数据科学与机器学习(第 01 部分):线性回归

概述
在不充分数据的基础上形成不成熟理论,这样的诱惑是我们职业的祸根。
“夏洛克·福尔摩斯(Sherlock Holmes)"
数据科学
它是一个跨学科领域,它运用科学方法、流程、算法、系统,从嘈杂、结构化和非结构化数据中提取出知识和见解,并将这些知识和可操作的见解在广泛的应用领域加以运用。
数据科学家则是创建编程代码、并将其与统计学相结合,从中挖掘创意的人。
从这些系列文章中可以期望得到什么?
- 理论(譬如数学方程式):理论在数据科学中是最重要的。 您需要深入了解算法,了解模型的行为方式,以及它以某种方式行为的原因,理解这一点要比算法编码本身困难得多。
- 亲手实践 MQL5 和 python 中的示例
线性回归
它是一种预测模型,用于发现因变量和一个或多个自变量之间的线性关系。
线性回归是许多算法所采用的核心算法之一,例如:
- 逻辑回归是一种基于线性回归的模型
- 支持向量机,这个数据科学中著名的算法就是一个基于线性的模型
什么是模型
模型并无特别之处,它只是一个后缀。
理论
通过图表的每条直线都有一个方程式
我们从哪里得到这个方程?
假设,您有两个数值相同的数据集,分别为 x 和 y:
| x | y |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
将数值在图型上绘出则为:
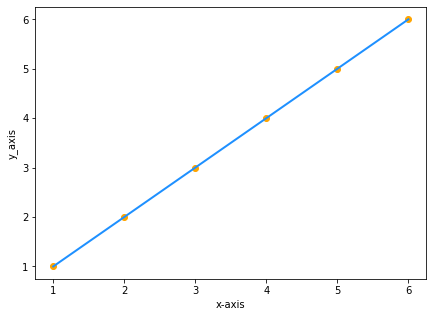
由于 y 等于 x,我们的直线方程是 y=x,对吗?错误
虽然,
y = x 在数学上与 y = 1x 相同,但在数据科学中是非常有区别的,直线的公式将是 y=1x,其中 1 是直线与 x 轴之间形成的夹角,也称为直线的斜率
但是,
斜率 = y 值的变化 /x 值的变化 = m (称为 m)
现在我们的公式是 y = mx。
最后,我们需要在方程中添加一个常数,即当 x 为零时,y 的对应值,换句话说,当直线穿过 y 轴时,y 对应的值。
最后,
我们的方程是 y = mx + c(这不代表什么,只是数据科学中的一个模型)
其中 c 是 y 轴上的截距
简单线性回归
简单线性回归有一个因变量和一个自变量。 在此,我们尝试理解两个变量之间的关系,例如,股票价格如何随简单移动平均线的变化而变化。
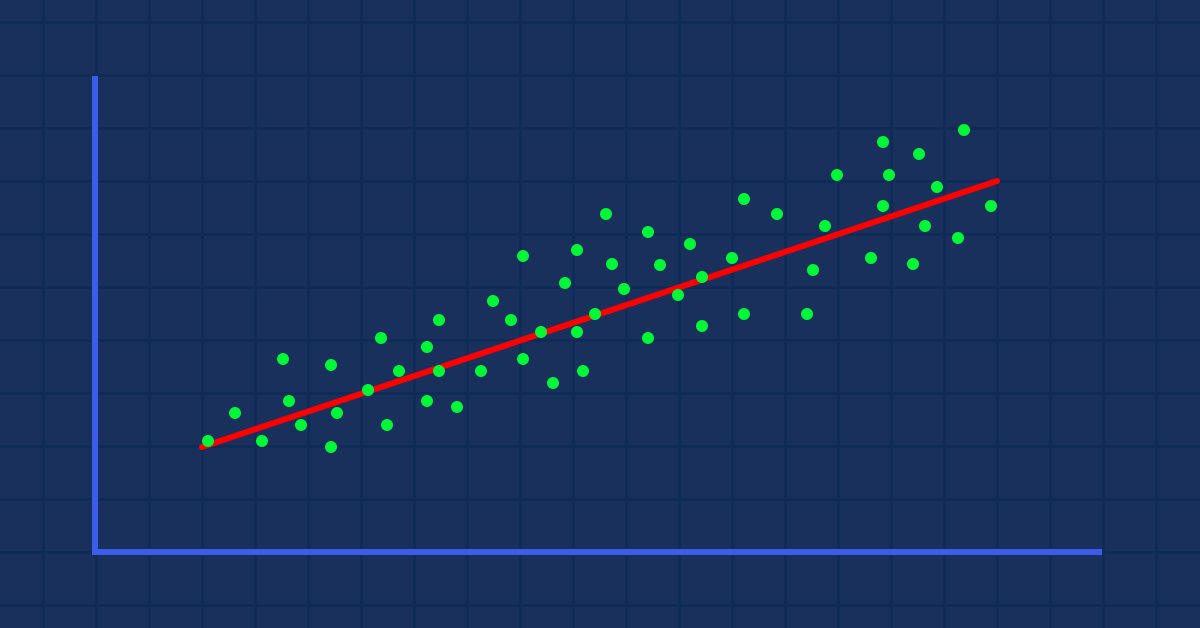
复杂数据
假设我们根据股票价格(现实生活中发生的事情)得到随机散状指标值
")
在这种情况下,我们的指标/自变量可能无法很好地预测我们的股价/因变量。
您必须在数据集中应用的第一个过滤器是删除与目标关联性不强的所有列,因为您不会依据这些列构建线性模型。
依据非线性相关数据来构建线性模型是一个巨大的根本性错误;一定要小心!
这种关系可以是颠倒的、亦或是逆向的,但它必须是强关联的,因为我们正在寻找线性关系,这就是您要找的。

那么,我们如何衡量自变量和目标之间的强度呢? 我们所用的度量称为相关系数。
相关系数
我们来编写一个脚本,创建一个数据集,作为本文的主要示例。 我们找出纳斯达克的预测因子。
input ENUM_TIMEFRAMES timeframe = PERIOD_H1; input int maperiod = 50; input int rsiperiod = 13; int total_data = 744; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string file_name = "NASDAQ_DATA.csv"; string nasdaq_symbol = "#NQ100", s_p500_symbol ="#SP500"; //--- int handle = FileOpen(file_name,FILE_CSV|FILE_READ|FILE_WRITE,","); if (handle == INVALID_HANDLE) { Print("data to work with is nowhere to be found Err=",GetLastError()); } //--- MqlRates nasdaq[]; ArraySetAsSeries(nasdaq,true); CopyRates(nasdaq_symbol,timeframe,1,total_data,nasdaq); //--- MqlRates s_p[]; ArraySetAsSeries(s_p,true); CopyRates(s_p500_symbol,timeframe,1,total_data,s_p); //--- Moving Average Data int ma_handle = iMA(nasdaq_symbol,timeframe,maperiod,0,MODE_SMA,PRICE_CLOSE); double ma_values[]; ArraySetAsSeries(ma_values,true); CopyBuffer(ma_handle,0,1,total_data,ma_values); //--- Rsi values data int rsi_handle = iRSI(nasdaq_symbol,timeframe,rsiperiod,PRICE_CLOSE); double rsi_values[]; ArraySetAsSeries(rsi_values,true); CopyBuffer(rsi_handle,0,1,total_data,rsi_values); //--- if (handle>0) { FileWrite(handle,"S&P500","NASDAQ","50SMA","13RSI"); for (int i=0; i<total_data; i++) { string str1 = DoubleToString(s_p[i].close,Digits()); string str2 = DoubleToString(nasdaq[i].close,Digits()); string str3 = DoubleToString(ma_values[i],Digits()); string str4 = DoubleToString(rsi_values[i],Digits()); FileWrite(handle,str1,str2,str3,str4); } } FileClose(handle); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+
在脚本中,我们收集了纳斯达克收盘价、13 周期的 RSI 值、标准普尔 500 指数,及其 50 周期的移动平均值。 数据成功收集到 CSV 文件之后,我们在 anaconda 的 Jupyter 笔记本上用 python 可视化数据,对于那些机器上没有安装 anaconda 的用户,可以运行在 google colab 一文中所用的数据科学 python 代码。
在打开由我们的测试脚本创建的 CSV 文件之前,需要将其转换为 UTF-8 编码,以便 python 可以读取它。 用记事本打开 CSV 文件,然后将其编码保存为 UTF-8。 最好将文件复制到外部目录中,这样的话,当您用 pandas 链接到该目录时,python 能单独读取该文件;现在我们读取 CSV 文件,并将其存储到数据变量之中。


输出如下:

从数据的直观表现中,我们已经可以看到,纳斯达克与标准普尔 500 指数之间存在着非常密切的关系,纳斯达克与其 50 周期移动平均线之间也存在着密切的关系。 如早前所述,每当数据分散在整个图形上时,在寻找线性关系时,依据自变量可能不是一个很好的目标预测器;但我们若看数字则能说明了它们的相关性,并依据数字而不是我们的眼睛得出结论,为了找出变量之间的相关性,我们将采用称为相关系数进行度量。
相关系数
它用于测量自变量和目标之间的强度。
有若干种类型的相关系数,但我们只用最常见的线性回归,即皮尔逊(Pearson)相关系数(R),其范围介于 -1 和 +1 之间
相关性的可能极值 -1 和 +1 分别表示 x 和 y 之间存在完全负线性相关,和完全正线性相关,而相关性为 0(零)表示没有线性相关性。
相关系数公式/皮尔逊系数(R)。

我已创建了一个 linearRegressionLib.mqh,在我们的主函数库当中,我们来编写函数 corrcoef()。
我们从数值平均函数开始,平均值是所有数据求和,然后除以它们的元素总数。
double CSimpleLinearRegression::mean(double &data[]) { double x_y__bar=0; for (int i=0; i<ArraySize(data); i++) { x_y__bar += data[i]; // all values summation } x_y__bar = x_y__bar/ArraySize(data); //total value after summation divided by total number of elements return(x_y__bar); }现在我们编码求解皮尔逊 R
