
ニューラルネットワークが簡単に(第66回):オフライン学習における探索問題

はじめに
強化学習法の連載が進むにつれ、学習した方策の環境探索と活用のバランスに関する問題に直面します。以前、エージェントの探索意欲を刺激するさまざまな方法を検討しましたが、オンライン学習で優れた結果を示したアルゴリズムが、オフラインではそれほど効果的でないことがよくあります。問題は、オフラインモードでは、環境に関する情報が訓練データセットのサイズによって制限されてしまうことです。多くの場合、モデル訓練用に選択されるデータは、タスクの小さな部分空間内で収集されるため、対象が狭くなります。これでは、環境に対する考え方がさらに限定されてしまいます。しかし、最適解を見つけるためには、エージェントは環境とそのパターンを完全に理解する必要があります。学習結果はしばしば訓練データセットに依存することは先に述べました。
さらに、訓練プロセスにおいて、エージェントは訓練データセットの部分空間を超える決定を下すことがよくあります。このような場合、その後の結果を予測するのは難しくなります。そのため、予備的なモデル訓練の後、訓練データセットに軌跡を追加収集し、訓練プロセスを調整することができます。
オンライン環境モデル訓練は、上記の問題を軽減できる場合があります。しかし、残念なことに、さまざまな理由により、環境モデルを訓練することができない場合もあります。モデルの訓練は、エージェント方策の訓練よりもさらに高くつくことがよくあります。不可能なこともあります。
2つ目の明白な方向性は、訓練データセットを拡大することです。しかし、ここでは主に利用可能な資源の物理的な大きさと、環境を研究するためのコストによって制限されます。
この記事では、Exploratory Data for Offline RL (ExORL)フレームワークについて学びます。これは、「Don't Change the Algorithm, Change the Data:Exploratory Data for Offline Reinforcement Learning」稿で紹介されています。その記事で示された結果は、データ収集への正しいアプローチが最終的な学習成果に大きな影響を与えることを示しています。この影響は、学習アルゴリズムやモデルアーキテクチャの選択に匹敵します。
1.Exploratory data for Offline RL (ExORL)法
Exploratory data for Offline RL (ExORL)法の作者は、新しい学習アルゴリズムやモデルのアーキテクチャソリューションを提供していません。その代わり、モデルを訓練するためのデータを収集するプロセスに焦点が当てられています。彼らは5つの異なる学習方法で実験をおこない、訓練データセットの内容が学習結果に与える影響を評価しています。
ExORL法は大きく3つの段階に分けられます。最初の段階は、ラベルのない探索的データの収集です。この段階では、さまざまな教師なし学習アルゴリズムを使用することができます。この方法の著者は、適用できるアルゴリズムの範囲を限定していません。さらに、環境との相互作用の過程では、各エピソードにおいて、過去の相互作用の履歴に応じた方策πを用います。各エピソードは、状態St、行動At、それに続く状態St+1のシーケンスとしてデータセットに保存されます。訓練データの収集は、訓練データセットが完全に埋まるまで続けられます。この訓練データセットのサイズは、技術仕様や利用可能なリソースによって制限されます。
実際には、この論文の著者らは9つの異なる教師なしデータ収集アルゴリズムを評価しています。
- 常に一様に無作為な方策を出力するシンプルなベースライン
- 予測モデルの誤差を最大化する方法:ICM、不同意、RND
- 状態空間のある推定カバレッジを最大化するアルゴリズム:APTおよびProto-RL
- 多様なスキルを学習する能力ベースのアルゴリズム:DIAYN, SMM、APS
状態と行動のデータセットを収集した後、次の段階は、与えられた報酬関数を使用してデータを関連付けることです。この段階は、データセットの各タプルに対する報酬の評価を意味します。
実験では、この方法の著者は標準的な報酬関数または手動報酬関数を使用しています。提案されたフレームワークでは、報酬関数の訓練も可能です。つまり、逆RLを実現できるのです。
ExORLの最後の段階はモデルの訓練です。方策は、ラベル付けされたデータセット上でオフライン強化学習アルゴリズムを用いて訓練されます。オフライン訓練は、ランダムにタプルを選択することで、訓練データセットからオフラインデータを使用して実施されます。最終的な方策は、実際の環境で評価されます。
以下は、著者らによる手法の視覚化です。
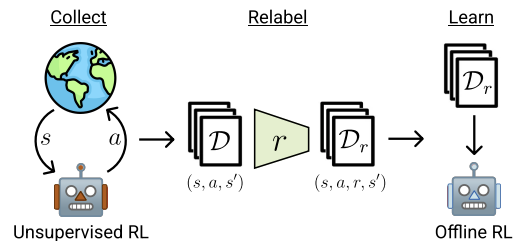
この論文で著者らは、5つの異なるオフライン強化学習アルゴリズムの結果を示しています。基本的なオプションは、シンプルな動作のクローニングです。また、3つのオフライン強化学習アルゴリズムの結果も発表しています。それぞれのアルゴリズムは、データ内の行動を超える外挿を防ぐために異なるメカニズムを使用しています。古典的なTD3は、もともとオンライン学習用に設計された手法で、訓練データセットから外挿できないように明示的に設計されたメカニズムを持たない手法に対するオフラインモードの影響を評価するためのベースラインテストとしても提示されています。
実験結果に基づき、この手法の著者は、多様なデータを使用することで、外挿問題を処理する必要がなくなり、オフライン強化学習アルゴリズムを大幅に簡素化できると結論づけています。その結果、探索的データが様々な問題に対するオフライン強化学習の性能を向上させることが実証されましました。さらに、これまでに開発されたオフラインRLアルゴリズムは、タスクに特化したデータでは良好なパフォーマンスを示しますが、ラベルなしのExORLデータではTD3に劣ります。理想的には、オフラインの強化学習アルゴリズムは、使用するデータセットに自動的に適応し、両方の長所を回復させるべきです。
2.MQL5を使用した実装
Exploratory Data for Offline RL (ExORL)法の著者は、フレームワーク構築の一般的な方向性を示しています。その論文の中で、著者らは様々なモデル訓練手法を試しています。この記事の実践編では、これまでの記事のモデルにできるだけ近いExORLの実装を構築することにしました。しかし、建設的な一点に注意してください。DWSLアルゴリズムは、S状態からの行動をそのアドバンテージに従って重み付けすることを意味します。私たち実装では、すべての軌道の埋め込みによって最も近い状態をターゲットにしました。選択された状態では、結果に対する影響度に応じて、行動の重みが決められました。
しかし、ExORL法はエージェントの行動の最大限の多様性を想定しています。この点で、個々の状態における行動間の距離を決定する必要があります。最も近い状態と行動のペアまでの距離を報酬として使用することで、エージェントは環境を探索するようになります。そこで、行動に基づいて状態の埋め込みを決定します。
別の方法として、後続の状態間の距離を決定することも可能です。ストキャスティックス(確率論的)な環境を扱う場合、これは極めて論理的です。このような環境では、ある行動をある確率で実行することで、その後のさまざまな状態につながる可能性があります。しかし、このようなアルゴリズムの使用は、私たちが実装の基礎として使用しているDWSL法からさらに遠ざけることになります。基本アルゴリズムに最小限の調整を加えることで、ExORLフレームワークがモデルの訓練結果に与える影響をより適切に評価できるようになります。
そこで、最初のオプションを使い、エンコーダーモデルのソースデータ層のサイズをActor行動ベクトル分だけ大きくすることにしました。それ以外は、モデルのアーキテクチャに変更はありません。添付ファイルをご覧ください。ファイル「...\ExORL\Trajectory.mqh」 メソッドCreateDescriptions
