
MQL5とPythonで自己最適化エキスパートアドバイザーを構築する(第3回):Boom 1000アルゴリズムの解読

Derivの合成市場をすべて個別に分析します。まずは最も有名な合成市場であるBoom 1000から始めます。Boom 1000は、その不安定で予測不可能な動きで有名です。この市場は、ゆっくりとした短い同サイズの弱気ローソク足と、その後に突然、超高層ビルサイズの強気ローソク足が続くという特徴があります。強気ローソク足は、ローソク足に関連付けられたティックが通常クライアント端末に送信されないため、緩和するのが特に難しく、すべてのストップロスが毎回確実にスリッページで突破されます。
そのため、成功しているトレーダーのほとんどは、Boom 1000を取引する際に買いの機会のみを狙うという緩やかな戦略を立てています。Boom 1000はM1時間枠で20分間下落する可能性があり、その動き全体を1本のローソク足で再現する可能性があることを思い出してください。したがって、その圧倒的な強気の性質を考えると、成功しているトレーダーは、売りセットアップよりもBoom 1000の買いセットアップに重点を置くことで、これを有利に利用しようとします。
一方、Derivの合成商品の価格レベルに応じて値が決まる新しい従属変数を単純に作成できれば、Boom 1000を予測する際に捉えられるよりも正確にモデル化できる新しい関係を作成できる可能性があります。言い換えれば、指標を市場に適用し、指標と市場の関係をモデル化すれば、より高い精度レベルを実現できる可能性があります。うまくいけば、新しいターゲットによって精度レベルが向上するだけでなく、実際の価格変動を忠実に反映することになります。つまり、指標の読み取り値が下がると予想される場合、価格レベルも下がると予想されます。機械学習は、関数の入力があることを前提として関数を近似することに重点を置いていることを思い出してください。Derivが乱数生成アルゴリズムで使用している入力はどれも持っていませんが、指標を市場に適用することで、指標が依存するすべての入力にアクセスできます。
方法論の概要
提案された戦略の実現可能性を評価するために、本日私が作成したカスタマイズされたスクリプトを使用して、MetaTrader 5端末から、各インスタンスのM1データ100,000行とRSI指標読み取り値を時間的に取得しました。スクリプトを読み込んだ後、探索的データ分析を実行しました。RSI読み取り値が下がると、Boom 1000の価格レベルも83%下がることがわかりました。これは、価格レベルがどこになるかを知ることができるため、RSI値を予測できることに利点があることを示しています。ただし、これはまた、約17%の確率でRSIが私たちを誤った方向に導くことも意味します。
Boom 1000のRSIと価格レベルの間には、読み取り値が0.016と、相関レベルが弱いことが観察されました。作成した散布図のいずれも、データに識別可能な関係性を明らかにせず、より高次元でのプロットも試みましたが、これも無駄に終わりました。データを効果的に分離するのはかなり難しいようです。
私たちの努力はそこで終わらず、その後、データセットを2つに分割しました。1つは訓練と最適化用、もう1つは検証と過剰適合のテスト用です。また、2つのターゲットも作成しました。1つのターゲットは価格レベルの変化を捉え、もう1つはRSI読み取り値の変化を捉えました。
価格レベルとRSIレベルの変化をそれぞれ予測する2つの同一のディープニューラルネットワーク分類器の訓練を進めたところ、最初のモデルは約53%の精度レベルを達成し、後者は約63%の精度レベルを達成しました。さらに、RSIの変化を予測する際の誤差レベルの分散は低く、後者のモデルの方が効果的に学習した可能性があることを示唆しています。残念ながら、訓練セットに過剰適合することなくディープニューラルネットワークを調整することはできませんでした。これは、未知の検証データでデフォルトのニューラルネットワークを上回ることができなかったという事実から推測できます。訓練と検証の両方で精度レベルを測定するために、ランダムシャッフルなしで5倍の時系列クロス検証を実行しました。
デフォルトのRSIモデルを最高のパフォーマンスモデルとして選択し、ONNX形式にエクスポートして、最終的にMQL5でカスタマイズされたBoom 1000 AI搭載EAを構築しました。
データの取得
まず、MetaTrader 5端末から必要なデータを取得する必要があります。このタスクは、便利なMQL5スクリプトによって自動的に処理されます。私が作成したスクリプトは、Boom 1000に関連付けられた市場相場、各ローソク足のタイムスタンプ、および関連するRSI指標読み取り値を取得してから、それらをCSV形式で書き出します。データを書き出す前にRSIバッファをシリーズとして設定していることに注意してください。この手順は重要です。そうしないと、RSIデータが逆時系列になり、望ましくない結果になります。
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","RSI"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), rsi_buffer[i] ); Print("Time: ",iTime(Symbol(),PERIOD_CURRENT,i),"Close: ",iClose(Symbol(),PERIOD_CURRENT,i),"RSI",rsi_buffer[i]); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
データクリーニング
これで、可視化のためにデータを準備する準備が整いました。まず必要なライブラリをインポートしましょう。#Import the libraries we need import pandas as pd import numpy as np
ライブラリのバージョンを表示します。
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}")
Numpy version 1.26.4
次にCSVファイルを読み込みます。
#Read in the data we need boom_1000 = pd.read_csv("Market Data Boom 1000 Index.csv")
データを見てみましょう。
#Let's see the data boom_1000
