linhas no conjunto de dados. Subtraímos esse valor de 1 para obter a proporção total de vezes em que o RSI e o Alvo Binário de Preço estavam em harmonia. De acordo com nossos cálculos, parece que em 83% das vezes, o RSI e o preço mudam na mesma direção.
#Let's assess the purity of the signals generated
rsi_purity = 1 - boom_1000.loc[boom_1000["RSI Binary Target"] != boom_1000["Price Binary Target"]].shape[0] / boom_1000.shape[0]
print(f"Price and the RSI tend to move together {rsi_purity * 100}% of the time")
Esse valor é bastante alto. Isso nos dá certo nível de confiança de que podemos obter uma boa separação ao visualizar os dados. Vamos começar criando um gráfico categórico para resumir todas as instâncias em que o nível do RSI caiu (coluna 0) ou subiu (coluna 1), respectivamente, no eixo x — com o preço de fechamento no eixo y. Em seguida, colorimos cada ponto, de azul ou laranja, para representar os casos em que os níveis de preço do Boom 1000 subiram ou caíram, respectivamente. Como podemos ver no gráfico abaixo, a coluna 0 é majoritariamente azul com alguns pontos laranja, e o oposto ocorre na coluna 1. Isso mostra que o RSI parece ser um bom separador de variações de preço neste caso. No entanto, não é perfeito. Podemos precisar de um indicador adicional no futuro.
#Let's see this purity level we just calculated sns.catplot(data=boom_1000,x="RSI Binary Target",y="Close",hue="Price Binary Target")
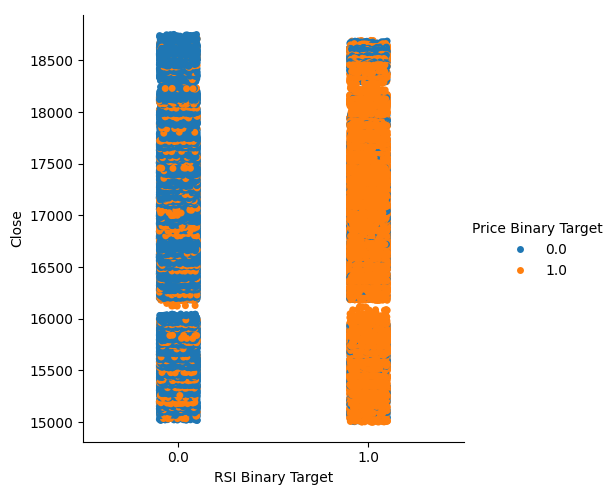
Fig 2: Um gráfico categórico mostrando o quão bem o RSI separa nossos dados
Também criamos um gráfico de dispersão para tentar visualizar a relação entre o RSI e o preço de fechamento do Boom 1000. Infelizmente, como podemos ver, não parece haver relação entre os dois. Observamos trilhas longas, como espaguete, de pontos azuis e laranja alternando aleatoriamente — isso pode indicar que há outras variáveis afetando o alvo.
#Let us also observe a scatter plot of the two sns.scatterplot(data=boom_1000,x="RSI",y="Close",hue="Price Binary Target")
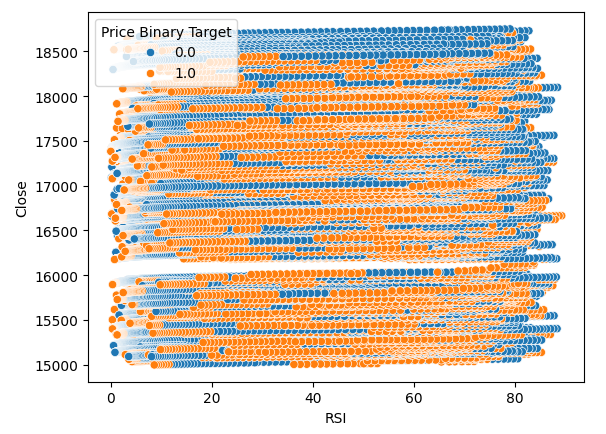
Fig 3: Um gráfico de dispersão das leituras do RSI versus o preço de fechamento
Talvez a relação que estamos tentando visualizar não possa ser vista em duas dimensões. Vamos tentar visualizar os dados em três dimensões — com sorte, poderemos observar os efeitos de interação ocultos que não conseguimos ver até agora.
