
ニューラルネットワークが簡単に(第48回):Q関数値の過大評価を減らす方法

はじめに
前回の記事では、連続行動空間におけるモデルの学習用に設計されたDDPG (Deep Deterministic Policy Gradient)法について考察しました。これにより、モデル訓練を次のレベルに引き上げることができます。その結果、直近のエージェントは、今後の値動きの方向性を予測することができるだけでなく、資本とリスク管理の機能も果たすことができます。これは、建てるポジションの最適なサイズと、ストップロスとテイクプロフィットのレベルを示します。
しかし、DDPGには欠点もあります。他のQ学習の信奉者同様、Q関数の値を過大評価するという問題があります。訓練中、誤差は蓄積され、最終的にエージェントは最適でない戦略を学習することになります。
覚えておいでかもしれませんが、DDPGでは、Criticモデルは環境との相互作用の結果に基づいてQ関数(期待報酬の予測)を学習し、エージェントモデルはCriticの行動評価の結果のみに基づいて期待報酬を最大化するように訓練されます。その結果、Criticの訓練の質は、エージェントの行動戦略と最適な意思決定をおこなう能力に大きく影響します。
1.過大評価を減らすためのアプローチ
DQN法やその派生モデルを用いて様々なモデルを訓練する際、Q関数の値を過大評価するという問題がよく現れます。これは、離散的な行動を持つモデルでも、連続的な行動の空間で問題を解くときでも特徴的です。この現象の原因や、その結果に対する対処法は、個々のケースによって異なります。したがって、この問題を解決するための統合的なアプローチが重要です。そのようなアプローチの1つが、2018年2月に発表された記事「Addressing Function Approximation Error in Actor-Critic Methods」で紹介されています。ここでは、TD3 (Twin Delayed Deep Deterministic policy gradient)と呼ばれるアルゴリズムが提案されています。このアルゴリズムはDDPGを論理的に継承したものであり、モデル学習の質を高めるいくつかの改良を導入しています。
まず、著者は2つ目のCriticを加えます。このアイデアは新しいものではなく、以前にも離散行動空間モデルで使われたことがあります。しかし、このメソッドの著者らは、2番目のCriticの使用について、彼らの理解、ビジョン、アプローチに貢献しています。
このアイデアは、両方のCriticsがランダムなパラメータで初期化され、同じデータで並列に学習されるというものです。異なる初期パラメータで初期化され、異なる状態から訓練を開始します。しかし、どちらのCriticも同じデータで訓練されているので、同じ(望ましいグローバルな)最小値に向かって動くはずです。訓練中に予測結果が収束するのはごく自然なことです。しかし、さまざまな要因の影響により、両者は同一ではありません。いずれもQ関数の過大評価という問題がありますが、ある時点において、一方のモデルはQ関数を過大評価し、もう一方のモデルは過小評価します。両方のモデルがQ関数を過大評価する場合でも、一方のモデルの誤差はもう一方のモデルの誤差よりも小さくなります。これらの仮定に基づき、このメソッドの著者は、両Criticの訓練に最小予測値を使用することを提案します。こうして、学習過程におけるQ関数の過大評価や誤差の蓄積の影響を最小限に抑えます。
数学的には、この方法は次のように表すことができます。
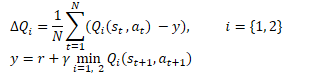
DDPGと同様に、TD3の著者もターゲットモデルのソフト更新を推奨しています。実用的な例を用いて、著者らは、ターゲットモデルのソフト更新を使用することで、結果のばらつきが少なく、より安定したQ関数学習プロセスにつながることを実証しています。同時に、訓練過程でより安定した(更新の少ない)目標を使用することは、Q関数再評価誤差の蓄積の減少につながります。
実験の結果、このメソッドの作者は、Actorの方策をよりまめに更新するように促されました。
ご存知のように、ニューラルネットワークの訓練は、徐々にエラーを減らしていく反復プロセスです。訓練速度は、訓練係数とパラメータ更新アルゴリズムによって決定されます。このアプローチでは、学習サンプルの誤差を平均化し、研究対象のプロセスにできるだけ近いモデルを構築することができます。
Actorモデルの結果は、評論家の訓練セットの一部です。Actor方策を稀に更新することで、Criticの訓練サンプルの確率性を減らし、訓練の安定性を高めることができます。
また、より精度の高いCriticの結果を評価したデータを使ってActorを訓練することで、Actorの仕事の質を向上させ、誤った結果をもたらす不要な更新操作を排除することができます。
さらに、TD3アルゴリズムの作者は、学習プロセスに目的関数の平滑化を加えることを提案しました。サブプロセスの使用は、似たような行動が似たような結果につながるという仮定に基づいています。微妙に異なる2つの行動が同じ結果をもたらすと仮定します。したがって、エージェントの行動に小さなノイズを加えても、環境からの報酬は変わりませんが、これによってCriticの学習プロセスに確率性を加え、目標値のある環境下での評価を滑らかにすることができます。
![]()
この方法によって、Criticの訓練に一種の正則化を導入し、Q関数の値の過大評価につながるピークを平滑化することができます。
このように、Twin Delayed Deep Deterministic policy gradient (TD3)は、DDPGアルゴリズムに3つの主な追加要素を導入しています。
