取引におけるニューラルネットワーク:階層型ベクトルTransformer(最終回)

はじめに
前回の記事自動運転車におけるマルチエージェント動作予測のために提案された階層的ベクトルTransformer(HiVT)アルゴリズムの理論的な説明を紹介しました。この手法は、予測問題を局所的なコンテキスト抽出と大域的な相互作用モデリングの段階に分けることで、効果的に解決するアプローチを提供します。
以下に、この手法の簡単な概要を示します。HiVT法では、時系列予測の問題を3つの段階で解決します。第一段階では、モデルがオブジェクトの局所的なコンテキスト特徴を抽出します。シーン全体は、各中央エージェントを中心とした一連の局所領域に分割されます。
第二段階では、各エージェント中心の局所領域間で情報を伝達することで、シーン全体におけるグローバルな長距離依存関係を捉えます。
このようにして得られた局所および大域の表現を組み合わせることで、デコーダはモデルの1回のフォワードパスで全エージェントの将来の軌道を予測することが可能になります。
以下に、著者によるこの手法の視覚的な図解を示します。
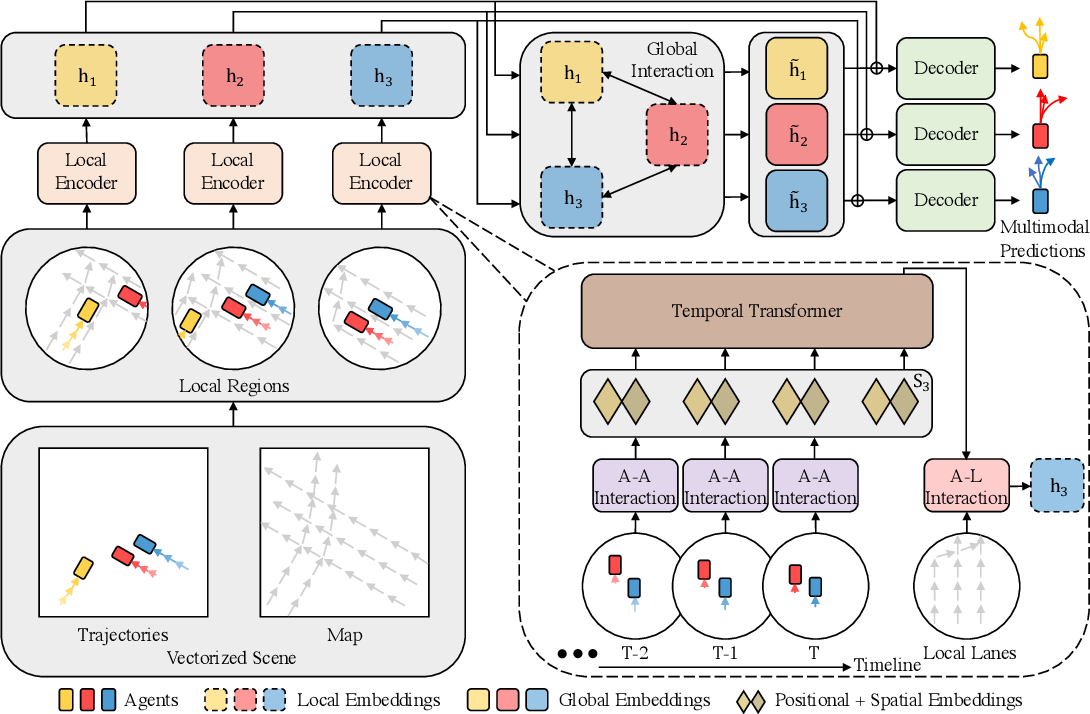
さらに、前回の記事では、提案されたアルゴリズムの各ブロックを実装するための、かなり広範な準備作業をおこないました。今回は、その作業を完了し、個々に実装されたブロックを1つの統一された複雑な構造へと統合していきます。
1. HiVTの組み立て
HiVTの著者によって提案されたアプローチに対する私たちの解釈を、CNeuronHiVTOCLクラスの枠組みの中で実装します。コアとなる機能は、全結合層基底クラスであるCNeuronBaseOCLから継承されます。その全体構造は以下の通りです。
class CNeuronHiVTOCL : public CNeuronBaseOCL { protected: uint iHistory; uint iVariables; uint iForecast; uint iNumTraj; //--- CNeuronBaseOCL cDataTAD; CNeuronConvOCL cEmbeddingTAD; CNeuronTransposeRCDOCL cTransposeATD; CNeuronHiVTAAEncoder cAAEncoder; CNeuronTransposeRCDOCL cTransposeTAD; CNeuronLearnabledPE cPosEmbeddingTAD; CNeuronMVMHAttentionMLKV cTemporalEncoder; CNeuronLearnabledPE cPosLineEmbeddingTAD; CNeuronPatching cLineEmbeddibg; CNeuronMVCrossAttentionMLKV cALEncoder; CNeuronMLMHAttentionMLKV cGlobalEncoder; CNeuronTransposeOCL cTransposeADT; CNeuronConvOCL cDecoder[3]; // Agent * Traj * Forecast CNeuronConvOCL cProbProj; CNeuronSoftMaxOCL cProbability; // Agent * Traj CNeuronBaseOCL cForecast; CNeuronTransposeOCL cTransposeTA; //--- virtual bool Prepare(const CNeuronBaseOCL *history); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override ; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronHiVTOCL(void) {}; ~CNeuronHiVTOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, uint num_traj, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronHiVTOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
提示されたCNeuronHiVTOCLオブジェクトの構造には、すでにおなじみのオーバーライド可能なメソッドのリストに加え、それらのメソッドのアルゴリズムを実装する過程で検討する、複数の内部オブジェクトの宣言が含まれています。
すべての内部オブジェクトはstaticとして宣言されているため、クラスのコンストラクタおよびデストラクタは空のままにしておくことができます。すべてのネストされたオブジェクトと変数の初期化は、Initメソッド内でおこなわれます。
bool CNeuronHiVTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, uint num_traj, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count < 2 || !CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * forecast, optimization_type, batch)) return false;
メソッドのパラメータでは、初期化されたオブジェクトのアーキテクチャを一意に識別するための主要な定数を受け取ります。メソッド本体では、親クラスの対応するメソッドを呼び出します。この親メソッドは、ご存知のとおり、継承されたすべてのオブジェクトおよび変数の初期化をおこないます。