Importar as bibliotecas necessárias.
#Let's create 3D scatter plots import matplotlib.pyplot as plt
Definir quanto dos dados será plotado.
#Define the plot end end = 10000
Agora criar o gráfico de dispersão 3D. Infelizmente, ainda observamos que os dados parecem distribuídos aleatoriamente, sem padrões observáveis que possamos usar a nosso favor.
#Visualizing our data in 3D fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'red' for movement in boom_1000.loc[0:end,"Price Binary Target"]] ax.scatter(boom_1000.loc[0:end,"RSI"],boom_1000.loc[0:end,"High"],boom_1000.loc[0:end,"Close"],c=colors) ax.set_xlabel('Boom 1000 RSI') ax.set_ylabel('Boom 1000 High') ax.set_zlabel('Boom 1000 Close')
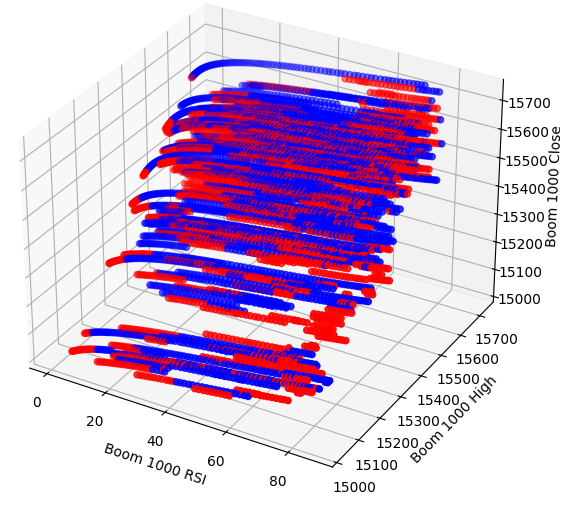
Fig 4: Um gráfico de dispersão 3D do mercado Boom 1000 e sua relação com o RSI
Vamos agora analisar os níveis de correlação entre o RSI e nossos dados de preço. Observamos níveis de correlação bastante fracos — praticamente zero, para ser preciso.
#Let's analyze the correlation levels sns.heatmap(boom_1000.loc[:,predictors].corr(),annot=True)
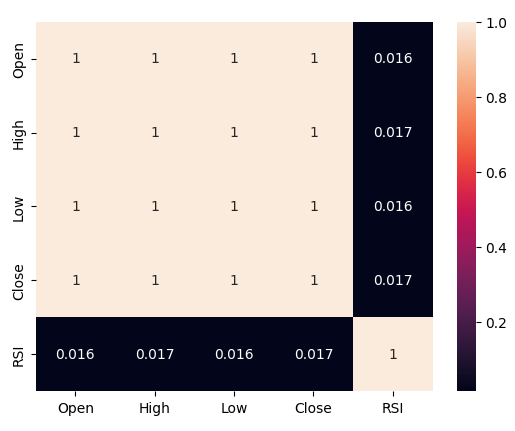
Fig 5: Um mapa de calor da nossa matriz de correlação
Preparando os Dados para Modelagem
Antes de podermos começar a modelar os dados, precisamos primeiro escalá-los e padronizá-los. Primeiro, vamos importar as bibliotecas necessárias.
#Preparing to model the data import sklearn from sklearn.preprocessing import RobustScaler from sklearn.neural_network import MLPClassifier,MLPRegressor from sklearn.model_selection import TimeSeriesSplit, train_test_split from sklearn.metrics import accuracy_score
Exibindo a versão da biblioteca.
#Display library version print(f"Sklearn version {sklearn.__version__}")
Escalar os dados.
#Scale our data
X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:,predictors]),columns=predictors)
Definindo nossos alvos antigos e novos.
#Our old and new target old_y = boom_1000.loc[:,"Price Binary Target"] new_y = boom_1000.loc[:,"RSI Binary Target"]
Realizando a divisão entre treino e teste.
#Perform train test splits train_X,test_X,ohlc_train_y,ohlc_test_y = train_test_split(X,old_y,shuffle=False,test_size=0.5) _,_,rsi_train_y,rsi_test_y = train_test_split(X,new_y,shuffle=False,test_size=0.5)
Preparar um data frame para armazenar nossos níveis de acurácia na validação.
