
Нейросети — это просто (Часть 66): Проблематика исследования в офлайн обучении

Введение
С первых статей изучения методов обучения с подкреплением подымается вопрос баланса между исследованием окружающей среды и эксплуатацией выученной политики. И ранее были рассмотрены различные методы стимулирования Агента к исследованию. Но довольно часто алгоритмы, которые демонстрируют отличные результаты в онлайн обучении, оказываются не столь эффективны в офлайн режиме. Проблема в том, что для офлайн режима информация об окружающей среде ограничена объемами обучающей выборки. И чаще всего данные, отобранные для обучения моделей, являются узко направленными, так как собраны в малом подпространстве поставленной задачи. Тем самым давая еще более скудное представление об окружающей среде. Однако для нахождения оптимального решения Агенту необходимо наиболее полное представление об окружающей среде и её закономерностях. Мы уже обращали внимание, что результаты обучения часто зависят от обучающей выборки.
Более того, довольно часто в процессе обучения Агент принимает решения, выходящие за рамки подпространства обучающей выборки. И в подобных случаях сложно спрогнозировать последующие результаты. Именно поэтому мы после предварительного обучения модели осуществляем дополнительный сбор траекторий в обучающую выборку, которые способны скорректировать процесс обучения.
Онлайн обучение модели окружающей среды иногда позволяет смягчить вышеуказанные проблемы. Но, к сожалению, в следствие различных причин обучение модели окружающей среды не всегда представляется возможным. Довольно часто, обучение модели может быть ещё дороже обучения политики Агента. А иногда просто невозможно.
Вторым очевидным направлением является расширение обучающей выборки. Но здесь мы прежде всего упираемся в физический размер имеющихся ресурсов и лимитом затрат на изучение окружающей среды.
В данной статье я предлагаю Вам познакомиться с фреймворкам Exploratory data for Offline RL (ExORL), который был представлен в статье "Don't Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning". Представленные в статье результаты демонстрируют, что корректный подход к сбору данных оказывает значительное влияние на конечные результаты обучения. Так же как выбор алгоритма обучения и архитектуры модели.
1. Метод Exploratory data for Offline RL (ExORL)
Сразу надо сказать, что авторы метода Exploratory data for Offline RL (ExORL) не предлагают новых алгоритмов обучения или архитектурных решений моделей. Напротив, все внимание акцентируется на процессе сбора данных для обучения моделей. И далее проводятся эксперименты с пятью различными методами обучения для оценки влияния содержания обучающей выборки на результат обучения.
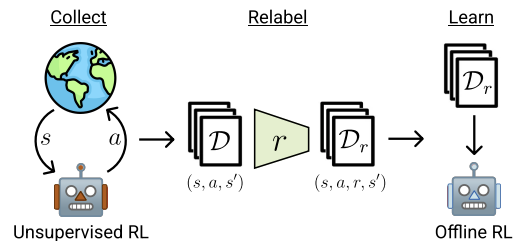
Метод ExORL можно разделить на 3 основных этапа. Первый этап — сбор неразмеченных исследовательских данных. Для этого возможно использование различных алгоритмов обучения без учителя. Авторы метода не ограничивают круг используемых алгоритмов. При этом в процессе взаимодействия с окружающей средой на каждом эпизоде используем политику π, зависящую от истории предыдущих взаимодействий. Каждый эпизод сохраняется в наборе данных в виде последовательности состояния St, дейcтвия At и последующего состояния St+1. Сбор обучающих данных осуществляется до полного заполнения обучающей выборки, размер которой органичен техническим заданием или доступными ресурсами.
На практике авторы статьи оценивают девять различных алгоритмов сбора данных без учителя:
- Простая базовая линия, которая всегда выводит политику равномерно случайного выбора;
- Методы на основе максимизации ошибки предиктивной модели: ICM, Disagreement, RND;
- Алгоритмы, максимизирующие некоторую оценку охвата пространства состояний: APT и Proto-RL;
- Алгоритмы, основанные на компетенциях, обучающие разнообразному набору навыков: DIAYN, SMM, и APS.
После сбора набора данных о состояниях и действиях, осуществляется их переоценка с использованием заданной функции вознаграждения. На этом этапе просто необходимо оценить вознаграждение для каждого кортежа в наборе данных.
В своих экспериментах авторы метода используют стандартные или ручные функции вознаграждения. При этом отмечается, что предложенный фреймворк также позволяет обучать функцию вознаграждения. То есть осуществлять инверсное RL.
Последним этапом ExORL является обучение модели. Обучение политики осуществляется с использованием оффлайн алгоритмов обучения с подкреплением на размеченном наборе данных. Оффлайн обучение осуществляется полностью на оффлайн данных обучающей выборки, путем случайного выбора кортежей. После чего конечная политика оценивается в реальной окружающей среде.
Ниже представлена авторская визуализация метода.
В статье авторы демонстрируют результаты пяти различных алгоритмов оффлайн обучения с подкреплением. В качестве базового варианта используется простое клонирование поведения. Так же представлены результаты трех современных алгоритма оффлайн обучения с подкреплением, каждый из которых использует различные механизм для предотвращения экстраполяции за пределы действий в данных. И классический TD3 представлен в качестве базового теста, чтобы оценить влияние оффлайн режима на методы изначально разработанные для обучения онлайн и не имеющие механизма, явно предназначенного для предотвращения экстраполяции за пределы обучающей выборки.
