
Simulação de mercado (Parte 22): Iniciando o SQL (V)

Introdução
Olá pessoal, e sejam bem-vindos a mais um artigo da série sobre como construir um sistema de replay/simulação.
No artigo anterior Simulação de mercado (Parte 21): Iniciando o SQL (IV), expliquei de uma forma totalmente abstrata como você poderia separar um banco de dados relacional, de um não relacional. Mas principalmente, e este foi o motivo do artigo anterior. Eu tentei mostrar, como você, aspirante a programador, pode entender o funcionamento de um banco de dados. Isto para que você pudesse de fato, compreender que mesmo parecendo adequado programar algumas coisas. Em alguns momentos podemos fazer uso de alguma implementação já existente. A fim de conseguir gerar o tipo de resultado esperado em uma aplicação.
O fato de eu estar utilizando algum tempo para explicar o SQL, e não programando em MQL5. Se deve justamente a isto. Quero tentar nivelar um pouco as coisas, a fim de que todos, consigam entender, por que estaremos usando SQL. Quando poderíamos estar criando rotinas e mais rotinas para produzir algum tipo de implementação.
A implementação, no caso, é a que nos permitirá desenvolver uma forma adequada e simples a fim de que o replay/simulador, conte com um sistema de ordens. Ou seja, precisamos de algum meio, para manter o sistema de ordens e posições para fazer estudos no replay/simulador. Criar rotinas e mais rotinas para fazer isto, ao meu ver é algo totalmente desnecessário. Já que o MQL5, nos permite ter algum suporte do SQL. Isto via SQLite. Mas para que, aqueles ansiosos em sempre criar códigos e mais códigos. Quero mostrar uma alternativa melhor. Isto por que, o tempo que seria gasto, implementando, testando e ajustando as rotinas, a fim de conseguir criar algum tipo de banco de dados. Pode ser melhor utilizado para outras coisas.
Desta maneira, no momento que começarmos a realmente desenvolver o sistema necessário para que o replay / simulador. Possa ser de fato usado como uma alternativa a contas demo, a fim de estudarmos alguma estratégia. Será feito de forma bastante mais rápida e sem muitos problemas relacionados a forma como as coisas deverão funcionar. O motivo disto é que usaremos o SQL, para prover o caminho necessário para a criação do sistema de ordens.
Porém, o que foi explicado no artigo anterior. É algo muito abstrato, isto se deixarmos as coisas apenas daquela forma e no campo da teoria. Mas como, o assunto em questão pode ser de interesse em outros campos. Como por exemplo, se você desejar criar um Expert Advisor que use um banco de dados a fim de aprender a operar. Precisará de fato colocar em prática o que foi explicado no artigo anterior. Um detalhe importante, e antes que alguém peça para fazer. Não tenho planos, pelo menos no momento, de explicar como você pode criar um banco de dados a fim de fazer com que um Expert Advisor, criado em MQL5, passe a aprender como operar um dado ativo.
Explicar este tipo de coisa, é algo que envolveria explicar muitos outros conceitos e funcionamento de um banco de dados. Mas se você, realmente desejar aprender como fazer isto. Sugiro que procure se aprofundar bastante, em algoritimos de jogos. Isto por que, a criação do banco de dados é algo trivial, assim como a programação do Expert Advisor em MQL5. Mas para que o banco de dados seja de fato útil para o Expert Advisor aprender, literalmente a operar no mercado. Você irá precisar saber como adicionar alguns dados ao banco que será criado. Para aprender a criar tais dados, o caminho mais simples é estudando algoritimos de jogos.
Porém existem outros caminhos um pouco mais complicados, como por exemplo, estudo de movimentação de ondas. Ou mesmo, conceitos de distribuição de calor. Mas estes ramos são consideravelmente mais complicados, apesar de que os resultados serão bem parecidos com o de algoritimos de jogos.
Mas vamos começar vendo na prática, o que foi explicado no artigo anterior. E como gosto de separar as coisas em tópicos, para facilitar o entendimento, vamos ao primeiro tópico deste artigo.
Criando um banco de dados simples
Aqui não irei me estender muito. Isto por que tal atividade já vem sendo explorada já a alguns artigos, onde estamos tratando do SQL. Mas devido ao fato de que, no artigo anterior, sugeri usarmos um outro programa. Isto para que, o trabalho fosse gerado diretamente no SQLite, que é a implementação da qual faremos uso via MQL5. Precisamos ver alguns poucos detalhes, voltados exclusivamente para o uso do SQLite.
Muito bem, o primeiro detalhe que iremos ver, é a relação de tipos de dados no SQLite, com os dados que colocaremos no banco de dados. Umas das coisas no SQLite que chamam a atenção, quando o assunto é tipos de dados. É que ele contém uma quantidade menor de tipos. Mas isto não é uma desvantagem, pelo contrário, dependendo do que você esteja desenvolvendo, isto é uma grande vantagem. Além de uma outra vantagem que o SQLite tem sobre outras implementações.