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor ........ ........ //--- Critic ........ ........ //--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr + NActions; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 ........ ........ //--- return true; }
訓練データの収集は、EA「...\ExORL\ResearchExORL.mq5」に実装されています。
ファイル名のフレームワークの表示に注意してください。添付ファイルには、前回の記事から移行したファイル「...\ExORL\Research.mq5」が含まれています。従って、そのアルゴリズムについては改めて説明しません。
これら2つのEAは、訓練データセットに入力するためのものです。奇妙なことに、訓練の過程でEAを使用することになります。しかし、これについてはもう少し後でお話しします。ここで、EA「...\ExORL\ResearchExORL.mq5」のアルゴリズムを考えてみましょう。
EAの外部パラメータは、環境との相互作用のために基本的なEAから移されましました。
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = 10; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price input int Agent = 1;
そのやり取りの過程で、Actorの環境学習方策を訓練します。学習プロセスでは、CriticモデルとEncoderモデルが必要になります。探索的方策の訓練コストを削減し、結果として訓練データの収集速度を上げるために、私は1つのCriticしか使用しないことにしました。
CNet Actor; CNet Critic; CNet Convolution;
さらに、以前に渡された軌跡とその埋め込み行列を読み込むためのフラグをグローバル変数のリストに追加します。
bool BaseLoaded; matrix<float> state_embeddings;
OnInitEA初期化メソッドでは、まず分析する指標を初期化します。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
取引操作の実行タイプを示します。
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
事前に訓練されたモデルを読み込みます。事前に訓練されたモデルがない場合は、無作為な重みで初期化された新しいモデルを作成します。このEAでは、モデルの読み込みを異なるブロックに分けることにしました。これにより、訓練済みのActorやEncoderがない状態でも、事前に訓練されたCriticを使用することができます。
以前、常に完全な同期モデルが必要だと話していたことにご注意ください。この場合、あえてActorとは別に訓練されたCriticを使用します。それには理由があります。異なるMetaTrader 5テストエージェントのモデル間で重み係数を同期させるアルゴリズムを構築することを思いついたのですが、その代わりに、並行していくつかの訓練済みActor探索モデルを作ることにしました。このようなモデルは、無作為なパラメータで初期化された後、過去のデータで並行して訓練されます。これらは同じ履歴セグメントを使用していますが、各探索Actorモデルは個別の学習経路を持っています。これにより、環境での探索される部分空間が広がります。過去に完了した軌道のバッファを1つ使用することで、軌道の繰り返しを最小限に抑えることができます。
探索Actorモデルを識別するために、モデルファイル名に接尾辞Exと外部パラメータのエージェント番号を追加します。このパラメータを最適化することで、MetaTrader 5のストラテジーテスターで複数の探索Actorを並行して実行することができます。
//--- load models float temp; if(!Actor.Load(StringFormat("%sAct%d.nnw", FileName, Agent), temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- }
同時に、すべての探索Actorに対して同一の訓練条件を整理するために、1つのCriticモデルを使用します。探索Actorモデルがない場合でも、事前に訓練されたCriticモデルを読み込むのが重要なのはこのためです。
if(!Critic.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Critic.Create(critic)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
すべてのエージェントに単一のエンコーダーモデルを使用することで、状態と行動の比較を単一の部分空間で整理することもできます。しかし、各エージェントは過去に通過した軌跡を独立して符号化するので、これは学習プロセスにとって重要ではありません。これにより、距離を正しく評価し、Actorの行動を多様化させることができます。
if(!Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Convolution.Create(convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
提示されたコードが煩雑に見えることには同意します。おそらく、モデルアーキテクチャの記述を異なる方法に従って分割するのが論理的でしょうが、それではこのEAだけのためにコードを単純化することになります。その一方で、この記事で使用されている他のプログラムのコードを複雑にしてしまいます。このため、モデルアーキテクチャを記述するメソッドを断片化しないことにしました。
すべてのモデルを1つのOpenCLコンテキストに転送します。これにより、それらの動作を同期させ、メインメモリとOpenCLコンテキストメモリ間のデータコピーの量を減らすことができます。
Critic.SetOpenCL(Actor.GetOpenCL());
Convolution.SetOpenCL(Actor.GetOpenCL());
Critic.TrainMode(false);
Critic訓練モードは無効にしています。先に、すべての環境探索エージェントに同じ訓練条件を作り出すことの重要性について述べました。Criticを固定状態に保つことは、このプロセスにおいて重要な役割を果たします。
その後、モデルアーキテクチャの標準的な最小限のコントロールを実装します。
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
次に、グローバル変数を初期化します。
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); BaseLoaded = false; bGradient.BufferInit(MathMax(AccountDescr, NActions), 0); //--- return(INIT_SUCCEEDED); }
以上の操作をすべて成功させたら、EAの初期化メソッドを完了します。
プログラム初期化メソッドでは、過去に完成した軌道は読み込みません。また、埋め込みもおこないません。というのも、過去に通貨した状態の埋め込みを作成するプロセスには、かなりのコストと時間がかかるからです。所要時間は訪問する状態の数によって異なります。
先に述べたように、環境と相互作用するEAとは異なり、今回は探索Actorを訓練します。各パスが完了すると、学習済みモデルを保存します。