親クラスのメソッドに実装されている各種チェックに加えて、本メソッドでは、解析対象のシーケンス内に含まれる要素数を直接確認する処理を追加しています。このチェックでは、要素数が少なくとも2つ以上であることを求めます。これは、HiVTアルゴリズムに基づく初期状態のベクトル化処理において、値の変化(ダイナミクス)を扱うためです。値の変化を算出するには、現在のタイムステップと直前のタイムステップ、つまり2つの参照値が必要になります。
初期化メソッド内の制御ブロックを正常に通過した後は、受け取ったブロックアーキテクチャのパラメータをローカル変数に保存します。
iVariables = window; iHistory = units_count - 1; iForecast = forecast; iNumTraj = MathMax(num_traj, 1);
次に、内部オブジェクトの初期化をおこないます。これらの初期化は、フィードフォワードパスのアルゴリズム内で使用される順序に従って進めていきます。このアプローチにより、構築中のアルゴリズムを改めて見直すことができると同時に、各オブジェクトの作成が必要かつ十分であることを確認できます。
まず、環境の解析状態をベクトルで表現するための内部層オブジェクトを作成します。
ここで改めて確認しておきたいのは、単変量シーケンスの各要素が持つ記述ベクトルの次元数は、分析対象の単変量シーケンス数の2倍であるという点です。これは、各要素が2次元空間での移動に加え、解析対象の要素に対する他のエージェントの位置変化という情報を持っているためです。
このような記述ベクトルは、すべての単変量シーケンスの各要素に対して、各タイムステップごとに生成されます。
if(!cDataTAD.Init(0, 0, OpenCL, 2 * iVariables * iVariables * iHistory, optimization, iBatch)) return false;
HiVTアルゴリズムの実装においては、3次元テンソルを用いて処理を構築し、その構造を1次元のデータバッファに保存する点にご注意ください。各オブジェクト名には、対応する次元を示すための3文字の接尾辞を付けています。
- T (Time):時間ステップの次元
- A (Agent):エージェントの次元(単変量時系列、すなわち本ケースでは解析対象のパラメータ)
- D (Dimension):単変量シーケンスの各要素を記述するベクトルの次元
続いて、畳み込み層を使用して、生成されたベクトル記述から埋め込みを作成します。
if(!cEmbeddingTAD.Init(0, 1, OpenCL, 2 * iVariables, 2 * iVariables, window_key, iVariables * iHistory, 1, optimization, iBatch)) return false;
この場合、埋め込みを生成するために1つのパラメータ行列を使用し、それをマルチモーダルシーケンスのすべての要素に適用します。したがって、この層で分析対象となるブロック数は、「単変量シーケンスの数 × 分析する履歴の深さ」として定義されます。
埋め込みを生成した後は、HiVTアルゴリズムに従い、1つのタイムステップ内におけるエージェント間のローカルな依存関係を分析する必要があります。前回の記事でも説明したとおり、この処理を行う前に、元のデータを転置する必要があります。
if(!cTransposeATD.Init(0, 2, OpenCL, iHistory, iVariables, window_key, optimization, iBatch)) return false;
その後になって初めて、ローカルグループ内のエージェント間の依存関係を識別するために、アテンションクラスを使用することができます。
if(!cAAEncoder.Init(0, 3, OpenCL, window_key, window_key, heads, (heads + 1) / 2, iVariables, 2, 1, iHistory, optimization, iBatch)) return false;
次の2つの瞬間に注意してください。まず、データの転置後、オブジェクト名のサフィックスの文字列をATDに変更しました。これは、データ転置層の出力として得られる3次元テンソルの次元構成に対応しています。
次に、アテンションブロックの機能について確認しておきましょう。当初、これらのブロックは2次元テンソルで動作するように設計されており、各行が単一のシーケンス要素を表す記述ベクトルでした。つまり、行同士の依存関係を抽出する、いわゆる「垂直アテンション」を実行していました。その後、マルチモーダル時系列内の各単変量シーケンスにおける依存関係の検出が導入されました。これを実現するために、元の行列を複数の小規模な行列に分割しました。各行列は同一構造を持ち、行数は元の行列と同じで、列方向のデータが均等に分割されています。この構造は、3次元テンソルの次元構成と一致します。第1次元は、元のデータ行列の行数(時系列の長さ)を示します。第2次元は、独立に処理される小行列の数(シーケンス数)を示します。第3次元は、1つのシーケンス要素を表す記述ベクトルの次元を示します。また、元のデータから埋め込みテンソルを転置したことを踏まえ、現在のアテンションブロックにおいては、分析対象のシーケンスサイズをユニタリシーケンスの数として定義します。一方で、履歴データの深さは「変数の数」として別のパラメータで指定します。このアプローチにより、1つの時間ステップ内における変数間の依存関係を効率的に分析することが可能になります。
