
取引におけるニューラルネットワーク:統合軌道生成モデル(UniTraj)

はじめに
マルチエージェントの動作分析は、金融、自動運転、監視システムなど、さまざまな分野で重要な役割を果たします。エージェントの行動を理解するには、オブジェクトの追跡、識別、軌跡のモデリング、アクションの認識といったいくつかの重要なタスクを解決する必要があります。その中でも、エージェントの動きを分析する際に軌道モデリングは特に重要です。環境ダイナミクスや微妙なエージェント同士の相互作用が複雑であるにもかかわらず、この問題の解決に関しては最近大きな進展が見られました。主な成果は、軌道予測、欠損データの回復、そして時空間モデリングの3つの主要な領域に集中しています。
しかし、ほとんどのアプローチは特定のタスクに特化しているため、他の問題に一般化することが難しいという課題があります。中には、前方と後方の両方の時空間的依存関係が必要なタスクもありますが、これらは予測中心のモデルでは見落とされがちです。また、いくつかのアルゴリズムはマルチエージェントの軌道の条件付き計算に成功していますが、将来の軌道に関しては十分に考慮していないことがよくあります。この制限により、過去の軌道を単に再構築するだけではなく、将来の軌道を予測することが次の行動計画にとって不可欠であるため、動きの完全な理解における実用性が低くなります。
論文「Deciphering Movement:Unified Trajectory Generation Model for Multi-Agent」では、さまざまな軌道関連のタスクを統一的なフレームワークに統合した汎用的なモデル、Unified TrajectoryGeneration (UniTraj)モデルを提案しています。具体的には、著者はさまざまな種類の入力データを、各タイムステップにおける各エージェントの可視性を示すマスクを持った不完全な軌跡という単一の形式に統合しています。このモデルは、不完全な軌跡に基づいて完全な軌跡を生成することを目的として、すべてのタスク入力をマスクされた軌跡として一貫して処理します。
異なる軌道表現における時空間依存性をモデル化するため、著者はGhost Spatial Masking (GSM)モジュールを提案し、これをTransformerベースのエンコーダに組み込みました。さらに、最近注目されている状態空間モデル(SSM)の一例であるMambaモデルの機能を活用し、これを長期的なマルチエージェント軌道生成用の双方向時間エンコーダMambaとして適応・強化しました。加えて、著者はシンプルでありながら効果的なBidirectional Temporal Scaled (BTS)モジュールを提案し、これは軌跡を包括的にスキャンしながら、シーケンス内の時間的な関係を保つことができます。実験結果は、提案された方法の堅牢さと優れたパフォーマンスを確認しています。
1.UniTrajアルゴリズム
単一のフレームワーク内でさまざまな初期条件を処理するために、著者は任意の入力をマスクされた軌跡シーケンスとして扱う統合生成軌跡モデルを提案しています。軌跡の可視領域は制約または入力データとして機能し、欠損領域は生成タスクのターゲットとなります。このアプローチにより、次のような問題定義が導かれます。
完全な軌道X[N,T,D]を求める必要があります。ここで、Nはエージェントの数、Tは軌道の長さ、Dはエージェントの状態の次元です。時刻tにおけるエージェントiの状態はxi,t[D]と表されます。さらに、このアルゴリズムはバイナリマスキング行列M[N、T]を使用します。変数mi,tは、tにおけるエージェントiの位置が既知であれば1となり、そうでなければ0となります。したがって、軌跡はマスクによって2つのセグメントに分割されます。Xv=X⊙Mとして定義される可視領域と、Xm=X⊙(1−M)として定義される欠落領域です。目的は、完全な軌道Y'={X'v、X'm}を生成することです。ここで、X'vは再構築された軌跡、X'mは新たに生成された軌道です。一貫性を保つために、著者は元の軌跡を真実値Y=X={Xv、Xm}と呼びます。
より正式には、目標はパラメータθを用いて生成モデルf(⋅)を訓練し、完全な軌跡Y'を出力することです。
モデルパラメータθを推定する一般的なアプローチは、結合軌道分布を因数分解し、対数尤度を最大化することです。
次に、時刻tにおける位置xi,tを持つエージェントiを考えます。まず、隣接する時間ステップ間の座標の差を取ることによって相対速度𝒗i,t,を計算します。欠損している位置については、マスクとの要素ごとの乗算をおこない、値がゼロで埋められます。さらに、エージェントのカテゴリを表すために、1つのカテゴリベクトル𝒄i,tが定義されます。この分類は、特にスポーツシナリオにおいて、選手が特定の攻撃または防御戦略を取る場合に重要です。エージェントの特徴量は高次元の特徴量ベクトル𝒇i,xtに投影されます。ソース特徴量ベクトルは次のように計算されます。
![]()
ここで、φx(⋅)は重み𝐖xを持つ射影関数、⊙は要素ごとの乗算、⊕は連結を表します。
この手法の著者はMLPを用いてφx(⋅)を実装しました。このアプローチでは、位置、速度、可視性、カテゴリに関する情報を統合し、後続の分析のために空間特徴量を抽出します。
他の順次モデリングタスクとは異なり、密な社会的相互作用を考慮することが重要です。人間の相互作用に関する既存の研究では、主にクロスアテンションやグラフベースアテンションといった注意メカニズムを使用して、このダイナミクスを捉えています。ただし、UniTrajは任意の不完全な入力データを使用する統合タスクであるため、提案されたモデルは時空間的な欠損パターンを探索する必要があります。著者は、欠損データの空間的構造を抽象化し、一般化するために、Ghost Spatial Masking (GSM)モジュールを導入しています。このモジュールは、モデルの複雑さを増すことなく、Transformerアーキテクチャにシームレスに統合されます。
元々、時系列データの時間的依存性をモデル化するために設計されたUniTrajのTransformerエンコーダは、空間次元でマルチヘッド自己アテンション設計を適用します。各タイムステップにおいて、N個のエージェントそれぞれの埋め込みがTransformerエンコーダへの入力として処理されます。このアプローチは、実際のシナリオで考えられるエージェントの順序付け順列を考慮して、順序不変の空間特徴量を抽出します。したがって、正弦波位置エンコーディングを完全に訓練可能なエンコーディングに置き換えることが望ましいです。
その結果、Transformerエンコーダは、各タイムステップtにおけるすべてのエージェントの空間特徴量Fs,xtを出力します。これらの特徴は時間的次元に沿って連結され、軌跡全体の空間的表現が得られます。
Mambaは長期的な時間的依存関係を捉える能力を持っているため、UniTrajの著者はそれを提案されたフレームワークに統合できるように適応させました。しかし、軌道専用のアーキテクチャが存在しないため、Mambaを統一された軌道生成に適用するのは困難です。効果的な軌道モデリングには、欠損データを処理しながら時空間特徴量を捉える必要があり、このプロセスは複雑化します。