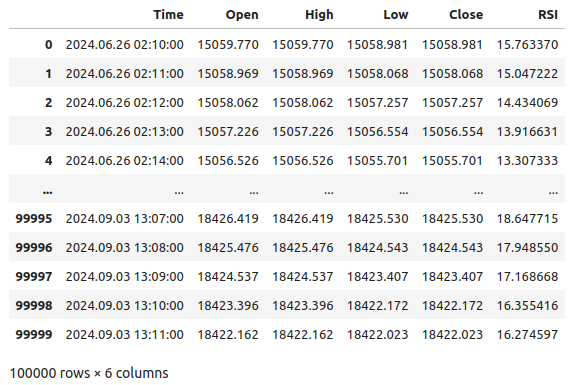
図1:Boom 1000市場データ
ここで、予測期間を定義してみましょう。
#Define how far into the future we should forecast look_ahead = 20
ここで、予測期間を定義し、可視化とプロットの目的でデータに追加のラベルを追加する必要があります。
#Let's add targets and labels for plotting boom_1000["Price Target"] = boom_1000["Close"].shift(-look_ahead) boom_1000["RSI Target"] = boom_1000["RSI"].shift(-look_ahead) #Let's also add binary targets for plotting purposes boom_1000["Price Binary Target"] = np.nan boom_1000["RSI Binary Target"] = np.nan #Label the binary targets boom_1000.loc[boom_1000["Price Target"] < boom_1000["Close"],"Price Binary Target"] = 0 boom_1000.loc[boom_1000["Price Target"] > boom_1000["Close"],"Price Binary Target"] = 1 boom_1000.loc[boom_1000["RSI Target"] < boom_1000["RSI"],"RSI Binary Target"] = 0 boom_1000.loc[boom_1000["RSI Target"] > boom_1000["RSI"],"RSI Binary Target"] = 1 #Drop na values boom_1000.dropna(inplace=True)
ここで、モデル入力と比較する2つのターゲットを定義しましょう。
#Define the predictors and targets predictors = ["Open","High","Low","Close","RSI"] old_target = "Price Binary Target" new_target = "RSI Binary Target"
探索的データ分析
必要なライブラリをインポートしましょう。
#Exploratory data analysis import seaborn as sns
使用されているライブラリのバージョンを表示します。
print(f"Seaborn version {sns.__version__}") Seaborn version 0.13.2RSIによって生成される信号の純度を評価してみましょう。ここで言う純度とは、「RSIレベルが下がれば、価格レベルも下がるのか」という疑問に対する答えです。この量を計算するには、まずRSIとPrice Binary Targetが一致しなかったインスタンスの数を数え、次にこの数をデータセット全体の行数で割ります。この量を1から引くと、RSIとPrice Binary Targetが一致したインスタンスの合計割合が算出されます。計算によると、83%の確率でRSIとPriceは同じ方向に変化しているようです。
#Let's assess the purity of the signals generated
rsi_purity = 1 - boom_1000.loc[boom_1000["RSI Binary Target"] != boom_1000["Price Binary Target"]].shape[0] / boom_1000.shape[0]
print(f"Price and the RSI tend to move together {rsi_purity * 100}% of the time")
この量はかなり高いため、データを可視化する際に良好なレベルの分離が得られるというある程度の信頼度が得られます。まず、X軸でRSIレベルが下がった(列0)または上がった(列1)すべてのインスタンスをまとめたカテゴリプロットを作成し、終値をY軸にとります。その後、各ポイントを青またはオレンジに色付けして、Boom 1000の価格レベルがそれぞれ上昇または下落したインスタンスを示します。下のプロットからわかるように、列0は主に青で、オレンジ色の点がいくつか散在しています。列1ではその逆になっています。これは、RSIがここでは価格変動の適切な区切りであることを示しています。ただし、完璧ではないため、将来的には追加の指標が必要になる可能性があります。
#Let's see this purity level we just calculated sns.catplot(data=boom_1000,x="RSI Binary Target",y="Close",hue="Price Binary Target")
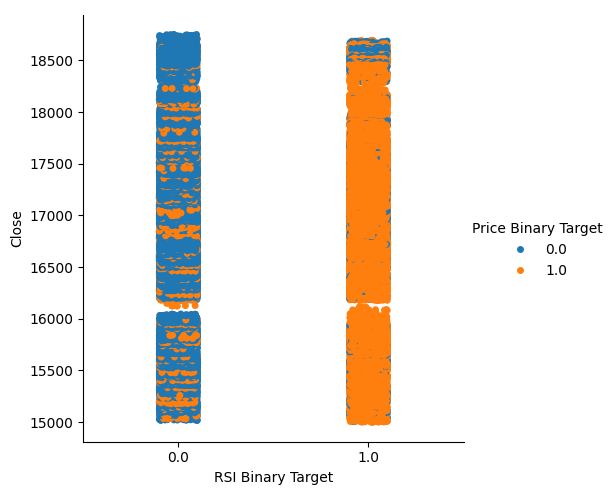
図2:RSIがデータをどれだけうまく分割しているかを示すカテゴリプロット
また、RSI とBoom 1000の終値の関係を視覚化するために散布図も作成しました。残念ながら、ご覧のとおり、この2つの間には関係がないようです。青とオレンジの点がランダムに交互に並ぶ長いスパゲッティのような跡が見られますが、これはターゲットに影響を与える他の変数があることを示している可能性があります。
#Let us also observe a scatter plot of the two sns.scatterplot(data=boom_1000,x="RSI",y="Close",hue="Price Binary Target")
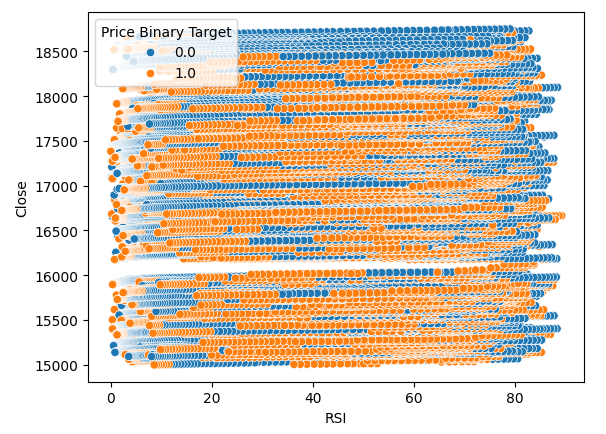
図3:終値とRSI値の散布図
おそらく、可視化しようとしている関係は 2 次元では確認できないので、データを 3 次元で可視化してみましょう。そうすれば、見逃していた隠れた相互作用効果を観察できるかもしれません。
必要なライブラリをインポートします。
#Let's create 3D scatter plots import matplotlib.pyplot as plt
