
機械学習や取引におけるメタモデル:取引注文のオリジナルタイミング
はじめに
一部の取引システムの特徴は、選択的な取引、つまり、常に市場にいるわけではないことです。ほとんどの場合、ある時点ではパターンが存在するがある時点では存在あるいは不定形であることが原因です。
前回まで、機械学習モデルを時系列分類に適用するための様々な方法について詳しく説明してきました。これらのモデルはすべて、訓練セットで「そのまま」訓練され、訓練後にボットにコンパイルしたものです。訓練データセットへのラベル付けや最適なモデルの選択などのプロセスを可能な限り自動化することで、人的要因をほぼ排除しています。ただし、これらのモデルには、機能を追加することなく修正することは困難な2つの欠点があります。
私は、モデルが次ができるケースにアプローチを拡大することを目指しました。
- 訓練データセットに適応し、訓練に最適な例を選択する
- 時系列のうち分類が困難な部分を選別し、訓練時や取引時にスキップする
この一般化によって、訓練への取り組み方を一部見直すことになりました。その結果、1つの分類器だけでは新しい要件を満たさないことがわかりました。訓練中に自分で修正することはできません。そこで、前述のようなケースを想定して機能を変更することにしました。
新しいアプローチの理論的側面
まず、少しコメントします。研究者は不確実性を扱いながら取引システムを開発する(機械学習を適用したものも含む)ので、探索対象を厳密に形式化することは不可能です。これは、多次元空間における多かれ少なかれ安定した依存関係として定義することができ、人間や数学的な言語でさえ解釈することが困難です。高度にパラメータ化された自己訓練システムから得られるものを詳細に分析することは困難です。このようなアルゴリズムは、バックテストの結果に基づくトレーダーの一定の信頼を必要とするが、発見されたパターンの本質や性質まで明らかにするものではありません。
私は、自分のエラーを解析して修正し、繰り返し結果を改善するようなアルゴリズムを書きたいと思っています。そのために、次の図のように、2つの分類器の束をとって、順次訓練することを提案します。このアイデアの詳細な説明は以下の通りです。
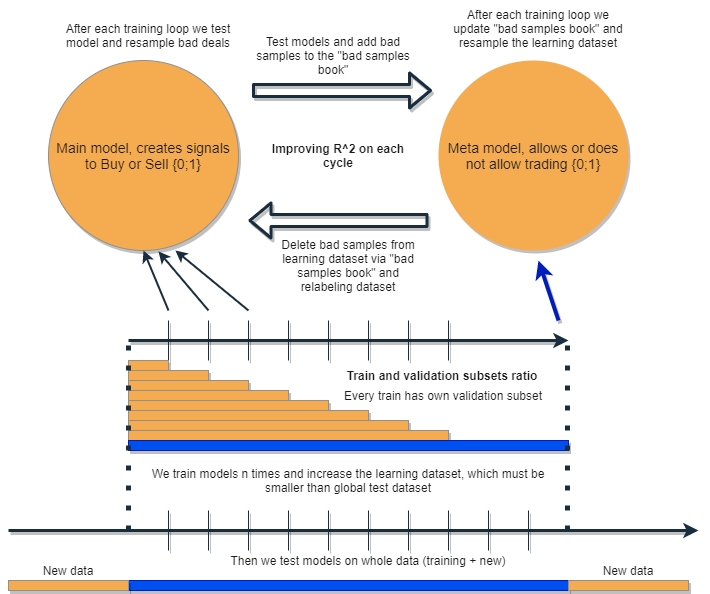
それぞれの分類器は、独自の大きさを持つデータセットで訓練されます。青い水平線はメタモデルの条件付き履歴の深さを表し、橙色のものは基本モデルを表しています。言い換えれば、メタモデルの履歴の深さは、常に基本モデルよりも大きく、これらのモデルの組み合わせがテストされる推定(テスト)時間間隔に等しくなります。
モデルの束は数回再訓練されるあいだに、基本モデルの訓練データセットは徐々に増やすことができます(新しい反復ごとに橙色の列の長さを増やす)が、その長さは青色の列の長さを超えてはなりません。各反復の後、メタモデルによって偽(またはゼロ)と分類されたすべての例は、基本モデルの訓練標本から削除されます。一方、メタモデルは、すべての例について訓練を続けます。
このアプローチの背後にある直感は、負けトレードは、混同行列の用語を使えば、基礎となるモデルのクラスIの分類エラーであるということです。つまり、このようなケースを誤検出と判断します。メタモデルでは、このようなケースをフィルタリングし、真陽性には1を、それ以外には0をスコアとして与えます。基本モデルを訓練するためのデータセットをメタモデルを介して並び替えすることで、その精度、すなわち正しい売買トリガーの数を増加させます。同時に、メタモデルはできるだけ多くの異なる結果を分類してリコール(完全性)を向上させます。
その精度が高いほど、モデルの精度も高くなります。ただし、実際の現場では、同じ分類器の中で、ある指標が改善されると別の指標が悪化することがあるので、2つの分類器の束を使うことは、両方の指標を改善することにつながる面白いアイデアだと思います。
2つのモデルは、同じ属性で訓練されるためにさらなる相互作用があるという考え方です。メタモデルの選択が増えたため(橙色の横列に比べ青色の横列)、まるで基本モデルの誤差を新しいデータで整理したかのように、良い取引状況が残ります。モデルは互いに作用し、再ラベル化により反復的に改善され、検証セットでのR^2スコアは常に増加します。ただし、メタモデルは基本モデルに対するフィルターとして、自身の属性について訓練させることができます。このような接続は、提案するアプローチの枠組みに全く当てはまらないので、ここでは考慮しません。
基本となるモデルはメタモデルの絶え間ない「メンテナンス」によってうまく機能するはずですが、メタモデル自体も間違っていることがあります。例えば、反復の1回目では取引に適さないケースが発見されました。2回目の反復では、基本モデルを再訓練し、メタモデル用の例を調整した後、悪い例が前の反復のものと異なる場合があります。このため、メタモデルでは、反復ごとに異なる例を常に再ラベル化する傾向があります。この挙動は、決してバランスされないかもしれません。この欠点を解決するために、「不良標本ブック」の表を作成し、過去のすべての反復の例を更新するようにします。具体的には、過去のすべての訓練反復において、取引に不利と判断された時間帯の特徴量を記憶します。これにより、各再訓練の前に、以前の反復で失敗したすべてのモーメントも悪い(ゼロ)としてマークされるように、メタモデルのデータセットを更新することができます。
また、「不良標本ブック」には、反復回数が多すぎるとゼロ(悪い取引)が増えすぎてしまうという欠点があります。新しい訓練反復のたびに、例の数は大幅に減少します。そのため、反復回数と不良標本ブックに追加する例数のバランスをとる必要があります。この状況は、悪い例の数を発生時間によって平均化し、最も多いものだけを選別することで部分的に解決することができます。この場合、メタモデルのデータセットが縮退することはありません(0と1のバランスは保たれます)。クラスが大きくバランスを失している場合は、オーバーサンプリングを使用するとよいでしょう。
