
Python、ONNX、MetaTrader 5:RobustScalerとPolynomialFeaturesデータ前処理を使用したRandomForestモデルの作成

どのようなベースを使用するのですか?ランダムフォレストとは?
ランダムフォレスト法の開発の歴史は古く、機械学習と統計の分野の著名な科学者の研究と関連しています。この方法の原理と応用をよりよく理解するために、協力して働く大勢の人々(意思決定木)を想像してみましょう。
ランダムフォレスト法のルーツは、決定木にあります。決定木は意思決定アルゴリズムのグラフィカルな表現として機能します。それぞれのノードは属性の1つに対するテストを表し、枝はそのテストの結果、そして葉は予測された出力を表します。決定木は20世紀半ばに開発され、一般的な分類および回帰のツールになりました。
次の重要なステップは、1996年にレオ・ブレイマンによって提案されたバギング(ブートストラップ集約)の概念でした。バギングとは、訓練データセットを複数のブートストラップサンプル(サブサンプル)に分割し、それぞれに対して個別のモデルを訓練することを意味します。その後、モデルの結果は平均化または結合され、より堅牢で正確な予測が生成されます。この方法により、モデルの分散が低減し、一般化能力が向上しました。
ランダムフォレスト法は、2000年代初頭にレオ・ブレイマンとアデル・カトラーによって提案されました。ランダムフォレスト法は、バギングと追加のランダム性を使用して複数の決定木を組み合わせるというアイデアに基づいています。それぞれの木は訓練データセットのランダムなサブサンプルから構築され、木の中の各ノードを構築するときにランダムな特徴セットが選択されます。これにより、それぞれの木が一意になり、木間の相関関係が減少し、一般化能力が向上します。
ランダムフォレストは、その高いパフォーマンスと分類と回帰の両方の問題を処理できる能力により、機械学習で最も人気のある手法の1つに急速に成長しました。分類問題では、オブジェクトがどのクラスに属するかを決定するために使用され、回帰では数値を予測するために使用されます。
現在、ランダムフォレストは金融、医療、データ分析などさまざまな分野で広く使用されています。堅牢性と複雑な機械学習の問題を処理する能力が高く評価されています。
ランダムフォレストは、機械学習ツールキットの強力なツールです。ランダムフォレストがどのように機能するかをよりよく理解するために、大勢の人が集まり、集団で意思決定をおこなう様子をイメージしてみましょう。ただし、このグループの各メンバーは実際の人間ではなく、現在の状況を独立して分類または予測する者です。このグループ内では、人は特定の属性に基づいて意思決定をおこなうことができる意思決定木です。ランダムフォレストが決定を下すときは、民主主義と投票が使用されます。つまり、それぞれの木が意見を表明し、複数の投票に基づいて決定が下されます。
ランダムフォレストはさまざまな分野で広く使用されており、その柔軟性により分類問題と回帰問題の両方に適しています。分類タスクでは、モデルは現在の状態がどの定義済みクラスに属するかを決定します。たとえば、金融市場では、さまざまな指標に基づいて資産を買う(クラス1)か売る(クラス0)かを決定することを意味します。
ただし、この記事では回帰問題に焦点を当てます。機械学習における回帰は、時系列の過去の値に基づいて将来の数値を予測する試みです。オブジェクトを特定のクラスに割り当てる分類の代わりに、回帰では特定の数値を予測することを目的とします。たとえば、株価の予測、気温の予測、その他の数値変数の予測などがこれに該当します。
基本的なRFモデルの作成
基本的なランダムフォレストモデルを作成するには、Pythonのsklearn (Scikit-learn)ライブラリを使用します。以下は、ランダムフォレスト回帰モデルを訓練するための簡単なコードテンプレートです。このコードを実行する前に、Pythonパッケージインストーラーツールを使用して、sklearnを実行するために必要なライブラリをインストールする必要があります。
pip install onnx
pip install skl2onnx
pip install MetaTrader5
次に、ライブラリをインポートし、パラメータを設定する必要があります。データの作業用の「pandas」、Googleドライブからデータを読み込むための「gdown」、データ処理やランダムフォレストモデルの作成用のライブラリなど、必要なライブラリを読み込みます。また、データシーケンス内の時間ステップ数(n_steps)も設定します。これは、特定の要件に応じて決定されます。
import pandas as pd import gdown import numpy as np import joblib import random import onnx import os import shutil from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score from sklearn.utils import shuffle from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures, PowerTransformer import MetaTrader5 as mt5 from datetime import datetime # Set the number of time steps according to requirements n_steps = 100
次のステップでは、データを読み込んで処理します。具体的な例では、MetaTrader 5から価格データを読み込んで処理します。時間インデックスを設定し、終値のみを選択します(これが私たちが作業するものです)。