- 評論家2人の並行訓練
- Actorパラメータ更新遅延
- ターゲット関数の平滑化
おわかりのように、3つの追加はすべて訓練の準備メントに関するもので、モデルのアーキテクチャには影響しません。
2.MQL5を使用した実装
この記事の実践編では、MQL5を使ったTD3アルゴリズムの実装について考えます。この実装では、3つの追加のうち2つだけを使用します。金融市場自体が確率的であるため、目的関数の平滑化は追加しませんでした。訓練セット全体で完全に同じ状態が2つ見つかることはまずありません。
また、3つのEAを使用した経験に戻ります。
- Research:例データベースの収集
- Study:モデル訓練
- Test:得られた結果の確認
さらに、モデル結果の解釈やEAの取引アルゴリズムにも変更を加えています。
2.1.取引アルゴリズムの変更
まず、取引アルゴリズムの変更について話します。「open and forget」原則(現在の市場状況の分析結果に基づいてポジションを建て、ストップロスまたはテイクプロフィットに従って決済する)を使って新しいポジションを際限なく建てることから離れることにしました。その代わり、ポジションを開いて維持します。同時に、ポジションの追加や一部決済も排除しません。
このパラダイムでは、モデルシグナルの解釈を変えます。以前と同様に、エージェントは6つの値(2つの取引方向におけるポジションサイズ、ストップロス、テイクプロフィット)を返しますが、今度は、受け取った出来高と現在のポジションを比較し、必要であればポジションを追加するか、部分的に決済します。標準的な方法で資金を追加します。ポジションを部分的に決済するためのClosePartial関数を作成します。
標準的な手段で1つのポジションの一部を決済することができますが、トップアップの結果、いくつかのポジションが開かれたと仮定します。したがって、作成された関数のタスクは、FIFO(First In - First Out)方式で総数量のポジションを決済することです。
パラメータには、ポジションの種類と終値が指定されます。関数本体では、受信した終値の出来高を直ちに確認し、不正確な値を受信した場合は関数を終了します。
次に、すべてのポジションを検索するサイクルを準備します。ループ本体で、ポジションの商品とタイプを確認します。必要なポジションを見つけたら、その出来高を確認します。ここで2つの選択肢があります。
- ポジションの出来高が終値の出来高以下である場合、ポジションを完全に決済し、終値の出来高をポジションの出来高分だけ減らします。
- ポジションの出来高が終値の出来高より大きい場合、ポジションを一部決済し、終値の出来高をゼロにリセットします。
すべてのポジションが検索されるか、決済までの出来高が「0」を超えるまで、このサイクルを繰り返します。
bool ClosePartial(ENUM_POSITION_TYPE type, double value) { if(value <= 0) return true; //--- for(int i = 0; (i < PositionsTotal() && value > 0); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; double pvalue = PositionGetDouble(POSITION_VOLUME); if(pvalue <= value) { if(Trade.PositionClose(PositionGetInteger(POSITION_TICKET))) { value -= pvalue; i--; } } else { if(Trade.PositionClosePartial(PositionGetInteger(POSITION_TICKET), value)) value = 0; } } //--- return (value <= 0); }
ポジションサイズを決めました。ストップロスとテイクプロフィットのレベルについて話しましょう。取引の経験から、価格がポジションに対して不利に動いた場合、ストップロス水準をずらすことは悪習慣であり、リスクを増大させ、損失を累積させるだけであることを知っています。従って、ストップロスは取引の方向にのみトレールします。テイクプロフィットレベルを両方向に移動させることができます。ここでのロジックは単純です。当初はテイクプロフィットをもっと控えめに設定することもできましたが、相場展開がより強い動きを示唆しています。従って、ストップロスをトレールしても、期待利益のバーを上げることができます。予想される市場の動きを逃せば、収益性のハードルを下げることができます。私たちは市場が与えてくれるものだけを受け取ります。
説明した機能を実装するために、TrailPosition関数を作成します。関数のパラメータでは、ポジションの種類、ストップロスとテイクプロフィットの価格を指定します。現在価格からのポイントインデントではなく、取引レベルの価格を正確に表示していることにご注意ください。
関数本体で指定されたレベルは確認しません。この点については、ユーザーの判断に任せ、メインプログラムの側でこのようなコントロールの必要性についてメモしておくことにします。
次に、すべてのポジションを検索するサイクルを準備します。ポジションを部分決済する関数と同様に、ループ本体では、ポジションの商品とタイプを確認します。
希望のポジションが見つかったら、そのポジションの現在のストップロスとテイクプロフィットをローカル変数に保存します。同時に、ポジション変更フラグをfalseに設定します。