何度か繰り返すうちに、このモデル群は訓練データと検証データで優れた結果を示すようになります。しかも、反復ごとに結果が改善されます。訓練後、モデルの束を完全に新しいデータでテストする必要があります。このデータは、時間的に訓練用サブ標本よりも前でも後でも構いません。非定常な金融時系列のテストにおいて、履歴のどの部分を選択すべきかを明確に示すことができる理論は存在しません。とはいえ、新しいデータに対する提案された手法のパフォーマンスの向上は期待できますし、あとは実戦で発揮されるでしょう。
1つのモデルを訓練させ、新しいデータで別のモデルでその誤差を修正する、このプロセスを何度か繰り返します。なぜ、新しいデータに対する分類器の頑健性を高める必要があるのでしょうか。この問いに対する答えはひとつではありません。ある種のパターンを扱っているという前提があります。存在すれば発見され、パターンのない状況は整理されます。そのパターンが安定していれば、新しいデータでもモデルは機能します。
理論的には、一石二鳥の方法です。
- 収益性の高い取引を期待できる
- 効果的なタイミングでのみ売買をおこなう、自動「タイミング」をおこなう
取引システムのタイミングの話なので、もう1つ興味深い点に触れておきましょう。これで、モデルの属性(特徴)の選択への依存度が低くなりました。
基本的なアプローチと教師ありマークアップは、予測因子とターゲットの綿密な選択を意味します。実は、これがこの手法の最大の問題点です。データの準備と分析が常に最優先され、モデルの質は特定の分野(私たちの場合は為替)でのアナリストのプロ意識に直接依存します。
提案するアプローチでは、相互に関連するタイミング、予測因子、ラベルイベントを自動的に見つけ、自動的に見つけられたパターンを利用します。予測因子の選択と案件のラベル付けは自動的におこなわれます。例えば、属性は定常的なものでなければならず、金融商品と少なくとも間接的な関係がなければなりません。ただし、本当のパターンがわからず、情報を得る場所もない状況では、この方法は正当化されるように思えます。
もちろん、案件と因果関係のない「ゴミ」のような属性を扱うと、アルゴリズムはランダムに動作することになります。しかし、これはすでにそのような因果関係の有無の問題です。この記事では、増分(移動平均と価格の差)以外の特徴の構築については、別の巨大なテーマであり、他の記事で検討される可能性があるため、意図的に考慮していません。情報量の多い特徴を選択するための分析的アプローチは、新しいデータに対するアルゴリズムの安定性を大幅に向上させるはずだと想定します。
提案された手法の実際の実装
いつもながら、理論的にはすべてが素晴らしく見えます。次に、実際に2つの分類器の束からどのような効果が得られるかを確認してみましょう。そのためには、もう一度、コードを書き直す必要があります。
取引自動マークアップの機能
少し変更しました。これで、基本モデルのラベルをメタモデルのラベルに基づいて再ラベル化することが可能になります。
def labelling_relabeling(dataset, min=15, max=15, relabeling=False) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'][i] future_pr = dataset['close'][i + rand] if relabeling: m_labels = dataset['meta_labels'][i:rand+1].values if relabeling and 0.0 in m_labels: labels.append(2.0) else: if future_pr + MARKUP < curr_pr: labels.append(1.0) elif future_pr - MARKUP > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2].index) return dataset
ハイライトされたコードでrelabelフラグの有無をチェックします。もしこれがtrueで、現在の取引水平線メタタグがゼロを含んでいる場合、メタモデルはこのセクションでの取引を拒否します。したがって、そのような取引は2.0とマークされ、データセットから削除されます。このように、基本モデルの訓練用標本から不要な標本を繰り返し除去することで、訓練誤差を低減することができるのです。
カスタムテスター関数
現在、2つのモデル(基本とメタ)を同時にテストできる拡張関数があります。また、カスタムテスターは、次の反復でメタモデルを改善するために、メタモデルのラベルを再ラベル化することができるようになりました。
def tester(dataset: pd.DataFrame, markup=0.0, use_meta=False, plot=False): last_deal = int(2) last_price = 0.0 report = [0.0] meta_labels = dataset['labels'].copy() for i in range(dataset.shape[0]): pred = dataset['labels'][i] meta_labels[i] = np.nan if use_meta: pred_meta = dataset['meta_labels'][i] # 1 = allow trades if last_deal == 2 and ((use_meta and pred_meta==1) or not use_meta): last_price = dataset['close'][i] last_deal = 0 if pred <= 0.5 else 1 continue if last_deal == 0 and pred > 