以下は、データを訓練セットとテストセットに分割し、モデル訓練用にセットにラベルを付けるコードの部分です。データを訓練セットとテストセットに分割します。次に、回帰のためにデータにラベルを付けます。つまり、各ラベルは実際の将来の価格値を表します。labelling_relabeling_regression関数は、ラベル付きデータを作成するために使用されます。mt5.initialize() SYMBOL = 'EURUSD' TIMEFRAME = mt5.TIMEFRAME_H1 START_DATE = datetime(2000, 1, 1) STOP_DATE = datetime(2023, 1, 1) # Set the number of time steps according to your requirements n_steps = 100 # Process data data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE), columns=['time', 'close']).set_index('time') data.index = pd.to_datetime(data.index, unit='s') data = data.dropna() data = data[['close']] # Work only with close prices
# Define train_data_initial training_size = int(len(data) * 0.70) train_data_initial = data.iloc[:training_size] test_data_initial = data.iloc[training_size:] # Function for creating and assigning labels for regression (changes made for regression, not classification) def labelling_relabeling_regression(dataset, min_value=1, max_value=1): future_prices = [] for i in range(dataset.shape[0] - max_value): rand = random.randint(min_value, max_value) future_pr = dataset['<CLOSE>'].iloc[i + rand] future_prices.append(future_pr) dataset = dataset.iloc[:len(future_prices)].copy() dataset['future_price'] = future_prices return dataset # Apply the labelling_relabeling_regression function to raw data to get labeled data train_data_labeled = labelling_relabeling_regression(train_data_initial) test_data_labeled = labelling_relabeling_regression(test_data_initial)
次に、特定のシーケンスから訓練データセットを作成します。重要なことは、モデルがシーケンス内のすべての終値を特徴として取ることです。ONNXモデルに入力されるデータのサイズと同じシーケンスサイズが使用されます。この段階では正規化はおこなわれません。正規化は、モデルパイプライン操作の一部として、訓練パイプラインで実行されます。
# Create datasets of features and target variables for training x_train = np.array([train_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(train_data_labeled))]) y_train = train_data_labeled['future_price'].iloc[n_steps:].values # Create datasets of features and target variables for testing x_test = np.array([test_data_labeled['<CLOSE>'].iloc[i - n_steps:i].values[-n_steps:] for i in range(n_steps, len(test_data_labeled))]) y_test = test_data_labeled['future_price'].iloc[n_steps:].values # After creating x_train and x_test, define n_features as follows: n_features = x_train.shape[1] # Now use n_features to determine the ONNX input data type initial_type = [('float_input', FloatTensorType([None, n_features]))]
データ前処理用のパイプラインの作成
次のステップは、ランダムフォレストモデルを作成することです。このモデルはパイプラインとして構築する必要があります。
scikit-learn (sklearn)ライブラリのパイプラインは、データ分析と機械学習のための変換とモデルの連続チェーンを作成する方法です。パイプラインを使用すると、複数のデータ処理およびモデリング段階を1つのオブジェクトに結合して、データを効率的かつ連続的に操作できるようになります。
コード例では、次のパイプラインを作成します。
# Create a pipeline with MinMaxScaler, RobustScaler, PolynomialFeatures and RandomForestRegressor
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(
n_estimators=20,
max_depth=20,
min_samples_split=5000,
min_samples_leaf=5000,
random_state=1,
verbose=2
))
])
# Train the pipeline
pipeline.fit(x_train, y_train)
# Make predictions
predictions = pipeline.predict(x_test)
# Evaluate model using R2
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}')
ご覧のとおり、パイプラインは、一連のデータ処理およびモデリング手順を1つのチェーンに組み合わせたものです。このコードでは、scikit-learnライブラリを使用してパイプラインが作成されます。これには次の手順が含まれます。
