
初級から中級へ:Includeディレクティブ

はじめに
ここで提示されるコンテンツは、教育目的のみを目的としています。いかなる状況においても、提示された概念を学習し習得する以外の目的でアプリケーションを閲覧することは避けてください。
前の記事「初級から中級まで:BREAK文とCONTINUE文」では、WHILE文やDO WHILE文を使ったループ内での実行フローの制御に焦点を当てました。おそらく読者の皆さんは、FOR文を用いたループの理解にも十分に備えていると思いますが、今回は少しループの話題から離れ、別の重要な概念を確認していきたいと思います。これにより、さらなるフロー制御構文に進む前に、より深い理解が得られるはずです。
本記事では、今後非常に役立つトピックを取り上げます。説明が終われば、より洗練されたコード例を紹介できるようになるでしょう。これまで、MQL5で利用できる特定のリソースを使わずにコードを書くことは苦痛でした。読者の中には「簡単そうに見えた」と思う方もいるかもしれませんが、実際にはかなり大変だったのです。しかしこれから、すでに実現可能な機能に加え、さらに新しいリソースを導入していきます。
ここで紹介するリソースとは、「コンパイルディレクティブ」です。これらのディレクティブなしでは、できることが大きく制限され、実際の開発現場では不必要に多くのコードを書く羽目になってしまいます。
多くの方が思っているのとは逆に、コンパイルディレクティブはコードを複雑にするものではありません。むしろ、コードをよりシンプルに、より高速に、そして扱いやすく、修正しやすくするためのものです。問題は、多くの初心者がこのリソースの使い方を学ばない、あるいは軽視してしまうことにあります。これは、JavaScriptやPythonのように、コンパイルディレクティブを持たない言語に親しんでいる人に特によく見られます。これらの言語はカジュアルなプログラマーの間で人気ですが、特定の種類のアプリケーション開発には適していないこともあります。しかし、本稿の目的はこれらの言語を論じることではありません。MQL5に焦点を当て、学習を進めていきましょう。それでは、この記事の最初のトピックに入ります。
コンパイルディレクティブを使用する理由
MQL5のコンパイルディレクティブは、ほとんどの状況において非常によく機能します。しかし、それでも時折、他のディレクティブも使えたらいいと感じることがあります。というのも、MQL5は本質的にC/C++を高度に洗練・改良したものに由来しているためです。ただし、C/C++には存在するものの、MQL5では使用できないディレクティブもあります。その一例が#ifディレクティブです。一見目立たないものの、作業中のバージョンにおいて特定の部分を制御する際には非常に便利なものです。
とはいえ、MQL5には(この記事執筆時点では)このディレクティブは存在しませんが、特に問題にはなりません。ここでこの話題を取り上げたのは、将来的にC/C++の学習に興味を持つかもしれない読者の皆さんに、MQL5とC/C++の違いを少しでも知っておいていただきたかったからです。ここで紹介する内容の多くは、C/C++を学ぶ際の良い足がかりにもなるでしょう。
簡単にまとめると、コンパイルディレクティブには基本的に2つの主要な目的があります。1つ目は、実装をより効率的なコードモデルへと導くこと、2つ目は、既存のコードセクションを削除・損失することなく、同じコードの異なるバージョンを作成できるようにすることです。
多くの方にとって、こうした考え方は少し奇妙に思えるかもしれません。それもそのはず、初心者のプログラマーは、問題を修正したり、計算や処理の方法を改善するために、コードの一部を削除して新たに作り直す習慣があるからです。
しかし、これはコンパイルディレクティブが存在しない言語において必要となる方法です。コンパイルディレクティブをサポートする言語では、同じコード内に複数のバージョンを共存させ、必要に応じて切り替えることが可能です。そして、その選択をインテリジェントかつ体系的におこなうのが、まさにディレクティブの役割なのです。
このように整理されたコードを書くためには、ある程度の経験が求められます。ここでは、いまこの瞬間から、まったくの基礎から始めていきます。つまり、私の大切な読者であるあなたには、コンパイルディレクティブを使ったコードの操作・実装方法について、まだ知識がないものと仮定して話を進めます。
今後の記事では、コンパイルディレクティブに関連する実践的な方法を少しずつ紹介していく予定です。おそらく、このテーマだけに絞った専用の記事は作らないと思います。今回の記事はあくまで「導入編」として、コンパイルディレクティブとは何かを理解してもらうことを目的としています。
ここまで、コンパイルディレクティブに関する全体的な紹介を終えました。それでは、MQL5コードの中で最もよく使われるディレクティブについて見ていきましょう。次のトピックへ進みます。
#INCLUDEディレクティブ