このエージェント間依存関係の分析ブロックでは、2つのアテンション層を用いて、それぞれの内部層に対してKey-Valueテンソルを生成しています。Key-Valueテンソルのアテンションヘッド数は、対応するQueryテンソルのパラメータの半分に設定されています。
加えて、このケースでは、CNeuronHiVTAAEncoderという機能管理関数を持つアテンションブロックを使用している点にも留意してください。
ローカルグループ内でのエージェント間依存関係に基づきシーケンス要素の埋め込みを強化した後、HiVTアルゴリズムは、各ユニタリシーケンス内における時間的依存関係の分析をおこなう段階に進みます。この段階では、データを再び元の形に戻す必要があります。
if(!cTransposeTAD.Init(0, 4, OpenCL, iVariables, iHistory, window_key, optimization, iBatch)) return false;
次に、完全に訓練可能な位置エンコーディングを追加します。
if(!cPosEmbeddingTAD.Init(0, 5, OpenCL, iVariables * iHistory * window_key, optimization, iBatch)) return false;
次に、アテンションブロックCNeuronMVMHAttentionMLKVを使用して、時間的な依存関係を識別します。
if(!cTemporalEncoder.Init(0, 6, OpenCL, window_key, window_key, heads, (heads + 1) / 2, iHistory, 2, 1, iVariables, optimization, iBatch)) return false;
局所的依存性アテンションブロックと時間依存性アテンションブロックではアーキテクチャに違いがありますが、初期化には同一のパラメータを使用します。
次のステップでは、HiVTの著者は、エージェントの埋め込みにロードマップの情報を加えることで表現を強化することを提案しています。道路の状態や標示、カーブといった要素がエージェントの行動に影響を与えることに疑いの余地はないでしょう。一方、私たちのケースでは、分析対象パラメータの値変化を制約する明確なガイドラインは存在しません。もちろん、個別のオシレーターには許容される値の範囲が設定されていることがあります。たとえば、 RSIは0から100の範囲に限定されます。しかし、これはあくまで例外的なケースです。
そこで、私たちは保有している過去の履歴データを用いて、最も起こりやすい変化を導き出すことにします。HiVTにおける「ロードマップ」の代替として、実際の軌跡の小セグメントをデータパッチング層によって生成し、それらを埋め込みベクトルとして活用します。
if(!cLineEmbeddibg.Init(0, 7, OpenCL, 3, 1, 8, iHistory - 1, iVariables, optimization, iBatch)) return false;
現在の状態をベクトル化する際には、1タイムステップにおけるパラメータ変化のダイナミクスを使用していたことに注意してください。一方、実際の軌道の小セクションを埋め込む際には、ステップサイズ1で3要素のブロックを使用します。このアプローチにより、ある特定のステップにおける指標の変化と、その後の軌道の継続パターンとの間に存在する可能性のある依存関係を明らかにしようとしています。
その後、生成された埋め込みベクトルに対して、完全に訓練可能な位置エンコーディングを追加します。
if(!cPosLineEmbeddingTAD.Init(0, 8, OpenCL, cLineEmbeddibg.Neurons(), optimization, iBatch)) return false;
次に、現在のエージェントの埋め込みに軌道に関する情報を付加します。そのために、2つの内部層を持つクロスアテンションブロックCNeuronMVCrossAttentionMLKVを使用します。
if(!cALEncoder.Init(0, 9, OpenCL, window_key, window_key, heads, 8, (heads + 1) / 2, iHistory, iHistory - 1, 2, 1, iVariables, iVariables, optimization, iBatch)) return false;
ここでは、時間的な依存関係の特定と、エージェントと軌道の間の依存関係の分析という、似たような処理を連続しておこなっているように見えるかもしれません。どちらの場合も、他の時間間隔における同じ指標のパラメーター表現と、エージェントの現在の状態との依存関係を分析しています。しかし、この2つには微妙な違いがあります。最初のケースでは、異なる時間ステップにおけるエージェントの類似した状態同士を比較しています。一方で、後者では、やや長い時間スパンにまたがる特定の軌道パターンを扱っています。
これで、ローカル依存関係の分析ブロックが完了し、エージェントの状態埋め込みは多面的に強化されます。HiVTアルゴリズムの次のステップは、大域的相互作用ブロックにおけるシーン全体の長期的な依存関係の分析です。
if(!cGlobalEncoder.Init(0, 10, OpenCL, window_key*iVariables, window_key*iVariables, heads, (heads+1)/2, iHistory, 4, 2, optimization, iBatch)) return false;