double CSimpleLinearRegression::corrcoef(double &x[],double &y[]) { double r=0; double numerator =0, denominator =0; double x__x =0, y__y=0; for(int i=0; i<ArraySize(x); i++) { numerator += (x[i]-mean(x))*(y[i]-mean(y)); x__x += MathPow((x[i]-mean(x)),2); //summation of x values minus it's mean squared y__y += MathPow((y[i]-mean(y)),2); //summation of y values minus it's mean squared } denominator = MathSqrt(x__x)*MathSqrt(y__y); //left x side of the equation squared times right side of the equation squared r = numerator/denominator; return(r); }
当我们在 TestSript.mq5 中打印结果时
Print("Correlation Coefficient NASDAQ vs S&P 500 = ",lr.corrcoef(s_p,y_nasdaq)); Print("Correlation Coefficient NASDAQ vs 50SMA = ",lr.corrcoef(ma,y_nasdaq)); Print("Correlation Coefficient NASDAQ Vs rsi = ",lr.corrcoef(rsi,y_nasdaq));
输出将是
Correlation Coefficient NASDAQ vs S&P 500 = 0.9807093773142763
Correlation Coefficient NASDAQ vs 50SMA = 0.8746579124626006
Correlation Coefficient NASDAQ Vs rsi = 0.24245225451004537
正如您所看到的,纳斯达克和标准普尔 500 指数与所有其它数据列都有很强的相关性(因为它的相关系数非常接近 1),因此在继续构建简单线性回归模型时,我们必须去掉其它弱相关列。
现在我们有两个数据列,我们将在此基础上构建我们的模型,我们来继续构建模型。
X 的系数
x 的系数,也称为斜率(m),根据定义是 Y 变化与 x 变化的比值,或者换句话说,是直线的坡度
公式:
坡度 = Y 的变化 / X 的变化
记住代数中的斜率是公式中的 m
Y = M X + C
为了求解线性回归斜率 m,公式为,
现在我们已经看到了公式,我们来为模型的斜率编写代码。

double CSimpleLinearRegression::coefficient_of_X() { double m=0; double x_mean=mean(x_values); double y_mean=mean(y_values);; //--- { double x__x=0, y__y=0; double numerator=0, denominator=0; for (int i=0; i<(ArraySize(x_values)+ArraySize(y_values))/2; i++) { x__x = x_values[i] - x_mean; //right side of the numerator (x-side) y__y = y_values[i] - y_mean; //left side of the numerator (y-side) numerator += x__x * y__y; //summation of the product two sides of the numerator denominator += MathPow(x__x,2); } m = numerator/denominator; } return (m); }
请注意 y_values 和 x_values 数组,这些数组是在类 CSimpleLinearRegression 中的 Init() 函数中初始化和复制的
以下是 CSimpleLinearRegression::Init() 函数:
void CSimpleLinearRegression::Init(double& x[], double& y[]) { ArrayCopy(x_values,x); ArrayCopy(y_values,y); //--- if (ArraySize(x_values)!=ArraySize(y_values)) Print(" Two of your Arrays seems to vary In Size, This could lead to inaccurate calculations ",__FUNCTION__); int columns=0, columns_total=0; int rows=0; fileopen(); while (!FileIsEnding(m_handle)) { string data = FileReadString(m_handle); if (rows==0) { columns_total++; } columns++; if (FileIsLineEnding(m_handle)) { rows++; columns=0; } } m_rows = rows; m_columns = columns; FileClose(m_handle); //--- }