A outra vantagem, da qual acabo de mencionar é o fato, de que no SQLite, os dados são dinâmicos, e não estáticos como acontece em muitas outras implementações. Mas espere um pouco. Como assim os dados no SQLite são dinâmicos. E por que isto seria uma vantagem? Bem, para entender isto. Será preciso que vejamos uma pequena tabela. Esta é vista logo abaixo:
| Tipo de dado em SQLite | Explicação |
|---|---|
| NULL | Inclui quaisquer valores NULL. |
| INTEGER | Inteiros com sinal, armazenados em 1, 2, 3, 4, 6 ou 8 bytes, dependendo da magnitude do valor. |
| REAL | Números reais, ou valores de ponto flutuante, armazenados como números de ponto flutuante de 8 bytes. |
| TEXT | Strings de texto armazenadas usando a codificação do banco de dados, que pode ser UTF-8, UTF-16BE ou UTF-16LE. |
| BLOB | Qualquer blob de dados, com cada blob armazenado exatamente como foi inserido. |
Veja que nesta tabela temos os tipos do SQLite. Agora só como curiosidade vamos ver, em outras implementações do SQL, como as coisas são. Começando com o MySQL, que tem a tabela de tipos mostrada abaixo:
| Tipo de dado no MySQL | Explicação |
|---|---|
| TINYINT | Um inteiro muito pequeno. O intervalo com sinal para esse tipo de dados numérico é de -128 a 127, enquanto o intervalo sem sinal é de 0 a 255. |
| SMALLINT | Um pequeno número inteiro. O intervalo com sinal para esse tipo numérico é de -32768 a 32767, enquanto o intervalo sem sinal é de 0 a 65535. |
| MEDIUMINT | Um inteiro de tamanho médio. O intervalo com sinal para esse tipo de dados numérico é de -8388608 a 8388607, enquanto o intervalo sem sinal é de 0 a 16777215. |
| INTEGER | Um número inteiro de tamanho normal. O intervalo com sinal para esse tipo de dados numérico é de -2147483648 a 2147483647, enquanto o intervalo sem sinal é de 0 a 4294967295. |
| BIGINT | Um grande inteiro. O intervalo com sinal para esse tipo de dados numérico é de -9223372036854775808 a 9223372036854775807, enquanto o intervalo sem sinal é de 0 a 18446744073709551615. |
| FLOAT | Um pequeno número de ponto flutuante (precisão simples). |
| DOUBLE | Um número de ponto flutuante de tamanho normal (precisão dupla). |
| DECIMAL | Um número de ponto fixo empacotado. O comprimento de exibição das entradas para este tipo de dados é definido quando a coluna é criada e cada entrada adere a esse comprimento. |
| BOOLEAN | Um booleano é um tipo de dados que possui apenas dois valores possíveis, geralmente verdadeiro ou falso. |
| BIT | Um tipo de valor de bit para o qual você pode especificar o número de bits por valor, de 1 a 64. |
| DATE | Uma data, representada como YYYY-MM-DD. |
| DATETIME | Um registro de data e hora mostrando a data e a hora, exibido como YYYY-MM-DD HH:MM:SS. |
| TIMESTAMP | Um timestamp indicando a quantidade de tempo desde a época do Unix (00:00:00 em 1º de janeiro de 1970). |
| TIME | Uma hora do dia, exibida como HH:MM:SS. |
| YEAR | Um ano expresso em um formato de 2 ou 4 dígitos, sendo 4 dígitos o padrão. |
| CHAR | Uma string de comprimento fixo; as entradas desse tipo são preenchidas à direita com espaços para atender ao comprimento especificado quando armazenadas. |
| VARCHAR | Uma cadeia de comprimento variável. |
| BINARY | Semelhante ao tipo char, mas uma string de bytes binários de um comprimento especificado em vez de uma string de caracteres não binários. |
| VARBINARY | Semelhante ao tipo varchar, mas uma string de bytes binários de comprimento variável em vez de uma string de caracteres não binários. |
| BLOB | Uma string binária com comprimento máximo de 65535 (2^16 - 1) bytes de dados. |
| TINYBLOB | Uma coluna blob com comprimento máximo de 255 (2^8 - 1) bytes de dados. |
| MEDIUMBLOB | Uma coluna blob com comprimento máximo de 16777215 (2^24 - 1) bytes de dados. |
| LONGBLOB | Uma coluna blob com comprimento máximo de 4294967295 (2^32 - 1) bytes de dados. |
| TEXT | Uma string com comprimento máximo de 65535 (2^16 - 1) caracteres. |
| TINYTEXT | Uma coluna de texto com comprimento máximo de 255 (2^8 - 1) caracteres. |
| MEDIUMTEXT | Uma coluna de texto com comprimento máximo de 16777215 (2^24 - 1) caracteres. |
| LONGTEXT | Uma coluna de texto com comprimento máximo de 4294967295 (2^32 - 1) caracteres. |
| ENUM | Uma enumeração, que é um objeto de cadeia de caracteres que obtém um único valor de uma lista de valores declarados quando a tabela é criada. |
| SET | Semelhante a uma enumeração, um objeto de string que pode ter zero ou mais valores, cada um dos quais deve ser escolhido em uma lista de valores permitidos que são especificados quando a tabela é criada. |
Note que existem muito mais tipos, e que devemos escolher adequadamente o tipo certo para evitar problemas futuros. Assim como no PostgreSQL que tem a sua tabela de tipos mostrada logo abaixo.