По результатам проведенных экспериментов авторы метода делают вывод, что использование разнообразных данных может существенно упростить алгоритмы оффлайн обучения с подкреплением, избавляясь от необходимости бороться с проблемой экстраполяции. Результаты демонстрируют, что исследовательские данные повышают эффективность оффлайн обучения с подкреплением при решении множества задач. Кроме того, ранее разработанные алгоритмы оффлайн обучения с подкреплением хорошо справляются с данными, ориентированными на задачу, но уступают TD3 на неразмеченных данных ExORL. В идеале алгоритмы оффлайн обучения с подкреплением должны автоматически адаптироваться к используемому набору данных, чтобы восстановить лучшее из обоих подходов.
2. Реализация средствами MQL5
Как можно заметить их представленного выше описания, авторы метода Exploratory data for Offline RL (ExORL) дают общее направление построения фреймворка. При этом сами экспериментируют с различными методами обучения моделей. И в практической части статьи я решил построить реализацию ExORL максимально приближенную к модели из предыдущей статьи. Но здесь следует обратить внимание на один конструктивный момент. Алгоритм DWSL предусматривает взвешивание действий из состояния S по их Преимуществу. Напомню, что в нашей реализации мы находили наиболее близкие состояния из всех траекторий по их эмбедингу. И взвешивали действия в отобранных состояниях в соответствии с их влиянием на результат.
А вот метод ExORL предполагает максимальное разнообразие поведения Агента. И в этой связи нам необходимо определять расстояние между действиями в отдельных состояниях. Использование расстояния до наиболее близкой пары "Состояние-Действие" в качестве вознаграждения будет стимулировать Агента к исследованию окружающей среды. Следовательно, мы будем определять эмбединг состояния с учетом действия.
В качестве альтернативного варианта существует практика определения расстояния между последующими состояниями. И в этом есть доля рационализма при работе со стохастической окружающей средой. Когда совершение одного действия с некоторой вероятностью может привести в различные последующие состояния. Но использование подобных алгоритмов еще больше нас отделяет от метода DWSL, который мы используем в качестве базового для нашей реализации. А минимальные корректировки базового алгоритма позволят нам лучше оценить влияние именно фреймворка ExORL на результат обучения модели.
Поэтому я остановился на первом варианте и увеличил размер слоя исходных данных модели Энкодера на вектор действий Актера. В остальном архитектура моделей осталась без изменений. И Вы можете самостоятельно с ней ознакомиться во вложении. Файл "...\ExORL\Trajectory.mqh", метод CreateDescriptions.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor ........ ........ //--- Critic ........ ........ //--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr + NActions; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 ........ ........ //--- return true; }
Непосредственно процесса сбора обучающих данных организован в советнике "...\ExORL\ResearchExORL.mq5".
Обратите внимание на указание фреймворка в названии файла. Дело в том, что во вложении Вы найдете и файл "...\ExORL\Research.mq5", который без изменений был перенесен из предыдущей статьи. И мы не будем останавливаться на рассмотрении его алгоритма.
Оба указанных советника предназначены для наполнения обучающей выборки. И как это не покажется странным, в процессе обучения мы будем использовать оба советника. Но об этом мы поговорим немного позже. А сейчас вернемся к рассмотрению алгоритма советника "...\ExORL\ResearchExORL.mq5".
Внешние параметры советника перенесены без изменений из базового советника взаимодействия с окружающей средой.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = 10; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price input int Agent = 1;
Только вот в процессе взаимодействия мы будем обучать политику исследования окружающей среды для Актера. А в процессе обучения нам понадобятся модели Критика и Энкодера. Для снижения затрат на обучение политики исследования и, как следствие, повышения скорости сбора обучающих данных было принято решение использовать только 1 Критика.
CNet Actor; CNet Critic; CNet Convolution;
Кроме того, в список глобальных переменных мы добавим флаг загрузки ранее пройденных траекторий и матрицу их эмбедингов.
bool BaseLoaded; matrix<float> state_embeddings;
В методе инициализации советника OnInit мы сначала инициализируем анализируемые индикаторы.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Укажем тип ордера торговых операций.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
И загрузим предварительно обученные модели. При отсутствии таковых мы создаем новые модели, инициализированные случайными весами. В данном советнике я решил разделить загрузку моделей на разные блоки, что позволяет мне использовать ранее обученного Критика при отсутствии обученного Актера или Энкодера.
Обратите внимание, что ранее мы всегда говорили о необходимости наличия полного набора синхронизированных моделей. А в данном случае намеренно используем Критика, обученного отдельно от Актера. И тому есть причина. Я долго думал о построении алгоритма синхронизации весовых коэффициентов между моделями в разных агентах тестирования MetaTrader 5. Но отказался от этой идеи и принял решение о создании нескольких параллельно обучаемых моделей Актера исследования. Однажды инициализированные случайными параметрами, такие модели будут параллельно обучаться на исторических данных. И несмотря на один исторический отрезок, каждая модель Актера исследования пройдет свой индивидуальный путь обучения. Тем самым расширяя исследованное подпространство окружающей среды. А использование одного буфера ранее пройденных траекторий позволит минимизировать повторение траекторий.