#Prepare data frames to store our accuracy levels validation_accuracy = pd.DataFrame(index=np.arange(0,5),columns=["Close Accuracy","RSI Accuracy"])
Agora vamos criar um objeto de divisão para séries temporais.
#Let's create the time series split object tscv = TimeSeriesSplit(gap=look_ahead,n_splits=5)
Modelagem dos Dados
Agora estamos prontos para realizar a validação cruzada e observar a variação nos níveis de acurácia entre os 2 alvos possíveis.
#Instatiate the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) #Cross validate the model for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],:],ohlc_train_y.loc[train[0]:train[-1]]) validation_accuracy.iloc[i,0] = accuracy_score(ohlc_train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],:]))
Nossos níveis de acurácia.
validation_accuracy
| Acurácia do Preço de Fechamento | Acurácia do RSI |
|---|---|
| 0.53703 | 0.663186 |
| 0.544592 | 0.623575 |
| 0.479534 | 0.597647 |
| 0.57064 | 0.651422 |
| 0.545913 | 0.616373 |
Nossos níveis médios de acurácia mostram imediatamente que podemos ter melhores resultados ao prever mudanças no valor do RSI.
validation_accuracy.mean()
Acurácia do RSI 0.630441
dtype: object
Quanto menor o desvio padrão, maior a certeza que o modelo tem em suas previsões. O modelo parece ter aprendido a prever o RSI com mais certeza do que as mudanças no preço.
validation_accuracy.std()
Acurácia do RSI 0.026613
dtype: object
Vamos plotar o desempenho de cada um de nossos modelos.
validation_accuracy.plot()
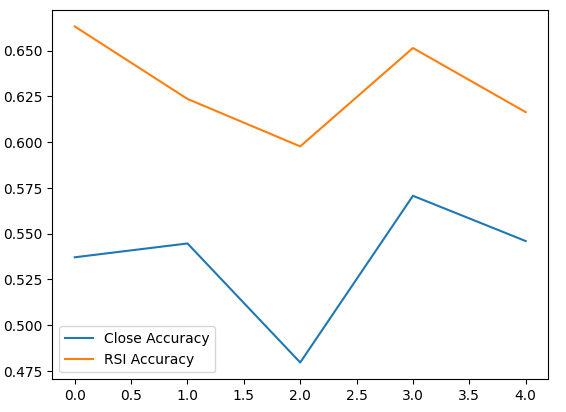
Fig 6: Visualizando nossa acurácia na validação
Por fim, gráficos de caixa (box plots) nos ajudam a observar a diferença de desempenho entre nossos dois modelos. Como podemos ver, o modelo de RSI está superando em muito o modelo baseado no preço.
#Our RSI validation accuracy is better
sns.boxplot(validation_accuracy)
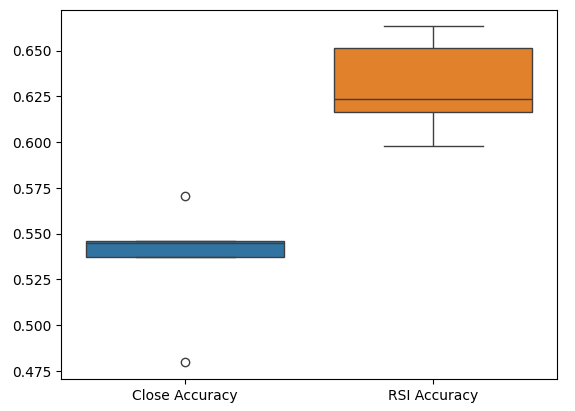
Fig 7: Box plots da nossa acurácia na validação
Importância das Variáveis
Agora vamos analisar quais variáveis são importantes para prever o valor do RSI. Começaremos realizando uma seleção progressiva (forward selection) em nossa Rede Neural. A seleção progressiva começa com um modelo nulo e adiciona uma variável por vez até que nenhuma melhoria adicional possa ser feita no desempenho do modelo.Primeiro, vamos importar as bibliotecas necessárias.
#Feature importance import mlxtend from mlxtend.feature_selection import SequentialFeatureSelector as SFS
Agora exibir a versão da biblioteca.
print(f"Mlxtend version: {mlxtend.__version__}")
Reinicializar o modelo.
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
Configurar o seletor de variáveis.