| Tipo de dados no PostgreSQL | Explicação |
|---|---|
| BIGINT | Um inteiro assinado de 8 bytes. |
| BIGSERIAL | Um inteiro de 8 bytes com incremento automático. |
| DOUBLE PRECISION | Um número de ponto flutuante de precisão dupla de 8 bytes. |
| INTEGER | Um inteiro assinado de 4 bytes. |
| NUMERIC | Um número de precisão selecionável, recomendado para uso em casos onde a exatidão é crucial, como valores monetários. |
| REAL | Um número de ponto flutuante de precisão simples de 4 bytes. |
| SMALLINT | Um inteiro assinado de 2 bytes. |
| SMALLSERIAL | Um inteiro de 2 bytes com incremento automático. |
| SERIAL | Um inteiro de 4 bytes com incremento automático. |
| CHARACTER | Uma cadeia de caracteres com um comprimento fixo especificado. |
| VARCHAR | Uma cadeia de caracteres com comprimento variável, mas limitado. |
| TEXT | Uma cadeia de caracteres de comprimento variável e ilimitado. |
| DATE | Uma data do calendário que consiste em dia, mês e ano. |
| INTERVAL | Um intervalo de tempo. |
| TIME WITHOUT TIME ZONE | Uma hora do dia, sem incluir o fuso horário. |
| TIME WITH TIME ZONE | Uma hora do dia, incluindo o fuso horário. |
| TIMESTAMP WITHOUT TIME ZONE | Uma data e hora, sem incluir o fuso horário. |
| TIMESTAMP WITH TIME ZONE | Uma data e hora, incluindo o fuso horário. |
| BOX | Uma caixa retangular em um plano. |
| CIRCLE | Um círculo em um plano. |
| LINE | Uma linha infinita em um plano. |
| LSEG | Um segmento de reta em um plano. |
| PATH | Um caminho geométrico em um plano. |
| POINT | Um ponto geométrico em um plano. |
| POLYGON | Um caminho geométrico fechado em um plano. |
| CIDR | Um endereço de rede IPv4 ou IPv6. |
| INET | Um endereço de host IPv4 ou IPv6. |
| MACADDR | Um endereço Media Access Control (MAC). |
| BIT | Uma cadeia de bits de comprimento fixo. |
| BIT VARYING | Uma cadeia de bits de comprimento variável. |
| TSQUERY | Uma consulta de pesquisa de texto. |
| TSVECTOR | Um documento de pesquisa de texto. |
| JSON | Dados JSON textuais. |
| JSONB | Dados JSON binários decompostos. |
| BOOLEAN | Um booleano lógico, representando verdadeiro ou falso. |
| BYTEA | Abreviação de “array de bytes”, esse tipo é usado para dados binários. |
| MONEY | Uma quantidade de moeda. |
| PG_LSN | Um número de sequência de log do PostgreSQL. |
| TXID_SNAPSHOT | Um instantâneo de ID de transação em nível de usuário. |
| UUID | Um identificador universalmente exclusivo. |
| XML | Dados XML. |
Note que temos ainda mais tipos disponíveis, aqui no PostgreSQL. Você pode estar pensando: Mas tudo isto pode tornar, para quem esperar usar o SQL, um pesadelo. Mas não é bem assim. O SQL, consegue se adequar as nossas necessidades. Isto para que um banco de dados possa ser usado em uma outra aplicação, criada também em SQL. O fato de termos mais ou menos tipos, torna a escolha do tipo, mais ou menos difícil. Isto por que, se você escolher o tipo errado. Quando você precisar mudar o tipo, todo o banco de dados terá que ser reconstruído. Apesar de ser uma tarefa bem fácil de ser feita, isto por que usamos scripts especialmente feitos para isto. Pode ser algo bastante trabalhoso, para quem deseja aprender SQL e não sabe por onde começar.
Porém, observando estas tabelas, você logo nota, que o fato do SQLite, usar poucos tipos. Faz com que os tipos presentes nele precisem de menos trabalho para manutenção. Mas isto nos traz outras questões que não vem ao caso. O que realmente nos interessa neste momento é o fato de que por ter menos tipos. O SQLite tem tipos dinâmicos, ou seja, eles crescem conforme a necessidade que a informação a ser armazenada venha a necessitar.
Mas como isto se aplica na prática? Para entender, isto é preciso que criemos dois bancos de dados distintos. Um será criado usando o MySQL e o outro usando o SQLite. Ambos utilizam o SQL como linguagem base. Vamos ver como fazer isto. A animação abaixo, mostra como este processo seria feito no MySQL.