-
MinMaxScalerはデータを0~1の範囲にスケーリングします。これは、すべての特徴が同じスケールであることを確認するのに役立ちます。
-
RobustScalerもデータのスケーリングを実行しますが、データセット内の外れ値に対してより堅牢です。スケーリングには中央値と四分位範囲を使用します。
-
PolynomialFeaturesは、特徴に多項式変換を適用します。これにより、モデルがデータ内の非線形関係を説明するのに役立つ多項式機能が追加されます。
-
RandomForestRegressorは、一連のハイパーパラメータを持つランダムフォレストモデルを定義します。
- n_estimators(フォレスト内の木の数):金融市場の価格予測を専門とする専門家のグループがあるとします。ランダムフォレスト内の木の数(n_estimators)によって、グループ内に存在するそのような専門家の数が決まります。木の数が増えるほど、モデルが決定を下すときに、より多様な意見や予測が考慮されるようになります。
- max_depth(それぞれの木の最大深度):このパラメータは、各EA(木)がデータ分析にどの程度深く「潜る」ことができるかを設定します。たとえば、最大深度を20に設定すると、それぞれの木は最大20個の機能または特性に基づいて決定を下します。
- min_samples_split(木のノードを分割するためのサンプルの最小数):このパラメータは、木を小さなノードに分割し続けるために、木のノードに必要なサンプル(観測値)の数を示します。たとえば、分割するサンプルの最小数を5000に設定すると、ノードあたりの観測値が5000を超える場合にのみ木はノードを分割します。
- min_samples_leaf(木の葉ノード内のサンプルの最小数):このパラメータは、木の葉ノードが葉になり、それ以上分割されないようにするために、その葉ノードに存在する必要があるサンプルの数を決定します。たとえば、葉ノードのサンプルの最小数を5000に設定すると、木のそれぞれの葉には少なくとも5000個の観測値が含まれます。
- random_state(ランダム生成の初期状態を設定し、再現可能な結果を保証):このパラメータは、モデル内のランダムプロセスを制御するために使用されます。固定値(たとえば1)に設定すると、モデルを実行するたびに結果は同じになります。これは結果の再現性に役立ちます。
- verbose(モデルの訓練プロセスに関する情報の出力を有効化):モデルを訓練するときに、プロセスに関する情報を確認すると便利です。verboseパラメータを使用すると、この情報の詳細レベルを制御できます。値が大きいほど(たとえば2)、訓練プロセス中に出力される情報が多くなります。
パイプラインを作成した後、fitメソッドを使用して訓練データで訓練します。次に、predictメソッドを使用して、テストデータに対して予測をおこないます。最後に、R2メトリクスを使用してモデルの品質を評価します。これは、データに対するモデルの適合度を測定します。
パイプラインは訓練され、R2メトリックに対して評価されます。正規化を使用して、データから外れ値を削除し、多項式特徴を作成します。これらは最も単純なデータ前処理方法です。今後の記事では、Function Transformerを使用して独自の前処理関数を作成する方法について説明します。
モデルをONNXに書き出し、書き出し関数を記述する
パイプラインを訓練した後、joblib形式で保存し、skl2onnxライブラリを使用してONNX形式で保存します。
# Save the pipeline
joblib.dump(pipeline, 'rf_pipeline.joblib')
# Convert pipeline to ONNX
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Save the model in ONNX format
model_onnx_path = "rf_pipeline.onnx"
onnx.save_model(onnx_model, model_onnx_path)
# Connect Google Drive (if you work in Colab and this is necessary)
from google.colab import drive
drive.mount('/content/drive')
# Specify the path to Google Drive where you want to move the model
drive_path = '/content/drive/My Drive/' # Make sure the path is correct
rf_pipeline_onnx_drive_path = os.path.join(drive_path, 'rf_pipeline.onnx')
# Move ONNX model to Google Drive
shutil.move(model_onnx_path, rf_pipeline_onnx_drive_path)
print('The rf_pipeline model is saved in the ONNX format on Google Drive:', rf_pipeline_onnx_drive_path)
これがモデルを訓練し、ONNXに保存した方法です。訓練を完了すると、次の画面が表示されます。
モデルは、GoogleドライブのベースディレクトリにONNX形式で保存されます。ONNXは、機械学習モデルの一種の「フロッピーディスク」と考えることができます。この形式を使用すると、訓練済みのモデルを保存し、さまざまなアプリケーションで使用できるように変換できます。これは、ファイルをフラッシュドライブに保存して、他のデバイスで読み取る方法に似ています。私たちの場合、ONNXモデルはMetaTrader 5環境で金融市場の価格を予測するために使用されます。ONNX「フロッピーディスク」自体は、MetaTrader 5などのサードパーティアプリケーションで読み取ることができます。これが私たちがこれからやることです。
MetaTrader 5テスターでモデルを確認する