我们已经针对 X 的系数进行了编码,现在我们进入下一部分。
Y-截距
如前所述,当 x 值为零时,Y-截距就是 Y 的值,或者当直线穿过 Y 轴时,该时刻 Y 的值。

查找 y-截距
来自方程
Y = M X + C
把 MX 项移到方程的左侧,并将方程左右翻转,x 截距的最终方程将是
C = Y - M X
此处,
Y = 所有 y 值的平均值
x = 所有 x 值的平均值
现在,我们来编写函数代码,以便求解 y截距
double CSimpleLinearRegression::y_intercept() { // c = y - mx return (mean(y_values)-coefficient_of_X()*mean(x_values)); }
一旦依据 y-截距完成,我们通过在主函数 LinearRegressionMain() 中打印它来构建线性回归模型
void CSimpleLinearRegression::LinearRegressionMain(double &predict_y[]) { double slope = coefficient_of_X(); double constant_y_intercept= y_intercept(); Print("The Linear Regression Model is "," Y =",DoubleToString(slope,2),"x+",DoubleToString(constant_y_intercept,2)); ArrayResize(predict_y,ArraySize(y_values)); for (int i=0; i<ArraySize(x_values); i++) predict_y[i] = coefficient_of_X()*x_values[i]+y_intercept(); //--- }
我们还用我们的模型来获得 y 的预测值,在将来若继续构建我们的模型,并分析其准确性时,这将很有帮助。
我们调用 TestScript.mq5 中的函数 Onstart()。
lr.LinearRegressionMain(y_nasdaq_predicted);
输出则是
2022.03.03 10:41:35.888 TestScript (#SP500,H1) The Linear Regression Model is Y =4.35241x+-4818.54986
void CSimpleLinearRegression::GetDataToArray(double &array[],string file_name,string delimiter,int column_number) { m_filename = file_name; m_delimiter = delimiter; int column=0, columns_total=0; int rows=0; fileopen(); while (!FileIsEnding(m_handle)) { string data = FileReadString(m_handle); if (rows==0) { columns_total++; } column++; //Get data by each Column if (column==column_number) //if we are on the specific column that we want { ArrayResize(array,rows+1); if (rows==0) { if ((double(data))!=0) //Just in case the first line of our CSV column has a name of the column { array[rows]= NormalizeDouble((double)data,Digits()); } else { ArrayRemove(array,0,1); } } else { array[rows-1]= StringToDouble(data); } //Print("column ",column," "," Value ",(double)data); } //--- if (FileIsLineEnding(m_handle)) { rows++; column=0; } } FileClose(m_handle); }