Для идентификации моделей Актеров исследования в название файла модели мы добавляем суффикс "Ex" и номер агента из внешних параметров. А оптимизация по данному параметру позволяет нам запускать несколько Актеров-исследования параллельно в тестере стратегий MetaTrader 5.
//--- load models float temp; if(!Actor.Load(StringFormat("%sAct%d.nnw", FileName, Agent), temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- }
В то же время, для организация идентичных условий обучения всех Актеров-исследования мы используем одну модель Критика. Именно поэтому нам важно загрузить предварительно обученную модель Критика даже при отсутствии моделей Актеров-исследования.
if(!Critic.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Critic.Create(critic)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Использование единой модель Энкодера для всех агентов так же позволяет организовать сравнение состояний и действий в едином подпространстве. Но не является критичным для процесса обучения. Так как каждый Агент самостоятельно осуществляет кодирование ранее пройденных траекторий. Что позволяет ему корректно оценивать расстояния и разнообразить поведение Актера.
if(!Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Convolution.Create(convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Согласен, что представленный код выглядит громоздко. И, наверное, логично было бы разделить описание архитектуры моделей по разным методам. Но это упростило бы код только данного советника. И напротив усложнило бы код других программ, используемых в статье. Именно по этой причине я отказался от дробления метода описания архитектуры моделей.
Все модели мы переводим в единый контекст OpenCL, что позволит нам синхронизировать их работу и снизить объем копирования данных между основной памятью и памятью контекста OpenCL.
Critic.SetOpenCL(Actor.GetOpenCL());
Convolution.SetOpenCL(Actor.GetOpenCL());
Critic.TrainMode(false);
Обратите внимание, что мы отключаем режим обучения Критика. Выше мы обсуждали важность создания одинаковых условий для обучения всех Агентов исследования окружающей среды. И сохранение Критика в фиксированном состоянии играет важную роль в этом процессе.
Затем мы осуществляем уже стандартный минимальный контроль архитектуры моделей.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
И инициализируем глобальные переменные.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); BaseLoaded = false; bGradient.BufferInit(MathMax(AccountDescr, NActions), 0); //--- return(INIT_SUCCEEDED); }
После успешного завершения всех вышеуказанных операций мы завершаем работу метода инициализации советника.
В методе инициализации программы мы не загружаем ранее пройденные траектории. И не создаем их эмбединги. Это связано с тем, что процесс создания эмбедингов ранее пройденных состояний может быть довольно затратным и длительным. Его продолжительность зависит от количества посещенных состояний.
Как уже было сказано ранее, в отличии от ранее рассмотренных советников взаимодействия с окружающей средой, в данном случае мы осуществляем обучения Актера-исследования. И по завершению каждого прохода мы сохраняем обученную модель.
void OnDeinit(const int reason) { //--- ResetLastError(); if(!Actor.Save(StringFormat("%sActEx%d.nnw", FileName, Agent), 0, 0, 0, TimeCurrent(), true)) PrintFormat("Error of saving Agent %d: %d", Agent, GetLastError()); delete Result; }
Далее следует сказать несколько слов о созданных вспомогательных методах. Прежде всего был вынесен процесс кодировки состояний и действий в метод CreateEmbeddings. Данный метод не имеет параметров и возвращает матрицу эмбедингов состояний.
В теле метода мы сначала создаем локальные переменные.
matrix<float> CreateEmbeddings(void) { vector<float> temp; CBufferFloat State; Convolution.getResults(temp); matrix<float> result = matrix<float>::Zeros(0, temp.Size());
Затем пробуем загрузить ранее собранную базу траекторий. И в случае ошибки загрузки данных возвращаем вызывающей программе пустую матрицу.
BaseLoaded = LoadTotalBase(); if(!BaseLoaded) { PrintFormat("%s - %d => Error of load base", __FUNCTION__, __LINE__); return result; }
При успешной загрузке базы траекторий мы подсчитываем общее количество состояний во всех траекториях и изменяем размер заполняемой матрицы.
int total_tr = ArraySize(Buffer); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; result.Resize(total_states, temp.Size());
Далее идет система вложенных циклов кодировки состояний и действий. Во внешнем цикле мы будем перебирать загруженные траектории. А во вложенном цикле — состояния.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
В теле указанной системы циклов мы сначала создаем буфер исходных данных описания состояния окружающей среды. В указанный буфер мы переносим исторические данные движения цены и показателей анализируемых индикаторов.
Затем добавляем описание состояния счета и открытых позиций.
float prevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float prevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - prevBalance) / prevBalance); State.Add(Buffer[tr].States[st].account[1] / prevBalance); State.Add((Buffer[tr].States[st].account[1] - prevEquity) / prevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / prevBalance); State.Add(Buffer[tr].States[st].account[5] / prevBalance); State.Add(Buffer[tr].States[st].account[6] / prevBalance);
Добавляем временную метку в виде вектора гармоник.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
И добавляем вектор действий Актера.
State.AddArray(Buffer[tr].States[st].action);
Собранный тензор мы передаем Энкодеру для кодирования и вызываем метод прямого прохода. Полученный эмбединг добавляем в матрицу результатов.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp); if(!result.Row(temp, state)) continue; state++; } } }
После чего переходим к следующему состоянию из буфера траекторий.