以前、ONNXモデルをGoogleドライブに保存たので、そこからダウンロードしてみましょう。MetaTrader 5でこのモデルを使用するには、このモデルを読み取って適用し、取引の決定を下すEAを作成しましょう。提示されたEAコードで、ロット量、ストップ注文の使用、利益確定および損失確定のレベルなどの取引パラメータを設定します。以下は、ONNXモデルを「読み取る」EAのコードです。
//+------------------------------------------------------------------+ //| ONNX Random Forest.mq5 | //| Copyright 2023 | //| Evgeniy Koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com" #property version "0.90" static vectorf ExtOutputData(1); vectorf output_data(1); #include <Trade\Trade.mqh> CTrade trade; input double InpLots = 1.0; // Lot volume to open a position input bool InpUseStops = true; // Trade with stop orders input int InpTakeProfit = 500; // Take Profit level input int InpStopLoss = 500; // Stop Loss level #resource "Python/rf_pipeline.onnx" as uchar ExtModel[] #define SAMPLE_SIZE 100 long ExtHandle=INVALID_HANDLE; int ExtPredictedClass=-1; datetime ExtNextBar=0; datetime ExtNextDay=0; CTrade ExtTrade; #define PRICE_UP 1 #define PRICE_SAME 2 #define PRICE_DOWN 0 // Function for closing all positions void CloseAll(int type=-1) { for(int i=PositionsTotal()-1; i>=0; i--) { if(PositionSelectByTicket(PositionGetTicket(i))) { if(PositionGetInteger(POSITION_TYPE)==type || type==-1) { trade.PositionClose(PositionGetTicket(i)); } } } } // Expert Advisor initialization int OnInit() { if(_Symbol!="EURUSD" || _Period!=PERIOD_H1) { Print("The model should work with EURUSD, H1"); return(INIT_FAILED); } ExtHandle=OnnxCreateFromBuffer(ExtModel,ONNX_DEFAULT); if(ExtHandle==INVALID_HANDLE) { Print("Error creating model OnnxCreateFromBuffer ",GetLastError()); return(INIT_FAILED); } const long input_shape[] = {1,100}; if(!OnnxSetInputShape(ExtHandle,ONNX_DEFAULT,input_shape)) { Print("Error setting the input shape OnnxSetInputShape ",GetLastError()); return(INIT_FAILED); } const long output_shape[] = {1,1}; if(!OnnxSetOutputShape(ExtHandle,0,output_shape)) { Print("Error setting the output shape OnnxSetOutputShape ",GetLastError()); return(INIT_FAILED); } return(INIT_SUCCEEDED); } // Expert Advisor deinitialization void OnDeinit(const int reason) { if(ExtHandle!=INVALID_HANDLE) { OnnxRelease(ExtHandle); ExtHandle=INVALID_HANDLE; } } // Process the tick function void OnTick() { if(TimeCurrent()<ExtNextBar) return; ExtNextBar=TimeCurrent(); ExtNextBar-=ExtNextBar%PeriodSeconds(); ExtNextBar+=PeriodSeconds(); PredictPrice(); if(ExtPredictedClass>=0) if(PositionSelect(_Symbol)) CheckForClose(); else CheckForOpen(); } // Check position opening conditions void CheckForOpen(void) { ENUM_ORDER_TYPE signal=WRONG_VALUE; if(ExtPredictedClass==PRICE_DOWN) signal=ORDER_TYPE_SELL; else { if(ExtPredictedClass==PRICE_UP) signal=ORDER_TYPE_BUY; } if(signal!