
Самооптимизирующийся советник на языках MQL5 и Python (Часть III): Реализация алгоритма Boom 1000

Мы проанализируем все синтетические рынки Deriv по отдельности, начав с самого известного — Boom 1000. Boom 1000 печально известен своим нестабильным и непредсказуемым поведением. Рынок характеризуется медленными, короткими и одинаковыми по размеру медвежьими свечами, за которыми случайным образом следуют бычьи свечи размером с небоскреб. Смягчить последствия бычьих свечей особенно сложно, поскольку тики, связанные со свечой, обычно не отправляются на клиентский терминал, а это означает, что все стоп-лоссы каждый раз срабатывают с гарантированным проскальзыванием.
Поэтому большинство успешных трейдеров используют стратегии, в основе которых лежит только покупка при торговле Boom 1000. Boom 1000 может падать в течение 20 минут на графике M1 и отыграть всё это падение за одну свечу! Таким образом, учитывая чрезмерно выраженный бычий характер рынка, успешные трейдеры придают больший вес покупке на Boom 1000.
С другой стороны, если мы просто создадим новую зависимую переменную, значение которой зависит от уровня цен синтетического инструмента Deriv, мы, возможно, создадим новую взаимосвязь, которую сможем смоделировать с большей точностью, чем сам индекс Boom 1000. Другими словами, если мы применим индикаторы к рынку и смоделируем связь индикатора с рынком, мы можем получить более высокий уровень точности. Будем надеяться, что наша новая цель не только обеспечит нам более высокий уровень точности, но и, кроме того, будет верным отражением фактических изменений цен. То есть, если ожидается, что показания индикатора упадут, то и цена должна упасть. Напомним, что машинное обучение сосредоточено на аппроксимации функции, исходя из предположения, что у нас есть входные данные этой функции, при том что у нас нет никаких входных данных, которые Deriv использует в своем алгоритме генератора случайных чисел. Применяя индикатор к их рынку, мы получаем доступ ко всем входным данным, от которых зависит индикатор.
Обзор методологии
Чтобы оценить жизнеспособность предлагаемой стратегии, мы извлекли 100 000 строк данных M1 и показания индикатора RSI для каждого из этих случаев из терминала MetaTrader 5, используя специальный скрипт. После считывания скрипта был проведен предварительный анализ данных. Мы обнаружили, что в 83% случаев, когда значения RSI падают, уровни цен на Boom 1000 также падают. То есть значение RSI дает нам представление о том, где будут находиться уровни цен. Однако это также означает, что примерно в 17% случаев RSI будет вводить нас в заблуждение.
Мы наблюдали слабые уровни корреляции между RSI и уровнями цен Boom 1000, показания составили 0.016. Ни одна из построенных нами диаграмм рассеяния не выявила каких-либо различимых связей в данных. Мы даже попытались построить графики в более высоких измерениях, но и это ничего не дало: данные оказалось довольно сложно эффективно разделить.
На этом наши усилия не закончились: впоследствии мы разделили наш набор данных на две половины: одну половину для обучения и оптимизации, а вторую — для проверки и тестирования на переобучение. Мы также создали два целевых показателя: один отражал изменения ценовых уровней, а второй — изменения значений RSI.
Мы приступили к обучению двух идентичных классификаторов на основе глубоких нейронных сетей для прогнозирования изменений уровней цен и уровней RSI соответственно. Первая модель достигла уровня точности около 53%, а вторая — около 63%. Более того, дисперсия наших уровней ошибок при прогнозировании изменений RSI была ниже, что говорит о том, что последняя модель могла обучаться более эффективно. К сожалению, нам не удалось настроить нашу глубокую нейронную сеть без переобучения на обучающем наборе. Об этом свидетельствует тот факт, что нам не удалось превзойти нейронную сеть по умолчанию на невидимых проверочных данных. Мы провели 5-кратную перекрестную проверку временных рядов без случайного перемешивания, чтобы измерить уровень точности как при обучении, так и при проверке.
Мы выбрали модель RSI по умолчанию как наиболее эффективную, экспортировали ее в формат ONNX и, наконец, создали наш специализированный советник Boom 1000 на базе искусственного интеллекта на языке MQL5.
Извлечение данных
Для начала нам необходимо извлечь необходимые данные из нашего терминала MetaTrader 5. Эту задачу выполняет наш удобный скрипт MQL5. Написанный мной скрипт будет извлекать рыночные котировки, связанные с Boom 1000, временную метку каждой свечи и соответствующие значения RSI, а затем записывать их в формате CSV. Обратите внимание, что мы устанавливаем буфер RSI как ряд перед записью данных. Этот шаг имеет решающее значение, иначе ваши данные RSI будут располагаться в обратном хронологическом порядке.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","RSI"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), rsi_buffer[i] ); Print("Time: ",iTime(Symbol(),PERIOD_CURRENT,i),"Close: ",iClose(Symbol(),PERIOD_CURRENT,i),"RSI",rsi_buffer[i]); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Очистка данных
Теперь мы готовы приступить к подготовке наших данных для визуализации. Сначала импортируем необходимые библиотеки.#Import the libraries we need import pandas as pd import numpy as np
Отобразим версии библиотек.
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}")
Numpy version 1.26.4
Теперь считаем CSV-файл.