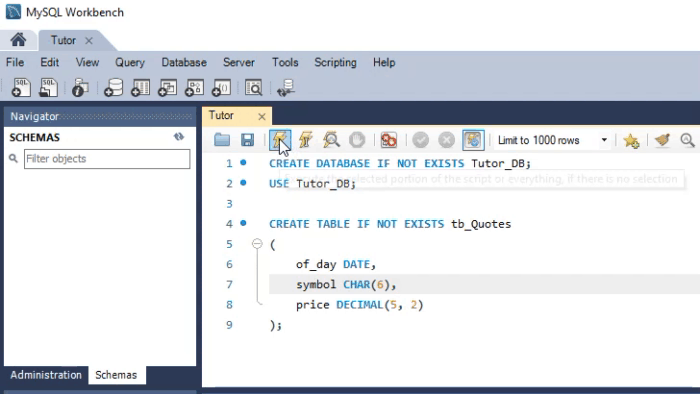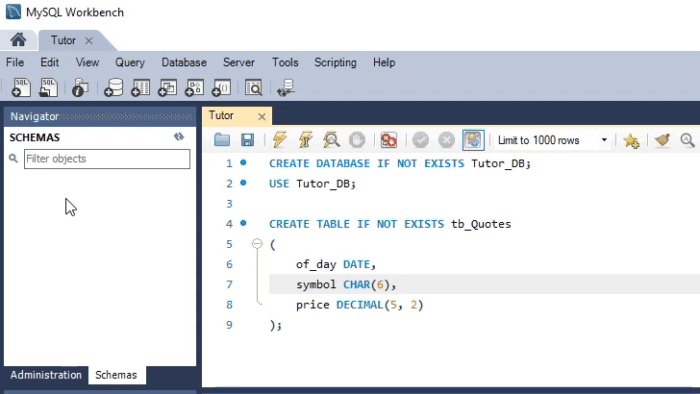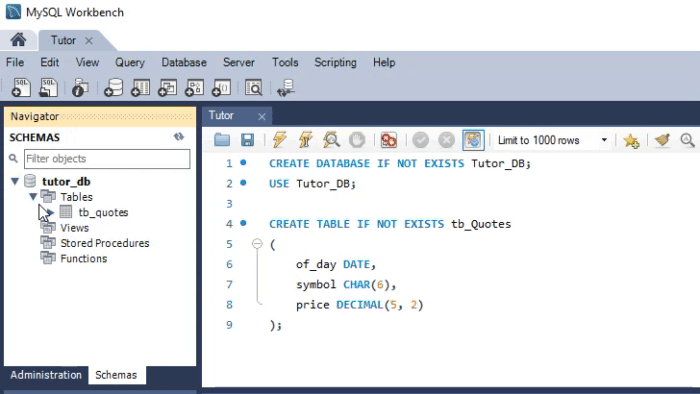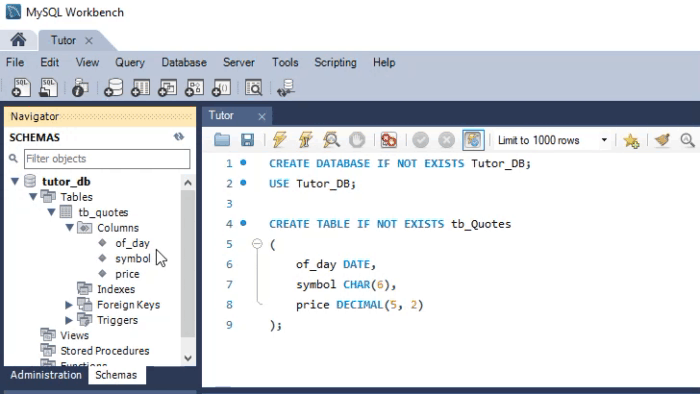
Note os tipos utilizados. Já a animação vista a seguir, executa praticamente o mesmo procedimento, só que no SQLite.
Veja os tipos que estão definidos nesta segunda animação. Apesar de que na animação vista no MySQL, o script criar o banco de dados. A mesma coisa não acontece no SQLite. Neste caso, temos que ter o banco já criado, e aberto no DB Browser. Mas você talvez esteja pensando: Bem, os tipos são diferentes, então um código não funcionaria de forma cruzada. Bem, se você está pensando isto, é que por que está caindo de paraquedas neste artigo. Minha sugestão é que leia os artigos anteriores. Já que ali, mostrei como usar o mesmo código. Tanto no MySQL, quanto no SQLite. Só que no caso estávamos usando o MetaEditor para executar o SQLite.
Mas o que os interessa neste ponto é o fato de que, no código visto em MySQL, definimos durante a criação das colunas, o tamanho que elas teriam. Já no caso do SQLite, tal coisa não foi feita. Este tipo de dinamismo pode ser feito no MySQL. Porém não será algo comumente encontrado em implementações diferentes do SQLite. O motivo é que muitas das vezes, o programador SQL, prefere definir o tipo ou mesmo o tamanho dos campos a fim de otimizar alguma característica do banco de dados. Por conta disto que temos um maior trabalho, no que rege a manutenção de bancos de dados em diferentes implementações.
Mas neste ponto pode surgir uma dúvida. Será que o MySQL conseguiria entender as colunas criadas pelo SQLite, ou vice versa? Quanto a isto, meu caro leitor, você não precisa se preocupar. Pois sim, qualquer implementação do SQL conseguirá entender o dimensionamento usado nas colunas. Por conta disto que mostrei as tabelas acima. Justamente para facilitar esta compreensão de que existe um certo cruzamento entre os tipos de dados. Mas dependendo da implementação, o programador pode decidir usar um ou outro tipo específico, a fim de otimizar algum tipo de detalhe no banco de dados.
Muito bem. Agora que fizemos as devidas apresentações, vamos ver na prática a questão de como as chaves primárias e estrangeiras entram nesta história toda.
Chaves primárias e estrangeiras na prática
Você pode ver nas animações acima, que estamos criando um banco de dados bem simples. Este tem como objetivo, armazenar o nome do ativo, junto com a cotação e a data que a cotação foi obtida. Porém na prática, dificilmente um programador de bancos de dados criaria o banco desta maneira. Isto por que, você poderia desejar colocar mais de um ativo, ou poderia desejar colocar algumas informações extras no próprio banco de dados. Como por exemplo: O nome fantasia da empresa, cujo o ativo esteja sendo representado na tabela.
Mas também pode acontecer, de o ativo trocar de nome, apesar de ser algo bem raro de ocorrer, as vezes ocorre. Temos um exemplo disto na B3, onde durante um tempo a empresa VIA VAREJO, tinha como ticket: VVAR3. Por algum motivo, o ativo mudou o ticket para VIIA3. Então pense em todo o trabalho de ter que trocar em cada um dos registros passados o nome do ativo de VVAR3 para VIIA3. Mas tudo isto poderia ser feito muito facilmente, se o banco estivesse sido construído de uma outra forma.
Apesar deste exemplo é bem simples. Ele é prático o suficiente, para que você possa entender diversas outras coisas. Pois muita gente acha que criar e manter um banco de dados é uma tarefa simples. Mas, quando vai realmente fazer isto, acaba fazendo um monte de bobagens que depois dão um baita de um trabalhão para serem resolvidos adequadamente.