おそらく、読者の皆さんがコードの中で、特にMQL5やC/C++スタイルのコードで最もよく目にするコンパイルディレクティブは、この#INCLUDEになるでしょう。なぜでしょうか。それは、経験豊富なプログラマーたちの多く(すべてとは言いませんが)が、すべてをひとつのコードファイルに詰め込むことを嫌うからです。通常、経験を積んだプログラマーは、コードを小さなブロックに分割して管理します。こうしたブロックは、関数、プロシージャ、構造体、クラスなどを集めた「ライブラリ」として発展していきます。そして、それらは非常に論理的に整理されています。このように整理されたコードのおかげで、たとえ新しく独自のコードを書く場合でも、最小限の変更だけで、非常にスピーディにプログラミングできるようになるのです。目指すのは、時間をかけて丁寧にカタログ化した元のコードを、簡単に新しいバージョンへと変換できるようにすることです。
一方で、あなたは今、同じタスクを実行するために毎回コードを一から書き直しているかもしれません。
しかし、コードをこのように整理して#INCLUDEディレクティブを活用する方法については、ここでは教えません。というのも、実際のところ、それを「教える」ことは誰もできないからです。コードの整理とは、あくまでそのコードを管理する人が、自分で考え抜いて、各要素を最も適切な場所に配置する作業だからです。とはいえ、整理の方法は教えられなくても、あなたが心を込めて作ったコードにアクセスする方法は、ここでしっかりお伝えします。これこそが、このディレクティブの主な役割なのです。つまり、非常に自然で、実用的にコードにアクセスできるようにするための手段です。
このディレクティブ自体には、コードの実行フローは関係しません。もちろん、注意すべき細かい点はいくつかありますが、それらはこれから少しずつ、自然な流れの中で解説していきます。
まずは、これまでの記事で扱ったコードのひとつを取り上げてみましょう。すでに見たことがあるコードを使うことで、今回学ぶ内容もより親しみやすく感じてもらえるはずです。それでは、小さなサンプルコードをひとつ作成して、スタートしましょう。以下をご覧ください。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. ulong value; 07. 08. Print("Factorial of 5: ", Factorial(5)); 09. Print("Factorial of 3: ", Factorial(3)); 10. Print(One_Radian()); 11. do 12. { 13. value = Tic_Tac(); 14. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 15. }while (value < 3); 16. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 17. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 18. } 19. //+------------------------------------------------------------------+ 20. double One_Radian() 21. { 22. return 180. / M_PI; 23. } 24. //+------------------------------------------------------------------+ 25. ulong Tic_Tac(bool reset = false) 26. { 27. static ulong Tic_Tac = 0; 28. 29. if (reset) 30. Tic_Tac = 0; 31. else 32. Tic_Tac = Tic_Tac + 1; 33. 34. return Tic_Tac; 35. } 36. //+------------------------------------------------------------------+ 37. ulong Factorial(uchar who) 38. { 39. static uchar counter = 0; 40. static ulong value = 1; 41. 42. if (who) who = who - 1; 43. else 44. { 45. counter = 0; 46. value = 1; 47. } 48. while (counter < who) 49. { 50. counter = counter + 1; 51. value = value * counter; 52. }; 53. while (counter > who) 54. { 55. value = value / counter; 56. counter = counter - 1; 57. }; 58. counter = counter + 1; 59. return (value = value * counter); 60. } 61. //+------------------------------------------------------------------+
