
取引におけるニューラルネットワーク:複雑な軌道予測法(Traj-LLM)

はじめに
金融市場における将来の価格変動の予測は、トレーダーの意思決定プロセスにおいて極めて重要な役割を果たします。高精度な予測が可能になれば、トレーダーはより多くの情報に基づいて判断を下し、リスクを最小限に抑えることができます。しかし、市場は本質的に混沌としており確率的な要素が強いため、価格の将来の推移を予測することには多くの課題が伴います。最先端の予測モデルであっても、参加者の行動の急激な変化や予期しない外部要因など、市場の動向に影響を与えるすべての要素を完全に捉えることは困難です。
近年、特に大規模言語モデル(LLM)の分野における人工知能の進展により、さまざまな複雑な課題を解決するための新たなアプローチが生まれています。LLMは、複雑な情報を処理し、人間の推論に近い形でシナリオを構築する卓越した能力を示しています。これらのモデルは、自然言語処理から時系列予測まで幅広い分野で活用されており、市場の動向を分析・予測するための有望なツールとなっています。
本稿では、Traj-LLMアルゴリズム(論文「Traj-LLM:A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models」で発表)を紹介します。Traj-LLMは、自動運転車の軌道予測に関する課題を解決するために開発されたものであり、著者はLLMを活用することで、交通参加者の将来の軌道予測の精度と適応性を向上させることを提案しています。
さらに、Traj-LLMは、大規模言語モデルの強力な処理能力と、時間的依存関係やオブジェクト間の相互作用をモデル化する革新的なアプローチを組み合わせることで、複雑かつ動的な環境下でもより正確な軌道予測を実現します。本モデルは、予測の精度を向上させるだけでなく、将来の潜在的なシナリオを分析し理解するための新たな手法も提供します。著者が提案する手法を活用することで、私たちの課題への適用が期待され、将来の価格変動予測の精度向上に寄与すると考えています。
1.Traj-LLMアルゴリズム
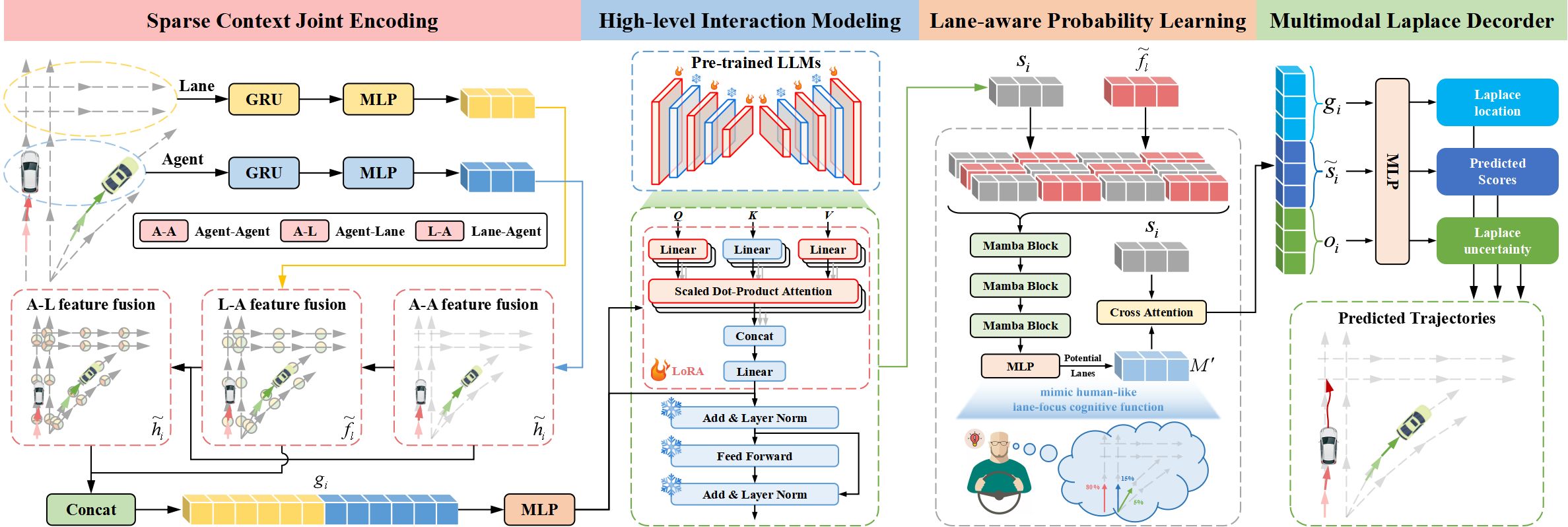
Traj-LLMアーキテクチャは、次の4つの重要なコンポーネントで構成されています。
- スパースコンテキスト統合エンコーディング
- 高次インタラクションモデリング
- 車線認識型確率学習
- ラプラスマルチモーダルデコーダー
Traj-LLMの著者は、明示的なリアルタイムの特徴量エンジニアリングを不要にし、軌道予測にLLMの能力を活用することを提案しています。まず、スパースコンテキスト統合エンコーディングにより、エージェントやシーンの特徴をLLMが解釈可能な形式へと変換します。その後、これらの表現を事前学習済みのLLMに入力し、高次インタラクションモデリングを処理します。さらに、Traj-LLMにおけるシーン理解を強化し、人間の認知機能に近づけるため、Mambaモジュールを用いた車線認識型確率学習を導入しています。最終的に、ラプラスマルチモーダルデコーダを用いることで、信頼性の高い予測を生成します。
Traj-LLMの最初のステップは、エージェントの状態や車線情報など、シーンの時空間データをエンコードすることです。それぞれのデータに対し、再帰層とMLPで構成された埋め込みモデルを適用し、多次元の特徴を抽出します。得られたテンソルhiおよびfサブモジュールにlはFusionサブモジュールに渡され、局所領域におけるエージェントの状態と車線間の複雑な情報交換を促進します。このプロセスでは、LLMアーキテクチャに適合させるため、トークン埋め込みメカニズムを採用しています。
具体的には、融合プロセスでは、マルチヘッド自己アテンション(Self-Attention)機構を使用して、エージェント同士(Agent-Agent)の特徴量を結合します。さらに、エージェントと車線の特徴量(Agent-LaneとLane-Agent)の統合には、スキップ接続を備えたマルチヘッドクロスアテンション機構を用い、エージェントビューおよび車線ビューの更新をおこないます。このプロセスは、以下のように表すことができます。

その後、hiとflが結合され、スパースコンテキスト統合エンコーディングgiが形成されます。これにより、ベクトル化されたエンティティの局所受容野に関連する依存関係を直感的に捉えることが可能になります。このエンコーディング手法は、LLMが軌道データをより効果的に解釈できるよう設計されており、LLMの機能を拡張する役割を果たします。
軌道の遷移は、シーン内のさまざまな要素から派生する高次の制約によって制御されるパターンに従います。これらの相互作用を解析するため、著者らは軌道予測タスクに内在する依存関係をモデル化するLLMの能力を調査しました。軌道データと自然言語テキストには類似点がありますが、事前訓練済みのLLMをそのまま適用してスパースコンテキスト統合エンコーディングを処理するのは非効率的だと考えられます。なぜなら、事前訓練済みのLLMは主にテキストデータ向けに最適化されているためです。この課題に対する一つの選択肢として、LLM全体を包括的に再訓練することが考えられます。しかし、この方法には膨大な計算リソースが必要となるため、現実的ではありません。より実用的な解決策として、パラメータ効率の高い微調整手法(PEFT: Parameter-Efficient Fine-Tuning)を用いた事前訓練済みLLMのファインチューニングが提案されています。
Traj-LLMの著者は、高次インタラクションモデリングのために、事前訓練済みのNLP Transformerアーキテクチャ(特にGPT-2)のパラメータを活用しています。彼らは、事前訓練済みの全パラメータを固定した上で、新たに訓練可能なパラメータを導入するため、低ランク適応技術(LoRA: Low-Rank Adaptation)を適用する手法を提案しています。LoRAは、LLMアテンション機構におけるQueryおよびKeyエンティティに適用されます。
この結果、スパースコンテキスト統合エンコーディングgiは、LoRAによって拡張された一連の事前訓練済みTransformerブロックから構成されるLLMに入力されます。この処理により、高次の相互作用表現ziが得られます。
![]()
事前訓練済みのLLMの出力は、giの次元に適合するようMLPを介して変換され、最終的な高次の相互作用状態siが生成されます。
経験豊富なドライバーは、将来の行動に大きく影響を与える限られた数の車線セグメントに注目します。この人間のような認知機能を再現し、Traj-LLMのシーン理解をさらに向上させるため、著者らは車線認識確率学習を導入し、動作状態と車線セグメントの整合性を継続的に評価する手法を採用しました。モデルは、Mamba層を用いて、各タイムステップt∈{1,…,tf}でターゲットエージェントの軌道を車線情報に適応させます。Mambaは選択的構造化状態空間モデル(SSM)として機能し、関連情報を精錬・一般化します。これは、人間のドライバーが潜在的な走行車線などの重要な環境要因を選択的に処理し、意思決定をおこなう方法に類似しています。
提案されたアーキテクチャでは、Mamba層には、Mambaブロック、3層正規化、および位置ごとのフィードフォワードネットワークが含まれます。まず、Mambaブロックは線形投影を通じて次元を拡張し、2つの並列データフローに対する異なる表現を生成します。一方のブランチは畳み込み層およびSiLU活性化関数を適用し、車線認識に関する依存関係を捉える役割を担います。Mambaブロックの中核には、入力データに基づく離散化パラメータを持つ選択的状態空間モデルが組み込まれています。さらに、安定性向上のためにインスタンス正規化と残差接続を導入し、より堅牢な潜在表現を生成します。
その後、位置ごとのフィードフォワードネットワークにより、隠れ層における車線認識の精度が強化されます。ここでもインスタンス正規化と残差接続を適用し、最終的に車線認識訓練ベクトルを生成し、MLP層に入力します。
先述の通り、経験豊富なドライバーは、意思決定のために重要な車線セグメントに焦点を当てます。したがって、モデルは最も有力な候補車線を慎重に選定し、それらを集合ℳに統合します。
この車線認識確率学習は、分類タスクとしてモデル化され、バイナリクロスエントロピー損失ℒlaneを最適化することで確率推定の精度を向上させます。
以下にTraj-LLM法の著者による視覚化を示します。
2.MQL5での実装
Traj-LLM法の理論的側面を検討した後、記事の実践的な部分に進み、MQL5を使用して提案されたアプローチのビジョンを実装します。Traj-LLMアルゴリズムは、複数のアーキテクチャコンポーネントを統合する複雑なフレームワークであり、その一部は以前の研究ですでに取り上げられています。したがって、アルゴリズムを構築するときに既存のモジュールを利用することができます。ただし、追加の変更が必要になります。
2.1LSTMブロックアルゴリズムの調整