この後、ポジションの取引水準とパラメータで得られた水準との乖離を確認します。改造の必要性の確認は、ポジションのタイプによって異なります。そのため、switch文の本文中で、ポジションタイプの確認を行い、この制御を実行します。取引レベルの少なくとも1つを変更する必要がある場合は、ローカル変数の対応する値を置き換え、ポジション変更フラグをtrueに変更します。
ループ操作の最後に、ポジション変更フラグの値を確認し、必要であれば取引レベルを更新します。操作の結果はローカル変数に格納されます。
すべてのポジションを検索した後、実行された操作の論理結果を呼び出し元のプログラムに返す関数を完成させます。
bool TrailPosition(ENUM_POSITION_TYPE type, double sl, double tp) { int total = PositionsTotal(); bool result = true; //--- for(int i = 0; i <total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; bool modify = false; double psl = PositionGetDouble(POSITION_SL); double ptp = PositionGetDouble(POSITION_TP); switch(type) { case POSITION_TYPE_BUY: if((sl - psl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; case POSITION_TYPE_SELL: if((psl - sl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; } if(modify) result = (Trade.PositionModify(PositionGetInteger(POSITION_TICKET), psl, ptp) && result); } //--- return result; }
Actorのシグナルの解釈の変化について言えば、もう一点注目すべき点があります。以前は、Actorの出力に対する活性化関数として LReLU を使用していました。これにより、上限値で無制限の結果を得ることができます。また、私たちが取引無しシグナルとみなしたネガティブな結果を表示することもできます。現在のActorシグナルの解釈のパラダイムにおいて、活性化関数を0から1の範囲のシグモイドに変更することにしました。取引量としては、この値にはかなり満足しています。同じことが取引レベルについても言えるわけではありません。取引レベルの値を読み解くために、ストップロスとテイクプロフィットの最大サイズを決定する2つの定数を価格から導入します。これらの定数に対応するActorデータを掛け合わせることで、現在価格からポイント単位で取引水準を求めることができます。
#define MaxSL 1000 #define MaxTP 1000
それ以外の点では、モデルのアーキテクチャは変わっていないので、ここでは説明しません。添付ファイルをご覧ください。例によって、モデルアーキテクチャの記述は、CreateDescriptions関数のTD3Trajectory.mqhにあります。
2.2.EAを収集するデータベース例の構築
Actorシグナル解読の原則と取引アルゴリズムの基本が決まったので、モデル訓練EAに直接取り掛かることができます。
まず、TD3Research.mq5 EAを作成し、例の訓練サンプルを収集します。このEAは、過去にレビューされた同様のEAに基づいて作成されています。この記事では、上述の取引アルゴリズムを実装するOnTickメソッドのみを検討します。それ以外は、新しいEAバージョンは以前のものと大差ありません。
メソッドの冒頭で、前回と同様に、新しいローソク足を開くイベントを確認します。そして、銘柄の値動きの履歴データと分析した指標のパラメータをダウンロードします。
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
ダウンロードしたデータを、環境の現在の状態を表すバッファに渡します。
MqlDateTime sTime; float atr = 0; State.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign); }
次のステップは、口座の状態を表すベクトルを用意することです。
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance));
見てわかるように、初期データの準備は、先に説明したEAの配置と同様です。
次に、準備したデータをActorモデルの入力に移し、フォワードパスを実行します。
if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) return;
次のバーで必要なデータを保存し、Actorの仕事の結果を得ます。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp;
このEAではActorモデルのみを使用していることに注意してください。結局のところ、学習した方策(戦略)に従って行動を生み出すのはActorなのです。モデルの訓練にはCriticモデルを使用します。
次に、環境を最大限に研究するために、Actorの結果に少しノイズを加えます。