在 void 函数 fileopen() 内部
void CSimpleLinearRegression::fileopen(void) { m_handle = FileOpen(m_filename,FILE_READ|FILE_WRITE|FILE_CSV,m_delimiter); if (m_handle==INVALID_HANDLE) { Print("Data to work with is nowhere to be found, Error = ",GetLastError()," ", __FUNCTION__); } //--- }
现在,我们的测试脚本内部,我们要做的第一件事是声明两个数组
double s_p[]; //Array for storing S&P 500 values double y_nasdaq[]; //Array for storing NASDAQ values
接下来我们要做的是传递这些数组,从而我们的 GetDataToArray() void 函数能获取它们的引用
lr.GetDataToArray(s_p,file_name,",",1); lr.GetDataToArray(y_nasdaq,file_name,",",2);
请注意列号,因为我们的函数参数在类的公开部分上就是如此
void GetDataToArray(double& array[],string filename, string delimiter, int column_number);
请确保您引用了正确的列号。 正如您所见,列是如何在 CSV 文件中排列的
S&P500,NASDAQ,50SMA,13RSI 4377.5,14168.6,14121.1,59.3 4351.3,14053.2,14118.1,48.0 4342.6,14079.3,14117.0,50.9 4321.2,14038.1,14115.6,46.1 4331.8,14092.9,14114.6,52.5 4336.1,14110.2,14111.8,54.7 4331.5,14101.4,14109.4,53.8 4336.4,14096.8,14104.7,53.3 .....
调用 GetDataToArray() 函数之后,是时候调用 Init() 函数了,因为如果没有正确收集数据,并将其存储到数组中,初始化函数库则没有任何意义。 如下所示,按正确的顺序调用函数,
void OnStart() { string file_name = "NASDAQ_DATA.csv"; double s_p[]; double y_nasdaq[]; double y_nasdaq_predicted[]; lr.GetDataToArray(s_p,file_name,",",1); //Data is taken from the first column and gets stored in the s_p Array lr.GetDataToArray(y_nasdaq,file_name,",",2); //Data is taken from the second column and gets stored in the y_nasdaq Array //--- lr.Init(s_p,y_nasdaq); { lr.LinearRegressionMain(y_nasdaq_predicted); Print("slope of a line ",lr.coefficient_of_X()); } }
现在,我们将预测值存储在 y_nasdaq_predicted 数组中,我们再把因变量(纳斯达克)、自变量(标普 500)和预测显示在同一条曲线上。
在 Jupyter 笔记本上运行以下代码

完整的 python 参考代码附在本文末尾。
成功运行上述代码段后,您将看到如下图形

现在,我们的函数库里已包含我们的模型和其它东西,那么我们的模型准确性如何呢? 我们的模型是否足够好,是否可以用于任何事情?
为了理解我们的模型在预测目标变量方面有多优秀,我们选用了一个称为行列式系数的指标,称为 R-平方
R-平方
这是 y 的总方差命题,该命题已由模型解释。
为了求解 r-平方,我们需要了解预测中的误差。 预测误差是 y 的实际值/实际值与 y 的预测值之间的差值。

在数学上,
误差 = Y 实际值 - Y 预测值
R-平方公式为
R-平方 = 1 - (平方误差合计 / 平方剩余误差合计)

为什么会有平方误差?