void OnDeinit(const int reason) { //--- ResetLastError(); if(!Actor.Save(StringFormat("%sActEx%d.nnw", FileName, Agent), 0, 0, 0, TimeCurrent(), true)) PrintFormat("Error of saving Agent %d: %d", Agent, GetLastError()); delete Result; }
では、作成されたヘルパーメソッドについて簡単に考えてみましょう。CreateEmbeddingsメソッドは、状態と行動をエンコードするプロセスを実装しています。このメソッドはパラメータを持たず、状態の埋め込み行列を返します。
メソッド本体では、まずローカル変数を作成します。
matrix<float> CreateEmbeddings(void) { vector<float> temp; CBufferFloat State; Convolution.getResults(temp); matrix<float> result = matrix<float>::Zeros(0, temp.Size());
次に、以前に収集した軌跡データベースの読み込みを試みます。データの読み込みに失敗した場合は、呼び出し元に空の行列を返します。
BaseLoaded = LoadTotalBase(); if(!BaseLoaded) { PrintFormat("%s - %d => Error of load base", __FUNCTION__, __LINE__); return result; }
軌跡データベースの読み込みに成功したら、すべての軌跡の状態の総数を数え、入力する行列のサイズを変更します。
int total_tr = ArraySize(Buffer); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; result.Resize(total_states, temp.Size());
次に来るのは、状態と行動をエンコードするためのネストされたループのシステムです。外側のループでは、読み込まれた軌道を繰り返し処理します。ネストされたループの中で、状態を反復します。
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
指定されたループシステムの本体では、まず、環境の状態を表す生データのバッファを作成します。過去の価格と指標データを指定されたバッファに転送します。
次に、口座の状態とポジションの説明を追加します。
float prevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float prevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - prevBalance) / prevBalance); State.Add(Buffer[tr].States[st].account[1] / prevBalance); State.Add((Buffer[tr].States[st].account[1] - prevEquity) / prevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / prevBalance); State.Add(Buffer[tr].States[st].account[5] / prevBalance); State.Add(Buffer[tr].States[st].account[6] / prevBalance);
調波ベクトルの形式でタイムスタンプを追加します。
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Actorの行動ベクトルを追加します。
State.AddArray(Buffer[tr].States[st].action);
組み立てたテンソルをエンコーダーに渡し、フィードフォワードメソッドを呼び出します。結果の埋め込みは、結果行列に追加されます。
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp); if(!result.Row(temp, state)) continue; state++; } } }
そして軌跡バッファから次の状態に移ります。
状態エンコーディングループシステムのすべての反復を完了した後、結果行列のサイズを保存された埋め込みの実際の数まで縮小し、以前に読み込まれた軌道のバッファをクリアします。その後は、埋め込みだけを扱います。
if(state != total_states) result.Reshape(state, result.Cols()); ArrayFree(Buffer);
呼び出し元のプログラムに結果を返し、メソッドを終了します。
//--- return result; }
次に、内部報酬を生み出すメソッドを構築しました。探索Actorを訓練する際、環境を効果的に探索するシステムを構築するため、エージェントに多様で反復性のない行動を促すことを目的とした内部報酬のみを使用することにご注意ください。したがって、この段階では、環境空間を制限するようなラベル付けされたデータや外在的な報酬は必要ありません。この点で、内部報酬の形成に特別な注意を払うべきです。
ResearchRewardメソッドのパラメータに、次を渡します。
- 内部報酬を形成するために使用される最も近い状態と行動の分位数
- 分析状態の埋め込み
- 上記のメソッドで形成された状態埋め込み行列
メソッド本体では、ゼロの結果ベクトルを用意し、分析された状態の埋め込みサイズが、先に作成した行列の埋め込みサイズと一致するかどうかを確認します。
vector<float> ResearchReward(double quant, vector<float> &embedding, matrix<float> &state_embedding) { vector<float> result = vector<float>::Zeros(NRewards); if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
コントロールブロックの受け渡しに成功したら、ローカル変数を初期化します。
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * quant); matrix<float> temp = matrix<float>::Zeros(states, size); vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S;
次のステップでは、経験再生バッファに保存されている、分析された状態と行動のペア間の距離を計算します。距離のソフトな推定を得るために、DWSL法の著者によって提案されたLogSumExp関数を使用します。
for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha = temp.Max(); if(alpha == 0) alpha = 1; vector<float> dist = MathLog(MathExp(temp / (-alpha)).Sum(1)) * (-alpha);
次に、最も近い状態と行動のペアの埋め込みを必要な数だけ選択します。
float max = dist.Quantile(quant); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
核規範アルゴリズムを用いて、選択されたActor行動と潜在状態に対する内部報酬を生成します。
k_embedding.SVD(U, V, S); result[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result[NRewards - 1] = EntropyLatentState(Actor); //--- return result; }