コード01
読者の皆さんには、このコード01を必ず理解していただく必要があります。これは、ここから先に進むための前提条件です。もしこのコードが理解できない場合は、ここで一旦立ち止まり、必ず前回までの記事に戻って復習してください。このコードは非常にシンプルであり、どんな状況であっても、混乱したり理解に苦しむようなものではありません。
このコードを実行すると、MetaTrader 5の端末に、次のような出力が表示されます。
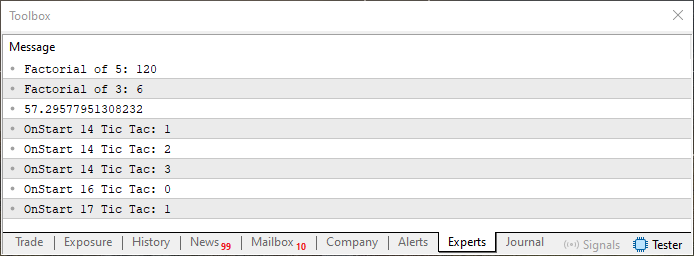
図01
これは単に、コードが正常に動作するかどうかを確認するためにおこなっているだけです。期待どおりに動いていることがはっきりと確認できたので、ここからはコンパイルディレクティブの使い方について話を進めていきましょう。もしかすると、別のディレクティブから始めた方がよかったのかもしれませんが、問題ありません。何といっても、#includeディレクティブは最も使用頻度が高いので、ここから始めるのは自然な流れです。それでは、次に進みましょう。
他のことに手を付ける前に、まず理解しておかなければならないことがあります。それは、コードをどのように分割するかということです。一見、些細なことに思えるかもしれませんが、決して軽視してはいけません。自分にとって使いやすく、実用的な方法を考え出しておかないと、やがて新しいコードを作成しようとしたときに深刻な問題に直面することになります。逆に、自分に合った分割方法を確立できれば、あなたのプログラミングは大きく飛躍するでしょう。
ここではあくまで教育的な目的で進めていくので、コードを3つの別々のファイルに分割してみましょう。それぞれのファイルには、先ほどのコード01に含まれていた関数やプロシージャを個別に格納します。
ここで「わかりました。ファイルを作成します。」と思うかもしれません。ですが、それは次のステップではありません。実は、もうひとつ先に考えるべきことがあります。それは、作成したファイルをどこに保存するのかということです。保存先はincludeディレクトリだとと思うかもしれませんが、これは非常に個人的な判断に関わる問題です。というのも、必ずしもincludeディレクトリがベストな選択肢とは限らないからです。もしこの意味がよく分からなければ、下の画像のようにMetaEditorを使ってMQL5フォルダを探してみてください。
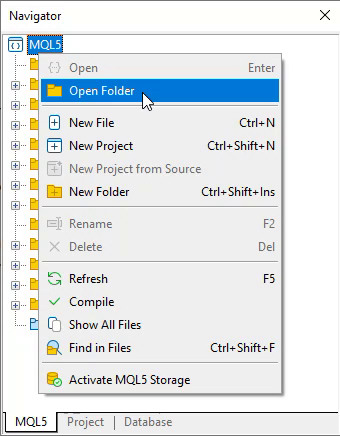
図02
これをおこなうと、MQL5ディレクトリ内に「include」という名前のフォルダが表示されます。このフォルダは、これから作成していくヘッダーファイル(一般的な呼び方です)のデフォルトの保存場所となっています。しかし、先ほども少し触れたように、これが常に最適な選択肢とは限りません。プロジェクトの内容や達成したい目的によっては、すべてのヘッダーファイルをincludeフォルダにまとめると、かえって問題を引き起こす可能性があるのです。たとえば、同じプロシージャや関数の少し違うバージョンが存在していて、それがincludeフォルダ内にある別のバージョンと競合してしまうかもしれません。
ここで、多くの人が、ヘッダーファイルを整理するために、サブディレクトリを作成すればいいのではないかと疑問に思うことでしょう。もちろん、その通りです。実際、これはよく使われる整理方法のひとつです。ただし、たとえサブディレクトリを作ったとしても、場合によってはそれでも最適な解決策にならないことがあるのです。
でも、心配はいりません。このあと、どう整理すればよいかをちゃんとお見せします。これは、あなたが自分のコードを最適な形で管理できるようになるためのものです。前にも言いましたが、「こうすれば完璧」というやり方は誰にも教えられません。ですが、いろいろな整理の考え方を理解すれば、あなた自身に合ったベストな方法を見つけられるようになります。
では、ここでちょっと違った方法を試してみましょう。Scriptsフォルダの中に、サブディレクトリを作成します。このサブディレクトリには、コード01に出てきた各関数をそれぞれ格納します。ただし、しっかりと分けて進めるために、ソリューション1から順に、セクションごとに説明していきます。
解決策1
コード01に出てきた関数を分離するための、最初の解決策は、それぞれの関数を個別のヘッダーファイルに保存するという方法です。ただし、これらのファイルは、Scriptsディレクトリの中に作成したフォルダに配置します。ここで、とても大事なポイントがあります。作成するヘッダーファイルには、必ず「.MQH」拡張子を付けてください。こうすることで、オペレーティングシステムのファイルエクスプローラー上でも、一目でヘッダーファイルだと分かるようになります以上を踏まえたうえで、実際にファイルを分割していきます。それぞれのファイルには、次のような内容が入ることになります。