После завершения всех итераций системы циклов кодирования состояний мы уменьшаем размер матрицы результатов до фактического количества сохраненных эмбедингов и очищаем буфер ранее загруженных траекторий. В дальнейшем мы будем работать только с эмбедингами.
if(state != total_states) result.Reshape(state, result.Cols()); ArrayFree(Buffer);
Полученный результат возвращаем вызывающей программе и завершаем работу метода.
//--- return result; }
Далее мы построили метод генерации внутреннего вознаграждения ResearchReward. Здесь стоит обратить внимание, что для создания системы эффективного исследования окружающей среды при обучении Актеров-исследования мы будем использовать только внутреннее вознаграждение, направленное на стимулирование Агента к совершению разнообразных и не повторяющихся действий. Поэтому на данном этапе нам не нужны размеченные данные или внешнее вознаграждение, способные ограничить исследуемое пространство окружающей среды. В этой связи следует особое внимание уделить формированию внутреннего вознаграждения.
В параметрах метода ResearchReward мы передадим:
- квантиль наиболее близких состояний и действий, используемых для формирования внутреннего вознаграждения;
- эмбелинг анализируемого состояния;
- матрицу эмбедингов состояний, которая была сформирована выше представленным методом.
В теле метода мы подготовим нулевой вектор результатов и проверим соответсвтие размеров эмбединга анализируемого состояния с эмбедингами в ранее созданной матрице.
vector<float> ResearchReward(double quant, vector<float> &embedding, matrix<float> &state_embedding) { vector<float> result = vector<float>::Zeros(NRewards); if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
После успешного прохождения контрольного блока мы инициализируем локальные переменные.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * quant); matrix<float> temp = matrix<float>::Zeros(states, size); vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S;
Следующим этапом мы посчитаем расстояние между анализируемой парой "Состояние-Действие" ранее сохраненными в буфере воспроизведения опыта. Для получения мягкой оценки расстояний мы воспользуемся функцией LogSumExp, как было предложено авторами метода DWSL.
for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha = temp.Max(); if(alpha == 0) alpha = 1; vector<float> dist = MathLog(MathExp(temp / (-alpha)).Sum(1)) * (-alpha);
Далее мы отбираем необходимое количество эмбедингов ближайших пар "Состояния-Действие".
float max = dist.Quantile(quant); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
И с помощью алгоритма ядерных норм генерируем внутреннее вознаграждение для выбранного действия Актера и латентного состояния.
k_embedding.SVD(U, V, S); result[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result[NRewards - 1] = EntropyLatentState(Actor); //--- return result; }
Полученный результат возвращаем вызывающей программе.
Обратите внимание, что в векторе результатов элементы внешнего вознаграждения остались с нулевыми значениями. Что вполне соответствует фреймворку ExORL. Рассматриваемый советник предназначен для организации неконтролируемого исследования окружающей среды. И как уже было сказано выше, использование внешнего вознаграждения на данном этапе лишь сузит исследуемое подпространство.
Непосредственно процесс взаимодействия с окружающей средой и обучения политики Актера-исследования организован в методе обработки тиков OnTick. Сразу надо сказать, что на данном этапе процесс обучения был максимально упрощен. Как уже было озвучено выше, в процессе обучения используется только 1 Критик. Кроме того, мы не отказались от использования буфера воспроизведения опыта в процессе обучения модели Актера-исследования. Потенциально, его отсутствие компенсируется дополнительными проходами в тестере стратегий.
Мы будем осуществлять по одному обратному проходу на каждой свече. При этом осуществляется корректировка параметров по последнему действию Актера.
Такой подход может быть и не самый эффективный, наиболее простой в реализации. И вполне применим для оценки эффективности метода.
В теле метода мы, как всегда, сначала проверяем наступление события открытия нового бара.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
После чего загружаем исторические данные.
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Далее мы формируем буферы исходных данных нашего Актера-исследования. Здесь мы сначала заполняем буфер описания состояния окружающей среды полученными историческими данными.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Далее мы проверим текущее состояние счета и открытые позиции.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Из полученных данных создадим буфер описания состояния счета.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
В который затем добавим вектор гармоник временной метки.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
Сформированных данных достаточно для осуществления прямого прохода Актера.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
В результате успешного прямого прохода Актера мы получаем вектор прогнозных действий, который мы дешифруем и передаем окружающей среде.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Сначала мы осуществляем взаимодействие с окружающей средой в рамках длинной позиции.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
И повторяем операции для короткой.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Результаты взаимодействия с окружающей средой мы собираем в структуру описания состояния и действий. Дополняем внешним вознаграждением. И дописываем в траекторию, которая по результатам прохода будет добавлена в буфер воспроизведения опыта.
//--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove();
Здесь стоит обратить внимание на вектор вознаграждений. Выше мы говорим неконтролируемом исследовании, а вектор заполняем внешними вознаграждениями. При этом элементы внутреннего вознаграждения, наоборот, оставляем с нулевыми значениями. Здесь надо понимать, что сохраняемые траектории будут использоваться для обучения основной политики Актера на 3 этапе фреймворка ExORL. А заполнения буфера вознаграждения является реализацией второго этапе рассматриваемого метода — Переоценка состояний и действий. Поэтому все наши действия укладываются в рамки алгоритма ExORL.
Как Вы можете заметить, представленный выше алгоритм практически полностью повторяет рассмотренные нами ранее методы взаимодействия с окружающей средой. Но на этом мы не завершаем работу метода, как ранее. А переходим к реализации процесса обучения политики Актера-исследования.
