
Simulador rápido de estrategias comerciales en Python usando Numba
Por qué es importante tener un simulador rápido de estrategias propio
Al desarrollar algoritmos comerciales basados en el aprendizaje automático, resulta importante evaluar correcta y rápidamente sus resultados comerciales en la historia. Si consideramos un uso poco frecuente del simulador en grandes intervalos de tiempo y con una profundidad de historia pequeña, el simulador de Python resultará bastante adecuado. Si la tarea consiste en realizar múltiples pruebas, incluidas estrategias de alta frecuencia, el lenguaje interpretado podría ser demasiado lento.
Supongamos que no estamos satisfechos con la velocidad de ejecución de algunos scripts, pero no queremos renunciar a nuestro conocido entorno de desarrollo Python. Aquí es donde entra en juego Numba, que nos permitirá traducir y compilar código Python nativo a código máquina rápido sobre la marcha, con velocidades de ejecución comparables a las de lenguajes de programación como C y FORTRAN.
Breve descripción de la biblioteca Numba
Numba es una biblioteca para el lenguaje de programación Python diseñada para acelerar la ejecución del código mediante la compilación de funciones a nivel de bytecode en código máquina utilizando la compilación JIT (Just-In-Time). Esta tecnología puede mejorar notablemente el rendimiento computacional, sobre todo en aplicaciones científicas en las que suelen usarse ciclos y operaciones matemáticas complejas. La biblioteca permite operar con arrays NumPy y trabajar de forma eficiente usando paralelismos y cálculos en la GPU.
La forma más común de usar Numba es aplicar su colección de decoradores a las funciones de Python para indicarle a Numba que las compile. Cuando se llama a una función decorada con Numba, esta se compila en código máquina "just-in-time" para que el código completo o parte del mismo pueda ejecutarse a la velocidad del código máquina nativo.
Actualmente se admiten las siguientes arquitecturas:
-
OS: Windows (64 bit), OSX, Linux (64 bit).
-
Architecture: x86, x86_64, ppc64le, armv8l (aarch64), M1/Arm64.
-
GPUs: Nvidia CUDA.
-
CPython
-
NumPy 1.22 - 1.26
Debemos tener en cuenta que el paquete Pandas no está soportado por la librería Numba, y el trabajo con dataframes se realizará a la misma velocidad.
Trabajando con los códigos del artículo
Para que todo funcione directamente, siga los pasos preliminares:
- instale todos los paquetes necesarios;
pip install numpy pyp install pandas pip install catboost pip install scikit-learn pip install scipy
- descargue los datos de EURGBP_H1.csv y colóquelos en la carpeta Files;
- descargue todos los scripts de python y póngalos en una carpeta;
- Corrija la primera línea del script Tester_ML.py para que sea así : from tester_lib import test_model;
- escriba la ruta al archivo en el script Tester_ML.py;
- p = pd.read_csv('C:/Program Files/MetaTrader 5/MQL5/Files/'EURGBP_H1'.csv', sep='\s+').
¿Cómo se usa el paquete Numba?
En general, para utilizar el paquete Numba bastará con instalarlo
pip install numba conda install numba
y aplicar un decorador delante de la función que queremos acelerar, por ejemplo
@jit(nopython=True) def process_data(*args): ...
La llamada a un decorador se realizará de dos formas diferentes.
- nopython mode
- object mode
El primer método consiste en compilar la función decorada para que funcione completamente sin el intérprete de Python. Esta es la forma más rápida y la recomendable. Sin embargo, Numba tiene limitaciones, por ejemplo, solo puede compilar las operaciones incorporadas de Python y las operaciones de array de Numpy. Si la función contiene objetos de otras librerías, como Pandas, Numba no podrá compilarla, y el código será ejecutado por el intérprete.