プロットするデータの量を定義します。
#Define the plot end end = 10000
次に、3D散布図を作成します。残念ながら、データはランダムに分布しているように見え、有利に活用できる目立ったパターンは見当たりません。
#Visualizing our data in 3D fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'red' for movement in boom_1000.loc[0:end,"Price Binary Target"]] ax.scatter(boom_1000.loc[0:end,"RSI"],boom_1000.loc[0:end,"High"],boom_1000.loc[0:end,"Close"],c=colors) ax.set_xlabel('Boom 1000 RSI') ax.set_ylabel('Boom 1000 High') ax.set_zlabel('Boom 1000 Close')
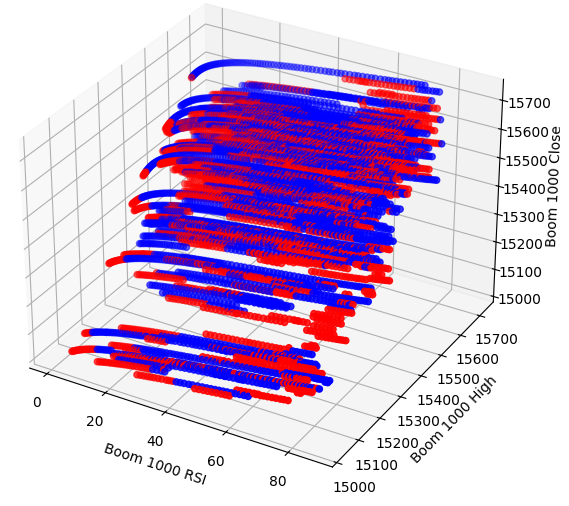
図4:Boom 1000市場の3D散布図とRSIとの関係
ここで、RSIと価格データ間の相関レベルを分析してみましょう。相関レベルはかなり低く、正確にはほぼ0です。
#Let's analyze the correlation levels sns.heatmap(boom_1000.loc[:,predictors].corr(),annot=True)
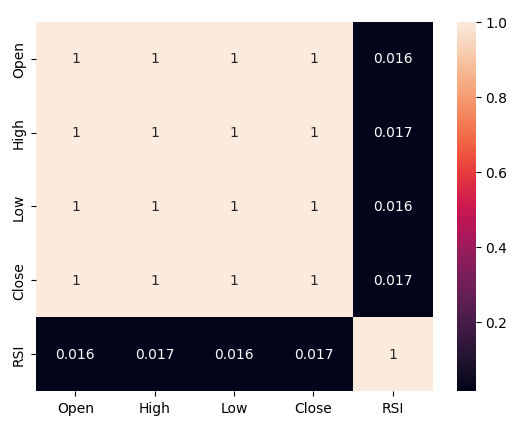
図5:相関行列のヒートマップ
データのモデル化の準備
データのモデリングを始める前に、まずデータをスケーリングして標準化する必要があります。まず、必要なライブラリをインポートしましょう。
#Preparing to model the data import sklearn from sklearn.preprocessing import RobustScaler from sklearn.neural_network import MLPClassifier,MLPRegressor from sklearn.model_selection import TimeSeriesSplit, train_test_split from sklearn.metrics import accuracy_score
ライブラリのバージョンを表示します。
#Display library version print(f"Sklearn version {sklearn.__version__}")
データをスケーリングします。
#Scale our data
X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:,predictors]),columns=predictors)
古い目標と新しい目標を定義します。
#Our old and new target old_y = boom_1000.loc[:,"Price Binary Target"] new_y = boom_1000.loc[:,"RSI Binary Target"]
訓練とテスト用に分割します。
#Perform train test splits train_X,test_X,ohlc_train_y,ohlc_test_y = train_test_split(X,old_y,shuffle=False,test_size=0.5) _,_,rsi_train_y,rsi_test_y = train_test_split(X,new_y,shuffle=False,test_size=0.5)
検証における精度レベルを保存するためのデータフレームを準備します。
#Prepare data frames to store our accuracy levels validation_accuracy = pd.DataFrame(index=np.arange(0,5),columns=["Close Accuracy","RSI Accuracy"])
次に、時系列スピットオブジェクトを作成します。
#Let's create the time series split object tscv = TimeSeriesSplit(gap=look_ahead,n_splits=5)
データのモデリング
これで、交差検証を実行して、2つのターゲット間の精度レベルの変化を観察する準備が整いました。
#Instatiate the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) #Cross validate the model for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],:],ohlc_train_y.loc[train[0]:train[-1]]) validation_accuracy.iloc[i,0] = accuracy_score(ohlc_train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],:]))
以下が精度レベルです。
validation_accuracy
| 近接精度 | RSIの精度 |
|---|---|
| 0.53703 | 0.663186 |
| 0.544592 | 0.623575 |
| 0.479534 | 0.597647 |
| 0.57064 | 0.651422 |
| 0.545913 | 0.616373 |
平均精度レベルは、RSI値の変化を予測する方がよい可能性があることを即座に示しています。
validation_accuracy.mean()
RSI Accuracy 0.630441
dtype: object
標準偏差が低いほど、モデルの予測の確実性が高まります。モデルは、価格の変化よりも確実にRSIを予測することを学習したようです。
validation_accuracy.std()
RSI Accuracy 0.026613
dtype: object
それぞれのモデルのパフォーマンスをプロットしてみましょう。
validation_accuracy.plot()