欠落した関係性を保持しつつ時間的特徴抽出を強化するため、双方向時間的Mambaが導入されています。この適応には、双方向時間スケール(BTS)モジュールとともに複数の残差Mambaブロックが組み込まれています。
最初に、軌跡全体のマスクMが処理されます。これを時間的次元に沿って展開し、M'を生成します。これにより、BTSモジュールで元のマスクと反転マスクの両方を利用し、時間的な欠損関係の学習が容易になります。このプロセスではスケーリング行列Sとその逆行列S'が生成されます。具体的には、時間ステップtにおけるエージェントiについて、s i,t sは次のように計算されます。
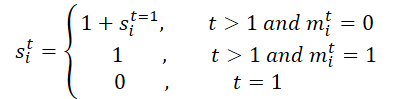
続いて、スケーリング行列Sとその逆行列S'が特徴量行列に投影されます。
![]()
ここでφs(⋅)は重み𝐖sを持つ射影関数を表します。
著者はMLPとReLU活性化関数を用いてφs (⋅)を実装しました。提案されたスケーリング行列は、最後の観測から現在の時間ステップまでの距離を計算し、特に複雑な欠損パターンを扱う際に時間的なギャップの影響を定量化します。重要な洞察は、変数が一定期間欠落していると、その影響が時間の経過とともに減少するという点です。負の指数関数とReLUを用いることで、影響が0から1の妥当な範囲内で単調に減少することが保証されます。
エンコードプロセスの目的は、近似事後分布のガウス分布のパラメータを決定することです。具体的には、事後ガウス分布の平均μqと標準偏差σqは次のように計算されます。
![]()
潜在変数𝒁を事前ガウス分布𝒩(0,I)からサンプリングします。
モデルが妥当な軌跡を生成する能力を向上させるために、この関数Fz,xを潜在変数𝒁と組み合わせてデコーダーに入力します。その後、軌道生成プロセスは次のように計算されます。
![]()
ここで、φdecはMLPを用いて実装されたデコーダー関数です。
任意の不完全な軌道が与えられた場合、UniTrajモデルは完全な軌道を生成します。訓練プロセス中に、可視領域の再構築誤差とマスクされたデータの復元誤差が計算されます。
以下に、著者によるUniTrajメソッドの視覚化を示します。
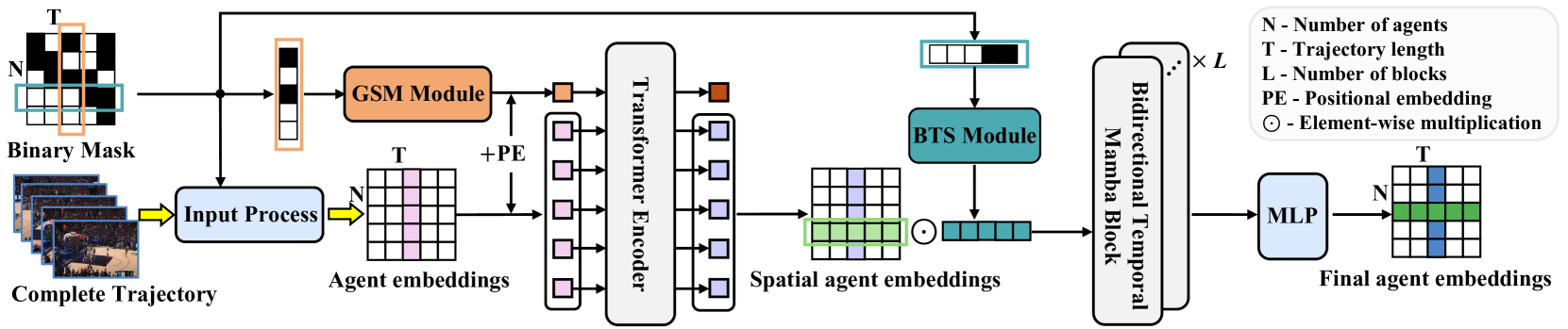
2.MQL5での実装
UniTraj法の理論的側面を検討した後は、本稿の実践的な部分に進み、MQL5を使用して、提案するアプローチのビジョンを実装します。提案されたアルゴリズムは、これまでに検討した方法とは構造的に異なる点が重要です。
最初の顕著な違いは、マスキングプロセスです。入力データをモデルに渡す際、著者はモデルが表示できるデータと生成する必要があるデータを決定するための追加のマスクを準備することを提案しています。これにより、ワークフローに余分なステップが追加され、意思決定にかかる時間が増加するため、望ましくありません。したがって、モデル自体にマスク生成を組み込むことを目指しています。
次に、完全な軌道をモデルに送信する点です。テスト中には完全な軌道を取得できますが、実際の展開環境では利用できません。このモデルは欠損データをマスクして再構築することが可能ですが、それでもより大きなテンソルをモデルに提供する必要があります。これにより、メモリ消費が増加し、データ転送のオーバーヘッドが発生し、最終的に処理速度に影響を与えます。潜在的な解決策として、
訓練と展開の両方で履歴データのみを伝送することが考えられます。しかし、これでは手法の機能のかなりの部分が制限されてしまいます。
効率性と精度のバランスを取るために、データ送信を履歴データと将来の軌道の2つに分けることにしました。将来の軌道は、空間的・時間的依存関係を抽出するために訓練段階でのみ提供されます。リアルタイム実行中には将来の軌道テンソルを省略し、モデルは予測モードで動作します。
さらに、この実装にはOpenCL側で特定の変更が必要でした。
2.1 OpenCLプログラムの機能強化
実装の最初のステップとして、OpenCLプログラム内に新しいカーネル関数を準備します。主な追加は、データの前処理を担当するUniTrajPrepareカーネルです。このカーネルは、履歴データと既知の未来の軌道を連結し、適切なマスキングを適用します。
カーネルのパラメータには、5つのデータバッファへのポインタが含まれます。4つは入力データ用、1つは出力結果用です。また、履歴データの分析の深さと計画期間を定義するパラメータも必要です。
__kernel void UniTrajPrepare(__global const float *history, __global const float *h_mask, __global const float *future, __global const float *f_mask, __global float *output, const int h_total, const int f_total ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
カーネルの実行は、二次元のタスク空間で計画します。最初の次元は、2つの時間期間(履歴の深さと計画期間)のうち、より大きい方のサイズです。2番目の次元は分析されるパラメータの数を示します。
カーネル本体では、まず指定されたタスク空間内でスレッドを識別します。また、データバッファ内でのオフセットも決定します。
const int shift_in = i * variables + v; const int shift_out = 3 * shift_in; const int shift_f_out = 3 * (h_total * variables + v);
次に、履歴データを処理します。ここではまず、マスクを考慮してパラメータの変化率を決定します。そして、最大値、以前に計算された速度、およびマスク自体を考慮して、パラメータ値を結果バッファに保存します。
//--- history if(i < h_total) { float mask = h_mask[shift_in]; float h = history[shift_in]; float v = (i < (h_total - 1) && mask != 0 ? (history[shift_in + variables] - h) * mask : 0); if(isnan(v) || isinf(v)) v = h = mask = 0; output[shift_out] = h * mask; output[shift_out + 1] = v; output[shift_out + 2] = mask; }
将来の値についても同様のパラメータを計算します。