上で示したTraj-LLMメソッドの視覚化を見てみましょう。生の入力データは、まず、再帰層とMLPで構成されるスパースコンテキスト結合エンコーディングブロックを通過します。私たちのライブラリにはすでに再帰層CNeuronLSTMOCLが含まれていますが、入力データは単一の統合された環境状態表現として処理されます。対照的に、この手法の著者は、個々のエージェントと車線の状態を独立してエンコードすることを提案しています。したがって、各データチャネルごとに独立したエンコーディングを構成する必要があります。各チャネルごとに個別のCNeuronLSTMOCLオブジェクトをインスタンス化することもできるでしょうが、これにより、内部オブジェクトと順次処理が制御不能に増加し、モデルのパフォーマンスに悪影響が及ぶことになります。
2番目の解決策は、既存のCNeuronLSTMOCL再帰層クラスを変更することです。これにはOpenCLプログラム側での変更が必要です。再帰層のフィードフォワードパスは、LSTM_FeedForwardカーネルに実装されています。単変量シーケンス内で操作を実装するために、カーネルの外部パラメータを変更しません。個々の一変量シーケンスのデータの並列処理を整理するために、タスク空間にもう1つの次元を追加します。
__kernel void LSTM_FeedForward(__global const float *inputs, int inputs_size, __global const float *weights, __global float *concatenated, __global float *memory, __global float *output) { uint id = (uint)get_global_id(0); uint total = (uint)get_global_size(0); uint id2 = (uint)get_local_id(1); uint idv = (uint)get_global_id(2); uint total_v = (uint)get_global_size(2);
LSTMブロックの動作は4つのエンティティに基づいており、その値は内部層によって計算されることを思い出してください。
- 忘却ゲート:無関係な情報を破棄する役割を担う
- 入力ゲート:新しい情報を組み込む役割を担う
- 出力ゲート:出力信号を生成する役割を担う
- 新しいコンテンツ:セルの状態を更新するための候補値を表す
これらのエンティティを計算するアルゴリズムは統一されており、完全に接続された層の構造に従います。唯一の違いは、各段階で適用される活性化関数にあります。したがって、実装では、これらのエンティティの計算がワークグループ内の並列スレッドで処理されるように設計しました。スレッド間のデータ交換を可能にするために、ローカルメモリに割り当てられた配列を使用します。
__local float Temp[4];
次に、グローバルデータバッファ内のシフト定数を定義します。
float sum = 0; uint shift_in = idv * inputs_size; uint shift_out = idv * total; uint shift = (inputs_size + total + 1) * (id2 + id);
以下の点にご注意ください。独立したチャネルを持つ再帰ブロックの動作プロセスを実装します。ただし、Traj-LLMアルゴリズムの構築ロジックによれば、さまざまなエージェントの状態に関する情報であろうと、既存の交通車線に関する情報であろうと、すべての独立した情報チャネルには比較可能なデータが含まれます。したがって、異なるデータチャネルからの情報をエンコードするために1つの重み行列を使用するのは非常に論理的であり、これにより出力で比較可能な埋め込みを取得できるようになります。
したがって、チャネル識別子はソースバッファと結果バッファのオフセットに影響します。しかし、重み行列のシフトには影響しません。
次に、隠し状態の加重合計を計算するループを作成します。
for(uint i = 0; i < total; i += 4) { if(total - i > 4) sum += dot((float4)(output[shift_out + i], output[shift_out + i + 1], output[shift_out + i + 2], output[shift_out + i + 3]), (float4)(weights[shift + i], weights[shift + i + 1], weights[shift + i + 2], weights[shift + i + 3])); else for(uint k = i; k < total; k++) sum += output[shift_out + k] * weights[shift + k]; }
そして、入力データの影響を加えます。
shift += total; for(uint i = 0; i < inputs_size; i += 4) { if(total - i > 4) sum += dot((float4)(inputs[shift_in + i], inputs[shift_in + i + 1], inputs[shift_in + i + 2], inputs[shift_in + i + 3]), (float4)(weights[shift + i], weights[shift + i + 1], weights[shift + i + 2], weights[shift + i + 3])); else for(uint k = i; k < total; k++) sum += inputs[shift_in + k] * weights[shift + k]; } sum += weights[shift + inputs_size];
得られた値に対応する活性化関数を適用します。
if(isnan(sum) || isinf(sum)) sum = 0; if(id2 < 3) sum = Activation(sum, 1); else sum = Activation(sum, 0);
その後、操作の結果を保存し、ワークグループスレッドを同期します。
Temp[id2] = sum; concatenated[4 * shift_out + id2 * total + id] = sum; //--- barrier(CLK_LOCAL_MEM_FENCE);
ここで、特定のセルの隠し状態であるLSTMブロックの作業の結果を計算する必要があります。
if(id2 == 0) { float mem = memory[shift_out + id + total_v * total] = memory[shift_out + id]; float fg = Temp[0]; float ig = Temp[1]; float og = Temp[2]; float nc = Temp[3]; //--- memory[shift_out + id] = mem = mem * fg + ig * nc; output[shift_out + id] = og * Activation(mem, 0); } }
操作の結果は、グローバルデータバッファの対応する要素に保存されます。
バックプロパゲーションパスカーネルにも同様の編集を加えました。それらの中で最も重要なものは、LSTM_HiddenGradientカーネルにありました。フィードフォワードカーネルと同様に、外部パラメータの構成は変更せず、タスク空間のみを調整します。
__kernel void LSTM_HiddenGradient(__global float *concatenated_gradient, __global float *inputs_gradient, __global float *weights_gradient, __global float *hidden_state, __global float *inputs, __global float *weights, __global float *output, const int hidden_size, const int inputs_size) { uint id = get_global_id(0); uint total = get_global_size(0); uint idv = (uint)get_global_id(1); uint total_v = (uint)get_global_size(1);
すべての独立したチャネルは1つの重みマトリックスで動作します。したがって、重み係数については、すべての独立したチャネルから誤差勾配を収集する必要があります。各データチャネルは独自のスレッドで動作し、これらをワーキンググループに統合します。スレッド間でデータを交換するには、ローカルメモリ内の配列を使用します。
__local float Temp[LOCAL_ARRAY_SIZE]; uint ls = min(total_v, (uint)LOCAL_ARRAY_SIZE);
次に、データバッファのオフセットを定義します。