- 误差可以是正值,也可以是负值(线上或线下),我们计算其平方来保持正值
- 负值可以减少误差
- 我们还将误差平方化,来惩治较大的误差,以便获得尽可能最佳的拟合
零意即该模型无法解释 y 的任何方差,表明该模型可能是最差的;一表示该模型能够解释数据集中 y 的所有方差(该模型不存在)。
您可以将 r-平方输出理解为模型优秀程度的百分比,零表示准确率为零,一表示模型准确率为百分百。
现在我们针对 R-平方编码。
double CSimpleLinearRegression::r_squared() { double error=0; double numerator =0, denominator=0; double y_mean = mean(y_values); //--- if (ArraySize(m_ypredicted)==0) Print("The Predicted values Array seems to have no values, Call the main Simple Linear Regression Funtion before any use of this function = ",__FUNCTION__); else { for (int i=0; i<ArraySize(y_values); i++) { numerator += MathPow((y_values[i]-m_ypredicted[i]),2); denominator += MathPow((y_values[i]-y_mean),2); } error = 1 - (numerator/denominator); } return(error); }
请记住,在我们的 LinearRegressionMain 内部,我们将预测值存储在由引用传递的 predicted_y[] 数组之中,我们必须将该数组复制到类的私密部分里声明的全局变量数组之中。
private: int m_handle; string m_filename; string m_delimiter; double m_ypredicted[]; double x_values[]; double y_values[];
在 LinearRegressionMain 的末尾,我添加了一行代码,将该数组复制到一个全局变量数组 m_ypredicted[] 之中。
//At the end of the function LinearRegressionMain(double &predict_y[]) I added the following line, // Copy the predicted values to m_ypredicted[], to be Accessed inside the library ArrayCopy(m_ypredicted,predict_y);
现在,我们在测试脚本中打印 R-平方值
Print(" R_SQUARED = ",lr.r_squared());
输出为:
2022.03.03 10:40:53.413 TestScript (#SP500,H1) R_SQUARED = 0.9590906984145334
这就是简单线性回归,现在我们来看看多重线性回归会是什么样子。
多元线性回归
多元线性回归有一个自变量和多个因变量。
多元线性回归模型的公式如下
这就是在类库里,针对我们类的私密和公开部分进行硬编码后的样子。
class CMultipleLinearRegression: public CSimpleLinearRegression { private: int m_independent_vars; public: CMultipleLinearRegression(void); ~CMultipleLinearRegression(void); double coefficient_of_X(double& x_arr[],double& y_arr[]); void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[]); double y_interceptforMultiple(double& Y[],double& A[],double& B[]); void MultipleRegressionMain(double& predicted_y[],double& Y[],double& A[],double& B[],double& C[],double& D[]); double y_interceptforMultiple(double& Y[],double& A[],double& B[],double& C[],double& D[]); };
由于我们将处理多元值,该部分会处理大量我们在函数参数引用的数组,故此,我找不到快捷方式来实现它。
为了创建两个因变量的线性回归模型,我们将采用该函数。
void CMultipleLinearRegression::MultipleRegressionMain(double &predicted_y[],double &Y[],double &A[],double &B[]) { // Multiple regression formula = y = M1X1+M2X2+M3X3+...+C double constant_y_intercept=y_interceptforMultiple(Y,A,B); double slope1 = coefficient_of_X(A,Y); double slope2 = coefficient_of_X(B,Y); Print("Multiple Regression Model is ","Y="+DoubleToString(slope1,2)+"A+"+DoubleToString(slope2,2)+"B+"+ DoubleToString(constant_y_intercept,2)); int ArrSize = (ArraySize(A)+ArraySize(B))/2; ArrayResize(predicted_y,ArrSize); for (int i=0; i<ArrSize; i++) predicted_y[i] = slope1*A[i]+slope2*B[i]+constant_y_intercept; }