//--- future if(i < f_total) { float mask = f_mask[shift_in]; float f = future[shift_in]; float v = (i < (f_total - 1) && mask != 0 ? (future[shift_in + variables] - f) * mask : 0); if(isnan(v) || isinf(v)) v = f = mask = 0; output[shift_f_out + shift_out] = f * mask; output[shift_f_out + shift_out + 1] = v; output[shift_f_out + shift_out + 2] = mask; } }
次に、上記の操作の逆パスのカーネルをUniTrajPrepareGradを用いて保存します。
__kernel void UniTrajPrepareGrad(__global float *history_gr, __global float *future_gr, __global const float *output, __global const float *output_gr, const int h_total, const int f_total ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
逆方向パスメソッドのパラメータでは、ソースデータとマスクバッファへのポインタを指定しない点に注意してください。代わりに、指定されたデータを格納するUniTrajPrepareフィードフォワードカーネルの結果バッファを使用します。また、誤差勾配は意味がないので、マスク層には渡しません。
バックプロパゲーションカーネルのタスク空間は、上記で説明したフィードフォワードカーネルのタスク空間と同一です。
カーネル本体では、タスク空間内の現在のスレッドを識別し、データバッファへのオフセットを決定します。
const int shift_in = i * variables + v; const int shift_out = 3 * shift_in; const int shift_f_out = 3 * (h_total * variables + v);
フィードフォワードカーネルと同様に、作業を2段階に分けて構成します。まず、誤差勾配を履歴データに分配します。
//--- history if(i < h_total) { float mask = output[shift_out + 2]; float grad = 0; if(mask > 0) { grad = output_gr[shift_out] * mask; grad -= (i < (h_total - 1) && mask != 0 ? (output_gr[shift_out + 1]) * mask : 0); grad += (i > 0 ? output[shift_out + 1 - 3 * variables] * output[shift_out + 2 - 3 * variables] : 0); if(isnan(grad) || isinf(grad)) grad = 0; //--- } history_gr[shift_in] = grad; }
次に、誤差勾配を既知の予測値に伝播します。
//--- future if(i < f_total) { float mask = output[shift_f_out + shift_out + 2]; float grad = 0; if(mask > 0) { grad = output_gr[shift_f_out + shift_out] * mask; grad -= (i < (h_total - 1) && mask != 0 ? (output_gr[shift_f_out + shift_out + 1]) * mask : 0); grad += (i > 0 ? output[shift_f_out + shift_out + 1 - 3 * variables] * output[shift_f_out + shift_out + 2 - 3 * variables] : 0); if(isnan(grad) || isinf(grad)) grad = 0; //--- } future_gr[shift_in] = grad; } }
OpenCL側で実装する必要があるもう1つのアルゴリズムは、スケーリング行列を作成するものです。UniTrajBTSカーネルでは、直接スケーリング行列と逆スケーリング行列を計算します。
ここでも、データ準備カーネルのフィードフォワード結果を入力として使用します。そのデータに基づいて、前方向と後方向の最後のマスクされていない値からのオフセットを計算し、対応するデータバッファに保存します。
__kernel void UniTrajBTS(__global const float * concat_inp, __global float * d_forw, __global float * d_bakw, const int total ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t variables = get_global_size(1);
二次元のタスク空間を使用します。ただし、最初の次元にはスレッドが2つだけあり、これらは直接および逆スケーリング行列の計算に対応します。2番目の次元では、前と同様に、分析する変数の数を示します。
タスク空間内のスレッドを識別した後、最初の次元の値に応じてカーネルアルゴリズムを分割します。
if(i == 0) { const int step = variables * 3; const int start = v * 3 + 2; float last = 0; d_forw[v] = 0; for(int p = 1; p < total; p++) { float m = concat_inp[start + p * step]; d_forw[p * variables + v] = last = 1 + (1 - m) * last; } }
直接スケーリング行列を計算するときは、分析対象変数の最初の要素のマスクへのオフセットと次の要素へのステップを決定します。次に、分析された要素のマスクを順番に反復処理し、指定された式に従ってスケーリング係数を計算します。
逆スケーリング行列の場合、アルゴリズムは同じままです。ただし、最後の要素へのオフセットを決定し、逆の順序で反復します。
else { const int step = -(variables * 3); const int start = (total - 1) * variables + v * 3 + 2; float last = 0; d_bakw[(total - 1) + v] = 0; for(int p = 1; p < total; p++) { float m = concat_inp[start + p * step]; d_bakw[(total - 1 - p) * variables + v] = last = 1 + (1 - m) * last; } } }