uint shift_in = idv * inputs_size; uint shift_out = idv * total; uint weights_step = hidden_size + inputs_size + 1;
入力データの連結バッファに対してループを作成します。まず、隠し状態を更新します。
for(int i = id; i < (hidden_size + inputs_size); i += total) { float inp = 0; if(i < hidden_size) { inp = hidden_state[shift_out + i]; hidden_state[shift_out + i] = output[shift_out + i]; }
そして、入力レベルでの誤差勾配を決定します。
else { inp = inputs[shift_in + i - hidden_size]; float grad = 0; for(uint g = 0; g < 3 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; grad += temp * (1 - temp) * weights[i + g * weights_step]; } for(uint g = 3 * hidden_size; g < 4 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; grad += temp * (1 - pow(temp, 2.0f)) * weights[i + g * weights_step]; } inputs_gradient[shift_in + i - hidden_size] = grad; }
ここでは、重みレベルでの誤差勾配も計算します。まず、ローカル配列の値をリセットします。
for(uint g = 0; g < 3 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; if(idv < ls) Temp[idv % ls] = 0; barrier(CLK_LOCAL_MEM_FENCE);
ワークグループスレッドの作業を必ず同期してください。
次に、すべてのデータチャネルから合計誤差勾配を収集します。最初のステップでは、個々の値をローカル配列に保存します。
for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += temp * (1 - temp) * inp; barrier(CLK_LOCAL_MEM_FENCE); }
分析されたデータには、独立したチャネルが比較的少数存在すると想定されます。したがって、配列値の合計を1つのスレッドで収集し、結果の値をグローバルデータバッファに保存します。
if(idv == 0) { temp = Temp[0]; for(int v = 1; v < ls; v++) temp += Temp[v]; weights_gradient[i + g * weights_step] = temp; } barrier(CLK_LOCAL_MEM_FENCE); }
同様に、新しいコンテンツの重みの誤差勾配を収集します。
for(uint g = 3 * hidden_size; g < 4 * hidden_size; g++) { float temp = concatenated_gradient[4 * shift_out + g]; if(idv < ls) Temp[idv % ls] = 0; barrier(CLK_LOCAL_MEM_FENCE); for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += temp * (1 - pow(temp, 2.0f)) * inp; barrier(CLK_LOCAL_MEM_FENCE); } if(idv == 0) { temp = Temp[0]; for(int v = 1; v < ls; v++) temp += Temp[v]; weights_gradient[i + g * weights_step] = temp; } barrier(CLK_LOCAL_MEM_FENCE); } }
ここで、メインループ操作の実行中に、ベイジアンバイアス重み付け係数が失われていることに注意してください。対応する誤差勾配を計算するために、上記のスキームに従って追加の操作を実装します。
for(int i = id; i < 4 * hidden_size; i += total) { if(idv < ls) Temp[idv % ls] = 0; barrier(CLK_LOCAL_MEM_FENCE); float temp = concatenated_gradient[4 * shift_out + (i + 1) * hidden_size]; if(i < 3 * hidden_size) { for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += temp * (1 - temp); barrier(CLK_LOCAL_MEM_FENCE); } } else { for(uint v = 0; v < total_v; v += ls) { if(idv >= v && idv < v + ls) Temp[idv % ls] += 1 - pow(temp, 2.0f); barrier(CLK_LOCAL_MEM_FENCE); } } if(idv == 0) { temp = Temp[0]; for(int v = 1; v < ls; v++) temp += Temp[v]; weights_gradient[(i + 1) * weights_step] = temp; } barrier(CLK_LOCAL_MEM_FENCE); } }
スレッド同期ポイントには特別な注意を払う必要があります。アルゴリズムが正しく機能することを保証するために、その数は最低限十分でなければなりません。同期ポイントが多すぎるとパフォーマンスが低下し、操作が遅くなります。さらに、不適切に配置された同期ポイントでは、すべてのスレッドが到達できず、プログラムが応答しなくなる可能性があります。
これで、独立したデータチャネルでLSTMブロック操作を整理するために必要なOpenCLコード調整のレビューは終了です。メインプログラム側の特定の編集については、個別に検討することをお勧めします。更新されたCNeuronLSTMOCLクラスとそのすべてのメソッドの完全なコードは添付ファイルに提供されています。
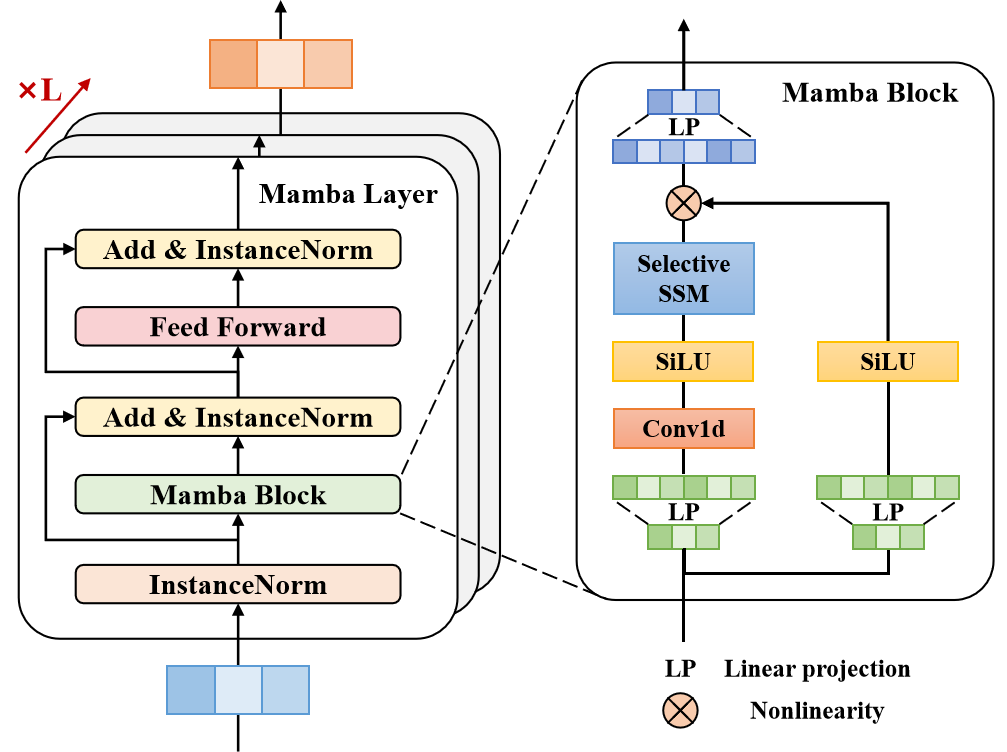
2.2 Mambaブロックの構築
準備作業の次のステップは、Mambaブロックの構築です。このブロックの名前は、前回の記事で説明した方法を意図的に連想させるものです。Traj-LLMの著者は、状態空間モデル(SSM)の使用を拡張し、Transformerエンコーダーと比較できるブロックアーキテクチャを提案しています。しかし、この場合、自己アテンションはMambaアーキテクチャに置き換えられます。
提案されたアルゴリズムを実装するために、新しいクラスCNeuronMambaBlockOCLを作成します。その構造を以下に示します。
class CNeuronMambaBlockOCL : public CNeuronBaseOCL { protected: uint iWindow; CNeuronMambaOCL cMamba; CNeuronBaseOCL cMambaResidual; CNeuronConvOCL cFF[2]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronMambaBlockOCL(void) {}; ~CNeuronMambaBlockOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMambaBlockOCL; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
コア機能は、基本完全接続層クラスCNeuronBaseOCLから継承されます。使い慣れた仮想メソッドのリストをオーバーライドします。
新しいクラスの構造内で、内部オブジェクトを強調表示できます。メソッドの実装を進めながら、その機能を段階的に調べていきます。すべてのオブジェクトは静的に宣言されます。これにより、クラスのコンストラクタとデストラクタを空のままにすることができます。すべての内部オブジェクトと変数の初期化は、Initメソッド内で処理されます。
前述したように、Mambaブロックは、そのアーキテクチャ上、Transformerエンコーダーに似ています。この類似性は、ブロックの内部アーキテクチャの明確で構造化された定義を提供する初期化メソッドのパラメータにも明らかです。