ここでは、4つの内部層を持つアテンションブロックを使用します。依存関係の分析には、個々のエージェントではなく、シーン全体の表現を使用します。
次に、予測される値のシーケンスをモデル化する必要があります。これまでと同様に、将来のシーケンスの予測は、個々の単変量シーケンスの枠組みでおこなわれます。そのためには、まず現在のデータを転置する必要があります。
if(!cTransposeADT.Init(0, 11, OpenCL, iHistory, window_key * iVariables, optimization, iBatch)) return false;
さらに、計画深度全体にわたる将来の値を予測するために、HiVT手法の著者はMLPの使用を提案しています。一方、私たちの場合は、この処理を3つの連続した畳み込み層のブロックでおこないます。各層は、それぞれ異なるデータウィンドウと固有の活性化関数を持っています。
if(!cDecoder[0].Init(0, 12, OpenCL, iHistory, iHistory, iForecast, window_key * iVariables, optimization, iBatch)) return false; cDecoder[0].SetActivationFunction(SIGMOID); if(!cDecoder[1].Init(0, 13, OpenCL, iForecast * window_key, iForecast * window_key, iForecast * window_key, iVariables, optimization, iBatch)) return false; cDecoder[1].SetActivationFunction(LReLU); if(!cDecoder[2].Init(0, 14, OpenCL, iForecast * window_key, iForecast * window_key, iForecast * iNumTraj, iVariables, optimization, iBatch)) return false; cDecoder[2].SetActivationFunction(TANH);
最初の段階では、個々のエージェントの状態を表す埋め込み記述の各要素を対象に処理をおこない、分析対象の履歴の深さから計画期間まで、シーケンスのサイズを変更します。
次に、テンソルのサイズを変更せずに、計画期間全体にわたって各エージェント内の大域的な依存関係を分析します。
最後の段階では、各一変量時系列に対して複数の予測シナリオを生成します。予測される軌道のバリエーション数は、メソッドのパラメータとして外部プログラムから指定されます。
ここで特筆すべき点は、複数のシナリオを同時に予測するという点が、このアプローチの大きな特徴であるということです。ただし、最も可能性の高い軌道を選択するためのメカニズムが必要になります。そのため、まず得られた各軌道を、各エージェントに対する予測軌道数という次元に投影します。
if(!cProbProj.Init(0, 15, OpenCL, iForecast * iNumTraj, iForecast * iNumTraj, iNumTraj, iVariables, optimization, iBatch)) return false;
次に、Softmax関数を使用して、得られた投影を確率領域に変換します。
if(!cProbability.Init(0, 16, OpenCL, iForecast * iNumTraj * iVariables, optimization, iBatch)) return false; cProbability.SetHeads(iVariables); // Agent * Traj
以前に予測された軌道をその確率で重み付けすることで、エージェントの今後の動きの平均軌道を取得します。
if(!cForecast.Init(0, 17, OpenCL, iForecast * iVariables, optimization, iBatch)) return false;
ここでは、予測値を元のデータの次元に変換するだけです。データを転置することで機能を実装します。
if(!cTransposeTA.Init(0, 18, OpenCL, iVariables, iForecast, optimization, iBatch)) return false;
データのコピー操作を削減し、メモリリソースの使用を最適化するために、本ブロックの結果および誤差勾配のバッファポインタを、最後の内部データ転置層の同様のバッファに再定義します。
SetOutput(cTransposeTA.getOutput(),true); SetGradient(cTransposeTA.getGradient(),true); //--- return true; }
次に、メソッド操作の論理結果を呼び出し元プログラムに返すことで、メソッド操作を完了します。
クラスオブジェクトの初期化作業が完了したら、feedForwardメソッドでクラスのフィードフォワードアルゴリズムの構築に進みます。
bool CNeuronHiVTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!Prepare(NeuronOCL)) return false;