ここで、EAを起動するために2つのモードがあることを覚えておく必要があります。初期段階では、事前に訓練したモデルなしでEAを起動し、ランダムなパラメータでActorを初期化します。このモードでは、環境を探索するためにノイズを加える必要はありません。結局のところ、訓練されていないモデルは、ノイズがなくてもカオス的な値を出しますが、事前に訓練されたモデルを読み込んだ場合、ノイズを加えることで、Actorの決定の近辺の環境を探索することができます。
得られた値をシグモイドの許容値の範囲に制限し、Actorモデルの出力で活性化関数として使用します。
if(AddSmooth) { int err = 0; for(ulong i = 0; i < temp.Size(); i++) temp[i] += (float)(temp[i] * Math::MathRandomNormal(0, 0.3, err)); temp.Clip(0.0f, 1.0f); }
次に、Actorの結果ベクトルを解読する段階に移ります。まず、主な定数をローカル変数に保存します。最小ポジション量、ポジション量を変更するステップ、取引レベルの最小インデントです。
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point();
まず、ロングポジションの指標を解読します。ベクトルの最初の要素は、ポジションボリュームと識別されます。最小ポジション量以上でなければなりません。2番目と3番目の要素は、それぞれテイクプロフィットとストップロスの値を示します。これらの要素を最大テイクプロフィットとストップロスの定数で調整し、さらに1銘柄ポイントの値で掛け算してみましょう。その結果、取引レベルの最小インデントよりも大きな値が得られるはずです。少なくとも1つのパラメータが条件を満たさない場合、その方向のポジションをすべて決済します。
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Actorの結果がロングポジションの建玉または保有を推奨する場合、分析銘柄に対するブローカーの要件に従ってポジションサイズを正規化します。取引レベルを具体的な価格に換算してみましょう。次に、POSITION_TYPE_BUYのポジションタイプと、その結果としての取引レベルの価格値を示して、ポジションを修正するための上述の関数を呼び出します。
else { double buy_lot = min_lot+MathRound((double)(temp[0]-min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
次に、ポジションのサイズをActorの推奨サイズに合わせます。未決済ポジションの数量が推奨よりも多い場合は、ポジションを部分決済する関数を呼び出します。この関数のパラメータには、POSITION_TYPE_BUY ポジションタイプを指定し、クローズするポジションのサイズとして、オープンボリュームと推奨ボリュームの差を指定します。
追加が推奨される場合は、不足分のポジションを追加で建てます。同時に、推奨されるストップロスとテイクプロフィットのレベルも示します。
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
ショートポジションのパラメータも同様に解読されます。
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot+MathRound((double)(temp[3]-min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
メソッドの最後に、軌跡配列にデータを追加し、それを例のデータベースに保存します。ここではまず、環境から報酬を生み出します。報酬として、口座の状態を表すベクトルの最初の要素に記録した、相対的な残高の変化を使用します。必要であれば、この報酬にポジションの不足に対するペナルティを加えます。
状態の記述構造に、環境の現在の状態とActorの結果のベクトルを追加します。口座状況の説明データは先ほど入力しました。現在の状態を軌跡配列に追加するメソッドを呼び出します。
//--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; State.GetData(sState.state); if(!Base.Add(sState, reward)) ExpertRemove(); }
その他のEA機能はほぼ変更なく移管されました。添付ファイルにあります。次の段階に進みます。
2.3.モデル訓練EAの作成
モデルはTD3Study.mq5 EAで訓練されます。このEAでは、TD3アルゴリズム全体を、Actorと2人のCriticの訓練で準備します。
訓練プロセスを準備するには、訓練管理に役立ついくつかの外部変数を加える必要があります。いつものように、ここではモデルパラメータを更新するための反復回数を示します。TD3法の文脈では、これはCriticモデルの訓練のことを指します。
input int Iterations = 1000000;
Actorの更新頻度を示すために、UpdatePolicy変数を作成し、1回のActorの更新に対して何回のCriticの更新をおこなうかを示します。
input int UpdatePolicy = 3;
さらに、対象モデルの更新頻度と更新比率を指定します。
input int UpdateTargets = 100; input float Tau = 0.01f;
グローバル変数エリアでは、ニューラルネットワーククラスのインスタンスを6つ宣言します。Actor、2つのCritic、対象モデルです。