Vamos primeiro ver como é feita a solução básica usando o SQLite. Para facilitar as coisas e assim por consequência a explicação. Você pode ver o código de um script SQL logo abaixo. Este fará uso do que queremos implementar.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. -- symbol TEXT, 13. price NUMERIC, 14. fk_id INTEGER, 15. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 16. );
Código em SQLite
Observe que este código já contém algumas coisas que NÃO são do SQL. Neste caso estamos falando da linha um. Onde fazemos uso de uma instrução interna do SQLite. Mas por que estou usando esta instrução aqui? O motivo é que na documentação do SQLite, que deixarei no final deste artigo, na parte sobre referências. É indicado que até na versão 3.6.19 o SQLite não faz uso de chaves estrangeiras por padrão. Sendo necessário que indiquemos isto a ele. Caso contrário ele não as usará. Apesar de a versão mencionada ser bastante antiga. Pode ser que alguém ainda a esteja utilizando por algum motivo. Salvo este fato, vamos ver o que está acontecendo neste script. Lembrando que para a correta execução do script no SQLite, um banco de dados deverá estar aberto no DB Browser.
Na linha três, estamos criando caso não exista uma tabela chamada tb_Symbols. Dentro desta tabela, declaramos na linha cinco, uma identidade única. Já na linha seis, definimos no nome do ativo. Aqui não estamos ainda limitando ainda mais os registros que esta tabela irá conter. O motivo disto, é que ainda quero mostrar, como chegamos a um modelo bem mais adequado de construção de um banco de dados. Então, apesar do valor de id, ser sempre único, podemos ter o mesmo ativo, sendo definido em mais de uma id. Mas isto é supersimples de ser resolvido. Mas antes de ver como faremos, vamos primeiro entender como as chaves funcionam aqui.
Uma vez que a tabela tb_Symbols, foi criada. Podemos modificar, ou melhor, iremos criar uma nova tabela. Esta está sendo iniciada na linha nove, onde dizemos que queremos criar a tabela tb_Quotes. Note que a linha 12 é a original, vista na animação logo acima. No entanto, diferente do que é visto na animação, aqui ela se encontra como sendo um comentário. O motivo disto é que, o nome do ativo, já não irá se encontrar nesta tabela. Por conta deste detalhe, foram adicionadas as linhas 14 e 15 ao código. Agora preste bastante atenção ao que irei explicar, pois é importante. Na linha 14 definimos um valor que deverá ter o mesmo tipo usado na chave primária da tabela tb_Symbols. Em alguns casos, o programador que usa o SQLite, não define o tipo, deixando isto para que o próprio programa faça a definição do tipo. Como quero manter um certo padrão no código, então estou definindo o tipo.
Esta será a nossa chave estrangeira, dentro da tabela tb_Quotes. Agora o ponto realmente importante neste script visto acima. Na linha 15 dizemos, quem é a chave estrangeira, e dizemos a quem esta chave estará se referindo. Note que precisamos dizer o nome da tabela, assim como também o nome da chave ou coluna a ser usada. Esta chave da qual estou me referindo, tem como origem a tabela tb_Symbols.
Com isto, criamos um sistema referencial, ou relacional. Onde temos a informação da cotação separada do nome do ativo. Porém, esta separação não é de fato real. Já que existe uma ligação entre o registro da cotação e o nome do ativo. E esta ligação se dá justamente por conta da criação da chave primária e da estrangeira. Se você conseguiu entender esta ligação, irá perceber, que podemos criar um verdadeiro banco de dados, relacionando diversas informações distintas entre si. De tal forma, que elas terão algum tipo de vínculo, que ao mesmo tempo, nos permite adicionar mais ou menos dados a um mesmo registro. Isto com um custo baixíssimo de manutenção ou modificação do banco de dados original.
Este mesmo código visto acima, pode ser criado como mostrado abaixo. O que seria algo bem mais próximo de uma possível realidade. Apesar de ainda não termos assegurando a questão do nome do ativo se repetir em mais de uma posição na tabela tb_Symbols.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY, 06. symbol TEXT 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT, 12. price NUMERIC, 13. fk_id INTEGER REFERENCES tb_Symbol (id) 14. );
Código em SQLite
Note que agora, fizemos uma pequena mudança. Esta está na linha 13 que tem o mesmo objetivo. Ou seja, ligar via chave estrangeira, a tabela tb_Quotes com a tabela tb_Symbols. Um detalhe: Apesar de eu estar dizendo que estamos ligando as tabelas, o correto mesmo, é dizer que estamos ligando um registro da tabela tb_Quotes a um outro registro na tabela tb_Symbols. Ok, agora note o seguinte fato. Não importa o que estaremos guardando em cada uma das tabelas. Podemos colocar mais ou menos campos, ou colunas de dados nas tabelas. E isto não influenciará diretamente na pesquisa e nos resultados que obteremos nas pesquisas.
Mas dependendo da necessidade, você pode desejar adicionar alguma informação a mais em uma das tabelas. Porém, ao fazer isto, qualquer outra tabela, ligada a esta, irá se beneficiar deste fato, mas sem de necessariamente precisar que reescrevamos todo o banco de dados. Talvez você não esteja de fato vendo a extensão disto. Mas se começar a usar SQL, irá em pouco prazo, perceber que isto ajuda bastante, quando queremos expandir um banco de dados. Ou gerar um sistema relacional entre diversas informações diferentes.
Muito bem, mas como podemos resolver o problema de possíveis duplicadas no banco de dados? A forma de fazer isto é muito simples. Durante a criação da tabela, dizemos que uma coluna não deverá ter certos valores, ou que os valores não poderão ser duplicados. Por exemplo, vamos modificar o código visto acima, de forma que não podemos ter um valor nulo nas colunas. Mas também não queremos que o nome de um ativo, apareça em mais de um registro na mesma coluna. Assim o código já corrigido fica como mostrado abaixo.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. CREATE TABLE IF NOT EXISTS tb_Symbols 04. ( 05. id INTEGER PRIMARY KEY NOT NULL, 06. symbol TEXT NOT NULL UNIQUE 07. ); 08. 09. CREATE TABLE IF NOT EXISTS tb_Quotes 10. ( 11. of_day TEXT NOT NULL, 12. price NUMERIC NOT NULL, 13. fk_id INTEGER NOT NULL, 14. FOREIGN KEY (fk_id) REFERENCES tb_Symbol (id) 15. );
Código em SQLite
Agora se você rodar este script. Notará que será criada as duas tabelas como esperado e visto na explicação acima. Porém diferente do que acontecia, agora não teremos mais registros sendo duplicados. Se você tentar duplicar algum registro, o SQL impedirá que isto aconteça. Assim como também não teremos mais a incidência de valores nulos na nossa tabela. Veja que o código para fazer isto é super simples e de fácil compreensão.