メソッドのパラメータでは、元のデータを含むオブジェクトへのポインタを受け取ります。受け取ったポインタは直ちに、初期データを準備するPrepareメソッドに渡されます。このメソッドは、データのベクトル化をおこなうカーネルHiVTPrepareを呼び出すための「ラッパー」です。そのアルゴリズムについては前回の記事で説明しました。また、OpenCLプログラムのカーネルをキューに登録するさまざまな方法についてもすでに取り上げました。Prepareメソッドのアルゴリズム自体には特別な処理はないため、本記事ではその詳細な説明は省略します。提供された添付ファイルに記載されたコードを使って、独自に学習することができます。
次に、得られたベクトル表現に基づき、各時間ステップごとにエージェントの埋め込みを生成します。
if(!cEmbeddingTAD.FeedForward(cDataTAD.AsObject())) return false;
転置します。
if(!cTransposeATD.FeedForward(cEmbeddingTAD.AsObject())) return false;
そして、その後、エージェント間の表現の分析の枠組み内で、局所的依存関係を強化します。
if(!cAAEncoder.FeedForward(cTransposeATD.AsObject())) return false;
次のステップでは、時間的な依存関係を追加することでエージェントの状態の埋め込みを強化します。これをおこなうには、まず現在のデータテンソルを転置します。
if(!cTransposeTAD.FeedForward(cAAEncoder.AsObject())) return false;
これに位置エンコードマークを追加します。
if(!cPosEmbeddingTAD.FeedForward(cTransposeTAD.AsObject())) return false;
そして、個々のエージェントのコンテキストで、時間的アテンションモジュールのフィードフォワードメソッドを呼び出します。
if(!cTemporalEncoder.FeedForward(cPosEmbeddingTAD.AsObject())) return false;
時間的アテンション操作が正常に実行されると、局所的および時間的依存関係が強化された分析データの埋め込みテンソルが得られます。次に、得られた埋め込みに、考えられる動きのパターンに関する情報を追加する必要があります。そのためには、まず分析対象の歴史的な移動パターンの埋め込みを作成します。
if(!cLineEmbeddibg.FeedForward(NeuronOCL)) return false;
結果として得られたパターン埋め込みに位置コーディングを追加します。
if(!cPosLineEmbeddingTAD.FeedForward(cLineEmbeddibg.AsObject())) return false;
クロスアテンションモジュールでは、さまざまな動きのパターンに関する情報を使用してエージェントの埋め込みを強化します。
if(!cALEncoder.FeedForward(cTemporalEncoder.AsObject(), cPosLineEmbeddingTAD.getOutput())) return false;
強化されたエージェント埋め込みのテンソルに大域的アテンション モジュールを適用します。
if(!cGlobalEncoder.FeedForward(cALEncoder.AsObject())) return false;
今後のエージェントの動きを予測するブロックが続きます。分析されたパラメータのその後の値を単変量シーケンスの観点から予測することを予定しています。したがって、まず与えられたデータテンソルを転置します。
if(!cTransposeADT.FeedForward(cGlobalEncoder.AsObject())) return false;
次に、データ予測のために 3層MLPブロックのフィードフォワードパスを実行します。
if(!cDecoder[0].FeedForward(cTransposeADT.AsObject())) return false; if(!cDecoder[1].FeedForward(cDecoder[0].AsObject())) return false; if(!cDecoder[2].FeedForward(cDecoder[1].AsObject())) return false;
ここで、HiVTの特徴を忘れないようにしましょう。今後の動きを予測するMLPは、分析された初期シーケンスの継続について、単一の予測ではなく、複数の異なるシナリオを出力します。それぞれの予測される動きのバリエーションに対して確率を算出する必要があります。これを実現するために、まず予測される軌道を作成します。
if(!cProbProj.FeedForward(cDecoder[2].AsObject())) return false;
Softmax関数を使用して、得られた投影を確率領域に変換します。
if(!cProbability.FeedForward(cProbProj.AsObject())) return false;
次に、予測される軌道のテンソルにその確率を掛け算するだけです。
if(IsStopped() || !MatMul(cDecoder[2].getOutput(), cProbability.getOutput(), cForecast.getOutput(), iForecast, iNumTraj, 1, iVariables)) return false;
この操作の結果、分析されたマルチモーダルシーケンスの各単変量シリーズについて、計画期間全体の平均加重軌道のテンソルが得られます。