結果は呼び出し側プログラムに返されます。
なお、結果ベクトルでは、外発的報酬の要素はゼロ値のままです。これはExORLのフレームワークと一致しています。問題のEAは、環境の無秩序な探索を組織するように設計されています。前述したように、この段階で外発的報酬を用いても、研究対象の部分空間を狭めるだけです。
環境との相互作用と探索Actor訓練のプロセスは、OnTickティック処理メソッドに実装されています。なお、この段階では学習プロセスは簡略化されています。学習プロセスで使用されるCriticは1つのみです。さらに、探索Actorモデルの訓練プロセスでは、経験再生バッファの使用を排除しています。このバッファの欠如は、ストラテジーテスターの追加パスによって補われる可能性があります。
各ローソク足に対して1回のバックプロパゲーションを実行します。パラメータは、Actorの最後の行動に基づいて調整されます。
このアプローチは、最も効果的で、実行しやすいものではないかもしれません。しかし、この手法の有効性を評価する上では、かなり有効です。
メソッド本体では、まず新しいバーの出現を確認します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
それから過去のデータを読み込みます。
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
次に、探索Actorのソースデータバッファを作成します。ここではまず、受信した履歴データを環境状態記述バッファに入力します。
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
次に、現在の口座状況とポジションを確認します。
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
受信したデータに基づいて、口座状況を記述したバッファを作成します。
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
このバッファに、タイムスタンプの調波ベクトルを追加します。
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
生成されたデータは、Actorのフィードフォワードパスを実行するのに十分です。
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Actorのフィードフォワードパスが成功した結果、予測行動のベクトルが得られるので、それを解読して環境に送信します。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
まず、ロングポジションの一員として環境と対話します。
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
これをショートポジションでも繰り返します。
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
そして、環境との相互作用の結果は、状態と行動を記述するための構造に集められます。外発的報酬を追加します。その後、これらすべてを軌跡に追加し、パス結果に基づいて、経験再生バッファに追加します。
//--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove();
報酬のベクトルにご注意ください。これまでは、ベクトルが外部からの報酬で満たされている間、無制限の探索について話してきました。一方、内部報酬の要素はゼロのままです。保存された軌道は、ExORLフレームワークのステージ3で、主なActor方策の訓練に使用されます。しかし、報酬バッファの母集団は、状態と行動の再評価に関連するステージ2の実装です。したがって、私たちのすべての行動は、ExORLアルゴリズムの枠組みの中に収まります。
おわかりのように、上で紹介したアルゴリズムは、先に説明した環境との相互作用の方法とほとんど同じです。ただし、ここでは以前のようにメソッド操作を完了させず、その代わりに、探索Actor方策の学習プロセスの実施に移ります。
まず、現在の状態と完了した行動を埋め込む必要があります。それらを得るために、口座の状態とActorが実行した行動に関する情報を、現在の環境状態のバッファに追加します。得られたバッファをエンコーダーの入力に送り、フィードフォワードメソッドを呼び出します。
bState.AddArray(GetPointer(bAccount)); bState.AddArray(temp); bActions.AssignArray(temp); if(!Convolution.feedForward(GetPointer(bState), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Convolution.getResults(temp);
作戦成功の結果、現在の状態の埋め込みを受け取ります。
次に、以前に走行した軌跡に関するデータが読み込まれているかどうかを確認し、必要であれば、上で紹介したCreateEmbeddingsメソッドを呼び出してそれらをエンコードします。
if(!BaseLoaded) { state_embeddings = CreateEmbeddings(); BaseLoaded = true; }
操作の結果にかかわらず、データ読み込みフラグをtrueに設定します。これにより、今後、通過した状態のデータベースを何度も読み込む手間を省くことができます。
次に、状態埋め込み行列のサイズを確認します。この行列のサイズがゼロであることは、以前に走行した軌跡がないことを示している場合があります。この場合、現段階ではモデルのパラメーターを更新するデータがありません。したがって、単純に現在の状態の埋め込みを行列に追加します。そして、次のローソク足のオープンの待機に移ります。
ulong total_states = state_embeddings.Rows(); if(total_states <= 0) { ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError()); return; }
渡された状態埋め込み行列にデータがあれば、内部報酬を生成し、現在の状態埋め込みを行列に追加します。
vector<float> rewards = ResearchReward(Quant, temp, state_embeddings); ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError());
内部報酬を生成した後にのみ、渡された状態埋め込み行列に現在の状態埋め込みを追加することが非常に重要です。そうでなければ、内部報酬を計算する際に、現在の埋め込みが2度考慮されることになり、データを歪めてしまう可能性があります。
一方、行列に埋め込みを追加するプロセスを完全に除外すると、内部報酬を生成する際に現在のパス状態を考慮することができなくなります。
生成された内部報酬をデータバッファに転送します。その後、Criticのフィードフォワードとバックプロパゲーションのパスを実行します。これに続いて、探索Actor用のバックプロパゲーションパスがおこなわれます。
Result.AssignArray(rewards); if(!Critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(bActions)) || !Critic.backProp(Result, GetPointer(bActions), GetPointer(bGradient)) || !Actor.backPropGradient(GetPointer(bAccount), GetPointer(bGradient), LatentLayer)) PrintFormat("%s -> %d: Error of backpropagation %", __FUNCTION__, __LINE__, GetLastError()); }