#Read in the data we need boom_1000 = pd.read_csv("Market Data Boom 1000 Index.csv")
Посмотрим на данные.
#Let's see the data boom_1000
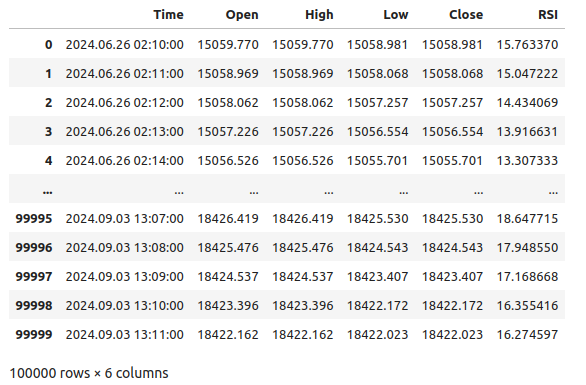
Рис. 1. Наши рыночные данные Boom 1000
Определим наш горизонт прогнозирования.
#Define how far into the future we should forecast look_ahead = 20
Теперь нам необходимо определить горизонт прогнозирования, а также добавить дополнительные метки к данным для визуализации и построения графиков.
#Let's add targets and labels for plotting boom_1000["Price Target"] = boom_1000["Close"].shift(-look_ahead) boom_1000["RSI Target"] = boom_1000["RSI"].shift(-look_ahead) #Let's also add binary targets for plotting purposes boom_1000["Price Binary Target"] = np.nan boom_1000["RSI Binary Target"] = np.nan #Label the binary targets boom_1000.loc[boom_1000["Price Target"] < boom_1000["Close"],"Price Binary Target"] = 0 boom_1000.loc[boom_1000["Price Target"] > boom_1000["Close"],"Price Binary Target"] = 1 boom_1000.loc[boom_1000["RSI Target"] < boom_1000["RSI"],"RSI Binary Target"] = 0 boom_1000.loc[boom_1000["RSI Target"] > boom_1000["RSI"],"RSI Binary Target"] = 1 #Drop na values boom_1000.dropna(inplace=True)
Теперь определим входные данные нашей модели и две цели, которые мы хотим сравнить.
#Define the predictors and targets predictors = ["Open","High","Low","Close","RSI"] old_target = "Price Binary Target" new_target = "RSI Binary Target"
Разведочный анализ данных
Импортируем необходимые библиотеки.
#Exploratory data analysis import seaborn as sns
Отображение версии используемой библиотеки.
print(f"Seaborn version {sns.__version__}") Seaborn version 0.13.2Давайте оценим чистоту сигналов, генерируемых RSI. Чистота в нашем понимании отвечает на вопрос: "Если уровень RSI упадет, упадут ли также и уровни цен?" Мы вычислили это количество, сначала подсчитав количество случаев, когда RSI и Price Binary Target не были равны друг другу, а затем разделив это количество на общее количество строк во всем наборе данных, это количество вычли из 1, чтобы получить общую долю случаев, когда RSI и Price Binary Target находились в гармонии. По нашим расчетам, в 83% случаев RSI и цена изменяются в одном и том же направлении.
#Let's assess the purity of the signals generated
rsi_purity = 1 - boom_1000.loc[boom_1000["RSI Binary Target"] != boom_1000["Price Binary Target"]].shape[0] / boom_1000.shape[0]
print(f"Price and the RSI tend to move together {rsi_purity * 100}% of the time")
Это количество довольно велико, и это дает нам некоторую уверенность в том, что мы сможем получить хорошие уровни разделения при визуализации данных. Давайте начнем с создания категориального графика, чтобы суммировать все случаи, когда уровень RSI падал (столбец 0) или рос (столбец 1) соответственно на оси X, в то время как цена закрытия отложена по оси Y. Затем мы раскрасили каждую точку синим или оранжевым цветом, чтобы обозначить случаи, когда уровни цен Boom 1000 соответственно росли или падали. Как видно из графика ниже, столбец 0 в основном синий с несколькими пятнами оранжевых точек, а для столбца 1 все наоборот. Это показывает нам, что RSI здесь является хорошим разделителем изменений цен. Однако он не идеален, в будущем нам может понадобиться дополнительный индикатор.
#Let's see this purity level we just calculated sns.catplot(data=boom_1000,x="RSI Binary Target",y="Close",hue="Price Binary Target")
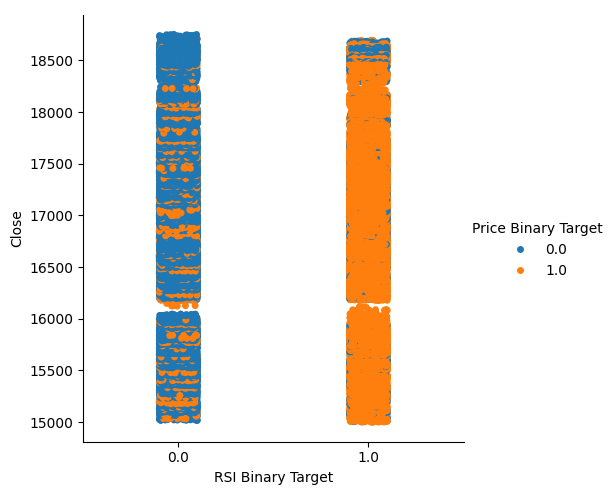
Рис. 2. Категориальный график, показывающий, насколько хорошо наш RSI разделяет наши данные
Мы также создали диаграмму рассеяния, чтобы попытаться визуализировать взаимосвязь между RSI и ценой закрытия Boom 1000. К сожалению, как мы видим, между ними, похоже, нет никакой связи. Мы наблюдаем длинные, похожие на спагетти следы из хаотично чередующихся синих и оранжевых точек. Это может указывать на то, что существуют и другие переменные, влияющие на целевую.
