
Asesores Expertos Auto-Optimizables con MQL5 y Python (Parte III): Descifrando el algoritmo del Boom 1000

Analizaremos todos los mercados sintéticos de Deriv individualmente, comenzando por su mercado sintético más conocido, el Boom 1000. El Boom 1000 es conocido por su comportamiento volátil e impredecible. El mercado se caracteriza por velas bajistas lentas, cortas y de tamaño uniforme, seguidas aleatoriamente por velas alcistas violentas del tamaño de un rascacielos. Las velas alcistas son especialmente difíciles de mitigar porque los ticks asociados con la vela normalmente no se envían a la terminal del cliente, lo que significa que todos los stop loss se rompen con un deslizamiento garantizado en cada ocasión.
Por lo tanto, la mayoría de los traders exitosos han creado estrategias basadas libremente en aprovechar únicamente oportunidades de compra cuando operan en el Boom 1000. Recuerde que el Boom 1000 podría caer durante 20 minutos en el gráfico M1 y retroceder todo ese movimiento en 1 vela. Por lo tanto, dada su naturaleza alcista excesivamente poderosa, los traders exitosos buscan usar esto para su beneficio al atribuir más peso a las configuraciones de compra en el Boom 1000 que a una configuración de venta.
Por otro lado, si pudiéramos simplemente crear una nueva variable dependiente, cuyo valor dependa de los niveles de precios del instrumento sintético de Deriv, podríamos haber creado una nueva relación que podamos modelar con más precisión que la que pudimos capturar al pronosticar el Boom 1000. En otras palabras, si aplicamos indicadores al mercado y modelamos la relación del indicador con el mercado, podemos obtener niveles de precisión más altos. Con suerte, nuestro nuevo objetivo no sólo nos proporcionará niveles de precisión más altos, sino que además será un reflejo fiel de los cambios reales en el precio. Es decir, si se espera que la lectura del indicador caiga, se espera que los niveles de precios también caigan. Recordemos que el aprendizaje automático se centra en aproximar una función asumiendo que tenemos las entradas de esa función, mientras que no tenemos ninguna de las entradas que Deriv utiliza en su algoritmo generador de números aleatorios, al aplicar un indicador a su mercado, tenemos acceso a todas las entradas de las que depende el indicador.
Descripción general de la metodología
Para evaluar la viabilidad de la estrategia propuesta, obtuvimos 100.000 filas de datos M1 y la lectura del indicador RSI para cada una de esas instancias en el tiempo desde nuestra terminal MetaTrader 5 usando un script personalizado que escribí para nosotros hoy. Después de leer el guión, realizamos un análisis exploratorio de datos. Descubrimos que el 83% de las veces cuando la lectura del RSI cae, los niveles de precios en el Boom 1000 también caen. Esto nos dice que hay virtud en poder predecir el valor del RSI porque nos da una idea de dónde estarán los niveles de precios. Sin embargo, esto también significa que aproximadamente el 17% de las veces el RSI nos llevará por mal camino.
Observamos niveles de correlación débiles entre el RSI y los niveles de precios en el Boom 1000, lecturas de 0,016. Ninguno de los diagramas de dispersión que realizamos expuso relaciones discernibles en los datos, incluso intentamos trazarlos en dimensiones más altas, pero esto también fue en vano; los datos parecen bastante difíciles de separar de manera efectiva.
Nuestros esfuerzos no terminaron allí, posteriormente dividimos nuestro conjunto de datos en dos mitades, una mitad para entrenamiento y optimización y la segunda para validación y para probar si hay sobreajuste. También creamos dos objetivos: uno capturaba los cambios en los niveles de precios, mientras que el segundo capturaba los cambios en la lectura del RSI.
Procedimos a entrenar dos clasificadores de redes neuronales profundas idénticos para predecir los cambios en los niveles de precios y en los niveles de RSI respectivamente, el primer modelo logró niveles de precisión de alrededor del 53% mientras que el último logró niveles de precisión de aproximadamente el 63%. Además, la varianza de nuestros niveles de error al predecir los cambios de RSI fue menor, lo que implica que el último modelo puede haber aprendido de manera más efectiva. Lamentablemente, no pudimos ajustar nuestra red neuronal profunda sin sobreajustarla al conjunto de entrenamiento; esto nos lo sugiere el hecho de que no logramos superar a la red neuronal predeterminada en datos de validación no vistos. Realizamos una validación cruzada de series de tiempo de cinco pasos sin mezcla aleatoria para medir nuestros niveles de precisión tanto en el entrenamiento como en la validación.
Seleccionamos el modelo RSI predeterminado como el modelo con mejor rendimiento y procedimos a exportarlo al formato ONNX y finalmente construimos nuestro Asesor Experto personalizado Boom 1000 impulsado por IA en MQL5.
Obteniendo los datos
Para comenzar, primero debemos obtener los datos que necesitamos de nuestra terminal MetaTrader 5, esta tarea la realiza nuestro práctico script MQL5. El script que he escrito recuperará las cotizaciones del mercado asociadas con el Boom 1000, la marca de tiempo de cada vela y la lectura RSI relevante antes de escribirlas en formato CSV para nosotros. Tenga en cuenta que configuramos el búfer RSI como serie antes de escribir los datos; este paso es crucial, de lo contrario, sus datos RSI estarán en orden cronológico inverso, que no es lo que desea.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","RSI"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), rsi_buffer[i] ); Print("Time: ",iTime(Symbol(),PERIOD_CURRENT,i),"Close: ",iClose(Symbol(),PERIOD_CURRENT,i),"RSI",rsi_buffer[i]); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Limpieza de datos
Ahora estamos listos para comenzar a preparar nuestros datos para la visualización. Primero importemos las bibliotecas que necesitamos.#Import the libraries we need import pandas as pd import numpy as np
Mostrar las versiones de la biblioteca.