提示されたアルゴリズムは、誤差勾配の分布が意味をなさないマスクに対してのみ機能することに注意してください。そのため、このアルゴリズムにはバックプロパゲーションカーネルを作成しません。これでOpenCLプログラム側の操作は終了です。すべてのコードは添付ファイルにあります。
2.2 UniTrajアルゴリズムの実装
OpenCLプログラム側での準備操作の後、メインプログラム側で提案されたアプローチの実装に進みます。UniTrajアルゴリズムは、CNeuronUniTrajクラス内に実装されます。その構造体を以下に示します。
class CNeuronUniTraj : public CNeuronBaseOCL { protected: uint iVariables; float fDropout; //--- CBufferFloat cHistoryMask; CBufferFloat cFutureMask; CNeuronBaseOCL cData; CNeuronLearnabledPE cPE; CNeuronMVMHAttentionMLKV cEncoder; CNeuronBaseOCL cDForw; CNeuronBaseOCL cDBakw; CNeuronConvOCL cProjDForw; CNeuronConvOCL cProjDBakw; CNeuronBaseOCL cDataDForw; CNeuronBaseOCL cDataDBakw; CNeuronBaseOCL cConcatDataDForwBakw; CNeuronMambaBlockOCL cSSM[4]; CNeuronConvOCL cStat; CNeuronTransposeOCL cTranspStat; CVAE cVAE; CNeuronTransposeOCL cTranspVAE; CNeuronConvOCL cDecoder[2]; CNeuronTransposeOCL cTranspResult; //--- virtual bool Prepare(const CBufferFloat* history, const CBufferFloat* future); virtual bool PrepareGrad(CBufferFloat* history_gr, CBufferFloat* future_gr); virtual bool BTS(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return feedForward(NeuronOCL, NULL); } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return calcInputGradients(NeuronOCL, NULL, NULL, None); } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return updateInputWeights(NeuronOCL, NULL); } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *second) override; //--- public: CNeuronUniTraj(void) {}; ~CNeuronUniTraj(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, float dropout, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronUniTrajOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
ご覧のとおり、クラス構造は多数の内部オブジェクトを宣言しています。メソッドの実装を進めながら、その機能を段階的に検討していきます。すべてのオブジェクトは静的に宣言されます。これにより、クラスのコンストラクタとデストラクタを空のままにして、メモリ操作をシステムに委任することができます。
すべての内部オブジェクトはInitメソッドで初期化されます。このメソッドのパラメータとして、オブジェクトのアーキテクチャを一意に識別するための主要な定数を取得します。
bool CNeuronUniTraj::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, float dropout, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * (units_count + forecast), optimization_type, batch)) return false;
メソッド本体では、まず親クラスの同名メソッドを呼び出し、継承されたオブジェクトの基本的な初期化処理をおこないます。これは確立された規則に従っています。
親クラスの操作が正常に実行された後、外部プログラムから受け取った定数を保存します。これには、入力データ内で分析される変数の数や、訓練プロセス中にマスクされる要素の割合が含まれます。
iVariables = window; fDropout = MathMax(MathMin(dropout, 1), 0);
次に、宣言されたオブジェクトの初期化に進みます。ここではまず、履歴データと予測データをマスクするためのバッファを作成します。
if(!cHistoryMask.BufferInit(iVariables * units_count, 1) || !cHistoryMask.BufferCreate(OpenCL)) return false; if(!cFutureMask.BufferInit(iVariables * forecast, 1) || !cFutureMask.BufferCreate(OpenCL)) return false;
次に、連結されたソースデータの内部層を初期化します。
if(!cData.Init(0, 0, OpenCL, 3 * iVariables * (units_count + forecast), optimization, iBatch)) return false;
そして、同様のサイズの学習可能な位置コーディング層を作成します。
if(!cPE.Init(0, 1, OpenCL, cData.Neurons(), optimization, iBatch)) return false;
続いて、空間的および時間的な依存関係を抽出するために使用されるTransformerエンコーダが続きます。
if(!cEncoder.Init(0, 2, OpenCL, 3, window_key, heads, (heads + 1) / 2, iVariables, 1, 1, (units_count + forecast), optimization, iBatch)) return false;