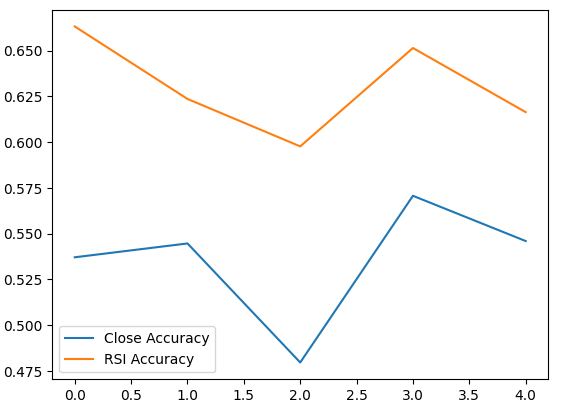
図6:検証精度の可視化
最後に、ボックスプロットは2つのモデル間のパフォーマンスの違いを観察するのに役立ちます。ご覧のとおり、RSIモデルはPriceモデルをはるかに上回るパフォーマンスを発揮しています。
#Our RSI validation accuracy is better
sns.boxplot(validation_accuracy)
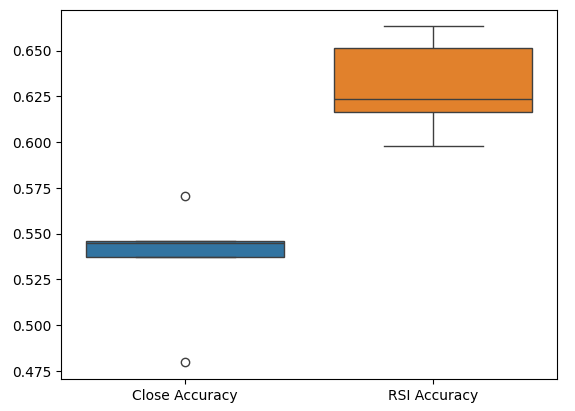
図7:検証の精度を示すボックスプロット
特徴量の重要性
RSI値を予測するためにどの特徴量が重要であるかを分析しましょう。まず、ニューラルネットワークで前進選択を実行します。前進選択はヌルモデルから開始し、モデルのパフォーマンスをこれ以上強化できなくなるまで、一度に1つの特徴量を順番に追加します。まず、必要なライブラリをインポートします。
#Feature importance import mlxtend from mlxtend.feature_selection import SequentialFeatureSelector as SFS
ライブラリのバージョンを表示します。
print(f"Mlxtend version: {mlxtend.__version__}")
モデルを再初期化します。
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
特徴量選択器を設定します。
#Define the forward feature selector sfs1 = SFS( model, k_features=(1,X.shape[1]), n_jobs=-1, forward=True, cv=5, scoring="accuracy" )
特徴量選択器を適合させます。
#Fit the feature selector
sfs = sfs1.fit(train_X,rsi_train_y)
特定された最も重要な特徴量を見てみましょう。利用可能な特徴量がすべて選択されました。
sfs.k_feature_names_
特徴量選択プロセスを可視化してみましょう。まず、必要なライブラリをインポートします。
#Importing the libraries we need from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
次に結果をプロットします。
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_err')
plt.title('Sequential Forward Selection')
plt.grid()
plt.show()
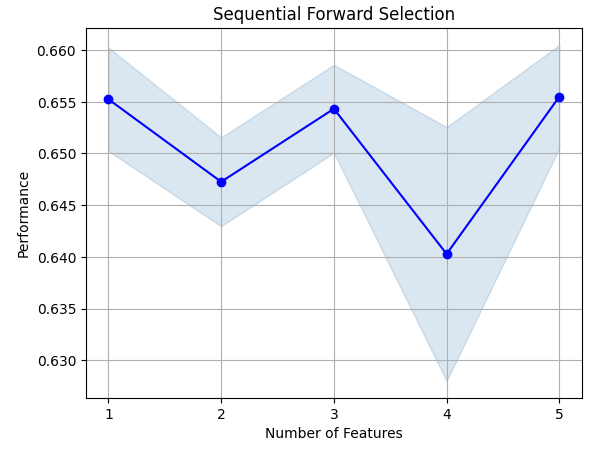
図8:特徴量選択プロセスの可視化
相互情報量(MI)により、各予測子の潜在能力を理解することができます。MIスコアが高いほど、一般的に予測子の有用性が高まります。MIは、データ内の非線形依存関係を捉えることができます。最後に、MIは対数スケールであるため、実際には3を超えるMIスコアはめったに見られません。
必要なライブラリをインポートします。
#Let's analyze our MI scores from sklearn.feature_selection import mutual_info_classif
MIスコアを計算します。
mi_scores = pd.DataFrame(mutual_info_classif(train_X,rsi_train_y).reshape(1,5),columns=predictors)
結果をプロットすると、MIによるとRSI列が最も重要な列であることがわかります。
#Let's visualize the results mi_scores.plot.bar()
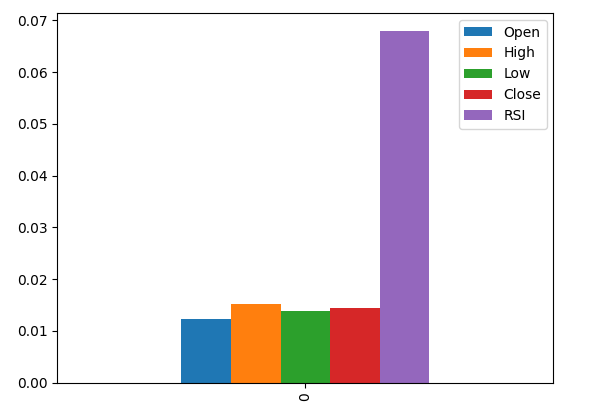
図9:MIスコアの可視化
パラメータ調整
ここで、モデルを調整して、さらにパフォーマンスを向上させてみます。sklearnライブラリのRandomizedSearchCVモジュールを使用すると、機械学習モデルを簡単に調整できます。機械学習モデルを調整する場合、精度と計算時間の間でトレードオフが発生します。この2つを決定するために、反復の合計回数を調整します。必要なライブラリをインポートしましょう。
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV
モデルを初期化します。
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
チューナーオブジェクトを定義します。
#Define the tuner tuner = RandomizedSearchCV( model, { "activation":["relu","tanh","logistic","identity"], "solver":["adam","sgd","lbfgs"], "alpha":[0.1,0.01,0.001,0.00001,0.000001], "learning_rate": ["constant","invscaling","adaptive"], "learning_rate_init":[0.1,0.01,0.001,0.0001,0.000001,0.0000001], "power_t":[0.1,0.5,0.9,0.01,0.001,0.0001], "shuffle":[True,False], "tol":[0.1,0.01,0.001,0.0001,0.00001], }, n_iter=300, cv=5, n_jobs=-1, scoring="accuracy" )
チューナーオブジェクトを適合させます。
#Fit the tuner
tuner_results =tuner.fit(train_X,rsi_train_y)
以下が、見つかった最良のパラメータです。
#Best parameters
tuner_results.best_params_ 'solver': 'lbfgs',
'shuffle':True,
'power_t':0.0001,
'learning_rate_init':0.01,
'learning_rate': 'adaptive',
'alpha':1e-06,