1. //+------------------------------------------------------------------+ 2. #property copyright "Daniel Jose" 3. //+------------------------------------------------------------------+ 4. double One_Radian() 5. { 6. return 180. / M_PI; 7. } 8. //+------------------------------------------------------------------+
ファイル01
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. ulong Tic_Tac(bool reset = false) 05. { 06. static ulong Tic_Tac = 0; 07. 08. if (reset) 09. Tic_Tac = 0; 10. else 11. Tic_Tac = Tic_Tac + 1; 12. 13. return Tic_Tac; 14. } 15. //+------------------------------------------------------------------+
ファイル02
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. ulong Factorial(uchar who) 05. { 06. static uchar counter = 0; 07. static ulong value = 1; 08. 09. if (who) who = who - 1; 10. else 11. { 12. counter = 0; 13. value = 1; 14. } 15. while (counter < who) 16. { 17. counter = counter + 1; 18. value = value * counter; 19. }; 20. while (counter > who) 21. { 22. value = value / counter; 23. counter = counter - 1; 24. }; 25. counter = counter + 1; 26. return (value = value * counter); 27. } 28. //+------------------------------------------------------------------+
ファイル03
もう1つの重要なポイントは、分割が終わった後、アイテムをどこに配置するか、各ファイルの名前をどうするかは、完全にあなたの判断に任されているということです。決まったルールはないので、自由に自分のやりやすいように選んで構いません。
さて、コード01からコードを抽出して個別のファイルに分けた結果、次のようなコード構成になります。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. ulong value; 07. 08. Print("Factorial of 5: ", Factorial(5)); 09. Print("Factorial of 3: ", Factorial(3)); 10. Print(One_Radian()); 11. do 12. { 13. value = Tic_Tac(); 14. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 15. }while (value < 3); 16. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 17. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 18. } 19. //+------------------------------------------------------------------+
コード02
素晴らしいです。コード01で見たものよりもずっとシンプルに見えます。本当です、親愛なる読者の皆さん。しかし、このコード02をコンパイルしようとすると、コンパイラから多数のエラーが報告されることになります。下の画像に示すように、これらのエラーはコンパイラがコードを解釈できなかったことを示しています。
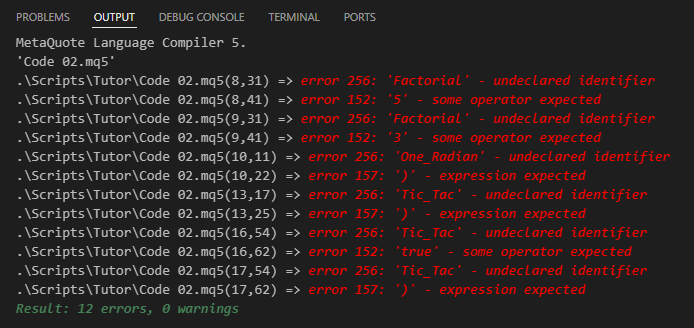
図03