フィードフォワードメソッドの操作の最後に、予測値テンソルを転置して元のデータの測定値と一致させます。
if(!cTransposeTA.FeedForward(cForecast.AsObject())) return false; //--- return true; }
通常通り、メソッドの操作が成功したことを示すブール値を呼び出し元のプログラムに返します。
これで、HiVT法のフォワードパスアルゴリズムの実装が完了したので、次にクラスのバックワードパスメソッドの開発に進みます。ご存知の通り、バックワードパスアルゴリズムは以下の2つの主要なコンポーネントで構成されています。
- 最終結果に対する影響に基づいて、すべての要素に勾配誤差を分散する。この機能はcalcInputGradientsメソッドに実装されています。
- モデルの訓練可能なパラメータを調整して、全体的な損失を最小化する。これはupdateInputWeightsメソッドで実行されます。
まず、勾配誤差分散をおこなうcalcInputGradientsメソッドの実装からバックワードパスアルゴリズムを始めます。このメソッドのロジックは、フォワードパスアルゴリズムのロジックと完全に一致していますが、すべての操作が逆順で実行される点が異なります。
bool CNeuronHiVTOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
このメソッドは入力パラメータとして、フィードフォワードパス中に入力データを提供したのと同じ層である前の層のオブジェクトへのポインタを受け取ります。ただし、この場合は誤差勾配をその層に戻し、元の入力データが最終結果に与える影響を反映させる必要があります。
メソッド本体では、受け取ったポインタの妥当性を即座に確認します。ポインタが無効であれば、メソッド操作を実行しても意味がありません。
検証チェックが正常に通過すると、それに応じて誤差勾配を分散する処理に進みます。
現在の層の出力レベルでは、誤差勾配はすでにクラスの対応するバッファに格納されています。これは後続の層で同等のメソッドを実行する際に記録されたものです。以前に実装したバッファスワッピングメカニズムにより、必要な誤差勾配は最終データ転置層のバッファにすでに格納されています。ここから、単変量時系列の加重平均予測軌道層のレベルまで誤差勾配を伝播させます。
if(!cForecast.calcHiddenGradients(cTransposeTA.AsObject())) return false;
ご存知のとおり、フィードフォワードパスでは、いくつかの予測軌道のテンソルを対応する確率ベクトルで乗算し、加重平均軌道を取得しました。したがって、バックプロパゲーションパスの過程では、予測軌道のセットのテンソルと確率ベクトルの両方に誤差勾配を分配する必要があります。
if(IsStopped() || !MatMulGrad(cDecoder[2].getOutput(), cDecoder[2].getGradient(), cProbability.getOutput(), cProbability.getGradient(), cForecast.getGradient(), iForecast, iNumTraj, 1, iVariables)) return false;
確率誤差勾配を予測軌道の投影層に渡します。
if(!cProbProj.calcHiddenGradients(cProbability.AsObject())) return false;
予測を得るために、予測軌道自体を使用しました。その後、通常は誤差勾配を予測軌道レベルに渡すことになります。
ただし、予測軌道セットに対する誤差勾配は、前のステップで加重平均軌道からすでに渡されていることに注意が必要です。対応する層のcalcHiddenGradientsメソッドを直接呼び出すと、以前に渡された誤差勾配が上書きされ、バッファが新しい値に置き換えられてしまいます。このような場合、通常は補助データバッファを使用して2つのデータストリームの値を合算し、すべての情報を保持します。しかし、この特定のケースでは、誤差勾配をデータ投影層に渡さないことが決定されました。このアプローチの目的は、後続の軌道予測を「クリーン」に保ち、個々の軌道の関連性に起因する確率分布誤差による歪みを防ぐことです。
その代わりに、予測軌道の誤差勾配を予測ブロック内のMLP層を通じて伝播します。
if(!cDecoder[1].calcHiddenGradients(cDecoder[2].AsObject())) return false; if(!cDecoder[0].calcHiddenGradients(cDecoder[1].AsObject())) return false;
結果として得られた誤差勾配テンソルを転置し、大域的相互作用ブロックに渡します。
if(!cTransposeADT.calcHiddenGradients(cDecoder[0].AsObject())) return false; if(!cGlobalEncoder.calcHiddenGradients(cTransposeADT.AsObject())) return false; if(!cALEncoder.calcHiddenGradients(cGlobalEncoder.AsObject())) return false;
大域的相互作用ブロックから、誤差勾配は局所的依存関係分析ブロックに渡されます。
このブロックは、個々の局所的オブジェクト間の相互依存関係を包括的に分析します。まず、受け取った誤差勾配をAgent-Trajectoryクロスアテンションブロックに通し、その後、時間的依存性分析およびモーションパターン埋め込みの位置エンコードのレベルまで伝播させます。