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetActor; CNet TargetCritic1; CNet TargetCritic2;
EAを初期化するメソッドは、訓練済みモデルの数の違いを考慮すると、以前の記事の同様のEAとほぼ同じです。添付ファイルをご覧ください。
しかし、初期化解除メソッドでは、(以前のように)訓練済みモデルではなく、ターゲットモデルを更新して保存します。ターゲットモデルはより静的で、エラーの可能性が低くなります。
void OnDeinit(const int reason) { //--- TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetActor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", TargetCritic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", TargetCritic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
モデル訓練はTrain関数で準備されます。関数本体では、学習サンプルのロードされた軌道の数をローカル変数に保存し、外部パラメータで指定された反復回数に従って学習サイクルを準備します。
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
ループ本体では、軌道と状態をランダムに選択します。
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
まず、ターゲットモデルに対してフォワードパスを実行し、後続の状態の予測値を得ます。
理論的には、ターゲット関数なしでモデルを訓練することができます。結局のところ、蓄積された実際の後続の報酬から、後続の状態の価値を決定することができました。環境の最終的な状態を扱うのであれば、このアプローチは適しているかもしれませんが、予見可能な時間軸で無限である金融市場をモデルとして訓練しているため、1ヶ月前や3ヶ月前の同じような状態にも同じ価値があります。したがって、よく訓練されたCriticモデルは、履歴の深さに関係なく結果を同等にします。
EAの話に戻りましょう。例のデータベースから、環境の状態を記述するバッファにデータを転送し、口座の状態を記述するベクトルを形成します。選択された状態ではなく、その後の状態のデータを取ることにご注意ください。
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
そして、ターゲットとなるActorモデルのダイレクトパスを準備します。
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!TargetActor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
次に、2つのCriticsモデルのダイレクトパスを実行します。両モデルのソースデータは、ターゲットとなるActorモデルです。
if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
得られたデータから、Criticモデルを訓練するための目標値を生成することができます。
各Criticが返すのは、現在のコンディションで予測される行動コストの1つの値だけであることを思い出してください。したがって、目標値も1つの数字になります。
TD3アルゴリズムに従い、Criticsモデルの2つのTarget結果から最小値を取ります。結果の値に割引係数を掛け、例のデータベースから取った行動に対する実際の報酬を加えます。
TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = DiscFactor * MathMin(reward, Result[0]) + (Buffer[tr].Revards[i] - Buffer[tr].Revards[i + 1]);
この時点で、Criticの目標値が決まりました。TD3アルゴリズムは、2つのCriticモデルに対して1つの目標値しか提供しませんが、戻る前にCriticたちのフォワードパスを実行する必要があります。ここにはニュアンスがあります。ご存知のように、Criticのアーキテクチャはプライマリデータ処理ユニットを備えていません。この機能はActorによって実行され、Actorの潜在的な状態を、環境の状態を記述するための初期データとしてCriticに転送します。そこでまず、例のデータベースから初期データを取得し、Actorモデルを通してフォワードパスを実行します。
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
ここで、Actorはおそらく、訓練の過程でデータベースに保存された例とは異なる行動を返すことに留意すべきです。しかし、報酬は保存された行動には対応しません。そこで、Actorの潜在的な状態を解除します。例のデータベースから完璧な行動をアップロードします。このデータを使って、両方のCriticのダイレクトパスを実行します。
if(!Critic1.feedForward(Result,1,false, GetPointer(Actions)) || !Critic2.feedForward(Result,1,false, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