Entendendo o último script
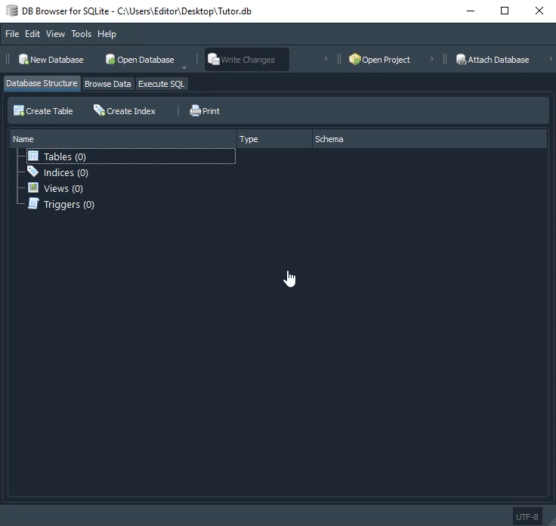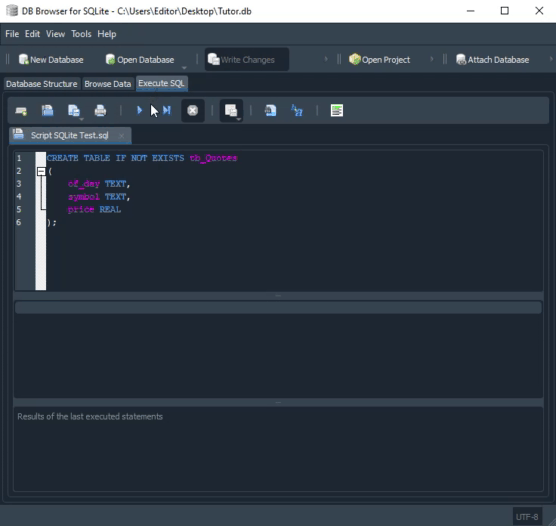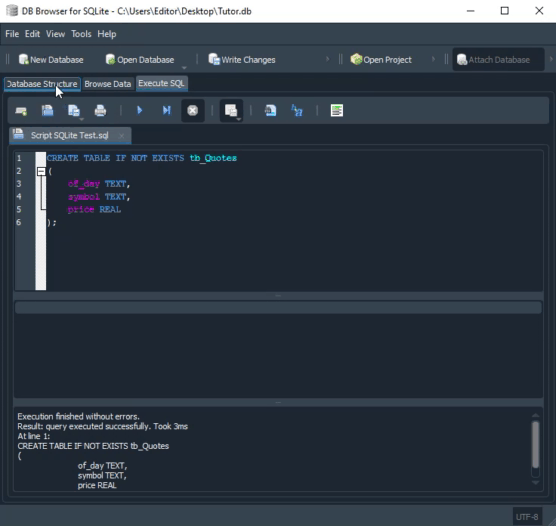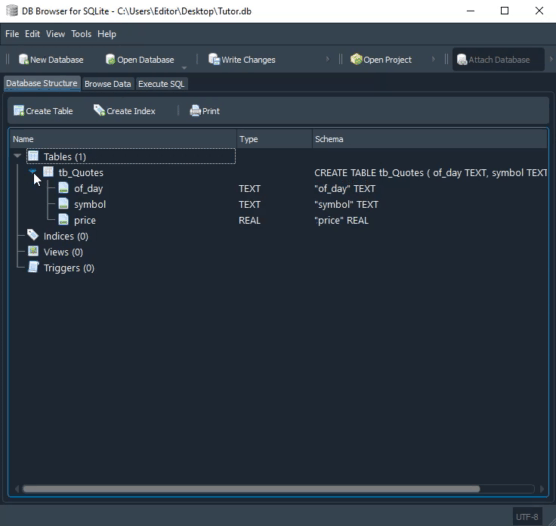
Entender como este último script funciona antes de nos aventurarmos por novos terrenos. Não é nem de longe algo opcional. É preciso que você de fato experimente e entenda o que está acontecendo aqui. Caso contrário ficará completamente perdido depois. Desta forma, depois de executar o último código de script em SQL visto logo acima, você terá no BD Browser, o seguinte resultado visto na imagem imediatamente abaixo:
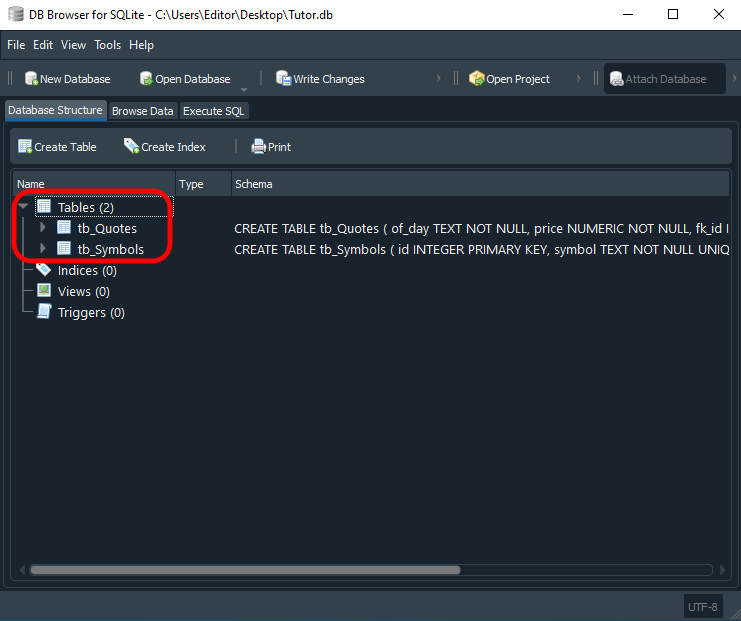
Observe que temos as duas tabelas sendo mostradas aqui em destaque. Mas como fazemos para de fato as utilizar? Parece ser algo muito complicado e só possível por grandes gurus da computação. Que nada. Usar este esquema, é mais simples do que caminhar para frente. Já mostrei como fazemos para adicionar informações a uma tabela via script. Isto em artigos anteriores falando sobre o SQL. Então aqui, vamos utilizar algo muito parecido com o que já foi visto.