#Define the forward feature selector sfs1 = SFS( model, k_features=(1,X.shape[1]), n_jobs=-1, forward=True, cv=5, scoring="accuracy" )
Ajustar o seletor de variáveis.
#Fit the feature selector
sfs = sfs1.fit(train_X,rsi_train_y)
Vamos ver as variáveis mais importantes que identificamos. Todas as variáveis disponíveis foram selecionadas.
sfs.k_feature_names_
Vamos visualizar o processo de seleção de variáveis. Vamos visualizar o processo de seleção de variáveis.
#Importing the libraries we need from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Agora vamos plotar os resultados.
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_err')
plt.title('Sequential Forward Selection')
plt.grid()
plt.show()
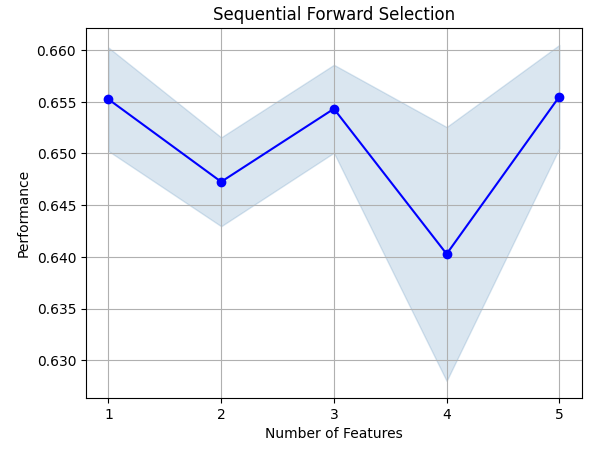
Fig 8: Visualizando o processo de seleção de variáveis
A informação mútua (MI) nos permite entender o potencial que cada preditor possui. Quanto maior o valor de MI, em geral, mais útil o preditor pode ser. A MI consegue capturar dependências não lineares nos dados. Por fim, a MI está em escala logarítmica, o que significa que valores acima de 3 são raramente vistos na prática.
Importar as bibliotecas necessárias.
#Let's analyze our MI scores from sklearn.feature_selection import mutual_info_classif
Calcular os valores de MI.
mi_scores = pd.DataFrame(mutual_info_classif(train_X,rsi_train_y).reshape(1,5),columns=predictors)
Ao plotar os resultados, vemos que a coluna RSI é a mais importante de acordo com a MI.
#Let's visualize the results mi_scores.plot.bar()
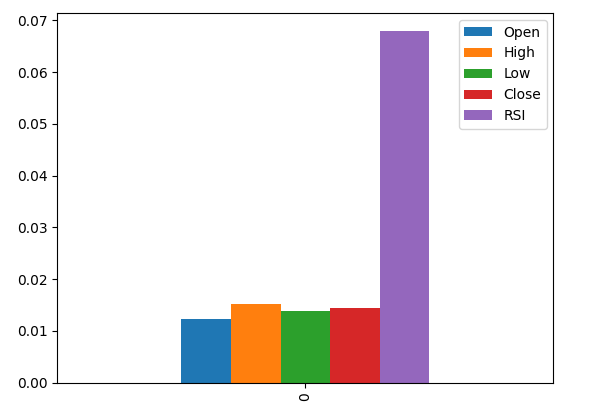
Fig 9: Visualizando nossos valores de MI
Ajuste de Parâmetros
Agora vamos tentar ajustar nosso modelo para extrair ainda mais desempenho dele. O módulo RandomizedSearchCV da biblioteca sklearn permite ajustar nossos modelos de machine learning com facilidade. Ao ajustar modelos de machine learning, há um equilíbrio a ser feito entre acurácia e tempo de computação. Ajustamos o número total de iterações para decidir entre esses dois fatores. Vamos importar as bibliotecas de que precisamos.
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV
Inicializar o modelo.
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
Definir o objeto de ajuste (tuner).
#Define the tuner tuner = RandomizedSearchCV( model, { "activation":["relu","tanh","logistic","identity"], "solver":["adam","sgd","lbfgs"], "alpha":[0.1,0.01,0.001,0.00001,0.000001], "learning_rate": ["constant","invscaling","adaptive"], "learning_rate_init":[0.1,0.01,0.001,0.0001,0.000001,0.0000001], "power_t":[0.1,0.5,0.9,0.01,0.001,0.0001], "shuffle":[True,False], "tol":[0.1,0.01,0.001,0.0001,0.00001], }, n_iter=300, cv=5, n_jobs=-1, scoring="accuracy" )
Ajustar (fit) o objeto tuner.