ここで、もう1つ気にしなければならないことがあります。理論的には、例のデータベースを収集する段階でActorの潜在的な状態を保存しておき、あとは単純に保存したデータを使えばいいのですが、すべてのニューラル層のパラメータは、モデルの訓練中に変化します。その結果、データの前処理ブロックもActorの訓練中に変更されます。そして、同じ環境状態の潜在的表現が変化します。もし間違った初期データでCriticを訓練すれば、Actorを訓練するときに予測できない結果になってしまうので、もちろん、これは避けたいものです。したがって、Criticsを訓練するには、環境状態の正しい潜在表現と、例データベースの完了した行動とそれに対応する報酬を使用します。
次に、ターゲット値バッファを満たし、両方のCriticでリバースパスを実行します。
Result.Clear(); Result.Add(reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Actor訓練に移りましょう。この記事の理論的な部分で述べたように、Actorのパラメータは更新頻度が低くなります。したがって、まず現在の反復でこの手順の必要性を確認します。
//--- Policy study if(iter > 0 && (iter % UpdatePolicy) == 0) {
Actorのパラメータを更新するときは、客観性を保つために、新しい初期データをランダムに選択します。
tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
次に、Actorのフォワードパスを実行します。
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
そして、Critic1つのフォワードパスを実行します。ここでは、例のデータベースのデータは使用していないことにご注意ください。Criticフォワードパスは、現在のモデル方策を評価することが重要であるため、Actorの新しい結果に対しておこなわれます。
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Actorのパラメータを更新するために、Critic1を使いました。私の観察によれば、この場合のCriticモデルの選択はそれほど重要ではありません。評価の違いにもかかわらず、どちらのCriticもテスト中、Actorに対して同じ誤差の勾配値を返しました。
Actorの訓練は、期待される報酬を最大化することを目的としています。Criticの行動評価の現在の結果を取り、それに小さな正の定数を加えます。行動に対する否定的な評価を受けた場合、自分の肯定的な定数を目標値としました。こうして、否定的な評価の領域からの脱出を早めようとしました。
Critic1.getResults(Result); float forecast = Result[0]; Result.Update(0, (forecast > 0 ? forecast + PoliticAdjust : PoliticAdjust));
Actorのパラメータを更新する際、Criticモデルは一種の損失関数としてのみ使用されます。Actorの出力に誤差の勾配を発生させるだけです。この場合、Criticパラメータは変わりません。このため、リバースパスの前にCriticの訓練モードを無効にします。誤差勾配をActorに転送した後、Criticを訓練モードに戻します。
Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { Critic1.TrainMode(true); PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Critic1.TrainMode(true); }
Criticから誤差勾配を受け取った後、Actorのリバースパスを実行します。
この段階で、CriticによるQ機能の訓練と、Actorへの方策の指導を準備しました。最後にすべきことは、ターゲットモデルのソフトアップデートを実装することです。これについては前回の記事で詳述しました。ここでは、モデルがいつ更新されたかを確認し、対象モデルごとに適切なメソッドを呼び出すだけです。
//--- Update Target Nets if(iter > 0 && (iter % UpdateTargets) == 0) { TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
ループの反復が終わったら、訓練についてユーザーに通知し、両評論家の現在の誤差を表示します。このモデルでは誤差は計算されないため、Actorの訓練の質を示す指標は表示しません。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
ループの反復が完了したら、コメントエリアをクリアし、EAのシャットダウン処理を開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
訓練済みモデル「TD3Test.mq5」をテストするアルゴリズムの説明は割愛します。そのコードは、例のデータベースコレクションEAをほぼ完全に繰り返しています。モデルの訓練の質を評価したいので、Actorの仕事の結果にノイズが加わることだけを除外しており、環境の研究は除外しています。同時に、軌跡を収集し、例のデータベースに記録するためのブロックも残してあります。これにより、成功したパスと失敗したパスを保存することができるので、次の訓練開始時に誤差の訂正をおこなうことができます。