Прежде всего, нам необходим эмбединг текущего состояния и совершенного действия. Для этого мы дополняем буфер текущего состояния окружающей среды информацией о состоянии счета и совершенном действии Актера. Полученный буфер подаем на вход Энкодера и вызываем метод прямого прохода.
bState.AddArray(GetPointer(bAccount)); bState.AddArray(temp); bActions.AssignArray(temp); if(!Convolution.feedForward(GetPointer(bState), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Convolution.getResults(temp);
В результате успешных операций мы получаем эмбединг текущего состояния.
Далее мы проверяем наличие загруженных данных о ранее пройденных траекториях и, при необходимости, осуществляем их кодирование, путем вызова выше представленного метода CreateEmbeddings.
if(!BaseLoaded) { state_embeddings = CreateEmbeddings(); BaseLoaded = true; }
Обратите внимание, что вне зависимости от результата операций мы переводим в состояние true флаг загрузки данных. Это позволит нам в будущем исключить повторные попытки загрузки базы пройденных состояний.
Далее мы проверяем размер матрицы эмбединга состояний. Нулевой размер данной матрицы может свидетельствовать об отсутствии ранее пройденных траекторий. В таком случае у нас нет данных для обновления параметров модели на данном этапе. И мы просто добавляем в матрицу эмбединг текущего состояния. После чего переходим к ожиданию открытия следующей свечи.
ulong total_states = state_embeddings.Rows(); if(total_states <= 0) { ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError()); return; }
При наличии данных в матрице эмбединга пройденных состояний мы генерируем внутреннее вознаграждение и дополняем матрицу эмбедингом текущего состояния.
vector<float> rewards = ResearchReward(Quant, temp, state_embeddings); ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError());
Очень важно эмбединг текущего состояния добавлять в матрицу эмбедингов пройденных состояний только после генерации внутреннего вознаграждения. В противном случае, текущий эмбединг будет дважды учтен при расчёте внутреннего вознаграждения, что способно исказить данные.
Полное же исключение процесса добавления эмбедингов в матрицу не позволит учитывать состояния текущего прохода при генерации внутреннего вознаграждения.
Сгенерированное внутреннее вознаграждение мы переносим в буфер данных. И далее осуществляем прямой и обратный проход Критика. С последующим обратным проходом Актера-исследования.
Result.AssignArray(rewards); if(!Critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(bActions)) || !Critic.backProp(Result, GetPointer(bActions), GetPointer(bGradient)) || !Actor.backPropGradient(GetPointer(bAccount), GetPointer(bGradient), LatentLayer)) PrintFormat("%s -> %d: Error of backpropagation %", __FUNCTION__, __LINE__, GetLastError()); }
Обратите внимание, что в данном случае мы рамках одной операции осуществляем последовательный вызов методов прямого и обратного прохода Критика. Дело в том, что в данном случае мы не осуществляем обучения Критика и не оцениваем результаты его прямого прохода. Он нам необходим лишь для передачи градиента ошибки Актеру. Поэтому оба метода вызываются в рамках организации процедуры обратного прохода Актера. Это и привело к столь необычной компоновке вызова методов, что, в прочем, не оказывает влияния на конечный результат.
На этом мы завершаем описания метода взаимодействия со средой и онлайн обучения политики Актера-исследования. Прочие методы советника были перенесены без изменений. И вы самостоятельно можете ознакомиться с ними во вложении.
А мы переходим к корректировки советника обучения модели. Несмотря на то, что авторы метода в своих экспериментах использовали базовые методы обучения моделей, в реализации нашего подхода потребовались все же некоторые изменения советника обучения из предыдущей статьи. Внесенные изменения главным образом обусловлены изменением архитектуры Энкодера, что повлекло корректировку моментов взаимодействия с моделью. Но обо всем по порядку.
Внесенные изменения не являются глобальными. Поэтому мы остановимся лишь на рассмотрении метода непосредственного обучения модели Train. В теле метода мы проверяем количество загруженных траекторий.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
После чего осуществляем подсчет общего количества состояний в данных траекториях.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total;
Далее мы подготовим локальные переменные.
vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
И организуем систему циклов кодирования ранее пройденных состояний с составлением матрицы эмбедингов. Данный процесс напоминает выше описанный процесс, но есть один нюанс.
Как и ранее, в теле системы циклов мы заполняем буфер текущего состояния окружающей среды.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
Дополняем его состоянием счета и открытых позиций.
float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance);
Заполняем гармоники временной метки.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
А вот вместо вектора действий передаем нулевой вектор соответствующей длины.
State.AddArray(vector<float>::Zeros(NActions));
Такое решение позволяет нам исключить влияние совершенных действий на эмбединг состояний. И тем самым вернуть нас в реализацию метода DWSL из прошлой статьи, нивелируя изменения архитектуры Энкодера. Таким образом, в соответствии с рекомендациями авторов метода ExORL мы используем не измененные методы обучения моделей. При этом в процессе обучения всех моделей используется один Энкодер "Состояний-Действий". Что позволяет нам максимально корректно обучать как политики Актеров-исследования, так и основную политику Актера.