#Fit the tuner
tuner_results =tuner.fit(train_X,rsi_train_y)
Os melhores parâmetros encontrados.
#Best parameters
tuner_results.best_params_ 'solver': 'lbfgs',
'shuffle': True,
'power_t': 0.0001,
'learning_rate_init': 0.01,
'learning_rate': 'adaptive',
'alpha': 1e-06,
'activation': 'logistic'}
Testando Overfitting
Para testar o overfitting, vamos realizar uma validação cruzada com um modelo padrão e com nosso modelo ajustado, usando os dados de validação. Se o modelo padrão tiver um desempenho melhor, saberemos que houve overfitting nos dados de treino. Caso contrário, o ajuste de hiperparâmetros foi bem-sucedido.
Inicializar os 2 modelos.
#Testing for overfitting default_model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) customized_model = MLPClassifier( hidden_layer_sizes=(30,10), max_iter=200, tol=0.00001, solver="lbfgs", shuffle=True, power_t=0.0001, learning_rate_init=0.01, learning_rate="adaptive", alpha=0.000001, activation="logistic" )
Ajustar ambos os modelos aos dados de treinamento.
#First we will train both models on the training set
default_model.fit(train_X,rsi_train_y)
customized_model.fit(train_X,rsi_train_y)
Redefinir os índices em ambos os conjuntos de dados.
#Now we will reset our indexes
rsi_test_y = rsi_test_y.reset_index()
test_X = test_X.reset_index()
Formatar os dados.
#Format the data rsi_test_y = rsi_test_y.loc[:,"RSI Binary Target"] test_X = test_X.loc[:,predictors]
Preparar um data frame para armazenar nossos níveis de acurácia.
#Prepare a data frame to store our accuracy levels validation_error = pd.DataFrame(index=np.arange(0,5),columns=["Default Neural Network","Customized Neural Network"])
Validando cruzadamente cada modelo para testar o overfitting.
#Perform cross validation for i,(train,test) in enumerate(tscv.split(test_X)): customized_model.fit(test_X.loc[train[0]:train[-1],predictors],rsi_test_y.loc[train[0]:train[-1]]) validation_error.iloc[i,1] = accuracy_score(rsi_test_y.loc[test[0]:test[-1]],customized_model.predict(test_X.loc[test[0]:test[-1]]))
Nossos níveis de desempenho na validação.
validation_error
| Rede Neural Padrão | Rede Neural Personalizada |
|---|---|
| 0.627656 | 0.597767 |
| 0.637258 | 0.635938 |
| 0.621414 | 0.631977 |
| 0.6429 | 0.6411 |
| 0.664866 | 0.652503 |
Analisando nossos níveis médios de desempenho, fica claro que o modelo padrão foi ligeiramente melhor que o modelo personalizado que criamos.
validation_error.mean()
Rede Neural Personalizada 0.631857
dtype: object
Além disso, nosso modelo personalizado demonstrou mais habilidade devido à menor variância nos seus escores de acurácia.
validation_error.std()
Rede Neural Personalizada 0.020557
dtype: object
Vamos plotar nossos resultados.
validation_error.plot()
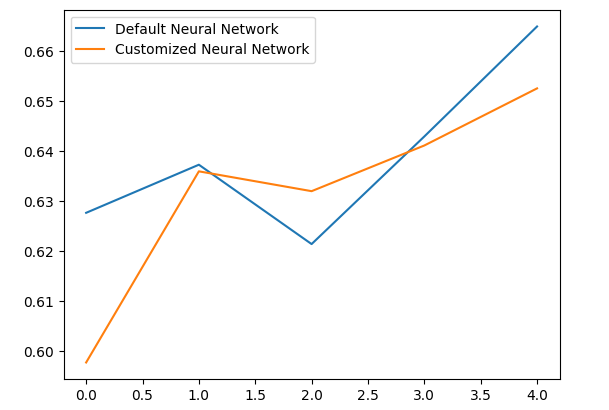
Fig 10: Visualizando nosso teste de overfitting
Os box plots mostram que nosso modelo personalizado parece menos estável, apresentando outliers que não são observados no modelo padrão. Além disso, nosso modelo padrão tem um desempenho médio ligeiramente melhor. Portanto, selecionaremos o modelo padrão em vez do personalizado.