bool CNeuronMambaBlockOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッドの本体内で、親クラスから同じ名前のメソッドを呼び出します。このメソッドには、パラメータの検証とすべての継承オブジェクトの初期化に必要な最小限のブロックが既に含まれています。
親クラスの初期化メソッドが正常に実行されると、データ分析ウィンドウのサイズがローカル変数に保存され、後で使用できるようになります。
iWindow = window;
次に内部オブジェクトの初期化に移ります。まず、Mamba状態空間層を初期化します。
if(!cMamba.Init(0, 0, OpenCL, window, window_key, units_count, optimization, iBatch)) return false;
この後には完全に接続された層が続き、そのバッファは残差接続による選択的状態空間解析の正規化された結果を格納するために使用します。
if(!cMambaResidual.Init(0, 1, OpenCL, window * units_count, optimization, iBatch)) return false; cMambaResidual.SetActivationFunction(None);
その後、FeedForwardブロックを追加します。
if(!cFF[0].Init(0, 2, OpenCL, window, window, 4 * window, units_count, 1, optimization, iBatch)) return false; cFF[0].SetActivationFunction(LReLU); if(!cFF[1].Init(0, 2, OpenCL, 4 * window, 4 * window, window, units_count, 1, optimization, iBatch)) return false; cFF[1].SetActivationFunction(None);
次に、不要なコピー操作を排除するために、データバッファへのポインタの置換を整理します。
SetActivationFunction(None); SetGradient(cFF[1].getGradient(), true); //--- return true; }
ここでは、誤差勾配バッファへのポインタのみを置き換えていることに注意してください。これは、フィードフォワードパス中に、結果を層出力に転送する前に、追加の残差接続と取得された結果の正規化が整理されるためです。
各ステップで操作の結果を監視することを忘れないでください。メソッドの最後に、実行された操作の論理結果を呼び出し元プログラムに返します。
クラスオブジェクトを初期化した後、feedForwardメソッドで実装されるフィードフォワードパスアルゴリズムの構築に進みます。それは非常に簡単です。
bool CNeuronMambaBlockOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cMamba.FeedForward(NeuronOCL)) return false;
メソッドパラメータでは、入力データを渡してくれる前の層のオブジェクトへのポインタを受け取ります。そして、メソッドの本体では、受信したポインタをすぐに状態空間の選択モデルに渡します。
内層の直接パス方式の操作が正常に完了したら、得られた結果と元のデータを合計し、値を正規化します。
if(!SumAndNormilize(cMamba.getOutput(), NeuronOCL.getOutput(), cMambaResidual.getOutput(), iWindow, true)) return false;
次はFeedForwardブロックです。
if(!cFF[0].FeedForward(cMambaResidual.AsObject())) return false; if(!cFF[1].FeedForward(cFF[0].AsObject())) return false;
その後のデータ正規化によって残差接続を整理します。
if(!SumAndNormilize(cMambaResidual.getOutput(), cFF[1].getOutput(), getOutput(), iWindow, true)) return false; //--- return true; }
バックプロパゲーションメソッドもアルゴリズムが非常に単純なので、独自の研究のために残しておくことをお勧めします。添付ファイルに、このクラスの完全なコードとそのすべてのメソッドが記載されていることをお知らせします。
これで準備作業は完了し、Traj-LLM法の一般的なアルゴリズムの構築に進みます。
2.3個々のブロックを一貫したアルゴリズムに組み立てる
上記では準備作業を完了し、CNeuronTrajLLMOCLクラス内でTraj-LLMアルゴリズムを構築するために使用する、不足している「ビルディングブロック」をライブラリに追加しました。以下に新しいクラスの構造を示します。
class CNeuronTrajLLMOCL : public CNeuronBaseOCL { protected: //--- State Encoder CNeuronLSTMOCL cStateRNN; CNeuronConvOCL cStateMLP[2]; //--- Variables Encoder CNeuronTransposeOCL cTranspose; CNeuronLSTMOCL cVariablesRNN; CNeuronConvOCL cVariablesMLP[2]; //--- Context Encoder CNeuronLearnabledPE cStatePE; CNeuronLearnabledPE cVariablesPE; CNeuronMLMHAttentionMLKV cStateToState; CNeuronMLCrossAttentionMLKV cVariableToState; CNeuronMLCrossAttentionMLKV cStateToVariable; CNeuronBaseOCL cContext; CNeuronConvOCL cContextMLP[2]; //--- CNeuronMLMHAttentionMLKV cHighLevelInteraction; CNeuronMambaBlockOCL caMamba[3]; CNeuronMLCrossAttentionMLKV cLaneAware; CNeuronConvOCL caForecastMLP[2]; CNeuronTransposeOCL cTransposeOut; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; //--- virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; //--- public: CNeuronTrajLLMOCL(void) {}; ~CNeuronTrajLLMOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronTrajLLMOCL; } //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
ご覧のとおり、クラス構造では同じ仮想メソッドをオーバーライドしています。ただし、このクラスは、内部オブジェクトの数が非常に多いという特徴があり、これはこのような複雑なアーキテクチャでは当然のことです。これらの宣言されたオブジェクトの目的は、クラスメソッドの実装を進めていくと明らかになります。
クラスの内部オブジェクトはすべてstaticとして宣言されています。その結果、コンストラクタとデストラクタは空のままになります。宣言されたすべてのオブジェクトの初期化はInitメソッドで実行されます。
メソッドパラメータでは、ネストされたオブジェクトを初期化するために使用される主要な定数を受け取ります。ここでは、すでによく知られているパラメータの名前が表示されます。ただし、個々の内部オブジェクトに対して異なる機能を実行する場合があることに注意してください。
bool CNeuronTrajLLMOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint forecast, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * forecast, optimization_type, batch)) return false;