Далее мы осуществляем прямой проход Энкодера. А результат операций в виде эмбединга состояния добавляем в матрицу.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); if(!state_embedding.Row(temp, state)) continue;
Тут же мы синхронно заполняем матрицы действий и вознаграждений, которые будут использоваться в процессе обучения в соответствии с алгоритмом DWSL. Как и ранее, матрица вознаграждений заполняется значениями преимуществ совершенных действий.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue; state++;
Информируем пользователя о ходе кодирования состояний и переходим к следующей итерации системы циклов.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
После успешного завершения всех итераций кодирования состояний мы уменьшаем размеры матриц до объема фактически сохраненных данных. Однако в отличии от выше рассмотренного метода кодирования CreateEmbeddings мы не очищаем массив траекторий, так как он нам еще понадобится при обучении моделей.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
} Далее следует организация непосредственного процесса обучения. Сначала мы создаем локальные переменные и формируем вектор вероятностей выбора траекторий.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr;
После чего организовываем цикл обучения. В теле цикла сэмплируем траекторию и состояние на ней.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
Затем мы проверяем необходимость формирования вознаграждения до конца эпизода. И в случае необходимости заполняем буфер последующего состояния окружающей среды.
target_reward = vector<float>::Zeros(NRewards); //--- Target if(iter >= StartTargetIter) { State.AssignArray(Buffer[tr].States[i + 1].state);
Тут же мы заполняем буфер описания последующего состояния счета и отрытых позиций.
float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
И дополняем его гармониками временной метки.
double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Сформированных данных достаточно для осуществления прямого прохода Актера, который сгенерирует действие в соответствии с обновленной политикой.
//--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Полученное действие оценивается 2 целевыми Критиками.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2);
В качестве ожидаемого вознаграждения мы используем меньшую из оценок. И дополняем её энтропией латентного состояния.
target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
Следующим этапом мы обучаем модели Критиков. Для этого формируем вектор описания текущего состояния окружающей среды.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Формируем вектор описания состояния счета и открытых позиций, дополненный гармониками временной метки.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
После чего мы осуществляем прямой проход Актера.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Как вы помните, для обучения Критиков мы используем фактические действия, совершенные при взаимодействии с окружающей средой. Однако прямой проход Актера нам необходим для формирования латентного состояния.
Далее мы копируем фактические действия из обучающей выборки в буфер данных и осуществляем прямой проход Критиков.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
После чего мы добавляем в буфер описания текущего состояния окружающей среды данные о состоянии счета и нулевой вектор, для подмены действий Актера. И генерируем эмбединг анализируемого состояния окружающей среды.
if(!State.AddArray(GetPointer(Account)) || !State.AddArray(vector<float>::Zeros(NActions)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
На основании полученного эмбединга мы генерируем структуру целей для обучения моделей. Алгоритм метода формирования целевых значений описан в предыдущей статье.
target = GetTargets(Quant, temp, state_embedding, rewards, actions);
На данном этапе у нас есть все необходимые данные, для обратного прохода Критиков. Но так как мы будем корректировать вектор градиента ошибки с помощью метода CAGrad, то обучение моделей мы осуществим последовательно.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Следующим этапом мы переходим к обучению основной политики Актера. Как и ранее, для обучения политики мы будем использовать комбинации подходов. Вначале мы используем алгоритм DWSL и обучаем Актера на повторение действий, взвешенных по их влиянию на конечный результат.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
А затем скорректируем действия Актера в сторону увеличения доходности. Только второй этап обучения используется при достаточной уверенности в корректности оценки действий Критиком.
//--- CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
В завершении итераций процесса обучения мы скорректируем параметры целевых моделей.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
Проинформируем пользователя о ходе процесса обучения и перейдем к следующей итерации цикла обучения.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения полного цикла обучения моделей мы очистим поле комментариев на графике. Выведем результаты обучения в журнал и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
На этом мы завершаем описание алгоритмов используемых программ. С полным кодом всех используемых в статье программ вы можете ознакомиться во вложении. А мы переходим к этапу тестирования проделанной работы.
3. Тестирование
В предыдущих разделах данной статьи мы познакомились с методом Exploratory data for Offline RL и реализовали свое видение представленного метода средствами MQL5. Теперь пришло время оценить результаты проделанной работы. Как всегда, обучение и тестирования модели осуществляется на исторических данных инструмента EURUSD, таймфрейм H1. Параметры всех индикаторов используются по умолчанию. Обучение моделей осуществляется на исторических данных за первые 7 месяцев 2023 года. Тестирование обученных моделей осуществляется на данных августа 2023 года.
Представленный в статье алгоритм позволяет осуществлять обучение абсолютно новых моделей. Так сказать "с нуля". Однако метод позволяет и осуществлять тонкую настройку ранее обученных моделей. Именно второй вариант использования метода я и решил протестировать. Как было сказано в самом начале нашей работы, в качестве основы нашей работы были использованы советники из предыдущей статьи. Оптимизацию этой модели мы и осуществим. Вначале на необходимо переименовать файлы моделей.
| DWSL.bd | ==> | ExORL.bd |
| DWSLAct.nnw | ==> | ExORLAct.nnw |
| DWSLCrt1.nnw | ==> | ExORLCrt1.nnw |
| DWSLCrt2.nnw | ==> | ExORLCrt2.nnw |
Мы не переносим модель Энкодера, так как изменили его архитектуру.