使用されたすべてのプログラムの完全なコードは、添付ファイルでご覧ください。
3.検証
訓練に移り、得られた結果を検証してみましょう。例によって、モデルは2023年1月から5月までのEURUSD H1の履歴データで訓練されました。指標パラメータとすべてのハイパーパラメータはデフォルト値に設定しました。
訓練はかなり長引き、反復されました。最初の段階では、200の軌跡のデータベースが作成されました。最初の訓練は、1,000,000回繰り返されました。Actorの方策は、Criticのパラメータを10回更新するごとに1回更新されました。ターゲットモデルのソフトアップデートは、Criticスのアップデートが1,000回繰り返されるごとにおこなわれました。
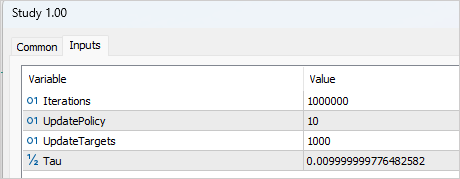
その後、さらに50の軌跡が例データベースに追加され、モデル訓練の第2段階が開始されました。同時に、Actorモデルとターゲットモデルを更新するまでの反復回数を、それぞれ3回と100回に減らしました。
約5回の訓練サイクル(各サイクルで50の軌道を追加)の後、訓練セットで利益を生み出すことができるモデルが得られました。訓練サンプルの5ヵ月後、モデルは収入のほぼ10%を受け取ることができました。これは最高の結果ではありません。58件の取引がおこなわれました。利益を上げたのは40%にも満ちません。プロフィットファクターは1.05、リカバリーファクターは1.50です。利益を上げたのは、利益を上げたポジションの大きさによるものです。1回の取引から得られた平均利益は、平均損失の1.6倍です。最大利益は、1回の取引による最大損失の3.5倍です。
注目すべきは、残高のドローダウンがほぼ32%であるのに対し、資産がほとんど6%を超えていないことです。チャートでおわかりのように、資産の曲線は横ばいか、あるいは伸びている状態で、残高のドローダウンが観察されます。この効果は、多方向のポジションが同時に開くことで説明できます。負けポジションのストップロスがトリガーされると、残高のドローダウンが発生します。同時に、反対方向のポジションは利益を蓄積し、資産の曲線に反映されます。


思い起こせば、前回の記事では、モデルは訓練セットでより有意な結果を示しましたが、新しいデータではそれを繰り返すことができませんでした。今、状況は逆転しています。訓練セットでは超過利益を得ていませんが、訓練セット以外では安定した結果を示しています。訓練セットに含まれていない後続のデータでモデルをテストすると、前回のテストの「小さなコピー」が表示されます。このモデルは1ヶ月で2.5%の利益を得ました。プロフィットファクターは1.07、リカバリーファクターは1.16です。利益が出た取引はわずか27%ですが、平均的な利益取引は平均的な損失取引の3倍近くあります。残高は32%減少し、資産はわずか2%減少しました。


結論
この記事では、Twin Delayed Deep Deterministic policy gradient (TD3)アルゴリズムを紹介しました。この手法の著者は、DDPGアルゴリズムにいくつかの重要な改良を提案しました。これにより手法の効率とモデル学習の安定性を高めることができます。
記事の一部として、MQL5を使ってこの方法を実装し、過去のデータでテストしました。訓練の過程で、訓練データだけでなく、新しいデータで得た経験も使って利益を生み出すことができるモデルが得られました。注目すべきなのは、新しいデータにおいて、モデルが訓練セットの結果と同等の結果を得たことです。結果は私たちが望んでいるようなものではありませんでした。まだ取り組まなければならないことがあります。しかし確かなことは、TD3アルゴリズムは新しいデータでも確実に機能するモデルを訓練できるということです。
一般に、このアルゴリズムは、実際の取引のためのモデル構築のさらなる研究に利用することができます。
参考文献リスト
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | Study.mq5 | EA | エージェント訓練 EA |
| 3 | Test.mq5 | EA | モデルテストEA |
| 4 | Trajectory.mqh | クラスライブラリ | システム状態記述構造 |
| 5 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 6 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/12892
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
Dimitryさん、素晴らしいシリーズをありがとうございます!
Trajectory.mqhをコンパイルする際、274行目の "int total = ArraySize(Buffer); "でエラーが発生しました。以前の記事で検索したのですが、この部分(48)でSaveTotalBase()という関数がソースコード上で初めて言及されています。
この素晴らしいシリーズをありがとう!
Trajectory.mqhをコンパイルする際、274行目の "int total = ArraySize(Buffer); "でエラーが発生しました。以前の記事で検索したのですが、この部分(48)でSaveTotalBase()という関数がソースコード上で初めて言及されています。
Trajectory.mqhをコンパイルする必要はありません。Trajectory.mqhは他のEAで使用するためのライブラリです。