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 continue if last_deal == 1 and pred < 0.5 and ((use_meta and pred_meta==1) or not use_meta): last_deal = 2 report.append(report[-1] - markup + (last_price - dataset['close'][i])) if report[-1] > report[-2]: meta_labels[i] = 1 else: meta_labels[i] = 0 y = np.array(report).reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = lr.coef_ if l >= 0: l = 1 else: l = -1 if(plot): plt.plot(report) plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l,".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l, meta_labels.fillna(method='backfill')
テスターは次のように動作します。
テスト中にメタモデルを考慮するフラグが設定されている場合、そのシグナルが存在する条件(1)を確認します。シグナルが存在する場合、基本モデルは取引の開始と終了を許可され、そうでない場合は取引をおこないません。薄緑のマーカーは、決済済み取引の結果に応じたメタモデルへの新しいラベルの追加をハイライトしています。結果が正であれば、1が追加されます。それ以外の場合、取引は0(不成立)とマークされます。
ブルートフォース関数
一番大きく変わったのはここです。コードを色分けしてマークして、より分かりやすく説明します。
def brute_force(dataset, bad_samples_fraction=0.5): # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels']==1] X = dataset[dataset.columns[:-2]] X = X[X.index >= START_DATE] X = X[X.index <= STOP_DATE] X_meta = dataset[dataset.columns[:-2]] X_meta = X_meta[X_meta.index >= TSTART_DATE] X_meta = X_meta[X_meta.index <= STOP_DATE] # labels for model\meta models y = dataset[dataset['meta_labels']==1] y = dataset[dataset.columns[-2]] y = y[y.index >= START_DATE] y = y[y.index <= STOP_DATE] y_meta = dataset[dataset.columns[-1]] y_meta = y_meta[y_meta.index >= TSTART_DATE] y_meta = y_meta[y_meta.index <= STOP_DATE] # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.5, test_size=0.5, shuffle=True,) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # train\test split train_X, test_X, train_y, test_y = train_test_split( X_meta, y_meta, train_size=0.5, test_size=0.5, shuffle=True) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.1, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', random_seed=13) meta_model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=50, plot=False) # predict on new data (validation plus learning) pr_tst = get_prices() X = pr_tst[pr_tst.columns[1:]] X.columns = [''] * len(X.columns) X_meta = X.copy() # predict the learned models (base and meta) p = model.predict_proba(X) p_meta = meta_model.predict_proba(X_meta) p2 = [x[0] < 0.5 for x in p] p2_meta = [x[0] < 0.5 for x in p_meta] pr2 = pr_tst.iloc[:len(p2)].copy() pr2['labels'] = p2 pr2['meta_labels'] = p2_meta pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) full_pr = pr2.copy() pr2 = pr2[pr2.index >= TSTART_DATE] pr2 = pr2[pr2.index <= STOP_DATE] # add bad samples of this iteratin (bad meta labels) global BAD_SAMPLES_BOOK