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}")
Numpy versión 1.26.4
Ahora lea el archivo CSV.
#Read in the data we need boom_1000 = pd.read_csv("Market Data Boom 1000 Index.csv")
Veamos los datos.
#Let's see the data boom_1000
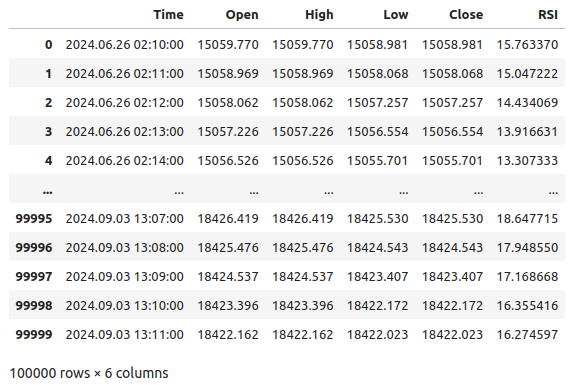
Figura 1: Nuestros datos de mercado de Boom 1000.
Definamos ahora nuestro horizonte de pronóstico.
#Define how far into the future we should forecast look_ahead = 20
Ahora necesitamos definir nuestro horizonte de pronóstico y también agregar etiquetas adicionales a los datos para fines de visualización y trazado.
#Let's add targets and labels for plotting boom_1000["Price Target"] = boom_1000["Close"].shift(-look_ahead) boom_1000["RSI Target"] = boom_1000["RSI"].shift(-look_ahead) #Let's also add binary targets for plotting purposes boom_1000["Price Binary Target"] = np.nan boom_1000["RSI Binary Target"] = np.nan #Label the binary targets boom_1000.loc[boom_1000["Price Target"] < boom_1000["Close"],"Price Binary Target"] = 0 boom_1000.loc[boom_1000["Price Target"] > boom_1000["Close"],"Price Binary Target"] = 1 boom_1000.loc[boom_1000["RSI Target"] < boom_1000["RSI"],"RSI Binary Target"] = 0 boom_1000.loc[boom_1000["RSI Target"] > boom_1000["RSI"],"RSI Binary Target"] = 1 #Drop na values boom_1000.dropna(inplace=True)
Definamos ahora las entradas de nuestro modelo y los dos objetivos que queremos comparar.
#Define the predictors and targets predictors = ["Open","High","Low","Close","RSI"] old_target = "Price Binary Target" new_target = "RSI Binary Target"
Análisis exploratorio de datos
Importemos las bibliotecas que necesitamos.
#Exploratory data analysis import seaborn as sns
Muestra la versión de la biblioteca que se está utilizando.
print(f"Seaborn version {sns.__version__}") Seaborn version 0.13.2Evaluemos la pureza de las señales generadas por el RSI. La pureza, en nuestro sentido, responde a la pregunta: «Si el nivel del RSI cae, ¿caerán también los precios?». Calculamos esta cantidad contando primero el número de casos en los que el RSI y el precio objetivo binario no coincidían. Luego, dividimos este recuento por el número total de filas del conjunto de datos. Restamos esta cantidad a 1 para obtener la proporción total de casos en los que el RSI y el precio objetivo binario coincidían. Según nuestros cálculos, parece que el 83% del tiempo, el RSI y el precio cambian en las mismas direcciones.
#Let's assess the purity of the signals generated
rsi_purity = 1 - boom_1000.loc[boom_1000["RSI Binary Target"] != boom_1000["Price Binary Target"]].shape[0] / boom_1000.shape[0]
print(f"Price and the RSI tend to move together {rsi_purity * 100}% of the time")
Esta cantidad es bastante alta, esto nos da ciertos niveles de confianza de que podremos obtener buenos niveles de separación al visualizar los datos. Comencemos creando un gráfico categórico para resumir todos los casos en los que el nivel RSI cayó, columna 0, o subió, columna 1 respectivamente en el eje x, y el precio de cierre está en el eje y. Posteriormente coloreamos cada punto, ya sea azul o naranja, para representar instancias en las cuales los niveles de precios del Boom 1000 se apreciaron o depreciaron respectivamente. Como podemos ver en el gráfico a continuación, la columna 0 es mayoritariamente azul con algunos parches de puntos naranjas, y lo opuesto es cierto para la columna 1. Esto nos muestra que el RSI parece ser un buen separador de cambios de precios aquí. Sin embargo, no es perfecto, es posible que necesitemos un indicador adicional en el futuro.
#Let's see this purity level we just calculated sns.catplot(data=boom_1000,x="RSI Binary Target",y="Close",hue="Price Binary Target")
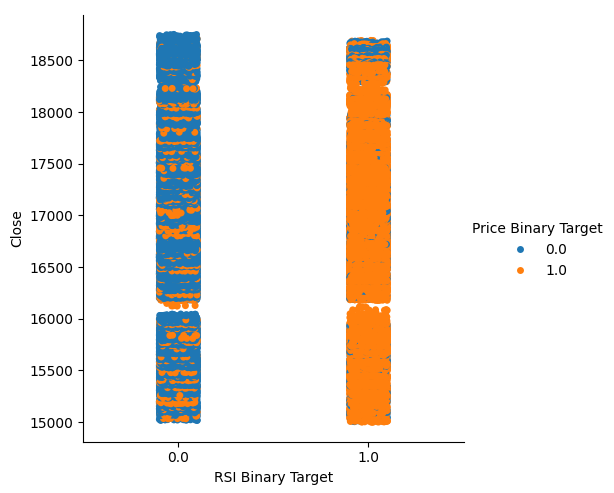
Figura 2: Un gráfico categórico que muestra qué tan bien nuestro RSI divide nuestros datos.
También creamos un diagrama de dispersión para intentar visualizar la relación entre el RSI y el precio de cierre del Boom 1000. Desafortunadamente, como podemos ver, no parece haber ninguna relación entre ambos. Observamos largas estelas, como espaguetis, de puntos azules y naranjas que se alternan al azar; esto puede indicarnos que hay otras variables que afectan al objetivo.
#Let us also observe a scatter plot of the two sns.scatterplot(data=boom_1000,x="RSI",y="Close",hue="Price Binary Target")
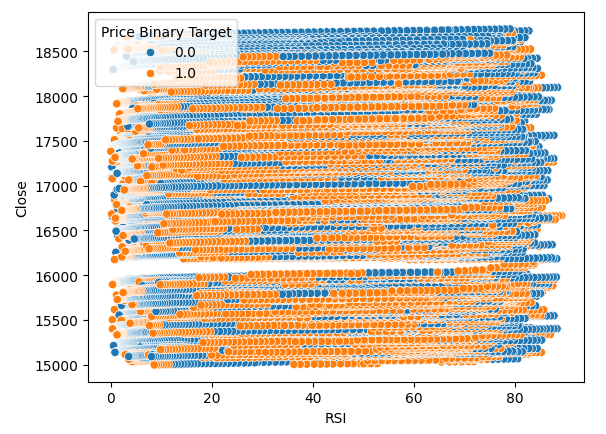
Figura 3: Un diagrama de dispersión de nuestras lecturas de RSI frente al precio de cierre.
Tal vez la relación que estamos intentando visualizar no se pueda ver en dos dimensiones; intentemos visualizar los datos en tres dimensiones; con suerte, podremos observar los efectos de interacción ocultos que no logramos ver.
Importamos las librerías que necesitamos.
#Let's create 3D scatter plots import matplotlib.pyplot as plt
Define cuántos datos quieres graficar.
#Define the plot end end = 10000
Ahora crea el gráfico de dispersión 3D. Lamentablemente, todavía podemos observar que los datos parecen estar distribuidos aleatoriamente sin patrones observables que podamos utilizar en nuestro beneficio.
#Visualizing our data in 3D fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'red' for movement in boom_1000.loc[0:end,"Price Binary Target"]] ax.scatter(boom_1000.loc[0:end,"RSI"],boom_1000.loc[0:end,"High"],boom_1000.loc[0:end,"Close"],c=colors) ax.set_xlabel('Boom 1000 RSI') ax.set_ylabel('Boom 1000 High') ax.set_zlabel('Boom 1000 Close')
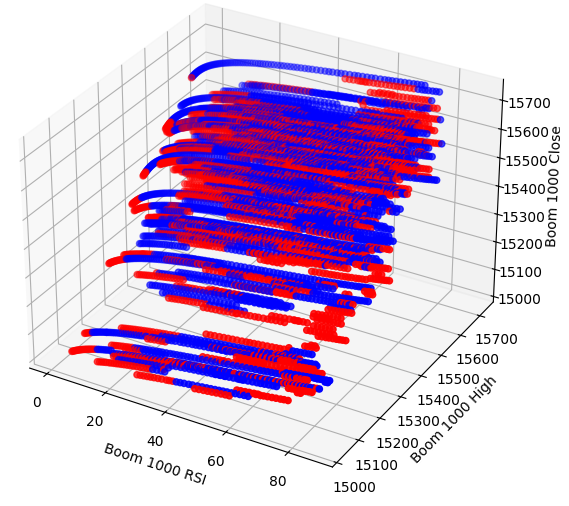
Figura 4: Un diagrama de dispersión 3D del mercado Boom 1000 y su relación con el RSI.
Analicemos ahora los niveles de correlación entre el RSI y nuestros datos de precios. Observamos niveles de correlación bastante pobres, casi 0 para ser precisos.
#Let's analyze the correlation levels sns.heatmap(boom_1000.loc[:,predictors].corr(),annot=True)
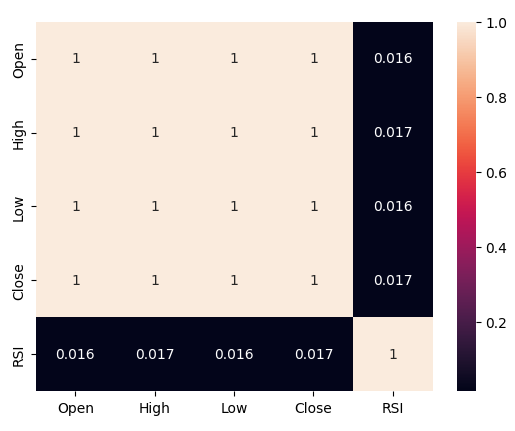
Figura 5: Un mapa de calor de nuestra matriz de correlación.
Preparación para modelar los datos
Antes de que podamos comenzar a modelar nuestros datos, primero necesitamos escalarlos y estandarizarlos. Primero, importemos las bibliotecas que necesitamos.
#Preparing to model the data import sklearn from sklearn.preprocessing import RobustScaler from sklearn.neural_network import MLPClassifier,MLPRegressor from sklearn.model_selection import TimeSeriesSplit, train_test_split from sklearn.metrics import accuracy_score
Mostrando la versión de la biblioteca.
#Display library version print(f"Sklearn version {sklearn.__version__}")
Escalar los datos.
#Scale our data
X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:,predictors]),columns=predictors)
Definiendo nuestros objetivos antiguos y nuevos.
#Our old and new target old_y = boom_1000.loc[:,"Price Binary Target"] new_y = boom_1000.loc[:,"RSI Binary Target"]
Realización de la prueba de tren dividido.
#Perform train test splits train_X,test_X,ohlc_train_y,ohlc_test_y = train_test_split(X,old_y,shuffle=False,test_size=0.5) _,_,rsi_train_y,rsi_test_y = train_test_split(X,new_y,shuffle=False,test_size=0.5)
Prepare un marco de datos para almacenar nuestros niveles de precisión en la validación.
#Prepare data frames to store our accuracy levels validation_accuracy = pd.DataFrame(index=np.arange(0,5),columns=["Close Accuracy","RSI Accuracy"])
Ahora vamos a crear un objeto spit de serie temporal.
#Let's create the time series split object tscv = TimeSeriesSplit(gap=look_ahead,n_splits=5)
Modelado de datos
Ahora estamos listos para realizar la validación cruzada para observar el cambio en los niveles de precisión entre los 2 posibles objetivos.
#Instatiate the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) #Cross validate the model for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],:],ohlc_train_y.loc[train[0]:train[-1]]) validation_accuracy.iloc[i,0] = accuracy_score(ohlc_train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],:]))
Nuestros niveles de precisión.
validation_accuracy
| Precisión de cierre | Precisión del RSI |
|---|---|
| 0.53703 | 0.663186 |
| 0.544592 | 0.623575 |
| 0.479534 | 0.597647 |
| 0.57064 | 0.651422 |
| 0.545913 | 0.616373 |
Nuestros niveles de precisión promedio nos muestran instantáneamente que podemos estar mejor prediciendo cambios en el valor del RSI.
validation_accuracy.mean()
Precisión RSI 0.630441
dtype: object
Cuanto menor sea la desviación estándar, más certeza tendrá el modelo en sus predicciones. El modelo parece haber aprendido a pronosticar el RSI con más certeza que los cambios en el precio.
validation_accuracy.std()
Precisión RSI 0.026613
dtype: object
Grafiquemos el rendimiento de cada uno de nuestros modelos.
validation_accuracy.plot()
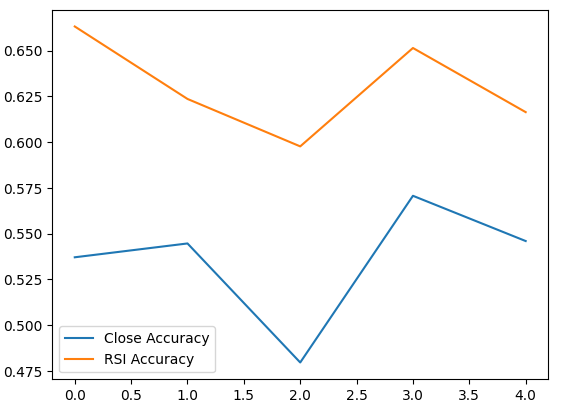
Figura 6: Visualizando nuestra precisión de validación.
Por último, los diagramas de caja nos ayudan a observar la diferencia de rendimiento entre nuestros dos modelos. Como podemos ver, el modelo RSI está superando ampliamente al modelo de precios.
#Our RSI validation accuracy is better
sns.boxplot(validation_accuracy)
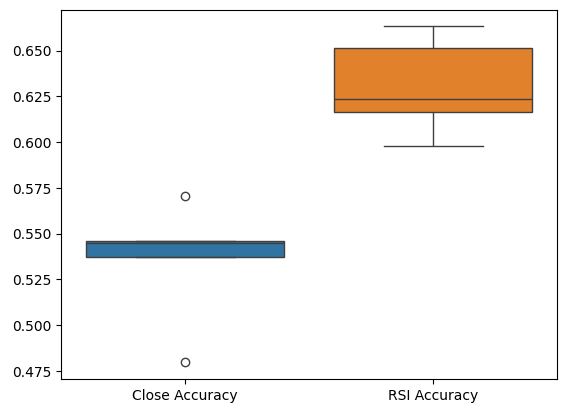
Figura 7: Diagramas de caja de nuestra precisión en la validación.
Importancia de las características
Analicemos ahora qué características son importantes para predecir el valor de RSI, comenzaremos realizando una selección hacia adelante en nuestra red neuronal. La selección hacia adelante comienza con un modelo nulo y agrega secuencialmente una característica a la vez hasta que no se puedan realizar más mejoras al rendimiento del modelo.Primero, importaremos las bibliotecas que necesitamos.
#Feature importance import mlxtend from mlxtend.feature_selection import SequentialFeatureSelector as SFS
Ahora muestra la versión de la biblioteca.
print(f"Mlxtend version: {mlxtend.__version__}")
Reiniciar el modelo.
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
Configurar el selector de funciones.
#Define the forward feature selector sfs1 = SFS( model, k_features=(1,X.shape[1]), n_jobs=-1, forward=True, cv=5, scoring="accuracy" )
Ajuste el selector de funciones.
#Fit the feature selector
sfs = sfs1.fit(train_X,rsi_train_y)
Veamos las características más importantes que hemos identificado. Se seleccionaron todas las funciones disponibles.
sfs.k_feature_names_
Visualicemos el proceso de selección de características. Primero, importamos las bibliotecas que necesitamos.
#Importing the libraries we need from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Ahora graficamos los resultados.
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_err')
plt.title('Sequential Forward Selection')
plt.grid()
plt.show()
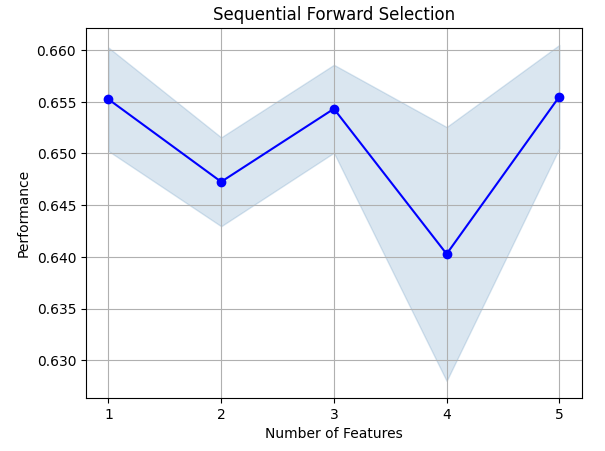
Figura 8: Visualización del proceso de selección de características.
La información mutua (Mutual information, MI) nos permite comprender el potencial que tiene cada predictor. Generalmente, cuanto mayor sea la puntuación MI, más útil puede ser el predictor. MI puede capturar dependencias no lineales en los datos. Por último, MI se mide en una escala logarítmica, lo que significa que es raro ver puntuaciones de MI superiores a 3 en la práctica.
Importamos las librerías que necesitamos.
#Let's analyze our MI scores from sklearn.feature_selection import mutual_info_classif
Calcular puntuaciones MI.
mi_scores = pd.DataFrame(mutual_info_classif(train_X,rsi_train_y).reshape(1,5),columns=predictors)
Al trazar los resultados se observa que la columna RSI es la columna más importante según MI.
#Let's visualize the results mi_scores.plot.bar()
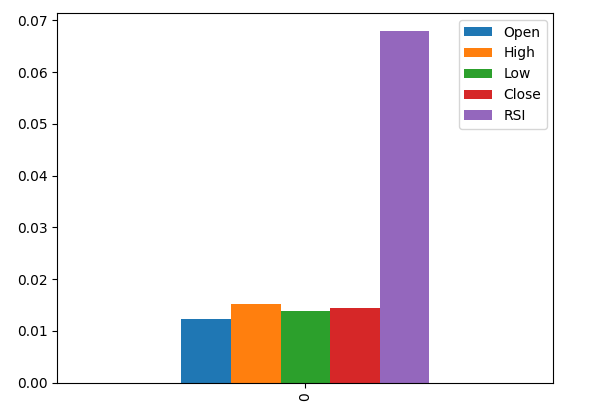
Figura 9: Visualización de nuestras puntuaciones de MI.
Ajuste de parámetros
Ahora intentaremos ajustar nuestro modelo para obtener aún más rendimiento de él. El módulo RandomizedSearchCV de la biblioteca sklearn nos permite ajustar fácilmente nuestros modelos de aprendizaje automático. Al ajustar modelos de aprendizaje automático, es necesario lograr un equilibrio entre precisión y tiempo de cálculo. Ajustamos el número total de iteraciones para decidir entre los dos. Importemos las bibliotecas que necesitamos.
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV
Inicializar el modelo.
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
Define el objeto ajustador.
#Define the tuner tuner = RandomizedSearchCV( model, { "activation":["relu","tanh","logistic","identity"], "solver":["adam","sgd","lbfgs"], "alpha":[0.1,0.01,0.001,0.00001,0.000001], "learning_rate": ["constant","invscaling","adaptive"], "learning_rate_init":[0.1,0.01,0.001,0.0001,0.000001,0.0000001], "power_t":[0.1,0.5,0.9,0.01,0.001,0.0001], "shuffle":[True,False], "tol":[0.1,0.01,0.001,0.0001,0.00001], }, n_iter=300, cv=5, n_jobs=-1, scoring="accuracy" )
Ajustar el objeto de ajuste.
#Fit the tuner
tuner_results =tuner.fit(train_X,rsi_train_y)
Los mejores parámetros que hemos encontrado.
#Best parameters
tuner_results.best_params_ 'solver': 'lbfgs',
'shuffle': True,
'power_t': 0.0001,
'learning_rate_init': 0.01,
'learning_rate': 'adaptive',
'alpha': 1e-06,
'activation': 'logistic'}
Prueba de sobreajuste
Para probar el sobreajuste, validaremos de forma cruzada un modelo predeterminado y nuestro modelo personalizado en los datos de validación. Si nuestro modelo predeterminado funciona mejor, entonces sabremos que estábamos sobreajustando el conjunto de entrenamiento. De lo contrario, realizamos con éxito el ajuste de hiperparámetros.
Inicializar los 2 modelos.
#Testing for overfitting default_model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) customized_model = MLPClassifier( hidden_layer_sizes=(30,10), max_iter=200, tol=0.00001, solver="lbfgs", shuffle=True, power_t=0.0001, learning_rate_init=0.01, learning_rate="adaptive", alpha=0.000001, activation="logistic" )
Ajuste ambos modelos a los datos de entrenamiento.
#First we will train both models on the training set
default_model.fit(train_X,rsi_train_y)
customized_model.fit(train_X,rsi_train_y)
Restablecer los índices en ambos conjuntos de datos.
#Now we will reset our indexes
rsi_test_y = rsi_test_y.reset_index()
test_X = test_X.reset_index()
Formatear los datos.
#Format the data rsi_test_y = rsi_test_y.loc[:,"RSI Binary Target"] test_X = test_X.loc[:,predictors]
Prepare un marco de datos para almacenar nuestros niveles de precisión.
#Prepare a data frame to store our accuracy levels validation_error = pd.DataFrame(index=np.arange(0,5),columns=["Default Neural Network","Customized Neural Network"])
Validación cruzada de cada modelo para comprobar si hay sobreajuste.
#Perform cross validation for i,(train,test) in enumerate(tscv.split(test_X)): customized_model.fit(test_X.loc[train[0]:train[-1],predictors],rsi_test_y.loc[train[0]:train[-1]]) validation_error.iloc[i,1] = accuracy_score(rsi_test_y.loc[test[0]:test[-1]],customized_model.predict(test_X.loc[test[0]:test[-1]]))
Nuestros niveles de desempeño en validación.
validation_error
| Red neuronal por defecto | Red neuronal personalizada |
|---|---|
| 0.627656 | 0.597767 |
| 0.637258 | 0.635938 |
| 0.621414 | 0.631977 |
| 0.6429 | 0.6411 |
| 0.664866 | 0.652503 |
El análisis de nuestros niveles de rendimiento medio muestra claramente que el modelo predeterminado fue ligeramente mejor que el modelo personalizado que tenemos.
validation_error.mean()
Red neuronal personalizada 0.631857
dtype: object
Además, nuestro modelo personalizado demostró mayor habilidad debido a la menor variación en sus puntuaciones de precisión.
validation_error.std()
Red neuronal personalizada 0.020557
dtype: object
Grafiquemos nuestros resultados.
validation_error.plot()
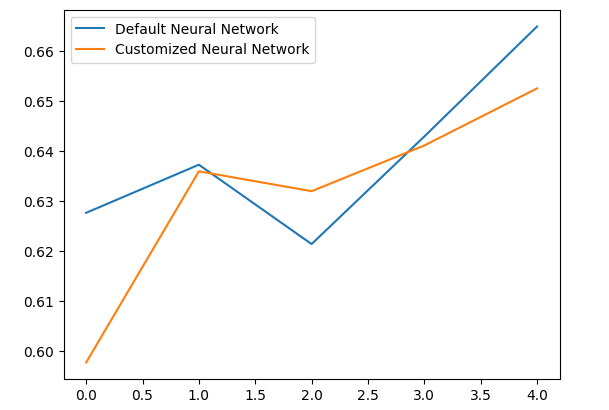
Figura 10: Visualización de nuestra prueba de sobreajuste.
Los diagramas de caja muestran que nuestro modelo personalizado parece menos estable y tiene valores atípicos que no observamos en el modelo predeterminado. Además, nuestro modelo predeterminado tiene un rendimiento promedio ligeramente mejor. Por lo tanto, seleccionaremos el modelo predeterminado en lugar del modelo personalizado.
sns.boxplot(validation_error)
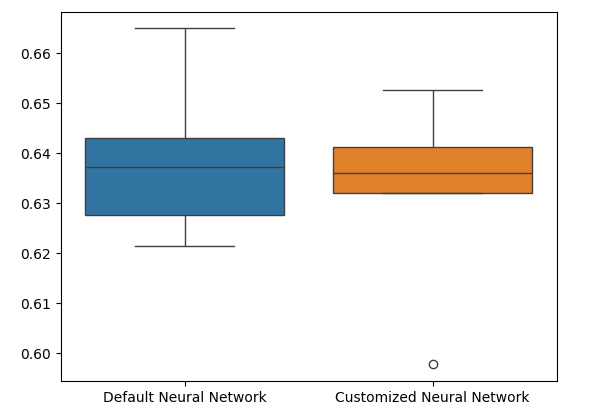
Figura 11: Visualización de nuestra prueba de sobreajuste II.
Preparándose para exportar a ONNX
Antes de poder exportar nuestro modelo al formato ONNX, primero debemos escalar los datos de una manera que podamos reproducir en nuestro terminal MetaTrader 5. Restaremos la media de la columna de cada columna y la dividiremos por la desviación estándar de la columna, esto asegura que nuestro modelo aprenda de manera efectiva ya que nuestros datos están en diferentes escalas. Además, exportaremos los valores de media y desviación estándar en formato CSV para que podamos recuperarlos más tarde.#Preparing to export to ONNX #Let's scale our data scaling_factors = pd.DataFrame(columns=predictors,index=['mean','standard deviation']) X = boom_1000.loc[:,predictors] y = boom_1000.loc[:,"RSI Target"]
Escala cada columna.
#Let's fill each column for i in np.arange(0,len(predictors)): scaling_factors.iloc[0,i] = X.iloc[:,i].mean() scaling_factors.iloc[1,i] = X.iloc[:,i].std() X.iloc[:,i] = ( ( X.iloc[:,i] - scaling_factors.iloc[0,i] ) / scaling_factors.iloc[1,i])
Guarde los factores de escala en formato CSV.
#Save the scaling factors as a CSV scaling_factors.to_csv("/home/volatily/.wine/drive_c/Program Files/MetaTrader 5/MQL5/Files/boom_1000_scaling_factors.csv")
Exportando a ONNX
Open Neural Network Exchange (ONNX) es un marco de aprendizaje automático interoperable de código abierto que permite a los desarrolladores crear, compartir y utilizar modelos de aprendizaje automático en cualquier lenguaje de programación que amplíe el soporte a la API ONNX. Esto nos permite construir nuestros modelos de aprendizaje automático en Python e implementarlos en MQL5 en producción.Primero, importaremos las bibliotecas que necesitamos.
#Exporting to ONNX
import onnx
import netron
import skl2onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
Mostrar las versiones de la biblioteca.
#Display the library versions print(f"Onnx version {onnx.__version__}") print(f"Netron version {netron.__version__}") print(f"Skl2onnx version {skl2onnx.__version__}")
Netron versión 7.8.0
Skl2onnx versión 1.16.0
Define los tipos de entrada de nuestro modelo.
#Define the model input types initial_types = [("float_input",FloatTensorType([1,5]))]
Ajuste el modelo a todos los datos que tenemos.
#Fit the model on all the data we have default_model = MLPRegressor(hidden_layer_sizes=(30,10),max_iter=200) default_model.fit(X,y)
Convierte el modelo en su representación ONNX.
#Convert the model to an ONNX representation onnx_model = convert_sklearn(default_model,initial_types=initial_types,target_opset=12)
Guarde la representación ONNX en un archivo.
#Save the ONNX representation onnx_name = "Boom 1000 Neural Network.onnx" onnx.save(onnx_model,onnx_name)
Ver el modelo usando Netron.
#View the onnx model
netron.start(onnx_name)

Figura 12: Visualización de nuestra red neuronal profunda.

Figura 13: Visualización de las entradas y salidas de nuestro modelo.
Implementación en MQL5
Para crear una aplicación comercial con un sistema de IA integrado, primero necesitaremos el modelo ONNX que acabamos de exportar en Python.
//+------------------------------------------------------------------+ //| Boom 1000.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| ONNX Model | //+------------------------------------------------------------------+ #resource "\\Files\\Boom 1000 Neural Network.onnx" as const uchar onnx_buffer[];
Carguemos también la biblioteca comercial para gestionar nuestras posiciones.
//+-----------------------------------------------------------------+ //| Libraries we need | //+-----------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Definiendo variables globales que utilizaremos a lo largo de nuestro programa.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; int rsi_handler,model_state,system_state; double mean_values[5],std_values[5],rsi_buffer[],bid,ask; vectorf model_outputs = vectorf::Zeros(1); vectorf model_inputs = vectorf::Zeros(5);
Definamos ahora una función para preparar nuestro modelo ONNX. Esta función primero creará nuestro modelo a partir del buffer que definimos al comienzo de nuestro programa, y validará que el modelo no esté dañado, si está dañado la función retornará falso y esto terminará el procedimiento de inicialización. Desde allí, la función procederá a establecer las formas de entrada y salida de nuestro modelo ONNX, si no logramos definir alguno de los parámetros de E/S, nuestra función volverá a devolver falso y finalizará el procedimiento de inicialización.
//+------------------------------------------------------------------+ //| This function will prepare our ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- First create the ONNX model from the buffer we created earlier onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the ONNX model if(onnx_model == INVALID_HANDLE) { Comment("[ERROR] Failed to create the ONNX model: ",GetLastError()); return(false); } //--- Set the input and output shapes of the model ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the input and output shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape: ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape: ",GetLastError()); return(false); } return(true); }
No podemos utilizar nuestro modelo ONNX sin escalar las entradas de nuestro modelo, la siguiente función cargará los valores de media y desviación estándar que necesitamos en matrices a las que podemos acceder fácilmente.
//+-----------------------------------------------------------------+ //| Load the scaling values | //+-----------------------------------------------------------------+ void load_scaling_values(void) { //--- BOOM 1000 OHLC + RSI Mean values mean_values[0] = 16799.87389394667; mean_values[1] = 16800.872890865994; mean_values[2] = 16798.91007345616; mean_values[3] = 16799.908906749482; mean_values[4] = 43.45867626462568; //--- BOOM 1000 OHLC + RSI Mean std values std_values[0] = 864.3356132780019; std_values[1] = 864.3839684000297; std_values[2] = 864.2859346216392; std_values[3] = 864.3344430387272; std_values[4] = 20.593175501388043; } //+------------------------------------------------------------------+
También necesitamos definir una función que obtenga los precios de mercado actualizados para nosotros y el valor de nuestro indicador técnico actual.
//+------------------------------------------------------------------+ //| Fetch updated market prices and technical indicator values | //+------------------------------------------------------------------+ void update_market_data(void) { //--- Market data bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); //--- Technical indicator values CopyBuffer(rsi_handler,0,0,1,rsi_buffer); }
Por último, necesitamos una función que obtenga las entradas de nuestro modelo, las escale y obtenga una predicción de nuestro modelo. Mantendremos una bandera para recordar la predicción de nuestro modelo, esto nos ayudará a darnos cuenta fácilmente cuando nuestro modelo está pronosticando una reversión.