Para evitar restricciones al usar bibliotecas de terceros, Numba puede utilizar el modo objeto (object mode). En este modo, Numba compilará la función asumiendo que todo es un objeto de Python, y esencialmente ejecutará el código en el intérprete. Directriz
@jit(forceobj=true, looplift=True) puede mejorar el rendimiento respecto al modo objeto puro porque Numba intentará compilar ciclos en funciones que se ejecuten en código máquina y ejecutar el código restante en el intérprete. Para obtener el máximo rendimiento, evite usar el modo objeto.
Este paquete también admite la computación en paralelo cuando esta sea posible (Parallel=True). Tenga en cuenta que la primera vez que se llame a la función, esta se compilará en código máquina, lo cual llevará algún tiempo. Este código se almacenará en la caché y las llamadas posteriores serán más rápidas.
Ejemplo de aceleración de la función de etiquetado de transacciones
Antes de empezar a acelerar el simulador, intentaremos acelerar algo más sencillo. Un candidato excelente para este puesto será la función de etiquetado de transacciones. Esta función toma un dataframe con precios y marca las transacciones de compra y venta (0 y 1). Estas características se usan a menudo para marcar previamente los datos de modo que el clasificador pueda ser entrenado.
def get_labels(dataset, min = 1, max = 15) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'].iloc[i] future_pr = dataset['close'].iloc[i + rand] if (future_pr + hyper_params['markup']) < curr_pr: labels.append(1.0) elif (future_pr - hyper_params['markup']) > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
Como datos, usaremos los precios de cierre de un minuto del par de divisas EURGBP a lo largo de 15 años:
>>> pr = get_prices() >>> pr close time 2010-01-04 00:00:00 0.88810 2010-01-04 00:01:00 0.88799 2010-01-04 00:02:00 0.88786 2010-01-04 00:03:00 0.88792 2010-01-04 00:04:00 0.88802 ... ... 2024-10-09 19:03:00 0.83723 2024-10-09 19:04:00 0.83720 2024-10-09 19:05:00 0.83704 2024-10-09 19:06:00 0.83702 2024-10-09 19:07:00 0.83703 [5480021 rows x 1 columns]
El conjunto de datos contiene más de cinco millones de observaciones, lo cual resultará suficiente para las pruebas.
Ahora mediremos la velocidad de esta función con nuestros datos:
# get labels test start_time = time.time() pr = get_labels(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
El tiempo de ejecución ha sido de 74,1843 segundos.
Ahora intentaremos acelerar esta función utilizando el paquete Numba. Podemos ver que el paquete Pandas también se utiliza en la función fuente, y sabemos que estos dos paquetes son incompatibles. Vamos a poner todo lo relacionado con Pandas en una función aparte y a acelerar el resto del código.
@jit(nopython=True) def get_labels_numba(close_prices, min_val, max_val, markup): labels = np.empty(len(close_prices) - max_val, dtype=np.float64) for i in range(len(close_prices) - max_val): rand = np.random.randint(min_val, max_val + 1) curr_pr = close_prices[i] future_pr = close_prices[i + rand] if (future_pr + markup) < curr_pr: labels[i] = 1.0 elif (future_pr - markup) > curr_pr: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_fast(dataset, min_val=1, max_val=15): close_prices = dataset['close'].values markup = hyper_params['markup'] labels = get_labels_numba(close_prices, min_val, max_val, markup) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) return dataset
La primera función irá precedida de una llamada al decorador @jit. Y esto significa que esta función se compilará en código de bytes. También nos hemos deshecho de Pandas en su interior y solo hemos utilizado listas, ciclos y Numpy.
La segunda función realizará el trabajo preparatorio. Convertirá el dataframe Pandas en un array Numpy y luego lo pasará a la primera función. A continuación, tomará el resultado y retornará de nuevo el dataframe Pandas. De este modo, se acelerará el cálculo básico de etiquetado.
Ahora vamos a medir la velocidad. El tiempo de cálculo se ha reducido a 12 segundos. Para esta función, hemos obtenido una aceleración de más de 5 veces. Obviamente, esto no supone del todo una prueba pura, ya que la biblioteca Pandas todavía se utiliza para los cálculos intermedios, sin embargo, hemos logrado una aceleración significativa en la parte del cálculo de etiquetas.