Para isto, ver como as coisas se dão, vamos adicionar alguns dados apenas para exemplificar a interação com este tipo de modelagem. E já que também mostrei o comando básico de seleção, podemos também usar ele aqui. Mas primeiro vamos adicionar alguns registros ao nosso banco de dados. Assim vamos modificar o script visto acima para um outro, ligeiramente diferente.
01. PRAGMA FOREIGN_KEYS = ON; 02. 03. DROP TABLE IF EXISTS tb_Quotes; 04. DROP TABLE IF EXISTS tb_Symbols; 05. 06. CREATE TABLE IF NOT EXISTS tb_Symbols 07. ( 08. id INTEGER PRIMARY KEY, 09. symbol TEXT NOT NULL UNIQUE 10. ); 11. 12. CREATE TABLE IF NOT EXISTS tb_Quotes 13. ( 14. of_day TEXT NOT NULL, 15. price NUMERIC NOT NULL, 16. fk_id INTEGER NOT NULL, 17. FOREIGN KEY (fk_id) REFERENCES tb_Symbols(id) 18. ); 19. 20. INSERT INTO tb_Symbols (id, symbol) VALUES(1, 'BOVA11'); 21. INSERT INTO tb_Symbols (id, symbol) VALUES(3, 'PETR4'); 22. INSERT INTO tb_Symbols (id, symbol) VALUES(2, 'WDOQ23'); 23. INSERT INTO tb_Symbols (id, symbol) VALUES(4, 'VALE3'); 24. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('17-07-2023', 12.90, 4); 25. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('14-07-2023', 118.12, 2); 26. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('13-07-2023', 119.53, 1); 27. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('12-07-2023', 117.45, 2); 28. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('11-07-2023', 119.30, 3); 29. INSERT INTO tb_Quotes (of_day, price, fk_id) VALUES ('10-07-2023', 120.59, 1); 30. 31. SELECT * FROM tb_Quotes;
Script em SQLite
Você talvez esteja olhando e pensando: Caramba, que código mais complicado. Eu nunca vou conseguir entender isto. Acho que vou desistir e voltar a fazer as coisas de uma outra forma. Mas eu lhe digo, caro leitor: Você vai desistir agora? Justo agora que as coisas começaram a ficar mais legais. Pois este código visto acima não tem nada de complicado. Tudo e absolutamente tudo que ele contém, já foi explicado nesta fase inicial. Onde tenho dado alguma explicação sobre como usar a linguagem SQL.
Talvez a única parte que faça você ficar um pouco confuso, são as linhas três e quatro, onde estamos dizendo ao SQL, que caso as tabelas tb_Quotes e tb_Symbol existam. Elas deverão ser destruídas. Mas porque estamos destruindo as tabelas antes de as usar? E a questão principal. Por que destruir as tabelas? Não poderíamos simplesmente as manter e ficarmos adicionado coisas ao banco de dados?
Todas estas questões, tem uma única resposta. Precisamos destruir as tabelas, pelo simples motivo de que entre as linhas 20 e 29, estaremos adicionando valores a elas. Porém, cada vez que você executar este mesmo script. O SQL irá no momento que formos adicionar valores as tabelas, nos informar um erro. O motivo de tal geração de erro, é justamente pelo fato de que não poderemos duplicar alguns campos no banco de dados.
No momento que você executar este script, terá como resultado a seguinte imagem vista abaixo:
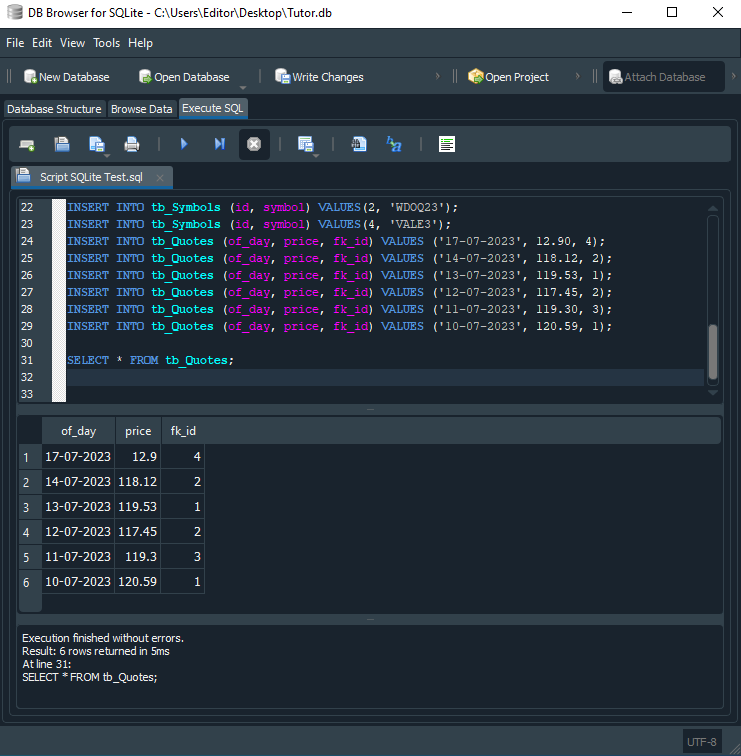
Observe que temos exatamente como resultado o conteúdo presente na tabela tb_Quotes. Isto por que, na linha 31, estamos dizendo ao SQL para nos dar tal informação. Mas olhando isto daqui você pode ficar meio que desanimado. Isto por que se tivermos um banco de dados muito extenso, com cotação de diversos ativos. Fica difícil saber qual é qual. Já que não temos como retorno o nome do ativo, ou alguma outra informação para melhor entendimento do que estamos procurando dentro do banco de dados. Mas em breve veremos como melhorar isto, fazendo uso de uma pequena mudança no código da linha 31, onde usamos o comando SELECT.