この場合、1つの操作の中で、Criticのフィードフォワードとバックプロパゲーションのメソッドを連続して呼び出すことを実装しています。これは、この場合、Criticを訓練せず、そのフィードフォワードパスの結果を評価しないからです。必要なのは、誤差の勾配をActorに伝えることだけです。したがって、両方のメソッドがActorのバックプロパゲーション手順の一部として呼び出されます。このため、他の点では最終的な結果には影響しないが、メソッド呼び出しがこのような変わった配置になりましました。
以上で、環境との相互作用の方法と、探索Actor方策のオンライン学習についての説明を終えます。その他のEAメソッドは変更なく使用されます。添付ファイルをご覧ください。
モデル訓練のEAの調整に移ります。この手法の著者は、実験においてモデルを訓練するための基本的な方法を使用していたにもかかわらず、私たちのアプローチを実装するには、以前の論文から訓練EAにいくつかの変更を加える必要がありました。この変更は主にエンコーダーのアーキテクチャーの変更によるもので、その結果、モデルとの相互作用に関連する変更が生じました。まず必要なことから始めていきます。
この変更はグローバルなものではありません。従って、ここではモデルの訓練メソッドTrainのみを検討することにします。メソッド本体では、読み込まれた軌道の数を確認します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
次に、これらの軌跡に含まれる状態の総数を数えます。
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total;
次に、ローカル変数を準備します。
vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
その後、過去に渡された状態をエンコードするためにループのシステムを編成し、埋め込み行列をコンパイルします。このプロセスは、上述のプロセスに似ています。1つ注意点があります。
先ほどと同じように、ループシステムの本体で、現在の環境状態バッファを埋めます。
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
口座状況とポジションを追加します。
float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance);
タイムスタンプのハーモニクスを埋めます。
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
ただし、行動ベクトルの代わりに、適切な長さのゼロベクトルを渡します。
State.AddArray(vector<float>::Zeros(NActions));
この解決策は、完了した行動が状態埋め込みに与える影響を排除します。これにより、エンコーダーアーキテクチャーの変更を平準化しながら、前回の記事のDWSL法の実装に戻ります。したがって、ExORL法の著者らの推奨に従って、モデルの訓練には変更されていない手法を使用します。この場合、すべてのモデルを学習する過程で、1つの状態行動エンコーダを使用します。これにより、探索Actor方策と主Actor方策の両方を正しく訓練することができます。
次に、エンコーダーのフィードフォワードパスを実行します。状態埋め込みという形で演算された結果が行列に追加されます。
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); if(!state_embedding.Row(temp, state)) continue;
同時に、DWSLアルゴリズムに従って、学習プロセスで使用される行動行列と報酬行列を入力します。先ほどと同じように、報酬行列には、取った行動の利点の値が記入されます。
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue; state++;
状態エンコードの進捗状況をユーザーに知らせ、ループシステムの次の反復に移ります。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
すべての状態エンコーディングの反復を成功させた後、行列のサイズを実際に保存されるデータ量まで縮小します。しかし、前述したCreateEmbeddingsのコーディング方法とは異なり、モデルの訓練時に軌跡配列が必要になるため、軌跡配列はクリアしません。
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
}
次に、学習プロセスを整理する必要があります。まず、ローカル変数を作成し、軌道選択確率のベクトルを形成します。
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr;
それから訓練ループを作成します。ループの本体では、軌跡と軌跡上の状態を標本化します。
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
そして、エピソードが終わるまでに報酬を発生させる必要があるかどうかを確認します。生成する必要がある場合は、その後の環境の状態のバッファを埋めます。
target_reward = vector<float>::Zeros(NRewards); //--- Target if(iter >= StartTargetIter) { State.AssignArray(Buffer[tr].States[i + 1].state);
すぐにその後の口座状態とポジションをバッファに入力します。
float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
それにタイムスタンプのハーモニクスを追加します。
double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
生成されたデータは、更新された方策に従って行動を生成するActorのフィードフォワードパスを実行するのに十分です。
//--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
結果の行動は、2つのCriticsによって評価されます。
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2);
推定値の低い方を期待報酬とし、それに潜在状態のエントロピーを追加します。
target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
次のステップでは、Criticsモデルを訓練します。そのために、環境の現在の状態を表すベクトルを形成します。
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
タイムスタンプのハーモニクスで補足された、口座の状態とポジションを記述するベクトルを形成します。
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
その後は、Actorへのフィードフォワードパスです。
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
覚えていらっしゃるかもしれませんが、Criticを訓練するために、環境との相互作用の中で取られた実際の行動を使用していますが、潜在状態を形成するためには、Actorのフィードフォワードパスが必要です。
次に、訓練セットから実際の行動をデータバッファにコピーし、Criticsのフィードフォワードパスを実行します。
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
その後、現在の環境状態を記述したバッファを取り出し、そこに口座状態のデータと、Actorの行動を置き換えるためのゼロベクトルを追加します。そして、分析された環境の状態の埋め込みを生成します。
if(!State.AddArray(GetPointer(Account)) || !State.AddArray(vector<float>::Zeros(NActions)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
受信した埋め込みに基づき、モデルを学習するためのターゲットの構造を生成します。目標値を生成する手法のアルゴリズムは、前回の記事で説明しました。
target = GetTargets(Quant, temp, state_embedding, rewards, actions);
このステップで、Criticsのバックプロパゲーションパスに必要なすべてのデータが揃いますが、CAGrad法を用いて誤差勾配ベクトルを修正するため、モデルを順次訓練する必要があります。
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
このステップでは、Actorの基本方策を訓練します。これまでと同じように、方策を訓練するためにいくつかのアプローチを組み合わせます。まず、DWSLアルゴリズムを使用し、最終結果への影響度によって重み付けされた行動を繰り返すようにActorを訓練します。
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
その後、リターンを増やす方向にActorの行動を調整します。訓練の第2段階は、Criticの行動評価の正しさにかなり自信がある場合にのみ用いられます。
//--- CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
訓練プロセスの反復の最後に、ターゲットモデルのパラメータを調整します。
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
学習プロセスの進行状況をユーザーに知らせ、学習ループの次の反復に移ります。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
モデルの訓練ループをすべて終了したら、グラフのコメントフィールドを消去します。訓練結果をログに出力し、EA操作を終了するプロセスを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
これで、使用したプログラムのアルゴリズムの説明は終わりです。記事で使用したすべてのプログラムの完全なコードは、添付ファイルでご覧いただけます。次に、完成した作業のテストに移ります。
3.テスト
本稿の前のセクションで、オフラインRL手法のための探索的データについて理解し、MQL5を使用して提示された手法のビジョンを実装しました。結果を評価する時です。いつものように、モデルの訓練とテストはEURUSDH1でおこなわれます。指標はデフォルトのパラメータで使用されます。モデルは2023年の最初の7ヶ月間の履歴データで訓練されています。訓練済みモデルをテストするために、2023年8月からの履歴データを使用します。
この論文で紹介されているアルゴリズムは、まったく新しいモデルの訓練を可能にします。ゼロからの訓練です。しかしこの手法では、以前に訓練したモデルを微調整することもできます。そこで、2つ目の選択肢を試すことにしました。冒頭で述べたように、前回の記事のEAを今回の作業のベースとして使用しました。このモデルを最適化します。まず、モデルファイルの名前を変更する必要があります。
| DWSL.bd | ==> | ExORL.bd |
| DWSLAct.nnw | ==> | ExORLAct.nnw |
| DWSLCrt1.nnw | ==> | ExORLCrt1.nnw |
| DWSLCrt2.nnw | ==> | ExORLCrt2.nnw |
エンコーダーのアーキテクチャを変更したため、エンコーダーのモデルを移管するつもりはありません。
ファイル名を変更した後、EAResearchExORL.mq5を起動し、訓練データ上の環境を追加調査します。私の作業では、5つのテストエージェントから100の追加パスを集めました。
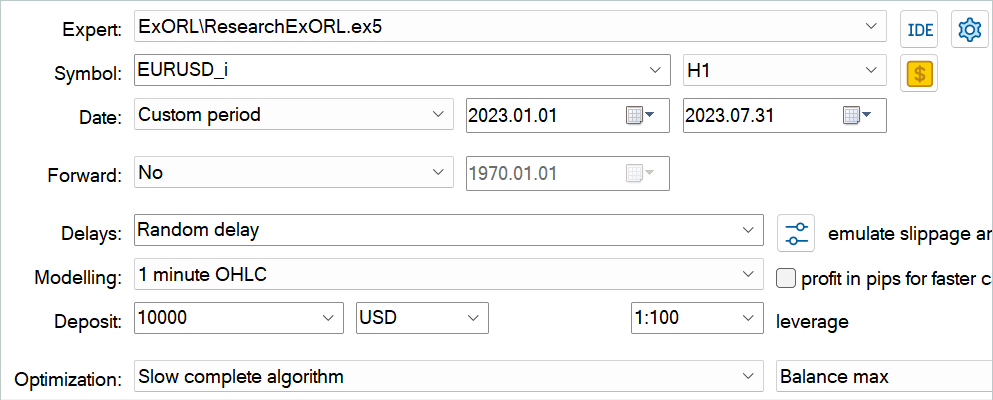
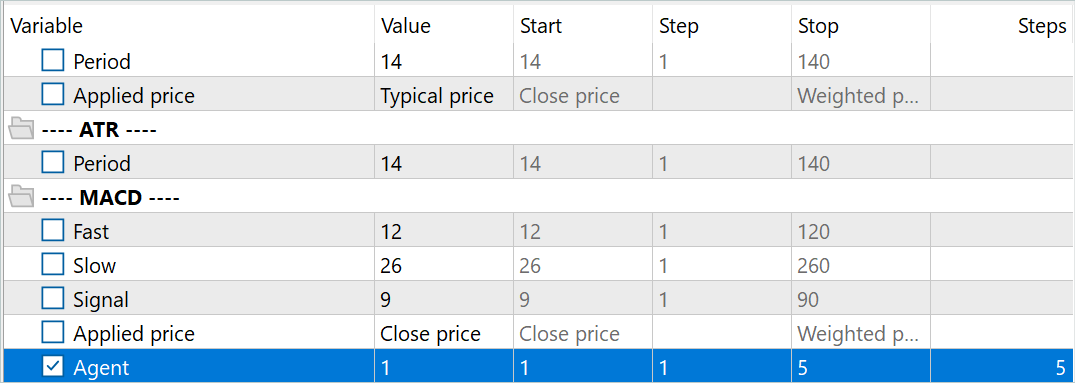
実際の経験から、異なる方法で収集された1つの再生バッファで並行して使用できる可能性があります。先に説明したEAResearch.mq5とEAResearchExORL.mq5で収集した軌道の両方を使用しました。最初のEAは、学習したActor方策の長所と短所を示しています。もうひとつでは、可能な限り環境を探索し、未知のチャンスを評価することができます。
モデルの反復訓練の過程で、そのパフォーマンスを向上させることに成功しました。


テスト期間中の取引回数は3倍(56回対176回)に減少しましたが、利益は約3倍に増加しました。最大勝ち取引額は2倍以上になり、平均利益率は5倍になりましました。さらに、全テスト期間を通じて残高が増加していることが確認されましました。その結果、このモデルのプロフィットファクターは1.3から2.96に上昇しました。
結論
本稿では、オフラインでモデル学習をおこなうための訓練データセットのデータ収集のアプローチに主眼を置いた新しい手法、Exploratory data for Offline RLを紹介します。この手法の著者がおこなった実験では、ソースデータの選択が重要な問題のひとつであり、モデルアーキテクチャや学習方法の選択と同様に結果に影響を与えます。
本稿の実践編では、提案手法のビジョンを実装し、MetaTrader 5ストラテジーテスターの履歴データを使用してテストしました。このテストは、訓練サンプル収集アルゴリズムがモデルの訓練結果に与える影響に関する手法の著者の結論を確認するものです。このように、訓練軌道の収集方法を変えることで、前回の記事で紹介したモデルの性能を最適化することができましました。
ただし、もう一度言っておきますが、この記事で紹介するプログラムはすべて、技術のデモンストレーションを目的としたものであり、実際の取引に使用するためのものではないことをお断りしておきます。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchExORL.mq5 | EA | ExORLメソッドによる事例収集のためのEA |
| 3 | Study.mq5 | EA | エージェント訓練EA |
| 4 | Test.mq5 | EA | モデルをテストするEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13819
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
。
MetaTrader Testerが各コアの入力をどのように選択するかは知らない。オンラインスタディでの主なアイデアは、あるパスから別のパスへ、事前に訓練されたモデルを使用することです。しかし、テスターがOptimithation 1...4からAgent 1を1つのパスで実行すると、それらはすべてランダムな(事前に訓練されていない)モデルを使用します。
MetaTrader Testerが各コアの入力をどのように選択するのかわかりません。オンラインスタディでの主なアイデアは、あるパスから別のパスへと事前に訓練されたモデルを使用することです。しかし、テスターがOptimithation 1...4からAgent 1を1つのパスで実行すると、それらはすべてランダムな(事前に訓練されていない)モデルを使用します。
また、いくつかのインジケータとパラメータを追加しました。モメンタム、バンド、一目均衡表 =)
int OnInit()
{
シンボルの設定とリフレッシュ
if(! Symb.Name(_Symbol))
return INIT_FAILED;
Symb.Refresh();
//---
if(! RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR.Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD.Create(Symb.Name(),TimeFrame,FastPeriod,SlowPeriod,SignalPeriod,MACDPrice)))。
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied)))
return INIT_FAILED;
一目均衡表のインジケータを初期化します。
if (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkanan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod))))
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied)))
return INIT_FAILED;
//---
if(! RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !
!ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
を返します;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Rates, true))
を返す;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
モメンタム.リフレッシュ();
Bands.Refresh();
Symb.RefreshRates();
現在のバーのイチモク値をリフレッシュする
Ichimoku.Refresh();
--- ヒストリー・データ
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Rates[b].open;
float close = (float)Rates[b].close;
float rsi = (float)RSI.Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR.メイン(b);
float macd = (float)MACD.Main(b);
float sign = (float)MACD.シグナル(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bands.Upper(b);
float bandzb = (float)Bands.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0); 計算値を使う。
float kijun = (float)Ichimoku.KijunSen(1);計算値を使用。
float senkasa = (float)Ichimoku.SenkouSpanA(2);計算値を使用。
float senkb = (float)Ichimoku.SenkouSpanB(3);計算値を使用。
EMPTY_VALUEとゼロによる除算をチェックする。
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||)
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE || bandzb == EMPTY_VALUE || bandzlo == EMPTY_VALUE || bandzlo == EMPTY_VALUE
bandzlo == EMPTY_VALUE || tenkan == EMPTY_VALUE || kijun == EMPTY_VALUE || senkasa == EMPTY_VALUE || senkasa == EMPTY_VALUE || senkasa == EMPTY_VALUE || senkb == EMPTY_VALUE || senkb == EMPTY_VALUE
senkb == EMPTY_VALUE || kijun == 0.0 || senkb == 0.0)
{
続行する;
}
ループ内でバッファのサイズが変更されないようにする。
int shift = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
モメンタム.リフレッシュ()
Bands.Refresh();
Symb.RefreshRates();
// 現在のバーの一目均衡表の値をリフレッシュする。
Ichimoku.Refresh();
//---
Print("State 0: ", sState.state[shift]);
Print("State 1: ", sState.state[shift + 1]);
Print("State 2: ", sState.state[shift + 2]);
Print("State 3: ", sState.state[shift + 3]);
Print("State 4: ", sState.state[shift + 4]);
Print("State 5: ", sState.state[shift + 5]);
Print("State 6: ", sState.state[shift + 6]);
Print("State 7: ", sState.state[shift + 7]);
Print("State 8: ", sState.state[shift + 8]);
Print("State 9: ", sState.state[shift + 9]);
Print("State 10: ", sState.state[shift + 10]);
Print("State 11: ", sState.state[shift + 11]);
Print("State 12: ", sState.state[shift + 12]);
Print("State 13: ", sState.state[shift + 13]);
Print("State 14: ", sState.state[shift + 14]);
Print("State 15: ", sState.state[shift + 15]);
Print("State 16: ", sState.state[shift + 16]);
Print("State 17: ", sState.state[shift + 17]);
Print("State 18: ", sState.state[shift + 18]);
Print("State 19: ", sState.state[shift + 19]);
Print("State 20: ", sState.state[shift + 20]);
Print("State 21: ", sState.state[shift + 21]);
Print("State 22: ", sState.state[shift + 22]);
Print("State 23: ", sState.state[shift + 23]);
Print("State 24: ", sState.state[shift + 24]);
Print("State 25: ", sState.state[shift + 25]);
Print("State 26: ", sState.state[shift + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
また、いくつかのインジケータとパラメータを追加しました。モメンタム、バンド、一目均衡表 =)
int OnInit()
{
シンボルの設定とリフレッシュ