すでに確立された伝統に従って、Initメソッド内の最初のステップは、同じ名前の親クラスメソッドを呼び出すことです。ご存知のとおり、このメソッドは、継承されたすべてのオブジェクトの基本的なパラメータ検証と初期化をすでに実行しています。親クラスメソッドが正常に実行されたら、宣言された内部オブジェクトの初期化に進みます。
以前のモデルの構築から得られた経験に基づいて、モデルへの入力は現在の市場状況を説明する行列であると想定します。この行列の各行には、分析された指標の対応する値を含む、個々の市場ローソク足を特徴付ける一連のパラメータが含まれています。
Traj-LLMアルゴリズムによれば、取得された入力データはまず、エージェントエンコーダーと車線エンコーダーを含むSparseContextEncoderブロックに渡されます。私たちの場合、これらは環境状態(個々のバーデータ)のエンコーダーと分析されたパラメータの履歴軌跡(インジケーター)に対応します。
状態エンコーダーは、個々のバーを分析するための再帰ブロックと、独立した情報チャネル内でMLP操作を実装する2つの後続の畳み込み層から構築されます。
//--- State Encoder if(!cStateRNN.Init(0, 0, OpenCL, window_key, units_count, optimization, iBatch) || !cStateRNN.SetInputs(window)) return false; if(!cStateMLP[0].Init(0, 1, OpenCL, window_key, window_key, 4 * window_key, units_count, optimization, iBatch)) return false; cStateMLP[0].SetActivationFunction(LReLU); if(!cStateMLP[1].Init(0, 2, OpenCL, 4 * window_key, 4 * window_key, window_key, units_count, optimization, iBatch)) return false;
メソッドパラメータには、埋め込みオブジェクトの初期化に使用される主な定数が含まれます。ここでは、よく知られたパラメータ名が表示されていますが、一部のパラメータは特定の内部オブジェクトに対して異なる機能を果たす場合があることに注意することが重要です。
//--- Variables Encoder if(!cTranspose.Init(0, 3, OpenCL, units_count, window, optimization, iBatch)) return false; if(!cVariablesRNN.Init(0, 4, OpenCL, window_key, window, optimization, iBatch) || !cVariablesRNN.SetInputs(units_count)) return false; if(!cVariablesMLP[0].Init(0, 5, OpenCL, window_key, window_key, 4 * window_key, window, optimization, iBatch)) return false; cVariablesMLP[0].SetActivationFunction(LReLU); if(!cVariablesMLP[1].Init(0, 6, OpenCL, 4 * window_key, 4 * window_key, window_key, window, optimization, iBatch)) return false;
Traj-LLMアルゴリズムによれば、その後エージェントと車線の共同分析が実行されることに注意することが重要です。したがって、エンコーダーの出力は、同一次元のシーケンス(環境状態または分析された指標の履歴軌跡)の個々の要素を表すベクトルを生成します。同時に、分析された環境状態の数は、それらの状態を記述する分析されたパラメータの数と一致しないことが多いため、シーケンスの長さの違いが許容されます。
Traj-LLMアルゴリズムの次のステップでは、エンコーダーの出力がFusionブロックに渡され、そこで自己アテンションおよびクロスアテンション機構を使用して、個々のシーケンス要素間の相互依存性の包括的な分析が実行されます。しかし、アテンション機構の効率を向上させるには、シーケンス要素に位置エンコーディングタグを追加する必要があることはよく知られています。この機能を実現するために、訓練可能な位置エンコーディング層を2つ導入します。
//--- Position Encoder if(!cStatePE.Init(0, 7, OpenCL, cStateMLP[1].Neurons(), optimization, iBatch)) return false; if(!cVariablesPE.Init(0, 8, OpenCL, cVariablesMLP[1].Neurons(), optimization, iBatch)) return false;
そして、その後に初めて、自己アテンションブロック内の個々の状態間の依存関係を分析します。
//--- Context if(!cStateToState.Init(0, 9, OpenCL, window_key, window_key, heads, heads / 2, units_count, 2, 1, optimization, iBatch)) return false;
次に、次の2つのクロスアテンションブロックで相互依存性分析を実行します。
if(!cStateToVariable.Init(0, 10, OpenCL, window_key, window_key, heads, window_key, heads / 2, units_count, window, 2, 1, optimization, iBatch)) return false; if(!cVariableToState.Init(0, 11, OpenCL, window_key, window_key, heads, window_key, heads / 2, window, units_count, 2, 1, optimization, iBatch)) return false;
状態と軌跡の強化された表現は、単一のテンソルに連結されます。
if(!cContext.Init(0, 12, OpenCL, window_key * (units_count + window), optimization, iBatch)) return false;
その後、データは別のMLPを通過します。
if(!cContextMLP[0].Init(0, 13, OpenCL, window_key, window_key, 4 * window_key, window + units_count, optimization, iBatch)) return false; cContextMLP[0].SetActivationFunction(LReLU); if(!cContextMLP[1].Init(0, 14, OpenCL, 4 * window_key, 4 * window_key, window_key, window + units_count, optimization, iBatch)) return false;
次は、高レベルのインタラクションモデリングブロックです。ここではTraj-LLMメソッドの著者が事前訓練済みの言語モデルを使用しており、これをTransformerブロックに置き換えます。
if(!cHighLevelInteraction.Init(0, 15, OpenCL, window_key, window_key, heads, heads / 2, window + units_count, 4, 2, optimization, iBatch)) return false;
次に、既存の交通車線を考慮して、その後の動きの確率を学習するという認知ブロックが続きます。ここでは、同じアーキテクチャを持つ3つの連続したMambaブロックを使用します。
for(int i = 0; i < int(caMamba.Size()); i++) { if(!caMamba[i].Init(0, 16 + i, OpenCL, window_key, 2 * window_key, window + units_count, optimization, iBatch)) return false; }
得られた値は、クロスアテンションブロック内の過去の軌跡と比較されます。
if(!cLaneAware.Init(0, 19, OpenCL, window_key, window_key, heads, window_key, heads / 2, window, window + units_count, 2, 1, optimization, iBatch)) return false;
そして最後に、MLPを使用して、独立したデータチャネルの後続の軌跡を予測します。