注目すべきは、著者が一連の実験を実施し、1つのTransformerエンコーダブロックと4つのMambaブロックを使用した場合にこの方法の最適なパフォーマンスが達成されると結論付けたことです。したがって、この場合は、エンコーダ層を1つだけ使用します。
さらに、入力ウィンドウのサイズは、各タイムステップでの単一のインジケーターの3つのパラメータ(値、速度、マスク)に対応して3に設定されていることにも注意してください。シーケンスの長さは分析される変数の数によって決定され、独立したチャネルの数は分析される履歴と予測期間の合計深度に設定されます。この設定により、分析された指標間の依存関係を単一の時間ステップ内で評価できます。
次に、BTSモジュールに進み、順方向および逆方向のスケーリング行列を作成します。
if(!cDForw.Init(0, 3, OpenCL, iVariables * (units_count + forecast), optimization, iBatch)) return false;; if(!cDBakw.Init(0, 4, OpenCL, iVariables * (units_count + forecast), optimization, iBatch)) return false;
次に、これらの行列を投影するための畳み込み層を追加します。
if(!cProjDForw.Init(0, 5, OpenCL, 1, 1, 3, iVariables, (units_count + forecast), optimization, iBatch)) return false; cProjDForw.SetActivationFunction(SIGMOID); if(!cProjDBakw.Init(0, 6, OpenCL, 1, 1, 3, iVariables, (units_count + forecast), optimization, iBatch)) return false; cProjDBakw.SetActivationFunction(SIGMOID);
結果の投影は、要素ごとにエンコーダの作業結果で乗算され、演算の結果が次のオブジェクトに書き込まれます。
if(!cDataDForw.Init(0, 7, OpenCL, cData.Neurons(), optimization, iBatch)) return false; if(!cDataDBakw.Init(0, 8, OpenCL, cData.Neurons(), optimization, iBatch)) return false;
次に、結果のデータを1つのテンソルに連結する予定です。
if(!cConcatDataDForwBakw.Init(0, 9, OpenCL, 2 * cData.Neurons(), optimization, iBatch)) return false;
このテンソルをSSMブロックに渡します。前述したように、このブロックでは4つの連続するMamba層を初期化します。
for(uint i = 0; i < cSSM.Size(); i++) { if(!cSSM[i].Init(0, 10 + i, OpenCL, 6 * iVariables, 12 * iVariables, (units_count + forecast), optimization, iBatch)) return false; }
ここで、この手法の著者は、Mamba層への残余接続を使用することを提案しています。もう少し進んで、TrajLLMメソッドで作業したときに作成したCNeuronMambaBlockOCLクラスを使用します。
得られた結果をターゲット分布の統計変数に投影します。
uint id = 10 + cSSM.Size(); if(!cStat.Init(0, id, OpenCL, 6, 6, 12, iVariables * (units_count + forecast), optimization, iBatch)) return false;
しかし、値をサンプリングして再パラメータ化する前に、データを再配置する必要があります。このために、転置層を使用します。
id++; if(!cTranspStat.Init(0, id, OpenCL, iVariables * (units_count + forecast), 12, optimization, iBatch)) return false; id++; if(!cVAE.Init(0, id, OpenCL, cTranspStat.Neurons() / 2, optimization, iBatch)) return false;
サンプリングされた値を独立した情報チャネルの次元に変換します。
id++; if(!cTranspVAE.Init(0, id, OpenCL, cVAE.Neurons() / iVariables, iVariables, optimization, iBatch)) return false;
次に、データをデコーダーに渡し、生成されたターゲットシーケンスを出力で取得します。
id++; uint w = cTranspVAE.Neurons() / iVariables; if(!cDecoder[0].Init(0, id, OpenCL, w, w, 2 * (units_count + forecast), iVariables, optimization, iBatch)) return false; cDecoder[0].SetActivationFunction(LReLU); id++; if(!cDecoder[1].Init(0, id, OpenCL, 2 * (units_count + forecast), 2 * (units_count + forecast), (units_count + forecast), iVariables, optimization, iBatch)) return false; cDecoder[1].SetActivationFunction(TANH);
ここで、得られた結果を元のデータの次元に変換するだけです。
id++; if(!cTranspResult.Init(0, id, OpenCL, iVariables, (units_count + forecast), optimization, iBatch)) return false;
不要なデータのコピー操作を回避するために、データバッファへのポインタを置き換えます。
if(!SetOutput(cTranspResult.getOutput(), true) || !SetGradient(cTranspResult.getGradient(), true)) return false; SetActivationFunction((ENUM_ACTIVATION)cDecoder[1].Activation()); //--- return true; }