#Let us also observe a scatter plot of the two sns.scatterplot(data=boom_1000,x="RSI",y="Close",hue="Price Binary Target")
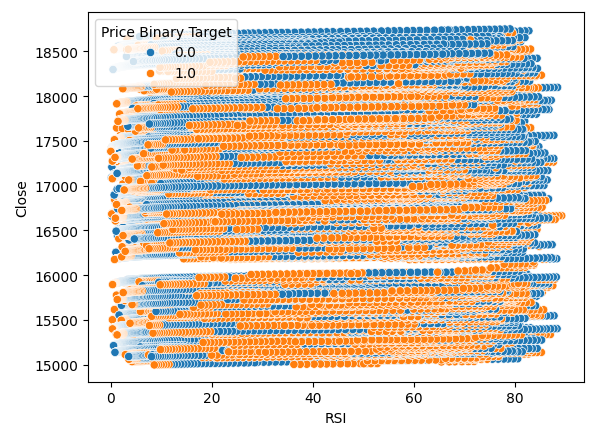
Рис. 3. Диаграмма рассеяния показаний RSI относительно цены закрытия
Возможно, взаимосвязь, которую мы пытаемся визуализировать, невозможно увидеть в двух измерениях. Давайте попробуем визуализировать данные в трех измерениях. Будем надеяться, что мы сможем увидеть скрытые эффекты взаимодействия.
Импортируем необходимые нам библиотеки.
#Let's create 3D scatter plots import matplotlib.pyplot as plt
Определите объем данных, которые необходимо отобразить.
#Define the plot end end = 10000
Теперь создадим трехмерную диаграмму рассеяния. К сожалению, мы по-прежнему видим, что данные распределены случайным образом, без каких-либо наблюдаемых закономерностей, которые мы могли бы использовать в своих интересах.
#Visualizing our data in 3D fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'red' for movement in boom_1000.loc[0:end,"Price Binary Target"]] ax.scatter(boom_1000.loc[0:end,"RSI"],boom_1000.loc[0:end,"High"],boom_1000.loc[0:end,"Close"],c=colors) ax.set_xlabel('Boom 1000 RSI') ax.set_ylabel('Boom 1000 High') ax.set_zlabel('Boom 1000 Close')
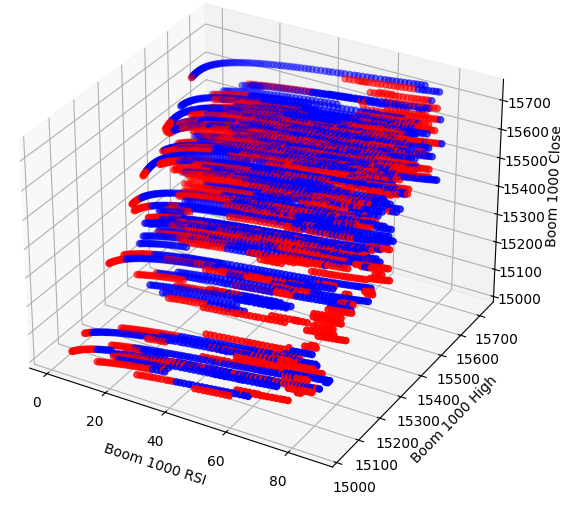
Рис. 4. Трехмерная диаграмма рассеяния рынка Boom 1000 и ее связь с RSI
Давайте теперь проанализируем уровни корреляции между RSI и нашими ценовыми данными. Мы наблюдаем довольно слабый уровень корреляции, если быть точным, почти нулевой.
#Let's analyze the correlation levels sns.heatmap(boom_1000.loc[:,predictors].corr(),annot=True)
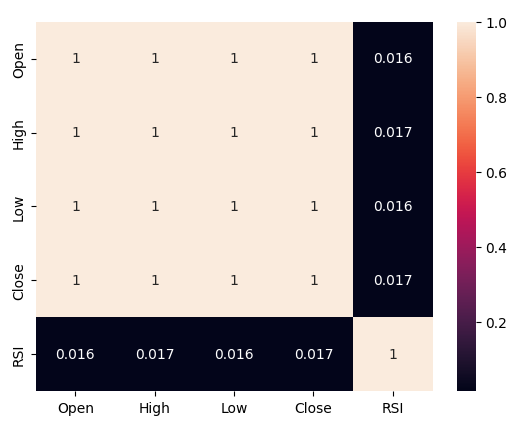
Рис. 5. Тепловая карта нашей корреляционной матрицы
Подготовка к моделированию данных
Прежде чем приступить к моделированию данных, нам необходимо масштабировать и стандартизировать данные. Сначала импортируем необходимые библиотеки.