if(!caForecastMLP[0].Init(0, 20, OpenCL, window_key, window_key, 4 * forecast, window, optimization, iBatch)) return false; caForecastMLP[0].SetActivationFunction(LReLU); if(!caForecastMLP[1].Init(0, 21, OpenCL, 4 * forecast, 4 * forecast, forecast, window, optimization, iBatch)) return false; caForecastMLP[1].SetActivationFunction(TANH); if(!cTransposeOut.Init(0, 22, OpenCL, window, forecast, optimization, iBatch)) return false;
予測された軌道テンソルは転置され、情報が元のデータの表現に取り込まれることに注意してください。
SetOutput(cTransposeOut.getOutput(), true); SetGradient(cTransposeOut.getGradient(), true); SetActivationFunction((ENUM_ACTIVATION)caForecastMLP[1].Activation()); //--- return true; }
不要なコピー操作を回避するために、データバッファポインタの置換も使用します。その後、メソッド操作の論理結果を呼び出し元プログラムに返します。
クラス初期化メソッドの作業が完了したら、フィードフォワードパスアルゴリズムの構築に移り、これをfeedForwardメソッドで実装します。
bool CNeuronTrajLLMOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- State Encoder if(!cStateRNN.FeedForward(NeuronOCL)) return false; if(!cStateMLP[0].FeedForward(cStateRNN.AsObject())) return false; if(!cStateMLP[1].FeedForward(cStateMLP[0].AsObject())) return false;
メソッドパラメータでは、初期データを含むオブジェクトへのポインタを受け取り、それをすぐに状態エンコーダブロックに渡します。
次に、元のデータを転置し、環境の状態を記述する分析されたパラメータの履歴軌跡をエンコードします。
//--- Variables Encoder if(!cTranspose.FeedForward(NeuronOCL)) return false; if(!cVariablesRNN.FeedForward(cTranspose.AsObject())) return false; if(!cVariablesMLP[0].FeedForward(cVariablesRNN.AsObject())) return false; if(!cVariablesMLP[1].FeedForward(cVariablesMLP[0].AsObject())) return false;
取得したデータに位置エンコーディングを追加します。
//--- Position Encoder if(!cStatePE.FeedForward(cStateMLP[1].AsObject())) return false; if(!cVariablesPE.FeedForward(cVariablesMLP[1].AsObject())) return false;
その後、相互依存性のコンテキストでデータを充実させます。
//--- Context if(!cStateToState.FeedForward(cStatePE.AsObject())) return false; if(!cStateToVariable.FeedForward(cStateToState.AsObject(), cVariablesPE.getOutput())) return false; if(!cVariableToState.FeedForward(cVariablesPE.AsObject(), cStateToVariable.getOutput())) return false;
強化されたデータは単一のテンソルに連結されます。
if(!Concat(cStateToVariable.getOutput(), cVariableToState.getOutput(), cContext.getOutput(), cStateToVariable.Neurons(), cVariableToState.Neurons(), 1)) return false;
そして、それはMLPによって処理されます。
if(!cContextMLP[0].FeedForward(cContext.AsObject())) return false; if(!cContextMLP[1].FeedForward(cContextMLP[0].AsObject())) return false;
次は、高次依存関係分析のブロックです。
//--- Lane aware if(!cHighLevelInteraction.FeedForward(cContextMLP[1].AsObject())) return false;
そして状態空間モデルです。
if(!caMamba[0].FeedForward(cHighLevelInteraction.AsObject())) return false; for(int i = 1; i < int(caMamba.Size()); i++) { if(!caMamba[i].FeedForward(caMamba[i - 1].AsObject())) return false; }
次に、過去の軌跡と分析結果を比較します。
if(!cLaneAware.FeedForward(cVariablesPE.AsObject(), caMamba[caMamba.Size() - 1].getOutput())) return false;
そして、得られたデータに基づいて、分析されたパラメータに今後起こる可能性が最も高い変化を予測します。
//--- Forecast if(!caForecastMLP[0].FeedForward(cLaneAware.AsObject())) return false; if(!caForecastMLP[1].FeedForward(caForecastMLP[0].AsObject())) return false;
その後、予測値を入力データ表現に転置します。
if(!cTransposeOut.FeedForward(caForecastMLP[1].AsObject())) return false; //--- return true; }
最後に、メソッドは、実行された操作の成功または失敗を示すブール値を呼び出し元プログラムに返します。
私たちの仕事の次の段階は、バックプロパゲーションアルゴリズムの構築です。ここでは、最終出力への影響に応じてすべてのオブジェクトにわたって誤差勾配を分散し、その後誤差を最小限に抑えることを目的とした訓練可能なパラメータを調整する必要があります。
パラメータの更新は比較的簡単ですが(すべての訓練可能なパラメータは内部(ネストされた)オブジェクト内に含まれているため、これらの内部オブジェクトのパラメータ更新メソッドを順番に呼び出すだけで十分です)、誤差勾配を分散することは、はるかに複雑で入り組んだ課題となります。
誤差勾配の分配は、フィードフォワードパスのアルゴリズムに完全に従って、逆の順序で実行されます。ここで、言葉遊びを許して頂ければ、フィードフォワードパスはそれほど「フォワード」ではないことに注意する必要があります。フォワードパスでは、複数の並列情報ストリームを識別できます。そして、これらすべてのストリームから誤差勾配を収集する必要があります。
誤差勾配分布アルゴリズムは、calcInputGradientsメソッドに実装されます。このメソッドのパラメータには、前の層オブジェクトへのポインタが含まれており、このオブジェクトには、初期入力データが最終的なモデル出力に与える影響に応じて分散された誤差勾配を渡す必要があります。メソッドの最初に、受信したポインタの有効性をすぐにチェックします。ポインタが正しくない場合、後続のプロセス全体が無意味になるためです。
bool CNeuronTrajLLMOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