BAD_SAMPLES_BOOK = BAD_SAMPLES_BOOK.append(pr2[pr2['meta_labels']==0.0].index) # test mdels and resample meta labels R2, meta_labels = tester(pr2, MARKUP, use_meta=True, plot=False) pr2['meta_labels'] = meta_labels # resample labels based on meta labels pr2 = labelling_relabeling(pr2, relabeling=True) pr2['labels'] = pr2['labels'].astype(float) pr2['meta_labels'] = pr2['meta_labels'].astype(float) # mark bad labels from bad_samples_book if BAD_SAMPLES_BOOK.value_counts().max() > 1: to_mark = BAD_SAMPLES_BOOK.value_counts() mean = to_mark.mean() marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index pr2.loc[pr2.index.isin(marked_idx), 'meta_labels'] = 0.0 else: pr2.loc[pr2.index.isin(BAD_SAMPLES_BOOK), 'meta_labels'] = 0.0 R2, _ = tester(full_pr, MARKUP, use_meta=True, plot=False) return [R2, model, meta_model, pr2]
BAD_SAMPLES_BOOKと適切なマーカーでハイライトされた残りのコードは、不良標本ブックの実装を担当します。2つのモデルの再訓練を新たに繰り返すごとに、前のモデルが訓練後に開いた失敗した案件の新しい事例が補充されます。検証はテスターを使用しておこないます。
最後のハイライトされたブロックは、失敗例のどの部分を次回の再訓練で0とするかによって柔軟に設定することができます。デフォルトでは、ワークブックに含まれる各日付の全重複の平均が計算されます。
marked_idx = to_mark[to_mark > mean*bad_samples_fraction].index これは、すべての不良な付を削除するのではなく、すべての訓練反復を通過している間にモデルが最も誤りを犯した日付だけを削除するためにおこなわれます。bad_samples_fractionパラメータ値が大きいほど、削除される不良な日付が少なくなり、その逆も同じです。
青色は、START_DATEから始まるデータセットの一部を短縮して基本モデルに使用していることを示します。それ以前のデータは、その訓練に参加していません。ただし、メタモデルの訓練には参加します。また、この色はBaseとMetaの2種類のモデルが訓練されていることを表しています。
桃色は、両モデルの予測値が抽出された部分をハイライトしています。これらの予測値を用いて、新しいデータセットが形成されます。データセットは、コードを通してさらにプッシュされます。また、不良メタモデルのラベルは、そこから不良標本ブックにも追加されます。
その後、両モデルはカスタムテスターでテストされ、さらに次の訓練イテレーションに向けてメタモデルのラベルを再ラベル化(調整)します。補正されたデータセットに対して、基本モデルに対してさらに再ラベリングがおこなわれます。
最終段階では,不良標本を使ってデータセットが追加調整され,次の訓練反復のために関数によって返されます.
Pythonコードの量は多いですが、入れ子ループがないことや最適化の実行により、高速に動作します。CatBoost分類器の訓練には、ほとんどの時間がかかります。訓練時間は、属性数およびデータセット長の増加に伴って増加します。
モデルの反復的な再訓練
以上が、新しいアプローチの主な内容です。さて、いよいよモデルの訓練サイクルに移行します。各段階で起こることをすべて見てみましょう。
# make dataset
pr = get_prices()
pr = labelling_relabeling(pr, relabeling=False)
a, b = tester(pr, MARKUP, use_meta=False, plot=False)
pr['meta_labels'] = b
pr = pr.dropna()
pr = labelling_relabeling(pr, relabeling=True)
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
最初の2つの文字列は、前の記事の例と同じように、単に訓練データセットを作成するものです。
>>> pr = get_prices(START_DATE, STOP_DATE) >>> pr = labelling_relabeling(pr, relabeling=False) >>> pr close 0 1 2 3 4 5 6 labels time 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 -0.002396 -0.004554 -0.007759 -0.009549 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 -0.002664 -0.004900 -0.008039 -0.009938 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 -0.003494 -0.005663 -0.008761 -0.010778 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 -0.003380 -0.005485 -0.008559 -0.010684 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 -0.002873 -0.004894 -0.007929 -0.010144 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 23:00:00 1.19474 0.000154 0.002590 0.003375 0.003498 0.004095 0.004273 0.004888 0.0 2021-04-14 00:00:00 1.19492 0.000108 0.002337 0.003398 0.003565 0.004183 0.004410 0.005001 0.0 2021-04-14 01:00:00 1.19491 -0.000038 0.002023 0.003238 0.003433 0.004076 0.004353 0.004908 0.0 2021-04-14 02:00:00 1.19537 0.000278 0.002129 0.003534 0.003780 0.004422 0.004758 0.005286 0.0 2021-04-14 03:00:00 1.19543 0.000356 0.001783 0.003423 0.003700 0.004370 0.004765 0.005259 0.0 [5670 rows x 9 columns]
ここで、メタモデルのラベルを追加する必要があります。覚えているかもしれませんが、tester()関数は、R^2スコアとラベル付き取引を持つフレームを返します。そこで、テスターを実行し、結果のフレームを元データに追加します。
>>> a, b = tester(pr, MARKUP, use_meta=False, plot=False) >>> pr['meta_labels'] = b >>> pr = pr.dropna() >>> pr close 0 1 2 ... 5 6 labels meta_labels time ... 2020-05-06 20:00:00 1.08086 0.000258 -0.000572 -0.001667 ... -0.007759 -0.009549 1.0 1.0 2020-05-06 21:00:00 1.08032 -0.000106 -0.000903 -0.002042 ... -0.008039 -0.009938 1.0 1.0 2020-05-06 22:00:00 1.07934 -0.001020 -0.001568 -0.002788 ... -0.008761 -0.010778 1.0 1.0 2020-05-06 23:00:00 1.07929 -0.000814 -0.001319 -0.002624 ... -0.008559 -0.010684 1.0 1.0 2020-05-07 00:00:00 1.07968 -0.000218 -0.000689 -0.002065 ... -0.007929 -0.010144 1.0 1.0 ... ... ... ... ... ... ... ... ... ... 2021-04-13 18:00:00 1.19385 0.001442 0.003437 0.003198 ... 0.003637 0.004279 0.0 1.0 2021-04-13 19:00:00 1.19379 0.000546 0.003121 0.003015 ... 0.003522 0.004166 0.0 1.0 2021-04-13 20:00:00 1.19423 0.000622 0.003269 0.003349 ... 0.003904 0.004555 0.0 1.0 2021-04-13 21:00:00 1.19465 0.000820 0.003315 0.003640 ... 0.004267 0.004929 0.0 1.0 2021-04-13 22:00:00 1.19552 0.001112 0.003733 0.004311 ... 0.005092 0.005733 1.0 1.0 [5665 rows x 10 columns]
これで訓練に必要なデータが揃いました。2番目のラベル(meta_labels)に従って、主ラベル(labels)の再ラベル化を追加でおこないます。つまり、採算が合わないことが判明した取引は、すべてデータセットから削除することができます。
pr = labelling_relabeling(pr, relabeling=True) データの準備ができたので、次に両モデルの訓練サイクルを見てみましょう。
# iterative learning
res = []
BAD_SAMPLES_BOOK = pd.DatetimeIndex([])
for i in range(25):
res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.7))
print('Iteration: {}, R^2: {}'.format(i, res[-1][0]))
pr = res[-1][3]
まず、前回の訓練で不良なものがが残っていた場合、不良ブックをリセットする必要があります。次に、ループ内で必要な反復回数を設定します。各反復では、保存されたモデル(およびbrute_force()関数が返す他のすべて)を含むネストされたリストがres[]リストに書き込まれます。例えば、各反復におけるモデルの主要な指標を追加で表示することができます。
pr変数には、変換されて返されたデータセットが格納され、次の反復で訓練に使用されます。
理論編で提案したように、基本モデルの訓練期間を長くすることは可能です。そのために、訓練の開始日を指定された日数分変更します。同時に、そのサイズはメタモデルの訓練対象となるTSTART_DATE 間隔のサイズを超えないようにします。
訓練を起動すると、次の図のようなものが表示されます。
Iteration: 0, R^2: 0.30121038659012245 Iteration: 1, R^2: 0.7400055934041012 Iteration: 2, R^2: 0.6221261327516192 Iteration: 3, R^2: 0.8892813889403367 Iteration: 4, R^2: 0.787251984980149 Iteration: 5, R^2: 0.794241109825588 Iteration: 6, R^2: 0.9167876214355855 Iteration: 7, R^2: 0.903399695678254 Iteration: 8, R^2: 0.8273236332747745 Iteration: 9, R^2: 0.8646088124681762 Iteration: 10, R^2: 0.8614746864767437 Iteration: 11, R^2: 0.7900599001415054 Iteration: 12, R^2: 0.8837049280116869 Iteration: 13, R^2: 0.784793801426211 Iteration: 14, R^2: 0.941340102099874 Iteration: 15, R^2: 0.8715065229034792 Iteration: 16, R^2: 0.8104990158946458 Iteration: 17, R^2: 0.8542444489379808 Iteration: 18, R^2: 0.8307365677342298 Iteration: 19, R^2: 0.9092509787525882
1回目は大抵、あまり良い出来ではありません。そして、新しいパスを通過するたびに、モデルは自身を改善しようとします。その後、モデルはR^2の昇順に並び替えされ、新しいデータに対してテストすることができます。すぐに並び替えを使うのではなく、まずはモデルの進化を見ることもあります。進化の特徴的な兆候は、モデルをテストする際の案件数が減少していることです。
例えば、前回訓練したモデルをテストしたところ、次のような結果が得られました(結果はすべて新しいデータに基づいています)。
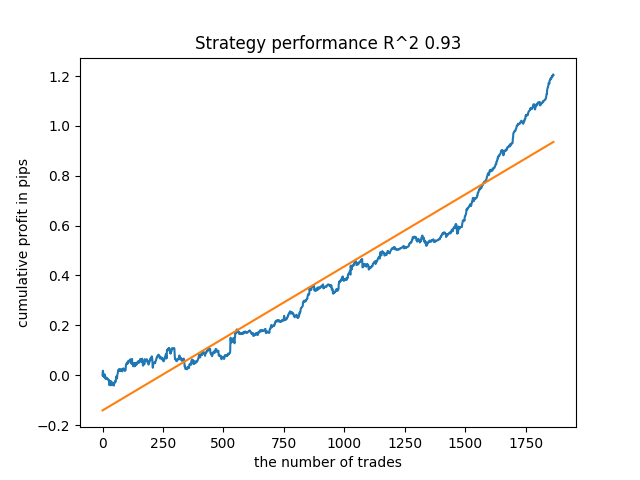
最後から5番目のモデルにはもっと取引がある、といった具合です。
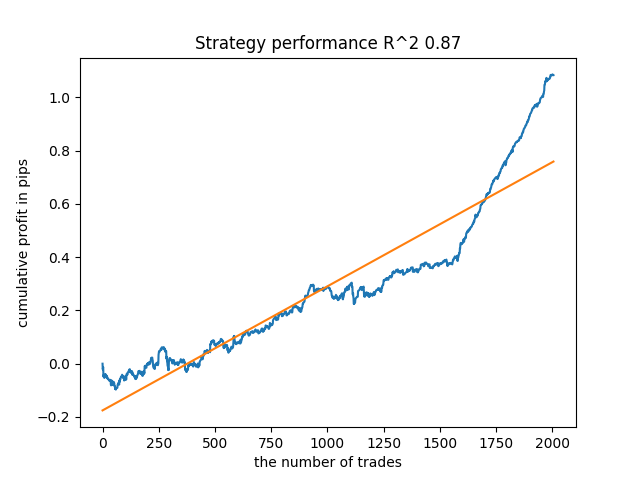
反復回数とbad_samples_fractionパラメータ、および訓練標本とテスト標本のサイズに依存し、新しいデータで安定したモデルを得ることができます。このアイデアは、理解して実装するのはかなり難しいですが、おおむねうまくいきました。use_GMM_resamplingパラメータを有効にした場合も、ほぼ同じ状況が発生しました。取引数は直接的に反復回数に依存しますが、例外もあり得ます。リサンプリングには訓練時間がかかりすぎ、アプローチを適用してもあまり結果が改善されないので、ライブラリから削除しました。
例えば、最後から5番目の結果が良好でした。
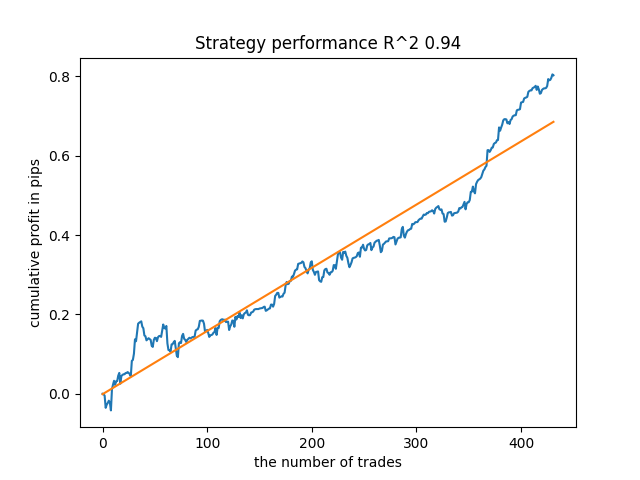
しかし、7番目の結果では取引の数が2倍となり、より好ましくなりました。また、ポイント単位での利益総額も増加しました。
モデルをMQL5形式にエクスポートし、取引EAをコンパイルします。
基本モデルとメタモデルの2つのモデルが保存されるようになりました。従来通り、基本モデルは売買シグナルを制御し、メタモデルはある時点の売買を禁止または許可するものです。
# add CatBosst base model code += 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n' # add CatBosst meta model code += 'double catboost_meta_model' + '(const double &features[]) { \n' code += ' ' with open('meta_catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth") :data.find("double Scale = 1;")] code += '\n\n' code += 'return ' + \ 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
取引EAを若干変更しました。シグナルを生成するcatboost_meta_model()関数が呼び出されます。0.5を超えると取引が可能になります。
void OnTick() { //--- if(!isNewBar()) return; TimeToStruct(TimeCurrent(), hours); double features[]; fill_arays(features); if(ArraySize(features) !=ArraySize(MAs)) { Print("No history availible, will try again on next signal!"); return; } double sig = catboost_model(features); double meta_sig = catboost_meta_model(features); // close positions by an opposite signal if(meta_sig > 0.5) if(count_market_orders(0) || count_market_orders(1)) for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } // open positions and pending orders by signals if(meta_sig > 0.5) if(countOrders() == 0 && CheckMoneyForTrade(_Symbol,LotsOptimized(),ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig < 0.5) { OrderSend(Symbol(),OP_BUY,l, Ask, 0, Bid-stoploss*_Point, Ask+takeprofit*_Point, NULL, OrderMagic); } else { OrderSend(Symbol(),OP_SELL,l, Bid, 0, Ask+stoploss*_Point, Bid-takeprofit*_Point, NULL, OrderMagic); } } }
追加
MACユーザーとLinuxユーザーは、相場読み込み用のターミナルAPIを利用できません。MetaTrader 5ターミナルからファイルに読み込まれた相場を受け入れる別の関数を使用することをお勧めします。ファイルは作業ディレクトリに保存されます。
def get_prices() -> pd.DataFrame:
p = pd.read_csv('EURUSDMT5.csv', delim_whitespace=True)
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], infer_datetime_format=True)
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
pFixed = pFixed.dropna()
pFixedC = pFixed.copy()
count = 0
for i in MA_PERIODS:
pFixed[str(count)] = pFixedC - pFixedC.rolling(i).mean()
count += 1
return pFixed.dropna()
現在、3つの日付が使われているので、バックテストとフォワードテストの両方でモデルを並び替えすることが可能になりました。フォワードの開始は、グローバル変数STOP_DATEで設定します。この日付以降のデータは、訓練に使用されません。その代わり、テストに使用されることになります。同様に、TSTART_DATE以前はすべてバックテストです。
START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2017, 1, 1) STOP_DATE = datetime(2022, 1, 1)
基本モデルはSTART_DATE~STOP_DATEの期間で訓練され、メタモデルはTSTART_DATE~ STOP_DATEのデータで訓練されます。ファイルに残っている他のデータは、バックテストとフォワードテストにのみ参加します。
その他のテスト
提案した訓練方法を、あるクロスレート、例えばGBPJPYのH1でテストすることにしました。2010年からの相場は、ターミナルからダウンロードしたものです。訓練用の属性数および期間は以下の通りです。
MA_PERIODS = [i for i in range(15, 500, 15)] MARKUP = 0.00002 START_DATE = datetime(2021, 1, 1) TSTART_DATE = datetime(2018, 1, 1) STOP_DATE = datetime(2022, 1, 1)
基本モデルは2021年から2022年初頭まで、メタモデルは2018年から2022年まで訓練します。それ以外のデータは、2010年から2022.06.15までの新しいデータでのテストに使用されます。
取引期間が15~35日の範囲内でランダムに選択されたサンプリング。
def labelling_relabeling(dataset, min=15, max=35, relabeling=False):
25回の訓練反復が選ばれます。例ブックの不良例の倍率は0.5倍と同じです。
# iterative learning res = [] BAD_SAMPLES_BOOK = pd.DatetimeIndex([]) for i in range(25): res.append(brute_force(pr[pr.columns[1:]], bad_samples_fraction=0.5)) print('Iteration: {}, R^2: {}'.format(i, res[-1][0])) pr = res[-1][3] # test best model res.sort() p = test_model(res[-1])
訓練時、2010年以降の全データセットについて、以下のR^2スコアが得られました。
Iteration: 0, R^2: 0.8364212812476872 Iteration: 1, R^2: 0.8265960950867208 Iteration: 2, R^2: 0.8710535097094494 Iteration: 3, R^2: 0.820894300254345 Iteration: 4, R^2: 0.7271704621597865 Iteration: 5, R^2: 0.8746302835797399 Iteration: 6, R^2: 0.7746283871087961 Iteration: 7, R^2: 0.870806543378866 Iteration: 8, R^2: 0.8651222653557956 Iteration: 9, R^2: 0.9452164577256995 Iteration: 10, R^2: 0.867541289963404 Iteration: 11, R^2: 0.9759544230548619 Iteration: 12, R^2: 0.9063804006221455 Iteration: 13, R^2: 0.9609701853129079 Iteration: 14, R^2: 0.9666262255426672 Iteration: 15, R^2: 0.7046628448822643 Iteration: 16, R^2: 0.7750941894554821 Iteration: 17, R^2: 0.9436968900331276 Iteration: 18, R^2: 0.8961403809578388 Iteration: 19, R^2: 0.9627553719743711 Iteration: 20, R^2: 0.9559809326980575 Iteration: 21, R^2: 0.9578579606050637 Iteration: 22, R^2: 0.8095556721129047 Iteration: 23, R^2: 0.654147043077418 Iteration: 24, R^2: 0.7538928969905255
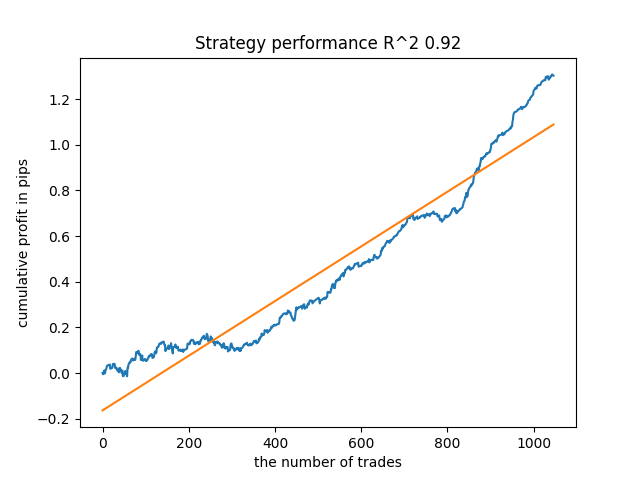
次に、R^2が高い順にモデルを並べ替えました。その中から、スコアの高い順に紹介します。
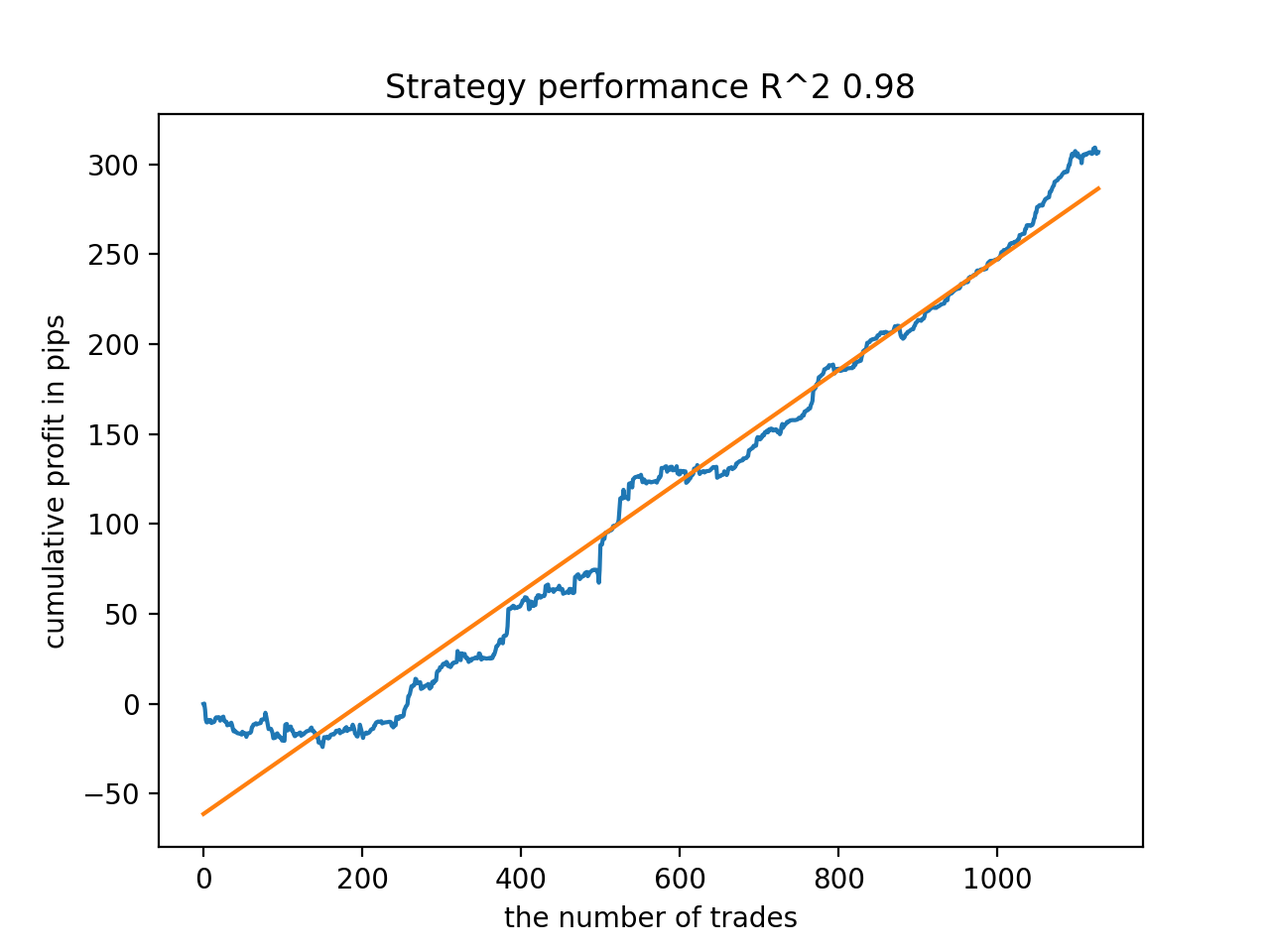
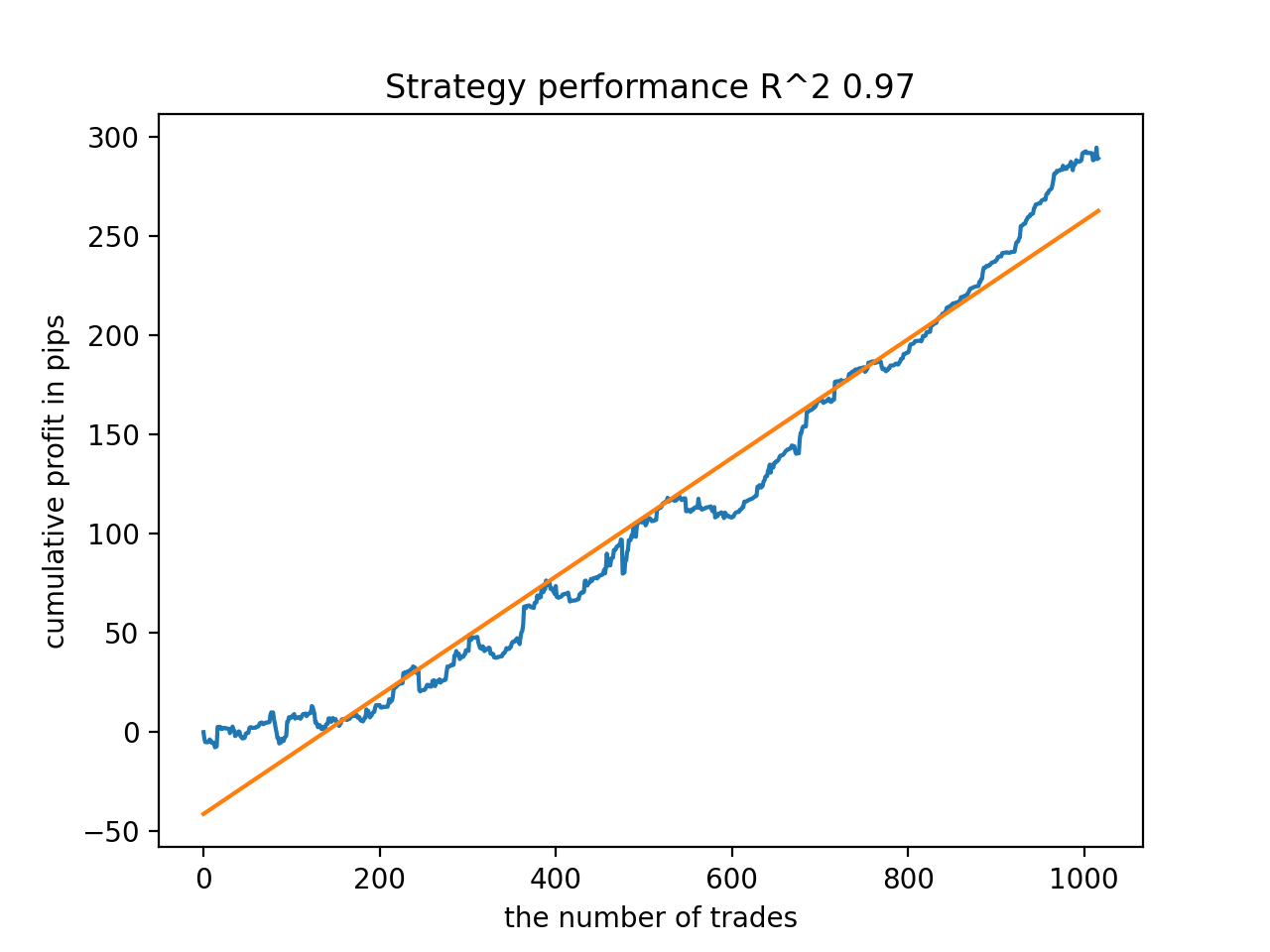
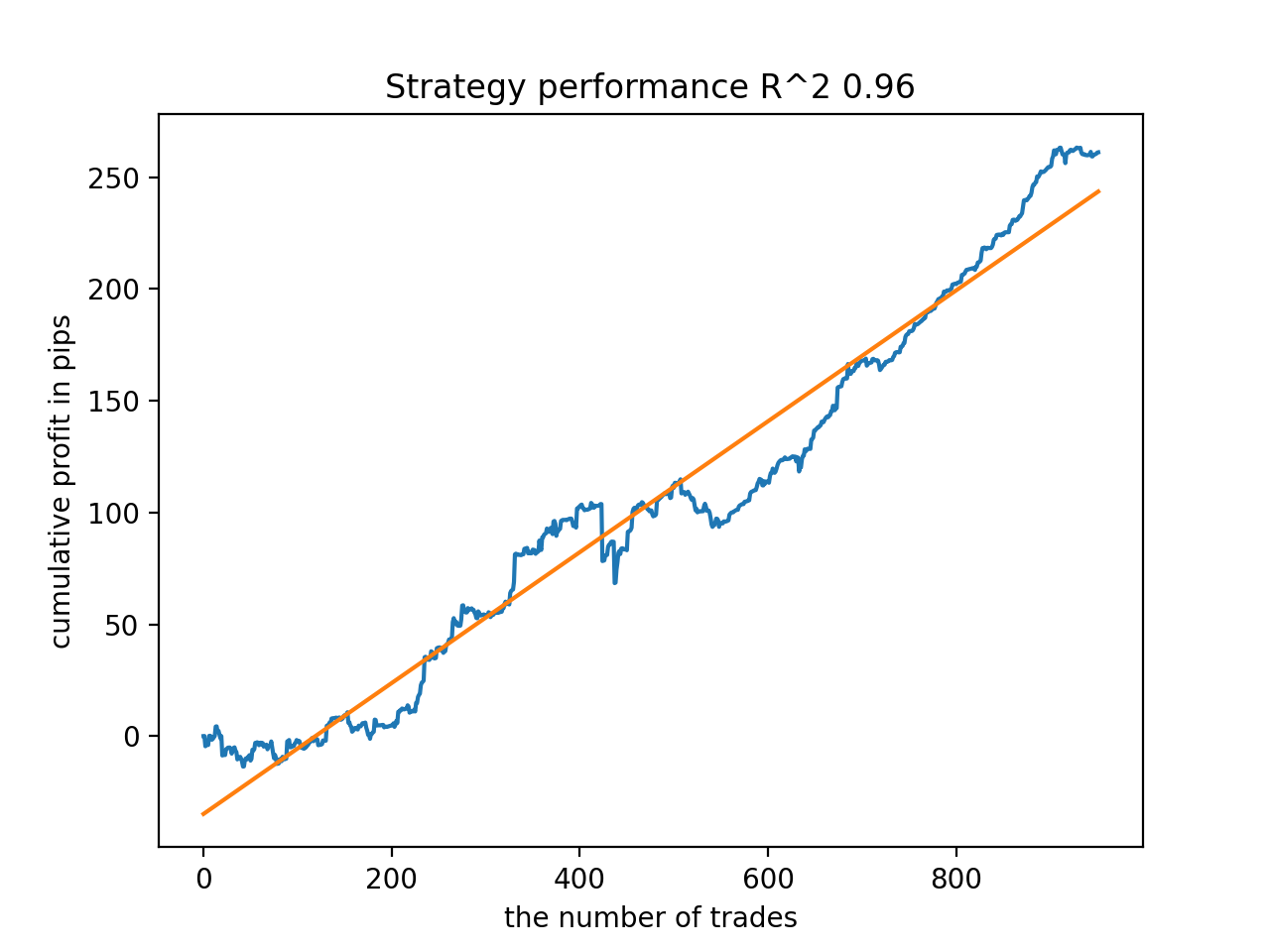
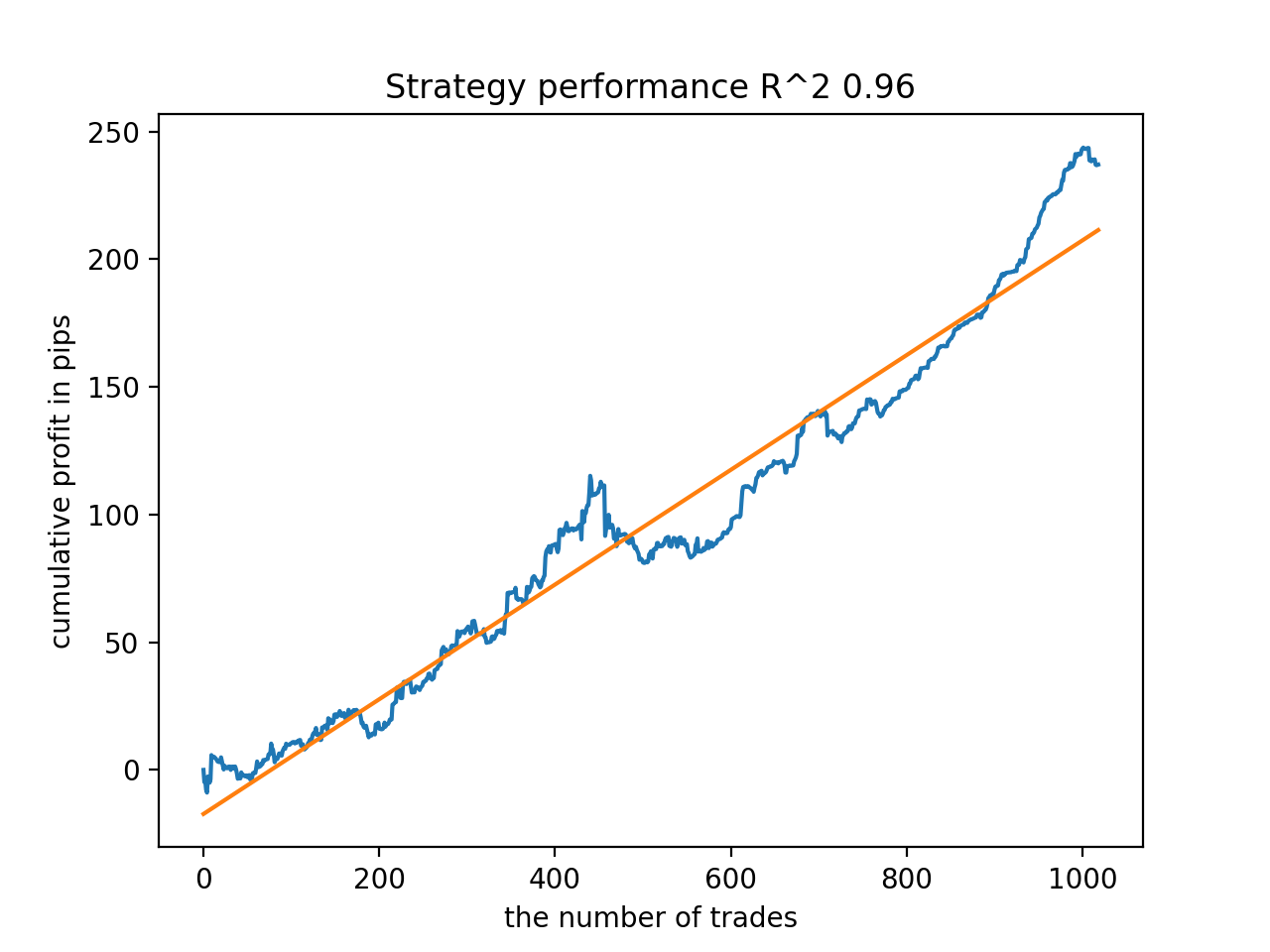
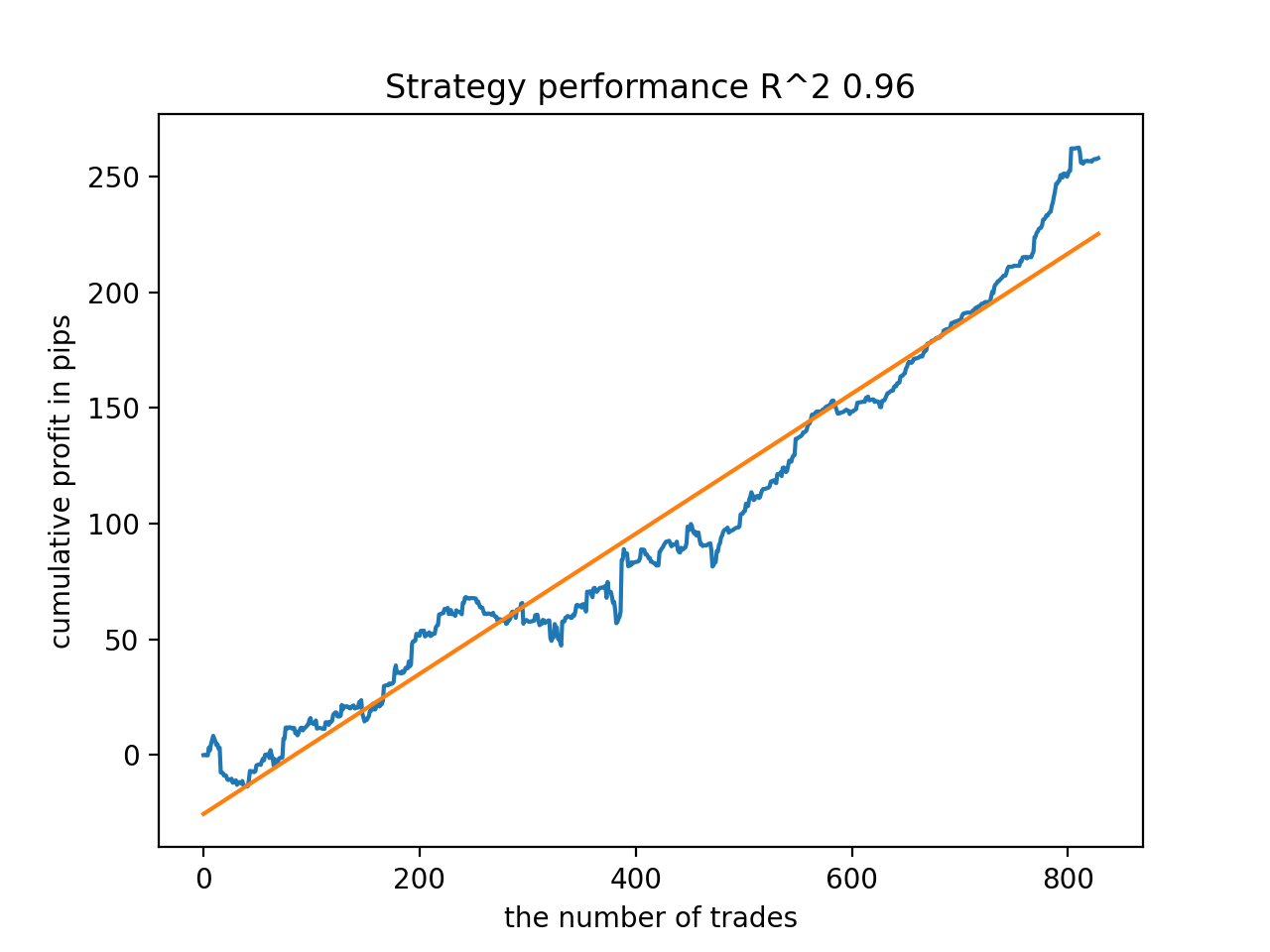
グラフは完全な曲線ではないが、どのパターンも2010年以降、おおむね安定します。
最終段階では、追加テストや取引に使用するために、関心のあるモデルをMetaTrader 5にエクスポートします。エクスポート機能は、入力としてモデル(この場合は最後から最良)を受け取り、ファイル名を変更することで複数のモデルを同時に記録することができます。
export_model_to_MQL_code(res[-1], str(1))
ボットをコンパイルし、MetaTrader 5ストラテジーテスターで確認します。
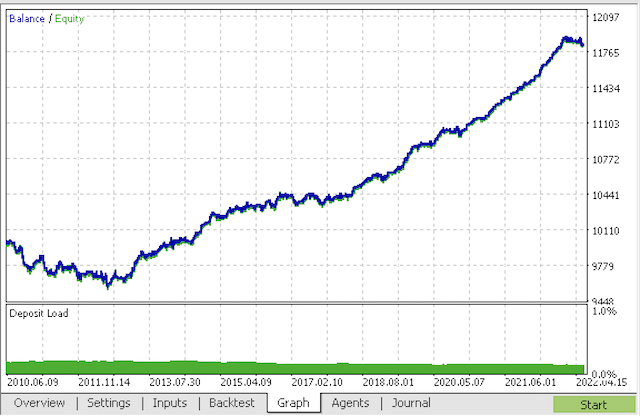
最終段階では、すでに使い慣れたMetaTrader 5ターミナルでモデルを操作することができます。
結論
この記事では、私がこれまで実装しなければならなかった中で、おそらく最も複雑で高度な時系列分類モデルを実証しています。興味深いのは、分類が難しい履歴の断片をメタモデルを使って自動的に取捨選択できる点です。このようなモデルは、季節的なサイクルが強く顕著な特定の時間帯や特定の曜日に取引するように訓練された季節モデルよりも優れていることさえあります。ここでは、人手を介さずに自動的に仕分けがおこなわれます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/9138
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
 一からの取引エキスパートアドバイザーの開発(第19部):新規受注システム(II)
一からの取引エキスパートアドバイザーの開発(第19部):新規受注システム(II)
 一からの取引エキスパートアドバイザーの開発(第20部):新規受注システム(III)
一からの取引エキスパートアドバイザーの開発(第20部):新規受注システム(III)
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
僕のコードは元のコードより少し速く動くよ :)だからトレーニングはさらに速くなる。でも、GPUを使っています。
これがコードのバグなのかどうか明らかにしてください。
正しい式は
そうでなければ、1行目は単に意味がありません。なぜなら、2行目ではデータコピーの条件が再度実行され、メタモデルのターゲット「1」によるフィルタリングなしにコピーされるからです。
私はまだ勉強中で、このpythonについて間違っている可能性があります。
はい、あなたのコードは正しいです。
私はまた、より速く、少し異なるバージョンを持っている、私はそれをmbの記事としてアップロードしたかった。はい、お気づきの通り、あなたのコードは正しいです。
私はまた、より高速で、少し異なるバージョンを持っている、私はそれをmbの記事としてアップロードしたかった。書いてみてください。
私はトレーニングで得ることができた最高の。
そして、これは別のサンプルです
私は訓練を通して初期化のプロセスを追加しました。
書けば面白くなる。
トレーニングで一番良かったのは
そして、これは別のサンプルで
トレーニングによる初期化のプロセスを追加しました。
パイソン 。
私は専門家ではありませんが、すべて「辞書」を使っています。
私はこのアプローチの効果を知りたかったのです。今のところ、それがあるのかどうかは分かっていません。一般的に、CatBoostは"マジック "なしでサンプルに対してトレーニングされる。したがって、私はより表現力豊かな結果を期待していました。
辞書があれば何でもわかるとは言わない。
私はこのアプローチの効果を知りたかった。今のところ、それがあるのかどうか気づいていない。つまり、CatBoostは「マジック」なしで、一般的にサンプルに対して学習される。そのため、もっと表現力豊かな結果を期待していた。