実際には、コンパイラがコードを理解しなかったわけではありません。問題は、コンパイラがコード内に現れるプロシージャや関数の呼び出しを解決する方法を知らないことです。それでは、これが何を意味するのでしょうか。プログラミング言語について多くの人が思ったり予想したりしていることとは逆に、実際のところ、プログラミング言語は2つのコンポーネントから成り立っています。まず最初のコンポーネントは標準ライブラリです。この標準ライブラリは、私たちが「ユーザーレベルコード」と呼ぶものを作成するために使用する関数、プロシージャ、予約語、定数、その他の要素を定義しています。
特定のプログラミング言語を使用しているプログラマーは、標準ライブラリの内容を変更することはできません。しかし、その中で定義されている機能を利用して、自分自身のソリューションを構築することができます。標準ライブラリに含まれるものは、特別な操作なしにそのまま利用できます。ただし、このライブラリに含まれていないものは、コードに明示的に追加する必要があります。この追加操作によって、コンパイラは発生する可能性のある関数やプロシージャの呼び出しをどのように解決すべきかを理解できるようになります。これが、コード02をコンパイルしようとするとエラーが出る理由です。コード01と似ているにもかかわらず、コンパイルに失敗するのです。
コードを正常にコンコードを正常にコンパイルするには、コンパイルプロセスにどのファイルを含めるかをコンパイラに明示的に指示する必要があります。これこそが、このディレクティブが「コンパイルディレクティブ」と呼ばれる理由であり、#includeという名前がぴったりな理由です。つまり、このコードをコンパイルする際に、どのファイルを含めるべきかをコンパイラに伝えるわけです。読者の皆さん、お分かりになったでしょうか。
この概念を本当に理解すれば、これまでできなかったことができるようになります。プログラミングを学んでいると、いくつかの事柄が不明確に感じられたり、明確な意味が欠けていることがあるかもしれません。しかし、この点については別の機会にさらに詳しく説明します。今はあまり情報を詰め込みすぎて、皆さんを圧倒したくはありません。各記事で説明し、実証している内容を十分に理解して、吸収していただきたいと思います。
さて、コンパイラが必要な情報にアクセスする方法を知らないためにコード02をコンパイルできない場合、どうすれば解決できるのでしょうか。作成したファイルを手動で開いて、各関数やプロシージャをコピーし、コード02に直接貼り付けて、コード01のようにする必要があるのでしょうか。確かに、コード01が正常にコンパイルされたなら、それが正しいということですが、この方法は少し論理的ではないように思えます。他のプログラムを見てきましたが、それらはコード全体をコピーして最終スクリプトに貼り付ける必要はありませんでした。それでは、この問題をどう解決すればよいのでしょうか。この部分は簡単です。次に示すコードにあるようなことを実行するだけです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. #include "Tutorial\File 02.mqh" 06. #include "Tutorial\File 03.mqh" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. ulong value; 11. 12. Print("Factorial of 5: ", Factorial(5)); 13. Print("Factorial of 3: ", Factorial(3)); 14. Print(One_Radian()); 15. do 16. { 17. value = Tic_Tac(); 18. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 19. }while (value < 3); 20. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 21. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 22. } 23. //+------------------------------------------------------------------+
コード03
さて、ここからが面白い部分です。コード03をコンパイルしようとすると、次のような応答が返されます。
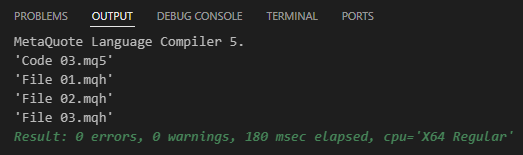
図04
つまり、成功です。しかし、どうしてそうなるのでしょうか。その理由は、コード03の4行目、5行目、6行目にあります。これらの行は技術的にはコード内のどこにでも配置できます。ただし、整理上の理由から、通常はスクリプトの先頭に配置されます。まれに、他の場所にも出現することがありますが、これは特定のケースに過ぎませんので、ここでは考慮しません。それでも、物事をもっと組織的で実用的な方法で構成できるのは素晴らしいことです。
しかし、理解しておくべき重要な概念が1つあります。これについては今後の記事でさらに詳しく掘り下げていきますが、現時点での重要なポイントは、コード03でどのように#includeディレクティブが宣言されているかということです。