sns.boxplot(validation_error)
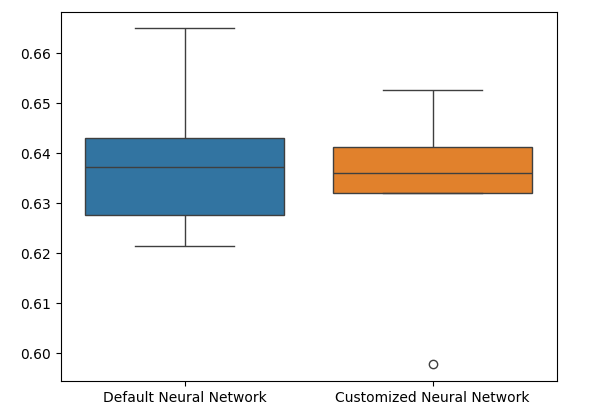
Fig 11: Visualizando nosso teste de overfitting II
Preparando para Exportar para ONNX
Antes de podermos exportar nosso modelo para o formato ONNX, devemos primeiro escalar os dados de uma forma que possamos reproduzir no nosso Terminal MetaTrader 5. Vamos subtrair a média de cada coluna e dividir pelo desvio padrão da coluna, isso garante que nosso modelo aprenda de forma eficaz, já que os dados estão em escalas diferentes. Além disso, vamos exportar os valores de média e desvio padrão em formato CSV para podermos utilizá-los futuramente.#Preparing to export to ONNX #Let's scale our data scaling_factors = pd.DataFrame(columns=predictors,index=['mean','standard deviation']) X = boom_1000.loc[:,predictors] y = boom_1000.loc[:,"RSI Target"]
Escalar cada coluna.
#Let's fill each column for i in np.arange(0,len(predictors)): scaling_factors.iloc[0,i] = X.iloc[:,i].mean() scaling_factors.iloc[1,i] = X.iloc[:,i].std() X.iloc[:,i] = ( ( X.iloc[:,i] - scaling_factors.iloc[0,i] ) / scaling_factors.iloc[1,i])
Salvar os fatores de escala em formato CSV.
#Save the scaling factors as a CSV scaling_factors.to_csv("/home/volatily/.wine/drive_c/Program Files/MetaTrader 5/MQL5/Files/boom_1000_scaling_factors.csv")
Exportando para ONNX
O Open Neural Network Exchange (ONNX) é um framework de machine learning interoperável e de código aberto que permite que desenvolvedores construam, compartilhem e utilizem modelos de machine learning em qualquer linguagem de programação que suporte a API ONNX. Isso nos permite construir nossos modelos de machine learning em Python e implantá-los em produção no MQL5.Primeiro, vamos importar as bibliotecas necessárias.
#Exporting to ONNX
import onnx
import netron
import skl2onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
Exibir as versões das bibliotecas.
#Display the library versions print(f"Onnx version {onnx.__version__}") print(f"Netron version {netron.__version__}") print(f"Skl2onnx version {skl2onnx.__version__}")
Versão do Netron: 7.8.0
Versão do Skl2onnx: 1.16.0
Definir os tipos de entrada do nosso modelo.
#Define the model input types initial_types = [("float_input",FloatTensorType([1,5]))]
Ajustar o modelo com todos os dados disponíveis.
#Fit the model on all the data we have default_model = MLPRegressor(hidden_layer_sizes=(30,10),max_iter=200) default_model.fit(X,y)
Converter o modelo para sua representação ONNX.
#Convert the model to an ONNX representation onnx_model = convert_sklearn(default_model,initial_types=initial_types,target_opset=12)
Salvar a representação ONNX em arquivo.
#Save the ONNX representation onnx_name = "Boom 1000 Neural Network.onnx" onnx.save(onnx_model,onnx_name)
Visualizar o modelo usando o Netron.