このメソッドが呼び出される時点で、現在の層の誤差勾配がすでに勾配バッファに格納されていることを思い出すことが重要です。この値は、モデルの後続の層で対応するメソッドの実行中に書き込まれました。さらに、先ほど整理したポインタ置換メカニズムのおかげで、この同じ誤差勾配は、予測結果を転置する内部層のバッファにも存在します。したがって、将来の動きを予測する役割を担うMLPにこの勾配を渡すことによって、勾配分散プロセスを開始します。
//--- Forecast if(!caForecastMLP[1].calcHiddenGradients(cTransposeOut.AsObject())) return false; if(!caForecastMLP[0].calcHiddenGradients(caForecastMLP[1].AsObject())) return false;
これが完了すると、分析されたパラメータの履歴軌跡を認知分析の結果と揃える層に誤差勾配を伝播します。
//--- Lane aware if(!cLaneAware.calcHiddenGradients(caForecastMLP[0].AsObject())) return false;
ここで重要なのは、クロスアテンションブロックが2つの別々の情報ストリームからのデータを一致させることです。したがって、最終的なモデル出力への影響に応じて、誤差勾配をこれら2つのストリームに分配する必要があります。
if(!cVariablesPE.calcHiddenGradients(cLaneAware.AsObject(), caMamba[caMamba.Size() - 1].getOutput(), caMamba[caMamba.Size() - 1].getGradient(), (ENUM_ACTIVATION)caMamba[caMamba.Size() - 1].Activation())) return false;
次に、誤差勾配を状態空間モデルに渡します。
for(int i = int(caMamba.Size()) - 2; i >= 0; i--) if(!caMamba[i].calcHiddenGradients(caMamba[i + 1].AsObject())) return false;
次に、高次依存関係分析ブロックを実行します。
if(!cHighLevelInteraction.calcHiddenGradients(caMamba[0].AsObject())) return false;
コンテキストMLPを使用して、誤差勾配を1レベル深く、つまり状態と軌跡の連結されたデータバッファまで押し進めます。
if(!cContextMLP[1].calcHiddenGradients(cHighLevelInteraction.AsObject())) return false; if(!cContextMLP[0].calcHiddenGradients(cContextMLP[1].AsObject())) return false; if(!cContext.calcHiddenGradients(cContextMLP[0].AsObject())) return false;
さて、ここからは最も複雑で重要な部分です。ここでは、細部を見落とさないように最大限の注意が必要です。
この時点で、連結されたバッファの勾配を2つの別々のストリームに分割する必要があります。何も複雑なことはありません。適切なデータバッファを指定して、連結解除メソッドを実行するだけです。私たちの場合、これらは2つのクロスアテンション層、つまり軌跡から状態への層と状態から軌跡への層です。しかし、課題は次のステップにあります。軌道から状態へのクロスアテンションブロックを通じて誤差勾配を伝播すると、そのブロック内で新たな勾配が発生し、それが状態から軌道へのクロスアテンション層にも伝達される必要があります。したがって、この複数ステップのプロセス中に勾配情報の一部が失われないようにするには、それを一時バッファに保存する必要があります。しかし、このクラス内では、補助バッファがなくても非常に多くのオブジェクトを作成しました。そして、これらのオブジェクトの中には、順番を待っているものも数多くあります。そこで、情報の一時的な保存に使用してみましょう。この部分勾配の一時的な保持者として、状態から軌跡へのクロスアテンションブロックに関連付けられた位置エンコーディング層を使用しましょう。
if(!DeConcat(cStatePE.getGradient(), cVariableToState.getGradient(), cContext.getGradient(), cStateToVariable.Neurons(), cVariableToState.Neurons(), 1)) return false;
さらに、軌跡の位置エンコーディング層の勾配バッファには、すでに有用な誤差勾配が含まれていることを思い出してください。この貴重な情報が失われないように、対応するエンコーダー内のMLPの勾配バッファに一時的に転送します。
if(!SumAndNormilize(cVariablesPE.getGradient(), cVariablesPE.getGradient(), cVariablesMLP[1].getGradient(), 1, false)) return false;
必要な勾配情報がすべて保持されていることを確認したら、軌跡を状態に合わせるクロスアテンションブロックを通じて誤差勾配を配布します。
if(!cVariablesPE.calcHiddenGradients(cVariableToState.AsObject(), cStateToVariable.getOutput(), cStateToVariable.getGradient(), (ENUM_ACTIVATION)cStateToVariable.Activation())) return false;
これで、両方のストリームから誤差勾配を蓄積し、状態を軌道に合わせるクロスアテンションブロックのレベルで誤差勾配を合計することができます。
if(!SumAndNormilize(cStateToVariable.getGradient(), cStatePE.getGradient(), cStateToVariable.getGradient(), 1, false, 0, 0, 0, 1)) return false;
ただし、次のステップでは、誤差勾配を軌跡の位置エンコーディング層に3回目に渡す必要があります。したがって、まず両方のデータストリームから既存の誤差勾配を集計します。
if(!SumAndNormilize(cVariablesPE.getGradient(), cVariablesMLP[1].getGradient(), cVariablesMLP[1].getGradient(), 1, false, 0, 0, 0, 1)) return false;
この集約の後でのみ、状態を軌道に合わせるクロスアテンションブロックの勾配分散法を呼び出します。
if(!cStateToState.calcHiddenGradients(cStateToVariable.AsObject(), cVariablesPE.getOutput(), cVariablesPE.getGradient(), (ENUM_ACTIVATION)cVariablesPE.Activation())) return false;
この時点で、3つの異なるソースからのものを組み合わせて、軌跡の位置エンコーディング層ですべての誤差勾配を最終的に合計できます。
if(!SumAndNormilize(cVariablesPE.getGradient(), cVariablesMLP[1].getGradient(), cVariablesPE.getGradient(), 1, false, 0, 0, 0, 1)) return false;
次に、誤差勾配を状態の位置エンコーディング層まで伝播します。
if(!cStatePE.calcHiddenGradients(cStateToState.AsObject())) return false;
位置エンコーディング層は2つの独立した並列データストリームで動作し、それぞれの誤差勾配を各ストリームの適切なエンコーダーに伝播する必要があることに注意してください。
//--- Position Encoder if(!cStateMLP[1].calcHiddenGradients(cStatePE.AsObject())) return false; if(!cVariablesMLP[1].calcHiddenGradients(cVariablesPE.AsObject())) return false;
次に、誤差勾配を2つの並列エンコーダーに渡します。各エンコーダーは、生データの同じ入力テンソルで動作します。ここで、これら2つの並列ストリームからの誤差勾配を1つの勾配バッファに結合する必要が生じます。ここでも補助データバッファが必要になりますが、これは作成されていません。さらに、この段階では、すべての内部オブジェクトにはすでに上書きできない重要なデータが入っています。