Aceleración del simulador de estrategias para tareas de aprendizaje automático
Hemos puesto el simulador de la estrategias en una biblioteca separada que se puede encontrar en los anexos al artículo. Hay dos funciones "tester" y "slow_tester" para comparar.
El lector puede objetar que la mayoría de las mejoras de velocidad en Python se producen a expensas de la vectorización. Y eso es cierto, pero a veces resulta necesario utilizar ciclos. Por ejemplo, el simulador implementa un ciclo bastante complejo para pasar por toda la historia y acumular el beneficio total considerando los stop-loss y take-profits. Implementar esto a través de la vectorización no parece una tarea sencilla.A continuación le mostramos el cuerpo del ciclo del simulador (lo que más tarda en ejecutarse), con fines informativos.
for i in range(dataset.shape[0]): line_f = len(report) if i <= forw else line_f line_b = len(report) if i <= backw else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue
Vamos a medir la velocidad de las pruebas con los datos que hemos obtenido antes. En primer lugar, veremos la velocidad del simulador lento:
# native python tester test start_time = time.time() tester_slow(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['markup'], hyper_params['forward'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 6.8639 seconds No parece muy lento, incluso se podría decir que el intérprete ejecuta el código bastante rápido.
Vamos a dividir nuevamente la función de comprobación en dos funciones. Uno será auxiliar y la otra hará los cálculos principales.
La función process data implementará el ciclo principal del simulador que debe acelerarse porque los ciclos en Python son lentos. Al mismo tiempo, la función tester preparará directamente los datos para la función process data primero, luego aceptará el resultado y dibujará el gráfico.
@jit(nopython=True) def process_data(close, labels, metalabels, stop, take, markup, forward, backward): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b def tester(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value plot: false/true ''' dataset, stop, take, forward, backward, markup, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data(close, labels, metalabels, stop, take, markup, forw, backw) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.plot(chart) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
Ahora vamos a probar el simulador de estrategias acelerado por Numba:
start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
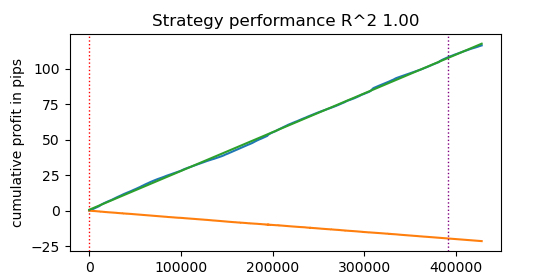
Execution time: 0.1470 seconds ¡El aumento de la velocidad es de casi 50 veces! De este modo, se han realizado más de 400.000 transacciones.
Imagine que dedica una hora al día a probar sus algoritmos, con un simulador rápido solo tardaría un minuto.
Probando estrategias con datos de ticks
Vamos a complicar la tarea y a descargar del terminal la historia de ticks de los últimos 3 años en un archivo .csv.
Para leer correctamente el fichero, la función de carga de cotizaciones deberá modificarse ligeramente. En lugar de los precios Close, utilizaremos los precios Bid. Todavía tendremos que eliminar los precios con los mismos índices.
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+') pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<BID>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') # Remove duplicate string by 'time' index pFixed = pFixed[~pFixed.index.duplicated(keep='first')] return pFixed.dropna()
Es decir, casi 62 millones de observaciones. Cabe señalar que el simulador toma los precios según el nombre de la columna "close", por lo que Bid pasará a llamarse Close.
>>> pr close time 2022-01-03 00:05:01.753 0.84000 2022-01-03 00:05:04.032 0.83892 2022-01-03 00:05:05.849 0.83918 2022-01-03 00:05:07.280 0.83977 2022-01-03 00:05:07.984 0.83939 ... ... 2024-11-08 23:58:53.491 0.82982 2024-11-08 23:58:53.734 0.82983 2024-11-08 23:58:55.474 0.82982 2024-11-08 23:58:57.040 0.82984 2024-11-08 23:58:57.337 0.82982 [61896607 rows x 1 columns]
Vamos a ejecutar un etiquetado rápido y medir el tiempo de ejecución.