#Preparing to model the data import sklearn from sklearn.preprocessing import RobustScaler from sklearn.neural_network import MLPClassifier,MLPRegressor from sklearn.model_selection import TimeSeriesSplit, train_test_split from sklearn.metrics import accuracy_score
Отобразим версию библиотеки.
#Display library version print(f"Sklearn version {sklearn.__version__}")
Масштабируем данные.
#Scale our data
X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:,predictors]),columns=predictors)
Определяем наши старые и новые цели.
#Our old and new target old_y = boom_1000.loc[:,"Price Binary Target"] new_y = boom_1000.loc[:,"RSI Binary Target"]
Выполним разделение на обучающие и тестовые данные.
#Perform train test splits train_X,test_X,ohlc_train_y,ohlc_test_y = train_test_split(X,old_y,shuffle=False,test_size=0.5) _,_,rsi_train_y,rsi_test_y = train_test_split(X,new_y,shuffle=False,test_size=0.5)
Подготовим фрейм данных для хранения наших уровней точности при проверке.
#Prepare data frames to store our accuracy levels validation_accuracy = pd.DataFrame(index=np.arange(0,5),columns=["Close Accuracy","RSI Accuracy"])
Теперь создадим объект TimeSeriesSpit.
#Let's create the time series split object tscv = TimeSeriesSplit(gap=look_ahead,n_splits=5)
Моделирование данных
Теперь мы готовы выполнить перекрестную проверку, чтобы проследить изменение уровней точности между двумя возможными целями.
#Instatiate the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) #Cross validate the model for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],:],ohlc_train_y.loc[train[0]:train[-1]]) validation_accuracy.iloc[i,0] = accuracy_score(ohlc_train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],:]))
Наши уровни точности.
validation_accuracy
| Точность закрытия | Точность RSI |
|---|---|
| 0,53703 | 0,663186 |
| 0,544592 | 0,623575 |
| 0,479534 | 0,597647 |
| 0,57064 | 0,651422 |
| 0,545913 | 0,616373 |
Наши средние уровни точности мгновенно показывают нам, что мы можем лучше прогнозировать изменения значения RSI.
validation_accuracy.mean()
RSI Accuracy 0.630441
dtype: object
Чем ниже стандартное отклонение, тем выше уверенность модели в своих прогнозах. Судя по всему, модель научилась прогнозировать RSI с большей уверенностью, чем изменения цены.
validation_accuracy.std()
RSI Accuracy 0.026613
dtype: object
Давайте построим график производительности каждой из наших моделей.
validation_accuracy.plot()
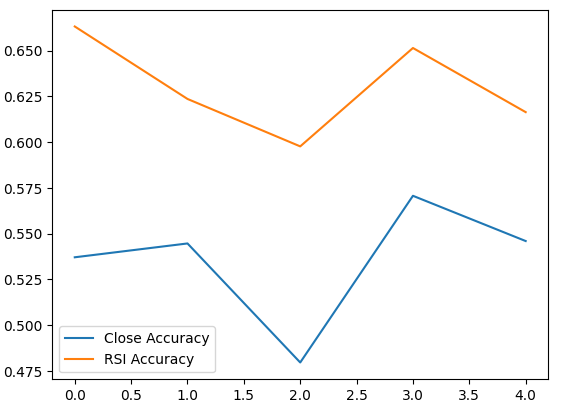
Рис. 6. Визуализация нашей точности проверки
Наконец, диаграммы размаха помогают нам наблюдать разницу в эффективности между нашими двумя моделями. Как мы видим, модель RSI намного превосходит модель цены.
#Our RSI validation accuracy is better
sns.boxplot(validation_accuracy)
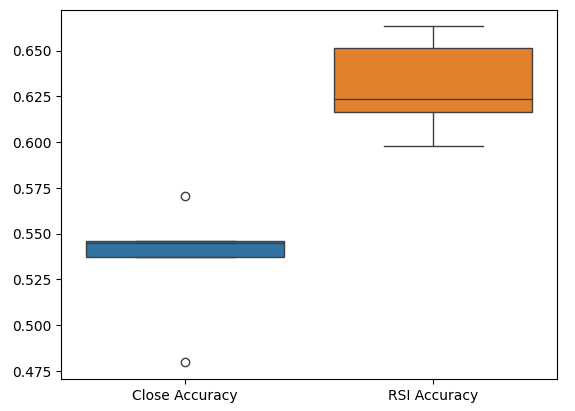
Рис. 7. Диаграммы размаха нашей точности проверки
Значимость признаков
Давайте теперь проанализируем, какие признаки важны для прогнозирования значения RSI. Начнем с прямого отбора в нашей нейронной сети. Прямой отбор начинается с нулевой модели и последовательно добавляет по одному признаку за раз до тех пор, пока невозможно будет внести дальнейшие улучшения в производительность модели.Сначала импортируем необходимые нам библиотеки.
#Feature importance import mlxtend from mlxtend.feature_selection import SequentialFeatureSelector as SFS
Отобразим версию библиотеки.
print(f"Mlxtend version: {mlxtend.__version__}")
Повторно инициализируем модель.
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
Настроим селектор признаков.