#View the onnx model
netron.start(onnx_name)

Fig 12: Visualizando nossa rede neural profunda

Fig 13: Visualizando as entradas e saídas do nosso modelo
Implementação em MQL5
Para construirmos uma aplicação de trading com um sistema de IA integrado, primeiro precisaremos do modelo ONNX que acabamos de exportar em Python.
//+------------------------------------------------------------------+ //| Boom 1000.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| ONNX Model | //+------------------------------------------------------------------+ #resource "\\Files\\Boom 1000 Neural Network.onnx" as const uchar onnx_buffer[];
Vamos também carregar a biblioteca de negociação para gerenciar nossas posições.
//+-----------------------------------------------------------------+ //| Libraries we need | //+-----------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Definindo variáveis globais que usaremos ao longo de nosso programa.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; int rsi_handler,model_state,system_state; double mean_values[5],std_values[5],rsi_buffer[],bid,ask; vectorf model_outputs = vectorf::Zeros(1); vectorf model_inputs = vectorf::Zeros(5);
Agora vamos definir uma função para preparar nosso modelo ONNX. Essa função criará primeiro nosso modelo a partir do buffer que definimos no início do programa e validará se o modelo não está corrompido. Se estiver corrompido, a função retornará falso e isso encerrará o procedimento de inicialização. A partir daí, a função prosseguirá para definir as formas de entrada e saída do nosso modelo ONNX. Se falharmos ao definir qualquer um dos parâmetros de entrada/saída, nossa função novamente retornará falso e encerrará a inicialização.
//+------------------------------------------------------------------+ //| This function will prepare our ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- First create the ONNX model from the buffer we created earlier onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the ONNX model if(onnx_model == INVALID_HANDLE) { Comment("[ERROR] Failed to create the ONNX model: ",GetLastError()); return(false); } //--- Set the input and output shapes of the model ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the input and output shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape: ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape: ",GetLastError()); return(false); } return(true); }
Não podemos usar nosso modelo ONNX sem escalar suas entradas. A função a seguir carregará os valores de média e desvio padrão necessários em arrays de fácil acesso.
//+-----------------------------------------------------------------+ //| Load the scaling values | //+-----------------------------------------------------------------+ void load_scaling_values(void) { //--- BOOM 1000 OHLC + RSI Mean values mean_values[0] = 16799.87389394667; mean_values[1] = 16800.872890865994; mean_values[2] = 16798.91007345616; mean_values[3] = 16799.908906749482; mean_values[4] = 43.45867626462568; //--- BOOM 1000 OHLC + RSI Mean std values std_values[0] = 864.3356132780019; std_values[1] = 864.3839684000297; std_values[2] = 864.2859346216392; std_values[3] = 864.3344430387272; std_values[4] = 20.593175501388043; } //+------------------------------------------------------------------+
Também precisamos definir uma função que buscará os preços de mercado atualizados e o valor atual do indicador técnico.
//+------------------------------------------------------------------+ //| Fetch updated market prices and technical indicator values | //+------------------------------------------------------------------+ void update_market_data(void) { //--- Market data bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); //--- Technical indicator values CopyBuffer(rsi_handler,0,0,1,rsi_buffer); }
Por fim, precisamos de uma função que buscará as entradas para o modelo, aplicará o escalonamento e obterá uma previsão do modelo. Manteremos um indicador (flag) para lembrar a previsão do modelo. Isso nos ajudará a identificar facilmente quando o modelo prever uma reversão.