各段階で実行プロセスが適切に監視され、メソッドが完了すると、メソッドの成功を示すブール値が呼び出し元プログラムに返されます。
クラスインスタンスの初期化が完了したら、フィードフォワードパスメソッドの実装に進みます。最初に、以前に作成したカーネルの実行をキューに入れるための簡単な準備手順を実行します。ここでは、添付の資料で独自に確認できる、確立されたアルゴリズムに依存しています。ただし、この記事では、高レベルのフィードフォワード方式に焦点を当て、アルゴリズム全体を大まかに概説することを提案します。
bool CNeuronUniTraj::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!NeuronOCL) return false;
メソッドパラメータでは、履歴値と予測値を含む2つのオブジェクトへのポインタを受け取ります。メソッドの本体では、履歴データへのポインタの関連性をすぐにチェックします。ご記憶のとおり、私たちの論理によれば、履歴データは常に存在します。しかし、予測値が存在しない可能性もあります。
次に、履歴データのランダムマスキングテンソルを生成するプロセスを整理します。
//--- Create History Mask int total = cHistoryMask.Total(); if(!cHistoryMask.BufferInit(total, 1)) return false; if(bTrain) { for(int i = 0; i < int(total * fDropout); i++) cHistoryMask.Update(RND(total), 0); } if(!cHistoryMask.BufferWrite()) return false;
マスキングは訓練プロセス中にのみ適用されることに注意してください。展開設定では、利用可能なすべての情報を活用します。
次に、予測値に対して同様のプロセスを確立します。しかし、重要なニュアンスがあります。予測値が利用可能な場合、ランダムなマスキングテンソルを生成します。将来の動きに関する情報がない場合、マスキングテンソル全体をゼロ値で埋めます。
//--- Create Future Mask total = cFutureMask.Total(); if(!cFutureMask.BufferInit(total, (!SecondInput ? 0 : 1))) return false; if(bTrain && !!SecondInput) { for(int i = 0; i < int(total * fDropout); i++) cFutureMask.Update(RND(total), 0); } if(!cFutureMask.BufferWrite()) return false;
マスキングテンソルが生成されると、データの準備と連結の手順を実行できます。
//--- Prepare Data if(!Prepare(NeuronOCL.getOutput(), SecondInput)) return false;
次に、位置エンコーディングを追加し、それをTransformerエンコーダに渡します。
//--- Encoder if(!cPE.FeedForward(cData.AsObject())) return false; if(!cEncoder.FeedForward(cPE.AsObject())) return false;
次に、UniTrajアルゴリズムに従って、BTSブロックを使用します。順方向および逆方向のスケーリング行列を作成しましょう。
//--- BTS if(!BTS()) return false;
予測を立ててみましょう。
if(!cProjDForw.FeedForward(cDForw.AsObject())) return false; if(!cProjDBakw.FeedForward(cDBakw.AsObject())) return false;
それらをエンコーダの作業結果で乗算します。
if(!ElementMult(cEncoder.getOutput(), cProjDForw.getOutput(), cDataDForw.getOutput())) return false; if(!ElementMult(cEncoder.getOutput(), cProjDBakw.getOutput(), cDataDBakw.getOutput())) return false;
次に、取得した値を1つのテンソルに結合します。
if(!Concat(cDataDForw.getOutput(), cDataDBakw.getOutput(), cConcatDataDForwBakw.getOutput(), 3, 3, cData.Neurons() / 3)) return false;
状態空間モデルでデータを分析してみましょう。
//--- SSM if(!cSSM[0].FeedForward(cConcatDataDForwBakw.AsObject())) return false; for(uint i = 1; i < cSSM.Size(); i++) if(!cSSM[i].FeedForward(cSSM[i - 1].AsObject())) return false;
その後、ターゲット分布の統計指標の投影が得られます。
//--- VAE if(!cStat.FeedForward(cSSM[cSSM.Size() - 1].AsObject())) return false;
次に、指定された分布から値をサンプリングします。
if(!cTranspStat.FeedForward(cStat.AsObject())) return false; if(!cVAE.FeedForward(cTranspStat.AsObject())) return false;
デコーダーはターゲットシーケンスを生成します。
//--- Decoder if(!cTranspVAE.FeedForward(cVAE.AsObject())) return false; if(!cDecoder[0].FeedForward(cTranspVAE.AsObject())) return false; if(!cDecoder[1].FeedForward(cDecoder[0].AsObject())) return false; if(!cTranspResult.FeedForward(cDecoder[1].AsObject())) return false; //--- return true; }
次に、それを入力データの次元に転置します。
ご記憶のとおり、オブジェクト初期化メソッドの実行中にデータバッファへのポインタを置き換えたため、この段階では、受信した値を内部オブジェクトからクラスの継承バッファにコピーする必要はありません。フィードフォワードメソッドを終了するには、呼び出し元のプログラムにブール値の実行結果を返すだけです。