#Define the forward feature selector sfs1 = SFS( model, k_features=(1,X.shape[1]), n_jobs=-1, forward=True, cv=5, scoring="accuracy" )
Установим селектор признаков.
#Fit the feature selector
sfs = sfs1.fit(train_X,rsi_train_y)
Давайте рассмотрим наиболее важные признаки, которые мы выявили. Были выбраны все доступные признаки.
sfs.k_feature_names_
Визуализируем выбор признаков. Сначала импортируем необходимые нам библиотеки.
#Importing the libraries we need from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Отобразим результаты на графике.
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_err')
plt.title('Sequential Forward Selection')
plt.grid()
plt.show()
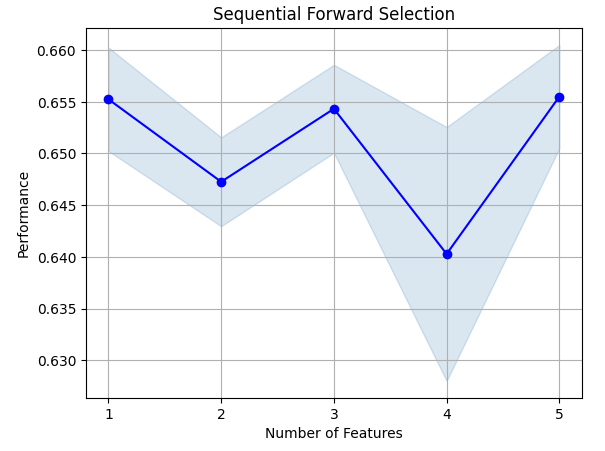
Рис. 8. Визуализация выбора признаков
Обмен данными (mutual information, MI) позволяет нам получить представление о потенциале каждого предиктора. Чем выше показатель MI, тем, как правило, более полезным может быть предиктор. MI может улавливать нелинейные зависимости в данных. Наконец, MI имеет логарифмическую шкалу, а это значит, что значение MI выше 3 редко встречаются на практике.
Импортируем необходимые нам библиотеки.
#Let's analyze our MI scores from sklearn.feature_selection import mutual_info_classif
Рассчитаем MI.
mi_scores = pd.DataFrame(mutual_info_classif(train_X,rsi_train_y).reshape(1,5),columns=predictors)
Столбец RSI является наиболее важным по данным MI.
#Let's visualize the results mi_scores.plot.bar()
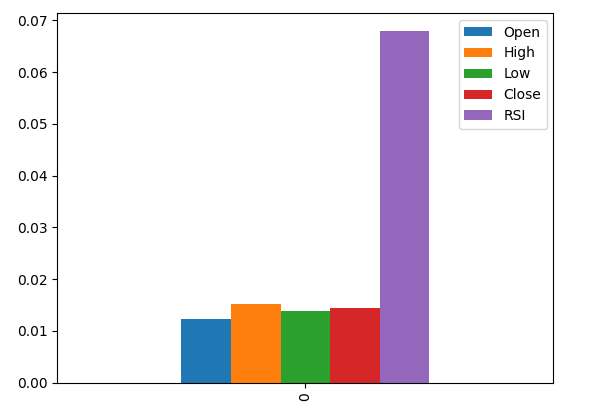
Рис. 9. Визуализация наших значений MI
Настройка параметров
Попытаемся настроить нашу модель, чтобы добиться от нее еще большей производительности. Модуль RandomizedSearchCV в библиотеке sklearn позволяет нам легко настраивать наши модели машинного обучения. При настройке моделей машинного обучения приходится искать компромисс между точностью и временем вычислений. Скорректируем общее количество итераций, чтобы сделать выбор между ними. Импортируем необходимые библиотеки.
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV
Инициализируем модель.
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
Определим объект тюнера.
#Define the tuner tuner = RandomizedSearchCV( model, { "activation":["relu","tanh","logistic","identity"], "solver":["adam","sgd","lbfgs"], "alpha":[0.1,0.01,0.001,0.00001,0.000001], "learning_rate": ["constant","invscaling","adaptive"], "learning_rate_init":[0.1,0.01,0.001,0.0001,0.000001,0.0000001], "power_t":[0.1,0.5,0.9,0.01,0.001,0.0001], "shuffle":[True,False], "tol":[0.1,0.01,0.001,0.0001,0.00001], }, n_iter=300, cv=5, n_jobs=-1, scoring="accuracy" )
Установим объект тюнера.
#Fit the tuner
tuner_results =tuner.fit(train_X,rsi_train_y)
Лучшие параметры, которые мы нашли.
#Best parameters
tuner_results.best_params_ 'solver': 'lbfgs',
'shuffle': True,
'power_t': 0.0001,
'learning_rate_init': 0.01,
'learning_rate': 'adaptive',
'alpha': 1e-06,
'activation': 'logistic'}
Проверка на переобучение
Для проверки на переобучение мы проведем перекрестную проверку модели по умолчанию и нашей настроенной модели на проверочных данных. Если наша модель по умолчанию работает лучше, то мы поймем, что мы переобучили обучающий набор. В противном случае мы успешно выполнили настройку гиперпараметров.
Инициализируем две модели.