今すぐにその詳細を説明することは避けますが、ドキュメントをお読みになることをお勧めします。今、このタイミングで詳しく説明すると、なぜコード03でそのように書かれているのか理解するのが難しいかもしれません。さらに、場合によっては他の方法で宣言されている理由がわかりにくく、逆に混乱を招くかもしれません。
詳細は、ドキュメントの「ファイルのインクルード(#include)」セクションに記載されています。ですが、私の記事を以前から追っている方々は、コード03の4行目、5行目、6行目の書き方には特別な理由があることをご存知かもしれません。
いずれにしても、コード03を実行すると、画像01に示された出力が得られます。それでは、2番目のタイプのソリューションに移行しましょう。この解決策を明確に区別するため、新しいセクションを設けます。
解決策2
この2番目の解決策は、ユーザビリティの原則に従います。言い換えれば、MQL5の機能を拡張し、新しいコードを作成したり、コードをより速く生成したりするためのものです。他のプログラマーが、元々MetaTrader 5に含まれていた変更されたヘッダーファイルを配布することは珍しくありません。個人的には、いくつかの変更が非常に興味深いものになる可能性があり、これらのディストリビューションは非常に便利だと感じています。しかし、問題はこれらのファイルをどこに保存するかです。
これが重要な理由は、MetaTrader 5が定期的に更新されるからです。他の人が作成したり、自分でカスタマイズしたりした変更されたヘッダーファイルがあり、それが開発作業に非常に実用的で役立つ場合でも、それをどこにでも保存してはいけません。MQL5フォルダ内のincludeディレクトリに保存してしまうと、次回のMetaTrader 5の更新時に上書きされてしまう可能性があります。この場合、貴重なファイルが失われてしまいます。
この問題を解決する方法があります。それは、変更されたヘッダーファイルの名前を変更することです。しかし、前のセクションで紹介したアプローチを使用する方法もあります。どちらの方法も有効ですが、最初の方法ではいくつかの制限に直面することになります。例えば、現在のディレクトリ外に保存されているヘッダーファイルにアクセスするのが難しくなります。これは不可能ではありませんが、管理には追加の手順が必要となります。
このため、複数の関連のないアプリケーションで同じヘッダーファイルを使用する場合は、それを1つの中央の場所に保存するのが最適です。ここでは、includeディレクトリ内にそれを保存する方法を採用します。ただし、定期的にバックアップを作成することを忘れないでください。理想的には、バージョン管理システムを使用してファイルを効率的に管理することをお勧めします。
そのため、GITの使用をお勧めします。詳細については、私の他の記事「GIT:それは何か?」を参照してください。GITを適切に使用すれば、数え切れないほどの頭痛や眠れない夜から解放されます。しかし、もちろん、ツールを正しく使用するには、十分に学習し、使いこなす必要があります。
さて、本題に戻ります。前のセクションで使用したファイルを再利用し、それをincludeディレクトリ内に保存することができるようになりました。これにより、同じファイルの2つの異なるバージョンを維持できます。一つは作成するすべてのアプリケーションから簡単にアクセスできるバージョン、もう一つは現在進行中のプロジェクトに固有のバージョンです。これを実証し、それが可能であることを証明するために、前のセクションのファイルの1つを変更してみましょう。実際、私たちは現在、2つのバージョンを維持しています。1つは現在のプロジェクト専用で、もう1つは開発するすべてのスクリプトで使用できるバージョンです。このファイルは以下の通りです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. double One_Radian() 05. { 06. return 180. / M_PI; 07. } 08. //+------------------------------------------------------------------+ 09. double ToRadians(double angle) 10. { 11. return angle / One_Radian(); 12. } 13. //+------------------------------------------------------------------+ 14. double ToDegrees(double angle) 15. { 16. return angle * One_Radian(); 17. } 18. //+------------------------------------------------------------------+
ファイル04