フィードフォワードアルゴリズムが構築された後、次のステップは通常、バックプロパゲーションプロセスの整理です。これらのプロセスはフィードフォワードパスを反映していますが、データの流れは逆になります。ただし、作業の範囲と記事のフォーマットの制約を考慮して、ここではバックプロパゲーションパスの詳細には触れません。その代わりに、独自に学習することをお勧めします。なお、このクラスとそのすべてのメソッドの完全なコードは、添付ファイルに記載されています。
2.3 モデルアーキテクチャ
UniTrajアルゴリズムの解釈を実装したので、次はそれをモデルに統合する作業に進みます。履歴データに適用される他の軌跡解析手法と同様に、提案されたアルゴリズムを環境状態エンコーダモデルに組み込みます。このモデルのアーキテクチャは、CreateEncoderDescriptionsメソッドで定義されます。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
このメソッドは、外部プログラムから、動的配列オブジェクトへのポインタをパラメータとして受け取り、そこでモデルアーキテクチャを指定します。メソッドの本体では、受信したポインタの有効性をすぐに確認し、必要に応じて新しいオブジェクトを作成します。その後、アーキテクチャソリューションの説明に移ります。
最初に実装するコンポーネントは、入力データを格納する全結合層です。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
この段階では、事前定義された履歴深度にわたって、過去の価格変動情報と分析された指標の値を記録します。これらの生の入力は、前処理なしでそのまま端末から取得されます。当然、そのようなデータは非常に矛盾している可能性があります。これを解決するには、バッチ正規化層を適用して、値を比較可能なスケールにします。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
正規化されたデータをすぐに新しいUniTrajブロックに転送します。ここでは、マスキング係数を受信データの50%に設定します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronUniTrajOCL; descr.window = BarDescr; //window descr.window_out = EmbeddingSize; //Inside Dimension descr.count = HistoryBars; //Units descr.layers = NForecast; //Forecast descr.step=4; //Heads descr.probability=0.5f; //DropOut descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
ブロックの出力では、復元された履歴データと特定の計画期間の予測値の両方を含む任意のターゲット軌道が取得されます。取得したデータに、データ正規化中に削除された入力データの統計変数を追加します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * (NForecast+HistoryBars); descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
次に、予測値を周波数領域で整列させます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast+HistoryBars; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
新しいCNeuronUniTrajブロックの包括的なアーキテクチャのおかげで、作成されたモデルの説明は、その機能を損なうことなく、簡潔かつ構造化されたままになります。
環境状態エンコーダモデルのテンソルサイズの増加により、ActorモデルとCriticモデルの両方に若干の調整が必要になったことに注意してください。ただし、これらの変更は最小限であり、添付の資料で個別に確認できます。ただし、エンコーダモデルの訓練プログラムに対する変更はより大規模です。
2.4 モデル訓練プログラム
環境状態エンコーダモデルのアーキテクチャに加えられた変更と、UniTrajの作成者によって提案された訓練アプローチにより、モデル訓練EA「...\Experts\UniTraj\StudyEncoder.mq5」の更新が必要になります。
最初の調整では、モデル検証ブロックを変更して出力層のサイズをチェックしました。これは、EA初期化メソッド内でのターゲット更新でした。
Encoder.getResults(Result); if(Result.Total() != (NForecast+HistoryBars) * BarDescr) { PrintFormat("The scope of the Encoder does not match the forecast state count (%d <> %d)", (NForecast+HistoryBars) * BarDescr, Result.Total()); return INIT_FAILED; }
しかし、ご想像のとおり、主な作業はモデルの訓練メソッドTrainで必要になります。
void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9);
このメソッドでは、まず、得られたリターンに基づいて訓練中に軌道を選択するための確率ベクトルを生成します。この操作の本質は、収益性の高い軌道をより頻繁に優先し、モデルがより収益性の高い戦略を学習できるようにすることです。
次に、必要な変数を宣言します。
vector<float> result, target, state; bool Stop = false; const int Batch = 1000; int b = 0; //--- uint ticks = GetTickCount();
モデル訓練サイクルのシステムを作成します。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += b) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 5 - NForecast)); if(start <= 0) continue;
Mambaブロックには反復的な性質があり、それが訓練プロセスに影響を与えることに注意することが重要です。最初に、経験再生バッファから単一の軌跡をサンプリングし、訓練の開始状態を選択します。次に、選択した軌道に沿って状態を順番に反復処理するネストされたループを作成します。
for(b = 0; (b < Batch && (iter + b) < Iterations); b++) { int i = start + b; if(i >= MathMin(Buffer[tr].Total, Buffer_Size) - NForecast) break;