if(! Symb.Name(_Symbol))
return INIT_FAILED;
Symb.Refresh();
//---
if(! RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR.Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice))
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied))
return INIT_FAILED;
一目均衡表の初期化
If (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod)).
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied))
return INIT_FAILED;
//---
if(! RSI.BufferResize(HistoryBars) || !CCI.BufferResize(ヒストリーバーズ) ||)
!ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
を返す;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Rates, true))
を返す;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh()Refresh();
Symb.Refresh();
モメンタム.リフレッシュ();
Bands.Refresh();
Symb.RefreshRates();
現在のバーのイチモク値を更新する
Ichimoku.Refresh();
--- 履歴データ
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Rates[b].open;
float close = (float)Rates[b].close;
float rsi = (float)RSI.Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR.Main(b); float cci = (float)CCI.Main(b)Main(b);
float macd = (float)MACD.Main(b);
float sign = (float)MACD.Signal(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bands.Upper(b);
float bandzb = (float)Bands.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0);計算値を使用する。
float kijun = (float)Ichimoku.KijunSen(1);計算値を使用。
float senkasa = (float)Ichimoku.SenkouSpanA(2);計算値を使用する。
float senkb = (float)Ichimoku.SenkouSpanB(3);計算値を使用する。
EMPTY_VALUEとゼロ除算のチェック
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||)
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE || bandzb == EMPTY_VALUE || を参照。
バンドズロ==EMPTY_VALUE||天覧==EMPTY_VALUE||紀順==EMPTY_VALUE||千笠==EMPTY_VALUE||千笠==EMPTY_VALUE||千笠==EMPTY_VALUE||千笠==EMPTY_VALUE
senkb == EMPTY_VALUE || kijun == 0.0 || senkb == 0.0)
{
を続ける;
}
ループ内でバッファのサイズが変更されないようにする。
int shift = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
モメンタム.リフレッシュ();
Bands.Refresh();
Symb.RefreshRates();
// 現在のバーのイチモク値をリフレッシュする
Ichimoku.Refresh();
//---
Print("State 0: ", sState.state[shift]);
Print("State 1: ", sState.state[shift + 1]);
Print("State 2: ", sState.state[shift + 2]);
Print("State 3: ", sState.state[shift + 3]);
Print("State 4: ", sState.state[shift + 4]);
Print("State 5: ", sState.state[shift + 5]);
Print("State 6: ", sState.state[shift + 6]);
Print("State 7: ", sState.state[shift + 7]);
Print("State 8: ", sState.state[shift + 8]);
Print("State 9: ", sState.state[shift + 9]);
Print("State 10: ", sState.state[shift + 10]);
Print("State 11: ", sState.state[shift + 11]);
Print("State 12: ", sState.state[shift + 12]);
Print("State 13: ", sState.state[shift + 13]);
Print("State 14: ", sState.state[shift + 14]);
Print("State 15: ", sState.state[shift + 15]);
Print("State 16: ", sState.state[shift + 16]);
Print("State 17: ", sState.state[shift + 17]);
Print("State 18: ", sState.state[shift + 18]);
Print("State 19: ", sState.state[shift + 19]);
Print("State 20: ", sState.state[shift + 20]);
Print("State 21: ", sState.state[shift + 21]);
Print("State 22: ", sState.state[shift + 22]);
Print("State 23: ", sState.state[shift + 23]);
Print("State 24: ", sState.state[shift + 24]);
Print("State 25: ", sState.state[shift + 25]);
Print("State 26: ", sState.state[shift + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
JimReaper - 写真のような結果が出るまで、何サイクル研究しましたか? データ収集 - トレーニング)。また、どのくらい時間がかかりましたか?
コンピュータの構成(プロセッサ、ビデオカード、RAM)を教えてください。
ありがとうございます。
then set agent to 5 and Optimisation to 20
Total of 100...
コードの中でエージェントが参照されているのはわかりますが、オプティマイゼーションが 見当たりません。この新しいパラメータを使用するために、さらにコードを追加したのですか?
ありがとう
Paul