Considerações finais
Antes que você chute o balde, e decida abandonar o estudo sobre como usar o SQL. Deixe-me lembrá-lo, meu caro leitor, que aqui estamos ainda usando apenas o básico do básico. Ainda não exploramos algumas coisas que são possíveis de serem feitas no SQL. Assim que as explorarmos você verá que o SQL é bem mais prático do que parece. Mesmo que muito provavelmente, eu venha a mudar a direção do que estamos criando. Isto por que, o processo de criação é dinâmico. Irei mostrar um pouco mais sobre como fazer as coisas no SQL. Isto por que, ele de fato é algo que você precisa entender e conhecer. Ficar simplesmente achando que é mais capaz, que toda uma comunidade de programadores e desenvolvedores, apenas lhe fará perder tempo e oportunidade. Tenha calma, pois a coisa irá se tornar ainda mais interessante.
Como eu disse há pouco. Ainda não tenho certeza de que usarei o SQLite ou uma outra implementação do SQL. Isto por que o desenvolvimento do que será feito, para o replay / simulador. É algo totalmente dinâmico. Ainda não nos decidimos em que direção de fato iremos seguir. Mas independentemente de como as coisas serão criadas e desenvolvidas, nos próximos passos, onde voltaremos para o MQL5. Com toda a certeza, iremos usar o SQL para nós auxiliar em diversas questões. Não pretendo e não vamos criar nenhuma rotina a fim de produzir algo que o SQL, nos permite fazer e nos auxilia. Mas a forma como iremos de fato usar o SQL, ainda não foi totalmente definida.
No próximo artigo, veremos como fazer algumas outras coisas no SQL. Isto por que agora, a coisa realmente começa a tomar mais corpo e o direcionamento, assim como o que pretendo abordar e explicar, já está quase em sua plenitude. No entanto, quero reforçar o fato de que estes artigos, não tem como foco serem um curso de SQL. Apenas quero mostrar alguns pontos que poderão vir a ser utilizados no futuro. Já que não faz sentido, usar o MQL5, ou qualquer outra linguagem para fazer algo que o próprio SQL poderá fazer para nós. E não estou falando apenas em questão de criar e manter um banco de dados. Estou falando em termos de programação em si.
Muitos apenas conhecem uns poucos comandos do SQL. Mas se esquecem ou não tem a devida curiosidade de se aprofundar em SQL. Perdendo assim a oportunidade de fazer uso de um verdadeiro auxiliar. Já que muitas das rotinas que alguns criam em linguagem que se integram ao SQL. Poderiam ser feitas diretamente pelo SQL. E saber como fazer este tipo de coisa, irá lhe ajudar bastante. Então procure se aprofundar no assunto. Use estes artigos daqui, apenas como um ponto de apoio. Mas não os tenha como única fonte, ou algo definitivo. Um grande abraço a todos, e nos vemos no próximo artigo.
| Arquivo | Descrição |
|---|---|
| Experts\Expert Advisor.mq5 | Demonstra a interação entre o Chart Trade e o Expert Advisor (É necessário o Mouse Study para interação) |
| Indicators\Chart Trade.mq5 | Cria a janela para configuração da ordem a ser enviada (É necessário o Mouse Study para interação) |
| Indicators\Market Replay.mq5 | Cria os controles para interação com o serviço de replay/simulador (É necessário o Mouse Study para interação) |
| Indicators\Mouse Study.mq5 | Permite interação entre os controles gráficos e o usuário (Necessário tanto para operar o replay simulador, quanto no mercado real) |
| Services\Market Replay.mq5 | Cria e mantém o serviço de replay e simulação de mercado (Arquivo principal de todo o sistema) |
| Code VS C++\Servidor.cpp | Cria e mantém um soquete servidor criado em C++ (Versão Mini Chat) |
| Code in Python\Server.py | Cria e mantém um soquete em python para comunicação entre o MetaTrader 5 e o Excel |
| Indicators\Mini Chat.mq5 | Permite implementar um mini chat via indicador (Necessário uso de um servidor para funcionar) |
| Experts\Mini Chat.mq5 | Permite implementar um mini chat via Expert Advisor (Necessário uso de um servidor para funcionar) |
| Scripts\SQLite.mq5 | Demonstra uso de script SQL por meio do MQL5 |
| Files\Script 01.sql | Demonstra a criação de uma tabela simples, com chave estrangeira |
| Files\Script 02.sql | Demonstra a adição de valores em uma tabela |
Referência
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso