
Selbstoptimierender Expert Advisor mit MQL5 und Python (Teil III): Den Boom-1000-Algorithmus knacken

Wir werden alle synthetischen Märkte von Deriv einzeln analysieren, beginnend mit ihrem bekanntesten synthetischen Markt, dem Boom 1000. Der Boom 1000 ist berüchtigt für sein volatiles und unberechenbares Verhalten. Der Markt ist durch langsame, kurze und gleich große Abwärtskerzen gekennzeichnet, auf die in unregelmäßigen Abständen heftige, wolkenkratzergroße Aufwärtskerzen folgen. Die Aufwärtskerzen sind besonders schwierig zu entschärfen, weil die mit der Kerze verbundenen Ticks normalerweise nicht an das Kundenterminal gesendet werden, was bedeutet, dass alle Stop-Losses jedes Mal mit garantiertem Slippage durchbrochen werden.
Daher haben die meisten erfolgreichen Händler Strategien entwickelt, die darauf basieren, beim Handel mit dem Boom 1000 nur Kaufgelegenheiten wahrzunehmen. Erinnern Sie sich daran, dass der Boom 1000 auf dem M1-Chart 20 Minuten lang fallen kann und diese gesamte Bewegung dann in einer Aufwärtskerze auf den Anfang zurückspringen kann! Angesichts des übermächtigen steigenden Charakters des Boom 1000 versuchen erfolgreiche Händler, dies zu ihrem Vorteil zu nutzen, indem sie einem Kauf-Setup beim Boom 1000 mehr Gewicht beimessen als einem Verkaufs-Setup.
Wenn wir andererseits einfach eine neue abhängige Variable schaffen können, deren Wert von den Preisniveaus des synthetischen Instruments von Deriv abhängt, haben wir möglicherweise eine neue Beziehung geschaffen, die wir mit größerer Genauigkeit modellieren können, als wir sie bei der Prognose des Booms 1000 erfassen konnten. Mit anderen Worten: Wenn wir Indikatoren auf den Markt anwenden und die Beziehung des Indikators zum Markt modellieren, können wir eine höhere Genauigkeit erzielen. Wir hoffen, dass unsere neue Zielvorgabe nicht nur eine höhere Genauigkeit bietet, sondern auch die tatsächlichen Preisänderungen getreu widerspiegelt. Das heißt, wenn ein Rückgang des Indikatorwerts erwartet wird, ist auch ein Rückgang des Preisniveaus zu erwarten. Erinnern Sie sich daran, dass es beim maschinellen Lernen darum geht, eine Funktion unter der Annahme zu approximieren, dass wir die Eingaben dieser Funktion haben. Während wir keine der Eingaben haben, die Deriv in ihrem Algorithmus der Zufallszahlengenerator verwendet, haben wir durch die Anwendung eines Indikators auf ihren Markt Zugang zu allen Eingaben, von denen der Indikator abhängt.
Überblick über die Methodik
Um die Durchführbarkeit der vorgeschlagenen Strategie zu beurteilen, haben wir 100.000 Zeilen von M1-Daten und den RSI-Indikatorwert für jede dieser Instanzen in der Zeit von unserem MetaTrader 5-Terminal mit einem angepassten Skript, das ich heute für uns geschrieben habe, abgerufen. Nach dem Einlesen des Skripts führten wir eine explorative Datenanalyse durch. Wir haben festgestellt, dass in 83 % der Fälle, in denen der RSI-Wert fällt, auch die Kurse des Boom 1000 fallen. Dies zeigt uns, dass es von Vorteil ist, den RSI-Wert vorhersagen zu können, denn er gibt uns eine Vorstellung davon, wo die Kursniveaus liegen werden. Das bedeutet aber auch, dass uns der RSI in etwa 17 % der Fälle in die Irre führen wird.
Wir haben eine schwache Korrelation zwischen dem RSI und den Kursen an der Boom 1000 beobachtet, die bei 0,016 liegt. Keines der von uns erstellten Streudiagramme enthüllte irgendwelche erkennbaren Beziehungen in den Daten, wir versuchten sogar, die Daten in höheren Dimensionen darzustellen, aber auch das war vergeblich, die Daten scheinen ziemlich schwierig effektiv zu trennen.
Wir haben unseren Datensatz anschließend in zwei Hälften geteilt, eine Hälfte zum Trainieren und Optimieren und die zweite zur Validierung und zum Testen auf Überanpassung. Wir haben auch zwei Ziele erstellt, wobei ein Ziel die Veränderungen der Kursniveaus erfasst, während das zweite Ziel die Veränderungen des RSI-Wertes abbildet.
Wir trainierten zwei identische tiefe neuronale Netzwerk-Klassifikatoren zur Vorhersage von Kursveränderungen bzw. RSI-Werten. Das erste Modell erreichte eine Genauigkeit von etwa 53 %, während das zweite Modell eine Genauigkeit von etwa 63 % erreichte. Außerdem war die Varianz unserer Fehler bei der Vorhersage der RSI-Änderungen geringer, was bedeutet, dass das letztgenannte Modell möglicherweise besser gelernt hat. Leider waren wir nicht in der Lage, unser tiefes neuronales Netzwerk ohne Überanpassung an den Trainingssatz zu optimieren. Dies wird uns durch die Tatsache suggeriert, dass wir das standardmäßige neuronale Netzwerk bei ungesehenen Validierungsdaten nicht übertreffen konnten. Wir haben eine 5-fache Zeitreihen-Kreuzvalidierung ohne zufälliges Shuffling durchgeführt, um unsere Genauigkeitsstufen sowohl beim Training als auch bei der Validierung zu messen.
Wir wählten das Standard-RSI-Modell als das Modell mit der besten Performance aus, exportierten es in das ONNX-Format und erstellten schließlich unseren maßgeschneiderten Boom 1000 AI-powered Expert Advisor in MQL5.
Abrufen der Daten
Um loszulegen, müssen wir zunächst die benötigten Daten von unserem MetaTrader 5-Terminal abrufen. Diese Aufgabe übernimmt unser praktisches MQL5-Skript für uns. Das Skript, das ich geschrieben habe, holt die Marktkurse, die mit dem Boom 1000 verbunden sind, den Zeitstempel jeder Kerze und den relevanten RSI-Wert, bevor es sie im CSV-Format für uns ausschreibt. Beachten Sie, dass wir den RSI-Puffer als Zeitreihe einstellen, bevor wir die Daten ausgeben. Dieser Schritt ist entscheidend, da Ihre RSI-Daten sonst in umgekehrter chronologischer Reihenfolge erscheinen, was nicht erwünscht ist.
//+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/users/gamuchiraindawa" #property version "1.00" #property script_show_inputs //+------------------------------------------------------------------+ //| Script Inputs | //+------------------------------------------------------------------+ input int size = 100000; //How much data should we fetch? //+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int rsi_handler; double rsi_buffer[]; //+------------------------------------------------------------------+ //| On start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load indicator rsi_handler = iRSI(_Symbol,PERIOD_CURRENT,20,PRICE_CLOSE); CopyBuffer(rsi_handler,0,0,size,rsi_buffer); ArraySetAsSeries(rsi_buffer,true); //--- File name string file_name = "Market Data " + Symbol() + ".csv"; //--- Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i= size;i>=0;i--) { if(i == size) { FileWrite(file_handle,"Time","Open","High","Low","Close","RSI"); } else { FileWrite(file_handle,iTime(Symbol(),PERIOD_CURRENT,i), iOpen(Symbol(),PERIOD_CURRENT,i), iHigh(Symbol(),PERIOD_CURRENT,i), iLow(Symbol(),PERIOD_CURRENT,i), iClose(Symbol(),PERIOD_CURRENT,i), rsi_buffer[i] ); Print("Time: ",iTime(Symbol(),PERIOD_CURRENT,i),"Close: ",iClose(Symbol(),PERIOD_CURRENT,i),"RSI",rsi_buffer[i]); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Datenbereinigung
Jetzt können wir damit beginnen, unsere Daten für die Visualisierung vorzubereiten. Lassen Sie uns zunächst die benötigten Bibliotheken importieren.#Import the libraries we need import pandas as pd import numpy as np
Anzeige der Bibliotheksversionen.
#Display library versions print(f"Pandas version {pd.__version__}") print(f"Numpy version {np.__version__}")
Numpy Version 1.26.4
Lesen wir nun die CSV-Datei ein.
#Read in the data we need boom_1000 = pd.read_csv("Market Data Boom 1000 Index.csv")
Schauen wir uns die Daten an.
#Let's see the data boom_1000
Abb. 1: Unsere Boom 1000 Marktdaten
Definieren wir nun unseren Prognosehorizont.
#Define how far into the future we should forecast look_ahead = 20
Nun müssen wir unseren Prognosehorizont festlegen und den Daten zusätzliche Beschriftungen für die Visualisierung und die grafische Darstellung hinzufügen.
#Let's add targets and labels for plotting boom_1000["Price Target"] = boom_1000["Close"].shift(-look_ahead) boom_1000["RSI Target"] = boom_1000["RSI"].shift(-look_ahead) #Let's also add binary targets for plotting purposes boom_1000["Price Binary Target"] = np.nan boom_1000["RSI Binary Target"] = np.nan #Label the binary targets boom_1000.loc[boom_1000["Price Target"] < boom_1000["Close"],"Price Binary Target"] = 0 boom_1000.loc[boom_1000["Price Target"] > boom_1000["Close"],"Price Binary Target"] = 1 boom_1000.loc[boom_1000["RSI Target"] < boom_1000["RSI"],"RSI Binary Target"] = 0 boom_1000.loc[boom_1000["RSI Target"] > boom_1000["RSI"],"RSI Binary Target"] = 1 #Drop na values boom_1000.dropna(inplace=True)
Definieren wir nun unsere Modelleingaben und die beiden Ziele, die wir vergleichen wollen.
#Define the predictors and targets predictors = ["Open","High","Low","Close","RSI"] old_target = "Price Binary Target" new_target = "RSI Binary Target"
Explorative Datenanalyse
Importieren wir nun die benötigten Bibliotheken.
#Exploratory data analysis import seaborn as sns
Anzeige der Version der verwendeten Bibliothek.
print(f"Seaborn version {sns.__version__}") Seaborn version 0.13.2Beurteilen wir die Reinheit der vom RSI erzeugten Signale, so beantwortet die Reinheit in unserem Sinne die Frage: „Wenn der RSI-Wert fällt, fallen dann auch die Kurse?“ Wir berechneten diese Fallzahlen, indem wir zunächst die Anzahl der Fälle zählten, in denen der RSI und das binäre Kursziel nicht übereinstimmten, und dann diese Anzahl durch die Gesamtzahl der Zeilen im gesamten Datensatz teilten. Diese Menge wurde von 1 abgezogen, um den Gesamtanteil der Fälle zu erhalten, in denen der RSI und das binäre Kursziel übereinstimmten. Unseren Berechnungen zufolge scheinen sich der RSI und der Preis in 83 % der Fälle in dieselbe Richtung zu bewegen.
#Let's assess the purity of the signals generated
rsi_purity = 1 - boom_1000.loc[boom_1000["RSI Binary Target"] != boom_1000["Price Binary Target"]].shape[0] / boom_1000.shape[0]
print(f"Price and the RSI tend to move together {rsi_purity * 100}% of the time")
Dieser Wert ist recht hoch, was uns ein gewisses Maß an Zuversicht gibt, dass wir bei der Visualisierung der Daten ein gutes Trennungsniveau erreichen können. Beginnen wir mit der Erstellung eines kategorischen Diagramms, um alle Fälle zusammenzufassen, in denen der RSI-Wert auf der x-Achse gefallen (Spalte 0) bzw. gestiegen ist (Spalte 1), während der Schlusskurs auf der y-Achse liegt. Anschließend haben wir jeden Punkt entweder blau oder orange eingefärbt, um die Fälle darzustellen, in denen das Preisniveau des Booms 1000 gestiegen bzw. gesunken ist. Wie aus der nachstehenden Grafik ersichtlich ist, ist Spalte 0 überwiegend blau mit einigen orangefarbenen Punkten, während für Spalte 1 das Gegenteil zutrifft. Dies zeigt uns, dass der RSI hier ein guter Indikator für Kursveränderungen zu sein scheint. Er ist jedoch nicht perfekt, sodass wir in Zukunft möglicherweise einen zusätzlichen Indikator benötigen.
#Let's see this purity level we just calculated sns.catplot(data=boom_1000,x="RSI Binary Target",y="Close",hue="Price Binary Target")
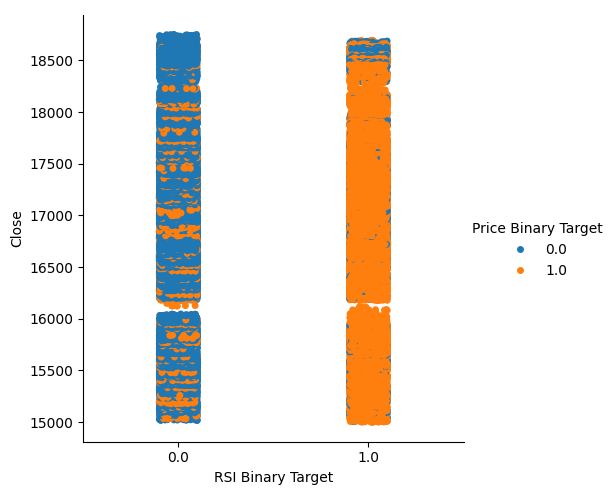
Abb. 2: Ein kategoriales Diagramm, das zeigt, wie gut unser RSI unsere Daten aufteilt
Wir haben auch ein Streudiagramm erstellt, um zu versuchen, die Beziehung zwischen dem RSI und dem Schlusskurs des Boom 1000 zu visualisieren. Leider scheint es, wie wir sehen können, keinen Zusammenhang zwischen beiden zu geben. Wir beobachten lange, spaghettiartige Spuren von blauen und orangefarbenen Punkten, die sich willkürlich abwechseln, was uns darauf hinweisen könnte, dass es noch andere Variablen gibt, die das Ziel beeinflussen.
#Let us also observe a scatter plot of the two sns.scatterplot(data=boom_1000,x="RSI",y="Close",hue="Price Binary Target")
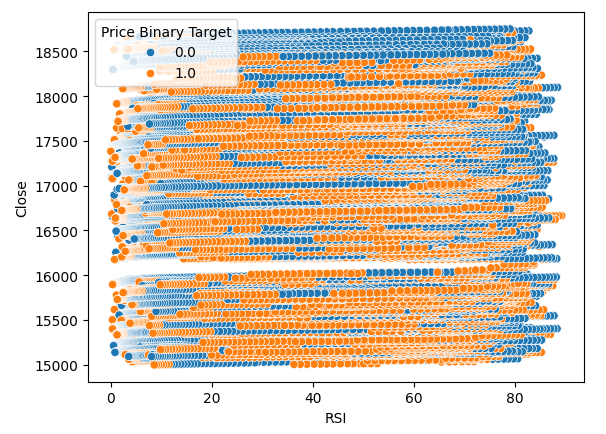
Abb. 3: Ein Streudiagramm unserer RSI-Werte gegen den Schlusskurs
Vielleicht ist die Beziehung, die wir zu visualisieren versuchen, in zwei Dimensionen nicht zu erkennen. Versuchen wir, die Daten in drei Dimensionen zu visualisieren, dann können wir hoffentlich die versteckten Interaktionseffekte beobachten, die wir nicht sehen.
Importieren wir die benötigten Bibliotheken.
#Let's create 3D scatter plots import matplotlib.pyplot as plt
Wir legen fest, wie viele Daten gezeichnet werden sollen.
#Define the plot end end = 10000
Erstellen wir nun das 3D-Streudiagramm. Leider können wir immer noch feststellen, dass die Daten zufällig verteilt sind und keine Muster erkennbar sind, die wir zu unserem Vorteil nutzen können.
#Visualizing our data in 3D fig = plt.figure(figsize=(7,7)) ax = fig.add_subplot(111,projection='3d') colors = ['blue' if movement == 0 else 'red' for movement in boom_1000.loc[0:end,"Price Binary Target"]] ax.scatter(boom_1000.loc[0:end,"RSI"],boom_1000.loc[0:end,"High"],boom_1000.loc[0:end,"Close"],c=colors) ax.set_xlabel('Boom 1000 RSI') ax.set_ylabel('Boom 1000 High') ax.set_zlabel('Boom 1000 Close')
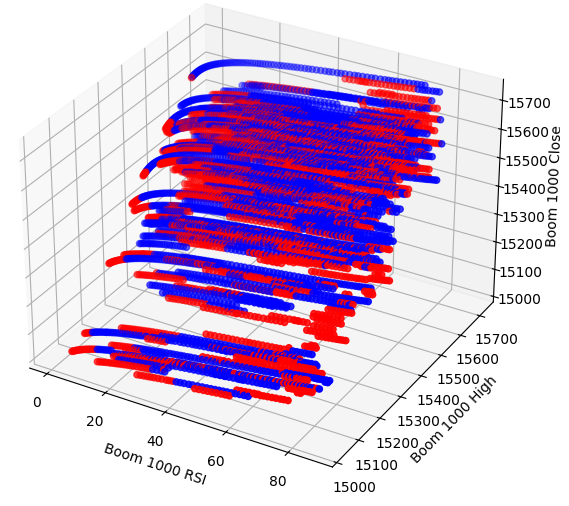
Abb. 4: Ein 3D-Streudiagramm des Boom 1000-Marktes und seine Beziehung zum RSI
Analysieren wir nun die Korrelationsniveaus zwischen dem RSI und unseren Kursdaten. Die Korrelationswerte sind eher gering, um genau zu sein fast 0.
#Let's analyze the correlation levels sns.heatmap(boom_1000.loc[:,predictors].corr(),annot=True)
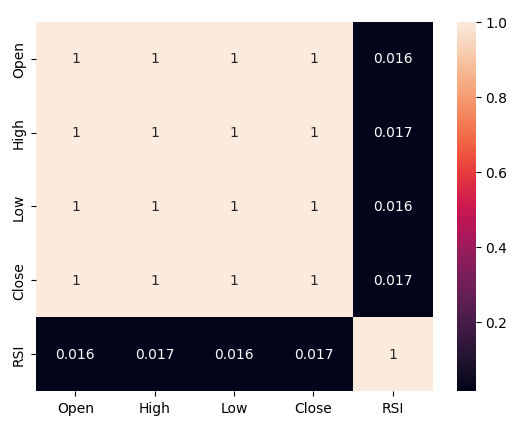
Abb. 5: Die Heatmap unserer Korrelationsmatrix
Vorbereiten der Datenmodellierung
Bevor wir mit der Modellierung unserer Daten beginnen können, müssen wir die Daten zunächst skalieren und standardisieren. Lassen Sie uns zunächst die benötigten Bibliotheken importieren.
#Preparing to model the data import sklearn from sklearn.preprocessing import RobustScaler from sklearn.neural_network import MLPClassifier,MLPRegressor from sklearn.model_selection import TimeSeriesSplit, train_test_split from sklearn.metrics import accuracy_score
Anzeige der Bibliotheksversion.
#Display library version print(f"Sklearn version {sklearn.__version__}")
Skalieren wir die Daten.
#Scale our data
X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:,predictors]),columns=predictors)
Festlegung unserer alten und neuen Ziele.
#Our old and new target old_y = boom_1000.loc[:,"Price Binary Target"] new_y = boom_1000.loc[:,"RSI Binary Target"]
Durchführung der Aufteilung in Trainings- und Test-Daten.
#Perform train test splits train_X,test_X,ohlc_train_y,ohlc_test_y = train_test_split(X,old_y,shuffle=False,test_size=0.5) _,_,rsi_train_y,rsi_test_y = train_test_split(X,new_y,shuffle=False,test_size=0.5)
Bereiten wir einen Datenrahmen vor, um unsere Genauigkeitsstufen in der Validierung zu speichern.
#Prepare data frames to store our accuracy levels validation_accuracy = pd.DataFrame(index=np.arange(0,5),columns=["Close Accuracy","RSI Accuracy"])
Lassen Sie uns nun das Objekt der aufgeteilten Zeitreihen erstellen.
#Let's create the time series split object tscv = TimeSeriesSplit(gap=look_ahead,n_splits=5)
Modellierung der Daten
Wir sind nun bereit, eine Kreuzvalidierung durchzuführen, um die Veränderung der Genauigkeit zwischen den 2 möglichen Zielen zu beobachten.
#Instatiate the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) #Cross validate the model for i,(train,test) in enumerate(tscv.split(train_X)): model.fit(train_X.loc[train[0]:train[-1],:],ohlc_train_y.loc[train[0]:train[-1]]) validation_accuracy.iloc[i,0] = accuracy_score(ohlc_train_y.loc[test[0]:test[-1]],model.predict(train_X.loc[test[0]:test[-1],:]))
Unser Genauigkeitsniveau.
validation_accuracy
| Genauigkeit des Schlusskurses (close) | Genauigkeit des RSI |
|---|---|
| 0.53703 | 0.663186 |
| 0.544592 | 0.623575 |
| 0.479534 | 0.597647 |
| 0.57064 | 0.651422 |
| 0.545913 | 0.616373 |
Die mittleren Genauigkeitsstufen zeigen uns sofort, dass wir möglicherweise besser dran sind, wenn wir Veränderungen des RSI-Werts vorhersagen.
validation_accuracy.mean()
Genauigkeit des RSI 0.630441
dtype: object
Je geringer die Standardabweichung, desto sicherer ist das Modell in seinen Vorhersagen. Das Modell scheint gelernt zu haben, den RSI mit größerer Sicherheit vorherzusagen als die Preisveränderungen.
validation_accuracy.std()
Genauigkeit des RSI 0.026613
dtype: object
Lassen Sie uns die Leistung jedes unserer Modelle aufzeichnen.
validation_accuracy.plot()
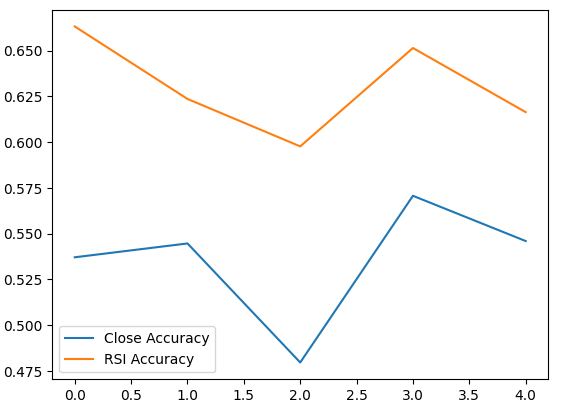
Abb. 6: Visualisierung unserer Validierungsgenauigkeit
Schließlich helfen uns Boxplots, die Leistungsunterschiede zwischen unseren beiden Modellen zu beobachten. Wie wir sehen können, übertrifft das RSI-Modell das Preismodell bei weitem.
#Our RSI validation accuracy is better
sns.boxplot(validation_accuracy)
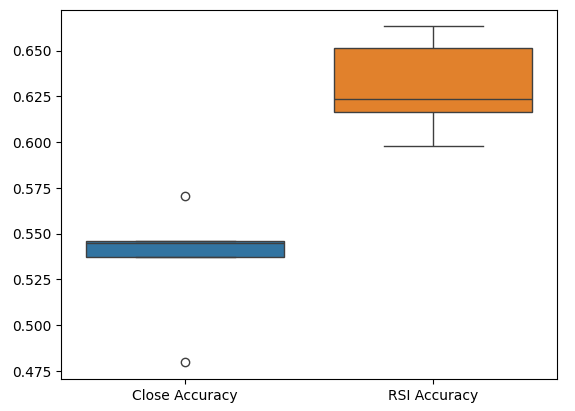
Abb. 7: Boxplots unserer Genauigkeit bei der Validierung
Die Bedeutung der Merkmale
Analysieren wir nun, welche Merkmale für die Vorhersage des RSI-Werts wichtig sind, indem wir zunächst eine Vorwärtsauswahl für unser neuronales Netzwerk durchführen. Die Vorwärtsselektion beginnt mit einem Nullmodell und fügt nacheinander ein Merkmal nach dem anderen hinzu, bis die Leistung des Modells nicht mehr verbessert werden kann.Zunächst werden wir die benötigten Bibliotheken importieren.
#Feature importance import mlxtend from mlxtend.feature_selection import SequentialFeatureSelector as SFS
Zeigen wir nun die Version der Bibliothek an.
print(f"Mlxtend version: {mlxtend.__version__}")
Reinitialisieren wir das Modell,
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
richten den Funktionswähler ein
#Define the forward feature selector sfs1 = SFS( model, k_features=(1,X.shape[1]), n_jobs=-1, forward=True, cv=5, scoring="accuracy" )
und passen den Funktionswähler an.
#Fit the feature selector
sfs = sfs1.fit(train_X,rsi_train_y)
Sehen wir uns die wichtigsten Merkmale an, die wir ermittelt haben. Es wurden alle verfügbaren Merkmale ausgewählt.
sfs.k_feature_names_
Lassen Sie uns den Prozess der Merkmalsauswahl visualisieren. Zunächst importieren wir die benötigten Bibliotheken.
#Importing the libraries we need from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs import matplotlib.pyplot as plt
Nun stellen wir die Ergebnisse dar.
fig1 = plot_sfs(sfs.get_metric_dict(), kind='std_err')
plt.title('Sequential Forward Selection')
plt.grid()
plt.show()
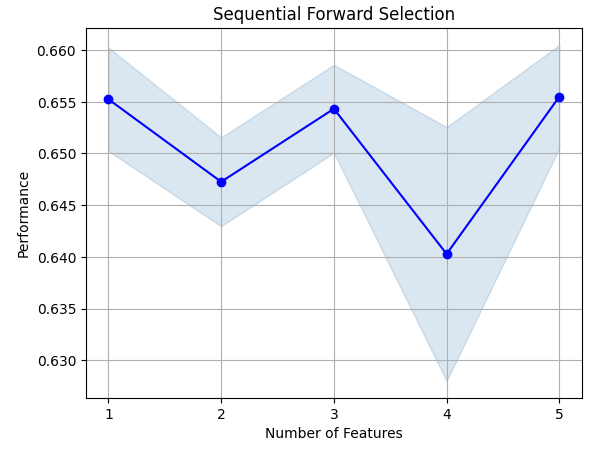
Abb. 8: Visualisierung des Prozesses der Merkmalsauswahl
Die wechselseitigen Information (MI) ermöglicht es uns, das Potenzial der einzelnen Prädiktoren zu verstehen. Je höher der MI-Wert ist, desto nützlicher ist der Prädiktor im Allgemeinen. MI kann nicht-lineare Abhängigkeiten in den Daten erfassen. Schließlich ist die MI auf einer logarithmischen Skala aufgebaut, was bedeutet, dass MI-Werte über 3 in der Praxis selten vorkommen.
Importieren wir die benötigten Bibliotheken
#Let's analyze our MI scores from sklearn.feature_selection import mutual_info_classif
und berechnen die MI-Bewertungen.
mi_scores = pd.DataFrame(mutual_info_classif(train_X,rsi_train_y).reshape(1,5),columns=predictors)
Die grafische Darstellung der Ergebnisse zeigt, dass die RSI-Spalte die wichtigste Spalte nach dem MI ist.
#Let's visualize the results mi_scores.plot.bar()
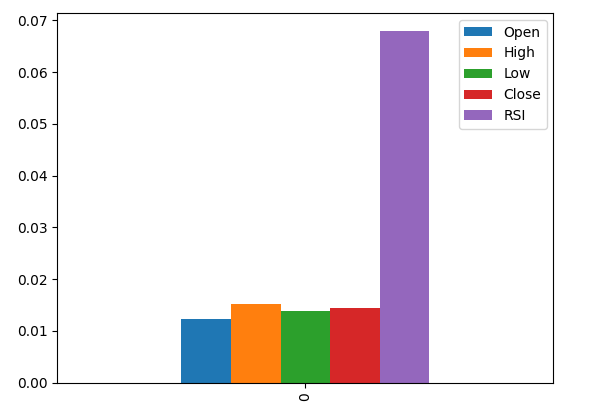
Abb. 9: Visualisierung unserer MI-Bewertungen
Einstellen der Parameter
Wir werden nun versuchen, unser Modell zu optimieren, um noch mehr Leistung aus ihm herauszuholen. Das Modul RandomizedSearchCV in der sklearn-Bibliothek ermöglicht es uns, unsere maschinellen Lernmodelle auf einfache Weise zu optimieren. Bei der Abstimmung von Modellen des maschinellen Lernens muss ein Kompromiss zwischen Genauigkeit und Rechenzeit gefunden werden. Wir passen die Gesamtzahl der Iterationen an, um zwischen den beiden Varianten zu entscheiden. Importieren wir nun die benötigten Bibliotheken.
#Parameter tuning
from sklearn.model_selection import RandomizedSearchCV
Initialisieren wir das Modell,
#Reinitialize the model model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200)
definieren das Tuner-Objekt
#Define the tuner tuner = RandomizedSearchCV( model, { "activation":["relu","tanh","logistic","identity"], "solver":["adam","sgd","lbfgs"], "alpha":[0.1,0.01,0.001,0.00001,0.000001], "learning_rate": ["constant","invscaling","adaptive"], "learning_rate_init":[0.1,0.01,0.001,0.0001,0.000001,0.0000001], "power_t":[0.1,0.5,0.9,0.01,0.001,0.0001], "shuffle":[True,False], "tol":[0.1,0.01,0.001,0.0001,0.00001], }, n_iter=300, cv=5, n_jobs=-1, scoring="accuracy" )
und passen das Tuner-Objekt an.
#Fit the tuner
tuner_results =tuner.fit(train_X,rsi_train_y)
Die besten Parameter, die wir gefunden haben.
#Best parameters
tuner_results.best_params_ 'solver': 'lbfgs',
'shuffle': True,
'power_t': 0.0001,
'learning_rate_init': 0.01,
'learning_rate': 'adaptive',
'alpha': 1e-06,
'activation': 'logistic'}
Testen auf Überanpassung
Um die Überanpassung zu testen, werden wir ein Standardmodell und unser angepasstes Modell anhand der Validierungsdaten kreuzvalidieren. Wenn unser Standardmodell besser abschneidet, dann wissen wir, dass wir die Trainingsmenge zu gut angepasst haben. Andernfalls haben wir die Abstimmung der Hyperparameter erfolgreich durchgeführt.
Initialisieren wir die 2 Modelle.
#Testing for overfitting default_model = MLPClassifier(hidden_layer_sizes=(30,10),max_iter=200) customized_model = MLPClassifier( hidden_layer_sizes=(30,10), max_iter=200, tol=0.00001, solver="lbfgs", shuffle=True, power_t=0.0001, learning_rate_init=0.01, learning_rate="adaptive", alpha=0.000001, activation="logistic" )
Passen wir beide Modelle an die Trainingsdaten an,
#First we will train both models on the training set
default_model.fit(train_X,rsi_train_y)
customized_model.fit(train_X,rsi_train_y)
setzen die Indizes für beide Datensätze zurück
#Now we will reset our indexes
rsi_test_y = rsi_test_y.reset_index()
test_X = test_X.reset_index()
und formatieren die Daten
#Format the data rsi_test_y = rsi_test_y.loc[:,"RSI Binary Target"] test_X = test_X.loc[:,predictors]
Wir bereiten einen Datenrahmen vor, um unsere Genauigkeitsstufen zu speichern.
#Prepare a data frame to store our accuracy levels validation_error = pd.DataFrame(index=np.arange(0,5),columns=["Default Neural Network","Customized Neural Network"])
Die Kreuzvalidierung jedes Modells zur Prüfung auf Überanpassung.
#Perform cross validation for i,(train,test) in enumerate(tscv.split(test_X)): customized_model.fit(test_X.loc[train[0]:train[-1],predictors],rsi_test_y.loc[train[0]:train[-1]]) validation_error.iloc[i,1] = accuracy_score(rsi_test_y.loc[test[0]:test[-1]],customized_model.predict(test_X.loc[test[0]:test[-1]]))
Unser Leistungsniveau bei der Validierung.
validation_error
| Standard Neuronales Netzwerk | Nutzerdefiniertes, neuronales Netzwerk |
|---|---|
| 0.627656 | 0.597767 |
| 0.637258 | 0.635938 |
| 0.621414 | 0.631977 |
| 0.6429 | 0.6411 |
| 0.664866 | 0.652503 |
Die Analyse unserer mittleren Leistungsniveaus zeigt deutlich, dass das Standardmodell etwas besser war als das angepasste Modell, das wir haben.
validation_error.mean()
Angepasstes neuronales Netzwerk 0.631857
dtype: object
Darüber hinaus zeigte unser angepasstes Modell aufgrund der geringeren Varianz in seinen Genauigkeitswerten eine höhere Kompetenz.
validation_error.std()
Nutzerdefiniertes, neuronales Netzwerk 0.020557
dtype: object
Lassen Sie uns unsere Ergebnisse grafisch darstellen.
validation_error.plot()
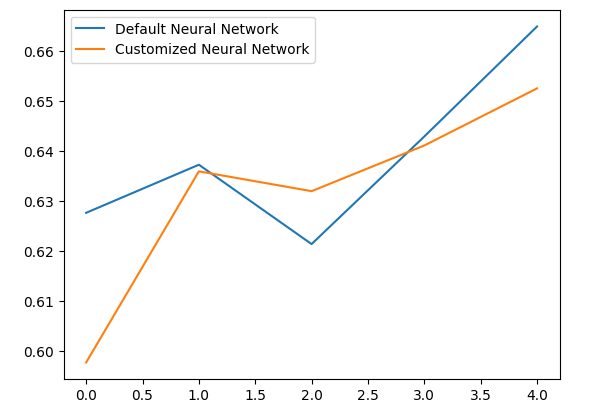
Abb. 10: Visualisierung unseres Tests zur Überanpassung
Die Boxplots zeigen, dass unser angepasstes Modell weniger stabil erscheint, es weist Ausreißer auf, die wir beim Standardmodell nicht beobachten können. Außerdem hat unser Standardmodell eine etwas bessere durchschnittliche Leistung. Daher werden wir das Standardmodell dem angepassten Modell vorziehen.
sns.boxplot(validation_error)
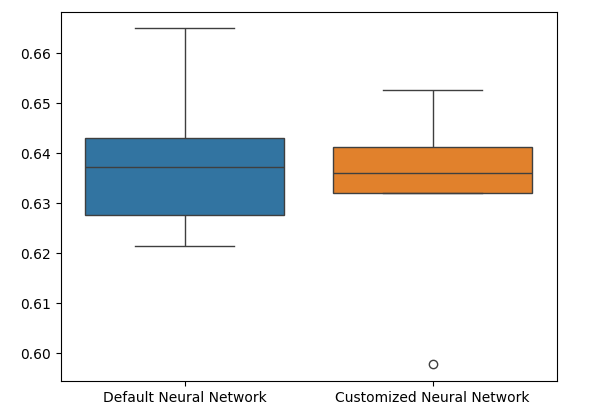
Abb. 11: Visualisierung unseres Tests auf Überanpassung II
Vorbereitungen für den Exports nach ONNX
Bevor wir unser Modell in das ONNX-Format exportieren können, müssen wir die Daten zunächst so skalieren, dass wir sie in unserem MetaTrader 5 Terminal reproduzieren können. Wir subtrahieren den Spaltenmittelwert von jeder Spalte und teilen ihn durch die Standardabweichung der Spalte, um sicherzustellen, dass unser Modell effektiv lernt, da unsere Daten auf unterschiedlichen Skalen liegen. Außerdem werden wir die Werte für Mittelwert und Standardabweichung im CSV-Format exportieren, damit wir sie später abrufen können.#Preparing to export to ONNX #Let's scale our data scaling_factors = pd.DataFrame(columns=predictors,index=['mean','standard deviation']) X = boom_1000.loc[:,predictors] y = boom_1000.loc[:,"RSI Target"]
Skalieren wir jede Spalte
#Let's fill each column for i in np.arange(0,len(predictors)): scaling_factors.iloc[0,i] = X.iloc[:,i].mean() scaling_factors.iloc[1,i] = X.iloc[:,i].std() X.iloc[:,i] = ( ( X.iloc[:,i] - scaling_factors.iloc[0,i] ) / scaling_factors.iloc[1,i])
und speichern die Skalierungsfaktoren im CSV-Format.
#Save the scaling factors as a CSV scaling_factors.to_csv("/home/volatily/.wine/drive_c/Program Files/MetaTrader 5/MQL5/Files/boom_1000_scaling_factors.csv")
Exportieren nach ONNX
Open Neural Network Exchange (ONNX) ist ein quelloffenes, interoperables Framework für maschinelles Lernen, das es Entwicklern ermöglicht, Modelle für maschinelles Lernen in jeder Programmiersprache zu erstellen, auszutauschen und zu verwenden, die das ONNX-API unterstützt. So können wir unsere maschinellen Lernmodelle in Python erstellen und sie in MQL5 in der Produktion einsetzen.Zunächst werden wir die benötigten Bibliotheken importieren.
#Exporting to ONNX
import onnx
import netron
import skl2onnx
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
Anzeige der Bibliotheksversionen.
#Display the library versions print(f"Onnx version {onnx.__version__}") print(f"Netron version {netron.__version__}") print(f"Skl2onnx version {skl2onnx.__version__}")
Netron Version 7.8.0
Skl2onnx Version 1.16.0
Definieren wir die Eingabetypen für unser Modell,
#Define the model input types initial_types = [("float_input",FloatTensorType([1,5]))]
passen das Modell an alle Daten an, die wir haben,
#Fit the model on all the data we have default_model = MLPRegressor(hidden_layer_sizes=(30,10),max_iter=200) default_model.fit(X,y)
wandeln das Modell in seine ONNX-Darstellung um
#Convert the model to an ONNX representation onnx_model = convert_sklearn(default_model,initial_types=initial_types,target_opset=12)
und speichern die ONNX-Darstellung in einer Datei.
#Save the ONNX representation onnx_name = "Boom 1000 Neural Network.onnx" onnx.save(onnx_model,onnx_name)
Betrachten wir das Modell mit netron.
#View the onnx model
netron.start(onnx_name)

Abb. 12: Visualisierung unseres tiefen neuronalen Netzwerks

Abb. 13: Visualisierung der Inputs und Outputs unseres Modells
Implementation in MQL5
Um eine Handelsanwendung mit einem integrierten KI-System zu erstellen, benötigen wir zunächst das ONNX-Modell, das wir gerade in Python exportiert haben.
//+------------------------------------------------------------------+ //| Boom 1000.mq5 | //| Gamuchirai Zororo Ndawana | //| https://www.mql5.com/en/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Zororo Ndawana" #property link "https://www.mql5.com/en/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| ONNX Model | //+------------------------------------------------------------------+ #resource "\\Files\\Boom 1000 Neural Network.onnx" as const uchar onnx_buffer[];
Lassen Sie uns auch die Handelsbibliothek für die Verwaltung unserer Positionen laden.
//+-----------------------------------------------------------------+ //| Libraries we need | //+-----------------------------------------------------------------+ #include <Trade/Trade.mqh> CTrade Trade;
Definition von globalen Variablen, die wir im gesamten Programm verwenden werden.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; int rsi_handler,model_state,system_state; double mean_values[5],std_values[5],rsi_buffer[],bid,ask; vectorf model_outputs = vectorf::Zeros(1); vectorf model_inputs = vectorf::Zeros(5);
Definieren wir nun eine Funktion zur Vorbereitung unseres ONNX-Modells. Diese Funktion erstellt zunächst unser Modell aus dem Puffer, den wir zu Beginn unseres Programms definiert haben, und überprüft, ob das Modell nicht beschädigt ist. Ist es beschädigt, gibt die Funktion false zurück und beendet damit die Initialisierungsprozedur. Von dort aus fährt die Funktion fort, die Eingangs- und Ausgangsformen unseres ONNX-Modells festzulegen. Wenn wir keinen der E/A-Parameter definieren können, gibt unsere Funktion erneut false zurück und beendet die Initialisierungsprozedur.
//+------------------------------------------------------------------+ //| This function will prepare our ONNX model | //+------------------------------------------------------------------+ bool load_onnx_model(void) { //--- First create the ONNX model from the buffer we created earlier onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Validate the ONNX model if(onnx_model == INVALID_HANDLE) { Comment("[ERROR] Failed to create the ONNX model: ",GetLastError()); return(false); } //--- Set the input and output shapes of the model ulong input_shape[] = {1,5}; ulong output_shape[] = {1,1}; //--- Validate the input and output shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Comment("Failed to set the ONNX model input shape: ",GetLastError()); return(false); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Comment("Failed to set the ONNX model output shape: ",GetLastError()); return(false); } return(true); }
Wir können unser ONNX-Modell nicht verwenden, ohne unsere Modelleingaben zu skalieren. Die folgende Funktion lädt die benötigten Werte für Mittelwert und Standardabweichung in Arrays, auf die wir leicht zugreifen können.
//+-----------------------------------------------------------------+ //| Load the scaling values | //+-----------------------------------------------------------------+ void load_scaling_values(void) { //--- BOOM 1000 OHLC + RSI Mean values mean_values[0] = 16799.87389394667; mean_values[1] = 16800.872890865994; mean_values[2] = 16798.91007345616; mean_values[3] = 16799.908906749482; mean_values[4] = 43.45867626462568; //--- BOOM 1000 OHLC + RSI Mean std values std_values[0] = 864.3356132780019; std_values[1] = 864.3839684000297; std_values[2] = 864.2859346216392; std_values[3] = 864.3344430387272; std_values[4] = 20.593175501388043; } //+------------------------------------------------------------------+
Außerdem müssen wir eine Funktion definieren, die die aktuellen Marktpreise und den aktuellen Wert unseres technischen Indikators abruft.
//+------------------------------------------------------------------+ //| Fetch updated market prices and technical indicator values | //+------------------------------------------------------------------+ void update_market_data(void) { //--- Market data bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); //--- Technical indicator values CopyBuffer(rsi_handler,0,0,1,rsi_buffer); }
Schließlich benötigen wir eine Funktion, die die Eingaben unseres Modells abruft, sie skaliert und eine Vorhersage von unserem Modell abruft. Wir werden die Vorhersage unseres Modells mit einer Flag kennzeichnen, damit wir leicht erkennen können, wann unser Modell eine Umkehrung vorhersagt.