非常に基礎から始めるので、できることのいくつかは示しません。今回は、ヘッダーファイルの操作方法に焦点を当てます。これで、同じ関数(この場合はOne_Radians関数)の2つの同一バージョンを含む2つのファイルが作成されました。今は些細で重要ではないと思えるかもしれませんが、さらに深く掘り下げて新しい機能を明らかにしていくと、この状況が非常に役立つことがわかります。適切なタイミングでしっかりと説明していきます。
さて、ここでファイル01の代わりにファイル04を使用することにします。なぜなら、ファイル04には使用したい他の機能も含まれているからです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. #include "Tutorial\File 02.mqh" 06. #include "Tutorial\File 03.mqh" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. ulong value; 11. 12. Print("Factorial of 5: ", Factorial(5)); 13. Print("Factorial of 3: ", Factorial(3)); 14. Print(One_Radian()); 15. Print(ToRadians(90)); 16. do 17. { 18. value = Tic_Tac(); 19. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 20. }while (value < 3); 21. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 22. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 23. } 24. //+------------------------------------------------------------------+
コード04
コード04をコンパイルしようとすると、下の画像に示すような結果になります。
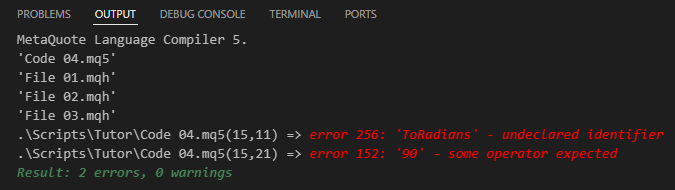
図05
これでコードにエラーがあることが証明されました。ただし、この問題の修正は簡単であるものの、プログラマーとして細心の注意が必要です。問題は、同じ名前の関数やプロシージャの異なるバージョンを含むヘッダーファイルを扱うときに発生します。ここが少しややこしくなる部分です。この状況にどう対処するかは、自分自身で学ばなければなりません。残念ながら、これに対処するための普遍的な方法や簡単な説明は存在しません。その理由はとても簡単で、すべてはコードを時間をかけてどのように構造化してきたかによるからです。この複雑さを除けば、この教育的な例では解決策は非常に単純です。実際、このエラーメッセージの原因は、15行目に存在すべき関数が欠落していることです。この関数は04コードに含まれているどのヘッダーファイルにも含まれていないため、コンパイルは常に失敗します。これを修正するには、15行目で必要な関数を含む正しいファイルの場所をコンパイラに伝える必要があります。解決策は、コードを次に示すコード05に更新することです。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include <Tutorial\File 01.mqh> 05. #include "Tutorial\File 02.mqh" 06. #include "Tutorial\File 03.mqh" 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. ulong value; 11. 12. Print("Factorial of 5: ", Factorial(5)); 13. Print("Factorial of 3: ", Factorial(3)); 14. Print(One_Radian()); 15. Print(ToRadians(90)); 16. do 17. { 18. value = Tic_Tac(); 19. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", value); 20. }while (value < 3); 21. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac(true)); 22. Print(__FUNCTION__, " ", __LINE__, " Tic Tac: ", Tic_Tac()); 23. } 24. //+------------------------------------------------------------------+
コード05