'activation': 'logistic'}
過剰適合のテスト
過剰適合をテストするには、検証データでデフォルトモデルとカスタマイズしたモデルを交差検証します。デフォルトモデルのパフォーマンスが優れている場合は、訓練セットが過剰適合されたことがわかります。それ以外の場合は、ハイパーパラメータの調整が正常に実行されたことを意味します。
2つのモデルを初期化します。
#Testing for overfitting default_model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) customized_model = MLPClassifier( hidden_layer_sizes=(30,10), max_iter=200, tol=0.00001, solver="lbfgs", shuffle=True, power_t=0.0001, learning_rate_init=0.01, learning_rate="adaptive", alpha=0.000001, activation="logistic" )
両方のモデルを訓練データに適合させます。
#First we will train both models on the training set
default_model.fit(train_X,rsi_train_y)
customized_model.fit(train_X,rsi_train_y)
両方のデータセットのインデックスをリセットします。
#Now we will reset our indexes
rsi_test_y = rsi_test_y.reset_index()
test_X = test_X.reset_index()
データを書式設定します。
#Format the data rsi_test_y = rsi_test_y.loc[:,"RSI Binary Target"] test_X = test_X.loc[:,predictors]
精度レベルを保存するためのデータフレームを準備します。
#Prepare a data frame to store our accuracy levels validation_error = pd.DataFrame(index=np.arange(0,5),columns=["Default Neural Network","Customized Neural Network"])
各モデルを交差検証して過剰適合をテストします。
#Perform cross validation for i,(train,test) in enumerate(tscv.split(test_X)): customized_model.fit(test_X.loc[train[0]:train[-1],predictors],rsi_test_y.loc[train[0]:train[-1]]) validation_error.iloc[i,1] = accuracy_score(rsi_test_y.loc[test[0]:test[-1]],customized_model.predict(test_X.loc[test[0]:test[-1]]))
以下は、検証におけるパフォーマンスレベルです。
validation_error
| デフォルトのニューラルネットワーク | カスタマイズされたニューラルネットワーク |
|---|---|
| 0.627656 | 0.597767 |
| 0.637258 | 0.635938 |
| 0.621414 | 0.631977 |
| 0.6429 | 0.6411 |
| 0.664866 | 0.652503 |
平均パフォーマンス レベルを分析すると、デフォルトのモデルがカスタマイズされたモデルよりもわずかに優れていることが明確にわかります。
validation_error.mean()
Customized Neural Network 0.631857
dtype: object
さらに、カスタマイズされたモデルは、精度スコアのばらつきが少ないため、より高いスキルを発揮しました。
validation_error.std()
Customized Neural Network 0.020557
dtype: object
結果をグラフにしてみましょう。
validation_error.plot()
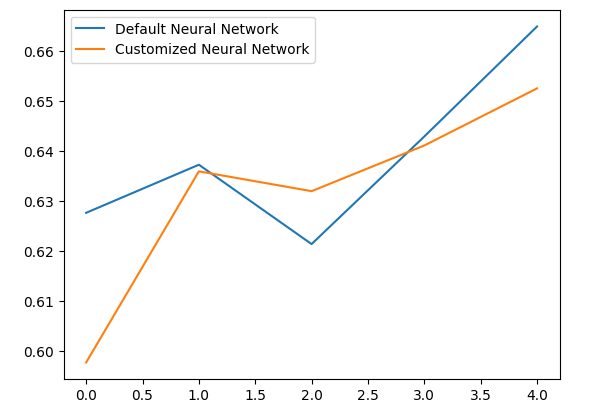
図10:過剰適合のテストを可視化する
ボックスプロットを見ると、カスタマイズされたモデルは安定性が低く、デフォルトモデルでは確認できない外れ値があることがわかります。さらに、デフォルトモデルの方が平均パフォーマンスがわずかに優れています。したがって、カスタマイズされたモデルよりもデフォルトモデルを選択します。
sns.boxplot(validation_error)
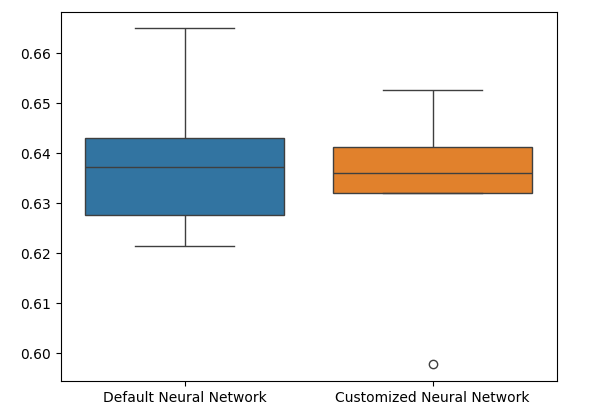
図11:過剰適合のテストを可視化する II
ONNXへのエクスポートの準備
モデルをONNX形式にエクスポートする前に、まずMetaTrader 5端末で再現できるようにデータをスケーリングする必要があります。各列から列の平均を減算し、列の標準偏差で割ります。これにより、データが異なるスケールにあるため、モデルが効果的に学習することが保証されます。また、平均値と標準偏差値をCSV形式でエクスポートして、後で取得できるようにします。#Preparing to export to ONNX #Let's scale our data scaling_factors = pd.DataFrame(columns=predictors,index=['mean','standard deviation']) X = boom_1000.loc[:,predictors] y = boom_1000.loc[:,"RSI Target"]
各列をスケーリングします。
#Let's fill each column for i in np.arange(0,len(predictors)): scaling_factors.iloc[0,i] = X.iloc[:,i].mean() scaling_factors.iloc[1,i] = X.iloc[:,i].std() X.iloc[:,i] = ( ( X.iloc[:,i] - scaling_factors.iloc[0,i] ) / scaling_factors.iloc[1,i])