//+------------------------------------------------------------------+ //| Fetch a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { //--- Get the model inputs model_inputs[0] = iOpen(_Symbol,PERIOD_CURRENT,0); model_inputs[1] = iHigh(_Symbol,PERIOD_CURRENT,0); model_inputs[2] = iLow(_Symbol,PERIOD_CURRENT,0); model_inputs[3] = iClose(_Symbol,PERIOD_CURRENT,0); model_inputs[4] = rsi_buffer[0]; //--- Scale the model inputs for(int i = 0; i < 5; i++) { model_inputs[i] = ((model_inputs[i] - mean_values[i]) / std_values[i]); } //--- Fetch a prediction from our model OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs); //--- Give user feedback Comment("Model RSI Forecast: ",model_outputs[0]); //--- Store the model's state if(rsi_buffer[0] > model_outputs[0]) { model_state = -1; } else if(rsi_buffer[0] < model_outputs[0]) { model_state = 1; } }
Agora, vamos definir o procedimento de inicialização do nosso modelo. Começaremos carregando nosso modelo ONNX, depois buscando os valores de escalonamento e configurando nosso indicador RSI.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- This function will prepare our ONNX model and set the input and output shapes if(!load_onnx_model()) { return(INIT_FAILED); } //--- This function will prepare our scaling values load_scaling_values(); //--- Setup our technical indicatot rsi_handler = iRSI(Symbol(),PERIOD_CURRENT,20,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
Sempre que nossa aplicação for removida do gráfico, liberaremos os recursos que não estiverem mais em uso. Iremos liberar o modelo ONNX, o indicador RSI e remover o Expert Advisor.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the resources we no longer need OnnxRelease(onnx_model); IndicatorRelease(rsi_handler); ExpertRemove(); }
Sempre que recebermos preços atualizados, primeiro buscaremos os dados de mercado e técnicos atualizados — isso inclui os preços de bid e ask, bem como a leitura do RSI. Então estaremos prontos para obter uma nova previsão do nosso modelo. Se não tivermos posições abertas, seguiremos a previsão do modelo e lembraremos nossa posição atual usando uma flag binária. Caso contrário, se já houver uma posição aberta, verificaremos se a nova previsão do modelo vai contra nossa posição atual. Se sim, fecharemos a posição. Caso contrário, continuaremos realizando lucros.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated market prices update_market_data(); //--- On every tick we need to fetch a prediction from our model model_predict(); //--- If we have no open positions, follow the model's prediction if(PositionsTotal() == 0) { //--- Our model detected a spike if(model_state == 1) { Trade.Buy(0.2,Symbol(),ask,0,0,"BOOM 1000 AI"); system_state = 1; } //--- Our model detected a drop if(model_state == -1) { Trade.Sell(0.2,Symbol(),bid,0,0,"BOOM 1000 AI"); system_state = -1; } } //--- If we have open positiosn, our AI system will decide when to close them else if(PositionsTotal() > 0) { if(system_state != model_state) { //--- Close the positions we opened Alert("Reversal detected by the AI system,closing all positions now!"); Trade.PositionClose(Symbol()); } } } //+------------------------------------------------------------------+

Fig 14: Nosso sistema Boom 1000 conseguiu capturar um pico

Fig 15: Nosso sistema Boom 1000 detectou uma reversão
Conclusão
No artigo de hoje demonstramos que é possível construir Expert Advisors auto otimizáveis para lidar até mesmo com os instrumentos sintéticos mais desafiadores. Além disso, mostramos que a abordagem tradicional de prever níveis de preço diretamente não é suficiente nos mercados algorítmicos atuais.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/15781
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Criando um Expert Advisor Integrado MQL5-Telegram (Parte 5): Enviando Comandos do Telegram para o MQL5 e Recebendo Respostas em Tempo Real
Criando um Expert Advisor Integrado MQL5-Telegram (Parte 5): Enviando Comandos do Telegram para o MQL5 e Recebendo Respostas em Tempo Real
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Analisaremos todos os mercados sintéticos de derivativos individualmente, começando pelo mais famoso - o Boom 1000.
Muito obrigado pelo artigo! Estou analisando esses índices há muito tempo, mas não sabia de que lado abordá-los.
Por favor, continue!
Tentei várias ferramentas e, em cada uma delas, seu modelo apresenta umerro devido a uma incompatibilidade entre as dimensões dos dados de entrada (X) e as variáveis de destino (y).
Thank you so much for the article! I've been analyzing these indexes for a long time, but I wasn't sure where to approach them.
Please continue!
You're welcome Janis.
I will definitely continue. There's a lot to cover, but I will create time.
I've tried several tools, and in each one your model gives an error due to inconsistent sizes of input data (X) and target variables (y).
Hello Aliaksandr, you can instead just use the code as template guide, and then make the necessary adjustments on your side. I'd also recommend you try different indicators, try different variations of the general idea in the article. That will help us understand the global truth faster.
Experimentei várias ferramentas, e cada uma delas causava erros no modelo devido a inconsistências no tamanho dos dados de entrada (X) e na variável de destino (y).
# Mantenha os índices consistentes; caso contrário, os índices serão reconstruídos se houver dados filtrados X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:, predictors]), columns=predictors, index=boom_1000.index)