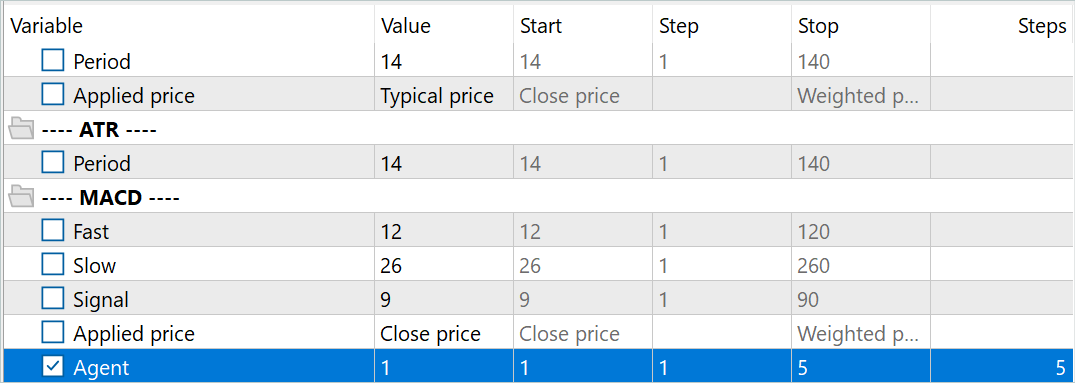
После переименования файлов мы осуществляем запуск советника "ResearchExORL.mq5" для дополнительного исследования окружающей среды на обучающих данных. В своей работе я собрал 100 дополнительных проходов с 5 агентов тестирования.
Практический опыт показывает о возможности параллельного использования в одном буфере воспроизведения собранных различными методами. Я использовал как траектории собранных ранее рассмотренным советником "Research.mq5", так и советником "ResearchExORL.mq5". Первый указывает на преимущества и недостатки выученной политики Актера. Второй позволяет максимально исследовать окружающую среду и оценить неучтенные возможности.
В процессе итерационного обучения модели мне удалось повысить её результативность.


При общем снижении количества сделок за тестовый период в 3 раза (56 против 176) прибыль увеличилась практически в 3 раза. Сумма максимальной прибыльной сделки увеличилась более чем в 2 раза. А средняя прибыльная сделка увеличилась в 5 раз. При этом мы наблюдаем рост баланса на протяжении всего периода тестирования. В итоге профит фактор модели увеличился с 1.3 до 2.96.
Заключение
В данной статье мы познакомились с новым методом Exploratory data for Offline RL, который главным образом акцентирует внимание на подходе к сбору данных для обучающей выборки при офлайн обучении модели. Проведенные авторами метода эксперименты ставят проблему выбора исходных данных в число одной из ключевых, которая оказывает влияние на результат на ровне с выбором архитектуры модели и метода её обучения.
В практической части нашей статьи мы реализовали свое видение предложенного метода и провели его тестирования на исторических данных тестера стратегий MetaTrader 5. Проведенные тесты, подтверждают выводы авторов метода о влиянии алгоритма сбора обучающей выборки на результат обучения модели. Практически только благодаря изменению подхода к сбору обучающих траекторий нам удалось оптимизировать работу модели из предыдущий статьи.
Однако, еще раз ходу обратить внимание, что все программы, представленные в статье предназначены только для демонстрации метода и не оптимизированы для реальной торговли.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchExORL.mq5 | Советник | Советник сбора примеров методом ExORL |
| 3 | Study.mq5 | Советник | Советник обучения агента |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
I don't know how MetaTrader Tester select inputs for every core. Main idea in online study use pretrained model from one pass to other. But if Tester run Optimithation 1..4 to Agent 1 at one pass the they all use random (not pretrained) model.
I don't know how MetaTrader Tester select inputs for every core. Main idea in online study use pretrained model from one pass to other. But if Tester run Optimithation 1..4 to Agent 1 at one pass the they all use random (not pretrained) model.