変更は非常に小さいように見えますが、この調整は意図的です。実際のコーディングで物事がどのように動作するかを実践し、真に理解することが重要であることを示すためにおこなわれています。コード05をコンパイルしようとすると、結果は以下のようになります。
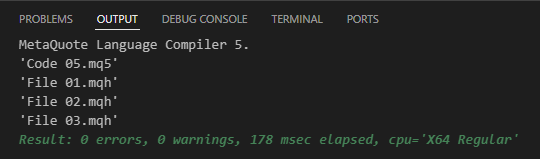
図06
これにより、4行目でインクルードされたファイルが実際にincludeディレクトリに存在することが確認できます。添付されたファイルで、すべてが実際にどのように整理されるべきかが視覚的に示されています。この記事で最後に示すのは、コード05を実行した結果です。
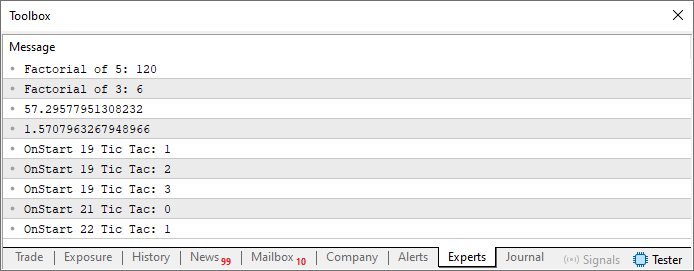
図07
最終的な考察
この記事では、最も一般的に使用されるコンパイルディレクティブの1つについて解説しました。私たちは1つの側面に焦点を当てましたが、このディレクティブが実行できるすべてのことを1つの記事で網羅することは不可能です。もしこのディレクティブだけに関する複数の記事を作成しても、完全に説明するのは難しい部分もあります。なぜなら、本当に優れたプログラマーになるために求められるのは、単に結果を出すプログラムを作る能力だけではなく、自分自身の開発者としてのアイデンティティを確立することだからです。つまり、日常のプログラミング作業で簡単に再利用できるよう、ヘッダーファイルに便利でよく使うコードスニペットを作成し、それを整理して保管することが重要です。
では、どうやってそれを学ぶのでしょうか。それは誰かに教わることができるものではなく、練習と時間をかけて身に付けるものです。しかし、最初の一歩を踏み出さなければなりません。この記事の目的は、その最初のステップをサポートすることです。読者の皆さん、この記事が役に立ったことを願っています。次回は、別の制御フローステートメントについて解説します。それでは、そこでお会いしましょう。
MetaQuotes Ltdによりポルトガル語から翻訳されました。
元の記事: https://www.mql5.com/pt/articles/15383
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 注文板に基づいた取引システムの開発(第1回):インジケーター
注文板に基づいた取引システムの開発(第1回):インジケーター
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
またしても筆者の戯言である。引用:"しかし、C/C++にはMQL5では使えないディレクティブがいくつかある。その1つが#ifdefで、一見面白みがないように見えるかもしれないが、作業中のバージョンの特定の部分を制御するのに非常に役立つ瞬間がある。"
#ifdefは、MQL4とMQL5では非常に長い間使われてきた。
🤦♀️。
またしても筆者の戯言である。引用:"しかし、C/C++にはMQL5では使えないディレクティブがいくつかある。その1つが#ifdefで、一見面白みがないように見えるかもしれないが、作業中のバージョンの特定の部分を制御するのに非常に役立つ瞬間がある。"
#ifdefは、MQL4とMQL5では非常に長い間使われてきた。
🤦♀️。
ベースでのニックネームはvDev!
レカ - スカルプテストをしよう!!!!)
この著者は、新たな挑戦を続けています。C/C++ には MQL5 にはないディレクティブがいくつかあります。そのうちのひとつが#ifdefで、退屈に思えるかもしれませんが、いくつかの部分で、私たちが作業しているバージョンのある部分を制御するのに役立っています。"
#ifdefはMQL4やMQL5ではかなり前から使われています。
申し訳ない。しかし、本文中でこのディレクティブを参照したのは私のミスでした。というのも、#ifdef指令はCやC++にある#if defined指令に相当するからだ。しかし、MQL5では一般化するために、CやC++にもある#ifdefを使用しています。ここでも、目的は#ifディレクティブを参照することである。#ifディレクティブはまったく異なる目的を持ち、定義の値をチェックするために使うこともできる。しかし、私の書き方のミスで#ifdefと書いてしまい、それに気がつきませんでした。私のこの見落としをお詫びします。👍
申し訳ない。しかし、本文中のディレクティブへの言及に私の誤りがありました。というのも、#ifdefディレクティブはCやC++に存在する#if definedディレクティブに相当するからです。しかし、MQL5では一般化するために、CやC++にも存在する#ifdefを使います。ここでも、目的は#ifディレクティブを参照することである。#ifディレクティブはまったく異なる目的を持ち、定義の値をチェックするために使うこともできる。しかし、私の書き方のミスで#ifdefと書いてしまい、それに気がつきませんでした。私のこの見落としをお詫びします。👍
大丈夫です、誰にでもそういう時はあります )
🤦♀️
偶然この記事を見つけた。サイトがリンク集で教えてくれたのだ。