#Testing for overfitting default_model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) customized_model = MLPClassifier( hidden_layer_sizes=(30,10), max_iter=200, tol=0.00001, solver="lbfgs", shuffle=True, power_t=0.0001, learning_rate_init=0.01, learning_rate="adaptive", alpha=0.000001, activation="logistic" )
Подгоним обе модели под обучающие данные.
#First we will train both models on the training set
default_model.fit(train_X,rsi_train_y)
customized_model.fit(train_X,rsi_train_y)
Сбросим индексы в обоих наборах данных.
#Now we will reset our indexes
rsi_test_y = rsi_test_y.reset_index()
test_X = test_X.reset_index()
Отформатируем данные.
#Format the data rsi_test_y = rsi_test_y.loc[:,"RSI Binary Target"] test_X = test_X.loc[:,predictors]
Подготовим фрейм данных для хранения наших уровней точности.
#Prepare a data frame to store our accuracy levels validation_error = pd.DataFrame(index=np.arange(0,5),columns=["Default Neural Network","Customized Neural Network"])
Проведем перекрестную проверку каждой модели для проверки на переобучение.
#Perform cross validation for i,(train,test) in enumerate(tscv.split(test_X)): customized_model.fit(test_X.loc[train[0]:train[-1],predictors],rsi_test_y.loc[train[0]:train[-1]]) validation_error.iloc[i,1] = accuracy_score(rsi_test_y.loc[test[0]:test[-1]],customized_model.predict(test_X.loc[test[0]:test[-1]]))
Наши уровни производительности при валидации.
validation_error
| Нейронная сеть по умолчанию | Настраиваемая нейронная сеть |
|---|---|
| 0,627656 | 0,597767 |
| 0,637258 | 0,635938 |
| 0,621414 | 0,631977 |
| 0,6429 | 0,6411 |
| 0,664866 | 0,652503 |
Анализ наших средних уровней производительности ясно показывает, что модель по умолчанию оказалась немного лучше, чем настроенная нами модель.
validation_error.mean()
Customized Neural Network 0.631857
dtype: object
Кроме того, наша индивидуальная модель продемонстрировала большую точность благодаря меньшей дисперсии показателей точности.
validation_error.std()
Customized Neural Network 0.020557
dtype: object
Отобразим наши результаты на графике.
validation_error.plot()
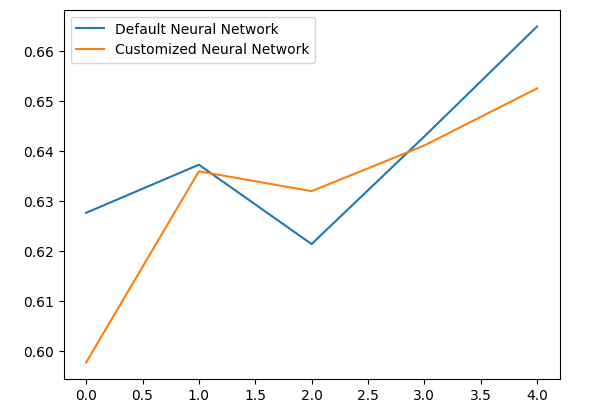
Рис. 10. Визуализация нашего теста на переобучение
Диаграммы размахов показывают, что наша настроенная модель выглядит менее стабильной, в ней есть выбросы, которых мы не наблюдаем в модели по умолчанию. Более того, наша модель по умолчанию имеет немного лучшую среднюю производительность. Поэтому мы выбираем модель по умолчанию, а не настроенную модель.
sns.boxplot(validation_error)
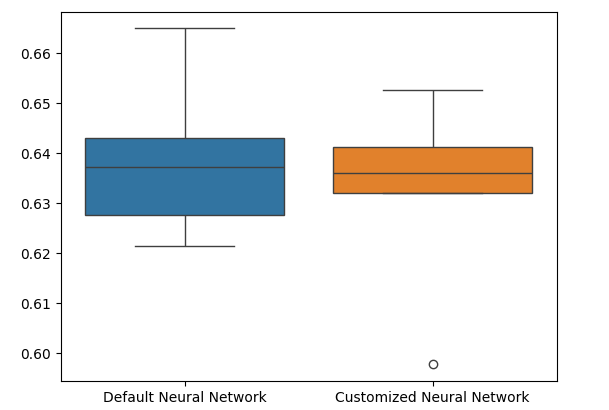
Рис. 11. Визуализация нашего теста на переобучение II
Подготовка к экспорту в ONNX
Прежде чем экспортировать нашу модель в формат ONNX, нам необходимо масштабировать данные таким образом, чтобы их можно было воспроизвести в терминале MetaTrader 5. Мы вычтем среднее значение из каждого столбца и разделим на стандартное отклонение столбца. Это гарантирует, что наша модель будет эффективно обучаться, поскольку наши данные находятся в разных масштабах. Кроме того, мы экспортируем значения среднего значения и стандартного отклонения в формат CSV, чтобы иметь возможность извлечь их позже.#Preparing to export to ONNX #Let's scale our data scaling_factors = pd.DataFrame(columns=predictors,index=['mean','standard deviation']) X = boom_1000.loc[:,predictors] y = boom_1000.loc[:,"RSI Target"]
Масштабируем каждый столбец.