//+------------------------------------------------------------------+ //| Fetch a prediction from our model | //+------------------------------------------------------------------+ void model_predict(void) { //--- Get the model inputs model_inputs[0] = iOpen(_Symbol,PERIOD_CURRENT,0); model_inputs[1] = iHigh(_Symbol,PERIOD_CURRENT,0); model_inputs[2] = iLow(_Symbol,PERIOD_CURRENT,0); model_inputs[3] = iClose(_Symbol,PERIOD_CURRENT,0); model_inputs[4] = rsi_buffer[0]; //--- Scale the model inputs for(int i = 0; i < 5; i++) { model_inputs[i] = ((model_inputs[i] - mean_values[i]) / std_values[i]); } //--- Fetch a prediction from our model OnnxRun(onnx_model,ONNX_DEFAULT,model_inputs,model_outputs); //--- Give user feedback Comment("Model RSI Forecast: ",model_outputs[0]); //--- Store the model's state if(rsi_buffer[0] > model_outputs[0]) { model_state = -1; } else if(rsi_buffer[0] < model_outputs[0]) { model_state = 1; } }
Nun werden wir die Initialisierungsprozedur unseres Modells definieren. Wir beginnen mit dem Laden unseres ONNX-Modells, holen dann die Skalierungswerte ab und richten den RSI-Indikator ein.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- This function will prepare our ONNX model and set the input and output shapes if(!load_onnx_model()) { return(INIT_FAILED); } //--- This function will prepare our scaling values load_scaling_values(); //--- Setup our technical indicatot rsi_handler = iRSI(Symbol(),PERIOD_CURRENT,20,PRICE_CLOSE); //--- Everything went fine return(INIT_SUCCEEDED); }
Sobald unsere Anwendung aus dem Chart entfernt wurde, werden wir die nicht mehr benötigten Ressourcen freigeben, das ONNX-Modell und den RSI-Indikator freigeben und den Expert Advisor entfernen.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Release the resources we no longer need OnnxRelease(onnx_model); IndicatorRelease(rsi_handler); ExpertRemove(); }
Immer wenn wir aktualisierte Kurse erhalten, holen wir zunächst aktualisierte Markt- und technische Daten ein, darunter die Geld- und Briefkurse sowie den RSI-Wert. Dann sind wir bereit, eine neue Vorhersage von unserem Modell abzuholen. Wenn wir keine offenen Positionen haben, folgen wir der Vorhersage unseres Modells und merken uns unsere aktuelle Position mit einem binären Flag. Andernfalls, wenn wir bereits eine Position geöffnet haben, prüfen wir, ob die neue Vorhersage unseres Modells mit unserer offenen Position übereinstimmt; ist dies der Fall, schließen wir unsere Position. Andernfalls werden wir weiterhin Gewinne mitnehmen.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Fetch updated market prices update_market_data(); //--- On every tick we need to fetch a prediction from our model model_predict(); //--- If we have no open positions, follow the model's prediction if(PositionsTotal() == 0) { //--- Our model detected a spike if(model_state == 1) { Trade.Buy(0.2,Symbol(),ask,0,0,"BOOM 1000 AI"); system_state = 1; } //--- Our model detected a drop if(model_state == -1) { Trade.Sell(0.2,Symbol(),bid,0,0,"BOOM 1000 AI"); system_state = -1; } } //--- If we have open positiosn, our AI system will decide when to close them else if(PositionsTotal() > 0) { if(system_state != model_state) { //--- Close the positions we opened Alert("Reversal detected by the AI system,closing all positions now!"); Trade.PositionClose(Symbol()); } } } //+------------------------------------------------------------------+

Abb. 14: Unser Boom-1000-System hat einen Spike aufgefangen

Abb. 15: Unser Boom-1000-System hat eine Umkehrung festgestellt
Schlussfolgerung
In unserem heutigen Artikel haben wir gezeigt, dass es möglich ist, selbstoptimierende Expert Advisors zu entwickeln, die selbst die anspruchsvollsten synthetischen Instrumente bewältigen können. Darüber hinaus haben wir gezeigt, dass der traditionelle Ansatz der direkten Vorhersage von Kursniveaus auf den heutigen algorithmischen Märkten nicht ausreicht.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/15781
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Einführung in Connexus (Teil 1): Wie verwendet man die WebRequest-Funktion?
Einführung in Connexus (Teil 1): Wie verwendet man die WebRequest-Funktion?
 Erstellen eines integrierten MQL5-Telegram Expert Advisors (Teil 5): Senden von Befehlen von Telegram an MQL5 und Empfangen von Antworten in Echtzeit
Erstellen eines integrierten MQL5-Telegram Expert Advisors (Teil 5): Senden von Befehlen von Telegram an MQL5 und Empfangen von Antworten in Echtzeit
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wir werden alle synthetischen Derivatemärkte einzeln analysieren, beginnend mit dem bekanntesten - Boom 1000.
Vielen Dank für diesen Artikel! Ich beobachte diese Indizes schon seit langem, wusste aber nicht, von welcher Seite ich sie angehen sollte.
Bitte machen Sie weiter!
Ich habe mehrere Tools ausprobiert, und bei jedem gibt Ihr Modell einenFehler aufgrund einer Nichtübereinstimmung zwischen den Dimensionen der Eingabedaten (X) und den Zielvariablen (y).
Vielen Dank für diesen Artikel! Ich analysiere diese Indizes schon seit langem, war mir aber nicht sicher, wie ich sie angehen sollte.
Bitte machen Sie weiter!
Gern geschehen, Janis.
Ich werde auf jeden Fall fortfahren. Es gibt eine Menge zu behandeln, aber ich werde Zeit schaffen.
Ich habe mehrere Tools ausprobiert, und in jedem davon gibt Ihr Modell einen Fehler aufgrund inkonsistenter Größen von Eingabedaten (X) und Zielvariablen (y).
Hallo Aliaksandr, Sie können stattdessen einfach den Code als Vorlage verwenden und dann die notwendigen Anpassungen auf Ihrer Seite vornehmen. Ich würde dir auch empfehlen, verschiedene Indikatoren auszuprobieren, verschiedene Variationen der allgemeinen Idee aus dem Artikel auszuprobieren. Das wird uns helfen, die globale Wahrheit schneller zu verstehen.
Ich habe mehrere Tools ausprobiert, und jedes von ihnen hat dazu geführt, dass das Modell aufgrund von Inkonsistenzen in der Größe der Eingabedaten (X) und der Zielvariablen (y) nicht funktioniert.
# Halten Sie die Indizes konsistent, sonst werden die Indizes rekonstruiert, wenn Daten herausgefiltert werden X = pd.DataFrame(RobustScaler().fit_transform(boom_1000.loc[:, predictors]), columns=predictors, index=boom_1000.index)