まず、経験再生バッファから分析されたパラメータの履歴データを読み込みます。
state.Assign(Buffer[tr].States[i].state); if(MathAbs(state).Sum() == 0) break; bState.AssignArray(state);
次に、実際の後続値をロードします。
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
その後、学習プロセスを50%の確率でランダムに2つのスレッドに分割します。
//--- State Encoder if((MathRand() / 32767.0) < 0.5) { if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
最初のケースでは、前と同様に、履歴データのみをモデルに入力し、フィードフォワードパスを実行します。2番目のケースでは、価格変動の実際の将来値もモデルに提供します。これは、モデルがシステムの過去と将来の状態の両方に関する完全な実情報を受け取ることを意味します。
else { if(Result.GetIndex()>=0) Result.BufferWrite(); if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
念のため、私たちのアルゴリズムは訓練中に入力データの50%のランダムマスキングを適用します。このモードでは、モデルはマスクされた値を復元する方法を学習します。
モデルの出力では、完全な軌跡が単一のテンソルとして取得されるため、2つのソースデータバッファを1つのテンソルに結合し、それをモデルのバックプロパゲーションパスに使用します。リカバリパスでは、データの回復と予測における全体的な誤差を最小限に抑えるために、モデルの訓練パラメータを調整します。
//--- Collect target data if(!bState.AddArray(Result)) continue; if(!Encoder.backProp((CBufferFloat*)GetPointer(bState), (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
ここで、訓練プロセスの進行状況をユーザーに通知し、ループシステムの次の反復に進む必要があります。
//--- if(GetTickCount() - ticks > 500) { double percent = double(iter + b) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
モデル訓練ループのすべての反復が正常に完了したら、銘柄のチャートのコメントフィールドをクリアします。訓練結果を端末ログに出力し、モデルの完了を初期化します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
モデルの展開中に、予測値を入力として提供する予定はありません。したがって、Actor方策訓練プログラムは変更されません。ここで使用されているすべてのプログラムの完全なコードは添付ファイルにあります。
3.テスト
前のセクションでは、マルチモーダル時系列を扱うためのUniTraj法の理論的基礎について解説し、MQL5を使用してその実装をおこないました。今回は最終段階として、これらのアプローチが特定のタスクに対してどれだけ有効かを評価します。
環境状態エンコーダーモデルのアーキテクチャや訓練プログラムにいくつかの変更を加えましたが、訓練データセットの構造には変更がありません。そのため、これまでに収集したデータセットを引き続き使用して訓練を開始できます。
ここでも、モデルの訓練には2023年通年のEURUSDのH1時間枠における実際の履歴データを使用します。各インジケーターパラメータはすべてデフォルト設定のままとしました。
この段階では、エンコーダモデルの訓練をおこないます。前述の通り、エンコーダーの訓練中にデータセットを更新する必要はありません。モデルは目標とするパフォーマンスに達するまで訓練を継続します。なお、このモデルは軽量とは言えず、訓練にはある程度の時間を要しますが、プロセスは順調に進行します。その結果、将来の価格変動を視覚的に合理的に予測できるモデルを得ることができました。
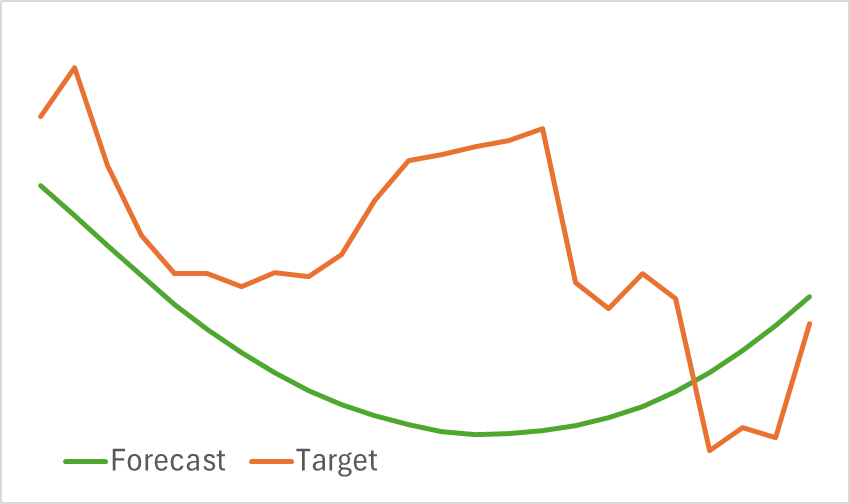
とはいえ、予測された軌道は大幅に平滑化されています。再構築された軌道についても同様です。これは、元のデータに含まれていたノイズが大幅に低減されたことを示しています。次のモデル訓練段階では、この平滑化が収益性の高いActor方策の開発にとって有益かどうかを検証することになります。
第2段階では、ActorモデルとCriticモデルを反復的に訓練します。この段階では、環境状態エンコーダによって生成された価格変動予測に基づいて、収益性の高いActor方策を見つけることが求められます。エンコーダは、将来の予測価格変動と再構築された過去の価格変動の両方を出力します。
訓練済みのモデルをテストするために、その他のパラメータを変更せずに、2024年1月の履歴データを使用しました。
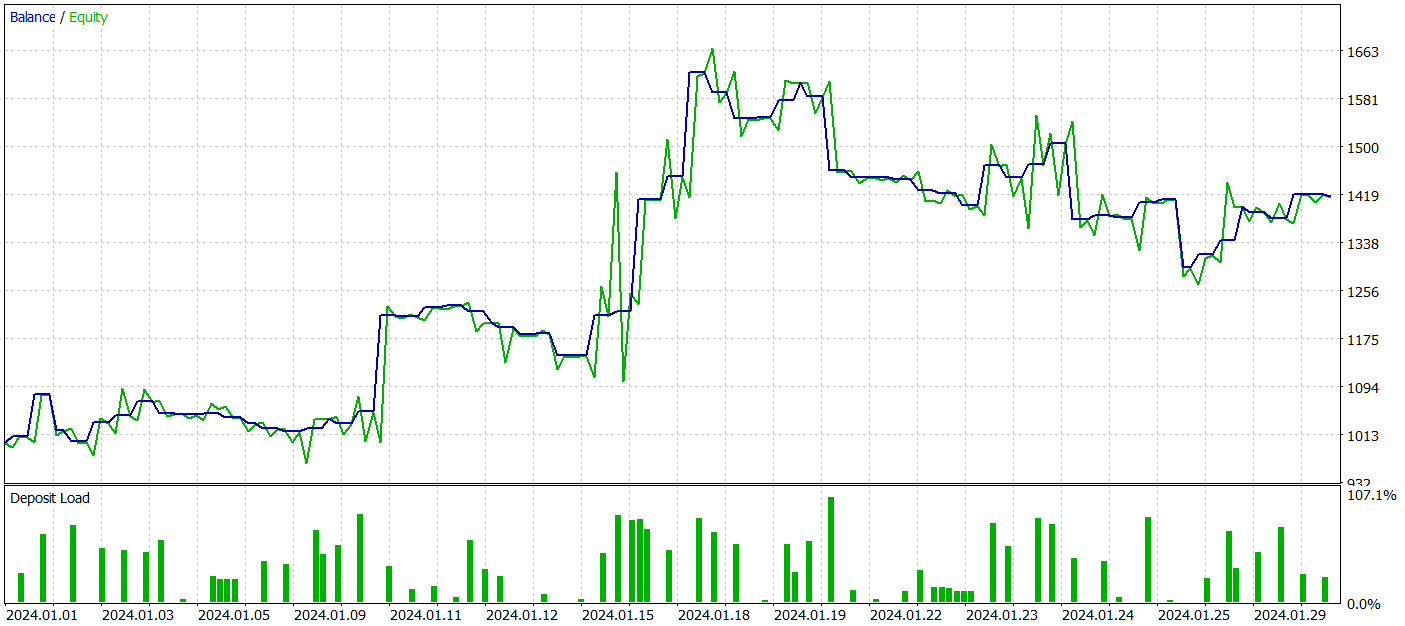
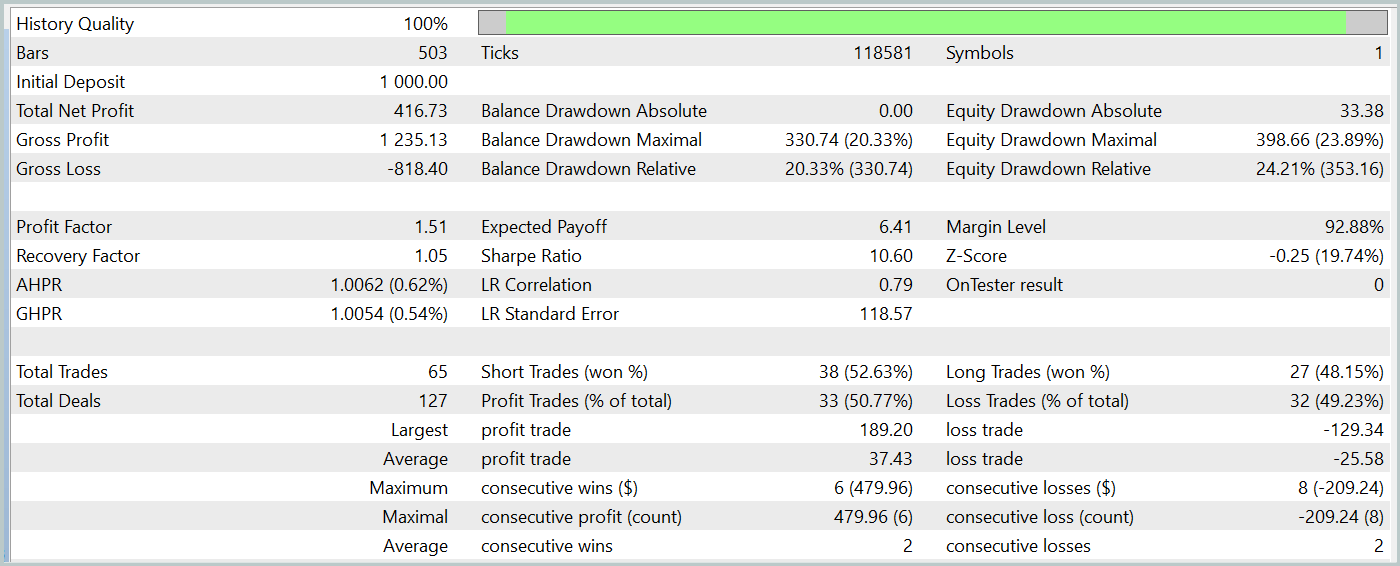
テスト期間中、訓練済みのActorモデルは、最大ドローダウンが24%強でありながら、40%以上の利益を達成しました。EAは合計65回の取引を実行し、そのうち33回が利益で終了しました。最大および平均の勝ちトレードの金額が、それぞれ対応する負けトレードの金額を上回ったため、プロフィットファクターは1.51と記録されました。もちろん、1か月間のテストと65回の取引だけでは長期的な安定性を保証するには不十分ですが、今回の結果はTraj-LLM法による結果を上回るものでした。
結論
本研究で提案したUniTraj法は、さまざまなシナリオにおいてエージェントの軌跡を処理する多目的ツールとしての可能性を示しました。本手法は、複数タスクへのモデル適応という重要課題に対応し、従来手法と比較してパフォーマンス向上を実現します。マスクされた入力データを統一的に扱うことで、UniTrajは柔軟かつ効率的なソリューションとなります。
実践セクションでは、提案手法をMQL5上で実装し、環境状態エンコーダモデルに統合しました。さらに、実際の履歴データを用いてモデルを訓練およびテストしました。得られた結果は、提案アプローチの有効性を示しており、実用的な取引戦略の構築にも適用可能であることを確認しました。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダ訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15648
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索