I also added some indicators and Parameters, total 27 BarDescr... Momentum, Bands & Ichimoku Kinko Hyo =)
int OnInit()
{
Set symbol and refresh
if(! Symb.Name(_Symbol))
return INIT_FAILED;
Symb.Refresh();
//---
if(! RSI. Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR. Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD. Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice))
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied))
return INIT_FAILED;
Initialize the Ichimoku Kinko Hyo indicator
if (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod))
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied))
return INIT_FAILED;
//---
if(! RSI. BufferResize(HistoryBars) || ! CCI.BufferResize(HistoryBars) ||
! ATR. BufferResize(HistoryBars) || ! MACD. BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
return;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Rates, true))
return;
//---
RSI. Refresh();
CCI.Refresh();
ATR. Refresh();
MACD. Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
--- History Data
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Rates[b].open;
float close = (float)Rates[b].close;
float rsi = (float)RSI. Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR. Main(b);
float macd = (float)MACD. Main(b);
float sign = (float)MACD. Signal(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bands.Upper(b);
float bandzb = (float)Bands.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0); Use the calculated value
float kijun = (float)Ichimoku.KijunSen(1); Use the calculated value
float senkasa = (float)Ichimoku.SenkouSpanA(2); Use the calculated value
float senkb = (float)Ichimoku.SenkouSpanB(3); Use the calculated value
Check for EMPTY_VALUE and division by zero
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE ||
bandzlo == EMPTY_VALUE || tenkan == EMPTY_VALUE || kijun == EMPTY_VALUE || senkasa == EMPTY_VALUE ||
senkb == EMPTY_VALUE || kijun == 0.0 || senkb == 0.0)
{
continue;
}
Ensure buffers are not resized within the loop
int shift = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
// Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
//---
Print("State 0: ", sState.state[shift]);
Print("State 1: ", sState.state[shift + 1]);
Print("State 2: ", sState.state[shift + 2]);
Print("State 3: ", sState.state[shift + 3]);
Print("State 4: ", sState.state[shift + 4]);
Print("State 5: ", sState.state[shift + 5]);
Print("State 6: ", sState.state[shift + 6]);
Print("State 7: ", sState.state[shift + 7]);
Print("State 8: ", sState.state[shift + 8]);
Print("State 9: ", sState.state[shift + 9]);
Print("State 10: ", sState.state[shift + 10]);
Print("State 11: ", sState.state[shift + 11]);
Print("State 12: ", sState.state[shift + 12]);
Print("State 13: ", sState.state[shift + 13]);
Print("State 14: ", sState.state[shift + 14]);
Print("State 15: ", sState.state[shift + 15]);
Print("State 16: ", sState.state[shift + 16]);
Print("State 17: ", sState.state[shift + 17]);
Print("State 18: ", sState.state[shift + 18]);
Print("State 19: ", sState.state[shift + 19]);
Print("State 20: ", sState.state[shift + 20]);
Print("State 21: ", sState.state[shift + 21]);
Print("State 22: ", sState.state[shift + 22]);
Print("State 23: ", sState.state[shift + 23]);
Print("State 24: ", sState.state[shift + 24]);
Print("State 25: ", sState.state[shift + 25]);
Print("State 26: ", sState.state[shift + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
I also added some indicators and Parameters, total 27 BarDescr... Momentum, Bands & Ichimoku Kinko Hyo =)
int OnInit()
{
Set symbol and refresh
if(! Symb.Name(_Symbol))
return INIT_FAILED;
Symb.Refresh();
//---
if(! RSI. Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR. Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD. Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice))
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied))
return INIT_FAILED;
Initialize the Ichimoku Kinko Hyo indicator
if (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod))
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied))
return INIT_FAILED;
//---
if(! RSI. BufferResize(HistoryBars) || ! CCI.BufferResize(HistoryBars) ||
! ATR. BufferResize(HistoryBars) || ! MACD. BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
return;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Rates, true))
return;
//---
RSI. Refresh();
CCI.Refresh();
ATR. Refresh();
MACD. Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
--- History Data
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Rates[b].open;
float close = (float)Rates[b].close;
float rsi = (float)RSI. Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR. Main(b);
float macd = (float)MACD. Main(b);
float sign = (float)MACD. Signal(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bands.Upper(b);
float bandzb = (float)Bands.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0); Use the calculated value
float kijun = (float)Ichimoku.KijunSen(1); Use the calculated value
float senkasa = (float)Ichimoku.SenkouSpanA(2); Use the calculated value
float senkb = (float)Ichimoku.SenkouSpanB(3); Use the calculated value
Check for EMPTY_VALUE and division by zero
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE ||
bandzlo == EMPTY_VALUE || tenkan == EMPTY_VALUE || kijun == EMPTY_VALUE || senkasa == EMPTY_VALUE ||
senkb == EMPTY_VALUE || kijun == 0.0 || senkb == 0.0)
{
continue;
}
Ensure buffers are not resized within the loop
int shift = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
// Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
//---
Print("State 0: ", sState.state[shift]);
Print("State 1: ", sState.state[shift + 1]);
Print("State 2: ", sState.state[shift + 2]);
Print("State 3: ", sState.state[shift + 3]);
Print("State 4: ", sState.state[shift + 4]);
Print("State 5: ", sState.state[shift + 5]);
Print("State 6: ", sState.state[shift + 6]);
Print("State 7: ", sState.state[shift + 7]);
Print("State 8: ", sState.state[shift + 8]);
Print("State 9: ", sState.state[shift + 9]);
Print("State 10: ", sState.state[shift + 10]);
Print("State 11: ", sState.state[shift + 11]);
Print("State 12: ", sState.state[shift + 12]);
Print("State 13: ", sState.state[shift + 13]);
Print("State 14: ", sState.state[shift + 14]);
Print("State 15: ", sState.state[shift + 15]);
Print("State 16: ", sState.state[shift + 16]);
Print("State 17: ", sState.state[shift + 17]);
Print("State 18: ", sState.state[shift + 18]);
Print("State 19: ", sState.state[shift + 19]);
Print("State 20: ", sState.state[shift + 20]);
Print("State 21: ", sState.state[shift + 21]);
Print("State 22: ", sState.state[shift + 22]);
Print("State 23: ", sState.state[shift + 23]);
Print("State 24: ", sState.state[shift + 24]);
Print("State 25: ", sState.state[shift + 25]);
Print("State 26: ", sState.state[shift + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
JimReaper - How many cycles did you study your version before getting the result in your picture? (data collection - training). And how long did it take?
What is your computer configuration (processor, video card, RAM)?
Thank you
затем устанавливаем агента на 5 и оптимизацию на 20
Итого 100...
Я вижу в коде ссылку на агента, но не вижу оптимизацию. Было ли дополнительное дополнение к коду, которое вы сделали, чтобы использовать этот новый параметр?
Спасибо
Пол