=WRONG_VALUE && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { double price,sl=0,tp=0; double bid=SymbolInfoDouble(_Symbol,SYMBOL_BID); double ask=SymbolInfoDouble(_Symbol,SYMBOL_ASK); if(signal==ORDER_TYPE_SELL) { price=bid; if(InpUseStops) { sl=NormalizeDouble(bid+InpStopLoss*_Point,_Digits); tp=NormalizeDouble(ask-InpTakeProfit*_Point,_Digits); } } else { price=ask; if(InpUseStops) { sl=NormalizeDouble(ask-InpStopLoss*_Point,_Digits); tp=NormalizeDouble(bid+InpTakeProfit*_Point,_Digits); } } ExtTrade.PositionOpen(_Symbol,signal,InpLots,price,sl,tp); } } // Check position closing conditions void CheckForClose(void) { if(InpUseStops) return; bool tsignal=false; long type=PositionGetInteger(POSITION_TYPE); if(type==POSITION_TYPE_BUY && ExtPredictedClass==PRICE_DOWN) tsignal=true; if(type==POSITION_TYPE_SELL && ExtPredictedClass==PRICE_UP) tsignal=true; if(tsignal && TerminalInfoInteger(TERMINAL_TRADE_ALLOWED)) { ExtTrade.PositionClose(_Symbol,3); CheckForOpen(); } } // Function to get the current spread double GetSpreadInPips(string symbol) { double spreadPoints = SymbolInfoInteger(symbol, SYMBOL_SPREAD); double spreadPips = spreadPoints * _Point / _Digits; return spreadPips; } // Function to predict prices void PredictPrice() { static vectorf output_data(1); static vectorf x_norm(SAMPLE_SIZE); double spread = GetSpreadInPips(_Symbol); if (!x_norm.CopyRates(_Symbol, _Period, COPY_RATES_CLOSE, 1, SAMPLE_SIZE)) { ExtPredictedClass = -1; return; } if (!OnnxRun(ExtHandle, ONNX_NO_CONVERSION, x_norm, output_data)) { ExtPredictedClass = -1; return; } float predicted = output_data[0]; if (spread < 0.000005 && predicted > iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_UP; } else if (spread < 0.000005 && predicted < iClose(Symbol(), PERIOD_CURRENT, 1)) { ExtPredictedClass = PRICE_DOWN; } else { ExtPredictedClass = PRICE_SAME; } }
次の入力次元に注意してください。
const long input_shape[] = {1,100};
Pythonモデルの次元と一致する必要があります。
# Set the number of time steps to your requirements n_steps = 100
次に、MetaTrader 5環境でモデルのテストを始めます。モデルの予測を使用して、価格変動の方向を決定します。モデルが価格が上昇すると予測した場合は、ロングポジション(買い)を建てる準備をし、逆に、モデルが価格が下落すると予測した場合は、ショートポジション(売り)を建てる準備をします。テイクプロフィットを1000、ストップロスを500にしてモデルをテストしてみましょう。
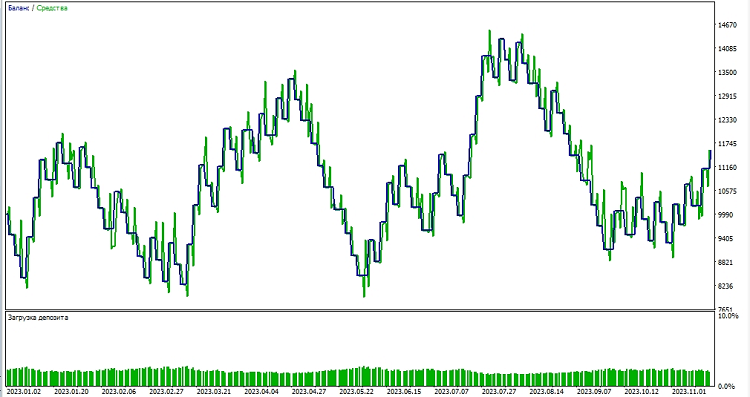
結論
この記事では、Pythonでランダムフォレストモデルを作成して訓練する方法、モデル内で直接データを前処理する方法、ONNX標準で書き出して、MetaTrader 5でモデルを開いて使用する方法について説明しました。
ONNXは優れたモデル読み込み/書き出しシステムで、普遍的かつシンプルです。ONNXでモデルを保存するのは、実際には見た目よりもはるかに簡単です。データの前処理も非常に簡単です。
もちろん、決定木が20本だけのモデルは非常に単純であり、ランダムフォレストモデル自体はすでにかなり古いソリューションです。今後の記事では、より複雑なデータ前処理を使用して、より複雑で最新のモデルを作成します。また、前処理と同時に、sklearnパイプラインの形式でモデルのアンサンブルをすぐに作成できる可能性にも注目したいと思います。これにより、分類問題を含む機能が大幅に拡張されます。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13725
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
単純な例として森を選んだだけだ。)
グッド)
コンベアとその ONNX への変換、およびその後のメタトレーダーでの使用に関するトピックをさらに発展させることができれば面白いと思います。例えば、パイプラインにカスタム変換を追加することは可能で、そのようなパイプラインから得られたONNXモデルはメタトレーダーで開くことができるのでしょうか?このトピックはいくつかの記事に値すると思います。
コンベアとその ONNX への変換、およびその後のメタトレーダーでの使用に関するトピックをさらに発展させることができれば面白いと思います。例えば、パイプラインにカスタム変換を追加することは可能で、そのようなパイプラインから得られたONNXモデルはメタトレーダーで開くことができるのでしょうか?このトピックはいくつかの記事に値すると思います。