if(!cTemporalEncoder.calcHiddenGradients(cALEncoder.AsObject(), cPosLineEmbeddingTAD.getOutput(), cPosLineEmbeddingTAD.getGradient(), (ENUM_ACTIVATION)cPosLineEmbeddingTAD.Activation())) return false;
位置コーディング操作を通じて誤差勾配を伝播します。
if(!cLineEmbeddibg.calcHiddenGradients(cPosLineEmbeddingTAD.AsObject())) return false;
そしてそれをソースデータ レベルに渡します。
if(!NeuronOCL.calcHiddenGradients(cLineEmbeddibg.AsObject())) return false;
2番目のデータ ストリームでは、まず時間依存性分析ブロックを通じて誤差勾配を伝播します。
if(!cPosEmbeddingTAD.calcHiddenGradients(cTemporalEncoder.AsObject())) return false;
その後、得られた誤差勾配を位置コーディング操作で調整します。
if(!cTransposeTAD.calcHiddenGradients(cPosEmbeddingTAD.AsObject())) return false;
次に、データを転置し、エージェント間の依存関係分析ブロックを通じて勾配を伝播します。
if(!cAAEncoder.calcHiddenGradients(cTransposeTAD.AsObject())) return false; if(!cTransposeATD.calcHiddenGradients(cAAEncoder.AsObject())) return false;
メソッドでの操作の最後に、データを元の表現に転置し、埋め込み生成層を通じて誤差勾配を元のデータのベクトル表現に伝播します。
if(!cEmbeddingTAD.calcHiddenGradients(cTransposeATD.AsObject())) return false; if(!cDataTAD.calcHiddenGradients(cEmbeddingTAD.AsObject())) return false; //--- return true; }
通常どおり、メソッド操作の実行結果を示すブール値を呼び出し元プログラムに返します。
この段階では、最終結果への影響に基づき、すべてのモデル要素に誤差勾配を分散しました。次に、全体的な誤差を最小化するために、訓練可能なモデルパラメータを調整する必要があります。この機能はupdateInputWeightsメソッドに実装されています。
新しいクラスCNeuronHiVTOCLのすべての訓練可能なパラメータは、その内部オブジェクト内に格納されていることに注意することが重要です。ただし、すべての内部オブジェクトが訓練可能なパラメータを持っているわけではありません。例えば、データ転置層にはそれらのパラメータは含まれていません。したがって、このメソッドでは、がく週可能なパラメータを含むオブジェクトのみと対話します。それらを調整するためには、各内部オブジェクトの対応するメソッドを呼び出すだけで十分です。
ご覧の通り、このメソッドのロジックは非常にシンプルであるため、この記事ではその完全なコードを提供することはありません。提供された添付ファイルに記載されたコードを使って、独自に学習することができます。また、添付ファイルには新しいクラスとそのすべてのメソッドの完全なソースコードも含まれています。
2. モデルアーキテクチャ
CNeuronHiVTOCLクラスとそのメソッドの開発が完了しました。このクラスは、 HiVT法の提案者によるアプローチの解釈を実装しています。ここで、新しいオブジェクトをモデルのアーキテクチャに統合します。
これまでと同様に、分析されたマルチモーダル系列の将来の動きに関する予測オブジェクトを、環境状態エンコーダモデルに組み込みます。このモデルのアーキテクチャ設計は、CreateEncoderDescriptionsメソッドで定義されます。このメソッドは、生成されたモデルのアーキテクチャを記録する動的配列オブジェクトへのポインタを受け取ります。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
メソッド本体では、受け取ったポインタの妥当性を確認し、必要であれば動的配列の新しいインスタンスを作成します。その後、モデルの各層のアーキテクチャソリューションについて順番に説明します。
初期データを取得するには、十分なサイズの全結合基本層を使用します。
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
モデルには、生データ、すなわち処理されていないデータを入力する予定です。このようなデータを比較可能な形にするために、バッチ正規化層を使用します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