ただし、微妙ではあるが重要なニュアンスがあります。軌跡エンコードの前に生の入力データを再配置するために使用するデータ転置層には、訓練可能なパラメーターが含まれていません。誤差勾配バッファは、前の層にデータを渡すためにのみ使用されます。さらに、同じデータを異なる順序で処理しているため、このバッファのサイズはニーズに完全に一致しています。素晴らしいです。誤差勾配を軌道エンコーディングブロックを通じて伝播します。
//--- Variables Encoder if(!cVariablesMLP[0].calcHiddenGradients(cVariablesMLP[1].AsObject())) return false; if(!cVariablesRNN.calcHiddenGradients(cVariablesMLP[0].AsObject())) return false; if(!cTranspose.calcHiddenGradients(cVariablesRNN.AsObject())) return false; if(!NeuronOCL.FeedForward(cTranspose.AsObject())) return false;
そして、得られた誤差勾配をデータ転置層のバッファに転送します。
if(!SumAndNormilize(NeuronOCL.getGradient(), NeuronOCL.getGradient(), cTranspose.getGradient(), 1, false)) return false;
同様に、誤差勾配を状態エンコーダーに渡します。
//--- State Encoder if(!cStateMLP[0].calcHiddenGradients(cStateMLP[1].AsObject())) return false; if(!cStateRNN.calcHiddenGradients(cStateMLP[0].AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(cStateRNN.AsObject())) return false;
その後、両方のストリームからの誤差勾配を合計します。
if(!SumAndNormilize(cTranspose.getGradient(), NeuronOCL.getGradient(), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; //--- return true; }
最後に、すべての操作の論理結果を呼び出し元プログラムに返して、成功または失敗を示します。
これで、CNeuronTrajLLMOCLクラスのアルゴリズムの説明は終了です。このクラスの完全なコードとすべてのメソッドは添付ファイルにあります。
2.4 モデルアーキテクチャ
これで、このクラスをモデルにシームレスに統合し、実際の履歴データを使用して提案されたアプローチの実際の効率を評価できるようになりました。Traj-LLMアルゴリズムは、将来の軌道を予測するために特別に設計されています。環境状態エンコーダーでも同様の方法を使用します。
Traj-LLMの実際の応用に関する当社の解釈は、統合された複合ブロック内に実装されていることに注意してください。これにより、機能性を犠牲にすることなく、クリーンかつわかりやすい外部モデル構造を維持できます。
通常どおり、現在の市場状況を示す未処理の生のデータがモデルの入力に送られます。
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } //--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
これらはバッチ正規化層で一次処理を受けます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
その後、データはすぐに新しいTraj-LLMブロックに転送されます。このような複雑なアーキテクチャソリューションをニューラル層と呼ぶのは困難です。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTrajLLMOCL; descr.window = BarDescr; //window descr.window_out = EmbeddingSize; //Inside Dimension descr.count = HistoryBars; //Units prev_count = descr.layers = NForecast; //Forecast descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
ブロックの出力にはすでに予測値があり、これに元の値の統計パラメータが追加されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; }
次に、結果を周波数領域で整列させます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFreDFOCL; descr.window = BarDescr; descr.count = NForecast; descr.step = int(true); descr.probability = 0.7f; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
他のモデルのアーキテクチャは変更されていません。使用されるすべてのプログラムのコードも同様です。以下に添付したコードで勉強できます。次の段階に進みます。
3. テスト
MQL5にTraj-LLMアプローチを実装する重要な作業を完了しました。さて、次は実際の結果を評価する時です。ここでの目標は、実際の履歴データでモデルを訓練し、これまでに見たことのないデータセットでそのパフォーマンスを評価することです。
前述したように、モデルのアーキテクチャの変更は、入力データの構造や出力の形式には影響しません。これにより、事前訓練の目的で以前にコンパイルされた訓練データセットを利用できるようになります。
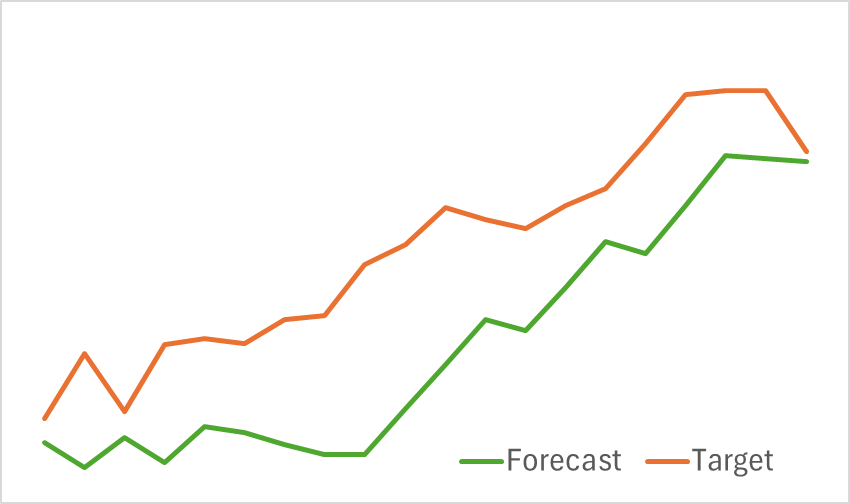
最初の段階では、環境状態エンコーダーを訓練して、今後の価格変動を予測します。予測誤差が許容可能なレベルで安定するまで訓練は継続されます。特に、このフェーズでは訓練データセットを更新または変更しません。この段階で、モデルは有望な結果を示しました。今後の価格動向を見極める優れた能力を示しました。
第2フェーズでは、Actorの行動方策とCriticの報酬関数の反復訓練を実行します。Criticモデルの訓練は補助的な役割を果たします。それはActorの行動に調整をもたらしました。しかし、主な目標はActorにとって収益性の高い方策を開発することです。Actorの行動の信頼性の高い評価を確実にするために、このフェーズでは訓練データセットを定期的に更新します。数回の反復を経て、テストデータセットで利益を生み出すことができる方策を開発することに成功しました。
すべてのモデルは、2023年H1時間枠におけるEURUSD銘柄の履歴データを使用して訓練されていることに注意してください。他のすべてのパラメータを変更せずに、2024年1月のデータでテストが実行されます。
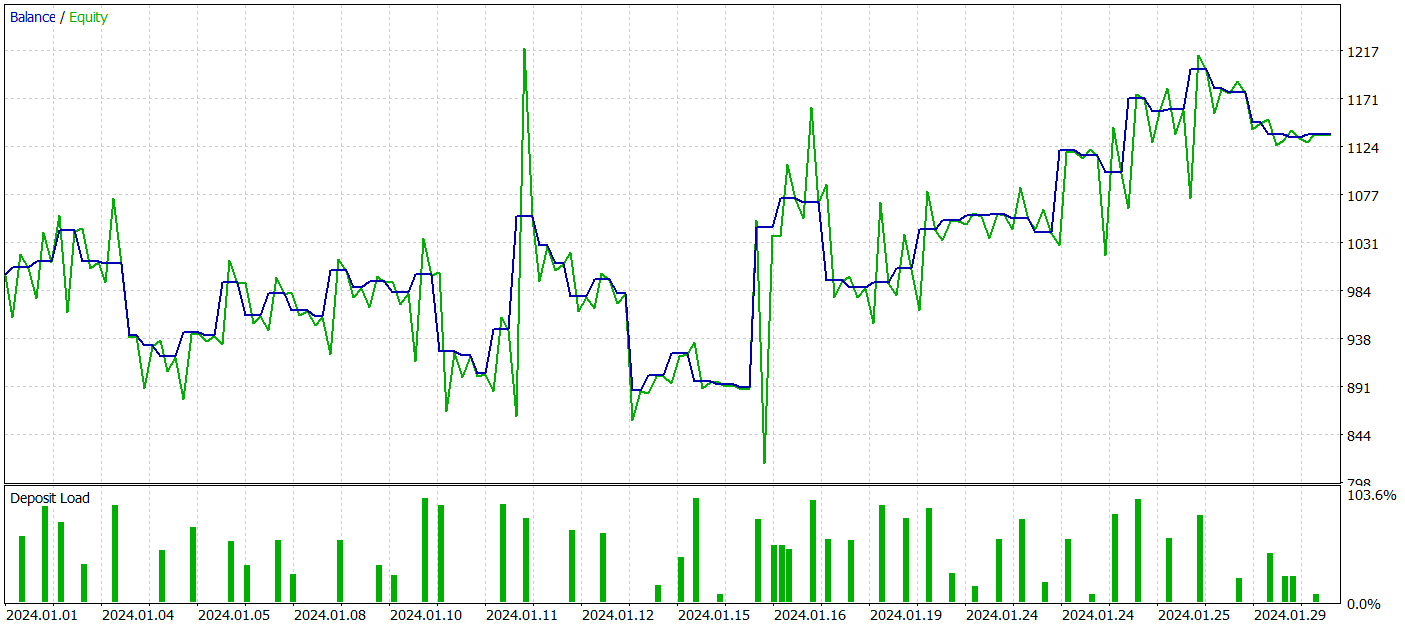
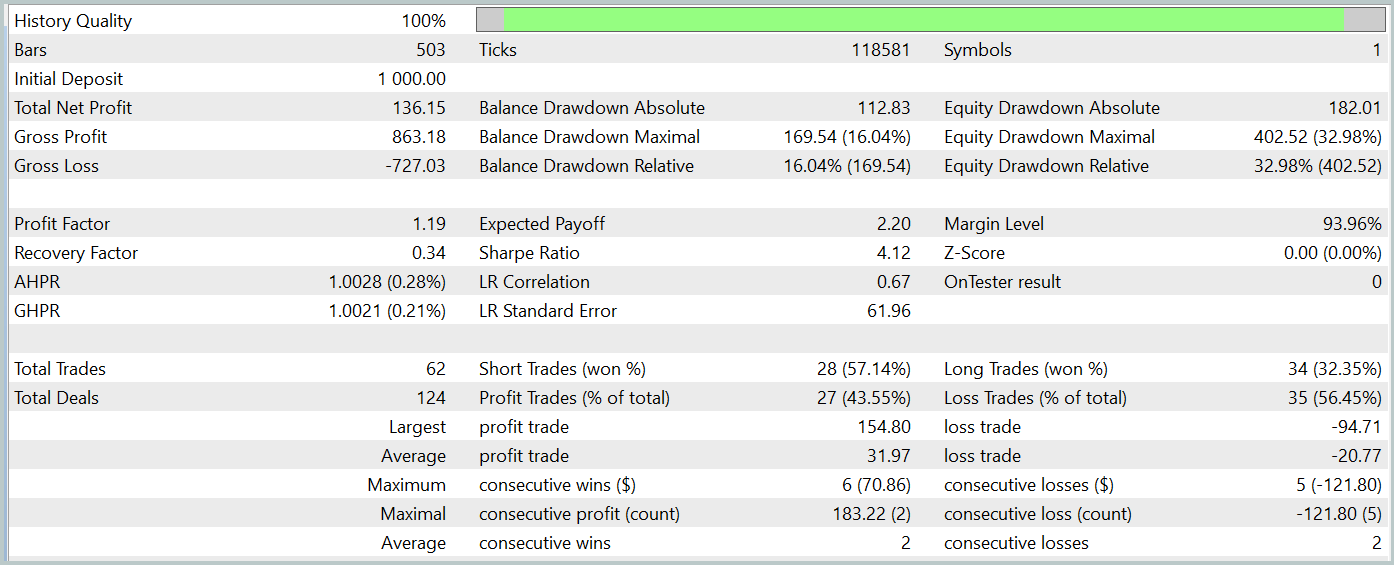
テスト期間中、モデルは62件の取引を実行し、そのうち27件(43.55%)が利益を上げて終了しました。ただし、最大および平均の利益のある取引が損失のある取引の同じ変数の半分以上であるという事実により、全体として、テスト期間中に13.6%の利益が得られました。そして利益率は1.19でした。しかし、大きな懸念は、ほぼ33%に達した株式の下落です。明らかに、現在の形式では、このモデルはまだ現実世界の取引には適しておらず、さらなる改善が必要です。
結論
本記事では、大規模言語モデル(LLM)の新たな応用に関する視点を提案するTraj-LLM法について考察しました。本手法は、LLMの機能をさまざまな時系列データの将来値予測に適応させる方法を示しており、不確実性や混沌とした環境下においても、より正確で適応性の高い予測を可能にします。
実践セクションでは、提案手法を独自に解釈し、実際の過去データを用いて検証しました。結果はまだ完全ではないものの、有望な傾向を示しており、さらなる発展の可能性が期待されます。
参照文献
- Traj-LLM:A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
- 本連載の他の記事
記事で使用されているプログラム
| # | ファイル名 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15595
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索