此实例的 Y-截距将基于我们已决定提取的数据列号。 从多元线性回归推导出公式后,最终公式为:
C = Y - M1 X1 - M2 X2
这是编码后的样子
double CMultipleLinearRegression::y_interceptforMultiple(double &Y[],double &A[],double &B[]) { //formula c=Y-M1X1-M2X2; return(mean(Y)-coefficient_of_X(A,Y)*mean(A)-coefficient_of_X(B,Y)*mean(B)); }
对于三个变量,只需再次对函数进行硬编码,并添加另一个变量即可。
void CMultipleLinearRegression::MultipleRegressionMain(double &predicted_y[],double &Y[],double &A[],double &B[],double &C[],double &D[]) { double constant_y_intercept = y_interceptforMultiple(Y,A,B,C,D); double slope1 = coefficient_of_X(A,Y); double slope2 = coefficient_of_X(B,Y); double slope3 = coefficient_of_X(C,Y); double slope4 = coefficient_of_X(D,Y); //--- Print("Multiple Regression Model is ","Y="+DoubleToString(slope1,2),"A+"+DoubleToString(slope2,2)+"B+"+ DoubleToString(slope3,2)+"C"+DoubleToString(slope4,2)+"D"+DoubleToString(constant_y_intercept,2)); //--- int ArrSize = (ArraySize(A)+ArraySize(B))/2; ArrayResize(predicted_y,ArrSize); for (int i=0; i<ArrSize; i++) predicted_y[i] = slope1*A[i]+slope2*B[i]+slope3*C[i]+slope4*D[i]+constant_y_intercept; }
多元线性回归的常数/Y-截距,亦如早前所述。
double CMultipleLinearRegression::y_interceptforMultiple(double &Y[],double &A[],double &B[],double &C[],double &D[]) { return (mean(Y)-coefficient_of_X(A,Y)*mean(A)-coefficient_of_X(B,Y)*mean(B)-coefficient_of_X(C,Y)*mean(C)-coefficient_of_X(D,Y)*mean(D)); }
线性回归假设
线性回归模型基于一组假设,如果基础数据集不满足这些假设,则可能必须转换数据,或者线性模型可能不适合。
- 线性假设,假设因变量/目标变量和自变量/预测变量之间存在线性关系
- 假设误差分布为正态性
- 误差应随模型呈正态分布
- 实际值和预测值之间的散点图应展现出数据在整个模型中的平均分布
线性回归模型的优点
实现简单,输出和系数更容易解读。
缺点
- 假设因变量和自变量之间存在线性关系,即假设它们之间存在直线关系
- 极端值对回归有巨大影响
- 线性回归假设属性之间独立
- 线性回归分析因变量和自变量的平均值之间的关系
- 正如平均数并非单个变量的完整描述一样,线性回归也不是变量之间关系的完整描述
- 边界是线性的
最后的想法
我认为线性回归算法在创建基于配对相关性和其它类似指标的交易策略时非常有用,虽然我们的函数库距完成还很远,我尚未包括模型的训练和测试,以及进一步改善结果,这部分将在下一篇文章中介绍,敬请期待;我在 Github 存储库中的 python 代码链接在此,如果您对该函数库有任何贡献,我们将不胜感激,您也可以在本文的讨论部分分享您的想法。
不久再相见
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/10459
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 一张图表上的多个指标(第 06 部分):将 MetaTrader 5 转变为 RAD 系统(II)
一张图表上的多个指标(第 06 部分):将 MetaTrader 5 转变为 RAD 系统(II)

What is a Model
模型只是一个后缀。
后缀?我不明白这是什么意思。
在打开由我们的测试脚本创建的 CSV 文件之前,你需要将其转换为 UTF-8 编码,这样 python 才能读取它。
这是为什么呢?直接从 MQL 创建一个 UTF-8 数据文件即可。
红色椭圆是我加的。这是错的,这个点不是 "y-截距",它的坐标也不是 (0,-5)。
后缀?我不明白这是什么意思。
为什么?直接从 MQL 创建 UTF-8 数据文件即可。
红色椭圆是我添加的。这是错的,这个点不是 "y-截距",它的坐标也不是(0,-5)。
我说的后缀是指数学符号,比如 y=mx+c 这是一个模型
是的,我明白了,是图像上的错误,另一点应该是 (-5,0),它不是 "y-截距"。
您好,感谢您提供有关线性回归 及其潜力的简明文章。
,Peasson 系数公式的分母存在缺陷。
你好,也许它就在那里,只是我没有找到,但文章中使用的 NASDAQ.csv 文件在哪里?