初期処理後、元のデータを即座にHiVT法のアプローチを使用して構築した新しいブロックに転送します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronHiVTOCL; { int temp[] = {BarDescr, NForecast, 6}; // {Variables, Forecast, NumTraj} ArrayCopy(descr.windows, temp); } descr.window_out = EmbeddingSize; // Inside Dimension descr.count = HistoryBars; // Units descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
ここでは、以前の研究で使用されたパラメータとほぼ同じものを使用しています。ただし、予測軌道のバリエーションの数を決定するための新しいブロックパラメータが1つ追加されています。この場合、6つのバリエーションを使用します。
CNeuronHiVTOCLブロックの出力として、分析されたマルチモーダル時系列の予測値を得ることが期待されます。しかし、1つ注意点があります。マルチモーダル時系列モデルが効率的に動作するようにするため、すべてのデータを比較可能な形式に変換しました。そのため、予測された値も同様の形式で得られました。しかし、得られた予測値を元のデータの通常の値に一致させるためには、正規化の過程で除外した分布の統計パラメータを再度追加する必要があります。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
その後、得られた結果を周波数領域で調整します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
ActorモデルとCriticモデルのアーキテクチャは変更されません。モデル訓練プログラムについても同様です。したがって、この記事ではそれらについて詳細には説明しません。ただし、この研究で使用したすべてのプログラムの完全なソースコードは、さらに詳しく調査するために添付資料にて利用可能です。
3.テスト
HiVT法の解釈の実装が完了しました。今、私たちのソリューションの有効性を評価する時が来ました。まず、実際の履歴データでモデルを訓練し、その後、訓練セットに含まれていないデータセットを使用して、訓練したモデルをテストする必要があります。
訓練には、2023年のH1時間足のEURUSD履歴データを使用します。
訓練はオフラインで実施されます。したがって、まず必要な訓練データセットをコンパイルする必要があります。このプロセスの詳細については、Real-ORLメソッドに関する記事を参照してください。環境状態エンコーダーの訓練には、前回のモデルの運用中に収集したデータセットを使用しました。
ご存知の通り、ステートエンコーダーモデルは、エージェントの行動とは無関係な過去の価格変動データと分析された指標のみで動作します。したがって、この段階では新たに追加された軌跡がエンコーダにとって追加情報を提供することはないため、訓練データセットを定期的に更新する必要はありません。望ましい結果が得られるまで訓練プロセスを続けます。
訓練されたモデルのテストの結果を以下に示します。
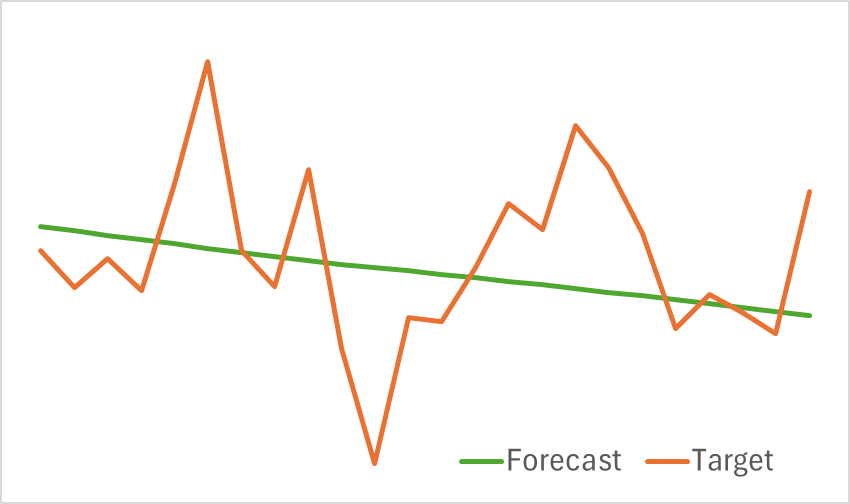
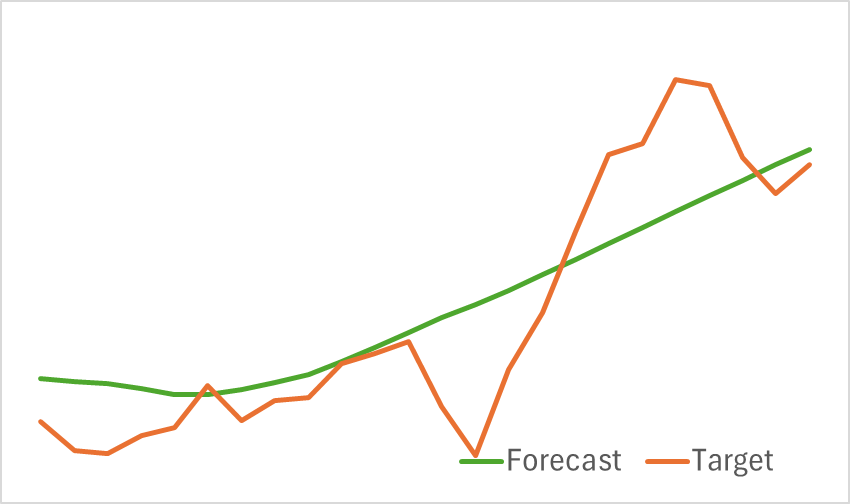
提供されたグラフからわかるように、モデルは今後の価格変動の主要な傾向を効果的に捉えています。
次に、訓練の第2段階に進みます。この段階では、Actorの利益最大化行動方策とCriticの報酬関数の訓練に重点を置きます。エンコーダとは異なり、Actorの訓練は環境内での行動に大きく依存します。効果的な学習を実現するためには、訓練データセットを常に最新の状態に保つ必要があります。そのため、Actorの現在のポリシーを反映するために、データセットは定期的に更新されます。
訓練は、モデルの誤差が特定のレベルで安定するまで続けられます。その時点で、データセットの更新はActorのポリシー最適化には寄与しなくなります。
訓練済みモデルの有効性は、MetaTrader 5のストラテジーテスターを使用して、2024年1月からの履歴データを適用し評価します。その他のパラメータは変更せず、以下にテスト結果を示します。訓練されたモデルのテストの結果を以下に示します。
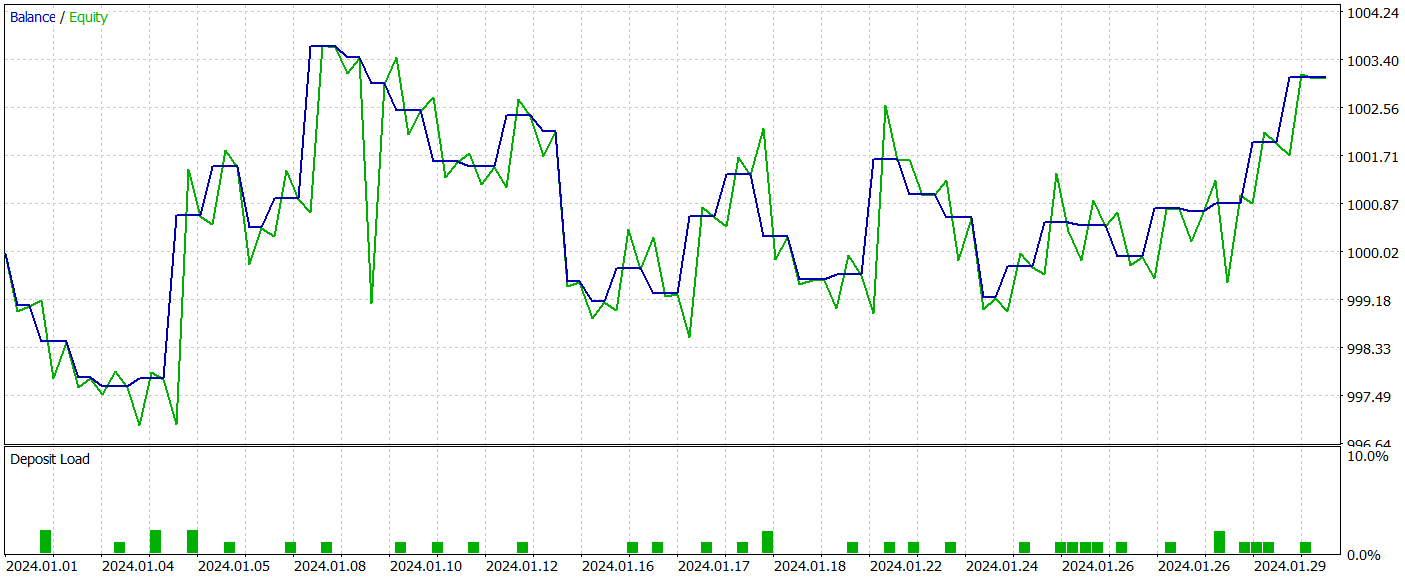
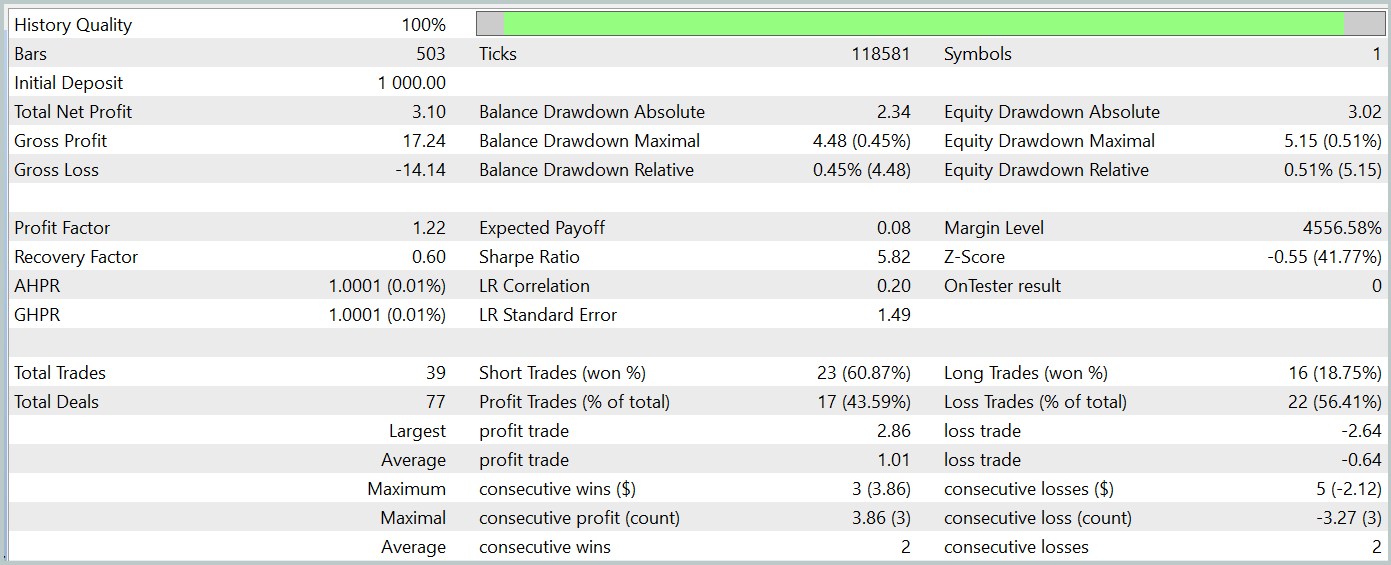
結果が示すように、訓練プロセスによって、訓練データおよびテストデータの両方で利益を生み出すActor方策が正常に構築されました。テスト期間中、モデルは39回の取引をおこない、そのうち43%以上が利益で終了しました。利益の出た取引の割合は損失を出した取引よりもわずかに低かったものの、1回あたりの平均利益および最大利益が損失額を上回ったため、モデルは最終的にわずかな純利益を達成しました。プロフィットファクターは1.22でした。
ただし、観測された残高ラインに明確なトレンドが見られず、取引回数も限られていることから、得られた結果が必ずしも代表的とは言えない点には注意が必要です。
結論
本記事では、MQL5を用いてHiVT法の実装に成功しました。提案手法を環境状態エンコーダモデルに統合し、訓練とテストを実施しました。テストの結果、HiVT法は市場のトレンドを効果的に捉え、エージェントにとって収益性の高い取引ポリシーの構築を支援するのに十分な予測精度を備えていることが確認されました。
参照文献
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15713
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索