//+------------------------------------------------------------------+ //| Fetch a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { //--- Get the model inputs model_inputs[0] = iOpen(_Symbol,PERIOD_CURRENT,0); model_inputs[1] = iHigh(_Symbol,PERIOD_CURRENT,0); model_inputs[2] = iLow(_Symbol,PERIOD_CURRENT,0); model_inputs[3] = iClose(_Symbol,PERIOD_CURRENT,0); model_inputs[4] = rsi_buffer[0]; //--- Scale the model inputs for(int i = 0; i < 5; i++) { model_inputs[i] = ((model_inputs[i] - mean_values[i]) / std_values[i]); } //--- Fetch a prediction from our model OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs); //--- Give user feedback Comment("Model RSI Forecast: ",model_outputs[0]); //--- Store the model's state if(rsi_buffer[0] > model_outputs[0]) { model_state = -1; } else if(rsi_buffer[0] < model_outputs[0]) { model_state = 1; } }
Ahora, definiremos el procedimiento de inicialización de nuestro modelo. Comenzaremos cargando nuestro modelo ONNX, luego obtendremos los valores de escala y configuraremos nuestro indicador RSI.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- This function will prepare our ONNX model and set the input and output shapes if(!load_onnx_model()) { return(INIT_FAILED); } //--- This function will prepare our scaling values load_scaling_values(); //--- Setup our technical indicatot rsi_handler = iRSI(Symbol(),PERIOD_CURRENT,20,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
Cada vez que nuestra aplicación sea eliminada del gráfico, liberaremos los recursos que ya no utilizamos, liberaremos el modelo ONNX, el indicador RSI y eliminaremos el Asesor Experto.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the resources we no longer need OnnxRelease(onnx_model); IndicatorRelease(rsi_handler); ExpertRemove(); }
Cada vez que recibamos precios actualizados, primero buscaremos datos técnicos y de mercado actualizados, esto incluye los precios de oferta y demanda, así como la lectura del RSI. Entonces estaremos listos para obtener una nueva predicción de nuestro modelo. Si no tenemos posiciones abiertas, seguiremos la predicción de nuestro modelo y recordaremos nuestra posición actual usando una bandera binaria. De lo contrario, si ya tenemos una posición abierta, verificaremos si la nueva predicción de nuestro modelo va en contra de nuestra posición abierta, si es así, cerraremos nuestra posición. De lo contrario, seguiremos obteniendo beneficios.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated market prices update_market_data(); //--- On every tick we need to fetch a prediction from our model model_predict(); //--- If we have no open positions, follow the model's prediction if(PositionsTotal() == 0) { //--- Our model detected a spike if(model_state == 1) { Trade.Buy(0.2,Symbol(),ask,0,0,"BOOM 1000 AI"); system_state = 1; } //--- Our model detected a drop if(model_state == -1) { Trade.Sell(0.2,Symbol(),bid,0,0,"BOOM 1000 AI"); system_state = -1; } } //--- If we have open positiosn, our AI system will decide when to close them else if(PositionsTotal() > 0) { if(system_state != model_state) { //--- Close the positions we opened Alert("Reversal detected by the AI system,closing all positions now!"); Trade.PositionClose(Symbol()); } } } //+------------------------------------------------------------------+

Figura 14: Nuestro sistema Boom 1000 logró atrapar un pico.

Figura 15: Nuestro sistema Boom 1000 detectó una reversión.
Conclusión
En el artículo de hoy hemos demostrado que es posible construir Asesores Expertos autooptimizables para abordar incluso los instrumentos sintéticos más desafiantes. Además, hemos demostrado que el enfoque tradicional de pronosticar los niveles de precios directamente no sería suficiente en los mercados algorítmicos actuales.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/15781
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

 Creación de un asesor experto integrado de MQL5 y Telegram (Parte 5): Envío de comandos desde Telegram a MQL5 y recepción de respuestas en tiempo real
Creación de un asesor experto integrado de MQL5 y Telegram (Parte 5): Envío de comandos desde Telegram a MQL5 y recepción de respuestas en tiempo real
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Analizaremos individualmente todos los mercados sintéticos Deriv, empezando por el más famoso: el Boom 1000.
¡Muchas gracias por el artículo! Llevo mucho tiempo mirando estos índices, pero no sabía desde qué lado acercarme a ellos.
Por favor, ¡continúen!
He probado varias herramientas y en todas ellas su modelo da unerror debido a un desajuste entre las dimensiones de los datos de entrada (X) y las variables objetivo (y).
Muchas gracias por el artículo. Llevo mucho tiempo analizando estos índices, pero no sabía muy bien por dónde enfocarlos.
Por favor, ¡continúen!
De nada, Janis.
Definitivamente continuaré. Hay mucho que cubrir, pero voy a crear tiempo.
He probado varias herramientas, y en cada una de ellas tu modelo da un error debido a tamaños inconsistentes de los datos de entrada (X) y las variables objetivo (y).
Hola Aliaksandr, puedes utilizar el código como modelo guía, y luego hacer los ajustes necesarios por tu cuenta. También te recomendaría probar diferentes indicadores, probar diferentes variaciones de la idea general del artículo. Eso nos ayudará a entender la verdad global más rápido.
He probado varias herramientas y todas ellas provocan errores en el modelo debido a incoherencias en el tamaño de los datos de entrada (X) y la variable objetivo (y).
# Mantener la coherencia de los índices, de lo contrario se reconstruirán los índices si hay datos filtrados X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:, predictors]), columns=predictors, index=boom_1000.index)