スケーリン係数をCSV形式で保存します。
#Save the scaling factors as a CSV scaling_factors.to_csv("/home/volatily/.wine/drive_c/Program Files/MetaTrader 5/MQL5/Files/boom_1000_scaling_factors.csv")
ONNXへのエクスポート
Open Neural Network Exchange (ONNX)は、オープンソースの相互運用可能な機械学習フレームワークであり、開発者は、ONNX APIをサポートする任意のプログラミング言語で機械学習モデルを構築、共有、使用できます。これにより、Pythonで機械学習モデルを構築し、本番環境でMQL5に展開できます。まず、必要なライブラリをインポートします。
#Exporting to ONNX
import onnx
import netron
import skl2onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
ライブラリのバージョンを表示します。
#Display the library versions print(f"Onnx version {onnx.__version__}") print(f"Netron version {netron.__version__}") print(f"Skl2onnx version {skl2onnx.__version__}")
Netron version 7.8.0
Skl2onnxバージョン1.16.0
モデルの入力タイプを定義します。
#Define the model input types initial_types = [("float_input",FloatTensorType([1,5]))]
保有するすべてのデータにモデルを適合させます。
#Fit the model on all the data we have default_model = MLPRegressor(hidden_layer_sizes=(30,10),max_iter=200) default_model.fit(X,y)
モデルをONNX表現に変換します。
#Convert the model to an ONNX representation onnx_model = convert_sklearn(default_model,initial_types=initial_types,target_opset=12)
ONNX表現をファイルに保存します。
#Save the ONNX representation onnx_name = "Boom 1000 Neural Network.onnx" onnx.save(onnx_model,onnx_name)
netronを使用してモデルを表示します。
#View the onnx model
netron.start(onnx_name)

図12:ディープニューラルネットワークの可視化

図13:モデルの入力と出力を可視化する
MQL5での実装
統合されたAIシステムを備えた取引アプリケーションを構築するには、まずPythonでエクスポートしたONNXモデルが必要になります。
//+------------------------------------------------------------------+ //| Boom 1000.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/ja/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/ja/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| ONNX Model | //+------------------------------------------------------------------+ #resource "\\Files\\Boom 1000 Neural Network.onnx" as const uchar onnx_buffer[];
ポジションを管理するための取引ライブラリも読み込みます。
//+-----------------------------------------------------------------+ //| Libraries we need | //+-----------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
プログラム全体で使用するグローバル変数を定義します。
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; int rsi_handler,model_state,system_state; double mean_values[5],std_values[5],rsi_buffer[],bid,ask; vectorf model_outputs = vectorf::Zeros(1); vectorf model_inputs = vectorf::Zeros(5);
ここで、ONNXモデルを準備するための関数を定義しましょう。この関数は、まずプログラムの先頭で定義したバッファからモデルを作成し、モデルが破損していないことを検証します。破損している場合、関数はfalseを返して初期化手順を終了します。その後、関数はONNXモデルの入力と出力の形状の設定に進みます。I/Oパラメータのいずれかを定義できなかった場合、関数は再びfalseを返して初期化手順を終了します。
//+------------------------------------------------------------------+ //| This function will prepare our ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- First create the ONNX model from the buffer we created earlier onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the ONNX model if(onnx_model == INVALID_HANDLE) { Comment("[ERROR] Failed to create the ONNX model: ",GetLastError()); return(false); } //--- Set the input and output shapes of the model ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the input and output shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape: ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape: ",GetLastError()); return(false); } return(true); }
モデル入力をスケーリングせずにONNXモデルを使用することはできません。次の関数は、必要な平均値と標準偏差値を、簡単にアクセスできる配列に読み込みます。
//+-----------------------------------------------------------------+ //| Load the scaling values | //+-----------------------------------------------------------------+ void load_scaling_values(void) { //--- BOOM 1000 OHLC + RSI Mean values mean_values[0] = 16799.87389394667; mean_values[1] = 16800.872890865994; mean_values[2] = 16798.91007345616; mean_values[3] = 16799.908906749482; mean_values[4] = 43.45867626462568; //--- BOOM 1000 OHLC + RSI Mean std values std_values[0] = 864.3356132780019; std_values[1] = 864.3839684000297; std_values[2] = 864.2859346216392; std_values[3] = 864.3344430387272; std_values[4] = 20.593175501388043; } //+------------------------------------------------------------------+
また、更新された市場価格と現在のテクニカル指標値を取得する関数を定義する必要があります。
//+------------------------------------------------------------------+ //| Fetch updated market prices and technical indicator values | //+------------------------------------------------------------------+ void update_market_data(void) { //--- Market data bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); //--- Technical indicator values CopyBuffer(rsi_handler,0,0,1,rsi_buffer); }
最後に、モデルの入力を取得し、スケーリングして、モデルから予測を取得する関数が必要です。モデルの予測を記憶するためのフラグを保持します。これにより、モデルが反転を予測しているときに簡単に認識できるようになります。
//+------------------------------------------------------------------+ //| Fetch a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { //--- Get the model inputs model_inputs[0] = iOpen(_Symbol,PERIOD_CURRENT,0); model_inputs[1] = iHigh(_Symbol,PERIOD_CURRENT,0); model_inputs[2] = iLow(_Symbol,PERIOD_CURRENT,0); model_inputs[3] = iClose(_Symbol,PERIOD_CURRENT,0); model_inputs[4] = rsi_buffer[0]; //--- Scale the model inputs for(int i = 0; i < 5; i++) { model_inputs[i] = ((model_inputs[i] - mean_values[i]) / std_values[i]); } //--- Fetch a prediction from our model OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs); //--- Give user feedback Comment("Model RSI Forecast: ",model_outputs[0]); //--- Store the model's state if(rsi_buffer[0] > model_outputs[0]) { model_state = -1; } else if(rsi_buffer[0] < model_outputs[0]) { model_state = 1; } }
ここで、モデルの初期化手順を定義します。まず、ONNXモデルを読み込み、スケーリング値を取得してRSI指標を設定します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- This function will prepare our ONNX model and set the input and output shapes if(!load_onnx_model()) { return(INIT_FAILED); } //--- This function will prepare our scaling values load_scaling_values(); //--- Setup our technical indicatot rsi_handler = iRSI(Symbol(),PERIOD_CURRENT,20,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
アプリケーションがチャートから削除されるたびに、使用しなくなったリソースを解放し、ONNXモデル、RSI指標をリリースし、EAを削除します。
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the resources we no longer need OnnxRelease(onnx_model); IndicatorRelease(rsi_handler); ExpertRemove(); }
更新された価格を受け取るたびに、まず更新された市場データと技術データを取得します。これには、Bid価格とAsk価格、およびRSIの読み取り値が含まれます。これで、モデルから新しい予測を取得する準備が整いました。ポジションがない場合は、モデルの予測に従い、バイナリフラグを使用して現在のポジションを記憶します。そうでない場合、すでにポジションが建っている場合は、モデルの新しい予測がポジションに反するかどうかを確認し、反している場合はポジションをクローズします。そうでない場合は、利益確定を続けます。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated market prices update_market_data(); //--- On every tick we need to fetch a prediction from our model model_predict(); //--- If we have no open positions, follow the model's prediction if(PositionsTotal() == 0) { //--- Our model detected a spike if(model_state == 1) { Trade.Buy(0.2,Symbol(),ask,0,0,"BOOM 1000 AI"); system_state = 1; } //--- Our model detected a drop if(model_state == -1) { Trade.Sell(0.2,Symbol(),bid,0,0,"BOOM 1000 AI"); system_state = -1; } } //--- If we have open positiosn, our AI system will decide when to close them else if(PositionsTotal() > 0) { if(system_state != model_state) { //--- Close the positions we opened Alert("Reversal detected by the AI system,closing all positions now!"); Trade.PositionClose(Symbol()); } } } //+------------------------------------------------------------------+

図14:Boom 1000システムがスパイクを検出

図15:Boom 1000システムが逆転を検出
結論
本日の記事では、最も難しい合成商品にも対応できる自己最適化EAを構築できることを実証しました。さらに、価格レベルを直接予測する従来のアプローチでは、今日のアルゴリズム市場では不十分であることも示しました。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/15781
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 Connexus入門(第1回):WebRequest関数の使い方
Connexus入門(第1回):WebRequest関数の使い方
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
最も有名なBoom1000から始めて、すべてのデリバティブ合成市場を個別に分析する。
記事をありがとうございました!長い間、これらの指数に注目してきましたが、どの側面からアプローチすればよいのかわかりませんでした。
これからもよろしくお願いします!
いくつかのツールを試しましたが、どのツールでも、入力データ(X)とターゲット変数(y)の次元が不一致のため、 このモデルではエラーが 発生しました。
記事を本当にありがとう!私は長い間、このようなインデックスを分析してきましたが、どこにアプローチすればいいのかわかりませんでした。
これからもよろしくお願いします!
どういたしまして、ジャニス。
必ず続けます。取り上げたいことはたくさんあるけど、時間を作るよ。
いくつかのツールを試しましたが、どのツールでも、 入力データ (X) とターゲット変数 (y) のサイズが一致しないため、 あなたのモデルは エラーを 出します。
Aliaksandrさん、こんにちは。代わりに、コードをテンプレートガイドとして使用し、必要な調整をあなた側で行うことができます。また、さまざまなインジケータを試して、記事の一般的なアイデアのさまざまなバリエーションを試してみることをお勧めします。そうすれば、グローバルな真実をより早く理解することができるでしょう。
いくつかのツールを試したが、いずれも入力データ(X)とターゲット変数(y)のサイズの不一致のためにモデルがエラーになってしまう。
# そうしないと、フィルタリングされたデータがある場合、インデックスが再構築される。 X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:, predictors]), columns=predictors, index=boom_1000.index)