# get labels test start_time = time.time() pr = get_labels_fast(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
El tiempo de etiquetado ha sido de 9,5 segundos.
Ahora vamos a hacer una prueba rápida.
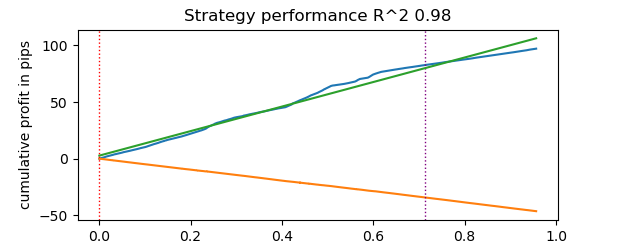
# numba tester test start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
La prueba ha durado 0,16 segundos. El simulador lento, a su vez, ha tardado 5,5 segundos.
El simulador rápido en Numba ha cumplido la tarea a una velocidad 35 veces mayor que el simulador en Python puro. De hecho, desde el punto de vista del observador, la prueba ha sido instantánea en el caso del simulador rápido, mientras que en el caso del simulador lento, ha habido un momento de espera. Aun así, debemos reconocer el mérito del simulador lento, que también hace un buen trabajo y resulta bastante adecuado para probar estrategias incluso con datos de ticks.
El total tenemos 1e6 o un millón de transacciones.
Información sobre el uso del simulador rápido para tareas de aprendizaje automático
Si tiene intención de usar el simulador propuesto, puede que le resulte útil la siguiente información.
Vamos a añadir características a nuestro conjunto de datos para que sea posible entrenar el clasificador.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC-pFixedC.rolling(i).mean() count += 1 return pFixed.dropna()
Son señales simples basadas en diferencias de precios y medias móviles.
A continuación, crearemos un diccionario de hiperparámetros del modelo que se usarán en el entrenamiento y las pruebas. Y los utilizaremos para generar un nuevo conjunto de datos.
hyper_params = {
'symbol': 'EURGBP_H1',
'markup': 0.00010,
'stop_loss': 0.01000,
'take_profit': 0.01000,
'backward': datetime(2010, 1, 1),
'forward': datetime(2023, 1, 1),
'periods': [i for i in range(50, 300, 50)],
}
# catboost learning
dataset = get_labels_fast(get_features(get_prices()))
dataset['meta_labels'] = 1.0
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() Tenga en cuenta que el simulador no solo admite valores de etiqueta "labels", sino también valores de etiqueta "meta_labels". ¿Para qué sirven? Son necesarios si deseamos usar filtros para nuestro sistema comercial basado en el aprendizaje automático. Entonces, el valor 1 permitirá el comercio, mientras que el valor 0 lo prohibirá. Como en esta demostración no utilizaremos filtros, simplemente crearemos una columna adicional y la rellenaremos con unidades, permitiendo siempre la negociación.
dataset['meta_labels'] = 1.0
Ahora podremos entrenar el modelo CatBoost con el conjunto de datos generado, eliminado previamente los datos de prueba anteriores y posteriores de la historia para que no se entrene con ellos.
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) model = CatBoostClassifier(iterations=500, thread_count=8, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False)
Tras el entrenamiento, probaremos el modelo con todo el conjunto de datos, incluidos los datos de prueba. La función test_model se encuentra en el archivo tester_lib.py junto con las funciones del simulador rápido y lento. Se trata de un envoltorio para un simulador rápido y obtiene los valores predichos del modelo de aprendizaje automático entrenado (en nuestro caso será CatBoost, pero puede ser cualquier otro).
def test_model(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, plt = False): ext_dataset = dataset.copy() X = ext_dataset[dataset.columns[1:-2]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] # ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) # ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(ext_dataset, stop, take, forward, backward, markup, plt)
Las líneas del código de arriba están comentadas para obtener las metaetiquetas responsables de indicar si se negocia o no. Es decir, se puede usar un segundo modelo de aprendizaje automático para este fin. En este artículo no se usa.
Empezamos con las pruebas.
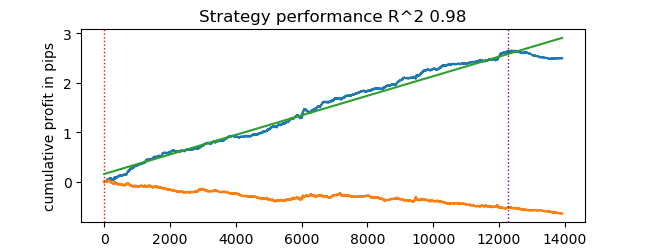
# test catboost model test_model(dataset, [model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True)
Y obtenemos el resultado. El modelo se ha reentrenado, como podemos ver en los datos de prueba a la derecha de la línea vertical. Pero no nos importa porque estamos probando el simulador.
Como el simulador presupone que puede utilizar stop loss y take profits y puede querer optimizarlos, utilizaremos la optimización, ¡porque nuestro simulador es ahora muy rápido!
Optimización de los parámetros de los sistemas comerciales basada en el aprendizaje automático
Veamos ahora cómo optimizar los stop loss y take profits. De hecho, podemos optimizar otros parámetros de los sistemas comerciales, como las metaetiquetas, pero esto queda fuera del alcance de este artículo y puede tratarse en el siguiente.
Aplicaremos dos tipos de optimización:
- Búsqueda por cuadrícula de parámetros
- Optimización según el método L-BFGS-B
Veamos brevemente el código de cada método. A continuación le mostramos el método GRID_SEARCH.
Como argumentos, admite:
- conjunto de datos de prueba
- modelo entrenado
- diccionario que contiene los hiperparámetros del algoritmo descrito anteriormente
- objeto de simulador
# stop loss / take profit grid search def optimize_params_GRID_SEARCH(pr, model, hyper_params, test_model_func): best_r2 = -np.inf best_stop_loss = None best_take_profit = None # Ranges for stop_loss and take_profit stop_loss_range = np.arange(0.00100, 0.02001, 0.00100) take_profit_range = np.arange(0.00100, 0.02001, 0.00100) total_iterations = len(stop_loss_range) * len(take_profit_range) start_time = time.time() for stop_loss in stop_loss_range: for take_profit in take_profit_range: # Create a copy of hyper_params current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = stop_loss current_hyper_params['take_profit'] = take_profit r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) if r2 > best_r2: best_r2 = r2 best_stop_loss = stop_loss best_take_profit = take_profit end_time = time.time() total_time = end_time - start_time average_time_per_iteration = total_time / total_iterations print(f"Total iterations: {total_iterations}") print(f"Average time per iteration: {average_time_per_iteration:.6f} seconds") print(f"Total time: {total_time:.6f} seconds") return best_stop_loss, best_take_profit, best_r2
Veamos ahora el código del método L-BFGS_B. Puede leer el artículo del enlace para obtener más detalles.
Los argumentos de la función seguirán siendo los mismos. Pero se creará una función de aptitud a través de la cual se llamará al simulador de estrategias. Luego se establecerán los límites de los parámetros de optimización y el número de inicializaciones iniciales (puntos aleatorios del conjunto de parámetros) para el algoritmo L-BFGS_B. Las inicializaciones aleatorias serán necesarias para que el algoritmo de optimización no se atasque en mínimos locales. A continuación, se llamará a la función minimize, a la que se transmitirán los parámetros del propio optimizador.
def optimize_params_L_BFGS_B(pr, model, hyper_params, test_model_func): def objective(x): current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = x[0] current_hyper_params['take_profit'] = x[1] r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) return -r2 bounds = ((0.001, 0.02), (0.001, 0.02)) # Let's try some random starting points n_attempts = 50 best_result = None best_fun = float('inf') start_time = time.time() for _ in range(n_attempts): # Random starting point x0 = np.random.uniform(0.001, 0.02, 2) result = minimize( objective, x0, method='L-BFGS-B', bounds=bounds, options={'ftol': 1e-5, 'disp': False, 'maxiter': 100} # Increase accuracy and number of iterations ) if result.fun < best_fun: best_fun = result.fun best_result = result # Get the end time and calculate the total time end_time = time.time() total_time = end_time - start_time print(f"Total time: {total_time:.6f} seconds") return best_result.x[0], best_result.x[1], -best_result.fun
Ahora podremos ejecutar ambos algoritmos de optimización y observar el tiempo de ejecución y la precisión.
# using
best_stop_loss, best_take_profit, best_r2 = optimize_params_GRID_SEARCH(dataset, model, hyper_params, test_model)
best_stop_loss, best_take_profit, best_r2 = optimize_params_L_BFGS_B(dataset, model, hyper_params, test_model) Algoritmo de búsqueda por cuadrícula:
Total iterations: 400 Average time per iteration: 0.031341 seconds Total time: 12.536394 seconds Best parameters: stop_loss=0.004, take_profit=0.002, R^2=0.9742298702323458
Algoritmo L-BFGS-B:
Total time: 4.733158 seconds Best parameters: stop_loss=0.0030492548809269732, take_profit=0.0016816794762543421, R^2=0.9733045271274298
Con nuestra configuración por defecto, el L-BFGS-B ha sido más del doble de rápido, mostrando resultados comparables a los del algoritmo de búsqueda por cuadrícula.
Así pues, podemos utilizar ambos algoritmos y elegir el mejor, en función del número y del rango de parámetros que haya que optimizar.
Conclusión
En este artículo hemos demostrado la posibilidad de acelerar un simulador de estrategias que puede utilizarse para probar rápidamente estrategias basadas en el aprendizaje automático. Asimismo, hemos demostrado que Numba ofrece un aumento de velocidad de 50 veces. La simulación se vuelve más rápida, y permite realizar múltiples pruebas e incluso optimizar parámetros.
Adjuntamos al artículo:
- tester_lib.py - biblioteca del simulador
- test tester.py - script para comparar simuladores lentos (Python) y rápidos (Numba)
- tester ticks.py - script para comparar simuladores con datos de ticks
- tester ML.py - script para el entrenamiento de clasificadores y la optimización de hiperparámetros
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/14895
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
 Encabezado en Connexus (Parte 3): Dominando el uso de encabezado HTTP para solicitudes WebRequest
Encabezado en Connexus (Parte 3): Dominando el uso de encabezado HTTP para solicitudes WebRequest
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Bueno, la desviación estándar en una ventana deslizante de valor fijo tendrá un rango de variación no normalizado dependiendo de la volatilidad. Por lo que yo sé, normalmente se utiliza z-score para este propósito, ya que es un valor normalizado. Hasta aquí la reflexión )
Lo tengo, tomo min / max sobre toda la historia disponible y establecer como límites, a continuación, dividir en rangos aleatorios en cada iteración del optimizador. También puede hacer zscore. Pensé que tal normalización podría ser mejor para el optimizador (deshacerse de los valores pequeños con un gran número de ceros después del punto decimal), pero no creo que deba ser.
Hola maxim, creo que eres la persona más inteligente del foro, espero ver una descripción detallada en el segundo artículo. agradecido
Gracias por el halagador comentario, intentaré escribir algo interesante para vosotros.
Tengo algo de tiempo y casi he terminado el entrenamiento de modelos + optimización de hiperparámetros en una botella.
Será posible entrenar muchos modelos a la vez, luego optimizarlos, luego seleccionar el mejor modelo con los mejores parámetros de optimización, por ejemplo:
Y emitir el resultado.
A continuación, el modelo se puede exportar al terminal con los hiperparámetros óptimos. O utilizar el propio optimizador del terminal.
Empezaré el artículo más tarde, no lo he olvidado.