#Let's fill each column for i in np.arange(0,len(predictors)): scaling_factors.iloc[0,i] = X.iloc[:,i].mean() scaling_factors.iloc[1,i] = X.iloc[:,i].std() X.iloc[:,i] = ( ( X.iloc[:,i] - scaling_factors.iloc[0,i] ) / scaling_factors.iloc[1,i])
Сохраним коэффициенты масштабирования в формате CSV.
#Save the scaling factors as a CSV scaling_factors.to_csv("/home/volatily/.wine/drive_c/Program Files/MetaTrader 5/MQL5/Files/boom_1000_scaling_factors.csv")
Экспорт в ONNX
Open Neural Network Exchange (ONNX) — совместимая среда машинного обучения с открытым исходным кодом, которая позволяет разработчикам создавать и совместно использовать модели машинного обучения на любом языке программирования с поддержкой ONNX API. Это позволяет нам создавать модели машинного обучения на Python и развертывать их в MQL5.Сначала импортируем необходимые нам библиотеки.
#Exporting to ONNX
import onnx
import netron
import skl2onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
Отобразим версии библиотек.
#Display the library versions print(f"Onnx version {onnx.__version__}") print(f"Netron version {netron.__version__}") print(f"Skl2onnx version {skl2onnx.__version__}")
Netron version 7.8.0
Skl2onnx version 1.16.0
Определим типы входных данных нашей модели.
#Define the model input types initial_types = [("float_input",FloatTensorType([1,5]))]
Подгоним модель под все имеющиеся у нас данные.
#Fit the model on all the data we have default_model = MLPRegressor(hidden_layer_sizes=(30,10),max_iter=200) default_model.fit(X,y)
Преобразуем модель в ее ONNX-представление.
#Convert the model to an ONNX representation onnx_model = convert_sklearn(default_model,initial_types=initial_types,target_opset=12)
Сохраним ONNX-представление в файл.
#Save the ONNX representation onnx_name = "Boom 1000 Neural Network.onnx" onnx.save(onnx_model,onnx_name)
Просмотрим модель с помощью netron.
#View the onnx model
netron.start(onnx_name)

Рис. 12. Визуализация нашей глубокой нейронной сети

Рис. 13. Визуализация входных и выходных данных нашей модели
Реализация средствами MQL5
Чтобы создать торговое приложение с интегрированной системой искусственного интеллекта, нам сначала потребуется ONNX-модель, которую мы только что экспортировали в Python.
//+------------------------------------------------------------------+ //| Boom 1000.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| ONNX Model | //+------------------------------------------------------------------+ #resource "\\Files\\Boom 1000 Neural Network.onnx" as const uchar onnx_buffer[];
Давайте также загрузим торговую библиотеку для управления нашими позициями.
//+-----------------------------------------------------------------+ //| Libraries we need | //+-----------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Определим глобальные переменные, которые мы будем использовать в нашей программе.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; int rsi_handler,model_state,system_state; double mean_values[5],std_values[5],rsi_buffer[],bid,ask; vectorf model_outputs = vectorf::Zeros(1); vectorf model_inputs = vectorf::Zeros(5);
Давайте теперь определим функцию для подготовки нашей ONNX-модели. Функция сначала создаст нашу модель из буфера, который мы определили в начале нашей программы, и проверит, что модель не повреждена. Если она повреждена, функция вернет false, и это завершит процедуру инициализации. Далее функция продолжит задавать формы входных и выходных данных нашей ONNX-модели. Если мы не определим ни один из параметров ввода-вывода, наша функция снова вернет false и завершит процедуру инициализации.
//+------------------------------------------------------------------+ //| This function will prepare our ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- First create the ONNX model from the buffer we created earlier onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the ONNX model if(onnx_model == INVALID_HANDLE) { Comment("[ERROR] Failed to create the ONNX model: ",GetLastError()); return(false); } //--- Set the input and output shapes of the model ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the input and output shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape: ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape: ",GetLastError()); return(false); } return(true); }
Мы не можем использовать нашу ONNX-модель без масштабирования ее входных данных. Следующая функция загрузит необходимые средние значения и значения стандартного отклонения в массивы, к которым мы сможем легко получить доступ.
//+-----------------------------------------------------------------+ //| Load the scaling values | //+-----------------------------------------------------------------+ void load_scaling_values(void) { //--- BOOM 1000 OHLC + RSI Mean values mean_values[0] = 16799.87389394667; mean_values[1] = 16800.872890865994; mean_values[2] = 16798.91007345616; mean_values[3] = 16799.908906749482; mean_values[4] = 43.45867626462568; //--- BOOM 1000 OHLC + RSI Mean std values std_values[0] = 864.3356132780019; std_values[1] = 864.3839684000297; std_values[2] = 864.2859346216392; std_values[3] = 864.3344430387272; std_values[4] = 20.593175501388043; } //+------------------------------------------------------------------+
Нам также необходимо определить функцию, которая будет извлекать для нас обновленные рыночные цены и текущее значение нашего технического индикатора.
//+------------------------------------------------------------------+ //| Fetch updated market prices and technical indicator values | //+------------------------------------------------------------------+ void update_market_data(void) { //--- Market data bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); //--- Technical indicator values CopyBuffer(rsi_handler,0,0,1,rsi_buffer); }
Наконец, нам нужна функция, которая будет извлекать входные данные нашей модели, масштабировать их и извлекать прогноз из нашей модели. Мы сохраним флаг, чтобы запомнить прогноз нашей модели. Это поможет нам легко понять, когда наша модель прогнозирует разворот.
//+------------------------------------------------------------------+ //| Fetch a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { //--- Get the model inputs model_inputs[0] = iOpen(_Symbol,PERIOD_CURRENT,0); model_inputs[1] = iHigh(_Symbol,PERIOD_CURRENT,0); model_inputs[2] = iLow(_Symbol,PERIOD_CURRENT,0); model_inputs[3] = iClose(_Symbol,PERIOD_CURRENT,0); model_inputs[4] = rsi_buffer[0]; //--- Scale the model inputs for(int i = 0; i < 5; i++) { model_inputs[i] = ((model_inputs[i] - mean_values[i]) / std_values[i]); } //--- Fetch a prediction from our model OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs); //--- Give user feedback Comment("Model RSI Forecast: ",model_outputs[0]); //--- Store the model's state if(rsi_buffer[0] > model_outputs[0]) { model_state = -1; } else if(rsi_buffer[0] < model_outputs[0]) { model_state = 1; } }
Теперь определим процедуру инициализации нашей модели. Начнем с загрузки нашей модели ONNX, затем выберем значения масштабирования и настроим индикатор RSI.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- This function will prepare our ONNX model and set the input and output shapes if(!load_onnx_model()) { return(INIT_FAILED); } //--- This function will prepare our scaling values load_scaling_values(); //--- Setup our technical indicatot rsi_handler = iRSI(Symbol(),PERIOD_CURRENT,20,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
Всякий раз, когда наше приложение удаляется с графика, мы освобождаем ресурсы, которые больше не используем, модель ONNX, индикатор RSI, а также удаляем советника.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the resources we no longer need OnnxRelease(onnx_model); IndicatorRelease(rsi_handler); ExpertRemove(); }
Всякий раз, когда мы получаем обновленные цены, мы сначала извлекаем обновленные рыночные и технические данные, включая цены спроса и предложения, а также значения RSI. После этого мы будем готовы получить новый прогноз из нашей модели. Если у нас нет открытых позиций, мы будем следовать прогнозу нашей модели и запомним нашу текущую позицию с помощью двоичного флага. В противном случае, если у нас уже есть открытая позиция, мы проверим, противоречит ли новый прогноз нашей модели нашей открытой позиции. Если это так, закроем позицию. В противном случае мы продолжим получать прибыль.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated market prices update_market_data(); //--- On every tick we need to fetch a prediction from our model model_predict(); //--- If we have no open positions, follow the model's prediction if(PositionsTotal() == 0) { //--- Our model detected a spike if(model_state == 1) { Trade.Buy(0.2,Symbol(),ask,0,0,"BOOM 1000 AI"); system_state = 1; } //--- Our model detected a drop if(model_state == -1) { Trade.Sell(0.2,Symbol(),bid,0,0,"BOOM 1000 AI"); system_state = -1; } } //--- If we have open positiosn, our AI system will decide when to close them else if(PositionsTotal() > 0) { if(system_state != model_state) { //--- Close the positions we opened Alert("Reversal detected by the AI system,closing all positions now!"); Trade.PositionClose(Symbol()); } } } //+------------------------------------------------------------------+

Рис. 14. Наша система Boom 1000 сумела поймать выброс

Рис. 15. Наша система Boom 1000 обнаружила разворот
Заключение
В статье мы продемонстрировали, что можно создавать самооптимизирующиеся советники, способные справиться даже с самыми сложными синтетическими инструментами. Более того, мы показали, что традиционный подход прямого прогнозирования уровней цен не достаточен на современных алгоритмических рынках.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15781
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Мы проанализируем все синтетические рынки Deriv по отдельности, начав с самого известного — Boom 1000.
Большое спасибо за статью! Давно присматриваюсь к этим индексам, но не знал, с какого боку к ним подступиться.
Пожалуйста, продолжайте!
я испробовал несколько инструментов и на каждом ваша модель выдает ошибку из-за несоответствия размеров входных данных (X) и целевых переменных (y).
Большое спасибо за статью! Я давно анализировал эти индексы, но не был уверен, с какой стороны к ним подойти.
Пожалуйста, продолжайте!
Не за что, Янис.
Я обязательно продолжу. Многое нужно осветить, но я найду время.
Я попробовал несколько инструментов, и в каждом из них ваша модель выдает ошибку из-за несоответствия размеров входных данных (X) и целевых переменных (y).
Здравствуйте, Александр, вы можете использовать код в качестве шаблона, а затем внести необходимые изменения на своей стороне. Я бы также рекомендовал вам попробовать разные индикаторы, попробовать разные вариации общей идеи, изложенной в статье. Это поможет нам быстрее понять глобальную истину.
Я попробовал несколько инструментов, и каждый из них приводил к ошибке модели из-за несоответствия размеров входных данных (X) и целевой переменной (y).
# Сохраняйте индексы согласованными, иначе при наличии отфильтрованных данных индексы будут перестроены. X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:, predictors]), columns=predictors, index=boom_1000.index)